概要
単一の画像を使って学習し、超解像・ハーモナイズ・アニメーション化といった様々なアプリケーション(Paint to image, Editing Harmonization, Super-resolution, Animation)への応用が可能なSinGANを紹介します。
SinGANは、ICCV2019において、Best Paper Award (Marr Prize)を受賞しました。

- ProjectPage
- 公式実装(github)
- Shaham, Tamar Rott, Tali Dekel, and Tomer Michaeli. "SinGAN: Learning a Generative Model from a Single Natural Image." Proceedings of the IEEE International Conference on Computer Vision. 2019.
手法の概要
まずはどのような手法なのかを解説します。
モデルのアーキテクチャ
以下にモデルのアーキテクチャを示します。
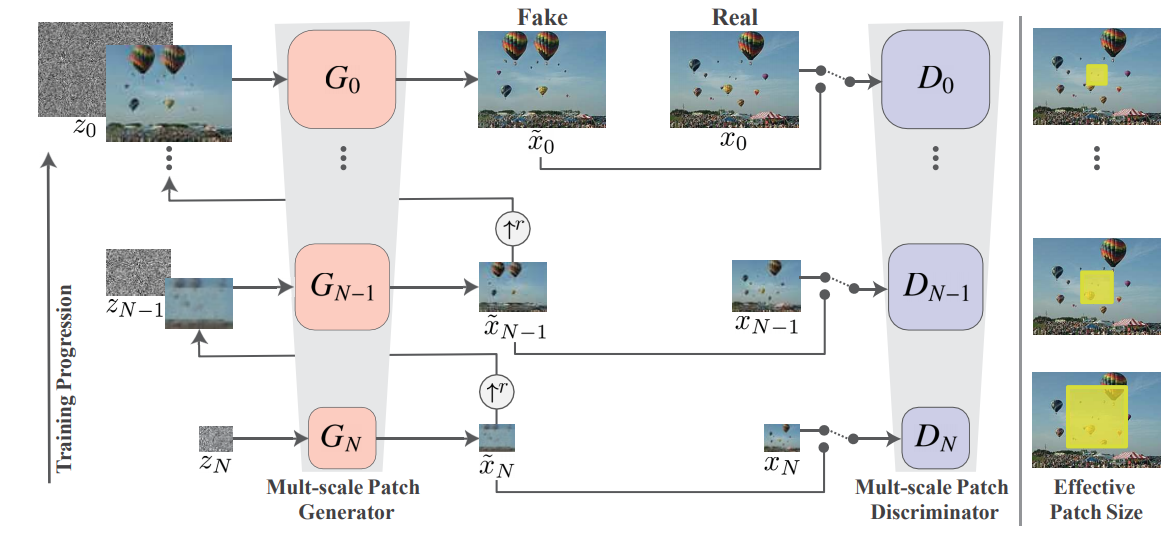
GANですので、GeneratorとDiscriminatorがいます。$G_n(n=0, 1, ..., N)$がGenerator、$D_n(0, 1, ..., N)$がDiscriminatorです。
Generator
Generatorは階層化されており、すべての階層でほぼ同じ構造を持っています。
各階層では入力として、ノイズ画像と低解像度画像を拡大した画像を受け取ります。ただし、最初の階層($G_N$)ではノイズ画像のみが入力されます。2種類の画像は、同じサイズ(幅と高さのピクセル数)です。
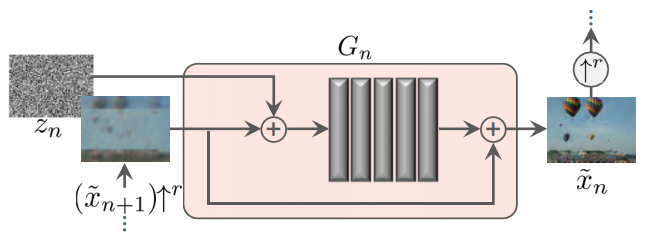
各階層では、入力された画像と同一サイズの画像を出力します。中身は下図のようになっており、Residualな構造を持っています。そのため、各階層の役割は、注入されたノイズ画像から、低解像画像(($\tilde{x}_{n+1})\uparrow^r$)と高解像画像($\tilde{x}_n$)の間のディテールを埋めていくことが期待されています。図中の5つの灰色の縦長の長方形は2DConv(3x3)-BatchNorm-LeakyReLUです。
Discriminator
Discriminatorも、Generatorと同様に階層化されていて、対応する階層のGeneratorの出力結果と実画像をダウンスケールした画像の真偽を見抜けるように訓練されます。
各$D_n$は$G_n$と同じアーキテクチャになっています。
損失関数
以下の最適化問題を解いていくことで訓練が行われます。
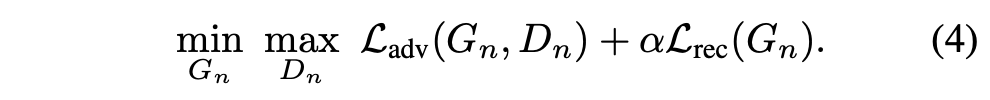
$L_{adv}$は、通常のGANで使われる損失で、Discriminatorは真の画像と生成画像との真偽を見抜けるように、GeneratorはDiscriminatorを騙せるように訓練するために使われます。なお、公式の実装を確認すると、Discriminatorの損失にはWGAN-gpが使われていることが確認できます。
$L_{rec}$は、入力画像を再構成できるようになるための損失で、各段階のGeneratorの出力をアップスケールした$(\tilde x_{n+1})\uparrow^r$ と真の画像をダウンスケールした$x_n$の誤差によって算出します。ただし、$G_N$に関しては、出力結果そのもののと$x_N$を比較して誤差を算出します。
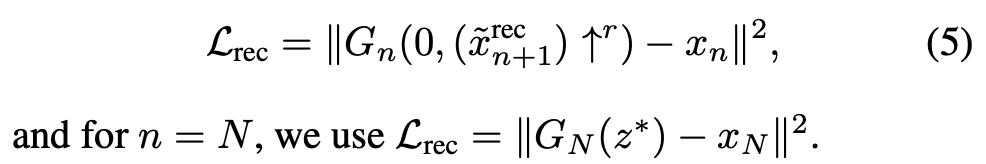
その際の入力ノイズ画像は、$z_n(n=0, ..., N-1)=0$とし、$z_N$のみ訓練初期に設定された固定の乱数としています。
$L_{rec}$について、なぜわざわざ「アップスケール済みの」画像とダウンスケールした画像を比較するのかというと、この損失(RMSE)をもとに、各段階でのノイズの大きさ($\sigma_n$)を調整するという操作をするためです。この操作は、公式実装のtraining.py内で確認できます。
訓練
訓練は、各階層ごとに行われます。公式の実装では、リンク先の部分に対応します。
訓練は単一の画像に対して行うこともあり、シングルのGPUでもかなり短い時間で実現できます。例えば、GTX 1080tiで、アニメーション用のスクリプトを動かすと、30分から1時間程度で完了します。
アプリケーション
訓練済みのモデルを利用して、推論時の処理を工夫することによって、様々なアプリケーションに応用することができます。
論文中では他のアプリケーションも説明されていますが、この記事では超解像とアニメーションのみを説明します。
超解像(Super Resolution)
超解像は、低解像度の画像を入力として、高解像度の画像を生成する操作です。つまり、ある程度の解像度をもとに、ディテールを足していく操作です。そのため、使用するのは、Generatorの最終層$G_0$を繰り返し適用することで実現します。例えば、$k$回の適用で解像度を4倍にしたいのであれば、各階層でのアップスケール率を $r=\sqrt[k]4$として、徐々に拡大しつつディテールを埋めていきます。

アニメーション(単一画像からの動画化)
ノイズ画像をランダムウォークさせることで、生成画像を連続的に変化させることができます。
また、どの段階でのノイズ画像を大きく動かすかによって、生成画像の変化をコントロールできます。例えば、入力に近い層は、大まかなレイアウトを決定する部分であるため、そこに入力されるノイズが変化すると、レイアウトそのものが大きく動きます。逆に、出力に近い層では、ノイズが変化すると細かいディテールの部分が動きます。


まとめ
ICCV2019のベストペーパーであるSinGANについて解説しました。アーキテクチャも単純で、大規模な訓練無しで実施できる(上記のアニメーション生成例は、自分の1080tiで実施しました)点で、GANの初心者にもわかりやすい論文かと思います。
また、公式実装も丁寧に作られているため、実装と論文を突き合わせながら数式と実装の対応関係や、細かい差異を確認できます。