Tensorflow-bin 
TPU-MobilenetSSD 

1.Introduction
TPUモデルコンパイラがカスタムモデルの変換に対応したそうですので早速試してみました。
この記事の手順では最終的に生成されたモデルの精度が極悪ですが、転移学習ではなくフル学習にしたり、パラメータを調整することで精度は改善可能です。
この記事で語るのは、あくまで 独自DockerイメージによるカスタムTPUモデルの学習と生成手順 のみです。
モデル性能のチューニングは実施しません。
2.Procedure
学習手順は、前回記事 Edge TPU Accelaratorの動作を少しでも高速化したかったのでMobileNetv2-SSD/MobileNetv1-SSD+MS-COCOをPascal VOCで転移学習して.tfliteを生成した_Docker編_その2 あるいは Edge TPU Accelaratorの動作を少しでも高速化したかったのでMS-COCOをPascal VOCで転移学習して.tfliteを生成した_GoogleColaboratory[GPU]編_その3 をそのまま使用します。 前回記事はもともと、 TPUコンパイラ がカスタムモデルに対応することを事前に知っていたため、機能がリリースされたときに最速で検証できるよう事前準備をしていたのです。
私独自のDockerは公式のDockerイメージとは異なり、NVIDIA Docker を使用します。
公式のDockerがGPUトレーニングに対応していないため、自力でシーケンスを大幅に組み直しています。
なお、対応可能なレイヤと変換アルゴリズムは、 公式の TensorFlow models on the Edge TPU に記載されていますので参考にしてください。
3.Results
前回記事 の手順により生成した MobileNetv2-SSDLite の .tflite ファイルをコンパイラに投入してみます。
https://coral.withgoogle.com/web-compiler/
ドラッグ&ドロップで、 せーの、ホイッ!
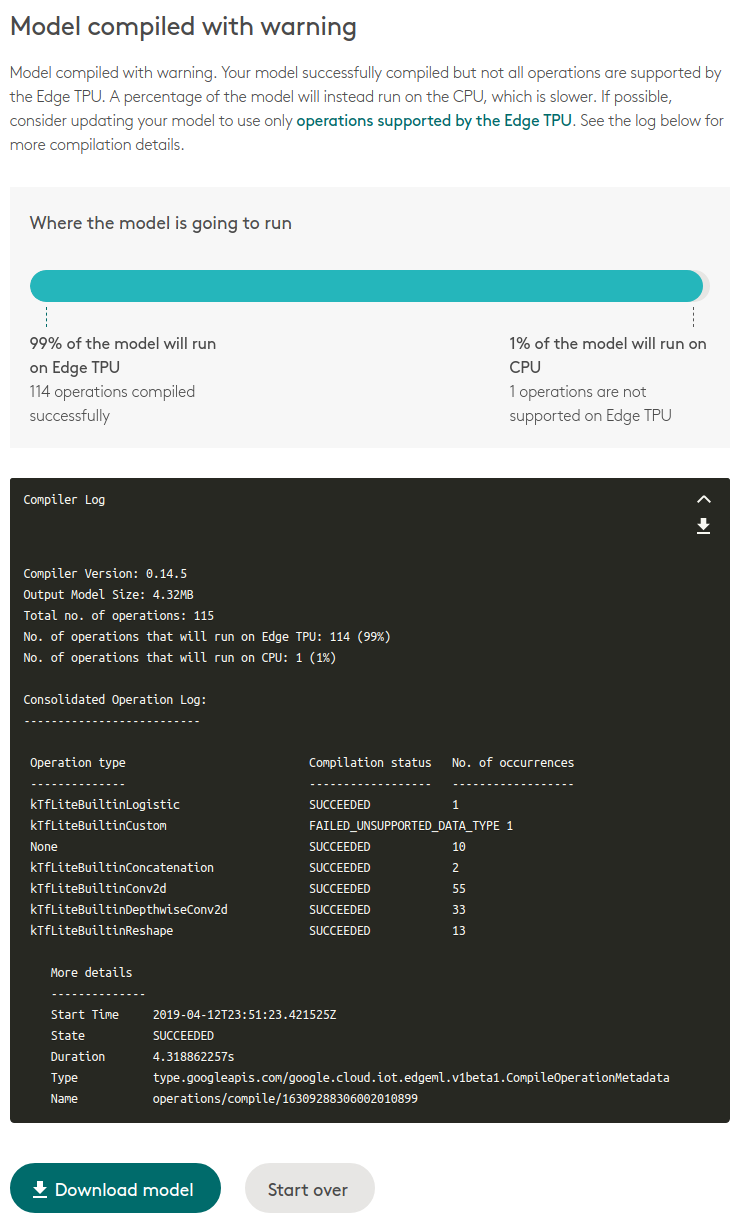
あっさり成功しました。 しかも、アップデートが入る前までは一切表示されなかった変換ログが表示されるようになっています。 さらに、TPU側で非対応のレイヤーは自動的にCPUへオフロードされる仕様に改善されています。
最高です。 OpenVINOに欲しい機能です。
ある程度自由にレイヤを組み合わせて推論させることができるため、対応モデルの幅が大幅に広がりましたね。
今回は、各種公式ドキュメントを一切見ずに独自の軽量トレーニングとコンバートを実施しました。
4.Finally
おいおいフルトレーニングをし直して推論精度を向上した .tflite モデルを生成して遊びたいと思います。