パソコンユーザーのためのDRAM入門 目次
- Part 1 : パソコンにおけるDRAM、DRAMの構造
- Part 2(本記事) : 制御、パッケージ
- Part 3 : GHzへの挑戦、PCB
- Part 4(準備中) : マルチチャンネル、規格、未来
Part 2があまりに肥大化したため、Part 2とPart 3に分割した。そのせいで若干Part 2が寂しい感じになってしまったが許せ。
Part 1 おさらい
まず、多くの人にPart 1を読んでいただいたことを感謝したい。Qiitaはソフトウェアの話題が多い中で、このようなゴリゴリのハードウェア、しかも半導体レベルの話題に興味を持っていただけたことは大変嬉しい。勢いで書いた拙い文章であるが、DRAMの話題を通して身近な半導体にさらに興味を持っていただけたらなと思う。(前半のバスの話が長すぎて、大事な後半読まれてない説が若干あるが(汗))というわけで、Part 2に進んでいこう。
Part 1ではDRAMがパソコンの中でどういう立ち位置なのかと、DRAMの、特にそのメモリバンクの物理的構造のお話をした。ただ、結局DRAMダイどころか、もはやメモリバンクの外の話すらしていない。それに、多少動作の話をしたとはいえ、せいぜい10ナノ秒前後ぐらいの話しかしていないし、デジタル制御の時間最小単位とも言えるクロックの話もほぼしていない。
というわけで、Part 2ではもっと長い時間軸でのDRAMの制御と、PCB(プリント基板)レベルの話に広げていく。なお、内容はPart 1を読み終わった人向けである。ちゃんとPart 1で友達減らしてきましたか?え?最初からゼロ?いい覚悟だ。あなたが未来を創るのだ。
このPart 2は友達減らしポイントがない。
つまり、意外性はないということだ。安心して読めるな!!!
Part 1に引き続き特に断りが無ければ対象とするDRAMチップはMicronのDDR4 SDRAM 8Gbで8bit幅のDDR4-3200(型番は MT40A1G8SA-062E)を想定して説明する。この際の1クロックサイクル(CK)は0.625ns(625ps)である。参考までに、これを2RankのUDIMMに搭載すると1枚あたり16GBのDIMMが出来上がる。Part 1で説明しなかったが、この容量のDRAMチップを選んだ理由は単に価格.comで一番売れてたDRAMが大体このあたりのスペックだっただけで大して深い意味はない。
DRAMチップの制御
タイミングチャート
Part 1で以下のような説明をした。
DRAMチップはフルでCMOSで組まれたいわゆるロジックチップとは異なり、それ自身には細かな制御機能は持たせていない。外からタイミングよくコマンドなどを入れることで、データを書き込み、読み取り、消去ができるというチップである。
いよいよこのコマンドの具体的な説明に入ることができる。Part 1でDRAMチップの中身を知ったあなたならタイミングチャートが読めるはずだ!というわけで、具体的なイメージを持ってもらうために、タイミングチャートの例を示す。
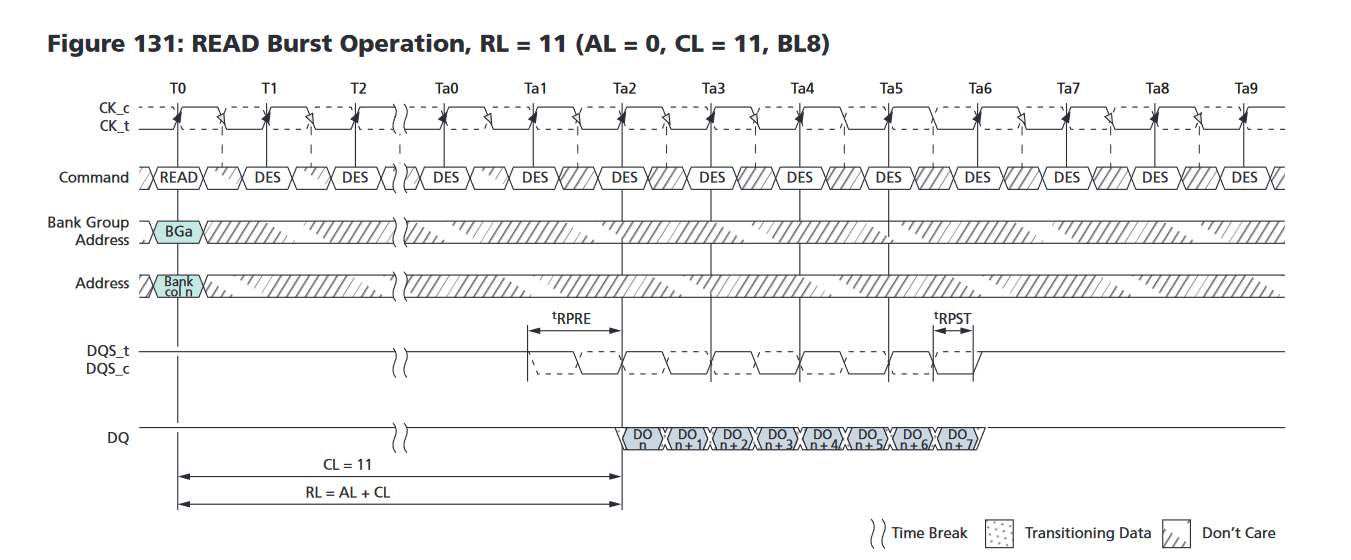
「…読めない」
うむ、あなたは正常だ。元から読める人でないとPart 1の内容を把握しただけではこの図は読めない。というわけで、Part 1と同じMicronのデータシートを元に説明していくのでリンクを再掲しておく。
ちなみに、日本語版WikipediaにはDDR3に関して異様に詳細な(というかほぼデータシートレベルの)DRAM制御方法の記事があるので興味がある人は読んでみてもいいだろう。メモリコントローラを実装するときでもないとここまでの粒度の情報が必要になることはないと思うが…。
まず、目的の確認だが、私はここでタイミングチャートやデータシートのすべてを説明するつもりはない。あくまで「オタクトークをするのに必要なだけ」説明していく。なので、細かいタイミング制約の話とかはザクザクすっ飛ばしていく。というか、そんなに細かい話をするなら「データシートを読め」で話が終わる。あくまで雑学だ。それと、これから説明するのはあくまで「DRAMチップのメーカーとしての取扱説明書」をベースとしている。同じDRAMチップでも使い方は1つじゃないし、実は違反しても動くので、違反して使っているケースもままある。それの最たる例がXMP含むメモリOCだったりする。また、実際のIntelやAMDのメモリコントローラがその機能を使っているかは、軽く調べたがわからなかった項目も多い。設定画面や挙動から推測した経験則的なものも多く混ざっていることはご理解いただきたい。製品の性能や設計に関わるので正確な情報は営業秘密の可能性もあるだろう。
ところで、余談なのだがこれから説明する図を「タイミングチャート」と私は呼んでいるが、英語だと"Digital timing diagram"と呼ばれ、そして、大変紛らわしいことにUMLでいう"timing diagram"とは別物のようなのだ。確かにUMLのSpec https://www.omg.org/spec/UML を見てみると、似てはいるのだがデジタル半導体の人が使う「タイミングチャート」はUMLのSpecを満たしているように見えない。そして日本語でも「タイムチャート」や「タイミング図」や微妙に表記ゆれがあるみたいだ。このあたりの関係詳しい人がいたら解説を希望したい。
余談終わり。まずは入力の詳細を見ていく。
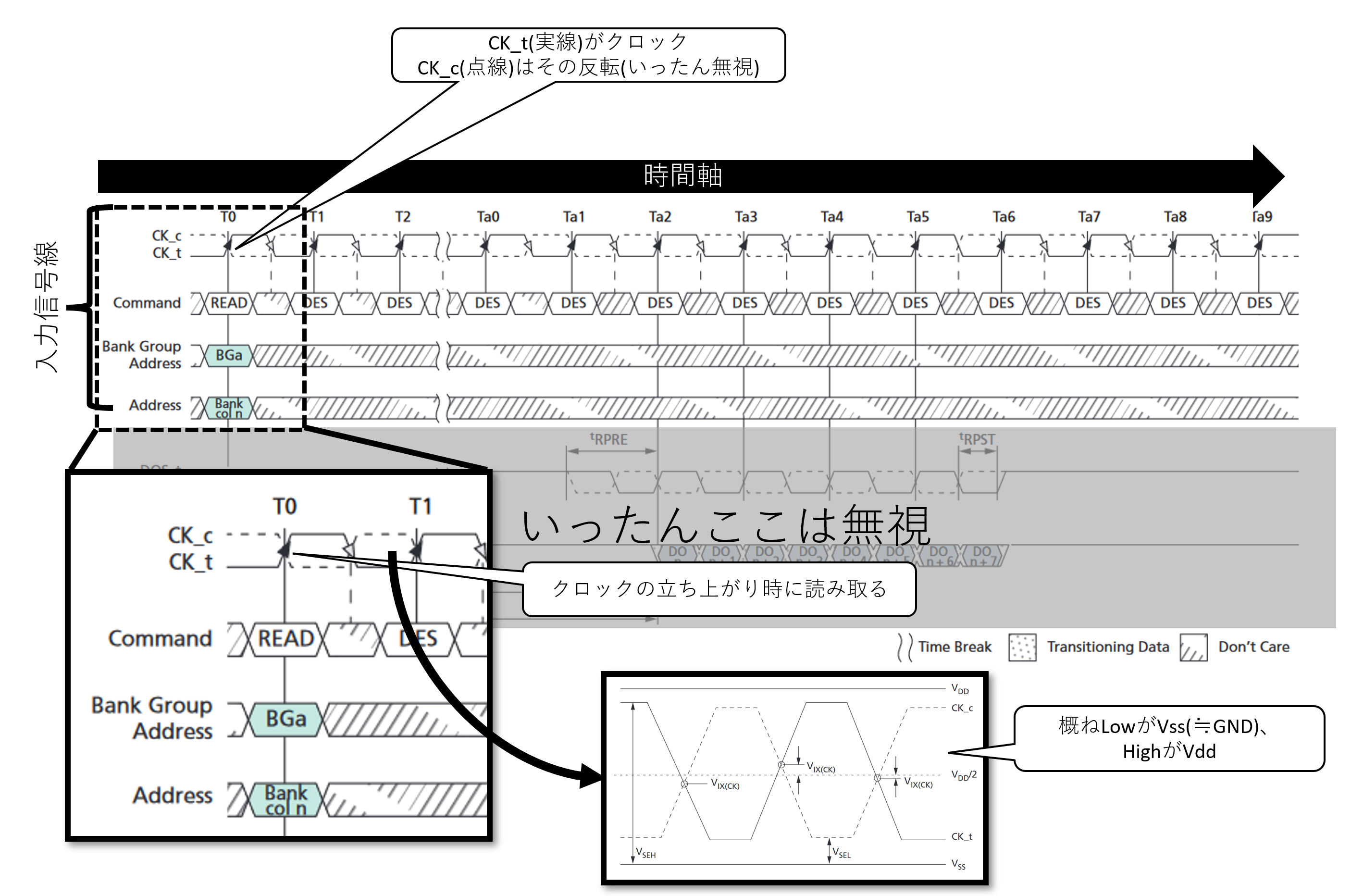
タイミングチャートは時間軸が左から右に進むように書かれており、それぞれの線は信号線に対応している。ここまで説明してこなかったが、いま対象としているのはSDRAM(Synchronous DRAM, 同期式DRAM)なので、このタイミングチャートの一番上に示されているクロック信号"CK_t"に合わせて他の信号線を駆動させることになる。ちなみに、Synchronousという名前が付いているということは当然Synchronousではない非同期式DRAMもあるが、今のパソコンのメモリでは使われていないので無視する。そのノリで、RDRAMも省く。期待していた方、すまんな。タイトル回収(?)。特にT0に着目するとその瞬間に合わせて、Commandに「READ」やBank Group Addressに「BGa」とか指示されているのが見えるだろう。一定のタイミング制約の範囲でT0の前後で信号線を所望の電位に保っておくことを示している。なおCommandやAddressは複数の信号線で構成されておりまたHigh,Lowどちらもあり得るので、幅をもたせて図示している。
T0はクロックであるCK_tがLowからHighに変わるタイミングである。このLowからHighの立ち上がりのときに、入力信号線のHigh or LowをDRAMダイが取り込む。詳細は他の資料に任せるが、D-フリップフロップと呼ばれる回路がこの動作を実現する。下記資料などを参考にしてほしい。ちなみに、半導体では普通の電子回路のGNDに相当するものをVssと呼ぶ。Part 1では半導体以外の人にも馴染み深いVdd,GNDの対で書いたが、最低でもDRAMの場合はVssと聞いたら基準電位GNDなんだなという認識でまず問題ない。Body biasとか出てくるとそうシンプルな話じゃなくなってくるのだが、パソコンには関係ないので無視する。
そしてこの図で多く見える斜線で覆われた"Don't Care"は特にその値は読み取らないので関知しない、HighでもLowでもどっちでも良いよ、という意味だ。この「どっちでも良いよ」というのは地味に肝であり、同じ信号線が分岐して他のDRAMチップにも繋がっているために、この「どっちでも良いよ」の間には他の信号を通すというタイミングもある。
ちなみに、「それぞれの線は信号線に対応している」と言ったが、実は若干ごまかしがあり、DDR4 SDRAMのチップにはこの「Command」に対応する線は厳密には存在しない。後ほど説明するがDRAMにとって信号線はとても貴重であるために、タイミング次第で同じ信号線を違う用途に使いまわしている。データシートを見ると厳密なパターンが説明されているが、ここでは触れない。興味がある人はP.70 Table 23: Truth Table – Command を参照してほしい。
Double Data Rate(DDR)
次は出力に入ろう。本来的には入力のCommandの話をしたほうが良いのだろうが(実際順番に迷った)、これを読んでいる諸氏はPart 1のメモリセルの仕組みを知っているので、出力の方が興味あるだろうと思い、こちらを先にする。
現在SDRAMにはSDR(Single Data Rate)とDDR(Double Data Rate)の大きく二種類がある。SDRは1クロックで1回データを転送し、DDRは1クロックで2回転送する。今回題材としているのは"DDR4 SDRAM"という名前の通りDDRである。DDRのDDRたる所以がさっきのタイミングチャートの下半分に見えているので、そこを説明する。
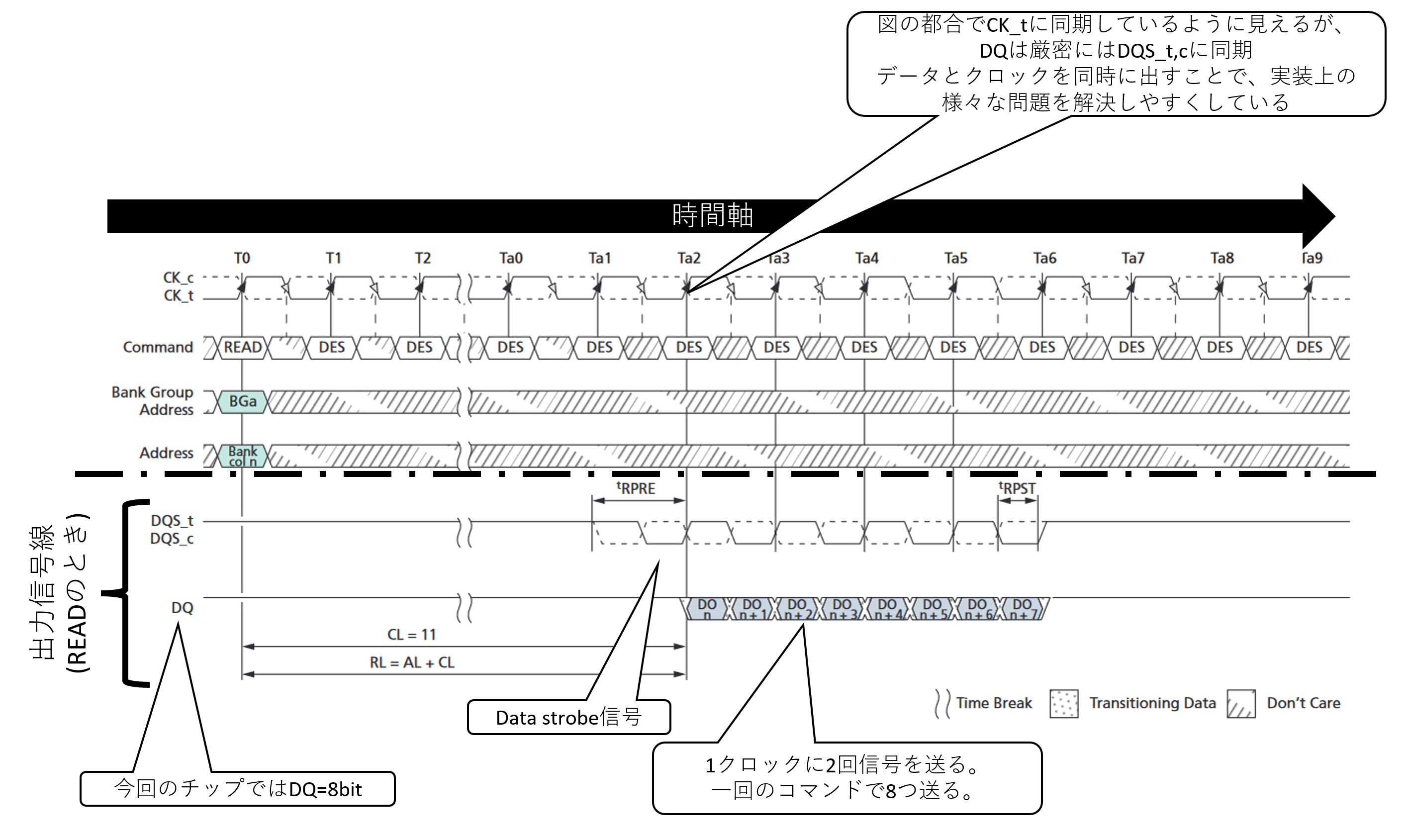
DQと示されているのがいわゆるデータ線で、READのときにはDRAMチップからの出力が行われれる。今回も前回に引き続きここが8bitのものを対象としている。そして、DQのデータのタイミングを示すDQS_t、DQS_cというクロック信号もセットで使われている。「クロック信号はCK_tがあるじゃないか?」と思う人もいるかも知れない(いや、その疑問が湧くなら理由もわかるか…)。このDQS_t,cはdata strobe信号と呼び、受け取り側のメモリコントローラはこの信号線を用いてフリップフロップを駆動することで、自身のFIFOにデータを取り込むことができる。CK_tのようなマスタークロックではなくdata strobeを使って信号を受け取るというのは、安定した高速信号伝送を行う鉄板技術なのでそれはそうという感じなのだが、ことDRAM on DIMMに関して言えば、後述の理由によりチップ枚にDQのタイミングがずれるという原理的な問題を抱えているために、data strobeを使わないことなど不可能なのだと一言付け加えておく。
そして、DDRのミソが"DQS_c"の存在である。見ての通りこれはDQS_tの反転クロックである。反転クロックはPart 1で述べたinverter(NOT回路)で簡単に作れる。そして、ちょっと前に説明したとおりフリップフロップは「クロックの立ち上がり」でデータを取り込むと説明した。これを利用して、受信側にDQS_cをクロック入力とするフリップフロップとDQS_tをクロック入力とするフリップフロップを設けることで、クロック周波数の2倍のペースでデータを1つの信号線から読み取ることができる。読み取り回路を下記に図示した。
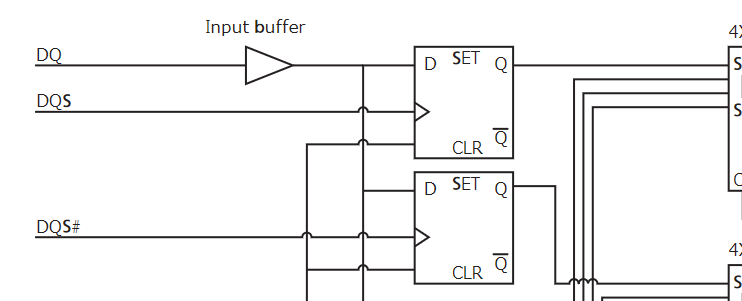
https://media-www.micron.com/-/media/client/global/documents/products/technical-note/dram-modules/tn0454.pdf のFigure 12から抜粋
無印DQSがDQS_t、DQS#がDQS_cに相当し、"SET"と書いてある四角い箱がフリップフロップである。1つの信号線DQを分岐して、別々のdata strobeにつないだフリップフロップに入れることで、1クロックで1つの信号線から2bit読み取れる。これがDDRの”Double”の所以である。もちろん送信側も倍速で信号を流す工夫が必要である。このPDFには生成回路も載っているので、興味のある方は読んでみてもいいだろう。
そして、DDR4の読み書きは原則8つ単位で行われ、4クロックサイクルをひとかたまりとして実行する。すなわち、このDRAMチップの場合は8x8=64bitをひとかたまりで指示することになる。このデータ単位である"8"をバースト長(burst length)と呼び、一気に連続して転送することをバースト転送と呼ぶ。DDRでバースト転送をする、というのが今のDRAMの高速化に繋がっている。なお、DDR4にはこれを半分の"4"で中断バーストチョップ(burst chop)という動作モードもある。ただ、内部的にはバースト長8で動いているのを中断する仕組みのため、微妙に制限がある。このあたりは細かい話なのでスキップする。
タイミングチャートの説明に使ったのはREADコマンドで、名前通り読み取りの操作で、コマンドをDRAMチップが受理してから一定サイクル後(先の図では11サイクル)にDQからデータをバースト転送で吐き出し始めるという流れてになっている。ちなみに、メモリコントローラ側で11サイクルではないことに大変注意である。後ほど触れるが、高速IFになってくるとあまりに動作が速すぎて、それが誰にとっての時間なのかが大変重要になってくる。Data strobeが存在する理由もそこにある。書き込みの時はDQとDQSをメモリコントローラが駆動することになる。
ここで、DRAM以外のPHY系に明るい人は「差動信号じゃないの?」という疑問があるかもしれないが、DDR4はクロックだけ差動で他はシングルエンドである。DDR5で全部が差動信号の規格も出るという話があるが、JEDECの中の人じゃない一般人なのでそのあたりの動向は承知していないし、出たとしてそれが普及するかは別問題なので未来へのお楽しみだ。
コマンドと状態遷移
さて、なんとなくコマンドの入れ方を掴んだところで、メモリバンクの状態遷移に話を進めていこう。Part 1で説明したように、メモリバンクの制御にはプリチャージなどの定まった手順が操作が必要であり、準備なしに読み取りはできない。そのために、バンク毎にどういう操作でどういう状態になるのかという簡単な状態遷移図がデータシートに示されている。以下にそこに説明を追加した図を載せる。なお、今回対象としない範囲はグレーアウトしている。緑色の図形でそれぞれの遷移にどれぐらいの時間を要するかの目安を示した。一応DDR4-3200を想定して数字を取ってきているが、速度が変わっても数字感は大きくは変動しない。
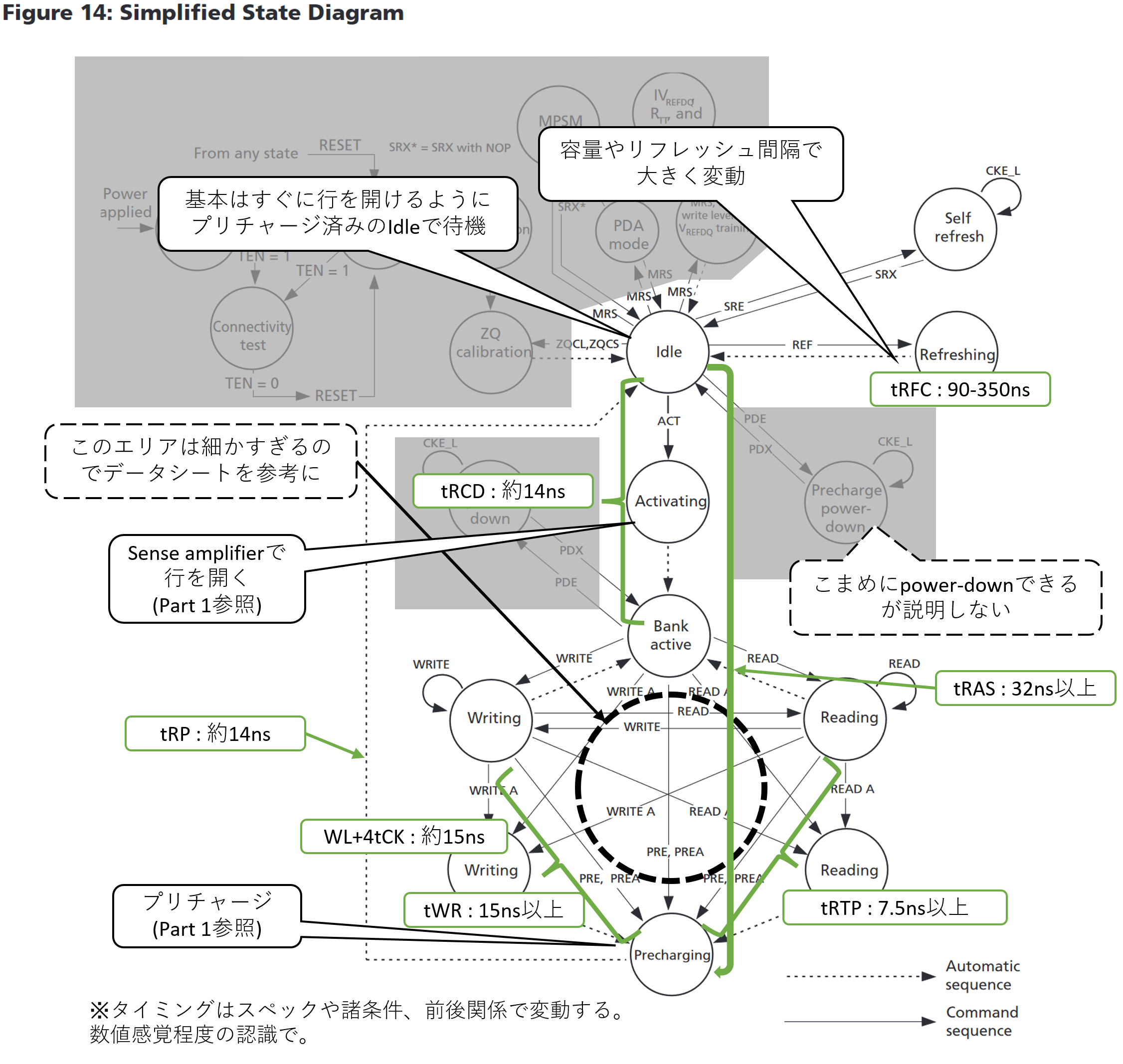
Part 1で説明したミクロな目線で見たメモリセルの動きが、より長い時系列の中でどの様に組み合わせれていたかが読み取れるかと思う。大体の操作は2桁ナノ秒オーダーを要しており、中でも書き込みが若干長めである。これはPart 1でのメモリセルの動きを考慮するとわかりやすいと思う。読み取り動作はBank activeになった状態からであれば、ビット線の情報をそのままDDR信号生成回路に委ねるだけなので、データ全体がとりあえずバッファから外に出てしまえば、行を閉じてPrechargeしちゃってもなんの問題もない。一方書き込みは複雑だ。(DDR4の仕様が洗練されていないと言ってしまうとそれはそうなのだが)行を開いた後に書き込みコマンドを発行して、Write Latency(WL)分だけ待ち、実際に送って、ビット線への書き戻し(Write recovery)を終えてから出ないと、そのバンクに対して一切他の操作ができない。理屈の上では行を開いている間にWLと書き込みデータのバッファリングをしてから、実際の書き込み位置をWRITEコマンドで指示して待ち時間tWRの15nsのみというのもありえなくはないのだろうが、最低でも今のDDR4はその選択をしていない。制御の複雑化やピーク電力の増加で制御の複雑化を招く割には、書き込み遅延を削減するメリットがないなどの理由などが想像される。
こう眺めると、よくソフトウェア高速化の際に「メインメモリの遅延は概ね100ns」と言われるのも分かるだろう。ここで書かれている遅延はすべてDRAMチップ内部の話なので、メモリコントローラやその他キャッシュシステムを通ると大体それぐらいかかる。そして、運悪くリフレッシュしてると更に+100nsかかることになる。DRAMは諸々の事情によりタイミング制約が厳しく、一つ一つの動作がどうしても遅いのだ。(2、3桁nsで遅いと言われるのも悲しい話だが、CPUは1桁nsの世界で動いているのだから仕方ない。)Part 1を読んだあなたはそれを痛感してきたはずだ(?)。
だが、遅延が遅くても帯域幅を稼ぐことは可能であり、先のDDRやバースト転送はその良い例だ。今回のDRAMの場合、1つの行を開くと8192本のビット線が一気にIOバッファにつながる。一旦開いてしまえば一気に読み書きできるというのが、DRAMの強みでありこれを最大限活かせるように進化してきている。DRAMチップの中が複数のBankやBank Groupに分かれているのもそのためだ。次はバンクを使った高速化について眺めていこう。
BankとBank Group
Part 1でDRAMチップの中のメモリセルの集まりが複数のメモリバンク(Memory bank)に分かれているという説明をした。だが、その理由には触れていなかった。まずわかりやすいのが消費電力の削減だ。Part 1で説明したように、たった1行を読み取るだけでもメモリバンクに存在する寄生容量を持ったすべてのビット線にプリチャージする必要があるし、ここの電位を上下するために多くの電荷を必要とする。全体を1つのメモリバンクにせず、メモリアレイを分割して複数のバンクにすれば、ビット線の本数やその長さ、すなわち寄生容量を減らせる。そうすれば自ずと必要電流も減ることとなる。他の条件が同じなら電気抵抗により電流の二乗に比例したエネルギー損失が生じるために、細切れにするインパクトは大きい。そして第二の理由が高速化だ。厳密には帯域幅の増大だ。
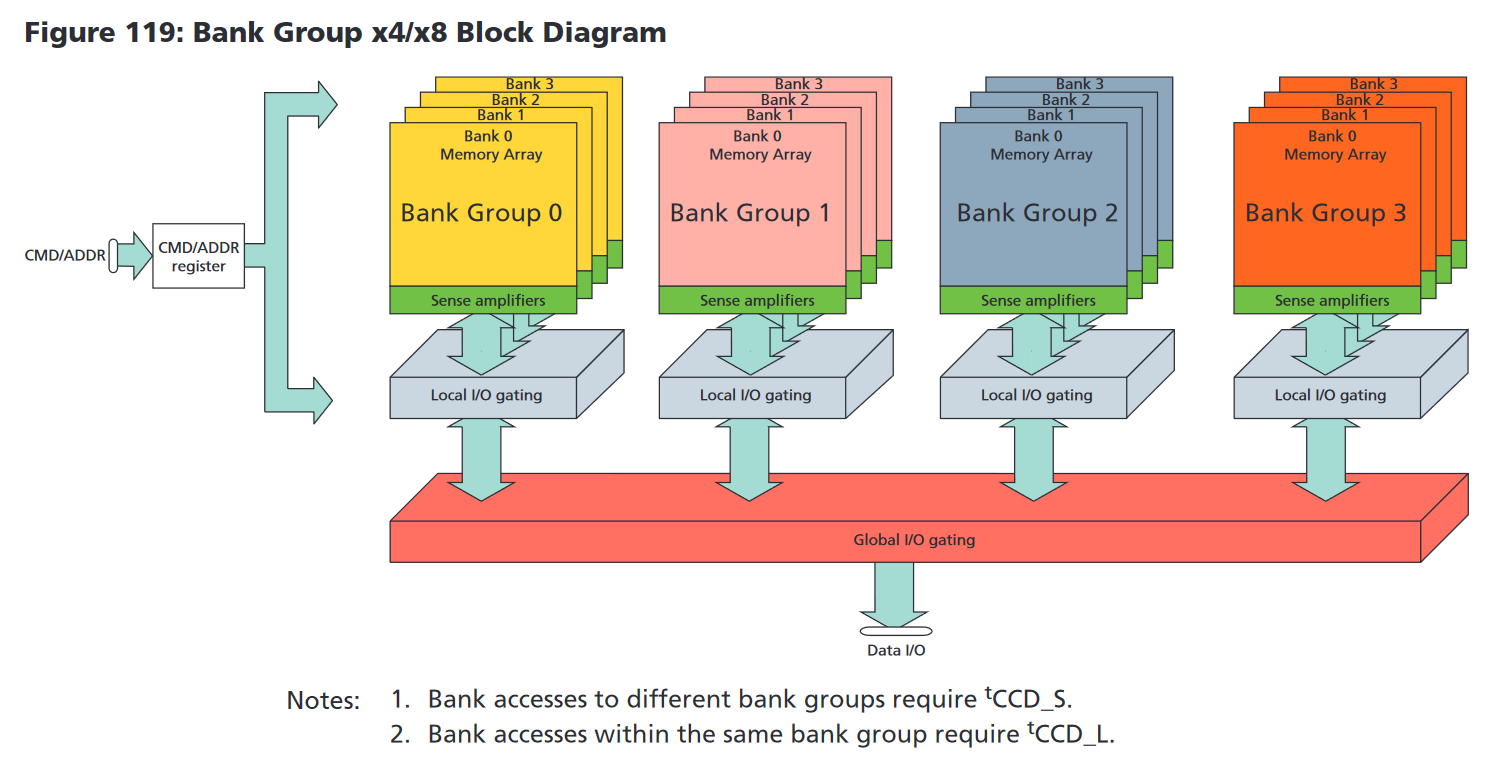
上に件のMicronのデータシートに描かれている、BankとBank Groupの図を持ってきた。Bank Groupが4つあり、1つのBank Groupあたり4つのBankがあり、合計で16Bankという構成となっている。
先程の状態遷移図の状態はそれぞれのBankが持っている。ACTやREADなどのコマンドは各Bankに対しての指示となる。つまり、複数のBankを同時に開くことができる仕様となっている。先述の通り、行を閉じて(Precharging)再度別の行を開く(Activating)という工程には、急いでも合計して約30nsを要する。その間にそのBankは何もできないため各種信号線は空いていることになる。その間に他のBankに読み書きできれば、いわゆる遅延隠蔽を行うことができる。ただ、当然メモリコントローラ側がうまいことスケジューリングする必要がある。軽くどのような制御で帯域幅を稼ぐかを説明しよう。
DDR4にはコマンド間に取らないと行けないタイミング制約であるtCCDが2種類設定されており、違うBank Groupに対するコマンドれあれば短い方のtCCD_S、同じBank Groupに対するコマンドであれば長いtCCD_Lが適用されることになる。今回のDRAMチップではtCCD_Sは4クロックサイクルで2.5ns、tCCD_Lは5nsとなる。この"4クロックサイクル"というのはちょうど1回のバースト転送に必要な時間であり、これをうまいこと使いREADを発行すると下図のように連続で一気にバースト転送ができる。
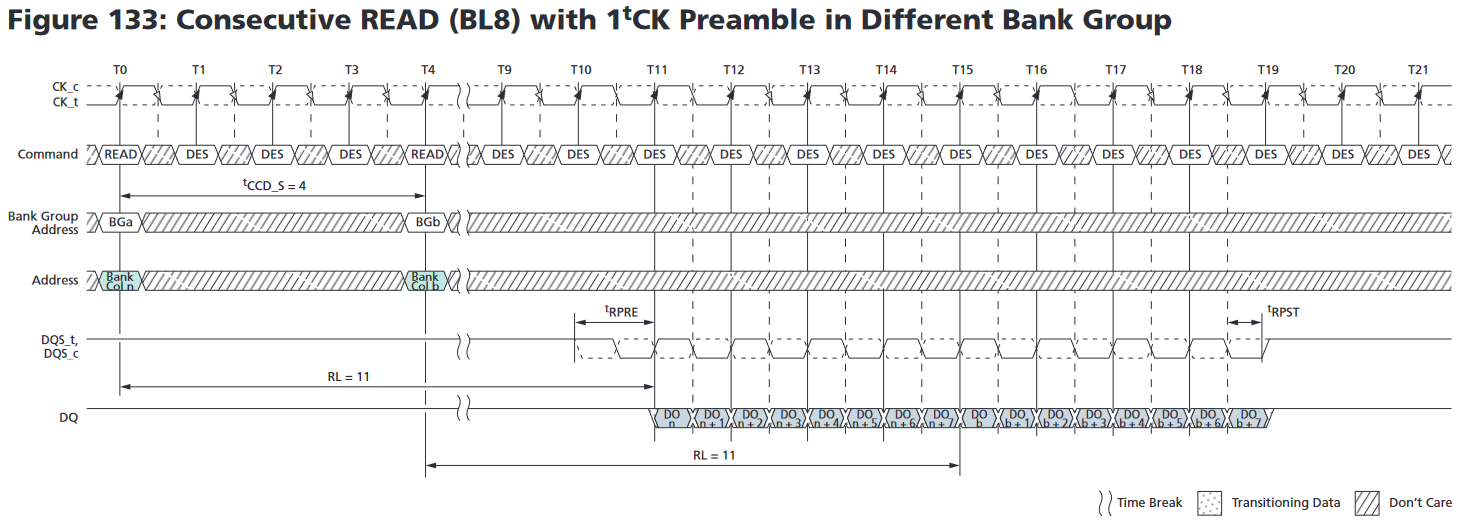
現状で開いている行に該当データがあるなら、異なるBank Groupに対して要求を交互に投げることでかなり長いことピーク速度で読み取りを継続することができる。この間は1つのチャンネルでいわゆる「モジュール規格」と呼ばれている"PC4-24000"みたいな数字の後ろにひっついている帯域幅をそのまま叩き出すことができる。 ただ、これを継続して出し続けられるわけでもなく、JEDECはPC4-3200のようにDIMMに対しても周波数でDisign Specificationとかを出しているため、この帯域幅ベースの名前は出処がよくわからない…。 (2021/12/15 追記) よく見たら、JESD21-Cに普通にModule bandwidthって書いてありました。

一方で、同じBank Groupに対する読み取りのタイミングチャートは上のようになる。図にする意義はあまり感じなかったが、今回のDRAMチップの場合はtCCD_Lが2倍の8クロックサイクルになるため、読み取りの間に待ちがありスループットが半減する。すなわちなるべく同じBank Groupにアクセスを集中させないことが、DDR4 SDRAMを使いこなすコツであり、ここがメモリコントローラを始めプロセッサ、ソフトウェアのチューニングのコツとなったりする。このばらばらの領域にデータを格納して、それに順次アクセスしていくことで高速化を狙うことをmemory interleavingというが、たぶんPart 4で触れるので今はスルーしよう。
ちなみに、なぜ同じBank Groupだと時間がかかるのかというのは、各Bank GroupのLocal I/O gatingの準備に時間を要するからである。Bank Groupを切り替えながら動作させるとこの遅延を隠蔽して隙間無しでDQにデータを吐き出し続けられる。
リフレッシュ
DRAMはキャパシタに電荷を蓄えて記憶しているために、一定期間ごとにリフレッシュで電荷を継ぎ足ししないとデータが消えてしまう、というのは割と常識的な知識であろう。だが、具体的にはどれぐらいの間隔でリフレッシュすれば良いのだろうか?これも当然データシートに書いてあるのだが、-40℃から85℃の間では64ms(ミリ秒)である。この数字はかなり昔から変わっていない。だがいきなりツッコミポイントがいくつかあるだろう。
まず温度である。これはDRAMに限った話ではないが、多くの物理現象は温度が上がると急激に加速する性質を持っており、キャパシタの自然放電もその性質を持っている。このリフレッシュ間隔もデータシートを見ると85℃を超えると32ms、95℃を超えると16msとどんどん厳しものに変わっていく。
逆に冷やせばより長い時間電荷が残ることを意味している。Cold boot attackと呼ばれる攻撃を耳にしたことがある人も多いだろう。DRAMチップのデータシートではきめ細かい連続的な間隔調整が難しいため、-40℃まで64ms固定の数字が書かれているが、これはあくまで取扱説明書として指定されている数字というだけで、-40℃まで冷やせば分単位でほとんどのメモリセルの電荷を維持することが可能だ。(ここまで冷却しなくても良いのだが)DRAMを冷やしつつコンピュータのDRAMを繋ぎ変えて無理やり中のデータを読み取るというのはかなり昔からありつつ、対処の難易度が高い攻撃手法として存在する。「コールドブート攻撃」などで調べてみると色々情報が手に入るだろう。
さて、先の64msというリフレッシュ間隔は「1つのメモリセルの立場に立ったときの間隔」だ。DRAMチップにはそれこそ無数のメモリセルがあるために、それら(ほぼ)全てに対して64ms以内にリフレッシュを掛ける必要がある。要はリフレッシュのスケジューリングだ。まずはミクロな視点でのリフレッシュの仕組みを確認しよう。と言っても、Part 1に必要なことはすべて説明しているのでサクッと文章だけで説明する。プリチャージとsense amplifierをきちんとPart 1で理解すれば、DRAMに関して怖いものなしだ!(?)
リフレッシュもミクロな目線ではメモリバンク単位の動作となる。まずは事前にメモリバンクをプリチャージしておく。次にリフレッシュしたい行を開きつつsense amplifierをEnableにする。そして一定時間たったらワード線とsense amplifierを切って行を閉じる。こうすると1行リフレッシュが完了する。ほとんど読み取り動作と同じである。ただ、読み取りと違って外にデータを出す必要がなく、外部IOの駆動などを一切待つ必要がないので、普通のActivationよりは短い時間で済む。
なぜこれでリフレッシュができるかはPart 1の説明で分かる…はず。わからなかったらコメントなりでリクエストしてくれれば、Part 1再構成してここか別記事に追加する。
ただ、それでも数十nsは要する作業だ。ざっくり1つに30nsと換算して、すべての行に対して1つ1つ実行すると今回のチップは1つのBankの行数が65536、それが16個あるので30ns * 65536 * 16 = 31.46ms、これを64ms間隔で実行などしていたらその半分をリフレッシュに充てる必要がある!無茶苦茶だ!というわけで、実際のDRAMチップにはこの辺りをうまくできるREFRESHコマンドがある。
まず、メモリコントローラがリフレッシュのためにやるべきことは、基本としてはtREFI=7.8μsおきにREFRESHコマンドをDRAMチップに指示し、毎度コマンドを送った後はtRFC=350nsの間、DESコマンド(要は何もしない)を送り続ける、これだけである。オーバーヘッドは約4.5%だ。この数字に関して人によって感想が大きく異なるかもしれない。先の50%近くをリフレッシュに費やしていたのに比べればはるかに短くなったが、だいたい1/20の時間がリフレッシュに使われているというのは、ちょっと ![]() という顔になる人も多いだろう。そして、大変厳しいことにこの割合はどんどん増えてきている。
という顔になる人も多いだろう。そして、大変厳しいことにこの割合はどんどん増えてきている。
最初の試算で出した約50%と実際のDRAMチップのオーバーヘッドの違いは主にすべてのバンクが並列でリフレッシュしていることに依存している。今回は16バンクあるので、ちょっと誤差はあるが「なるほど」という感じがするだろう。そして、メモリセル自体の必要リフレッシュ間隔がほとんど変わらない以上、リフレッシュオーバーヘッドはメモリバンク1つ当たりの行数に概ね比例することになる。これはかなり深刻な問題だ。ご存じの通りDRAM製品の容量はどんどん増えており、それに伴いDRAMチップ自体の容量も増えている。列数も増やせるので、比例まではいかないが、データシートを見ると1チップの容量が4倍になるとリフレッシュの時間も2倍ちょっと増える傾向が見える。(ちなみに、なぜかMicronのデータシートだと8Gbと16Gbが同じだが、Samsungは16Gbのものは550nsかかるといっており、おそらくMicronのは誤植…?真偽は不明)
DDR5でも1チップあたりの容量が最大で4倍にもなる見通しだ。一方でバンク数は2倍の32に留まる。DDR5系の正確なデータを持ち合わせていないが、行と列を同じペースで増やすと最大密度の場合で約10%のリフレッシュオーバーヘッドとなる。ここまでくるとさすがにリフレッシュ時間を隠ぺいする方針を取る必要がある、ということでDDR5では一部のバンクだけリフレッシュしてその間に別のバンクは操作可能という機能が追加されるらしい。ちょっと前までは「リフレッシュのオーバーヘッドは電力の問題にはなっても、性能面では誤差誤差」と言ってられたのだが、DRAMの密度があまり上がりすぎたせいで、もはやそんなことも言ってられなくなってきたといっていいだろう。
ところで、教科書的なリフレッシュのメカニズムの場合、先述の通りメモリバンクの行数に比例したオーバーヘッドが発生する。だが、データシートでは「チップの密度」の依存したオーバーヘッドになっている。おそらくはsense amplifierの配置などの工夫でどうにかしているのだろうかと想像はするのだが、筆者の知識不足で正確な手法などはわからなかった。もし公知な情報を知っている識者の方がいたら教えてほしい。
DRAMダイとPCB
半導体製品の設計において**「貴重な資源」と言ったら何を想像するだろうか?面積?電力?メタル層?それらも大変重要であり、頭が痛い問題であるのは事実だろう。だが、近年の大規模集積回路の設計者はおそらく「パッド」や「ピン」をその上位に上げるだろう。端的にいえば「端子」**である。半導体製造プロセスの微細化に伴って、シリコンダイ本体に集積できる回路は確かに高密度になったのだが、そこに対して電力を供給したりIOを担うための端子は同じペースでは高密度になっていない。端子の数は設計の大枠そのものを縛るために、「端子がいっぱいあったら」という仮定をが語られることは少ないが、確実に半導体の能力を制限してくるのは確かだ。なんたって同じ周波数で動いてたってピン数を2倍にできれば2倍の帯域幅を稼ぐことができる。ただし、それは大抵の場合コスト増大を招くために現実的ではない。端子は高いのだ。まずは今のパッケージング技術をおさらいしよう。
基本はDie, Package Substrate, PCBの3層
上は半導体大手のサムスンのパッケージング技術の解説ページだ。ただ、最新技術を説明するためにかなりごちゃっとしてるので、軽く基本的な構成を以下に示す。あくまで構成の一例であり半導体製品によって大きく異なるし、同じDRAMでもメーカーや世代、容量などによって変動があるかもしれない。とりあえずは、パソコン向けの安価なDRAMの代表例としてはメジャーな構成を示す。
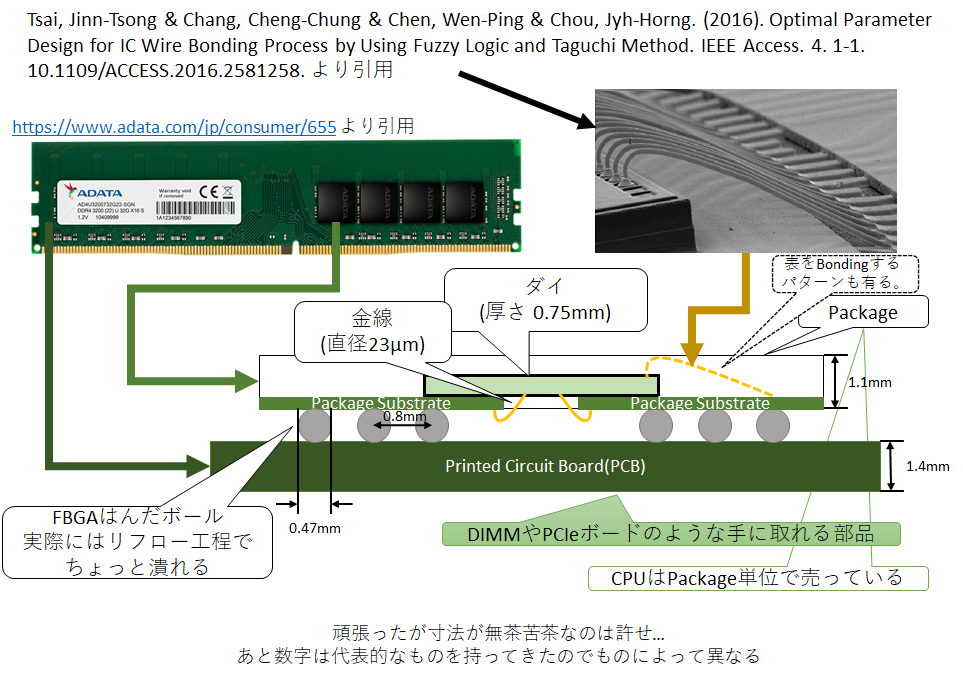
↓DRAMパッケージ外観例 https://eetimes.itmedia.co.jp/ee/articles/1802/21/news030.html より引用

これまで説明した機能が実装されているダイ(Die)は見た目が黒いパッケージの中に収められており、Part 1で示したとおり、キラキラしたきれいな薄膜だ。ただこれはあまりにペラペラで部品として供給するのが難しいため、通常は樹脂製のパッケージに封止して出荷する。そのパッケージの外部とダイを電気的に中継するための基板が"Package Substrate"だ。「パッケージ基板」という名の通り、一般名詞でありその材質や形状、作り方や中の配線に至るまで実に多様なものが開発されている。また、場合によっては1つのパッケージに複数のPackage Substrateが使われている場合もあるが、それはまた別のお話。
安価な一般な1枚のダイを封止したSingle Die Package(SPD)のDRAMの場合には真ん中に空いたPackage Substrateが使われていることが多い。そこにダイを裏返し、すなわちダイの回路が焼かれた面を図の下向きにしてPackage Substrateに接着、その後にPackage Substrateの真ん中の穴を通して、Package Substrateとダイを金線でつなぐ。もちろんこれも金がメジャーというだけで、金じゃない場合もある。この金線でつなぐのを「ワイヤーボンディング」と呼ぶ。ワイヤーボンディングのピッチは概ね150μmぐらいだと認識してもらえば問題ない。もちろんこれも物による。そして、どこをどうワイヤーボンディングするのも当然物による。DRAM以外に目を向けるとダイを裏返さずに表をワイヤーボンディングするケースが多いように思う。先の図にはその時の顕微鏡写真も掲載した。
ちなみに、工業製品の場合はこれをワイヤーボンダーと呼ばれる工作機械で自動で行う。その様子がなかなか見てていい気分になれるので貼っておこう。
ワイヤーボンディングを行った後は、全体をモールド樹脂で固めて封止する。
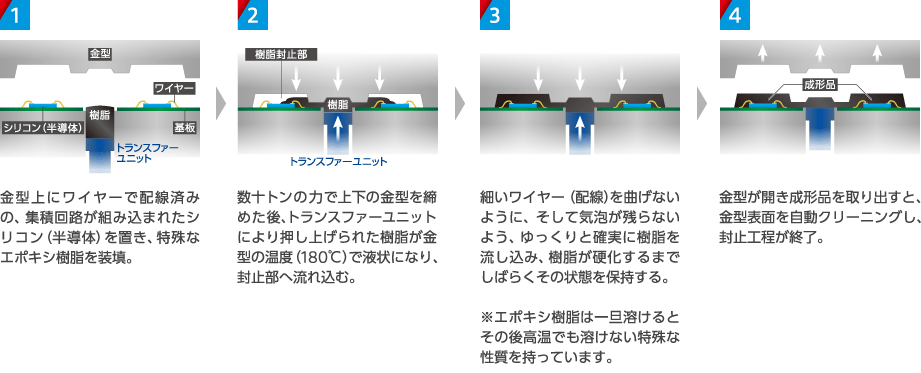
https://www.corp.i-pex.com/ja/product/semiconductor/process より引用
その後、FBGAのはんだボールを取り付けて、DRAMチップ、もといDRAMパッケージは完成だ。後は製品テストをして更に大きなパッケージに梱包して出荷となる。Micronによる製造工程の動画もあるので貼っておく。
なお、この解説ではパッケージを指して「DRAMチップ」と呼んできたが、半導体業界では「チップ」という呼称で「ダイ」のことを多い。Part 1でちらっと言及したMulti-Chip Moduleの"Chip"はパッケージではなくダイを指している。ただ、パッケージと一般に言うともっと大きな箱のようなものを想像されるので、あえてPart 1でDRAMチップでパッケージを指すようにした。ダイはダイと呼べば良いので…。
はんだボールの数が設計を律するが…?
今回対象としているDRAMチップには78個のはんだボールが取り付けられており、その割当は以下の通りである。これもデータシートにある。そして、ページをめくると96個のものもある。
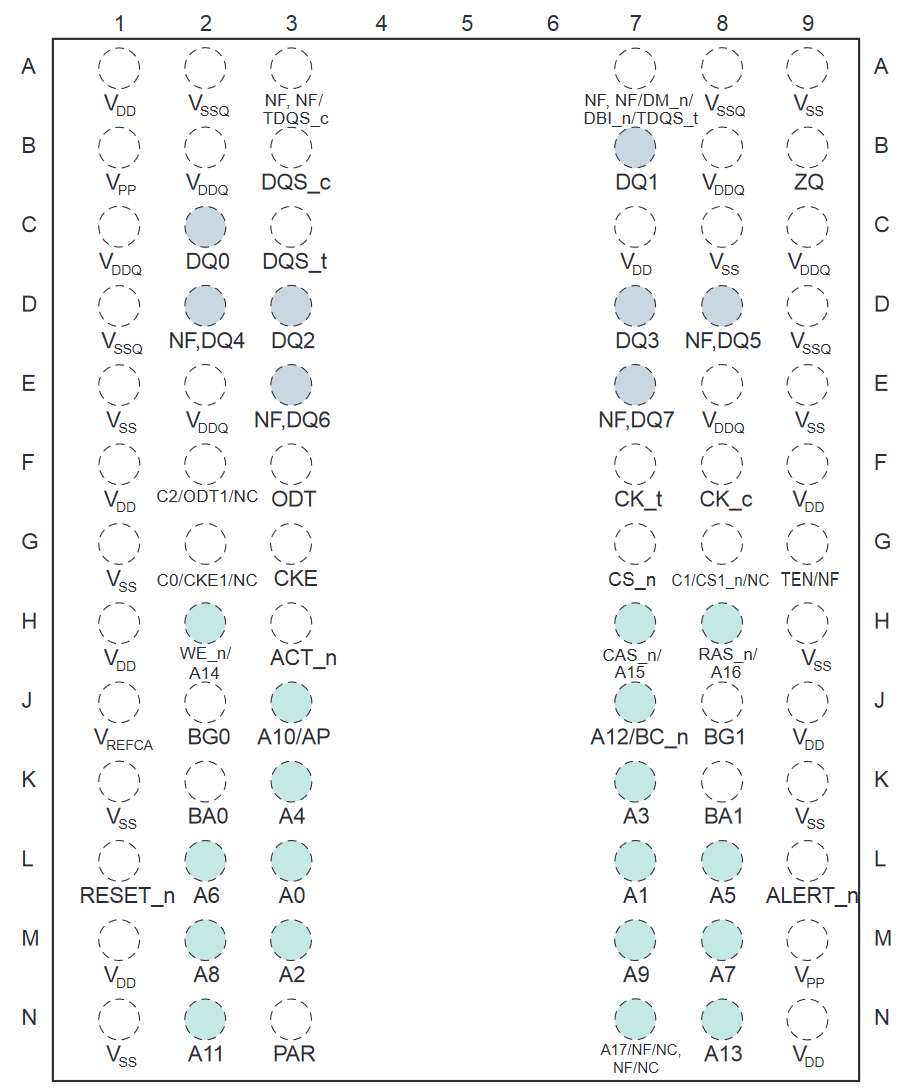
きちんと設計されているために、端子の余りはなくむしろ同じ端子を複数用途に使いまわしているぐらいだというのがよく分かるだろう。もちろん、ピン数を増やすというオプションもありえ、それが16bit幅の96-Ballのものだが、物理的な寸法も大きくなる。一般にパッケージ外寸と比べて、中に収まっているダイのサイズは小さいことが多い。そこから、ワイヤーボンディングで一回り大きなスケールのPackageにつなぎ、最終的にはPCBという巨大なボードに固定する必要がある。この中で生で半導体パッケージを買ってきて、自宅炉(?)でリフローしてパソコンを組み立ててる人は皆無だろう。(CPUは例外で、パッケージ単位で売っているが、さすがに固定はLGAかPGAのソケットだ。加熱はいらない。)PCBにしないと商品にならないのだ。そして、PCBに固定するに当たって大体0.5mmぐらいのオーダーでの端子の間隔や端子のサイズが必要になる。もちろんコストを度外視すればもっと高精度ピッチなども可能なのだろうが、それだと製品の価格が跳ね上がってしまい、誰も買ってくれないために、製品の端子も自ずとその標準的なサイズとなる。
こうなると、端子数を増やすためにはPCB上の配線数を増やす必要もあり、製品自体を大きくして行くことになるが、こういう商品は普通コンパクトな方が良い。そうすると当然配線の間隔や幅を縮める必要が出てきて、それらはクロストークや特性インピーダンスの増大を招き、PCB設計をよりシビアにする。そして、DIMMのような更に別のPCBに取り付ける製品の場合はその接続端子も増やす必要も出てくる。色んな所にしわ寄せが行くために、端子数を増やすというのは大変コストが高いことなのだ。
そして、DRAMチップというのは各種半導体製品の中でも価格競争が激しく、かなり安い製品であることを忘れてはならない。1つのパッケージの価格は容量などで変動はあるものの、多く流通しているものは数ドル程度の価格だ。DIMMの販売価格ベースで見ても16GBのDIMMが1万円を割っているのが当たり前で、そこには8GbのDRAMチップが16枚搭載されている。PCBの価格や組み立て価格をすべてゼロとしてもDRAMチップ1枚が1000円を超えることはありえない。極限までコストを切り詰めなければならない製品なのだ。
それと比較するとパソコン向けCPUはとんでもない富豪プレイをしていることがわかる。工具無しで取付可能な高価なLGAやPGAを1000から2000ピン程度用いており、価格が1万円を下回ることは極稀で個人向けでも10万近くに匹敵するものがラインナップされ、そして普通に売れている。あまりビジネスは得意ではないので確かなことは言えないが、CPUはブランドや性能面での差別化がやりやすいが、DRAMはあまりにコモディティ化してしまい価格以外で価値を出すのが難しいのが大きいのではないかと思う。パソコンオタクじゃなくても、自分のパソコンのCPUのブランド名ぐらい分かる人は多いだろうが、自作PCやってる人でも自分のパソコンのDRAMチップメーカーを把握している人は稀だろう。というか、最近のDRAMはヒートシンクのせいで見えないことも多い。普通の無印DRAMで商品価値を出すのは究極的に難しいのだ。
Part 3の予定
さて、DRAMチップすなわちパッケージまで話したので、次はPCBに移ろう…と言いたいところだが、PCBの話に入るためにはある大きな壁を超えないと行けない。それがGHzの壁だ。本当はPart 2としてそれをやろうと思ったのだが、あまりにPart 2が長くなってしまうのと、私個人の手が空かないせいでいつまで経ってもできる気がしないので、とりあえずここで切る。
今度こそGHzオーダーの高周波信号の闇を見ることとなるだろう…!(すまぬ!)