はじめに
PythonもOpenCVもこれまでまったく触れてこなかったけど、ちょっとやってみたいと思ってはじめたので、色々と試しているという状況です。
前回『(2017年12月) PythonとOpenCVをこれからやってみる - 5 - 学習(1) - Qiita』は言語データを作成しましたので、今回はさらに認識精度を上げるためのコンフィグ設定を行なっていこうと思います。
ホワイトリストとブラックリスト
色々と調べていると、とりあえずホワイトリストがあり、デフォルトでは"Tesseract-OCR\tessdata\configs"に"digits"というファイルがあり、中身は次のようになっています。
tessedit_char_whitelist 0123456789-.
またブラックリストの指定もあるようで、その場合、指定した文字を対象外にするみたいです。
基本的な使い方としては次のようになるみたいです。
>tesseract ocr.png out -l jpn digits
コンフィグファイルの名称を指定すればいいようです。
しかし、数値しか指定していないのに、普通にその他の文字も認識されてしまいます。
自分が作った言語データの場合は効果があるようなので、今回は必要な言語データを作成して、読み取り文字の指定を行ってみます。
言語データの作成
前回の方法で、テスト用の画像データの元となっている文字列をそのまま登録します。
今回はフォントとサイズはデフォルトのままです。
画像処理方法とコンフィグの指定を追加する
次のようにしました。
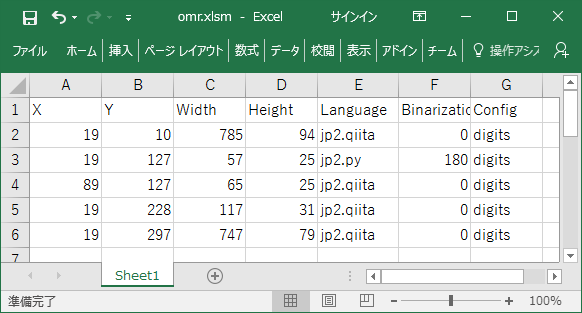
Binarizationが0以上の場合、その閾値で二値化を行ないます。
Configについてはとりあえずすべてdigitsを指定しておきます。
画像処理方法による補正とコンフィグの読込み
コンフィグファイルの指定は調べてもよくわかりませんでしたので、pyocrのコードを見てそれっぽい項目をそれっぽくしてみました。
from PIL import Image
import sys
import pyocr
import pyocr.builders
import cv2
import numpy as np
import json
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
args = sys.argv
img = cv2.imread(args[1], cv2.IMREAD_GRAYSCALE)
# 座標の指定は x, y, width, Height
file = open(args[2], "r", encoding="utf-8_sig")
boxs = json.load(file)
for box in boxs:
#イメージは OpenCV -> PIL に変換する
img2 = img[box["Y"]:box["Y"]+box["Height"], box["X"]:box["X"]+box["Width"]]
if 0 < box["Binarization"]:
ret, img2 = cv2.threshold(img2, box["Binarization"], 255, cv2.THRESH_BINARY_INV)
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
if box["Config"] is not None:
builder.tesseract_configs.append(box["Config"])
txt = tool.image_to_string(Image.fromarray(img2),
lang=box["Language"],
builder=builder)
print(txt)
>ocr6.py ocr.png ocr.json
601-7 21-22 1 1 0 102762 4-27 7
- - 2 - 4 6 0 -
0 7162
- 26 2
- 2 0 412 2 72 6122 72 6 0 2 20 - 222- 6 4 7 6
2 27 6 77 7 62 27 6 267 62 70 2 66627 7
6 7 64 - 7
どうやらちゃんとホワイトリストの設定が行なえているようです。
では、個別にコンフィグファイルを指定して、読み取りの精度を上げられるか試してみます。
コンフィグの調整を行なっていく
とりあえず、読込みの設定を次のようにしました。
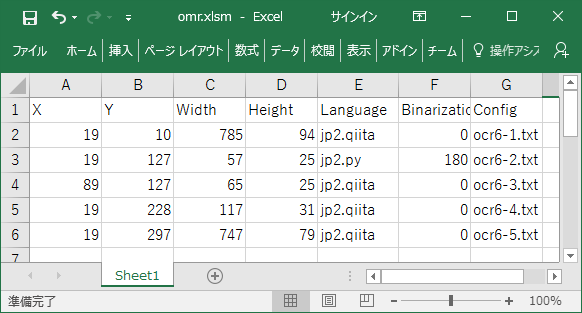
各ファイルの中身は次のようにしておきます。
tessedit_char_whitelist
tessedit_char_blacklist
tessedit_char_blacklistはブラックリストだからこの名前でいいかな?っと試したらうまく行きました。
この状態での出力が次のようになります。

>ocr6.py ocr.png ocr.json
(20年7年年2月) PythonとOpenCVをこれから
やつてみる - 2t - はじめの一歩
Python
openCy
は じめに
Pyth。n(nイソン)を中々使う機会が無(、 openCVPt-プンシ-プイ)も気にはなりっっ使う
機会が無く月
そんな折、 ちょっとやってみょうと思ったので、 今からやるにあたっての導入やはじめ
のブ歩なとこ7
境境はwind。ws7 64bitでやります。
OpenCVと読み取って欲しい所がopenCyとなっていますので、ocr6-3.txtを次のようにしてみます。
tessedit_char_whitelist
tessedit_char_blacklist oy
>ocr6.py ocr.png ocr.json
(20年7年年2月) PythonとOpenCVをこれから
やつてみる - 2t - はじめの一歩
Python
OpenCV
は じめに
Pyth。n(nイソン)を中々使う機会が無(、 openCVPt-プンシ-プイ)も気にはなりっっ使う
機会が無く月
そんな折、 ちょっとやってみょうと思ったので、 今からやるにあたっての導入やはじめ
のブ歩なとこ7
境境はwind。ws7 64bitでやります。
うまいくいきました。この場合でしたら、ホワイトリスト側に"OpenCV"としてもいいです。
"Pyth。n"や"wind。ws7"のように"o"が"。"で判断されていますので、"。"を対象外にしてみます。
tessedit_char_whitelist
tessedit_char_blacklist 。
※日本語を入れたので"UTF-8"で保存しました
>ocr6.py ocr.png ocr.json
(20年7年年2月) PythonとOpenCVをこれから
やつてみる - 2t - はじめの一歩
Python
OpenCV
は じめに
Pyth()n(nイソン)を中々使う機会が無(、 openCVPt-プンシ-プイ)も気にはなりっっ使う
機会が無く月
そんな折、 ちょっとやってみょうと思ったので、 今からやるにあたっての導入やはじめ
のブ歩なとこ7
境境はwindows7 64bitでやります、7
"windows7"はうまく認識できましたが"Python"の方は"Pyth()n"と"o"が"()"となっています。
この場合、"(" ")" を対象外にするわけにもいかないので困りました。
最初の"(20年7年年2月)"も"1"が"年"で判断されています。どうしてでしょうね・・・
また、逆に"。"の部分は、"、7"のように認識されています。
下手な調整はかえってわかりづらくなってしまう場合もあるようですね。
その他にもコンフィグの項目があり、日本語の場合に調整した方がいい項目がwikiにかかれていましたので、その辺も今後ためして行こうと思います。
ともかくも、ホワイトリストとブラックリストの指定が行えるようになりましたので、よくあるOCRなら、項目に合わせてこんな感じで定義すれば、読み取り精度を上げられるのではないかと思います。
以上
【追記 2017/12/10】
その後次のコンフィグ設定を追加してみましたが、このケースでは改善できませんでした。
参考記事からの丸写しで設定内容もまだ把握できていないので、この辺も今後調査していかないとです。
chop_enable T
use_new_state_cost F
segment_segcost_rating F
enable_new_segsearch 0
language_model_ngram_on 0
textord_force_make_prop_words F
edges_max_children_per_outline 40
参考にした記事など
これまでの記事
| 前回 | 一覧 | 次回 |
|---|---|---|
| 5 - 学習(1) | 一覧 | 7 - 信頼度 |