たぶん、今年最大の発見の一つだと思うので、Pytorch入門として遊んでみました。
ほぼ、以下の先駆者の方々と同じようなお話なのでウワンの苦労とちょっと解説(気づいたこと)を中心に書こうと思います。
参考は以下のとおりです。
Citation
If you use this code for your research, please cite our paper:
@inproceedings{rottshaham2019singan,
title={SinGAN: Learning a Generative Model from a Single Natural Image},
author={Rott Shaham, Tamar and Dekel, Tali and Michaeli, Tomer},
booktitle={Computer Vision (ICCV), IEEE International Conference on},
year={2019}
}
【参考】
①SinGAN: Learning a Generative Mode from a Single Natural Image@arXiv:1905.01164v2 [cs.CV] 4 Sep 2019
②Code available at: https://github.com/tamarott/SinGAN
③SinGANの論文を読んだらテラすごかった
④【論文解説】SinGAN: Learning a Generative Model from a Single Natural Image
⑤【SinGAN】たった1枚の画像から多様な画像生成タスクが可能に
やったこと
・環境と実行
・論文の簡単な解説
・Trainingについて
・Animation
・Super Resolution
・Paint to Image
・環境と実行
まず、上記の参考②のGithubからZipをダウンロードして展開してください。
先日のPytorch環境に以下のコマンドでインストールできます。
Install dependencies
python -m pip install -r requirements.txt
This code was tested with python 3.6
そして、出来ることは以下のことです。(上記のGithubの翻訳)
Train
自分の画像でSinGANモデルをトレーニングするには、トレーニング画像をInput / Imagesの下に置き、以下を実行します
python main_train.py --input_name <input_file_name>
また、結果のトレーニング済みモデルを使用して、最も粗いスケール(n = 0)から開始するとランダムサンプルを生成できます。
訳注)学習すると学習済モデルが粗さスケール(n)毎に格納されています
CPUマシンでこのコードを実行するには、main_train.pyを呼び出すときに--not_cudaを指定します
Random samples
粗さスケールからランダムサンプルを生成するには、最初に欲しいイメージのSinGANモデルをトレーニングしてください, その後以下を実行します。
python random_samples.py --input_name <training_image_file_name> --mode random_samples --gen_start_scale <generation start scale number>
注意:フルモデルを使用する場合は、開始粗さスケールを0に指定し、2番目のスケールから生成を開始するには1に指定します。
訳注)出来上がりの美しさはスケール0のものがいいようです
Random samples of arbitrery sizes
任意のサイズのランダムサンプルを生成するには、最初に欲しい画像のSinGANモデルをトレーニングしてください(上記のとおり), そして以下を実行します
python random_samples.py --input_name <training_image_file_name> --mode random_samples_arbitrary_sizes --scale_h <horizontal scaling factor> --scale_v <vertical scaling factor>
Animation from a single image
単一の画像から短いアニメーションを生成するには,以下を実行します。
python animation.py --input_name <input_file_name>
これにより、ノイズパディングモードで新しいトレーニングフェーズが自動的に開始されます。
訳注)実行が終了すると、自動的にGifアニメーションを開始粗さスケール毎に複数ずつ生成し、それぞれのDirに格納してくれます。start_scale=0が一番変化が激しく、start_scaleが大きくなるにつれ変化は小さくなります。
Harmonization
貼り付けられたオブジェクトを画像に調和させるには(論文の図13の例を参照), 最初に、欲しい背景画像用にSinGANモデルをトレーニングしてください(上記のとおり), 次に the naively pasted reference image and it's binary mask を "Input/Harmonization"に保存します (例がダウンロードファイルのディレクトリにあるので参照). そして以下を実行します
python harmonization.py --input_name <training_image_file_name> --ref_name <naively_pasted_reference_image_file_name> --harmonization_start_scale <scale to inject>
異なる注入スケールは異なる調和効果を生み出すことに注意してください。最も粗い注入スケールは1です。
Editing
画像を編集するには(論文の図12の例を参照)、最初にSinGANモデルを目的の非編集画像(上記のように)でトレーニングしてください, 次に、単純な編集画像を、対応するバイナリマップと共に"Input/Editing"の下の参照画像として保存します(保存画像の例を参照). そして以下を実行します。
python editing.py --input_name <training_image_file_name> --ref_name <edited_image_file_name> --editing_start_scale <scale to inject>
マスクされた出力とマスクされていない出力の両方が保存されます。 ここでも、異なる注入スケールは異なる編集効果を生み出します。最も粗い注入スケールは1です。
Paint to Image
ペイントをリアルな画像に変換するには(論文の図11の例を参照), 最初にSinGANモデルを欲しいイメージでトレーニングしてください(上記のように), 次に、"Input/Paint"の下にペイントを保存します,そして以下を実行します。
python paint2image.py --input_name <training_image_file_name> --ref_name <paint_image_file_name> --paint_start_scale <scale to inject>
ここでも、異なる注入スケールは異なる編集効果を生み出します。最も粗い注入スケールは1です。
Advanced option: Specify quantization_flag to be True, to re-train only the injection level of the model, to get a on a color-quantized version of upsamled generated images from previous scale. For some images, this might lead to more realistic results.
Super Resolution
画像を超解像するには、次を実行してください:
python SR.py --input_name <LR_image_file_name>
これにより、4倍のアップサンプリング係数に対応するSinGANモデルが自動的にトレーニングされます(まだ存在しない場合)。 さまざまなSR係数については、関数を呼び出すときにパラメーター--sr_factorを使用して指定してください。
訳注)SR係数はデフォルト4で、大きくすると出来上がりの画像が大きくなります
BSD100データセットに関するSinGANの結果は、「ダウンロード」フォルダーからダウンロードできます。
Additional Data and Functions
Single Image Fréchet Inception Distance (SIFID score)
実際の画像とそれに対応する偽サンプル間のSIFIDを計算するには、次を実行してください。
python SIFID/sifid_score.py --path2real <real images path> --path2fake <fake images path> --images_suffix <e.g. jpg, png>
偽の画像ファイル名のそれぞれが、対応する実際の画像ファイル名と同一であることを確認してください。
・論文の簡単な解説
参考は論文等ですが、sinGANの発明は以下にあると思います。
- Oneデータの学習
- ResGANを利用(WGAN-GPのLoss)
- 大域から局所の段階的な特徴学習
- おまけ;複数タスクに対応
Oneデータの学習
Oneデータの学習はたぶん最近だと随分浸透してきたが、実際にそれを生かした学習・利用は初めてだと思う。
ResGANを利用(WGAN-GPのLoss)
ResGANは、参考⑥、そしてWGAN-GPについては参考⑦にあり、収束性能が高い手法として提案されている。
【参考】
⑥Generative Adversarial Network based on Resnet for Conditional
Image Restoration@arXiv:1707.04881v1 [cs.CV] 16 Jul 2017
⑦Improved Training of Wasserstein GANs
まず、参考⑥のResGANは以下のGeneratorとなっている。
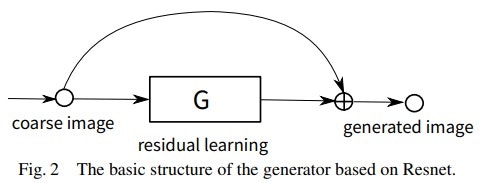
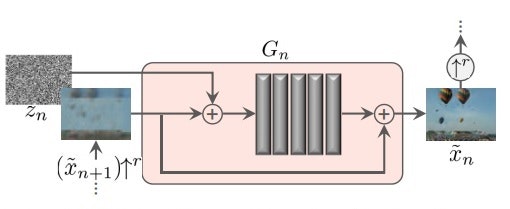
一方、sinGANの各段階のGeneratorは最初を除いて基本以下のResGANで構成されている。すなわち、$z_n$とより粗い画像で生成された画像をUpsizingした$(\bar x_{n-1})↑^r$を$G_n$の入力とし、それとの差分を学習することにより鮮明な画像$\bar x_n$を生成するものである。
注)ここで$↑^r$は画像のUpsizingを示している
ちなみに、
ResGANの損失関数
min_{G_n}max_{D_n}L_{adv}(G_n,D_n)+αL_{rec}(G_n)
第一項は、参考⑦のWGAN-GPであり、以下の式であらわされる。
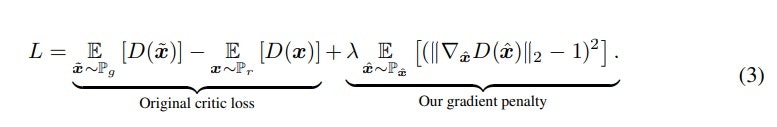
第二項は、
L_{rec} = ||G_n(0,(\bar{x}^{rec}_{n+1}) ↑^r) − x_n||^2,
and for $n = N$, we use
L_{rec} = ||G_N (z^∗) − x_N||^2
「その際の入力ノイズ画像は、$z_n(n=0,...,N−1)=0$ とし、$z_N$のみ訓練初期に設定された固定の乱数としています。」(参考④より引用)
大域から局所の段階的な特徴学習
以下の図のようにResGANを繰り返すことにより、学習が進む。ここで、一番下の段から学習が開始するが、ここでは乱数から生成される$z_N$だけが入力される。Dicriminatorでは、学習回数を決めると自動的に決まる元画像の縮小されたreal画像$x_N$と比較される。
それ以降は、こうして生成される画像$\bar x_{n-1}$をUpsizingした画像 $(\bar x_{n-1})↑^r$と$z_{N-1}$を入力とする。
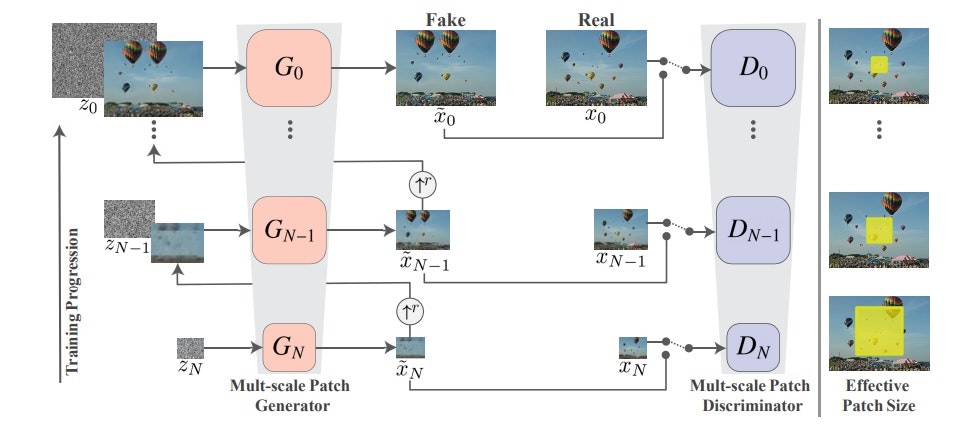
こうして、種々のアプリでは学習された学習パラメータや画像を利用する。
・Trainingについて
上述のとおりで、学習できると思う。
ウワンのPytorch環境は、1060を使っているので、GPUメモリーが3GB程度である。これだと、cows.pngなど学習が最後までできない画像がいくつかあった。
そこで、初期画像(Input/images)のサイズを小さくしてみたが、学習のn=0などの縮小画像のサイズは変わらずなかなかMemmoryエラーが消えなかった。
1/3位まで減らしたところで、どうにかこのnの最終値が少し小さくなって無事に学習できたが、学習画像が小さくてあまり面白みがない結果となった。
・Animation
これは動きがあって面白いがanimation.pyを見ると、特徴の局所性を変化させて(start_scaleの値を変えて)、潜在空間中を乱数振って動かしているようです。その結果、nの値が小さいものは大きく変動し、大きなものはほとんど動かないアニメーションが作成できます。
以下、2-3例を挙げます。
| start_scale=0 | start_scale=1 | start_scale=2 |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
・Super Resolution
論文中の以下の表によれば先日ウワンも紹介したSRGANと匹敵する精度を出しているということです。
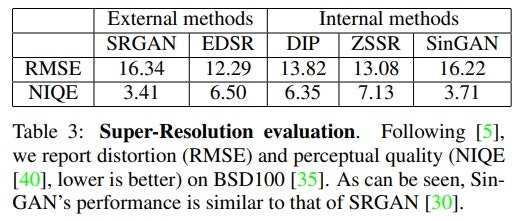

ということで、以下やってみました。
以下の表は、超解像度を右側ほど大きくしています。
同時に大きさも一応右に行くにしたがって大きくなっています。
実際の大きさや超解像度はクリックして単独表示させると実感できると思います。
| original | 拡大1 | 拡大2 | 拡大3 |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
・Paint to Image
簡単な絵をイメージに変換するよということです。
論文では以下の例が掲載されていて、左側のイメージを学習させ、二番目の簡単な絵を”Input/paints”に置いてコマンドを実行させると右側のImageが出力するということです。この図もsinGANの結果が他の手法に比較して優れていることを示しています。
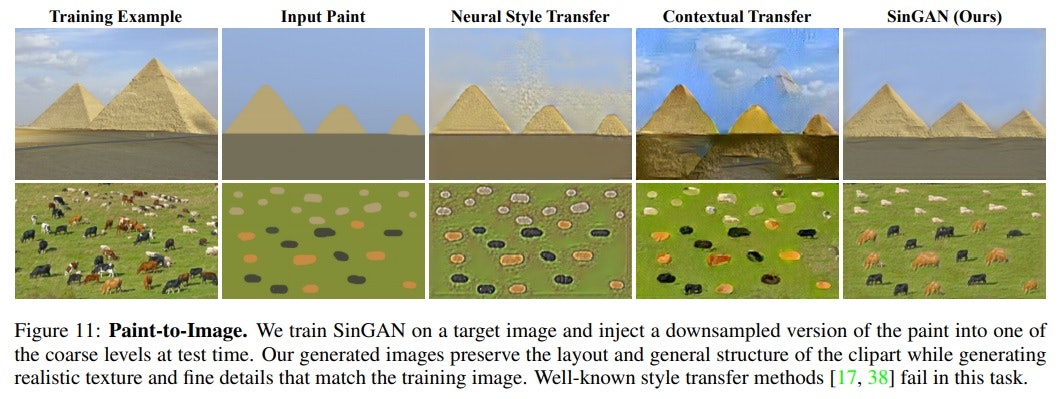
これのウワンの実行結果は以下のとおりです。
これをやるのに1060ではメモリーエラーが出て左のイメージが学習できませんでした。そこで、
250x141の画像を80x46まで縮小して実施しました。
Paint画像は300x200です。
結果は小さすぎますが、一応学習パラメータが粗い特徴しか学習していないものほど粗いイメージしか再現できていません。一方、n=1はある程度牛らしいイメージが出現できています。
※もう少しメモリーの大きいマシンでやろうと思います
| 元画像 | Paint | n=1 | n=2 | n=3 | n=4 |
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
まとめ
・sinGANで遊んでみた
・一応、原理的なことは理解できた
・新しいResGANを利用した大域から局所の学習の威力を実感できた
・1060だとGPUのメモリーが不足気味で絵のサイズが限定されてしまう
・進歩の予感を感じさせる発見だと思う
おまけ
ResGANのGeneratorとDicriminatorは、入力画像サイズに応じてパラメータ調整されており、以下のような構造となっています。
GeneratorConcatSkip2CleanAdd(
(head): ConvBlock(
(conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(body): Sequential(
(block1): ConvBlock(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(block2): ConvBlock(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(block3): ConvBlock(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
)
(tail): Sequential(
(0): Conv2d(32, 3, kernel_size=(3, 3), stride=(1, 1))
(1): Tanh()
)
)
WDiscriminator(
(head): ConvBlock(
(conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(body): Sequential(
(block1): ConvBlock(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(block2): ConvBlock(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(block3): ConvBlock(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
)
(tail): Conv2d(32, 1, kernel_size=(3, 3), stride=(1, 1))
...
GeneratorConcatSkip2CleanAdd(
(head): ConvBlock(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(body): Sequential(
(block1): ConvBlock(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(block2): ConvBlock(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(block3): ConvBlock(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
)
(tail): Sequential(
(0): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1))
(1): Tanh()
)
)
WDiscriminator(
(head): ConvBlock(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(body): Sequential(
(block1): ConvBlock(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(block2): ConvBlock(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
(block3): ConvBlock(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(norm): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(LeakyRelu): LeakyReLU(negative_slope=0.2, inplace=True)
)
)
(tail): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1))
)