はじめに
PythonもOpenCVもこれまでまったく触れてこなかったけど、ちょっとやってみたいと思ってはじめたので、色々と試しているという状況です。
前回『(2017年12月) PythonとOpenCVをこれからやってみる - 4 - 座標設定 - Qiita』は読み取り座標を指定するツールを用意しました。
今回はいよいよ、読込み精度を上げるための根本的な部分として、言語データを作成する部分を行なっていきます。
言語データについて
最初にダウンロードしたjpn.traineddataは基本的なものということもあり、精度はそれ程高くないようです。
本格的に使っていくのであれば、カスタマイズして行く必要があるでしょう。
Tesseractのコンフィグファイルを調整する事でも、精度を上げられるようですが、今回は先に言語データを調整する事にします。
作るデータは、OCRの確認で利用した画像の中の文字の"Python"が"pwhon"となっていたので、試しに"Python"だけの言語データを作ってみます。
言語データを作成する
ざっくり調べていると何だか難しそうですが、簡単に出来るツールもあるようです。
その中でも今回は、jTessBoxEditorというのを使うことにしました。
jTessBoxEditor - Tesseract box editor & trainer
ダウンロード先に行くと、最新はベータ版のようですが「jTessBoxEditorFX-2.0-Beta.zip」をダウンロードして解凍して実行します。(javaが無ければダウンロードしてパスを通すなりしておきます)
>java -Xms128m -Xmx1024m -jar jTessBoxEditorFx.jar
[TIFF/Box Generator]のタブをクリックし、画面も広げます。
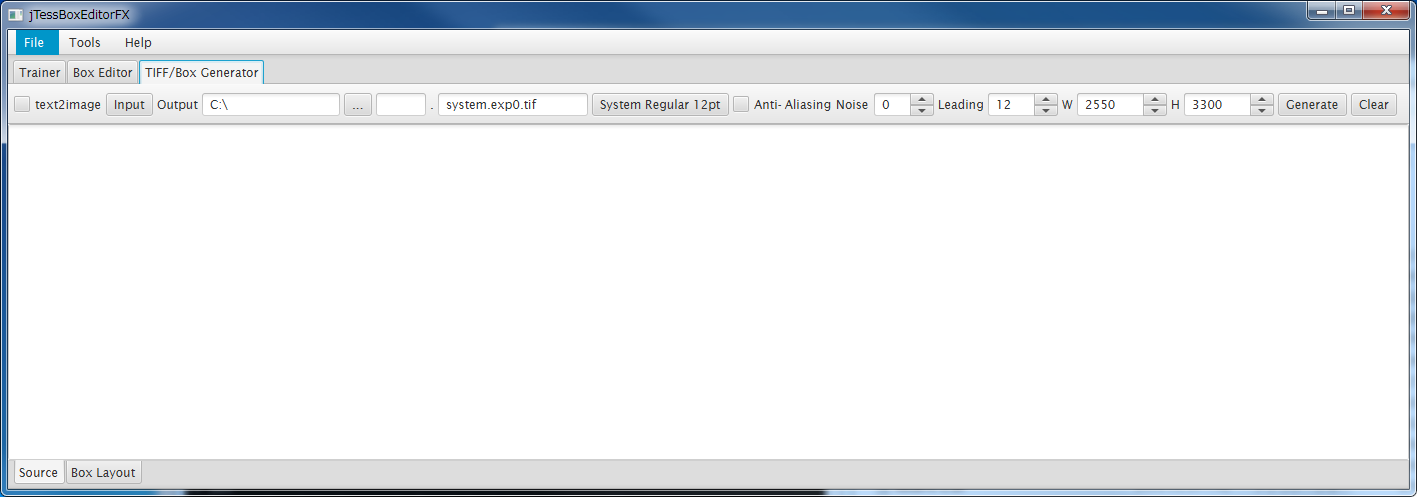
・[text2image]チェックボタン
まだよくわかっていません。今回は使いません。
・[Input]ボタン
作成するデータの文字列を設定したテキストファイルを取り込むことが出来るようです。
今回は直接入力してしまいますので使用しません。
・[Output]テキストボックス、[...]ボタン
ファイルの生成先の場所を指定します。
・[...]の次のテキストボックス
"jpn"など、言語データの最初の3文字の部分を指定する。
その後にフォント名を指定するので、被っていても大丈夫だとは思いますが、今回は"jp2"としてみます。
・その後のテキストボックスとボタン
フォント名の指定と、フォントの指定。
ボタンの方を押せば、フォントの選択のダイアログが表示されます。
フォント名もそれに合わせて変わりますが、書きかえても大丈夫です。
(最後の拡張子部分の".tif"はそのままに)
・anti-aliasing(アンチエイリアス)
境界を滑らかにする指定と思われますが、とりあえず今回は使用しません。
・その後の色々
よくわかっていません。今回はさわりません。
・[Generate]ボタン
必要な入力が終わったらボタンを押す事で、tifファイルとboxファイルが生成されます。
tifファイルは文字のイメージ、boxは各文字の座標と対応付ける文字を定義したファイルのようです。
・[Clear]ボタン
入力内容などをクリアします。
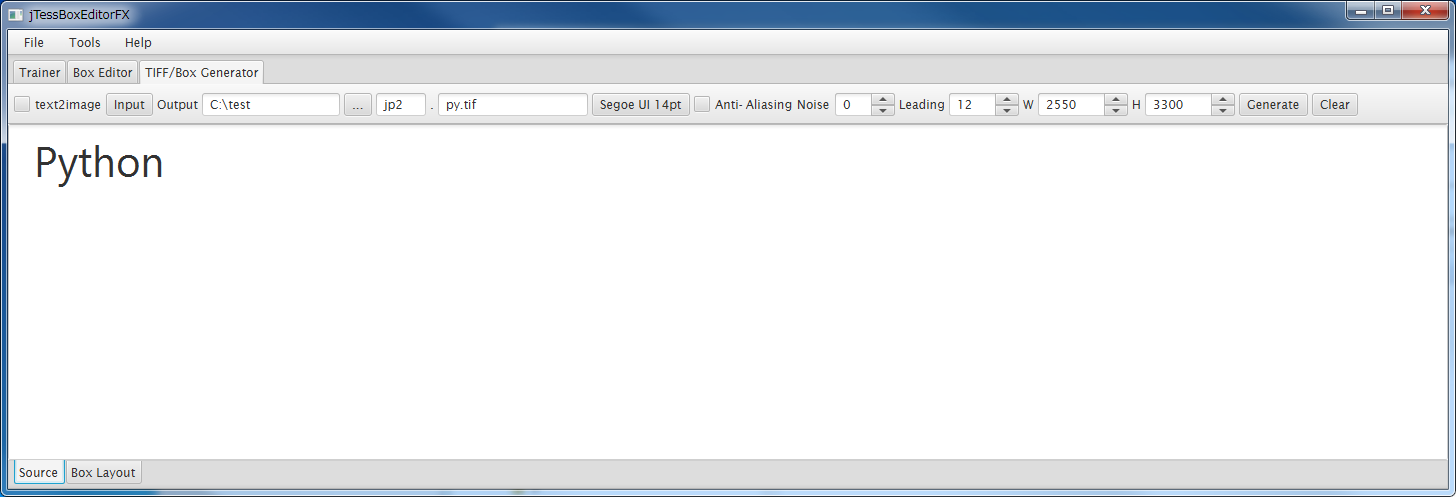
では、次のように設定します。
フォントはChromeのDevToolsで確認したところ"-apple-system,BlinkMacSystemFont,Segoe UI,Helvetica Neue,Hiragino Kaku Gothic ProN,"メイリオ",meiryo,sans-serif;"となっていました。この内実施環境では"Segoe UI"があり、表示してみたところそれっぽいのでこのフォントを指定します。サイズは14pxです。
"Python"と入力します。
画面下部の[Box Layout]をクリックすると次のように表示されています。
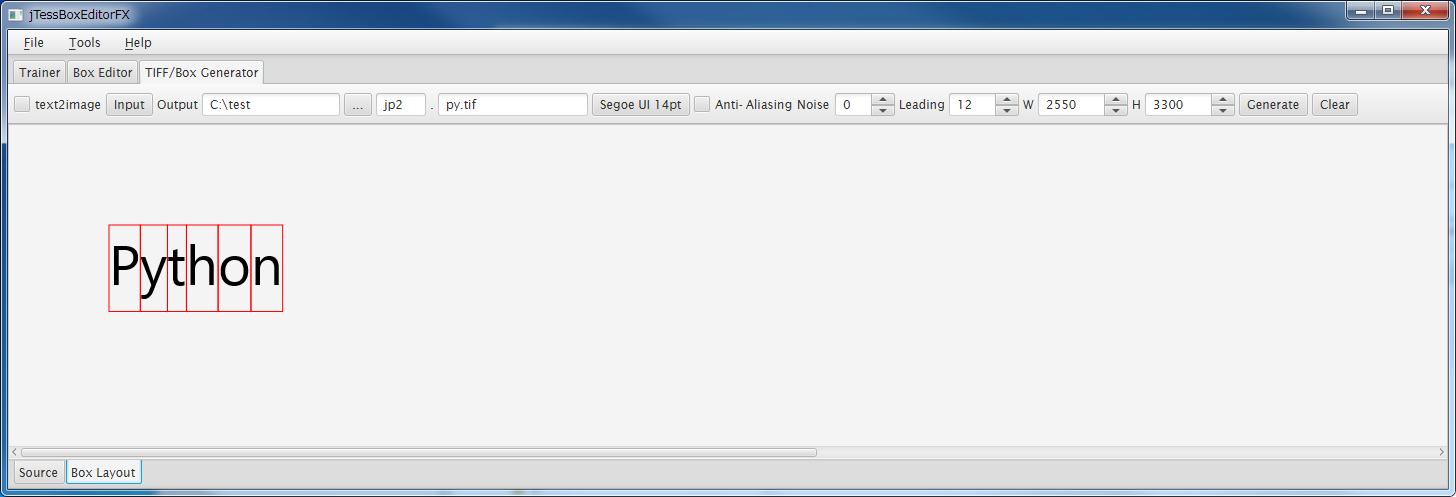
問題なさそうなので、[Generate]ボタンをクリックします。
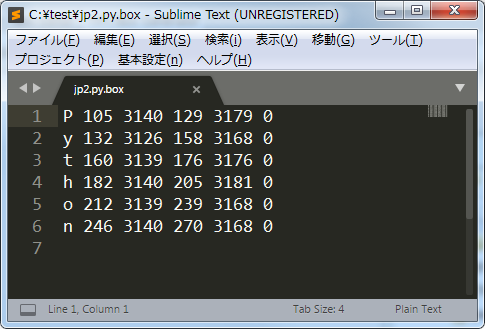
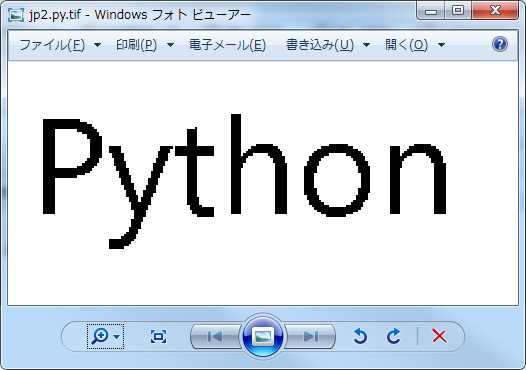
指定した出力先に次のファイルが出力されました。
jp2.py.box
jp2.py.tif
それぞれ普通にファイルを見てみると次のようになっています。
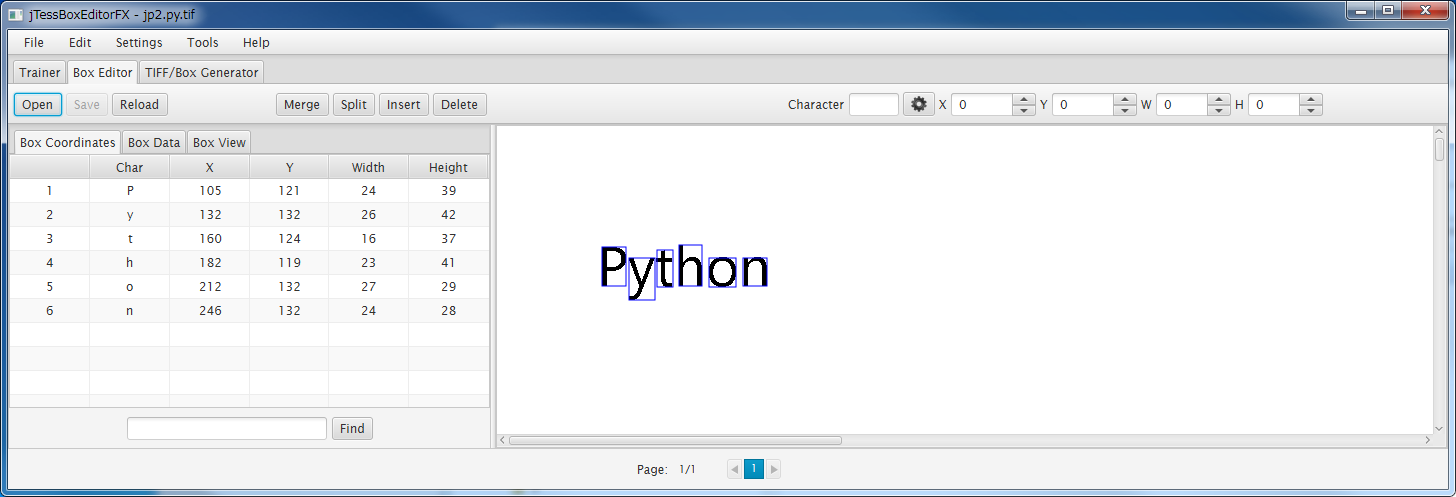
jTessBoxEditorFXにて[Box Editor]をクリックし、[Open]をクリックして、"jp2.py.box"を開いてみると次のように表示されます。
続いては、「font_properties」「word list」「frequent word list」というファイルを用意しておく必要があるようです。
・font_propertiesファイル
{言語名}.font_properties
今回の場合、"jp2.font_properties"
中身は次のようにするみたいです。
py 0 0 0 0 0
pyの部分がフォント名です。
・word listファイル
{言語名}.words_list
今回の場合、"jp2.words_list"
中身は空でいいようです。
・frequent word listファイル
{言語名}.frequent_words_list
今回の場合、"jp2.frequent_words_list"
こちらも中身は空でいいようです。
以下のようになりました。
続いて作成したファイルを元に学習を行なわせます。
jTessBoxEditorFXの[Trainer]タブをクリックします。
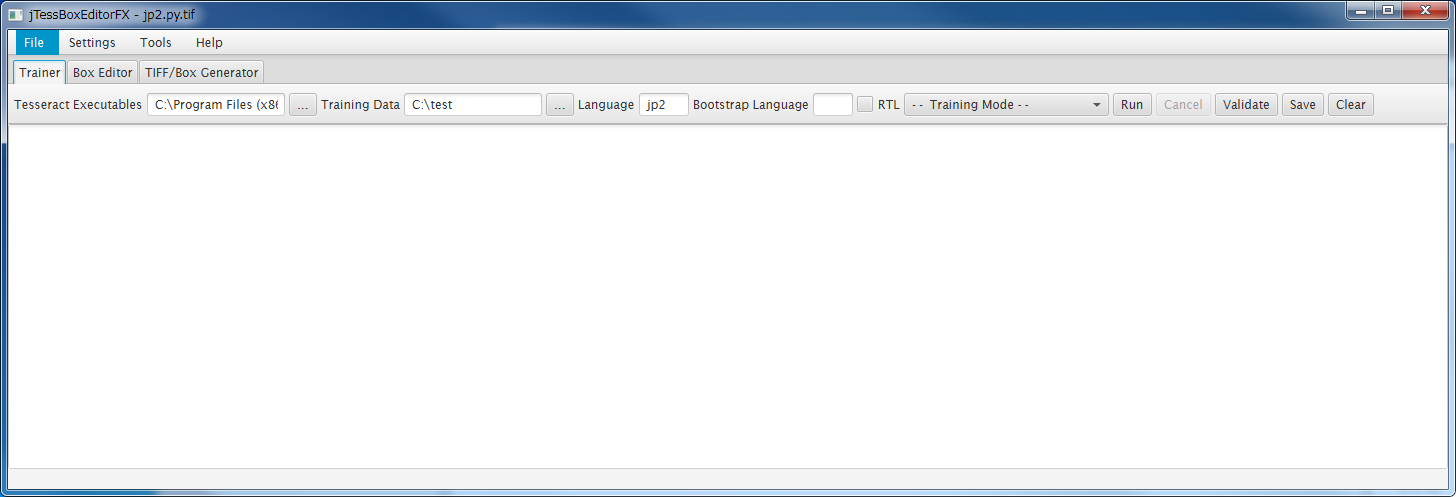
・[Tesseract Executables]
tesseract.exeのパスの指定。デフォルトではjTessBoxEditorFXにあるtesseract.exeを見ているようなので、必要に応じて変更。
・Training Data
作成したファイルの場所を指定。
・Language
言語名を指定。今回の場合"jp2"
・その他
あまりよくわかっていません。
[- - Training Mode - -]とあるコンボボックスをクリックして、[Train with Existing Box]を選択して、[Run]ボタンクリックで実行します。
次のように最終的に"** Training Completed **"が表示されれば問題ないでしょう。
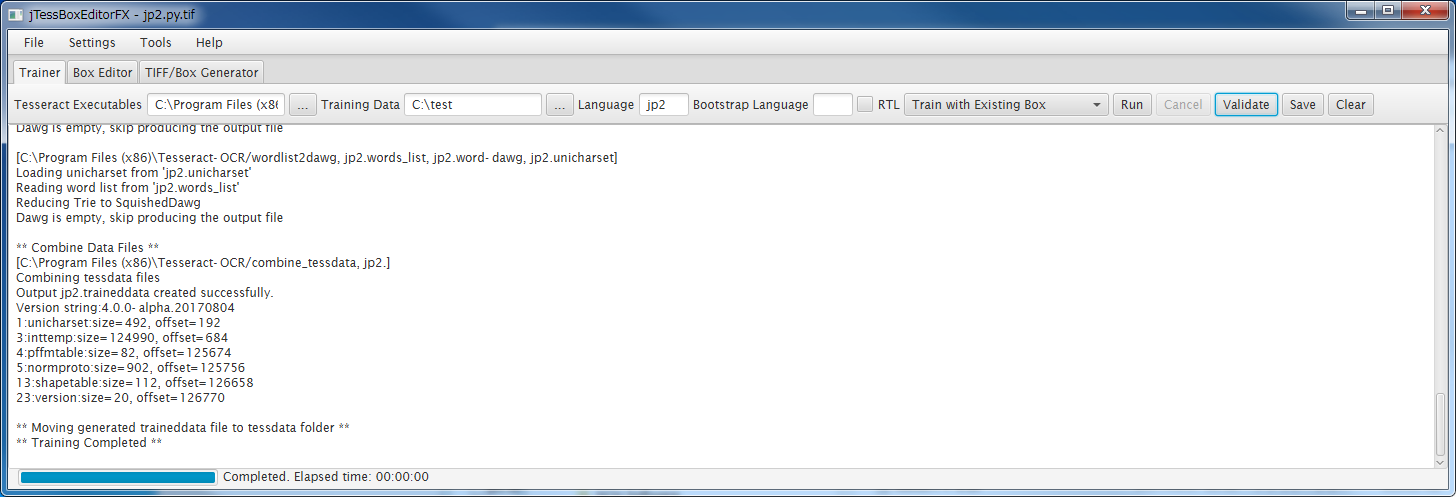
今回は中身が少ないので一瞬で終わりました。
次のようにファイルが作られています。
最後に、次のようにしてファイルをひとまとめにします。
c:\test>combine_tessdata jp2.
Combining tessdata files
Output jp2.traineddata created successfully.
Version string:4.0.0-alpha.20170804
1:unicharset:size=492, offset=192
3:inttemp:size=124990, offset=684
4:pffmtable:size=82, offset=125674
5:normproto:size=902, offset=125756
13:shapetable:size=112, offset=126658
23:version:size=20, offset=126770
これで、"jp2.traineddata"ファイルが作成されました。
よくわかっていないのですが、フォント名が入っていないので、一応ファイル名を"jp2.py.traineddata"としておきます。
そして、"Tesseract-OCR\tessdata"にファイルを配置します。
言語データを指定して読み取りを行なうようにする。
まずはExcelに出力して、言語設定の欄を追加します。
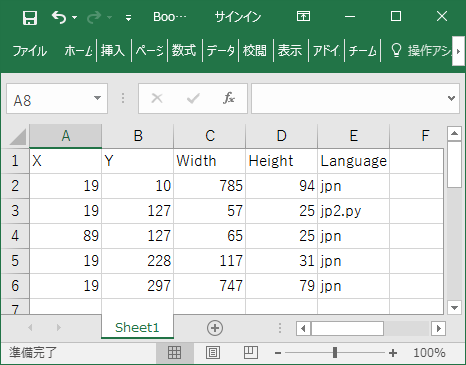
前回作成したExcel側のJSONファイル出力の際に、文字形式を出力する部分をヘッダーが"Output"だったらとしていたので、セルの書式が文字型かで判断するように修正します。
If UsedRange(i, j).NumberFormat = "@" Then
[{"X":19,"Y":10,"Width":785,"Height":94,"Language":"jpn"},{"X":19,"Y":127,"Width":57,"Height":25,"Language":"jp2.py"},{"X":89,"Y":127,"Width":65,"Height":25,"Language":"jpn"},{"X":19,"Y":228,"Width":117,"Height":31,"Language":"jpn"},{"X":19,"Y":297,"Width":747,"Height":79,"Language":"jpn"}]
ocr.pyの言語指定部分をjsonで設定した値を指定するように修正します。
from PIL import Image
import sys
import pyocr
import pyocr.builders
import cv2
import numpy as np
import json
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
args = sys.argv
img = cv2.imread(args[1], cv2.IMREAD_GRAYSCALE)
# 座標の指定は x, y, width, Height
file = open(args[2], "r", encoding="utf-8_sig")
boxs = json.load(file)
for box in boxs:
#イメージは OpenCV -> PIL に変換する
txt = tool.image_to_string(Image.fromarray(img[box["Y"]:box["Y"]+box["Height"], box["X"]:box["X"]+box["Width"]]),
lang=box["Language"],
builder=pyocr.builders.TextBuilder(tesseract_layout=6))
print(txt)
>ocr.py ocr.png ocr.json
(②0①⑦ 年 ⑫ 月 ) Python と OpenCV を こ れ か ら
や っ て み る - ① - は じ め の 一 歩
Pytnon
ocpancy
は じ め に
Python0 バ イ ソン ) を 中 々 使 う 機 会 が 無 く 、OpenC/ オ ー プ ン シ ー プ
イ ) も 気 に は な り つ つ 使 う 橋 会 が 無 く 。
そ ん な 承 、 ち ょ っ と や っ て み よ う と 思 っ た の で 、 う か ら や る
に あ た っ て の 導 入 や は じ め の 一 歩 な ど 。
邉 境 は Windows⑦ ⑥bt で や り ま す 。
結果は"Pytnon"。う~ん、おしい!!
"h"と"n"の差か・・・
前回は"pwhon"で"h"と"n"は区別できていましたから、定義のどこかが悪いのかもしれないですね。
ともかくもこれで、言語データの作り方もわかりましたし、個別に指定できますので、フォントなどに応じて読み取り精度を上げられるかと思います。
次はコンフィグなどで、読み取り文字の絞込みなどをどのように行なうか確認して行こうと思います。
数値のみ("0123456789")などの指定があるでしょうから、そうした設定をどのように行なうかですね。
後は、学習機能があるということは、今回のように読み取りがうまく行なえなかった文字について、教える事でも精度を上げられると言う事でしょうから、その辺もどのように行なうのかなども調べて行きたいと思います。
以上
【追記】このケースの場合、背景がグレーであったのが影響していたようです。次のように2値化すれば読み取れました
ret, img2 = cv2.threshold(img, 180, 255, cv2.THRESH_BINARY_INV)


>ocr.py ocr.png ocr.json
(②0①⑦ 年 ⑫ 月 ) Python と こ OpenCV を こ れ か ら
や っ て み る - ① - は じ め の 一 歩
Python
Ge)
は じ め に
0000⑧②0 に gi ES0①①⑧utduauo cz と z⑧0②①a②②leeiis t
そ ん な 折 、 ち ょ っ と や っ て み よ う と 思 っ た の で 、 今 か ら や る
に あ た っ て の 尊 入 ゃ は じ め の 一 歩 な ど 。
ただし、他の場所が今度は問題ありなので、座標情報のjsonに、画像補正を行なうかといったパラメータなどを用意する形になるかとおもいます。
参考にした記事など
これまでの記事
| 前回 | 一覧 | 次回 |
|---|---|---|
| 4 - 座標設定 | 一覧 | 6 - コンフィグ(1) |