WindowsのAnaconda(Jupyter)環境で wordcloud を使う。
シンプルにシンプルに手順だけ。ほぼ自分のメモ用。
※ こういうときは gist を使うか悩みますが、誰かがみてくれる、誰かの役に立つ可能性が高い気がするのでQiitaを使う!!
以下の手順でいく
一応確認しておく
Jupyterなどの環境で下記の1行だけかいて実行させてみる。
from wordcloud import WordCloud
インストールされていなければエラーが出ます。
ModuleNotFoundError: No module named 'wordcloud'
ということでインストールされていないことを確認できたので次に進む。
Anaconda prompt を起動して以下コマンドで wordcloud のインストール
> conda install -c conda-forge wordcloud
:
※ 何回かなにかきかれるけど y で切り抜ける
一応確認してみる
from wordcloud import WordCloud
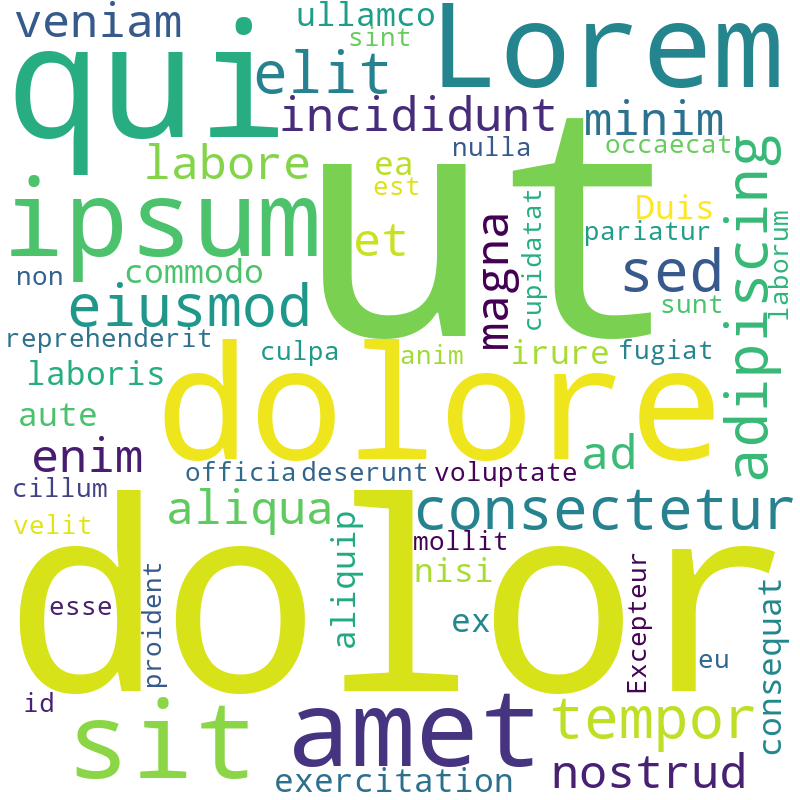
text = "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum."
wordcloud = WordCloud(background_color="white", width=800,height=800).generate(text)
wordcloud.to_file("./test.png")
カレントディレクトリに png が出来てたら成功。
おまけ:Windowsで日本語フォント
font_pathでフォントを指定してください。 .otf だとうまくいきます。
wordcloud = WordCloud(background_color="white", font_path=r"C:\WINDOWS\Fonts\SourceHanCodeJP-Bold.otf", width=800,height=800).generate(text)
さいごに
もしどなたかの役にたったなら、気軽に いいね お願いいたします m__m
Appendix.
上の例は英語の文章なのでスペースで分かち書きされていますが、日本語をわかちしたかったら janome が便利です。
janome からの日本語フォントを使ってのWordCloudのサンプルだとこうなります。
## 分かち書き
## pip install janome
from janome.tokenizer import Tokenizer
tokenizer = Tokenizer()
text = ''
line = '吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。'
tokens = tokenizer.tokenize(line)
for token in tokens:
parts = token.part_of_speech.split(',')
if (parts[0] == '名詞'):
text = text + ' ' + token.surface
print(text)
## 引き続きWordCloud
from wordcloud import WordCloud
wordcloud = WordCloud(background_color="white", font_path=r"C:\WINDOWS\Fonts\SourceHanCodeJP-Bold.otf", collocations = False, width=800,height=800).generate(text)
wordcloud.to_file("./test.png")