読者の想定
初心者向けとありますが、私も初心者です。
webスクレイピングの簡単なサンプルコードの理解をした後、ちょっと自身のオリジナリティを出したいなと思って、調べながらやってみたという内容です。
webスクレイピングの参考コード通りに実行したら、タイトルとかを抜きだす事ができた!がレベル1なら、今回はレベル2くらいの内容だと思います。
なので、勘違いの部分もあったりすると思うので、ご指摘あればコメントいただければと思います。
はじめに
環境
python 3.7.3
私は、visual studio codeで開発しました。
ライブラリのインポート
Pythonには"urlib2"というHTTPのライブラリがあるのですが、使い勝手がよくないので、"Requests"と"BeautifulSoup"のライブラリを使ってwebスクレイピングを行います。
RequestsでWebページを取得して、Beautiful SoupでそのHTMLを抽出します。
やっていこう!
スクレイピング内容
日経ビジネス電子版
https://business.nikkei.com/
から、新着記事の見出しとURLを取得してみようと思います。
Google Chromeでアクセスし、F12キーで、デベロッパーツール(検証モード)にアクセスします。
新着記事の部分が、HTMLのどの部分なのか知りたいので、Ctrl + Shift + Cで見出しにカーソルを動かします。

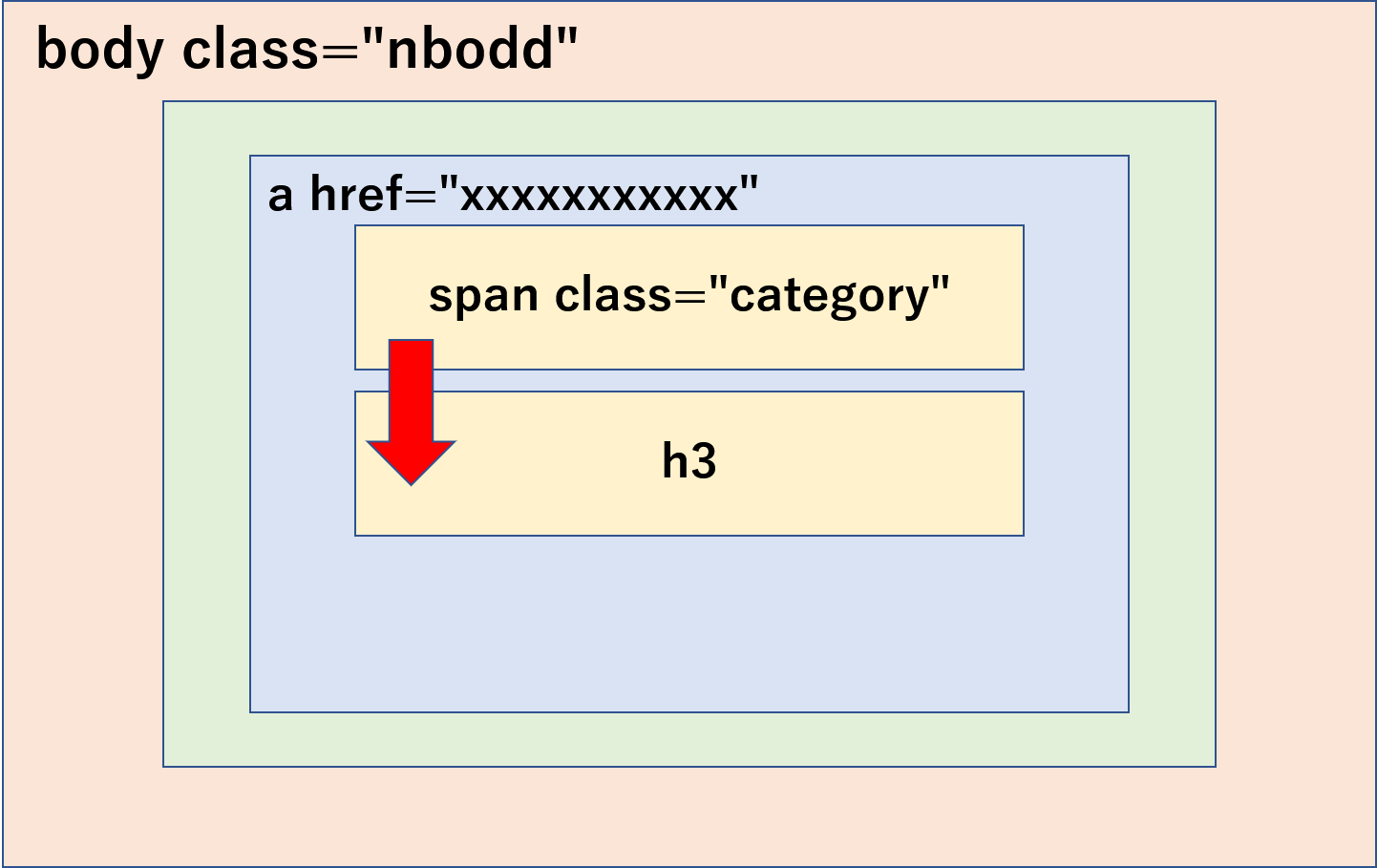
 すると、classがcategoryという部分に、記事の連載名がある事が分かりました。
すると、classがcategoryという部分に、記事の連載名がある事が分かりました。


記事の見出しは、h3タグに入っています。
また、URLは、少し上のaタグの部分にある事が分かります。
この関係を図に示すと、以下のような構図になります。
あとで、プログラムと一緒に解説したいと思います。

コードの解説
import requests
from bs4 import BeautifulSoup
import re
urlName = "https://business.nikkei.com"
url = requests.get(urlName)
soup = BeautifulSoup(url.content, "html.parser")
requestsのライブラリでhttp接続をして、BeautifulSoupでhtmlの解析をします。
elems = soup.find_all("span")
まず、span要素を全てelemsに格納します。
for elem in elems:
try:
string = elem.get("class").pop(0)
if string in "category":
print(elem.string)
title = elem.find_next_sibling("h3")
print(title.text.replace('\n',''))
r = elem.find_previous('a')
print(urlName + r.get('href'), '\n')
except:
pass
次に、span要素の中から、class名を取り出して、categoryかどうかを判別します。
もし、classがcategoryであった場合には、連載名のテキストを、.stringを用いて抜き出します。
そして、次は見出しの内容を取得します。
見出しは、h3タグにありました。
h3タグは、同じ深さで、すぐ下の部分にありました。
なので、find_next_sibling()を使って、要素以降の同じ深さにあるh3を検索します。
抜き出した文章には、画像もついている場合があり、改行が含まれている場合と含まれていない場合があったので、含まれている場合は削除しました。
最後に、URLを抜き出しにいきたいと思います。先ほどは、同じ深さでしたが、aタグは、ひとつ上の深さにいます。
したがって、find_previous()を使って、aタグを探しに行き、要素の指定の属性値を取得するgetメソッドを用いて、hrefのアドレスを取り出しました。

以下、実行結果の一部です。
池松由香のニューヨーク発直行便
米海軍の巨大病院船がNY入り それでも足らない病床
https://business.nikkei.com/atcl/gen/19/00119/033100011/
市嶋洋平のシリコンバレーインサイ…
「需要2割経済」を生きる ポストコロナ考え動く米外食業界
https://business.nikkei.com/atcl/gen/19/00137/033100002/
橋本宗明が医薬・医療の先を読む
中国平安保険と提携した塩野義・手代木社長の深謀遠慮
https://business.nikkei.com/atcl/gen/19/00110/033100012/
このように、取得する事ができました。
さいごに
まだまだ勉強中なので、勘違いしている部分があったり、もっと良い方法があるかとは思います。
少しずつ理解を深めながら実践していきたいと思います。