この記事の内容
MeCabやBeautiful Soupのインポートから、WEBスクレイピングし口コミ、レビューを抽出。それをwordcloudにし、どんな事が書かれているのか可視化してやろう!という内容です。
できるようになること
例えばトリップアドバイザーの「口コミ」これをワードクラウド(頻出単語≒多くの人がわざわざ口コミで言及しているトピック、の可視化)ができます。
東京タワーとスカイツリー、東京タワーと通天閣の可視化などして比較すると差異が見えて面白いかも。。。という発想です。
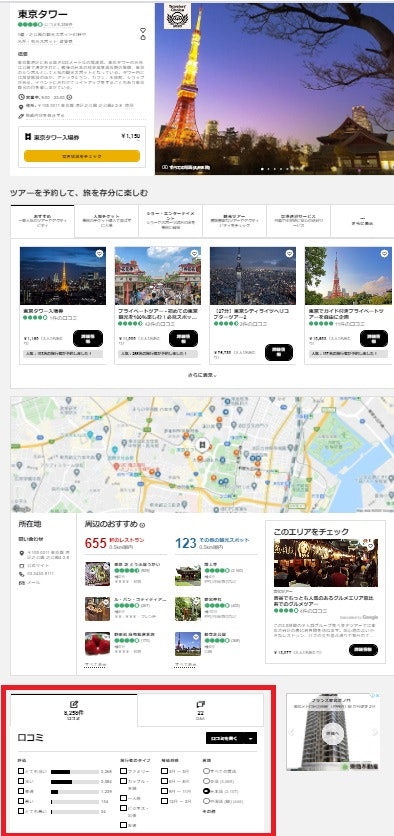
赤枠の「口コミ」から、こんなものを作ります。

参考にさせていただいたサイト、記事
初めてWEBスクレイピングに挑戦し、wordcloudまで作ったのですが、その際に参考にさせていただいたサイトを先に紹介させていただきます。
レビューサイトをスクレイピングして単語数を調査する
【初心者向け】PythonでWebスクレイピングをやってみる
PythonでMeCabを利用する方法を現役エンジニアが解説【初心者向け】
wordcloud を Windows で Anaconda / Jupyter で使う(Tips)
ライブラリのインストール
まずは必要なライブラリのインストールから行います。(すでに入ってる方は飛ばしてください。)
ちなみに私の環境はWindows 10、Anaconda(jupyter)で行ってます。
Beautiful Soup、request、wordcloud
Ancaonda Promptを起動し、Beautiful Soupとrequestをインストールします。
conda install beautifulsoup4
conda install request
conda install -c conda-forge wordcloud
MeCab
公式サイトから「Binary package for MS-Windows」をダウンロードし、インストールします。これなら辞書が最初から入っています。慣れてきたら他の辞書に変えても良いでしょう。
インストール途中で文字コードを聞かれますが、「UTF-8」に!他はそのままでOK。
インストールが終わったら、環境変数の設定を行います。
・(おそらくタスクバー左下に合う検索窓で)「システムの詳細」と検索
・「環境変数」を選択
・システム環境変数の「Path」を選択
・編集をクリックし、新規を選択
・「C:\Program Files (x86)\MeCab\bin」と入力
・OKを選択し、画面を閉じる
PythonでMeCabを利用する方法を現役エンジニアが解説【初心者向け】 さんに手順が書いてありますので、そちらもぜひご覧ください。
ここから本番
ここまでで下準備は終わったので、ここからコードを書いていきます。
まずはインポート
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
ここまでできたら、スクレイピングしたいサイトに行きます。
今回の例ではTrip advisorの東京タワーのページ。
以下の2つを確認します。
・URL
・HTMLのどこにスクレイピングしたいもの(今回は口コミ)があるか。
まずURLはそのまま見ればわかるので、説明は省略します。
後者は「F12」を押しデベロッパーツールを起動します。

上記のようなウィンドウが表示されます。
ここから口コミがどこに、どのように格納されているかを確認します。
確認方法は簡単で、「Shift + Ctrl + C」をクリックした後、記事の口コミ部分をCLICKします。
すると、先のウィンドウで該当部分が選択されます。
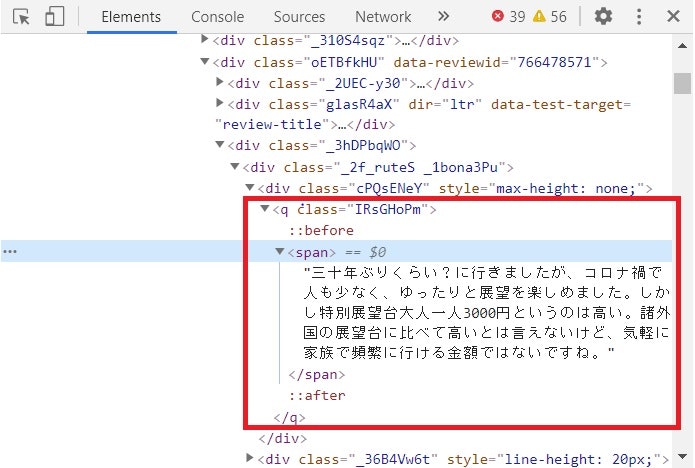
口コミはqのclass「IRsGHomP」に格納されていることがわかります。
あとはコード上でこのURL、場所を指定しスクレイピングを実行します。
# スクレイピングした口コミをdf_listに格納していく
df_list = []
# 20ページ分スクレイピング行う。
pages = range(0, 100, 5)
for page in pages:
# 1ページ目と2ページ目以降で若干URLが異なるのでIFで分岐
if page == 0:
urlName = 'https://www.tripadvisor.jp/Attraction_Review-g14129730-d320047-Reviews-Tokyo_Tower-Shibakoen_Minato_Tokyo_Tokyo_Prefecture_Kanto.html'
else:
urlName = 'https://www.tripadvisor.jp/Attraction_Review-g14129730-d320047-Reviews-or' + str(page) + '-Tokyo_Tower-Shibakoen_Minato_Tokyo_Tokyo_Prefecture_Kanto.html'
url = requests.get(urlName)
soup = BeautifulSoup(url.content, "html.parser")
# HTMLの中からタグqのClass 'IRsGHoPm'を指定
review = soup.find_all('q', class_ = 'IRsGHoPm')
# 抜き出した口コミを順番に格納
for i in range(len(review)):
_df = pd.DataFrame({'Number':i+1,
'review':[review[i].text]})
df_list.append(_df)
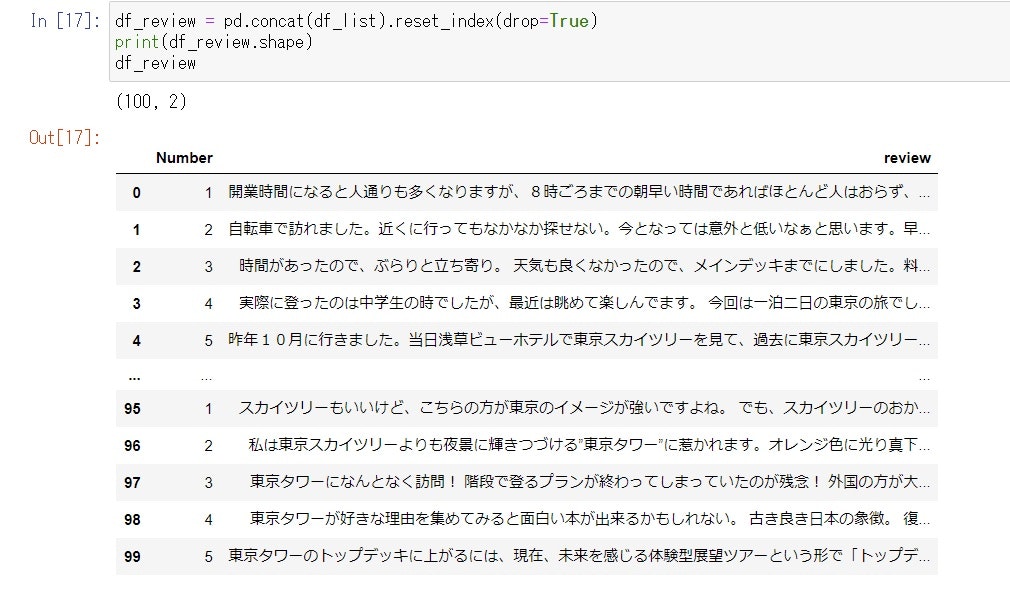
ここまで行うと、df_listには以下が入っているはずです。
df_review = pd.concat(df_list).reset_index(drop=True)
print(df_review.shape)
df_review
wordcloudの作成
まずはMeCabやWordCloudのインポート
import MeCab
import matplotlib.pyplot as plt
from wordcloud import WordCloud
レビューサイトをスクレイピングして単語数を調査するを参考にさせて頂き、コードを記入。
# MeCab準備
tagger = MeCab.Tagger()
tagger.parse('')
# 全テキストデータを結合
all_text= ""
for s in df_review['review']:
all_text += s
node = tagger.parseToNode(all_text)
# 名詞を抽出しリストに
word_list = []
while node:
word_type = node.feature.split(',')[0]
if word_type == '名詞':
word_list.append(node.surface)
node = node.next
# リストを文字列に変換
word_chain = ' '.join(word_list)
あとはwordcloudを実行すればokです。
# ストップワード(除外するワード)の作成
stopwords = ['']
# ワードクラウド作成
W = WordCloud(width=500, height=300, background_color='lightblue', colormap='inferno', font_path='C:\Windows\Fonts\yumin.ttf', stopwords = set(stopwords)).generate(word_chain)
plt.figure(figsize = (15, 12))
plt.imshow(W)
plt.axis('off')
plt.show()
すると下記のように作成されます。

ただ、「の」や「こと」「ため」とうは不要なので除こうと思います。
そこで、上記のストップワードの出番です。
# ストップワード(除外するワード)の作成
stopwords = ['の', 'こと', 'ため']
# ワードクラウド作成
W = WordCloud(width=500, height=300, background_color='lightblue', colormap='inferno', font_path='C:\Windows\Fonts\yumin.ttf', stopwords = set(stopwords)).generate(word_chain)
plt.figure(figsize = (15, 12))
plt.imshow(W)
plt.axis('off')
plt.show()
すると下記のようになります。

何かわかるような、何もわからんような。。。
スカイツリーと比較している人が多いのか、「スカイツリーも見えます」という人が多いのか、、とはいえ「スカイツリー」が東京タワー利用者の関心の対象となっていることは間違いなさそうです。
そこでスカイツリーの口コミもワードクラウドにしたものが下記です。

こちらは「エレベーター」や「チケット」など東京タワーではあまり言及のなかった(文字の大きくなかった)ワードが目立ちます。また「東京タワー」は目立ちません。このあたりは東京タワーとスカイツリーの差異と言えそうです。
おわり。
補足
Open Workなど企業の口コミサイトで、自社と競合を比べてみたりしても面白いかもしれませんし、
札幌ドーム、東京ドーム、名古屋ドーム、大阪ドーム、福岡ドームの五大ドームの口コミ比較もなど、類似施設を比較することで見えてくるものもありそうです。
ちなにみOpen Workのスクレイピングはheaderの設定が必要です。
詳細は下記をご参照ください。
【Python】スクレイピングで403 Forbidden:You don’t have permission to access on this serverが出た際の対処法