スクレイピング練習の備忘録です。
概要
・映画レビューサイトをスクレイピング
・レビュー内容の出現単語数を可視化
映画レビューサイトはfilmarksを利用しました。
filmarksとは
0~5.0のスコア(0.1刻み)と映画の感想をシェアするSNSです。
好きな人をフォローすることができます。
今回は名探偵ピカチュウの投稿内容をスプレイピングしていきます。

実装コード
# Filmarksのスクレイピング
# 対象映画は「名探偵ピカチュウ」
from bs4 import BeautifulSoup
from urllib import request
url = 'https://filmarks.com/movies/77543/'
response = request.urlopen(url)
# ページのソースコードを取得
soup = BeautifulSoup(response)
response.close()
# ページのソースコードを表示
print(soup)
出力した一部

スクレイピングは成功です。
次は投稿内容だけを抽出していきます。
class属性が「p-main-area p-timeline」のdivタグが投稿内容なので、
# レビューゾーンのスクレイピング
# class属性が「p-main-area p-timeline」のdivタグを検索する
p_main_area = soup.find('div', class_='p-main-area p-timeline')
print(p_main_area)
出力した一部

と打つと、レビューゾーンの全てが抽出されます。
レビューだけを抽出するには、find_all関数を用います。
# class属性が「p-mark__review」であるdivタグを検索する
review = p_main_area.find_all('div', class_='p-mark__review')
for i in range(10):
print(review[i])
出力した一部

同じ要領でスコアも抽出可能。
# class属性が「p-mark__review」であるdivタグを検索する
score = p_main_area.find_all('div', class_='c-rating__score')
review = p_main_area.find_all('div', class_='p-mark__review')
for i in range(10):
print(score[i].text)
print(review[i].text)
出力した一部

スコアも出せました。
今のやり方だと、レビュー数は表示したページの10個のみです。
たくさんのレビューを抽出するために、複数のページをスクレイピングしていきます。(今回は100ページ)
import pandas as pd
df_list = []
pages = range(100)
for page in pages:
url = 'https://filmarks.com/movies/77543?page='+str(page)+''
response = request.urlopen(url)
soup = BeautifulSoup(response)
response.close()
# レビューゾーンのスクレイピング
# class属性が「p-main-area p-timeline」のdivタグを検索する
p_main_area = soup.find('div', class_='p-main-area p-timeline')
# class属性が「p-mark__review」であるdivタグを検索する
score = p_main_area.find_all('div', class_='c-rating__score')
review = p_main_area.find_all('div', class_='p-mark__review')
for i in range(len(score)):
_df = pd.DataFrame({'score': [score[i].text],
'review': [review[i].text]})
df_list.append(_df)
print("page%s is over"%page )
# 一つのデータフレームにまとめる
df_review = pd.concat(df_list).reset_index(drop=True)
print(df_review.shape)
df_review.head()
出力した一部

100ページ分の1000個のレビューをデータフレームに格納できました。
(注意:スクレイピングはハッキングと勘違いして通報される恐れもあるので、2~30ページが推奨です。
ヤフーファイナンスなど一部のサイトでは、スクレイピングが禁じられています。)
この後、スコア別に解析を行う場合は以下のようにスコアを数値化してあげます。
# スコアがない場合は0を入れる
df_review['score'].replace("-", 0 ,inplace=True)
# スコアを数値化
df_review['score'] = df_review['score'].astype(float)
また、スクレイピングしたデータフレームをcsv形式で保存もできます。
# スクレイピングしたデータフレームをcsv形式で保存
df_review.to_csv('filmarks_review_pikachu.csv', index=False, encoding='utf_8_sig')
レビューデータからワードクラウド作成します。
import MeCab
from matplotlib import pyplot as plt
from wordcloud import WordCloud
# MeCabの準備
tagger = MeCab.Tagger()
tagger.parse('')
# 形態素分析を行うために,まず全テキストデータを結合します。
all_text= ""
for s in df_review['review']:
all_text += s
node = tagger.parseToNode(all_text)
# 名詞を取り出す
word_list = []
while node:
word_type = node.feature.split(',')[0]
if word_type == '名詞':
word_list.append(node.surface)
node = node.next
# リストを文字列に変換
word_chain = ' '.join(word_list)
# ワードクラウド作成
W = WordCloud(width=640, height=480, background_color='white', colormap='bone', font_path='C:\Windows\Fonts\yumin.ttf').generate(word_chain)
plt.imshow(W)
plt.axis('off')
plt.show()
出力した一部

最後に高スコア(4以上)と低スコア(3以下)に分けた単語の頻度表を描画します。
これまでのコードを関数化して動かします。
import collections
# matplotlibの日本語対応
from matplotlib import rcParams
rcParams['font.family'] = 'sans-serif'
rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio', 'Takao', 'IPAexGothic', 'IPAPGothic', 'Noto Sans CJK JP']
import numpy as np
# テキストから名詞を取り出す
def make_noun_list(text):
node = tagger.parseToNode(text)
# 名詞を取り出す
word_list = []
while node:
word_type = node.feature.split(',')[0]
word_type2 = node.feature.split(',')[1]
if word_type == '名詞' or word_type2 == '一般':
word_list.append(node.surface)
node = node.next
return word_list
# 出現数トップ20を昇順にデータフレーム化
def make_df_wordcount20(word_list):
# 各要素の出現回数をカウント
c = collections.Counter(word_list)
# 出現回数順に要素を取得
c.most_common()
# 出現回数順に並べた要素・出現回数のリスト
values, counts = zip(*c.most_common())
# 出現数トップ20を昇順にデータフレーム化
df_word = pd.DataFrame({ 'count' : counts[:20][::-1],
'word' : values[:20][::-1]})
return df_word
# 出現数を可視化
def draw_word_num(df):
x_axis = np.arange(df.shape[0])
fig, ax = plt.subplots(figsize=(7, 5))
plt.barh(x_axis, df['count'], height=0.4, align="center")
plt.yticks(x_axis, df['word'])
plt.show()
def text_to_word_num(text):
# テキストから名詞を取り出す
word_list = make_noun_list(text)
# 出現数トップ20を昇順にデータフレーム化
df_word = make_df_wordcount20(word_list)
# 出現数を可視化
draw_word_num(df_word)
# 形態素分析を行うために,スコア別にテキストデータを結合
high_score_text = ""
low_score_text = ""
for s in range(1000):
if df_review['score'][s] >= 4.0:
high_score_text += df_review['review'][s]
if df_review['score'][s] <= 3:
low_score_text += df_review['review'][s]
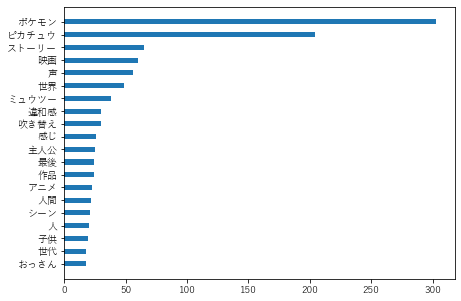
# スコア3以下の出現単語トップ20
text_to_word_num(low_score_text)
出力した一部
# スコア4以上の出現単語トップ20
text_to_word_num(high_score_text)
出力した一部
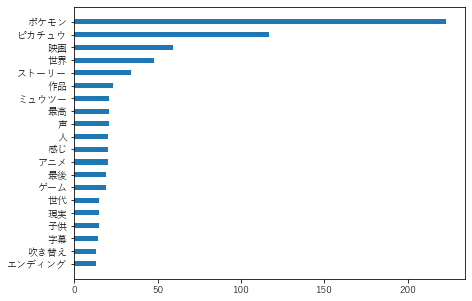
あまり違いはなさそうです。
単純な頻度表だとこんなもんですね。
参考記事
・[Python入門]Beautiful Soup 4によるスクレイピングの基礎
・PythonでHTMLを解析してデータ収集してみる? スクレイピングが最初からわかる『Python 2年生』
・MeCabインストール(PythonとMeCabで形態素解析(on Windows))