序 : プロセッサへの嫉妬
DRAMさん「最近みんなCPUやGPUにばかりうつつを抜かしやがって…。みんながやれRyz○nだの、FinFET ○nmだの盛り上がって、みんなが次世代プロセッサを楽しみにしている。新しいアーキテクチャやISAが出てきて話題も絶えない。」
DRAMさん「たしかによ…CPUはパソコンの花形だし、GPUの性能上げればゲームのグラフィックスがきれいになるよ。それに比べると俺は目立たない。」
DRAMさん「挙句の果てに、Memory wallだなんて言われて、CPUやGPUの足を引っ張る存在だと疎まれている。」
DRAMさん「だけど…だけど…俺がいなかったらパソコンは動かない…!それに、俺だって頑張ってる!お腹にviaを貫通させたりして、CPUやGPUの足を引っ張らないようにしている!」
DRAMさん「だから…だから…俺を…DRAMを…見てくれ…!!!」
対象読者
- DRAMオタクトークをしたい人
パソコンユーザーの皆様は、買うパソコンを選ぶときに、DRAM、すなわちメモリの容量を確認して、選定要件に入れるであろう。普通の使い方をしている限り、DRAMに関してはその容量が最も使用時のパフォーマンスに影響を与え、そしてそれ以外はまず問題になることはない。十中八九それは正しい。
だが、「今度DDR4からDDR5になって早くなるんだって」とか「LPDDRって何…?」とか「PS5のメモリはGDDR6らしいよ!(何…?)」とか、ちょっとオタクトークしたいときに容量以外の知識が欲しくなることがあるだろう。え?ない?そういう方はこの記事の対象読者ではないということですね…。でも、もし気になったならぜひ読んでみてほしい。人生に彩りを与えてくれるムダ知識を得られるであろう。
ちなみに私はDRAMやメモリコントローラの開発は一切やったことがないただのパソコンオタクなので、内容の正しさを保証はできないことは示しておく。
読んだ副作用
- 友達が減る
予め抑えておきたい単語
以下の単語に関してはいちいち説明しないのでググってほしい。Qiita内で良い記事があったらコメントを期待している。
- CPU
- ダイ
- 拡張カード
- FET(電界効果トランジスタ)
- プリント基板, PCB, printed circuit board
- はんだボール - 名前通りだが小さなはんだのボールである。なに?はんだ付けをしたことがない?フリー素材をぶつけてやる!(なお、筆者は中学生の時に半田ごてを手に落としてやけどをしたことがある。不安定なところではんだ付けをしてはいけない…。)

パソコンユーザーのためのDRAM入門 目次
- Part 1(本記事) : パソコンにおけるDRAM、DRAMの構造
- Part 2: 制御、パッケージ
- Part 3 : GHzへの挑戦、PCB
- Part 4(準備中) : マルチチャンネル、規格、未来
パソコンにおけるDRAM
まず、今回対象とするのは普通のパソコンにおけるメインメモリのDRAMである。おまけ話としてゲームとかGPUとかHPCとかに触れるかもしれないが、一応話の中心としてはパソコンのメインメモリとする。DRAM自体はただの記憶素子なので何にでも使えるのだが、話のまとまりを良くするために絞らせてもらう。
DRAMはDynamic Random Access Memoryの略であり、名前通り記憶素子である。電源を落とすと内容が消えてしまう揮発性メモリの一種であり、また、電源を入れていても無制御だと時間経過でデータが消えてしまうという特徴を持っている。しかし、高速で動作し、高密度に作ることができるために小さな部品で大容量であり、低コストで作れ、事実上書き換え回数に制限がない。
一般に使われているパソコンのコンピューターアーキテクチャ全体で見ると、DRAMというのは主記憶装置にあたり、CPUの仕事は事実上そのDRAMに読み書きすることがその多くを占める。処理するプログラムの読み込みは当然DRAM経由であるし、そのプログラムの命令も大半が演算かメモリIOであるのはもちろん、SSDなどのストレージへの読み書きも、ネットワークIOも、グラフィックスも、全てがDRAMを経由する。パソコンの中身の話をすると、どうしてもCPUのコアがその中心として語られがちだが、その能力を引き出すために圧倒的に重要な役目を担うのがDRAM、そしてDRAMとの出入り口にあたるメモリコントローラとCPU内のインターコネクション(要は通信システム)である。AMDのZen系アーキテクチャ(Ryzen, EPYC)が既存のものより強いと言われるのは、"Infinity Fabric"と名付けられているまさにこのインターコネクションのおかげである。言ってしまうと、パソコンというのはDRAMを中心に動いているのだ。
さて、そんな超重要なDRAMであるがゆえに、それをどのようにシステムに接続するかはアーキテクチャレベルでも多くの変化があり、そして今も変化し続けている。軽くその流れを追ってみよう。ぜひ メモリコントローラ の周辺に注目してみてほしい。
i386(1980年代) 牧歌的なシステムバスの時代
"i386"という単語は一昔前にLinuxをインストールしたことある人ならしょっちゅう目にしていたであろう。いわゆる32bit版のLinuxディストリビューションにつけられていた名前であるが、その由来はi386(Intel 80386)と呼ばれるプロセッサの名前である。Intel x86 PCの時代のマイルストーンとなった偉大なプロセッサである。今のx64 ISA(AMD64,EM64T)にも当時のアーキテクチャが息づいている。さて、当時のDRAMはどのようにつながっていたのだろうか?
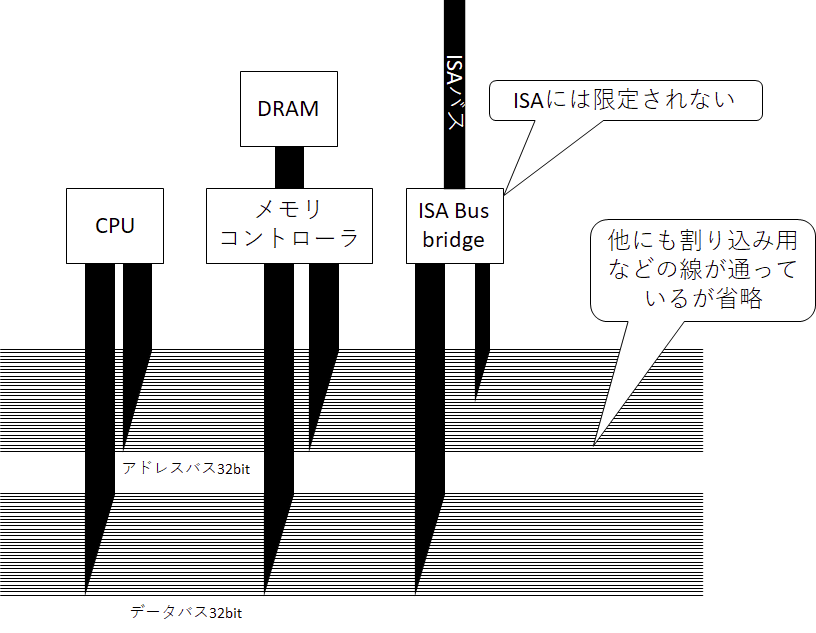
ざっくり図示するとこの様になる。システム全体を貫くバス(アドレスバス、データバスなど)があり、CPUやメモリコントローラ、IO(代表的なのはISAバス)などがつながっている。この共通のバスをシステムバスやメモリバスなどと呼んでいた。当時のコンピューターではCPUやDRAM、各種IOが共通のシステムバスにつながっており、CPUから共通のアドレス線、データ線を通してDRAMやIOを制御していた。今回はパソコンがテーマなのでi386をとりあえず出してきたが、それよりも前からあり、そして今でもマイコンとかでは使われている、教科書の序盤で出てくるような単純で低コストで使える方式である。
バスというのは複数本の導線を束にしたものであり、そこに接続された部品は線に電気を流して送信したり、電圧を読んで受信したりする通信方式である。全員互いの声が聞こえる狭い会議室で会話するような仕組みだ。ただ、バスには同時に1つの信号しか通すことができないという問題がある。CPUからDRAMに書き込むのと同時にIOからキーボード入力を読み取ったりすることはできないということだ。そして、バスには設定された固有の周波数があり、そこにつながった部品は同じ周波数で通信することになるという大きな問題がある。i386時代の牧歌的なシステムは IOとメモリとが同じ周波数でつながっていた わけである。今のパソコンからは考えられない(色んな意味で)。
i486(1989年) 狂気のVLバス
さて、前述のi386では、グラフィックスや各種追加のIOボードなどを繋げるために、ISAバスを別で設けてそこに橋渡しするISAバスブリッジを設けて使われていた。ただ、ISAは遅く(16MB/s)これに代わる手段が色々模索されていた。そして、出てきたアイデアが、まさかのシステムバスに拡張カードを直結するという手段である。 まさに狂気…!
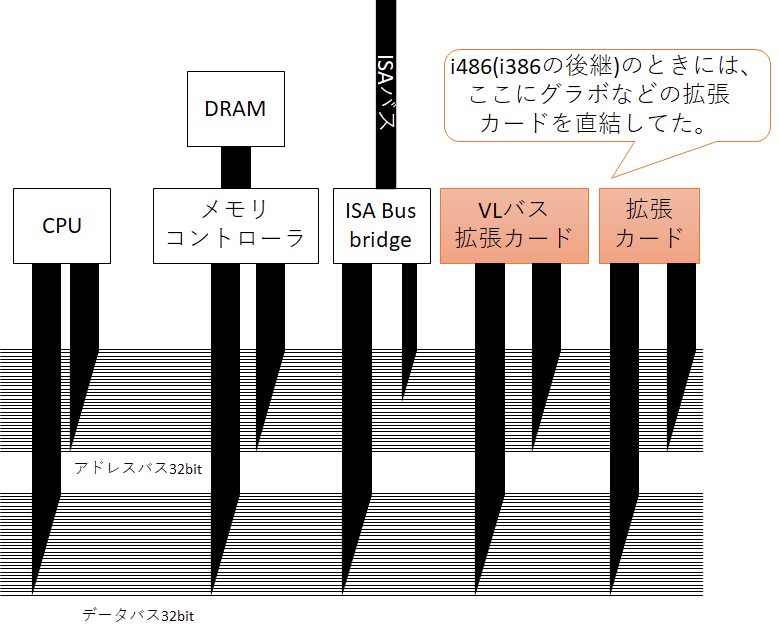
i386の後継のi486ではこのシステムバスに拡張カードをほぼ直結するVLバスというものも使われていた。バスという仕組みの特徴としてバスに多くの機器がつながっていると、それだけバスに高い周波数を通すのが大変になるために、つなげる機器を増やすには周波数を落とさなければならない。性能と拡張性のトレードオフが生じるのだ。ただ、拡張性が低くても、VLバスは仕組みが単純だったので、とりあえずのつなぎとしては機能し、システムバス直結なので当時としては高速だったらしい。うーん、ロックだ。ちなみに、このVLバス向けのカードはi486と密結合であるために、以降のプロセッサでは結局中継のチップが追加で必要となる。さらには規格破りの製品が出回り不安定だったなどといろいろと問題を抱えてしまった。この辺りは下記のASCII.jpの記事に触れられている。興味のある人はぜひご一読を。
Pentium(1993年) PCIの登場とOver 100MHzの時代の到来
ここまでのアプローチの根本的な問題点は拡張カードなどのIOをシステムバスにつなげようとしていた点である。このころはCPUの速度が著しく向上しており、100MHzに到達しようとしていた。こうなるとそのバスを伸ばして、他のデバイスをつなげるということ自体に無理が生じてくる。高周波の通信は設計がよりシビアになり、自由にその途中に拡張カードを追加していくということが難しい。100MHzというのは自由に分岐して通信するのが難しくなる境界の目安ともいえる。ちなみに、さらに速くなりGHzになるともPCB上の信号の波長が20cmを下回ってくるため、1クロックの間にマザーボードの端から端まで信号が届かない。これではまともなバスアービトレーションは困難であり、かなりのクロックをそれに割く必要がある。遅かれ早かれ、メモリ直結のバスは捨てる必要があったということだ。
さて、これまでの問題を解決するために、まともに標準化されたCPUアーキテクチャに非依存なオンボードのバスとしてPCI(Peripheral Component Interconnect)が新たに提案された。皆様ご存じ、結果としてPCIは後継のPCI Expressに交代するまで拡張ボードのインターフェースとしての覇権を取ることになる。PCIはシステムバス(ホストバス)と分離したバスであり、つながり方という視点ではISAと同様である。
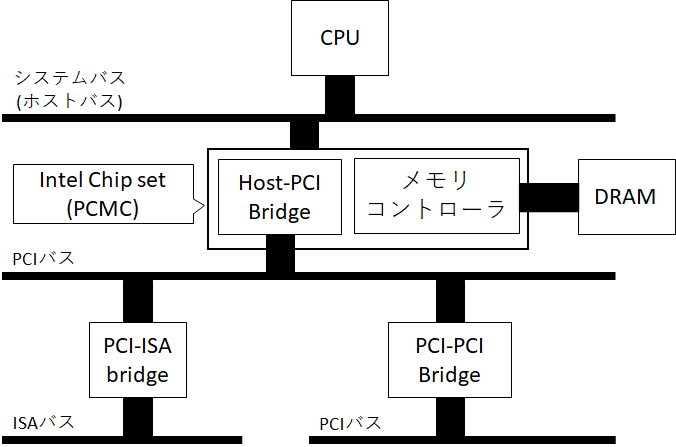
システム全景としては上のような感じになる。システムバスにHost-PCI Bridgeがぶら下がり、PCIバスとつながる仕組みになっている。PCIバスに直接つなげられる機器数には上限があるので、場合によってはPCI-PCI BridgeでさらにPCIバスが分岐している場合もある。また、これまでシステムバスにつながっていたISA BridgeはPCIデバイスの一つとしてぶら下がったPCI-ISA Bridgeがその役目を担うことになる。
Host-PCI Bridgeは具体的にはチップセットの1機能として提供されており、例えばIntel 82434LX PCMC(PCI, Cache and Memory Controller)であれば、メモリ、キャッシュコントローラと一緒になっている。メモリコントローラが独立ではなくチップセットに内蔵されたのは、一つの変化ではあるが、対CPU通信にシステムバスを利用しており帯域を共有しているというのは前と変化がない。ただし、システムバスにつながる機器が制限され、また拡張用の外部バスとして利用されなくなったため、今後、このシステムバスの周波数やビット幅などを増やして高速化していけるようになった、という点で将来に向けた大きな布石となっている。
Pentium Pro(1995年) P6マイクロアーキテクチャの衝撃
1995年に登場したPentium ProではP6マイクロアーキテクチャが採用され、CISC命令をRISC μOPsに分解する仕組みやアウトオブオーダー実行、投機実行などのモダンな仕組みが投入された、今につながるx86系マイクロアーキテクチャの元祖である。そして、その変化はCPUの命令実行だけでなく、バスにも及んでいる。バスがBack-side busとFront-side busに別れたのである。
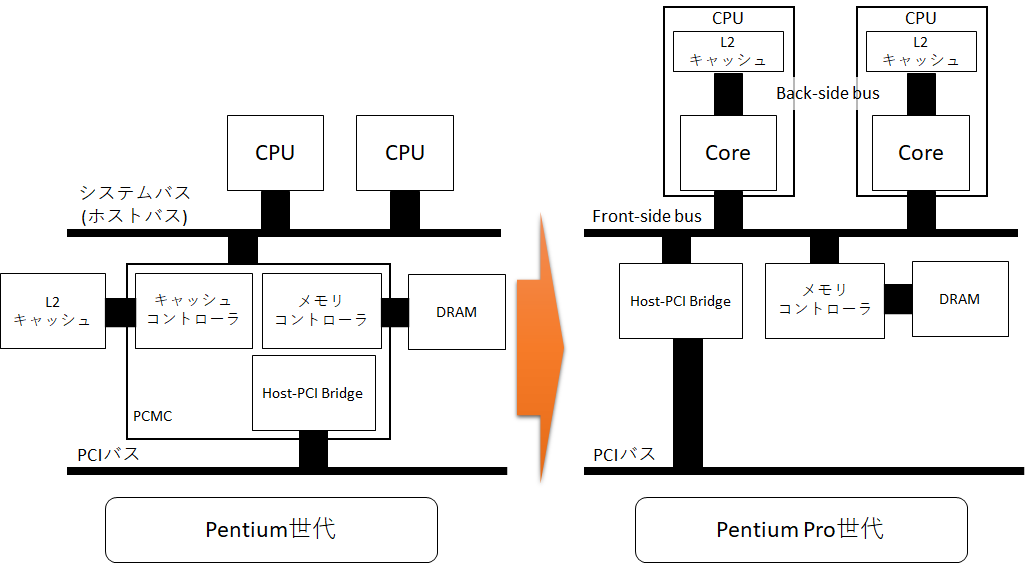
図がごちゃごちゃするので、前の図では省いたのだが、Pentiumのときにはチップセット(PCMC)にキャッシュコントローラーが入っていた。まあ名前通りである。そして、このころからマルチCPU構成が可能だった。キャッシュはDRAMのキャッシュであり、DRAMより高速であるが小さいSRAMで作られたキャッシュにデータを一時保存することで、CPUの動作をより高速にするものである。だが、そのキャッシュが遠くにあったのではそのメリットも台無しである。しかもマルチCPU構成だと、2つのCPUが同じキャッシュを使うことになってシステムバスが込み合う。
そこで、CPU内にキャッシュをもたせ、CPUの外に出るシステムバスより高速なCPU内で完結するBack-side busを設けそこにキャッシュをつなげたのである。キャッシュとDRAMには速度差があることを考えると、それらとの通信方式にも速度差がつくのはアーキテクチャとしては自然な変化である。なお、Back-side busは最初はオフダイ、すなわちダイの外のバスだったが、割とすぐにキャッシュがダイに統合されて消滅したために、Front-side busだけが残って「Frontって何?」という感じになってしまったり。
ここまでの流れを追っていくと、要は最初は原始的な一気通貫した通信システムだったが、高速化に伴ってパソコン内部の各部の速度域に差が出始め、それに伴い通信系も徐々に分化していっているのだ。
Athlon 64(2003年) AMDの起こした革命とHyperTransport
Jim Keller、彼はマイクロアーキテクチャに興味がある人が知らない人はいないであろう伝説的なエンジニアである。彼の偉大な仕事は数多いが、その中でも代表とされるのがAMD在籍時に開発にしたAthlon 64を代表とするK8マイクロアーキテクチャである。これは今の「パソコン向け64bit CPU」であるAMD64アーキテクチャを採用したCPUの元祖であり、そして「CPUやメモリがどのように接続されるか」という点で大きな革命を起こした。
CPU大辞典じゃないのでここまでAMDのプロセッサの説明をすっ飛ばしてきたが、Athlon 64より前はIntelとほぼ同様にFSBとしてEV6バスを使用して、そこを通してメモリコントローラもつながっていた。ただ、これはメモリIOとPCIなどの他のIOが同じバスの上に乗っている上に、マルチCPUの際の大きなボトルネックとなる。(EV6はPoint-to-pointであり共有型じゃないが、チップセットがボトルネックとなるという意味ではほぼ同じである。)高クロック化、マルチコア化に伴いCPUによるメモリIOの要求スループットはどんどん増えていき、メモリコントローラがCPUの外側にあるということ自体がシステムの性能に限界をもたらすようになってきた。
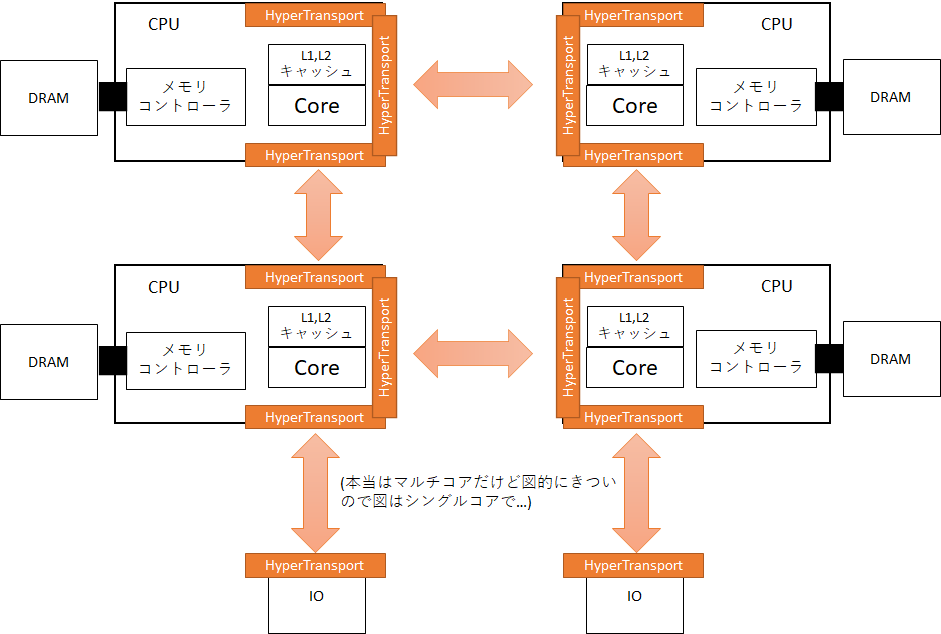
そこで、AMDはAthlon 64世代でメモリコントローラを直接CPUに組み込むという手段をとった。そして、FSBに相当する部分にHyperTransportという新しいインターフェースを搭載した。このHyperTransportは主にマザーボードのようなPCB(printed circuit board,プリント基板)上での通信のためのインターフェースで、Athlon 64ではチップセット、すなわちPCI/PCIeなどのIO向けチップとの通信の1つのHyperTransportポートのみがあるが、サーバー向けOpteronには3つのHyperTransportのポートが用意されている。そして、HyperTransportによって受信したパケットを適切な宛先に転送するクロスバスイッチが搭載されている。これにより、複数のCPUをつなげることで統合し、あるCPUから他のCPUに接続したメモリを読み書きすることができる。そう、HyperTransportはマザーボードの上に超広帯域ネットワークを形成することで、スケーラブルなcc-NUMAを実現しているのだ。cc-NUMAに関しては私の指導教員の資料などを参考にしてほしい。
Athlon 64といえば周波数向上に頼った性能向上からクロックあたりの性能向上へのパラダイムシフトを先導したプロセッサとしてその性能面に注目が集まったが、今から振り返るとそのスケーラブルなアーキテクチャは確実に10年以上先を見据えていたと言っていいだろう。これぐらいの時期からメモリ帯域がボトルネックとなるMemory wallが表に出て、皆が頭を抱える問題として今も横たわっている。これを解決する1つの策としてメモリコントローラ内蔵とプロセッサ間の相互結合というスケーラブルなアーキテクチャは今でも有効である。この発想は世界最速のスパコン「富岳」のプロセッサ、A64FXでも生きている。HBM2(DRAM)と直結したCMGを1つのダイに4つ載せ、それらをリングネットワークでつなぐことで1つのダイから1TB/sというとんでもないメモリ帯域幅を確保している。
ただ、このK8の成功の後、数年もするとAMDはシェアを落とし始め、冬の時代が到来することとなる。AMD再興には現AMD CEOであるLisa Su氏とJim Keller氏の復職を待つ必要がある。
Nehalem(2009年) QPIの登場とIntelのメモリコントローラの統合
AMDがメモリコントローラを統合後も、しばらくはIntelはメモリコントローラをチップセットに置いていた。正直私はよくわかっていないのだが、IntelはNUMAではなくUMA(すべてのメモリへのアクセス遅延が均一であること)であることにこだわりを持っていたらしい。IntelはMemory Controller Hub(MCH, 要はノースブリッジ)を介してCPUとメモリを仲介するという仕組みを採用していたために、マルチCPU環境において大きなボトルネックを抱えていた。
そんなIntelもNehalem(Intel Core iブランドにおける初代相当)でメモリコントローラをCPU側に内蔵して、外部バスに相当する部分をQPI(QuickPath Interconnect)に置き換えた。アーキテクチャ的にはHyperTransportとほぼ同じなので図や説明は省略する。
Zen(2017年) AMDの起こしたさらなる革命
メモリコントローラがCPUに内蔵されてしまうと、ほぼそのまま「そして現在に至る」という感じなのだが、CPUの中でも変化は当然起きている。シェアを落とし息が絶えそうだったAMDから出てきた"Zen"マイクロアーキテクチャとRyzenはこれまでのHyperTransportを進化させたInfinityFabricを登場させたのだ。もちろん立役者はJim Keller、彼が帰ってきたのだ!
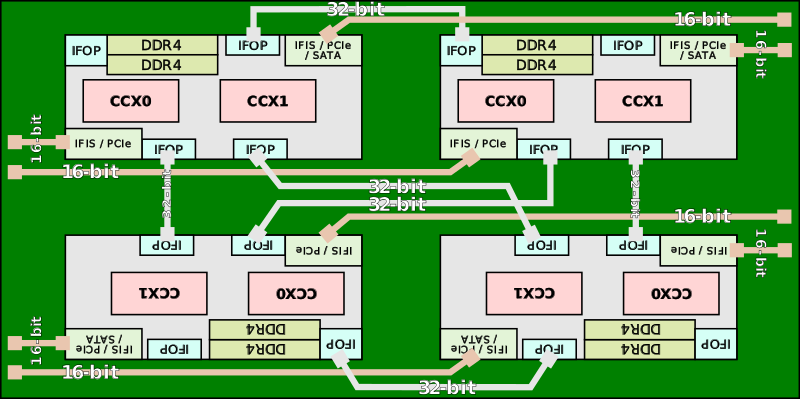
https://en.wikichip.org/wiki/amd/infinity_fabric より引用
この辺りで私の作図能力を超えてくるので、WikiChipから引用させてもらった。そして、ぜひこのWikiChipも参考としてほしい。図での緑がpackage substrate、要はCPUパッケージの基板であり、グレーがその上に載っているダイである。性能面での向上は14nm FinFETを使えるようになったからという面がかなり大きいのだが、InfinityFabricと洗練されたレイアウトによって同じダイを1,2,4枚組み合わせることで、柔軟な製品ラインナップを実現する。DRAMコントローラはInfinityFabricの重要な構成要素であるSDF(Scalable Data Fabric)につながっており、ここはメモリと同じクロックで動いている。そして、それぞれのダイにコントローラが存在する。細かい説明はしないが、要は1つのパッケージ内でNUMAが構成されるようになった。もちろんこれによって癖が出るのだが、スケーラビリティの高い設計であるといえるだろう。
このように複数のダイを1つのパッケージに収めることをMCM(Multi-Chip Module)などと言ったりする。本筋とは関係ないが、今後のデジタル半導体においてこのMCMパッケージング技術は確実にカギになってくるので、オタクトークをするときに頭に叩き込んでおくとよいだろう。
Zen2(2019年) chipletとIOダイ
AMDはZen,Zen+をさらに改良したZen2を出した。ここでの大きな変更はコアのプロセスルールが7nmになり、IOのプロセスルールが12 or 14nmになったことである。そう、コアとIOのダイが分かれたのである。ちなみにコアはTSMC、IOダイはGlobalFoundriesの製造である。

https://www.microway.com/hpc-tech-tips/amd-epyc-rome-cpu-review/ より引用
Zen2では上図の用に小さなコア用のダイとメモリコントローラなどを内蔵したIOダイが組み合わせて、パッケージに収められている。Zen,Zen+で一旦は分散したメモリコントローラがまた統合されたのである。ちなみにこの小さなコアのダイをAMDは"chiplet"と呼んでおり、より柔軟な構成選択が可能となっている。
「DRAM」の仕組み
DRAMとその周辺の構成要素
ここまで長々とDRAMがシステムとどう繋がっているかを説明してきた。ただ、肝心のDRAMに関してほぼ一切の説明をしていない。というわけで、DRAMの説明に移ろう。
まずは「DRAM」と言って想像する具体的なもののすり合わせをする必要がある。というのも、一般にパソコン向けのDRAMは周辺回路も一緒にモジュール化された「DIMM」と言った形式で売られているために、DRAMという言葉でDIMMを指すことのほうが多いからである。というわけで下図に名称を示した。名付け問題なので、これが常に正しいというわけではないのだが、この記事中ではこの呼び方で説明する。
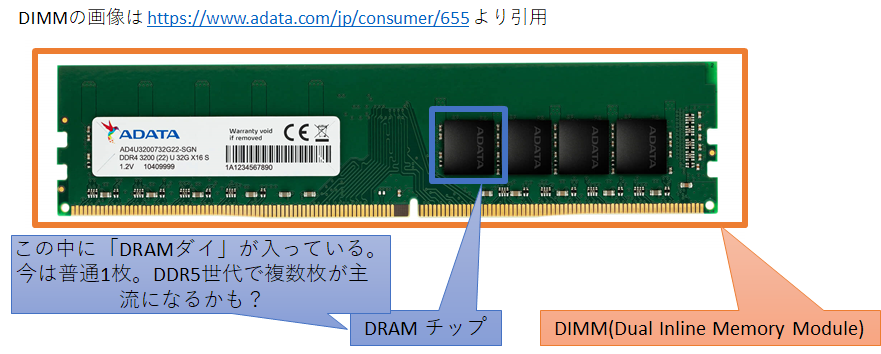
パソコン向けDRAMは通常PCBにDRAMチップを初めとした半導体部品やチップ抵抗などを取り付け、DIMM(Dual Inline Memory Module)という形で規格化されたパッケージとして扱われる。なお、ノートパソコン向けはいろいろ事情が違うのだが、それは後ほど。最近のDRAMチップであればパッケージの裏面に細かい間隔ではんだボールが付いたFBGA(Fine pitch Ball Grid Array)でDIMMのPCBと接続されている。興味がある人は要らないDIMMからDRAMをはがしてみるといいだろう。部品の故障を考えず単にはがすだけなら250度近くまで加熱すれば、大抵の組成のはんだボールを溶かせる。すべてではないが、多くの家庭用オーブンレンジでも出せる温度だ。 **やけどに注意。**このDIMMをマザーボードのDIMMスロットに取り付ける。マザーボードの配線は最終的にメモリコントローラにつながっており、最近であればそれはCPUソケットを経由してCPUに内蔵されたメモリコントローラに直結している。
この「メモリコントローラ」がDRAMにおける鍵である。DRAMチップはフルでCMOSで組まれたいわゆるロジックチップとは異なり、それ自身には細かな制御機能は持たせていない。外からタイミングよくコマンドなどを入れることで、データを書き込み、読み取り、消去ができるというチップである。タイミングがずれるとデータが消えてしまったりする。いわゆるメモリオーバークロックでは、このタイミングを切り詰めることで高速化を狙っているのである。と言っても、この記事はOCの記事じゃないので、そこは細かく説明しない。
DRAMチップの構造
では、DRAMチップにはどのような信号を入れるのだろうか?そのためには、ある程度DRAMチップの内部構造に触れる必要がある。DRAMチップの外観は先の図のとおりであるが、中には何が収まっているのだろうか?

https://www.techinsights.com/ja/node/30162 より引用
デデドン!という感じで画質が低い写真を載せたが、高解像度な画像は残念ながらここには載せられない。これはMicronのDRAMチップに収まっているDRAMダイの写真、すなわち"die shot"であるのだが、この写真を取るだけでもかなりの手間ひまがかかる。解像度が高いものであればより高い倍率を持った顕微鏡を持っていないと撮影できないし、そもそも最近の半導体部品は表面だけ可視光線で見てもなんにもわからないことが多いため、X線を用いて画像を得ている場合も多い。さすがに自宅でX線が取り扱える人は皆無であろう。高解像度のdie shotはそれ自身に商品価値があるものなのだ。まあ研究室に落ちている設備でもうちょいマシな解像度を見せられなくもないのだが、この記事のために勝手にバラしたり色々するのはまずいので、国内でこのような分析をやっているテカナリエ社の動画を掲載しておこう。雰囲気がわかると思う。(というか、この記事に高解像度die shotは必要がない)
さて、シリコンでできたダイに回路が焼かれていることが分かったとして、肝心なのはその中身である。最先端のプロセスを肉眼でリバースエンジニアリングして理解するのは人智を超越しているので、データシートを見てみよう。このあたりはMicronのデータシートが図が豊富でわかりやすい。現役最新世代のDDR4 SDRAMの8Gb(1GB)チップのデータシートを使う。
ここのP.22にFunctional Block Diagramsがあり、いくつかの構成例が例示されている。この中から多分パソコンでよく使われているデータピン8bitのものをピックアップしてみよう。要は1ランクあたり8枚のDRAMチップを使うときに採用するDRAMチップである。
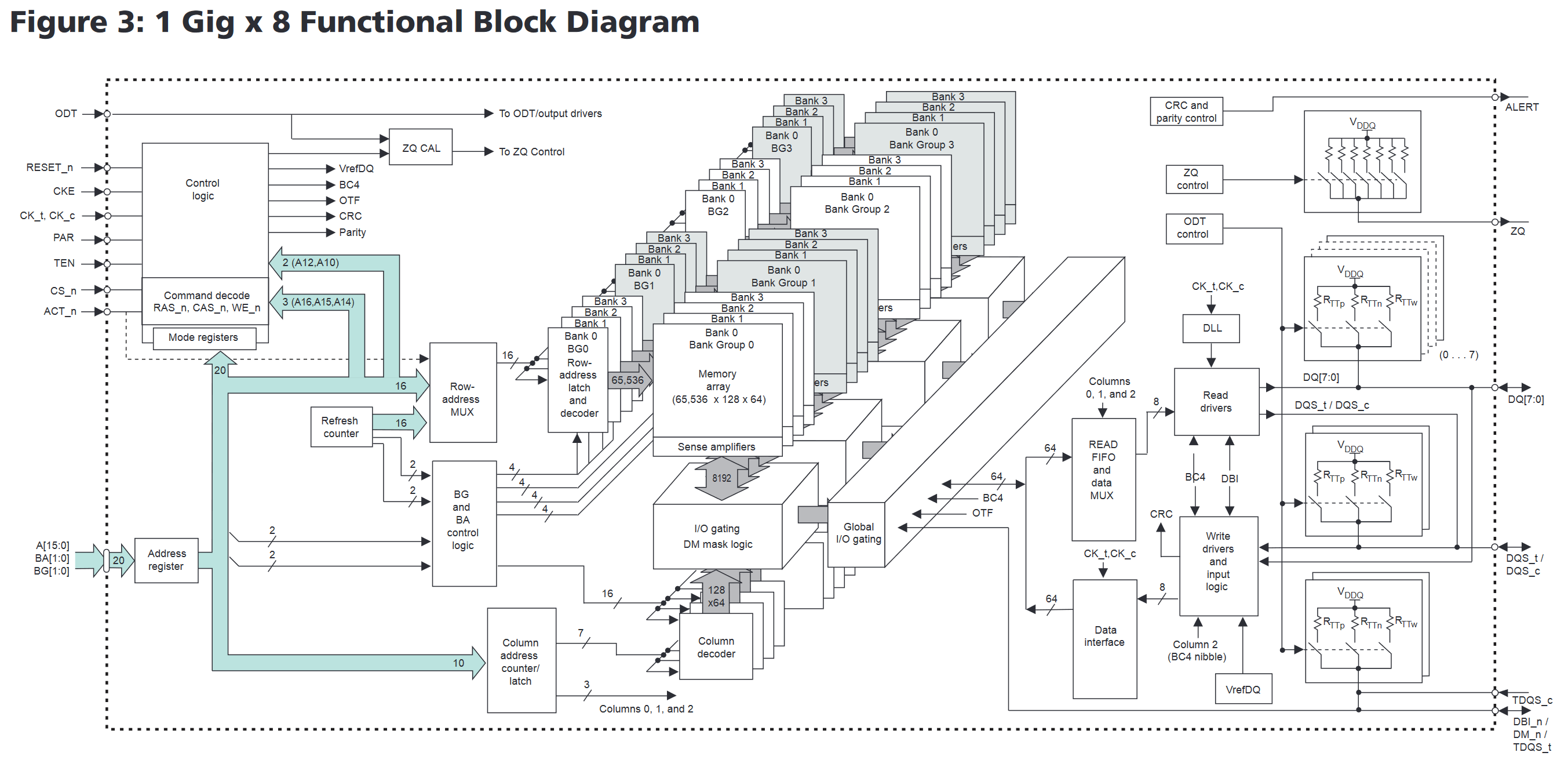
なんじゃらほい、という感じなので、ちょっとだけ説明を足す。なお、外枠から外に伸びている線が最終的にDRAMチップの裏側のはんだボールに繋がっており、そこから最終的にはメモリコントローラに接続されている。どう繋がっているかも後ほど説明する。
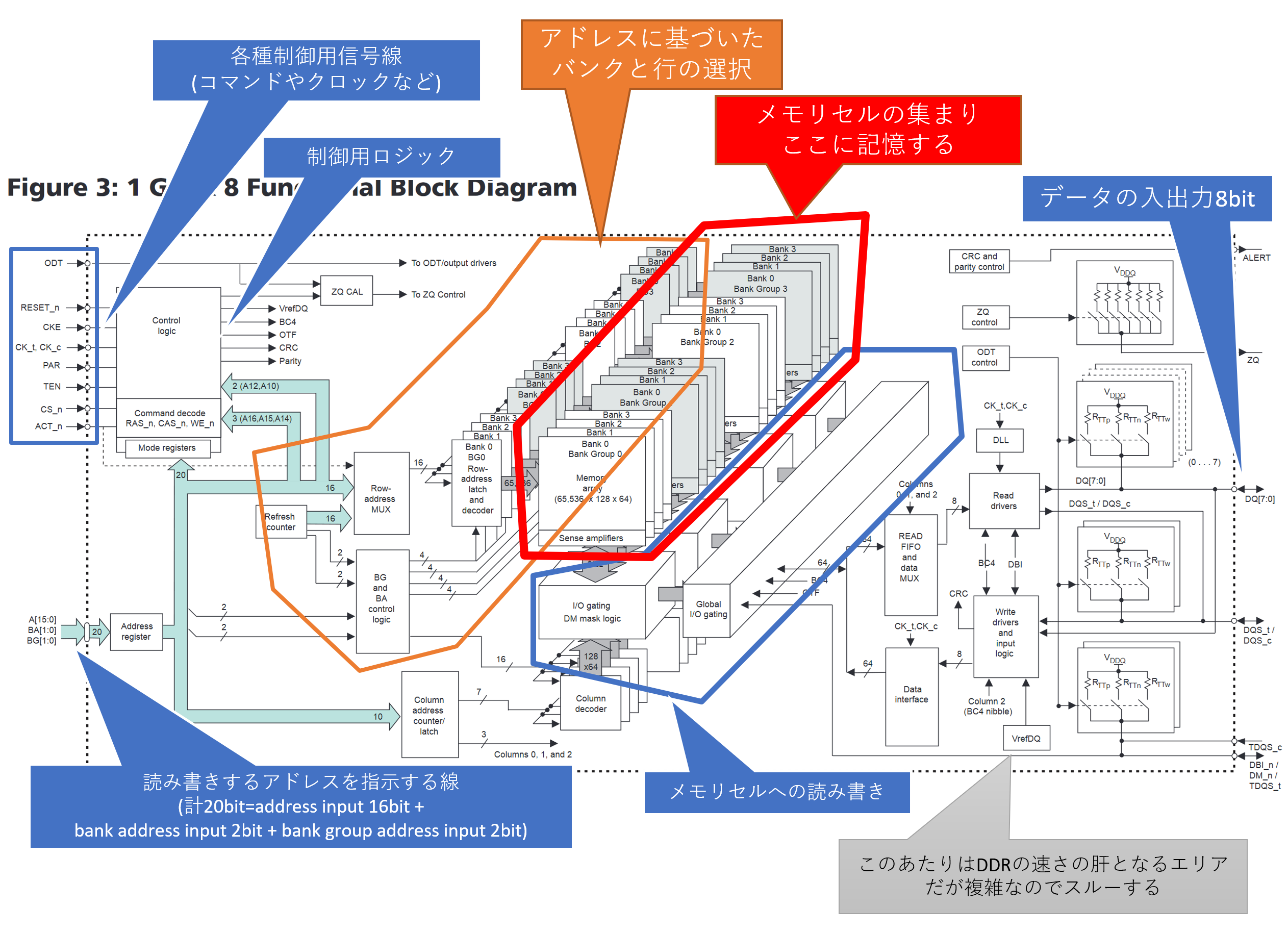
赤枠で囲ったバカでかいメモリアレイの周りに、それを読み書きするための周辺回路がひっついている感じである。ちなみに、先のdie shotで確認できるパターン模様はほぼすべてこのメモリアレイである。DRAMダイの面積はほとんどその全てがメモリアレイである。まあ記憶素子なので当然といえば当然なのだが。
仕組みをとんでもなく単純に説明すると、書き込むときには書き込みコマンドとDRAMにアドレス、すなわち場所と書き込みたいデータをデータピンに入れ、読み取りたいときには読み取りコマンドとアドレスを与えると、データピンからデータが出てくるという寸法である。DRAMとかコントローラ作ってる人からすれば「いや、そんな簡単なら苦労しねえよ!プリチャージとかリフレッシュとかどうすんだ!」とか突っ込みが入りそうだが、ひとまずは落ち着いてほしい。話には順序がある。まずはメモリセルの話をする必要がある。
DRAMのメモリセル
先の図の"Memory array"となっている部分が記憶する部分だといったが、具体的にはどのように記憶しているのだろうか?…といっても、ここまで読み進めてきている人に対しては愚問だろう。キャパシタ、すなわちコンデンサに電荷を蓄えて記憶している。そして、これは時間が経つと消えてしまうためにリフレッシュする必要があり、ゆえに"Dynamic RAM"なのだ、と。この辺りはDRAMでググれば即座に出てくる知識なので、Wikipedia冒頭などを読めばわかるだろう。
では、そのキャパシタはどのように接続されているのだろうか?まずは電子回路的な面から説明しよう。メモリセルの回路図をまず以下に示す。
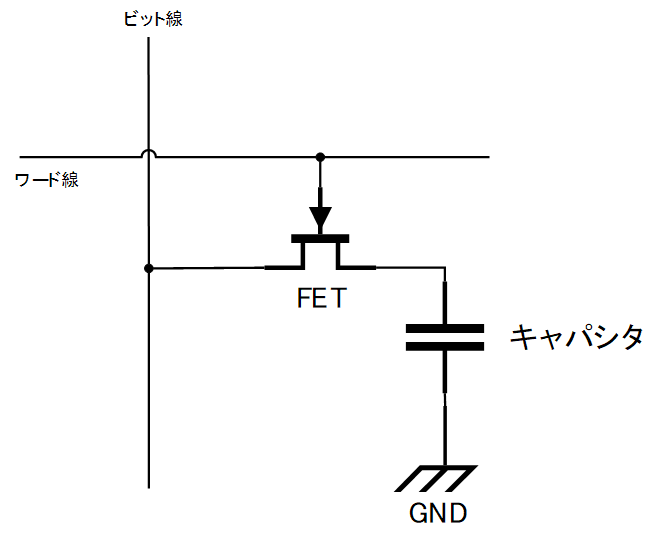
(ツールの都合でFETの記号が後述のものと違うがこれはnMOSである)
このメモリセルは1bit記憶できるもので、ビット線、ワード線、キャパシタ、FET(トランジスタ)で構成されている。ワード線に電圧が印加されるとFETによりキャパシタとビット線がつながるため、それを利用して読み書きするというわけである。そして、これがめーっちゃめちゃめちゃめちゃいっぱいつながっているのだ。
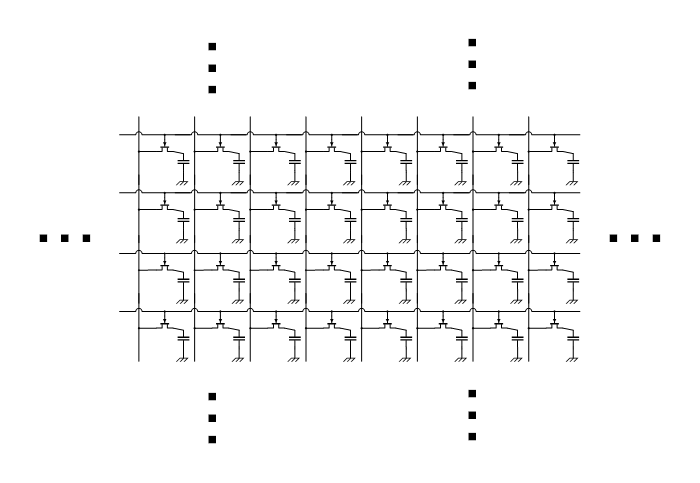
図に示したように、ビット線とワード線がグリッド状に並んで結合されたメモリセルの集まりといくつかの周辺素子をひとまとめに「バンク(bank)」または「メモリバンク(memory bank)」と呼ぶ。ここで要注意なのだが、DRAMチップを指して「バンク」と言ったり、DIMMの片面を指して「バンク」と言ったりすることがあるが、 JEDEC規格に従ったDRAMにおいては 、それらはバンクとは呼ばないので注意してほしい。逆にJEDEC規格にの外に出てしまえば「メモリバンク」という単語の意味はメモリ管理単位以上の厳密な意味がないため、きちんと事前に単語の意味をすり合わせる必要がある。言葉の意味を明瞭にするという意味でも規格というのは大変重要だとわかる。もし、DRAMの実物を指差して「これがメモリバンクで~」と言ってたら、そっとドヤ顔をしながら 「JEDEC規格によればバンクというのはDRAMチップの中にある更に小さなメモリセルの管理単位で~」 とオタクトークを炸裂させよう。 友達が一人減ります。
まずは読み取りである。DRAMのバンク操作は1行ずつ行う。その行を選択するのが先の図で横方向に伸びていたワード線である。そして、対象とするメモリセルは以前に書き込んだ値に応じた電荷が溜まっているのだが、メモリセルはめーっちゃめちゃめちゃめちゃ小さいので、満充電でもロジック回路を動かせるほどの力を持っていない。というより、根本的にキャパシタは継続した電圧源でないためにMOSFETをまともに駆動させられない。そのため、無造作にワード線をHighにしようものなら、データは消えてしまう。また、時間経過による電荷の流出もある。微小な電荷の違い、すなわちキャパシタの電圧を検知する仕組みが必要なのである。そこで出てくるのが、先のデータシートにも見えている"sense amplifier"である。
最先端DRAMでも同じ回路を使っているかは怪しいが、一般的なsense amplifierの仕組みについて説明していく。ただ、その前段として、CMOSによるinverter(NOT回路)を説明する必要がある。一気に半導体のアナログレベルの挙動まで降りていくが、ぜひ少しだけお付き合いいただきたい。
閑話休題 CMOS入門
CMOS(Complementary MOS, 相補型MOS)は昨今のデジタル半導体のほとんどで使われている技術であり、最先端として話題になる5nm FinFETやGAA FETもCMOSを形成するためのMOSFETの一種である。そして、プロセッサだけでなく皆が目にするDRAMのほとんどがCMOSだし、フラッシュメモリもCMOSだし、カメラのイメージセンサーも今はCMOSのものが主流であり、文字通りCMOSなくして現代の社会はありえないといっても過言ではない。
CMOSはその名前通り、2種類のMOS、nMOSとpMOSを相補的に用いて作られる回路及び部品である。なお、MOSと書いたが正確にはMOSFET(metal-oxide-semiconductor field-effect transistor, 金属酸化膜半導体電界効果トランジスタ)のことを意味している。個人的にはどう考えても"FET"の方が大事な部分だと思うのだが、略されると大事なところが消えるというのはよくある話である。これまた、私の指導教員のとある授業の1回目にMOSFETと今回扱うCMOSによるNOTゲートの解説があるので、ぶっちゃけこれさえ読めばバッチリなのだが、ここでも軽く解説する。
MOSFETには電気的な特性が反対なnMOSとpMOSがある。電子がキャリアとなるN型半導体が拡散層に使われているのがnMOS、正孔(電子ホール、)がキャリアとなるP型半導体が拡散層に使われているのがpMOSである。半導体そのものの細かい話は別で調べてもらうとして、回路記号で表すと以下のようになる。
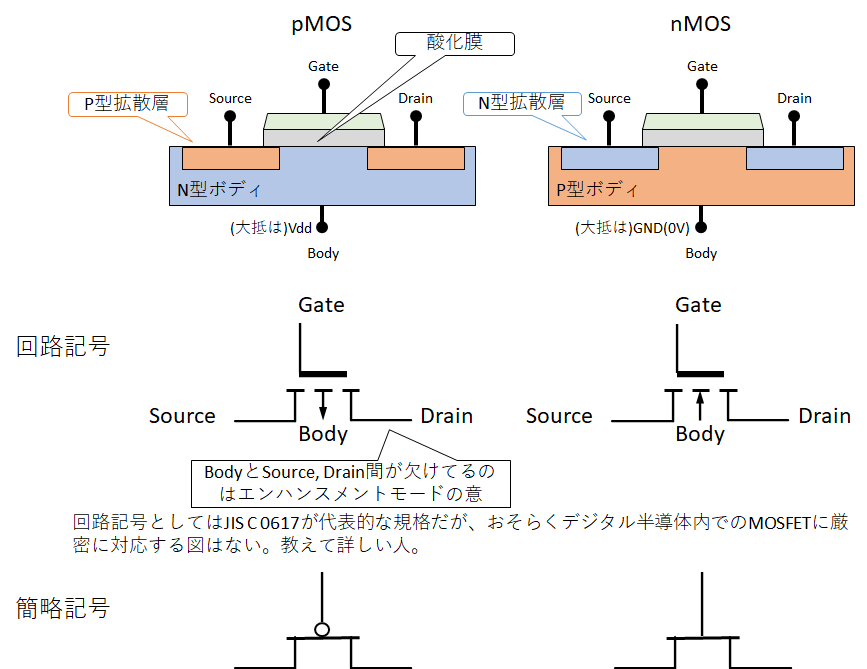
どちらのMOSFETもゲートに所定の電圧をかけることで、ソース - ドレイン間の接続をON/OFFするものである。pMOSはゲートがLow、すなわち0V(厳密にはVth以下だが簡単のためにこうする)のときにソースとドレインが繋がり、逆にnMOSはゲートがHigh、すなわちVdd(+1Vなど。設計に依存し、そして簡単のために固定する)のときにソースとドレインが繋がる。そして、経時的な変化に関しても反対の特徴を示す。MOSFETのスイッチングはソース - ドレインが短絡し同じ電位になることが肝になるが、pMOSの場合、そのソース - ドレインの間をLow → Highにするのは素早くできるのだが、High → Lowにするのは時間がかかってしまう。nMOSは全く逆でHigh → Lowが早くてLow → Highが遅い。そのため、pMOSはVdd側、nMOSは0V側につないで、相補的な配線を行うことで、スイッチング特性のいいとこ取りができるのだ。このようにMOSFETを相補的なつなげた回路をCMOSと呼ぶのだ。スイッチングが素早くできるということはすなわち、デジタル回路の場合は動作周波数が上げられることに直結する。それゆえに特にデジタル回路においてCMOSが覇権を握っているのだ。
CMOSを使えばどんな論理回路も組むことができる。CMOSでNANDやNORといった基本的な部品をスタンダードセルとして構築し、それを大量に集積し、そして最終的にはプロセッサを作ることができるのだが、この記事の主題はDRAMであるためそっちの話はしない。ちなみに、よくDRAMと対比されるSRAM(Static Random Access Memory)はCMOSのみで組まれているのが普通だ。興味がある人はSRAMも入門してみよう。
Sense amplifierの理解に必要なのは一番単純なNOTゲートとトランスミッションゲートだけだ。まず以下にNOTゲートの回路を図示した。
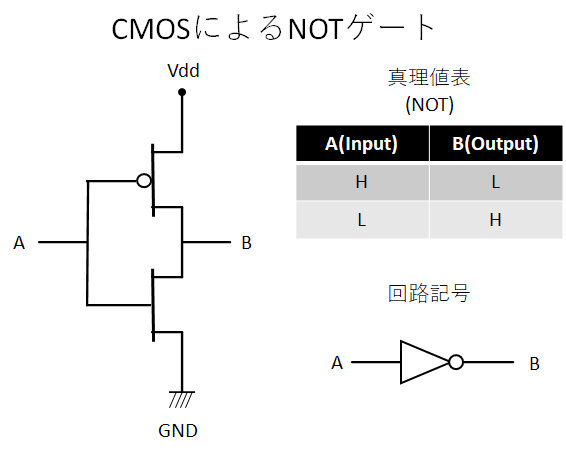
最も単純なCMOS回路であることがわかるだろう。AがHighの時にBがLow、AがLowの時にBがHighになるというとても単純な回路だ。どうしてそうなるかも図示する。
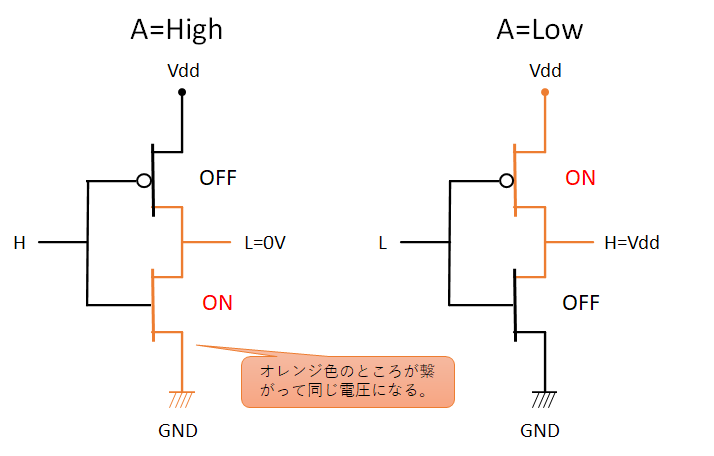
A=Highの時、Vdd側のpMOSはOFF、GND側のnMOSがONになり、出力のBがGNDとつながるため、出力はLowになる。逆にA=Lowのときは、Vdd側のpMOSがON、GND側のnMOSがOFFになり、BがVddとつながりHighとなる。
次にトランスミッションゲートを図示する。
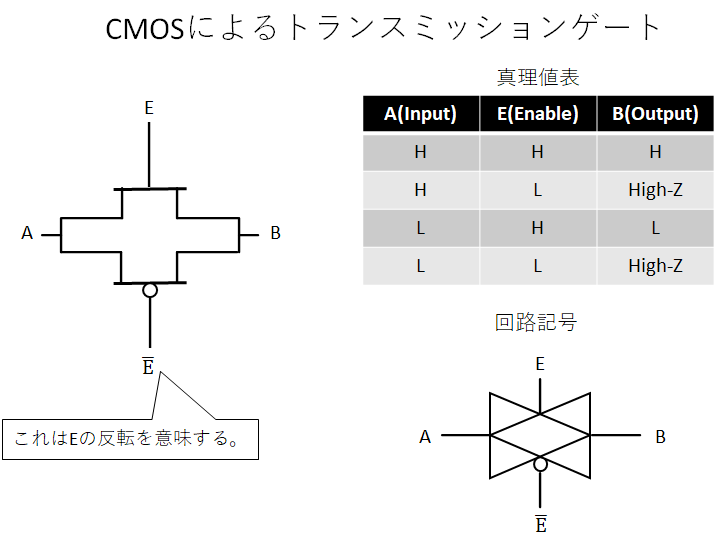
こちらもpMOS、nMOS一つづつの単純なものだ。ただし、真理値表に"High-Z"という変わったものが目に見える。これは「ハイインピーダンス」を意味しており、何も出力していない状態を意味する。トランスミッションゲート単品で見ると意味不明だが、要はトランスミッションゲートを境に電気的に分離され、Bの先の回路次第でHighにもLowにもアナログな中間電圧にもなれるという状態である。トランスミッションゲートで信号をせき止められるのである。
そして、最後にNOTゲートの出力にトランスミッションゲートをつなげたトライステートインバーターを紹介する。
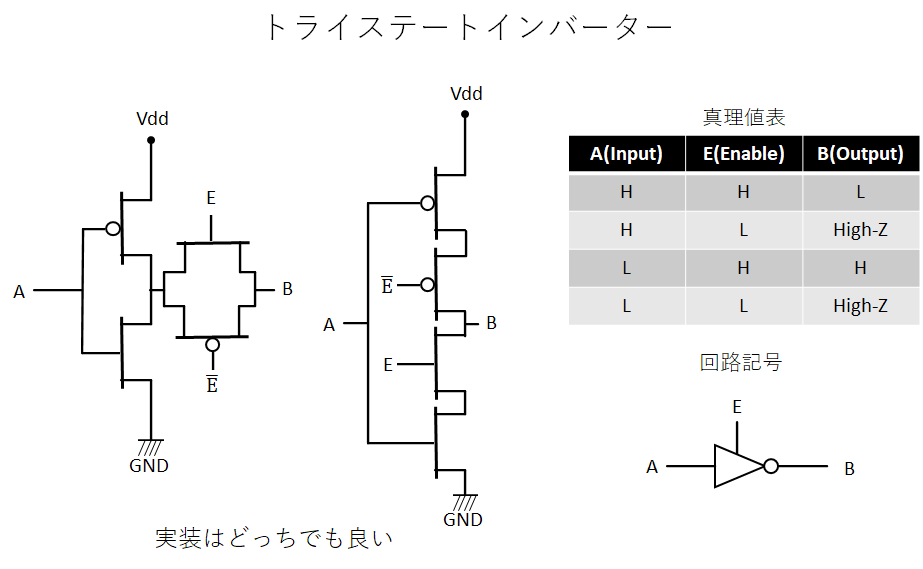
本当にただつなげただけである。トランスミッションゲートの出力のHighとLowが反転しただけである。そしてこの、トライステートインバーターがsense amplifierの鍵となる部品である。
Sense amplifierの配置
さて、ここでようやくsense amplifierの話に戻ってくられる。なお、Sense amplifierの挙動は以下のチューリッヒ工科大学の授業動画の冒頭の説明がわかりやすい。英語がわかるならこれを見たほうが早いかもしれない。
Sense amplifierは以下のような回路で構成されており、AとBの僅かな電位差を増幅することができる。
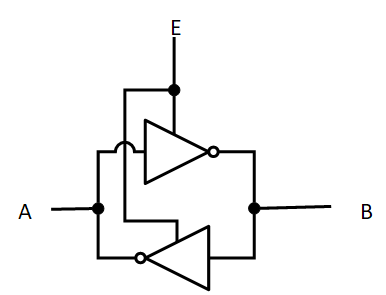
E(Enable)をLow → Highとすると、その時点で高い方の線の電圧がVddとなり、低い方の電圧が0となる。これをDRAMのバンクに以下のように配置する。これまでの図と同様、縦方向の線がビット線、横方向の線がワード線である。
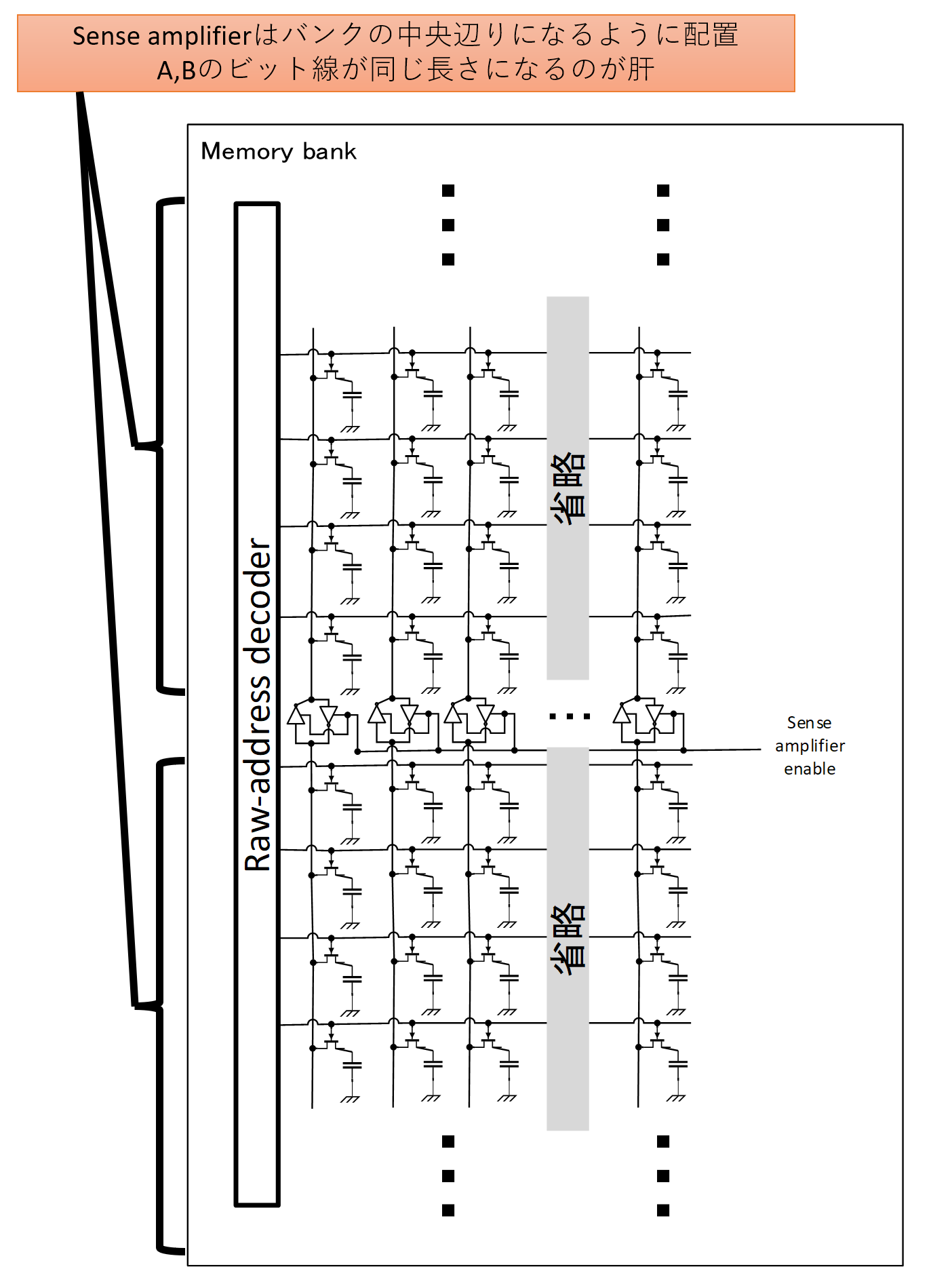
DRAMのメモリバンクにおいて、ビット線1本あたりに1つ、その中央を分割するようにSense amplifierを設置する。この左右対称というのが地味に肝になってくる。なお、もちろん他にもいろいろな部品が繋がっている必要があるのだが、さすがに図がごちゃごちゃするのと、そこまでの労力を割いてられないので、厳密さはご容赦願いたい。なので、この後、このSense amplifierの動作の説明において謎の電圧源や謎のスイッチングが入ってくるが、実際にはそれに応じた回路が更にごちゃごちゃ付いているものと思ってほしい。
さて、ではDRAMメモリセル、正確には「行」を読み取って行こう!下の図にこれから読み取り対象とする行を緑で囲み、これから細かく挙動を追っていくビット線をオレンジで示した。
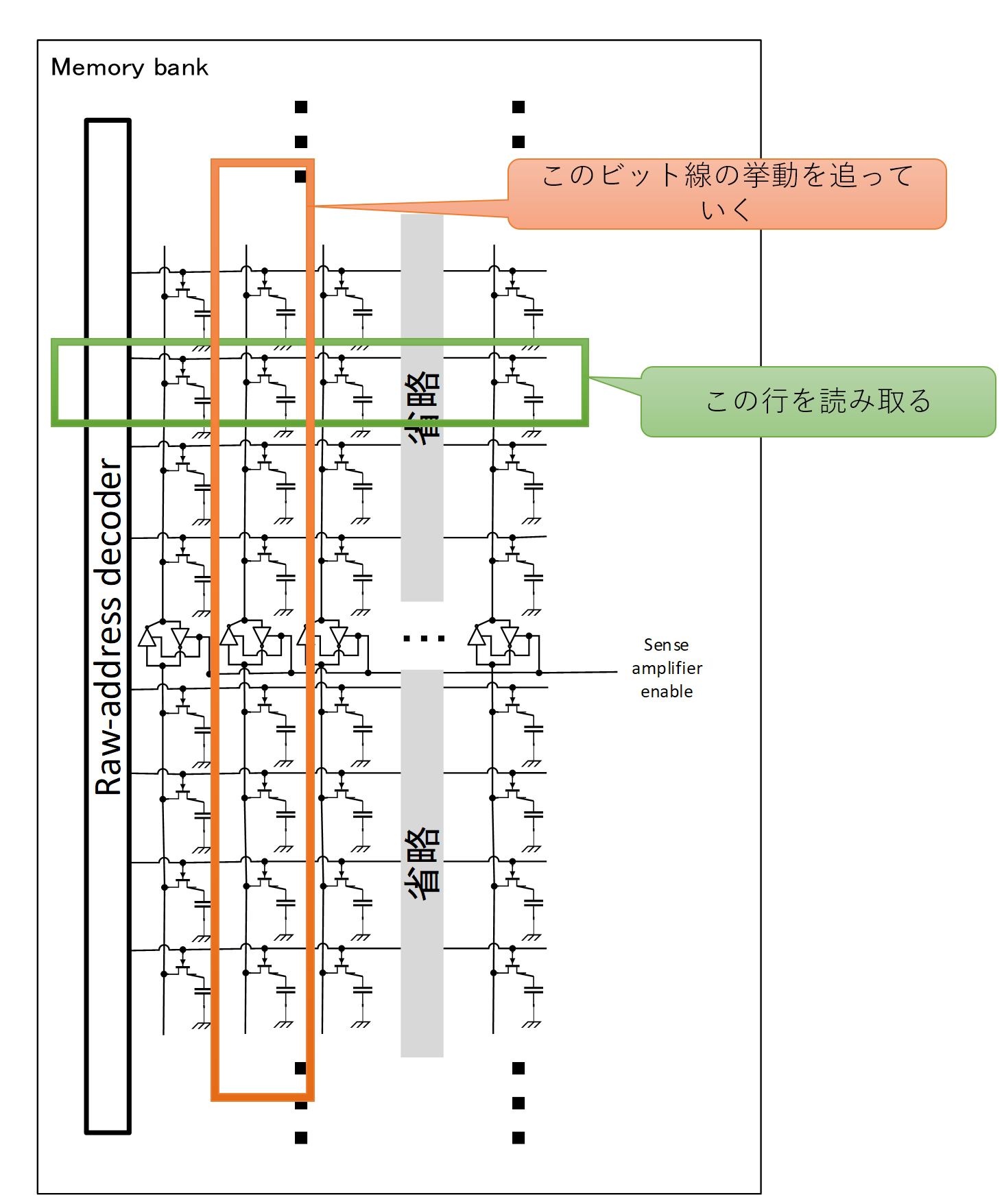
プリチャージ
まず最初にやるべきは「プリチャージ」である。プリチャージはビット線の電圧を厳密にVdd/2にする作業である。特にsense amplifierを挟んだビット線の対が同じ電圧であることが大変重要である。データシートを見るとわかるのだが、DRAMの電源にはかなり厳しい制約がかかっており、DRAMを安定して動作させるためには専用の電源回路が必要である。Part 2で説明する予定のタイミングチャートにおいて、プリチャージがそれなりの時間を要しているのは、この作業が大変繊細であるがゆえにである。
だが、そもそもなんでプリチャージに時間がかかるのだろうか?ビット線はただの導線である。中学校の物理ぐらいまでの知識で言えば、そもそも「導線の電圧を揃える」などというのは意味不明な工程だ。導線は即座に電圧を伝えられるのだから、電気抵抗は多少あれど、ちょっと電荷を与えれば十分に電圧が上がるはずである。ところが、現実の半導体部品には寄生容量という半導体設計者に襲いかかる悪魔が電気を吸い取ってしまうというという大問題があるのだ。
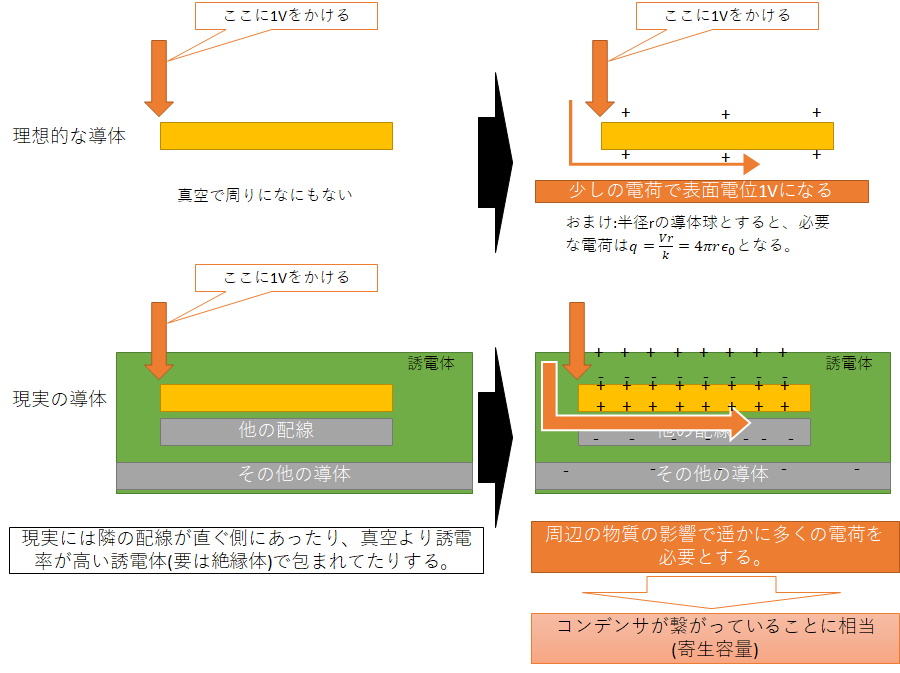
ここにその寄生容量の模式図を示した。教科書的な真空中にある理想的な導体の場合、周辺に電場を形成するだけの最低限の電荷さえあれば、すぐに目的の電圧に達する。ところが、現実には近くには別の配線があり、他の導体部品があったり、そもそもサブストレートもほぼ導体として振る舞うし、絶縁に用いているものは真空より誘電率が高い。そのため、電荷を入れても入れても、他の物質の電荷が移動するばかりでなかなか電位が上がらないのだ。要はコンデンサのような振る舞いをしてしまうのだ。この周りの物質がコンデンサのような振る舞いをする際のコンデンサの容量に相当する量を「寄生容量」と呼ぶ。ただの導線であっても、この寄生容量にきちんと電荷をチャージをしないと電位が上がらないのだ。物理で出てくる Q=CV を思い出してほしい。これはスイッチング速度を下げてしまうため、動作周波数を落とす大きな要因となる。高周波回路ではなるべく寄生容量が小さい方が望ましい。
そして、この寄生容量は他の導体との距離が短ければ短いほど大きくなり、誘電体(絶縁体)の誘電率が高ければ高いほど大きくなる。平行板コンデンサと同じ傾向である。そう、技術が進みどんどん微細化すればするほど寄生容量は大きくなっていく。そして大変都合の悪いことに、DRAMはメモリセルの容量を稼ぐために高い誘電率を必要としている。こちらもキャパシタなので完全に要求がかち合っているのだ。
さて、問題のビット線なのだが、確かに寄生容量は大きいのだが、電源からの電気を使って電位を変える事自体は、ちょっと時間をかければそれで済む話ではある。ところが、このビット線を用いて私達がやりたいことは、メモリセルに電荷が溜まっているかどうかを知ることだ。これは先の寄生容量の話を加味するとかなり無茶苦茶な話なのだ。メモリセルとビット線では全然サイズが違うため、メモリセルが頑張ってその容量を大きくしたところで、到底ビット線にはかなわないのだ。
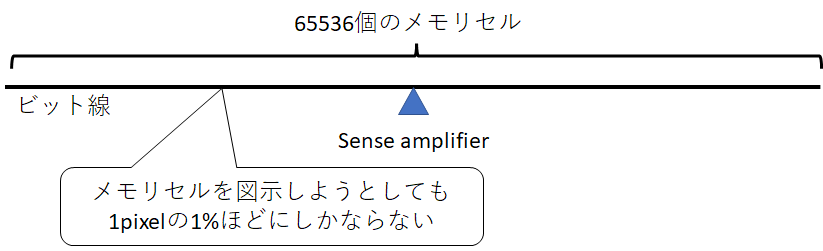
なにせバンクの行数は例えば先のMicronの例では65536であるため、上図のようにビット線には65536個のメモリセルが繋がっている。中央で分離されてると考えても32768個である。この画像ではメモリセルを80個並べてようやく1pixelに達するかどうかである。微細加工で工夫してキャパシタを作っても、到底敵うスケール感ではないのだ。
そこで、予めキャパシタのLow=0VとHight=Vddの中間であるVdd/2にプリチャージを行うのだ!…ん…?ドヤ顔で言うのは構わないが、全然説明になってないって?そうですね。プリチャージから行のアクティベートまでの動作をひとまず追ってみましょう。まずは動作に関係がある部品だけの回路図をいかに示した。そして、合わせてビット線の寄生容量も示した。
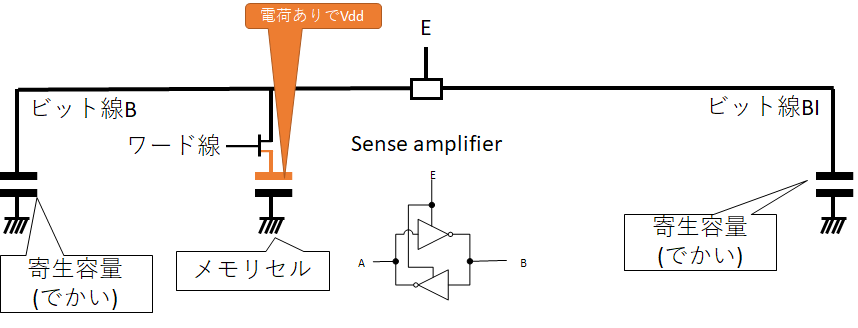
ビット線Bが目的とするメモリセルに繋がっており、その反対側のビット線をBIと呼ぶ。初期状態として、メモリセルにはVddがチャージされてるものとしよう。そして、ワード線はすべてLowの状態から始める。(これに違反すると当然データがめちゃくちゃになる。)ここで(魔法の)電源でプリチャージをすると以下のような状態になる。
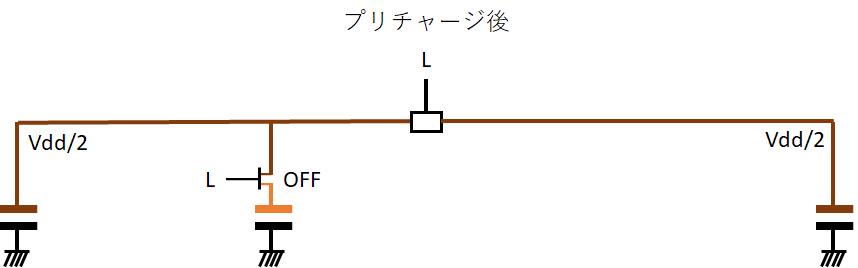
ビット線が両方ともきっちりVdd/2になる。そして、(魔法の)電源から両方とものビット線を切断し、孤立させる。次にワード線をEnableにして、メモリセルとビット線Bを接続する。
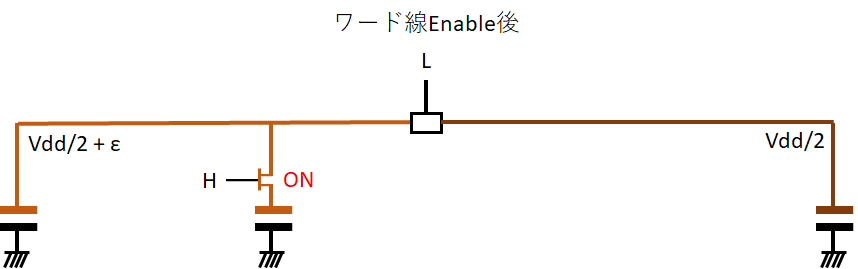
そうすると、孤立していたビット線Bの電圧がキャパシタの電荷によりわずかに上昇し、ビット線BIよりもちょっと高い状態になる。ここでsense amplifierをEnableにする。
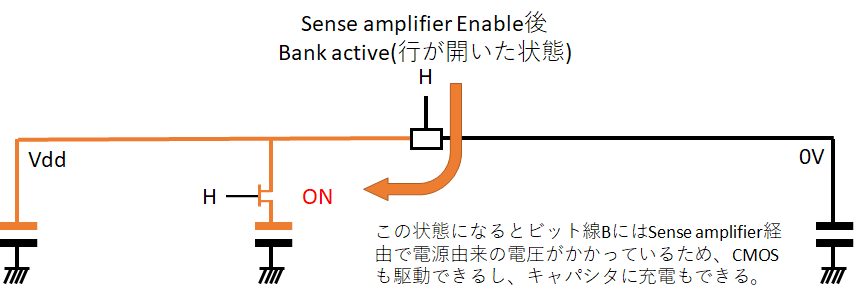
すると、sense amplifierはその僅かな電位差を増幅して、ビット線B側をVdd、ビット線BI側を0Vで駆動するようになる。この状態になれば、ビット線B側はpMOS経由で電源に繋がった状態となり、通常の半導体デジタルロジック回路を駆動させることができる。あとはIOバッファなりがこのビット線Bを読み取って、DDR信号生成などをすれば無事に読み取りが完了する。
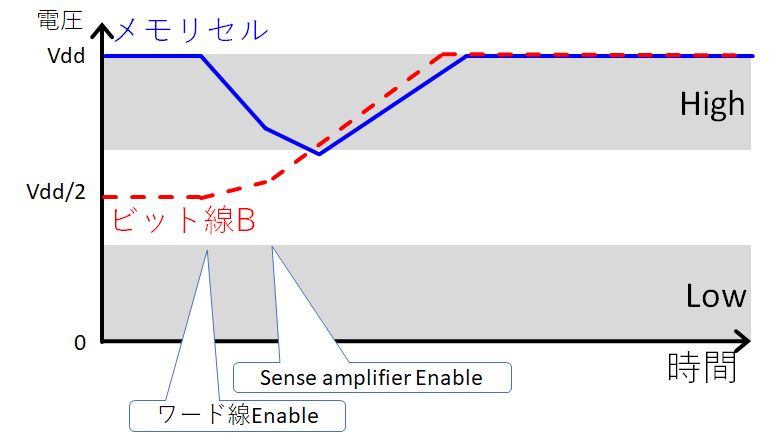
時間経過に伴う電圧変動は概ね上図の様になる。
なお、もしメモリセルのキャパシタの電圧が0Vだった場合には、Vddと0V、εの符号が反転し、ビット線Bが0V、ビット線BIがVddとなる。
ところで、このsense amplifierの挙動はちょっと不思議かもしれない。以下のような図でなんとなく伝わってくれると嬉しい。
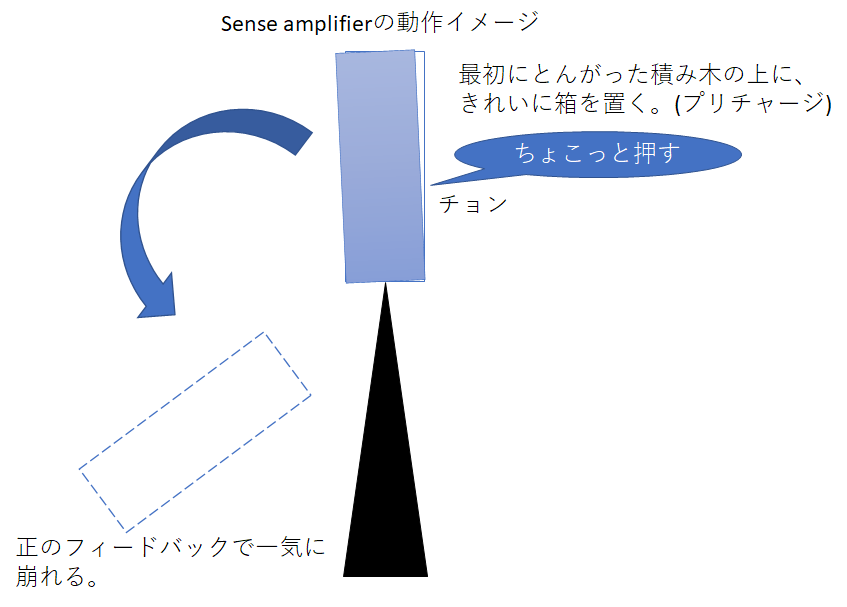
Sense amplifierは真理値表的に両端がH,Lの反転で安定するトライステートインバーターを互い違いに接続したものだと先程説明した。すなわち、どちらかがHigh,反対側がLowが安定した状態なのだ。ところが、プリチャージ直後はどっちつかずの状態で、HighともLowとも言えない不安定な状態となる。まるでとんがった積み木の上に四角い箱をどちらにも倒れないようにそっとおいたような状態だ。それを、キャパシタの電圧ですこしだけ崩してから、sense amplifierをつなげると、正のフィードバックがかかり、一気に安定した状態に崩れていくという仕組みになる。電流や電圧を絶対値として精密に直接計測することは至難の業なのだが、「符号」だけであればとても正確に得ることができるというのは、いろんな場合においても言える。高校物理で扱うホイートストンブリッジもその好例である。ブリッジのバランスを基準に抵抗値を測定することで高精度に抵抗値を得ることができる。
このような測定値をゼロ点の周辺に持ってくることで、高精度に測定する方法を「零位法」と呼び、精度をその中核に据えている現代の技術は多くの場面でこの手法を用いている。何かを高精度で測定したい人は是非参考にされたい。
そして読み取りが終わったら、ワード線とsense amplifierをNegateして行を閉じる。
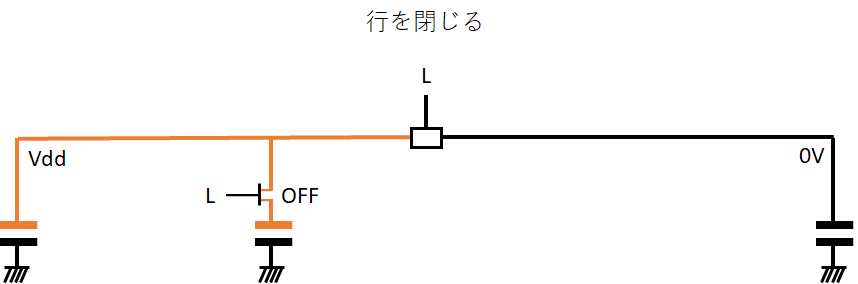
そして、次の読み取りに備えてプリチャージすることで元の状態に戻るのだ。
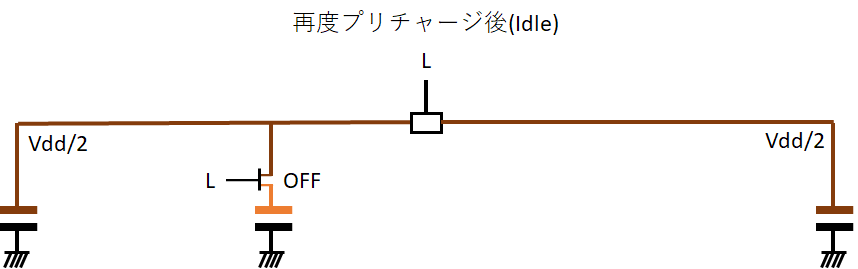
こうすれば、迅速にかつ安定してキャパシタという不安定な素子の電荷を読み取る事ができる。(なお、この仕組がMLC NANDフラッシュメモリのような多値化を難しくしているのだが、それは「入門」ではないので各自で調べよう。)
ここでプリチャージに関して大きな誤解を正しておきたい。ちょいちょい…いや、もっと高頻度だが、読み込みでメモリセルのキャパシタから失われた電荷を再充電することを「プリチャージ」と言っている説明が大変、本当に大変多いのだが それは間違いである。(というかWikipediaもこのあたりは間違っている。)だいたい"pre"って着いているのに、読み取り後のチャージだなんて意味がおかしいじゃない。そして、先のsense amplifierの説明の通り、そもそもメモリセル読み取り操作は電圧が0 or Vddに収束する回路を接続することで読み取っているために、読み出しと電荷再充電は分離した振る舞いではない。ここはDRAMに関して大きな誤解を招きがちなポイントなので、知っていると一目置かれるか、ドン引きされるかの二択だろう。
もし誰かが「DRAMってコンデンサに電気を蓄えてるんだけど、読み取ったらその電気なくなっちゃうから後からプリチャージしないと行けないんだよね」と言っていたら 「プリチャージの意味、違うよ。みんなよく間違えるんだけど~」 という爆速オタクトーク炸裂タイムである。 友達が一人減ります。 (いや、一人じゃ済まないかもな…)
次に書き込みだ。といっても、読み込みを理解したなら書き込みはとても簡単である。行を開くところまではリードと全く同じである。まずはプリチャージして、ワード線をEnableして、sense amplifierもEnableにする。その後、変更したい部分のビット線を書き込みたいパターンでHigh or Lowにセットする。(ショートしないようにsense amplifierはもちろん切る)その後は行を閉じる、プリチャージすればIdleに戻る。
ただ、ここに若干の無駄があるとも言える。もし同じBankに対して連続で2つ以上の行をすべて上書きしたいとしよう。今の規格だと、行を閉じたあとにはプリチャージするしか選択肢がない。だが、もし次の操作が書き込みで、かつ、行の内容を一切維持する必要がなければ理屈上はプリチャージしなくても適切な最終状態に行き着くことになる。もちろん、そんなレアケースは少ないだろ、とか、周辺回路への影響とか制御の複雑さを招くとか、課題は多くあるのだが、こういうことを妄想することはタダなので、ぜひみんなもデータシートとにらめっこしてみよう。次にDRAMに革命を起こすのはあなたかもしれないのだから。
キャパシタ
Part 1の最後はメモリセルの物理的な構造について説明する。
キャパシタの電気的特性は主にその静電容量で示すことができ、 電荷量 = 静電容量 * 電圧 という関係式が成り立つことが分かっている。電圧一定と仮定すると、なるべく静電容量を大きくして蓄える電荷量を増やすことで、より長時間データを保持したり amplifier を安定して動かすことができる。そして逆に同じ電荷量を蓄えるために、低い電圧で問題ないことになる。そのために、キャパシタの静電容量を大きくすることがDRAMの消費電力削減における重要な要素となっている。
静電容量は平行版コンデンサを仮定すると概ね 絶縁体の誘電率 * 導体の表面積 / 距離 に比例する。形状が平行板じゃないので、距離ってなんやねん、という感じだが、微細に作れば作るだけそれだけ距離が縮まるという理解で問題ない。だが、微細化すれば同時に表面積も減ってしまう。むしろ面積は二乗で減っていくので、容量を増やすために微細化すれば微細化するだけどんどんと静電容量が減っていく。静電容量が減ればプリチャージやsence amplifierでの増幅などへの精度要求が高まるために、まともに駆動できなくなってくる。
DRAMにおいて重要なのは、可能な限り狭い空間にFETとキャパシタを詰め込みつつ、そのキャパシタの容量を確保する、すなわち表面積を増やすことにある。そこで今はトランジスタの上、すなわちダイの表側の方に縦長のキャパシタを設けたVCT(Vertical Channel Transistor)が使われている。(たぶん?直近のDRAMの研究状況は把握しておらず。)
具体的な形状はJEITAにおける報告書や以下の記事を是非参考にしてほしい。
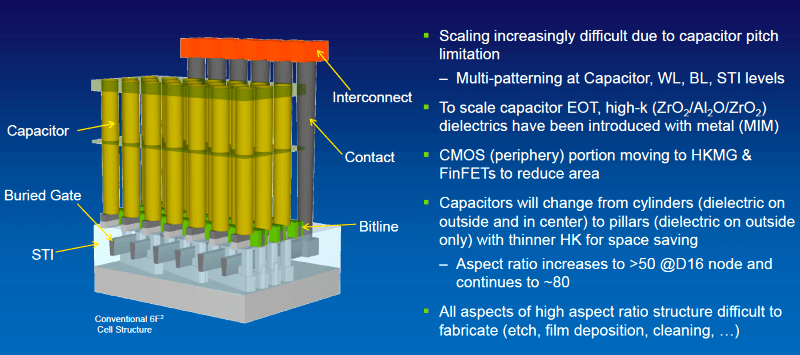
https://eetimes.itmedia.co.jp/ee/articles/1901/21/news067.html より引用
サブストレートの直上にトランジスタを形成し、円筒形の導体を設けることで、高密度に大きな容量を確保していくというのが高密度DRAMの今の姿だ。だが、問題は「円筒形の導体」を作る具体的な方法である。あまり細かいCMOS製造プロセスは説明しないが、ちょうどつい数日前に出た下記の動画が参考になるだろう。
CMOSなどのシリコンウェハー上の微細加工は、表面処理、フォトレジスト、露光、現像、エッチングなどの工程を複雑に組み合わせ、繰り返すことで行われている。下記のページが参考になるだろう。
これによりとても微細な加工ができるのだが、基本的に加工範囲は表面の本当に薄い領域のみにとどまる。垂直軸方向の加工は根本的に苦手なのだ。先の動画で紹介されているDeep RIEがそれを可能にするのだが、少しずつ穴を掘るのをひたすらに繰り返していく工程になる。特に表面積に対して垂直軸の比率が高い(アスペクト比が高い)加工を行うのは大変な工数増加と歩留まり悪化を招くため、できたとしても高コストになりがちである。その最たる例がTSV(through-silicon via)であろう。これはHBM2(Part 3で出てくる予定)などの広帯域メモリで用いられる技術で、シリコンダイを貫通した電極を作って、最終的にはそれらを積層して3D ICを組むというものなのだが、価格が尋常じゃなく高い。DRAMのキャパシタもスケールメリットなどで価格を抑えているが、これは本質的にはかなり困難を伴う加工である。そのせいで、最先端のプロセスでは大規模なCMOSロジックとDRAMを同じダイに乗せるのが現実的ではなくなってしまった。ロジックチップとDRAMとでは異なる製造プロセスの進化を遂げたからだ。
ただ、ロジックチップにもTSVを通すというのは今後期待されている技術であり、多くの研究や開発が行われている。これができるとロジック積層によるより大規模で高密度なプロセッサが実現できるからだ。今のシリコンは「垂直軸が熱い」、これはロジック、DRAM、そしてNANDフラッシュにおいて共通した傾向である。
Part 2 の予定
Part 1お疲れ様です。友達何人減りましたか?
Part 2は物理的構造の話から時間軸方向の話へシフトしていく。DRAMチップを操作するコマンドとタイミング、そしてガーバーと配線長の話だ。GHzオーダーの高周波信号の闇を見ることとなるだろう。1GHzの信号周期は1ns(ナノ秒)、そしてその間に光が進む距離は30cm、このスケール感を頭に叩き込んで挑むのだ。光速が遅すぎてなかなかDIMMから出ることができない…。
ちなみに、Part 3で規格とDRAMの未来の話をして締める予定である。みんな大好きPS5とApple M1が出てくる予定だぞ。完走できなかったらごめんね。
追記
編成が予定から変更になりましたが、Part 2を書きました。