はじめに
予備校のノリで学ぶ「数学・物理」で機械学習をテーマにしている授業動画を拝見したことをきっかけに、AIに興味を持ち、2021年11月1日からAidemyで機械学習について学び始めました。(受講期間:2021年11月1日〜2022年5月1日)
Pythonの基礎から機械学習の基礎までみっちり学ぶことができ、とても充実した半年になりました。受講終了後は、かめ@米国🇺🇸データサイエンティスト/コミュニティ"DataScienceHub"を活用し、さらなるスキルアップに努めていきます。
最終成果物として、顔識別アプリを作成しましたので改善点やアドバイスなどがありましたら、ご指摘よろしくお願い致します。
なぜ顔識別アプリを作ったの?
日向坂46ファンの友人に機械学習の魅力について話をしたら、「メンバーの顔を判別してみてよ!」と言われたことがきっかけでした。アプリの性能としてはまだまだ実用性が低いですが、少しでも初学者の方の参考になれば幸いです。
実行環境
ニューラルネットワークのユニット数などにもよりますが、GPU(graphic processing unit)を使用するとCPU(central processing unit)だけで計算するより数倍から数十倍早く深層学習の訓練ができます。画像データを扱う際は、CPUだけで計算をすると膨大な時間を要することから画像の加工や描画の処理を得意とするGPUを使用することで計算時間を短くできるため、計算を行う際は、環境構築不要でGPUを無料で扱うことができるgoogle colaboratoryを使用しました。それ以外は、ローカル環境でVisual Studio Codeを用いて、実装しています。
opencv-python-headless==4.5.5.64
flask==2.0.1
numpy==1.18.0
tensorflow-cpu==2.3.0
Werkzeug==2.0.0
ディレクトリ構造図
aidemy/
├─ data(スクレイピングした画像をメンバー毎に保存)
├─ face_cut(顔検出&トリミングした画像をメンバー毎に保存)
├─ face_cut_rename(face_cut内の不要な画像を削除後、連番に修正)
├─ face_cut_inflated(face_cut_rename内の画像を水増し後、保存)
├─ templates(index.htmlファイルを格納)
├─ static(stylesheet.cssを格納)
├─ uploads(flaskで入力した画像を保存)
├─ haarcascade_frontalface_default.xml (顔検出の学習済モデル)
├─ model.h5 (学習済モデル)
目次
1.スクレイピング
2.顔検出&トリミング
3.画像の水増し
4.データセットの作成&データの分割
5.モデルの学習
6.画像の識別確認
7.Flaskでwebアプリケーション開発
8.考察
9.今後の課題
10.参考文献
1. スクレイピング
コチラの記事を参考にicrawlerを用いて、日向坂46全メンバー画像500枚のスクレイピングを実施。(dataに格納)
目的と違った画像が保存されている可能性もありますので、注意する必要があります。
また、icrawlerを用いて画像を取得する場合、ファイル名が[000001.jpg, 000002.jpg, ・・・000010.jpg]となります。以後、扱いやすくするためにファイル名を[1.jpg, 2.jpg, ・・・10.jpg]に変更しておきます。
import os
import glob
from icrawler.builtin import BingImageCrawler
#メンバーの名前をリスト形式でまとめる
members = ['潮紗理菜', '影山優佳', '加藤史帆', '齋藤京子', '佐々木久美', '佐々木美玲', '高瀬愛奈', '高本彩花',
'東村芽依', '金村美玖', '河田陽菜', '小坂菜緒', '富田鈴花', '丹生明里', '濱岸ひより', '松田好花', '宮田愛萌',
'渡邉美穂', '上村ひなの', '高橋未来虹', '森本茉莉', '山口陽世']
dir = './data/'
for member in members:
#指定のディレクトリを作成(画像の保存場所)
crawler = BingImageCrawler(storage={"root_dir": dir + member})
# 検索内容と枚数の指定
crawler.crawl(keyword=member, max_num=500)
#ディレクトリ内の画像ファイルを取得
files = glob.glob(dir + member + '/' + '*')
for i, file in enumerate(files):
#ファイル名の変更
os.rename(file, dir + member + '/' + str(i+1) + '.jpg')
スクレイピング結果
2. 顔検出&トリミング
コチラの記事を参考に顔検出を実施。
1ヶ所以上検出(顔以外を検出する可能性もあり)できた画像のみを検出部分でトリミングし、保存。(face_cutに格納)
※顔以外を検出した画像は削除しておく必要があります。
特にトリミングを行わなくても識別は可能かと思いますが、今回は顔に特化して学習・識別という目的からトリミングを行い、精度向上に努めました。
import os
import glob
import cv2
# 顔検出の学習済モデルを取得
cascade_path = os.path.join(os.path.dirname(__file__), './haarcascade_frontalface_default.xml')
# メンバーの名前をリスト形式でまとめる
members = ['潮紗理菜', '影山優佳', '加藤史帆', '齋藤京子', '佐々木久美', '佐々木美玲', '高瀬愛奈', '高本彩花',
'東村芽依', '金村美玖', '河田陽菜', '小坂菜緒', '富田鈴花', '丹生明里', '濱岸ひより', '松田好花', '宮田愛萌',
'渡邉美穂', '上村ひなの', '高橋未来虹', '森本茉莉', '山口陽世']
dir1 = './data/'
dir2 = './face_cut/'
# 画像の読み込み
for member in members:
files = glob.glob(dir1 + member + '/' + '*')
for j, file in enumerate(files):
img = cv2.imread(file)
# 顔検出
cascade = cv2.CascadeClassifier(cascade_path)
facerect = cascade.detectMultiScale(img, scaleFactor=1.143, minNeighbors=3, minSize=(246, 246))
if len(facerect) > 0:
# 検出した顔の領域範囲をトリミング
for x, y, w, h in facerect:
face_cut = img[y:y+h, x:x+w]
# 画像を保存するフォルダを作成
if not os.path.exists(dir2 + member):
os.mkdir(dir2 + member)
# 保存先のディレクトリを指定、番号を付けて保存
cv2.imwrite(dir2 + member + '/' + str(j+1) + '.jpg', face_cut)
print(dir2 + member + '/' + str(j+1) + '.jpg: ' + '検出されました')
# 画像を1秒間表示
cv2.imshow('sample', face_cut)
cv2.waitKey(1000)
else:
print(dir2 + member + '/' + str(j+1) + '.jpg' + '検出されませんでした')
continue
画像を削除したため、ファイル名の番号がとびとびになってしまいました。
ファイル名が連番になるように変更しておきます。(face_cut_renameに格納)
import os
import glob
#メンバーの名前をリスト形式でまとめる
members = ['潮紗理菜', '影山優佳', '加藤史帆', '齋藤京子', '佐々木久美', '佐々木美玲', '高瀬愛奈', '高本彩花',
'東村芽依', '金村美玖', '河田陽菜', '小坂菜緒', '富田鈴花', '丹生明里', '濱岸ひより', '松田好花', '宮田愛萌',
'渡邉美穂', '上村ひなの', '高橋未来虹', '森本茉莉', '山口陽世']
dir = './face_cut_rename/'
for member in members:
files = glob.glob(dir + member + '/' + '*')
for i, file in enumerate(files):
# 画像を保存するフォルダーを作成
if not os.path.exists(dir + member):
os.mkdir(dir + member)
# ファイル名の変更
os.rename(file, dir + member + '/' + str(i+1) + '.jpg')
顔検出&トリミング処理の結果
メンバーそれぞれのデータの枚数は、以下のようになっています。
潮紗理菜 ⇨ 100枚, 影山優佳 ⇨ 94枚, 加藤史帆 ⇨ 100枚, 齋藤京子 ⇨ 100枚, 佐々木久美 ⇨ 100枚, 佐々木美玲 ⇨ 100枚, 高瀬愛奈 ⇨ 100枚
高本彩花 ⇨ 100枚, 東村芽依 ⇨ 100枚, 金村美玖 ⇨ 100枚, 河田陽菜 ⇨ 100枚, 小坂菜緒 ⇨ 100枚, 富田鈴花 ⇨ 100枚, 丹生明里 ⇨ 100枚
濱岸ひより ⇨ 96枚, 松田好花 ⇨ 100枚, 宮田愛萌 ⇨ 100枚, 渡邉美穂 ⇨ 100枚, 上村ひなの ⇨ 100枚, 高橋未来虹 ⇨ 90枚, 森本茉莉 ⇨ 95枚
山口陽世 ⇨ 96枚
3. 画像の水増し
『2. 顔検出&トリミング』で取得した画像のみでは、データ数が少ないため、以下の手法で水増し作業を実施。(face_cut_inflatedに格納)
・反転
・閾値処理(二値化)
・ぼかし(平滑化)
・モザイク処理
・収縮
上記5つの手法を組み合わせることによって、1枚の画像を$2^5=32枚$まで増やすことが可能です。他にも、回転や膨張など様々な手法がありますが、今回は上記5つの手法を採用しました。
import os
import glob
import numpy as np
import cv2
# メンバーの名前をリスト形式でまとめる
members = ['潮紗理菜', '影山優佳', '加藤史帆', '齋藤京子', '佐々木久美', '佐々木美玲', '高瀬愛奈', '高本彩花',
'東村芽依', '金村美玖', '河田陽菜', '小坂菜緒', '富田鈴花', '丹生明里', '濱岸ひより', '松田好花', '宮田愛萌',
'渡邉美穂', '上村ひなの', '高橋未来虹', '森本茉莉', '山口陽世']
dir1 = './face_cut_rename/'
dir2 = './face_cut_inflated/'
def inflated_image(img, flip=True, thr=True, filt=True, resize=True, erode=True):
# 水増しの手法を配列にまとめる
methods = [flip, thr, filt, resize, erode]
img_size = img.shape
mat = cv2.getRotationMatrix2D(tuple(np.array([img_size[1], img_size[0]]) / 2 ), 45, 1.0)
filter1 = np.ones((3, 3))
# オリジナルの画像データを配列に格納
images = [img]
scratch = np.array([
# 左右反転
lambda x: cv2.flip(x, 1),
# 閾値処理
lambda x: cv2.threshold(x, 100, 255, cv2.THRESH_TOZERO)[1],
# ぼかし
lambda x: cv2.GaussianBlur(x, (5, 5), 0),
# モザイク処理
lambda x: cv2.resize(cv2.resize(x, (img_size[1]//6, img_size[0]//6)), (img_size[1], img_size[0])),
#収縮
lambda x: cv2.erode(x, filter1)
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
# doubling_imagesを用いてmethodsがTrueの関数で水増し
for func in scratch[methods]:
images = doubling_images(func, images)
return images
# 画像の読み込み
for i, member in enumerate(members):
files = glob.glob(dir1 + member + '/' + '*')
for j, file in enumerate(files):
img = cv2.imread(file)
# 画像の水増し
inflated_images = inflated_image(img)
# 画像を保存するディレクトリを作成
if not os.path.exists(dir2 + member):
os.mkdir(dir2 + member)
# 保存先のディレクトリを指定、番号を付けて保存
for k, im in enumerate(inflated_images):
cv2.imwrite('./' + dir2 + member + '/' + str((len(inflated_images) * j) + (k+1)) + '.jpg', im)
1枚の画像につき、32枚ずつ生成されていることが確認できます。
水増し手法が適用されていることが少し分かりにくいですが、問題なく適用されています。

メンバーそれぞれの水増し後のデータの枚数は、以下のようになっています。
潮紗理菜 ⇨ 3200枚, 影山優佳 ⇨ 3008枚, 加藤史帆 ⇨ 3200枚, 齋藤京子 ⇨ 3200枚, 佐々木久美 ⇨ 3200枚, 佐々木美玲 ⇨ 3200枚
高瀬愛奈 ⇨ 3200枚, 高本彩花 ⇨ 3200枚, 東村芽依 ⇨ 3200枚, 金村美玖 ⇨ 3200枚, 河田陽菜 ⇨ 3200枚, 小坂菜緒 ⇨ 3200枚
富田鈴花 ⇨ 3200枚, 丹生明里 ⇨ 3200枚, 濱岸ひより ⇨ 3072枚, 松田好花 ⇨ 3200枚, 宮田愛萌 ⇨ 3200枚, 渡邉美穂 ⇨ 3200枚
上村ひなの ⇨ 3200枚, 高橋未来虹 ⇨ 2880枚, 森本茉莉 ⇨ 3040枚, 山口陽世 ⇨ 3072枚
4. データセットの作成&データの分割
画像データにラベルが対応するように振り分け、データの分割を行います。
ホールドアウト法では、データの分割方法によって偶然分布の偏りが生まれてしまい正確な評価を行えない可能性があります。
ここでは、訓練データとテストデータのラベルを均等にするため、StratifiedKFoldを用います。
import os
import cv2
import numpy as np
from sklearn.model_selection import StratifiedKFold
from tensorflow.keras.utils import to_categorical
# メンバーの名前をリスト形式でまとめる
members = ['潮紗理菜', '影山優佳', '加藤史帆', '齋藤京子', '佐々木久美', '佐々木美玲', '高瀬愛奈', '高本彩花',
'東村芽依', '金村美玖', '河田陽菜', '小坂菜緒', '富田鈴花', '丹生明里', '濱岸ひより', '松田好花', '宮田愛萌',
'渡邉美穂', '上村ひなの', '高橋未来虹', '森本茉莉', '山口陽世']
dir = '~/face_cut_inflated'
images = []
labels = []
number_of_members = len(members)
# 辞書にメンバーの名前とラベルを格納
members_label = {member_name: i for i, member_name in enumerate(members)}
for name in os.listdir(dir):
# メンバーラベルの取得
label = members_label[name]
# 画像の読み込み
for jpg in os.listdir(dir + '/' + name):
img = cv2.imread(dir + '/' + name + '/' + jpg)
# 画像のリサイズ
img = cv2.resize(img, (100, 100))
# 画像データとラベルの格納
images.append(img)
labels.append(label)
# numpy形式に変換
X = np.array(images)
y = np.array(labels)
# データの分割
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
for i, (trn_index, val_index) in enumerate(cv.split(X, y)):
X_train, X_test = X[trn_index], X[val_index]
y_train, y_test = y[trn_index], y[val_index]
# 正解ラベルをone-hot表現
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
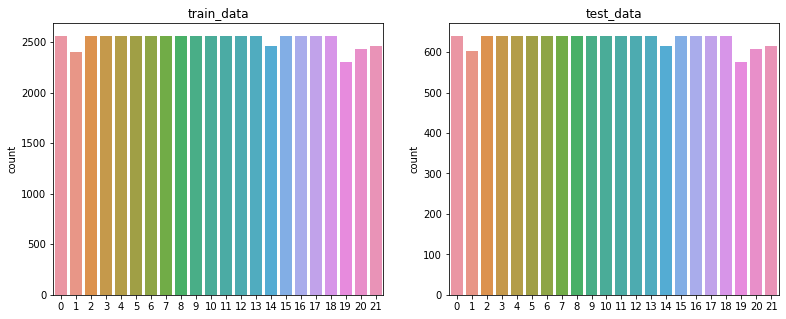
# 訓練データとテストデータのラベルの可視化
print('StratifiedKFold:', i)
fig = plt.figure(figsize=(13, 5))
ax = fig.add_subplot(1, 2, 1)
ax.set_title('train_data')
sns.countplot(y_trn, ax=ax)
ax = fig.add_subplot(1, 2, 2)
ax.set_title('test_data')
sns.countplot(y_val, ax=ax)
plt.show()
訓練データとテストデータのラベルの可視化を行い、均等になっていることを確認しておきます。
モデルの学習に入る前に、データの整合性のチェック処理を入れます。
from random import randint
import japanize_matplotlib
# ランダムに5×5枚の画像をプロット
f, ax = plt.subplots(5, 5)
f.subplots_adjust(0, 0, 3, 3)
for i in range(5):
for j in range(5):
rnd = randint(0, len(images))
ax[i, j].imshow(cv2.cvtColor(images[rnd], cv2.COLOR_BGR2RGB))
ax[i, j].set_title(list(members_label.keys())[labels[rnd]])
ax[i, j].axis('off')
ラベルと画像の整合性が取れていることが確認できます。

5. モデルの学習
深さ16層(畳み込み13層+全結合層3層)の畳み込みニューラルネットワークVGG16を用いて、モデルの学習。
過学習を防ぐため、EarlyStopping(テストデータに対する誤差関数の値が上昇傾向に転じたときに学習を打ち切る)を設定しておきます。
import matplotlib.pyplot as plt
from keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras import optimizers
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.callbacks import EarlyStopping
# モデルにvggを使用
input_tensor = Input(shape=(100, 100, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、22クラス分類する層を定義
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(1024, activation='relu'))
top_model.add(Dense(512, activation='relu'))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.4))
top_model.add(Dense(number_of_members, activation='softmax'))
# vggと、top_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg層の重みを変更不能に
for layer in model.layers[:19]:
layer.trainable = False
# コンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics='acc')
# early_stoppingの設定
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=2, mode='auto')
# 学習
history = model.fit(X_train, y_train, batch_size=32, epochs=30, validation_data=(X_test, y_test), callbacks=[early_stopping])
model.save('model.h5')
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
学習済モデル「model.h5」を保存。
Epoch 1/30
1737/1737 [==============================] - 57s 28ms/step - loss: 3.0474 - acc: 0.1252 - val_loss: 2.4446 - val_acc: 0.2844
Epoch 2/30
1737/1737 [==============================] - 49s 28ms/step - loss: 2.3328 - acc: 0.2987 - val_loss: 1.7579 - val_acc: 0.4881
Epoch 3/30
1737/1737 [==============================] - 49s 28ms/step - loss: 1.7980 - acc: 0.4554 - val_loss: 1.2506 - val_acc: 0.6482
Epoch 4/30
1737/1737 [==============================] - 49s 28ms/step - loss: 1.3884 - acc: 0.5737 - val_loss: 0.9136 - val_acc: 0.7326
Epoch 5/30
1737/1737 [==============================] - 49s 28ms/step - loss: 1.0648 - acc: 0.6674 - val_loss: 0.6853 - val_acc: 0.8047
Epoch 6/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.8349 - acc: 0.7375 - val_loss: 0.4944 - val_acc: 0.8609
Epoch 7/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.6523 - acc: 0.7927 - val_loss: 0.3692 - val_acc: 0.8946
Epoch 8/30
1737/1737 [==============================] - 47s 27ms/step - loss: 0.5126 - acc: 0.8362 - val_loss: 0.3012 - val_acc: 0.9206
Epoch 9/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.4137 - acc: 0.8663 - val_loss: 0.2409 - val_acc: 0.9354
Epoch 10/30
1737/1737 [==============================] - 47s 27ms/step - loss: 0.3295 - acc: 0.8951 - val_loss: 0.1615 - val_acc: 0.9562
Epoch 11/30
1737/1737 [==============================] - 47s 27ms/step - loss: 0.2670 - acc: 0.9157 - val_loss: 0.1334 - val_acc: 0.9645
Epoch 12/30
1737/1737 [==============================] - 47s 27ms/step - loss: 0.2283 - acc: 0.9275 - val_loss: 0.1056 - val_acc: 0.9723
Epoch 13/30
1737/1737 [==============================] - 48s 28ms/step - loss: 0.1886 - acc: 0.9389 - val_loss: 0.0885 - val_acc: 0.9768
Epoch 14/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.1592 - acc: 0.9506 - val_loss: 0.0798 - val_acc: 0.9794
Epoch 15/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.1359 - acc: 0.9578 - val_loss: 0.0668 - val_acc: 0.9822
Epoch 16/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.1175 - acc: 0.9632 - val_loss: 0.0573 - val_acc: 0.9850
Epoch 17/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.1034 - acc: 0.9686 - val_loss: 0.0500 - val_acc: 0.9874
Epoch 18/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.0936 - acc: 0.9716 - val_loss: 0.0439 - val_acc: 0.9892
Epoch 19/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.0844 - acc: 0.9740 - val_loss: 0.0364 - val_acc: 0.9904
Epoch 20/30
1737/1737 [==============================] - 48s 28ms/step - loss: 0.0733 - acc: 0.9770 - val_loss: 0.0294 - val_acc: 0.9924
Epoch 21/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.0671 - acc: 0.9793 - val_loss: 0.0313 - val_acc: 0.9914
Epoch 22/30
1737/1737 [==============================] - 49s 28ms/step - loss: 0.0605 - acc: 0.9822 - val_loss: 0.0289 - val_acc: 0.9927
Epoch 23/30
1737/1737 [==============================] - 48s 28ms/step - loss: 0.0513 - acc: 0.9841 - val_loss: 0.0296 - val_acc: 0.9912
Epoch 24/30
1737/1737 [==============================] - 46s 26ms/step - loss: 0.0510 - acc: 0.9844 - val_loss: 0.0259 - val_acc: 0.9926
Epoch 25/30
1737/1737 [==============================] - 46s 26ms/step - loss: 0.0462 - acc: 0.9864 - val_loss: 0.0210 - val_acc: 0.9941
Epoch 26/30
1737/1737 [==============================] - 48s 27ms/step - loss: 0.0418 - acc: 0.9877 - val_loss: 0.0210 - val_acc: 0.9946
Epoch 27/30
1737/1737 [==============================] - 48s 27ms/step - loss: 0.0425 - acc: 0.9873 - val_loss: 0.0203 - val_acc: 0.9947
Epoch 28/30
1737/1737 [==============================] - 48s 27ms/step - loss: 0.0355 - acc: 0.9893 - val_loss: 0.0198 - val_acc: 0.9942
Epoch 29/30
1737/1737 [==============================] - 46s 26ms/step - loss: 0.0337 - acc: 0.9908 - val_loss: 0.0141 - val_acc: 0.9963
Epoch 30/30
1737/1737 [==============================] - 46s 26ms/step - loss: 0.0322 - acc: 0.9909 - val_loss: 0.0188 - val_acc: 0.9944
435/435 [==============================] - 9s 21ms/step - loss: 0.0188 - acc: 0.9944
Test loss: 0.018776342272758484
Test accuracy: 0.9943860769271851
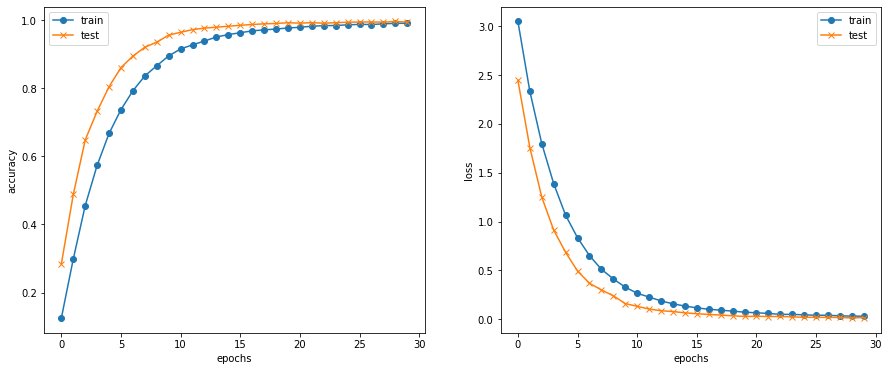
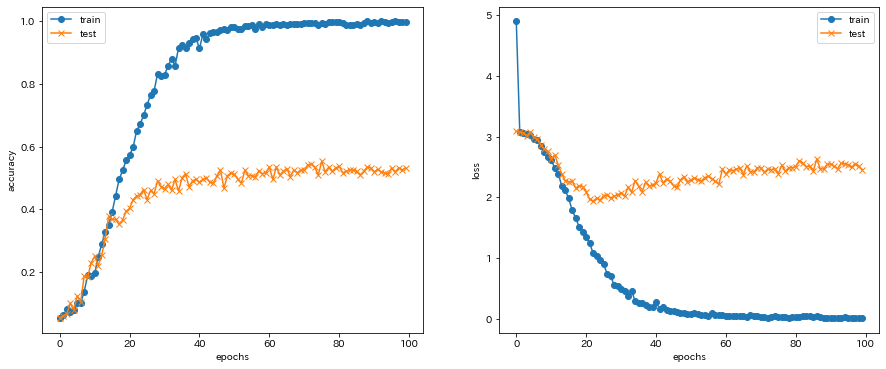
学習結果をプロットし、可視化します。
綺麗な曲線を描いてaccuracyが向上していることが分かります。
水増しする前のデータで学習した結果のプロット図も載せておきます。
水増し前の学習では、Epochを100に設定し、学習を行いました。
データの枚数も少ないことから、accuracyの向上は見られませんでした。
6. 画像の識別確認
テストデータから画像をランダムに抽出し、model.predictで予測した結果が正しいかどうかをチェックします。
# 画像を一枚受け取り、メンバーを判定する関数
def idol(img, name):
img = cv2.resize(img, (100, 100))
pred = np.argmax(model.predict(np.array([img])))
if pred == members_label[name]:
return name
else:
return list(members_label.keys())[pred]
# ランダムに5×5枚の画像をプロット
f, ax = plt.subplots(5, 5)
f.subplots_adjust(0, 0, 3, 3)
for i in range(5):
for j in range(5):
rnd = randint(0, len(X_test))
ax[i, j].imshow(cv2.cvtColor(X_test[rnd], cv2.COLOR_BGR2RGB))
ax[i, j].set_title(idol(X_test[rnd], list(members_label.keys())[y_val[rnd]]))
ax[i, j].axis('off')
ランダムに表示したテストデータ25枚を完璧に予測しました。

7. Flaskでwebアプリケーション開発
Pythonのための軽量なウェブアプリケーションフレームワークであるFlaskを使用しました。
import os
from flask import Flask, request, redirect, render_template, flash, send_from_directory
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
import cv2
# メンバーの名前をリスト形式でまとめる
members = ['潮紗理菜', '影山優佳', '加藤史帆', '齋藤京子', '佐々木久美', '佐々木美玲', '高瀬愛奈', '高本彩花',
'東村芽依', '金村美玖', '河田陽菜', '小坂菜緒', '富田鈴花', '丹生明里', '濱岸ひより', '松田好花', '宮田愛萌',
'渡邉美穂', '上村ひなの', '高橋未来虹', '森本茉莉', '山口陽世']
image_size = 100
# 顔検出の学習済モデルを取得
cascade_path = os.path.join(os.path.dirname(__file__), "haarcascade_frontalface_default.xml")
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
app.secret_key = b'_5#y2L"F4Q8z\n\xec]/'
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
#学習済みモデルをロード
model = load_model('./model.h5')
@app.route("/uploads/<path:name>")
def download_file(name):
return send_from_directory("./uploads", name)
def face_trimming(img):
# 顔検出
cascade = cv2.CascadeClassifier(cascade_path)
facerect = cascade.detectMultiScale(img, scaleFactor=1.143, minNeighbors=3, minSize=(246, 246))
if len(facerect) == 1:
# 検出した顔の領域範囲をトリミング
for x, y, w, h in facerect:
face_cut = img[y: y+h, x: x+w]
return face_cut
elif len(facerect) >= 2:
return '1人だけの画像を入力してください'
else:
return '顔が検出されませんでした'
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
render_template('index.html', answer='ファイルがありません', img='')
file = request.files['file']
if file.filename == '':
render_template('index.html', answer='ファイルがありません', img='')
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = cv2.imread(filepath)
img = face_trimming(img)
if type(img) is str:
pred_answer = img
return render_template('index.html', answer=pred_answer, img=filepath)
img = cv2.resize(img, (image_size, image_size))
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
predicted_value = result[predicted]
# 予測値が50%未満の場合、「メンバーではない」と判定
if predicted_value > 0.5:
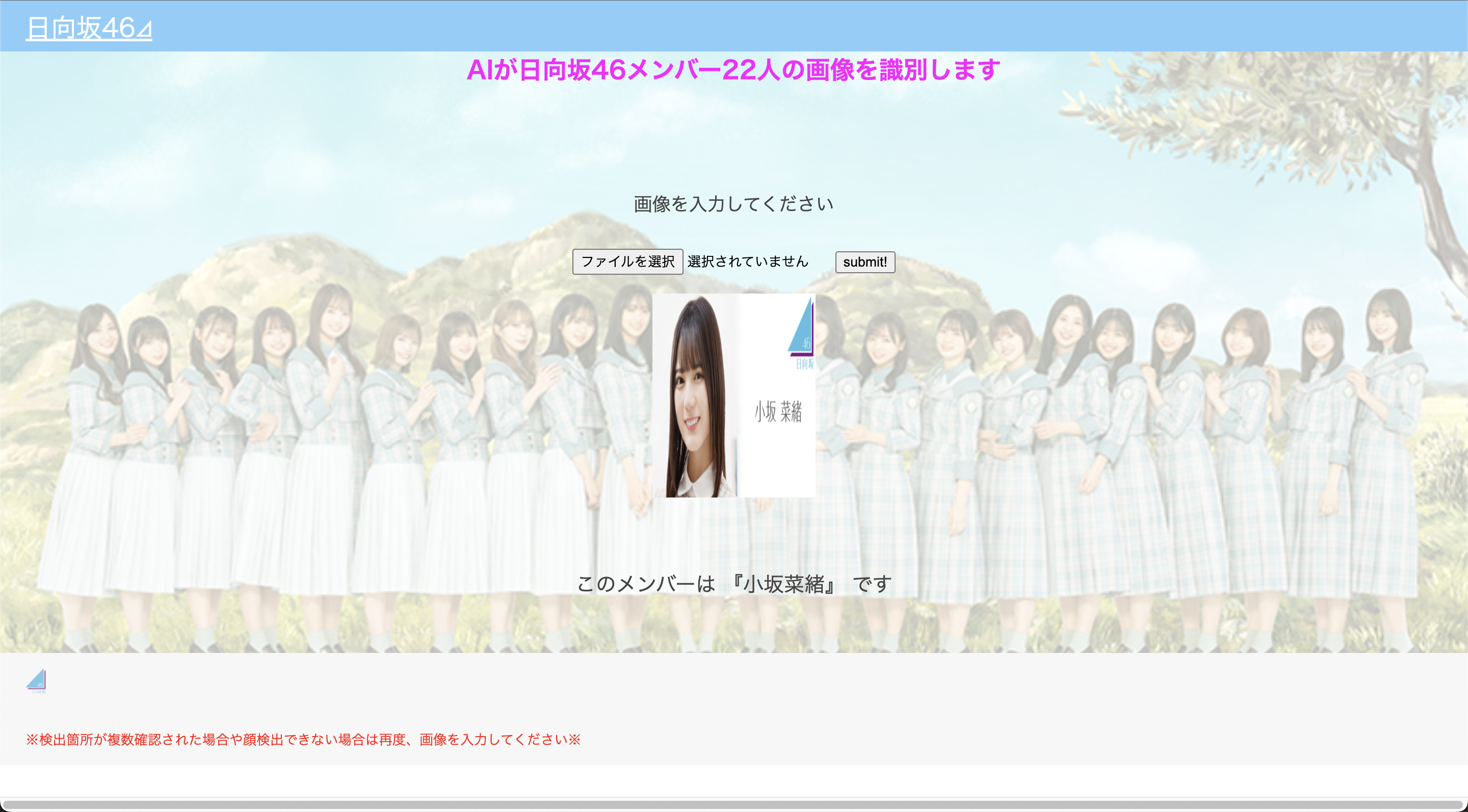
pred_answer = 'このメンバーは ' + '『' + members[predicted] + '』' + ' です'
return render_template('index.html', answer=pred_answer, img=filepath)
else:
return render_template('index.html', answer='日向坂46のメンバーではありません', img=filepath)
return render_template('index.html', answer='', img='')
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host='0.0.0.0', port=port)
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>日向坂46⊿</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="">
<a class="header-logo" href="#">日向坂46⊿</a>
</header>
<div class="main">
<div class="mask">
<h2>AIが日向坂46メンバー22人の画像を識別します</h2>
<p>画像を入力してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
{% if img %}
<div class="image-block">
<h3><img class="img" src="{{ img }}" alt="image"></h3>
</div>
{% endif %}
<div class="answer">{{answer}}</div>
</div>
</div>
<footer>
<img class="footer_img" src="https://upload.wikimedia.org/wikipedia/commons/thumb/0/0b/Hinatazaka46_logo.svg/1200px-Hinatazaka46_logo.svg.png" alt="日向坂46">
<small><font color="red">※検出箇所が複数確認された場合や顔検出できない場合は再度、画像を入力してください※</font></small>
</footer>
</body>
</html>
header {
background-color: #87cefa;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #fff;
font-size: 25px;
margin: 8px 25px;
}
.main {
background-image: url('https://img.hmv.co.jp/hybridimage/news/images/22/0324/109/headline_L.jpeg');
background-repeat: no-repeat;
background-position: center;
height: 600px;
background-size: 100%;
margin: -10px;
}
.mask {
height: 100%;
background: rgba(255,255,255,0.7);
}
h2 {
color: #FF00FF;
margin: 0px 0px;
text-align: center;
}
p {
color: #444444;
font-size: 18px;
margin: 100px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
font-size: 20px;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}
.image-block {
height: 200px;
width: 160px;
display: block;
margin: auto;
}
.img {
height: 200px;
width: 160px;
}
〜使用方法〜
【ファイルを選択】をクッリクし、識別したいメンバーの画像を入力したら、【submit!】をクリック。
メンバーを識別することができました!!
8. 考察
今回は、転移学習(VGG16)を活用させていただきました。
水増し前と後で学習結果の比較を行い、水増し前では誤差関数lossが増加傾向にあることから過学習が起きていましたが、水増し後では誤差関数lossが減少し、過学習を引き起こすことなく、val_accを0.99まで向上させることができました。
しかし、アプリ上で何枚か未知の画像データを入力してみましたが、識別以前に顔検出できない画像が多かったため、再度パラメータの調整を図っていく必要があります。顔検出できた画像を識別する際にも、画像の人物とは異なった名前を出力していることが多々ありました。各クラスの画像にノイズになる様な画像(背景が違う画像が多いことや同じクラスでも化粧や髪型などのばらつきが大きいなど)が含まれていることが、原因の1つではないかと考えます。
9. 今後の課題
今後の課題として、複数のメンバーが写っている画像データから、それぞれメンバーの顔を同時に予測し、より精度の高いシステム開発に取り組んでいきます。