はじめに
本記事はDeep learning論文紹介のAdvent Calender 2019の6日目の記事です。
本記事ではコンピュータビジョンのトップカンファレンスであるICCV2019でBest paperに選ばれたSin GANの論文について紹介し、公式のGitHubを色々触ってみようと思います。
SinGANは1枚の訓練データのみを学習に用いるので、気軽に画像生成を試すことができます(画像サイズにもよりますがGoogle colabratoryのGPUでおよそ1~5時間程度)。後半ではGoogle Colabratoryを用いて実際に画像生成を行っているのでぜひ試してみてください。
【SinGAN公式】
・arxiv
・Github
【Qiitaの記事】
・【論文解説】SinGAN: Learning a Generative Model from a Single Natural Image
・ SinGANの論文を読んだらテラすごかった
図は各論文より引用
GANの概要
GANについて簡単におさらいしようと思います。
GANとはGenerative Adversarial Network(敵対的生成ネットワーク)の略で、Generatorと呼ばれる生成モデル(以下Gと略)とDiscriminatorと呼ばれる識別モデル(以下Dと略)を利用して学習を行う生成タスクに特化したニューラルネットワークです。
GANは特に画像生成のタスクで利用されることが多いため画像で説明をすると、DはGが生成した画像と本物の画像を正確に識別しようと働き、Gは本物そっくりの画像を生成してDを騙そうと働きます。このように2つのモデルが互いに敵対しながら学習が進んでいくことがAdversarial learning(敵対的学習)と呼ばれる所以です。2014年にIan J. Goodfellow氏が出したGenerative Adversarial Netsという論文を皮切りにGANは2019年現在に至るまでに凄まじい進化を遂げました。

2019年に発表されたGANの中では、高解像度の画像生成に成功したBigGAN、ペイントから美麗な風景画を生成するGauGAN等が有名です。(ちなみにGANの世界では、新しい特性や構造を持つGANに対して◯◯GANのように名称をつけるのが慣例となっています。)
BigGAN (高解像度の画像生成)
https://arxiv.org/abs/1809.11096v2

GauGAN (ペイントから美麗な風景画を生成)
https://arxiv.org/abs/1903.07291

以上が簡単にではありますがGANの背景的な知識になります。
GANの仕組みを基礎から学びたい方は@triwaveさんの記事が非常に参考になると思います。
論文の紹介
ここから論文の紹介に移ります。
SinGANは冒頭でも述べたように1枚の訓練画像でマルチタスクを可能とするGANです。
SinGANの特徴

1枚の画像を訓練データとして、上記のように、
①ペイントからの画像生成
②物体の位置移動やスケール変更等の編集を加えた画像の生成
③2つの画像を調和した画像の生成
④超解像化
⑤アニメーション生成
これらをなんと全て1つのモデルで作成することができます。
これ実はとても凄いことで、過去のGANというのは大きなデータセットで学習させる場合が非常に多く,計算量は膨大でした。また超解像化なら超解像化というように、特定のタスクにフォーカスしたGANが主流でした。
それを単一の画像のみで訓練を行い、しかも多様な画像生成タスクをこなすことができるSinGANは、今までにないGANであるということができます。
GANの構造
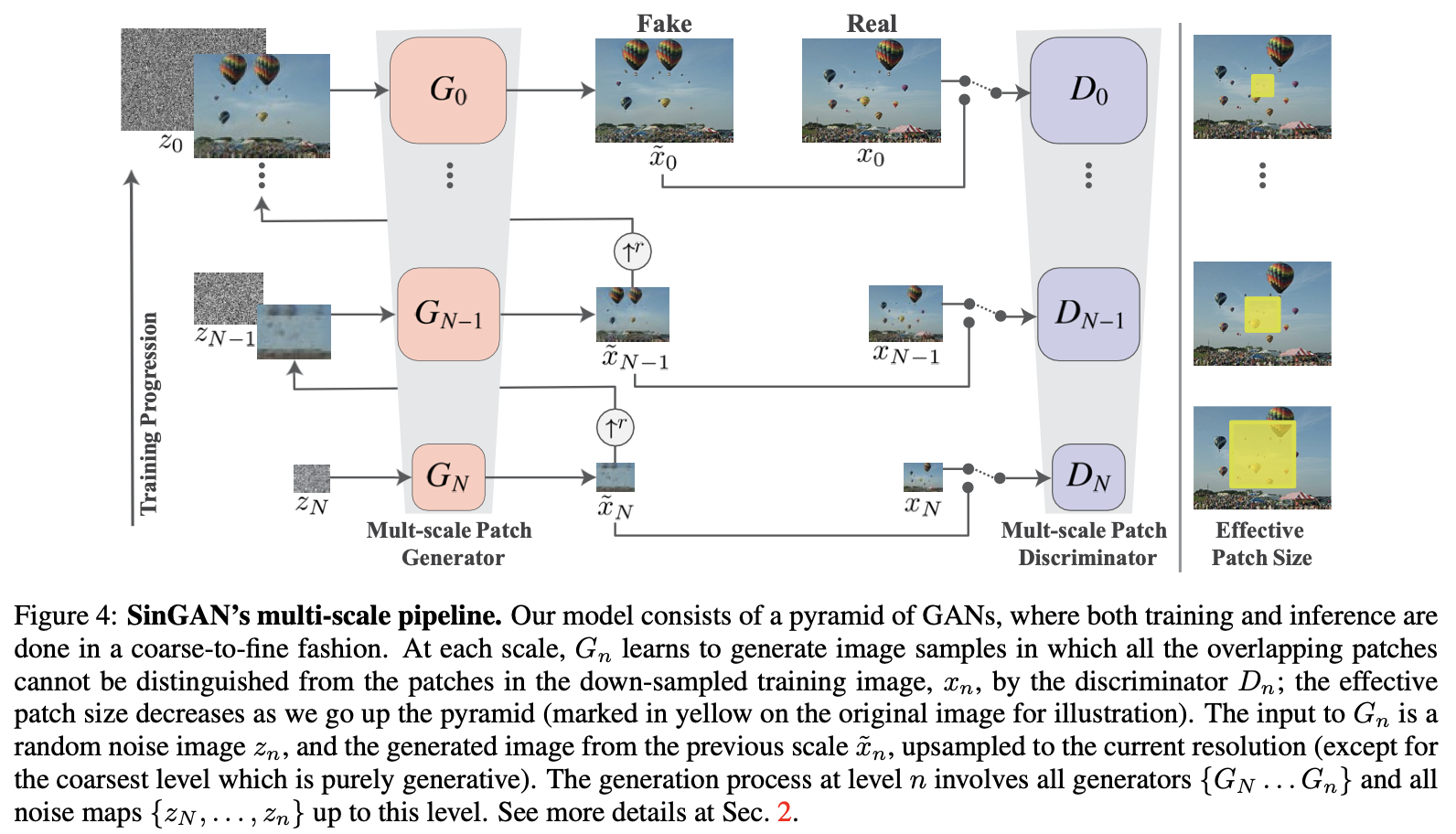
SinGANの構造は意外とシンプルです。
SinGANはN層からなるピラミッド構造になっており、図の下層から順に学習をしていき最後の上層でモデルの学習が終了するというものです。要は学習の段階がN段階のフェーズに分かれているような感じです。また各層で入力する画像のスケールが異なっており、小さいスケールの画像から徐々にスケールを大きくしていっているのが図からわかると思います。Gに入力するノイズ画像、Gによる生成画像、Dを学習する際に使用する本物の画像の全てが同一の層では同じスケールとなります。このような構造を取ることで、はじめの層では画像の巨視的な構造(大まかなレイアウト)を学習し、次のフェーズに進めていくことで細かい部分の学習が可能になっているそうです。
SinGANの構造についてざっくり説明すると、はじめのフェーズであるN層目は通常のGANと同様の仕組みで学習が進みます。変化があるのは次の層からです。N-1層目~0層目にかけては全て同じ流れとなりますが、前の層で生成した画像を現在のフェーズのスケールに揃え、入力ノイズと共に訓練データとしてGに学習させます。
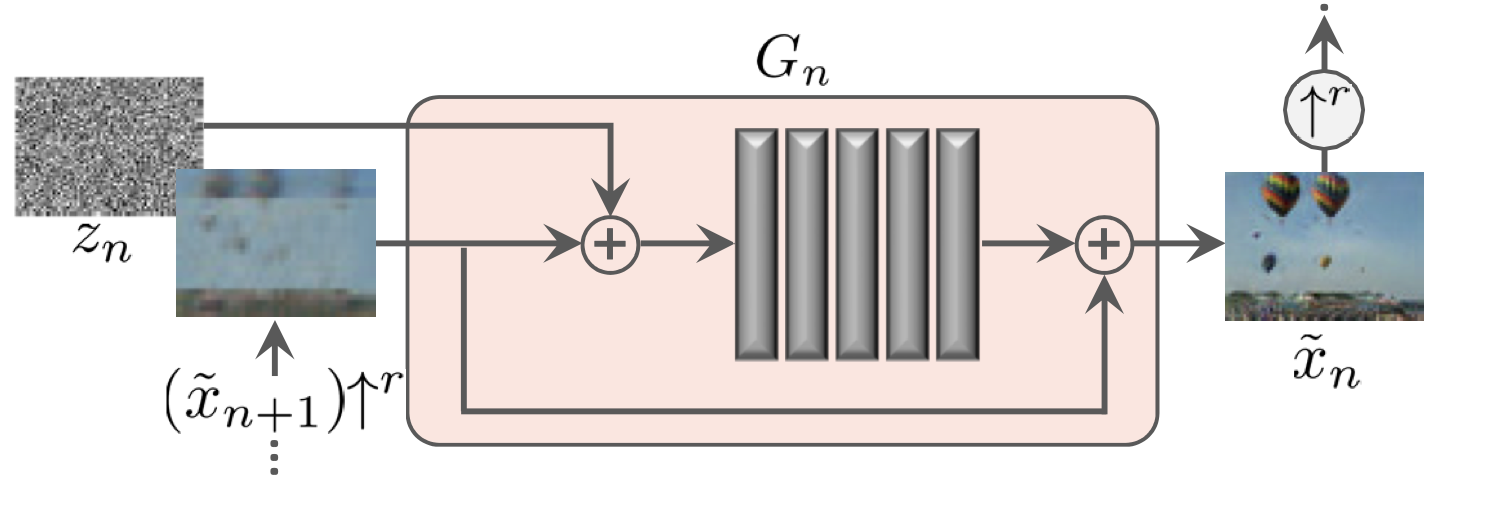
上記の図はGの構造を詳しく説明した図です。内部はConv+BN+LeakyReLUからなる5つのブロックを持つCNNで構成されています。ノイズ画像と前の層の生成画像を足し合わせてCNNに入力として与え、出力された画像にさらに前の層の生成画像を足し合わせています。CNNの部分で前の生成画像の欠如している詳細な部分を学習してくれるそうです。またノイズを各フェーズで加えることによってGANの学習で陥りがちなモード崩壊を抑えランダム性を担保しているそうです。
GANの損失関数
min_{G_n}\,max_{D_n}\;L_{adv}(G_n,D_n) + \alpha L_{rec}(G_n)
SinGANの最適化に用いられる式は上記のようになっています。Gはこの式を最小化しようと働き、Dは最大化しようと働きます。左の項はGANのAdversarial Lossで、WGAN-GPのLOSS関数を用いています。WGAN-GPはWGANに正則化の項を加えたものでこれにより学習が安定化しているそうです。右の項はReconstruction Lossと記載されており、N-1層目以降の入力にノイズを加えずに学習した画像と本物画像の2乗誤差をとっています。
WGAN-GPのLOSS (Adversarial Loss)
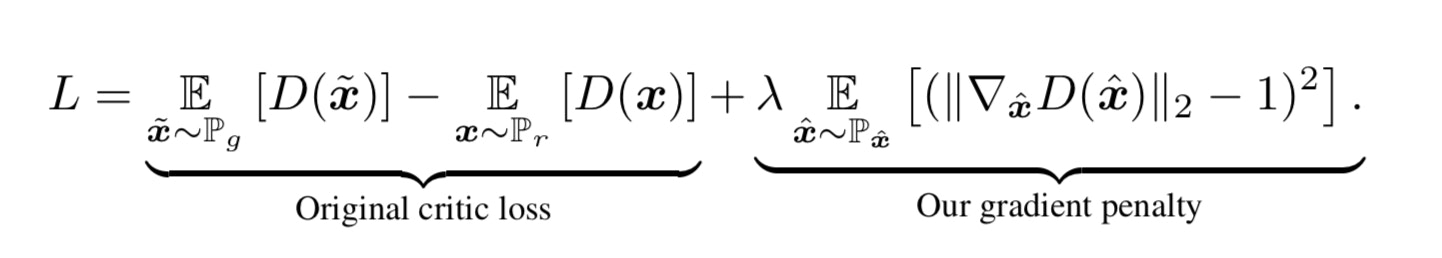
Improved Training of Wasserstein GANs
Reconstruction Loss
n < Nの場合
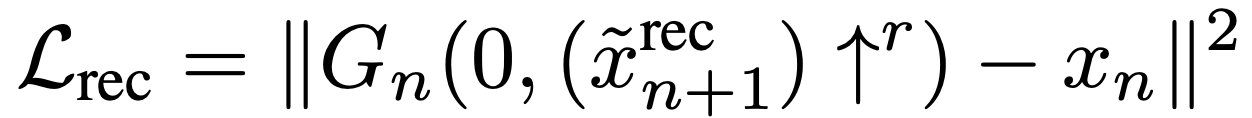
n = Nの場合
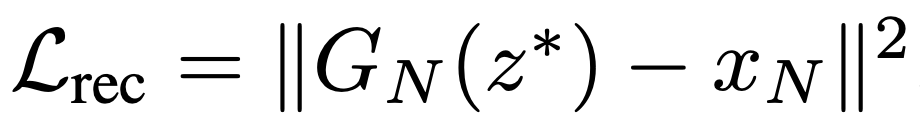
以上がSinGANの構造になっています。
画像生成に挑戦
論文の紹介はこのくらいにして実際にコードを動かしてみたいと思います。
と言ってもコードの説明となると長々しくなってしまうのでここでは実際にSinGANで画像生成に挑戦してみようと思います。
準備
著者のGitHubからPyTorchによるSinGANの公式の実装を取得することができます。この実装ではCUDAが使用されているのでGPU環境が使えるGoogle Colabratlyを使用したいと思います。
(1)google colabで新規のノートブックを作成してGoogle Drive上のフォルダを使用するために以下のコードを実行します。
from google.colab import drive
drive.mount('/content/drive')
(2)GitHubからGoogle Driveのディレクトリを指定してcloneします。
ここではclone先のフォルダ名をGitHubのレポジトリ名と同じSinGANとしています。
!git clone https://github.com/tamarott/SinGAN.git "/content/drive/My Drive/SinGAN"
(3)ディレクトリを移動します。
import os
os.chdir('/content/drive/My Drive/SinGAN/')
(4)最後にCUDAの設定です。
Colab上のランタイムタブのランタイムのタイプを変更をクリックし、ハードウェアアクセラレータをGPUに切り替えます。今回の実装ではPyTorchが使用されているので、PyTorchでCUDAが使用できるかを確認します。以下のコードを入力しTrueが返ってきたらOKです。
import torch
torch.cuda.is_available()
準備ができたのでいよいよ画像生成をしてみたいと思います。今回はSinGANで可能なタスクの中でも特に面白そうなランダムサンプリング画像生成、Animation生成そして超解像化に挑戦してみます。
ランダムサンプリング画像生成
ランダムサンプリングでは元画像と局所的に異なる画像を生成することができます。
事前に用意されていたシマウマの画像を使用したいと思います。
zebra.png

ランダムサンプリングにはまずモデルの訓練をする必要があるようなので、READMEを参考にして以下のようにNotebook上で実行します。自分で用意した画像を用いたい場合は/SinGAN/Input/Images/の中に用意した画像を移動して実行します。
!python main_train.py --input_name <画像名>
訓練が終了したらそのまま以下を実行します。
!python random_samples.py --input_name <画像名> --mode random_samples --gen_start_scale 1
--input_nameの後に先ほどと同様の画像名を入力します。
--gen_start_scaleはどのスケールから画像の生成を行うかというパラメータであり
今回は1を引数として与えて実行してみます。(0,1,2で試したが0と2は微妙だった)
画像生成自体は数秒ほどで終わります。
/SINGAN/Output/下に生成画像を格納するフォルダが自動で作成されています。デフォルトでは50枚の画像が生成されていたので代表として3枚の生成画像のみ示します。
【start_scale = 1で生成したシマウマ画像】



一見、何も変化が無いように見えますが、シマウマの模様に注目すると、所々模様が異なっているのがわかります。アハ体験です。
Animation画像作成
次にAnimation生成をやってみます。これは画像生成に使用する潜在変数を潜在空間内でランダムウォークさせ、画像を組み合わせることで作成しています。
事前にいくつかの画像が用意されていますが、ここではネットから用意した画像でやってみたいと思います。用意した画像を/SinGAN/Input/Images/内に配置します。

READMEを参考に以下をNotebook上で実行します。
!python animation.py --input_name <画像名>
【アニメーション生成結果】
左: start_scale=0 中: start_scale=1 右: start_scale=2



学習が終了するとOutputフォルダに、自動でいくつかのパラメータをふったアニメーションのgifファイルが作成されています。上記のようにstart_scale=0~2のものが生成されておりパラメータによってアニメーションの動きが異なっています。アニメーションの自由度は低いですが1枚の画像からこのようなアニメーションを作成できるのは非常に興味深いです。オーロラが動いているように見えなくもないです。
超解像化
最後に超解像化を行ってみます。
超解像化タスクでは事前に用意されている画像を使用して以下をNotebook上で実行します。
!python SR.py --input_name <画像名>
【超解像化の結果】
(左:訓練データ 右:生成データ)


ご覧のようにぼやけている部分が鮮明に補完された画像が生成されています。すごいです。
ただし他の画像ではうまく行かない場合もあります。
(左: 本物の画像 中: 訓練に用いるボケた画像 右: 生成画像)



この画像は著者がBSD100というデータセットで訓練を行った結果ですが、ご覧ようにゴツゴツした質感となり、超解像化はうまくいってません。他のタスクでも同様に画像によってはうまくいかないこともあるため、適応できる画像の幅を広げるのが今後の課題と言えそうです。
おわりに
SinGANは素晴らしい技術を手軽に体験できるGANで、触ってみて非常に面白かったです。
機械学習の中でもGANなどの生成タスクは非常に面白い分野だと思うので、今後も引き続き、勉強していこうと思います。最後まで見てくださりありがとうございました。