Webスクレイピングとは
スクレイピング(Scraping)とは、Webサイトから任意の情報を検索し抽出する技術のことです。
また、Web上のデータの取得だけではなく、構造も解析できます。
Webスクレイピングをする前に
スクレイピングを行う前に、確認するべき点や、作業中に気を付ける必要がある点がいくつかかありますので説明します。
1)APIが存在するかどうか
APIを提供しているサービスがあればそちらを使い、データを取得しましょう。
それでも、データが不十分だったりなどの問題があるのであればスクレイピングを検討します。
2)取得後のデータの用途に関して
取得後のデータを使う場合には、注意が必要です。
取得先のデータは自分以外の著作物にあたり、著作権法に抵触しないように考慮する必要があるためです。
私的利用のための複製(第30条)
http://www.houko.com/00/01/S45/048.HTM#030
情報解析のための複製等(第47条の7)
http://www.houko.com/00/01/S45/048.HTM#047-6
また、特に問題となる3つの権利として以下が挙げられます。
- 複製権:
製権は、著作権に含まれる権利のひとつで、著作権法第21条で規定されています。(第21条「著作者は、その著作物を複製する権利を専有する。」)
複製とは、作品を複写したり、録画・録音したり、印刷や写真にしたり、模写(書き写し)したりすること、そしてスキャナーなどにより電子的に読み取ること、また保管することなどを言います。
引用先: https://www.jrrc.or.jp/guide/outline.html
- 翻案権:
翻訳権・翻案権は、著作権法第二十七条に規定されている著作財産権です。第二十七条では「著作者は、その著作物を翻訳し、編曲し、若しくは変形し、又は脚色し、映画化し、その他翻案する権利を専有する」(『社団法人著作権情報センター』 http://www.cric.or.jp/db/article/a1.html#021より)と明記されています。反対に見ると、これらを著作者の許諾なしに行うと、著作権の侵害になるということです。
引用先: http://www.iprchitekizaisan.com/chosakuken/zaisan/honyaku_honan.html
- 公衆送信権:
公衆送信権は、著作権法第二十三条において規定される著作財産権です。この第二十三条では「著作者は、その著作物について、公衆送信(自動公衆送信の場合にあっては、送信可能化を含む。)を行う権利を占有する。」「著作者は、公衆送信されるその著作物を受信装置を用いて公に伝達する権利を占有する。」と明記されています。
引用先: http://www.iprchitekizaisan.com/chosakuken/zaisan/kousyusoushin.html
また上記を注意しながら、実際にスクレピングを行う際に、書いたコードによってサーバに負荷がかからないようにしましょう。
過度なアクセスはサーバに負担をかけてしまい攻撃だとみなされてしまい、最悪の場合一定期間サービスを利用できなくなってしまう可能性があります。
さらには、システムにアクセス障害が発生し、利用者の一人が逮捕された事件もありますので、常識の範囲内での使用してください。
https://ja.wikipedia.org/wiki/岡崎市立中央図書館事件
以上を踏まえた上で、次に進んでいきましょう。
HTML基礎
Webスクレイピングを実践する際にHTMLの基礎を知っておくと便利です。
なぜかというと、HTMLで使われるタグ(<html>や<div>、<p>)を指定してデータを取得するからです。
ちょっと例をあげてみましょう。
<html>
<head>
<title>neet-AI</title>
</head>
<body>
<div id="main">
<p>neet-AIのリンクはこちら</p>
<a href="https://neet-ai.com">neet-AI</a>
</div>
</body>
</html>
上記のコードをブラウザ上で見ると
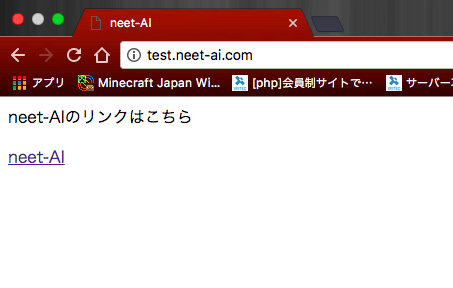
このようなページがでてきます。
このページ上で使われているHTMLタグについて解説していきましょう。
HTMLタグ一覧
| タグ名 | 説明 |
|---|---|
| <html></html> | これはHTMLのコードですよと明示するタグ |
| <head></head> | ページの基本的情報(文字コードやページタイトル)を表します。 |
| <title></title> | ページタイトルを表します。 |
| <body></body> | ページの本体を表します。 |
| <div></div> | タグ自身には意味はありませんが、これで1コンテンツと表すときによく使われます。 |
| <p></p> | このタグで囲まれた文はこれで1段落と表します。 |
| <a></a> | 他ページへのリンクを表します。 |
上記で説明したタグ以外にも種類はたくさんあります。どのようなタグかきになる場合にはその都度調べてみましょう。
Webスクレイピング基礎
HTMLのタグについて理解できたので、さっそくスクレイピングをしてみましょう。
Webスクレイピングの基本的手順
1.Webページを取得する
2.プログラムで、指定したタグを検索し抽出する(スクレイピング)
3.スクレイピングして得たデータを整形し保存or表示する
以上の手順がスクレイピングの基本手順です。
使用するライブラリ
PythonでWebスクレイピングする場合にはさまざまなライブラリを使っていきます。
・Requests
Webページを取得する際に使います。
・BeautifulSoup4
取得したWebページを解析し、タグの検索、データの整形をします。
上記のライブラリを使ってWebスクレイピングをしていきます。
Pythonでスクレイピングする準備
スクレイピングをする前にPythonでWebページのHTMLをとってくる必要があります。
import requests
response = requests.get('http://test.neet-ai.com')
print(response.text)
各行の説明をしていきましょう。
response = requests.get('http://test.neet-ai.com')
この行ではhttp://test.neet-ai.comからHTMLをとってきてます。
とってきたHTMLはresponse変数に入ります。
print(response.text)
responseという変数はtextをつけないとBeautifulSoupで使えません。
ページのタイトルをスクレイピング
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com')
soup = BeautifulSoup(response.text,'lxml')
title = soup.title.string
print(title)
百聞は一見にしかずでプログラムをみていきましょう。
4行目までは先ほどの「Pythonでスクレイピングする準備」と変わりありません。
5行目からがスクレイピングのプログラムとなりますので各行を解説していきましょう。
soup = BeautifulSoup(response.text,'lxml')
ここではsoupという変数を用意し、取ってきたHTMLデータをスクレイピングできる形にしています。
カッコ内の'lxml'というのは 「lxmlというツールでresponse.textを変換するよ」 という意味です。
title = soup.title.string
取ってきたHTMLデータを変換できたら、BeautifulSoupの決まった型で指定してあげれば指定のデータを抽出することができます。
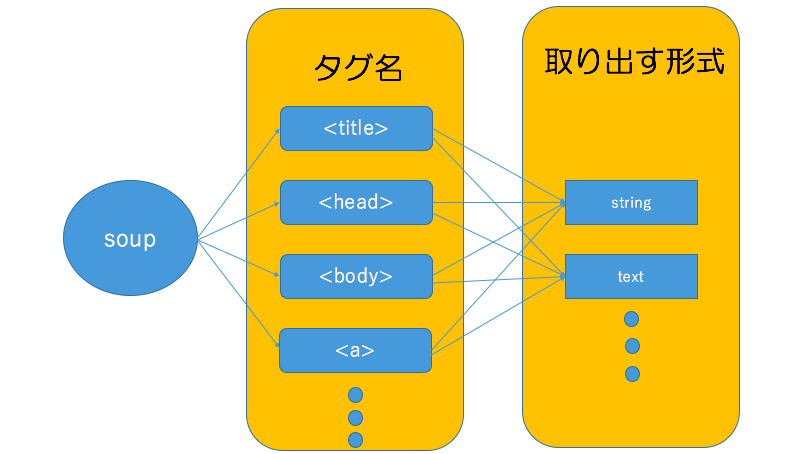
このプログラムを順を追って解説していきましょう。
soup変数の中からtitleというタグを探し、titleタグ内の文字列をstring形式で出力するという感じです。
ここはちょっとプログラム的に理解しにくいので直感的に理解した方がいいかもしれません。
このままでは理解しにくいので以下のような感じでイメージしていただければ幸いです。
さらに詳しい形式などはここで紹介すると時間が足りないので下記URLをご参考にしてください。
このプログラムを実行することによって以下の結果が出れば成功です。
neet-AI
リンク先をスクレイピング
まずはじめに、HTMLでリンクを表すには<a></a>タグが使われます。
この場合は、aタグ内のURLを取得したいので、string形式は使えません。
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com')
soup = BeautifulSoup(response.text,'lxml')
link = soup.a.get('href')
print(link)
get()という関数を使うことによってリンクが貼ってあるhrefを取得することができます。
get()関数はこの先頻繁に使う上に、便利なのでぜひ覚えておきましょう。
複数のリンク先をスクレイピング
これまで参照していたページはaタグが1つのみでした。
ではaタグが複数あるページではどうスクレイピングすればよいのでしょう?
まずはじめにaタグが複数あるページで以前のプログラムを実行してみましょう。
ページを取得する行のURLを変えましょう。
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com/index2.html')
soup = BeautifulSoup(response.text,'lxml')
link = soup.a.get('href')
print(link)
実行してみると、neet-AIのリンクしか表示されませんね。
これは、soup.a.get('href')で最初に見つかったaタグしか抽出していないからです。
全てのaタグを抽出したい場合には以下のようになります。
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com/index2.html')
soup = BeautifulSoup(response.text,'lxml')
links = soup.findAll('a')
for link in links:
print(link.get('href'))
各行を解説していきましょう。
links = soup.findAll('a')
ここで全てのaタグを抽出し、一度linksというリストに入れています。
for link in links:
print(link.get('href'))
リスト型なので、forで回してあげると1個ずつ操作が可能になります。
操作が可能になったlink変数にget()関数を使ってあげることによって各URLを取得することができます。
この一度全てのタグを取得し、操作できるようにforで回す手法も今後よく使うので覚えておきましょう。
idまたはclassを指定したスクレイピング
これまでは、タグにidやclassは記載されていませんでした。
しかし、一般的なサイトではWebデザインをしやすいようにまたはプログラムの可読性を高めるためにタグにidやclassを設定します。
idやclassが設定されたからといって、スクレイピングが格段と難しくなるわけではありません。
逆に「この内容だけをスクレイピングしたい!」と言った場面で楽になるかもしれません。
<html>
<head>
<title>neet-AI</title>
</head>
<body>
<div id="main">
<a id="neet-ai" href="https://neet-ai.com">neet-AI</a>
<a id="twitter" href="https://twitter.com/neetAI_official">Twitter</a>
<a id="facebook" href="https://www.facebook.com/Neet-AI-1116273381774200/">Facebook</a>
</div>
</body>
</html>
例えば上記のようなサイトがあるとします。
aのタグをみてもらえればわかりますが、全てにidが付与されています。
この時にtwitterのURLを取得したいといった場合にはこう記述することができます。
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com/index5.html')
soup = BeautifulSoup(response.text,'lxml')
twitter = soup.find('a',id='twitter').get('href')
print(twitter)
findの2番目にid名を指定してやると簡単に取ることができます。
次はclassにしてみます。
<html>
<head>
<title>neet-AI</title>
</head>
<body>
<div id="main">
<a class="neet-ai" href="https://neet-ai.com">neet-AI</a>
<a class="twitter" href="https://twitter.com/neetAI_official">Twitter</a>
<a class="facebook" href="https://www.facebook.com/Neet-AI-1116273381774200/">Facebook</a>
</div>
</body>
</html>
import requests
from bs4 import BeautifulSoup
response = requests.get('http://test.neet-ai.com/index6.html')
soup = BeautifulSoup(response.text,'lxml')
twitter = soup.find('a',class_='twitter').get('href')
print(twitter)
ここで注意してほしいのは、**classではなく、class_**です。
pythonではあらかじめ予約語(言語仕様上特別な意味を持った語)としてclassが登録されているからです。
これを回避するために、BeautifulSoupライブラリ作成者はアンダーバーをつけたのでしょう。
Webスクレイピング応用
これまでのWebスクレイピング基礎は、こちらがWebスクレイピングをしやすいように設計したHTMLページです。
しかし、一般のWebサイトではスクレイピングするために設計はされていないので、とても複雑な構造になっている場合があります。
とても複雑になっているゆえにスクレイピング以外にもWebページの特性などのスクレイピング以外の知識が必要となってきます。
応用編では複雑なサイトもコツを掴めばある程度はスクレイピングできるようになるので、応用編でノウハウを培っていきましょう。
Webページの通信特性を使う
この手法はかなり重宝します。
niftyニュースを例に取って説明していきます。
例えばITカテゴリでページ送りできるページがあります。
実際に下の2番目を押してページ送りしてみましょう。
再びURLをみて見ると、
https://news.nifty.com/technology/2
となります。
それでは次に3ページ目に移動してみましょう。
3ページ目ではこのようなURLです。
https://news.nifty.com/technology/3
サーバサイドの開発をしたことがある方ならわかると思いますが大抵、ページ送りのページを作る際には
URL末尾やパラメータにページ数を入れて、ページを更新していきます。
この仕組みを利用すれば、URLの数字を入れ替えるだけでページ送りをすることができます。
試しに末尾を好きな数字に変えてみてください。その数字に飛べると思います。(限界はありますが)
それでは試しにプログラム上で1ページ目から10ページ目までの検索結果をスクレイピングするプログラムを作ってみましょう。
import requests
from bs4 import BeautifulSoup
for page in range(1,11):
r = requests.get("https://news.nifty.com/technology/"+str(page))
r.encoding = r.apparent_encoding
print(r.text)
このようになります。
検索結果や連番になっているURLをスクレイピングする際はこの手法が便利です。
Webスクレイピング実践
https://search.nifty.com/imagesearch/search?
今回はニフティ画像検索で検索した結果をスクレイピングして大量の画像をダウンロードしていきます。
この章では画像のダウンロードの仕方とYahoo画像検索からどうやって画像のURLを取得するか学んでいきます。
事前知識
画像スクレイピングをする前にまず画像のダウンロードの仕組みとしては画像の性質を知る必要があります。
みなさまは画像をテキストエディタなどで開いたことはありますでしょうか。
開いたことがある方はわかると思いますが、写真やデータなどは全て数字で構成されています。
その数字を画像ビューアなどが解析して画像に変換しているわけですね。
話がそれましたが、画像が数字で構成されているならその数字を全てコピーできれば写真をダウンロードすることは可能になります。
詳しいプログラムに関しては画像ダウンロード編で説明いたします。
大雑把なプログラムの流れとしては
①あるキーワードで取得した検索結果画面をスクレイピングし画像URLを取得する。
②画像URL先に画像のデータ(文字)があるのでそれをコピーする。
③コピーしたデータを自分のコンピュータに貼り付ける。
になります。
画像URLスクレイピング編
事前準備でも説明したとおり画像をダウンロードするにはまず画像のURLが必要です。
まず始めにニフティ画像検索で「猫」と検索し、検索結果画面を見てみましょう。
URLをみてみると、「q=猫」というのがありますね。「q=」が検索するキーワードのパラメータです。
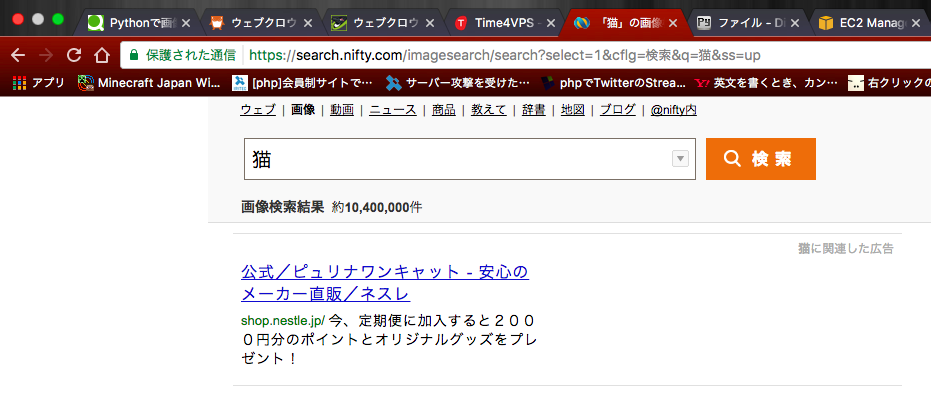
検索結果ページでは20枚の写真が出て来ますね。
今回はこの20枚の画像URLをとってみましょう。
ソースコードをみてみましょう。
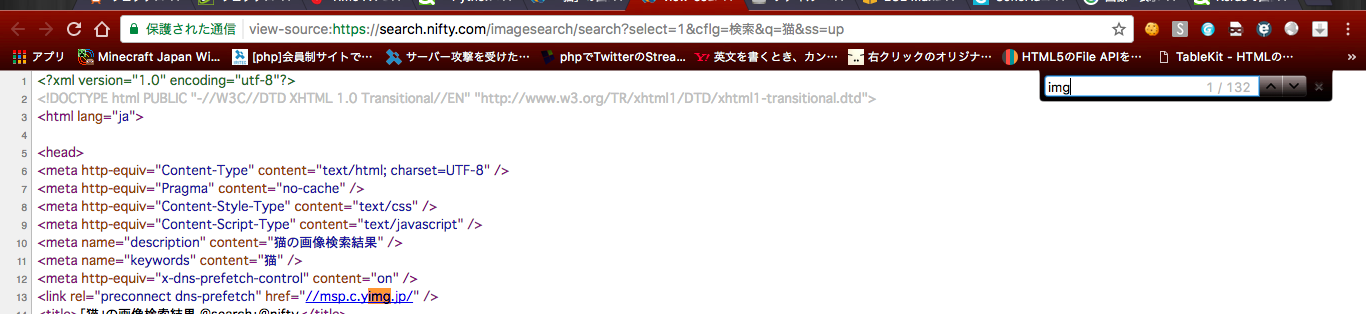
写真はimgタグで貼り付けられているのでimgと検索してみると、約140件ヒットします。
140件中20件は私たちが求めている画像URLです。
該当する20件以外排除するにはどんどん条件を追加していきます。
img srcで検索してみましょう。
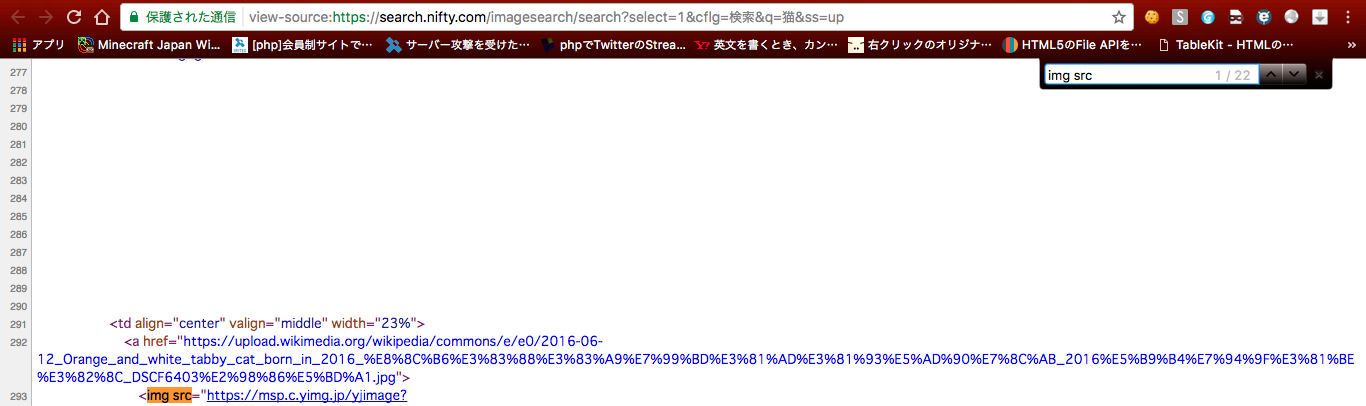
これだけで結構近づきましたね。しかしまだ邪魔な要素が残っています。
ここで一旦該当する20件の画像URL(src)をみてみましょう。
お分かりの通り「https://msp.c.yimg.jp/」というURLから全て始まっていますね。
それでは「https://msp.c.yimg.jp/」で検索してみましょう。
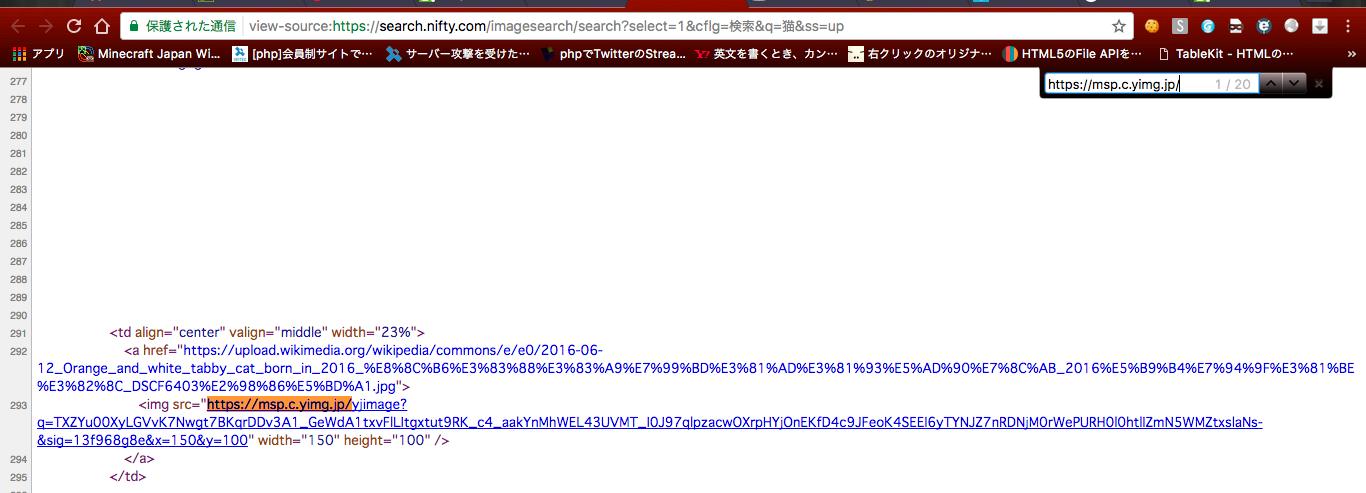
ピッタリ20件ですね!
該当する20件を絞ることができたのでこれを参考にプログラムを作成していきます。
import requests
import re
from bs4 import BeautifulSoup
url = "https://search.nifty.com/imagesearch/search?select=1&q=%s&ss=up"
keyword = "猫"
r = requests.get(url%(keyword))
soup = BeautifulSoup(r.text,'lxml')
imgs = soup.find_all('img',src=re.compile('^https://msp.c.yimg.jp/yjimage'))
for img in imgs:
print(img['src'])
このプログラムの肝となるのは
imgs = soup.find_all('img',src=re.compile('^https://msp.c.yimg.jp/yjimage'))
です。
find_allの第2引数では正規表現のオブジェクトを渡すこともできます。
ここでは先頭が「https://msp.c.yimg.jp/yjimage」で始まるsrcを探しています。
画像ダウンロード編
画像をダウンロードする際にはページ先画像のデータ(文字)をコピーします。
まず、ページ先画像のデータを取得するにはrequests内の**.content**で取得できます。
次にコンピュータにファイルとして書き込むにはopen()と.writeで書き込むことができます。
これでプログラムを組んでみるとこんな感じになります。
import requests
import re
import uuid
from bs4 import BeautifulSoup
url = "https://search.nifty.com/imagesearch/search?select=1&q=%s&ss=up"
keyword = "猫"
r = requests.get(url%(keyword))
soup = BeautifulSoup(r.text,'lxml')
imgs = soup.find_all('img',src=re.compile('^https://msp.c.yimg.jp/yjimage'))
for img in imgs:
print(img['src'])
r = requests.get(img['src'])
with open(str('./picture/')+str(uuid.uuid4())+str('.jpeg'),'wb') as file:
file.write(r.content)
ファイルを生成(開く)ところでは、
with open(str('./picture/')+str(uuid.uuid4())+str('.jpeg'),'wb') as file:
世界で1つのIDを作ってくれるuuidというライブラリを作り、ファイル名が被らないようにしています。
ファイルを作り終わったところで、画像のデータを書き込んでいきます。
file.write(r.content)
総集編
これまでの知識を活かし、1キーワードごとに100枚の画像をスクレイピングしていきます。
ニフティの画像検索では検索結果画面1ページにつき20枚の写真が取れます。
なので、5ページ分取得してあげましょう。
しかしニフティ画像検索ではどのようにしてページ移動をするのでしょうか。
ニフティニュースではページの末尾の数字を変えればいいのですが、ページ移動をしてみると、ニフティ画像検索の場合は「start=」の数値を変えると移動できます。
もう1ページ移動してみましょう。次は40になりましたね。20ごと数値を変えてやればページ移動が可能になることがわかりました。
これらの情報を元にプログラムを作成していきましょう。
サンプルプログラム
import requests
import re
import uuid
from bs4 import BeautifulSoup
url = "https://search.nifty.com/imagesearch/search?select=1&chartype=&q=%s&xargs=2&img.fmt=all&img.imtype=color&img.filteradult=no&img.type=all&img.dimensions=large&start=%s&num=20"
keyword = "猫"
pages = [1,20,40,60,80,100]
for p in pages:
r = requests.get(url%(keyword,p))
soup = BeautifulSoup(r.text,'lxml')
imgs = soup.find_all('img',src=re.compile('^https://msp.c.yimg.jp/yjimage'))
for img in imgs:
r = requests.get(img['src'])
with open(str('./picture/')+str(uuid.uuid4())+str('.jpeg'),'wb') as file:
file.write(r.content)