@cosme(アットコスメ)の商品口コミをpythonで収集する方法を知りたい
@cosme(アットコスメ)の商品口コミをpythonで収集する方法を知りたい
大学の研究でテキスト分析をすることになり、化粧品の口コミを集めることにしました。
利用規約にスクレイピングに関することが記載されていましたが、学術利用であることを問い合わせたら許諾されたので、倫理的に問題はありません。
商品レビューのURL例(https://www.cosme.net/products/10258796/review/?page=2)
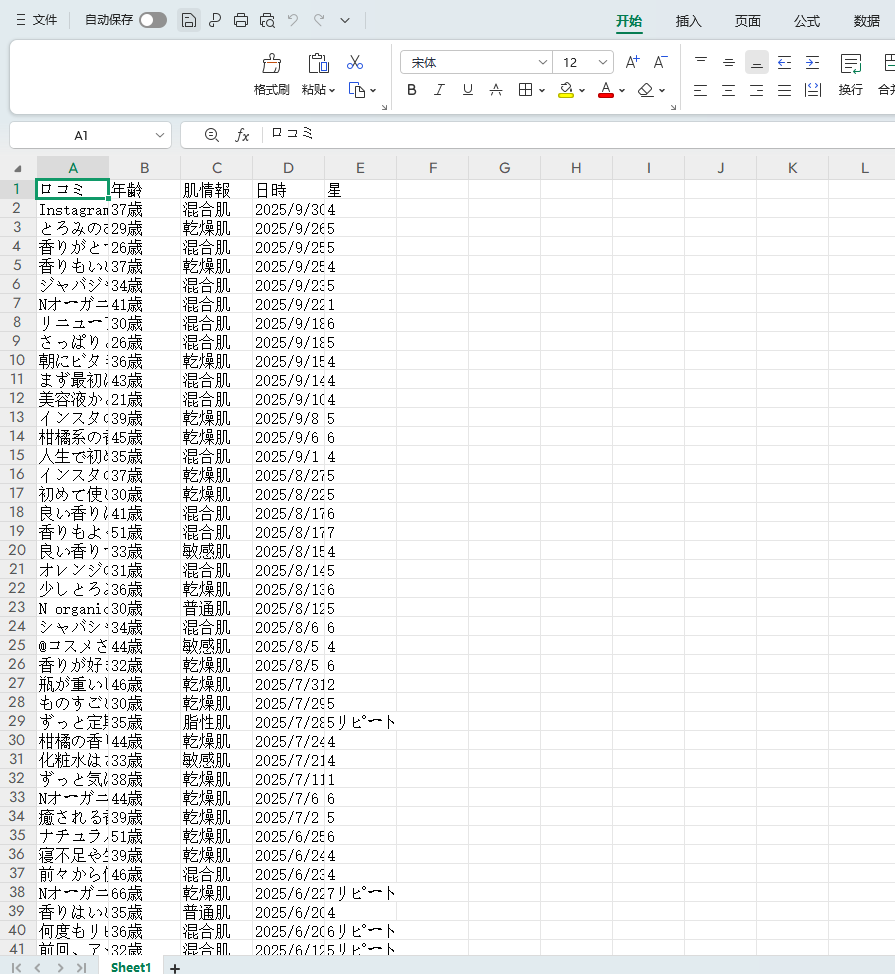
このURLのページから「年齢」「肌情報(乾燥肌、混合肌など)」「口コミ」「星」のようにカテゴリを分けてデータを集めたいです。
該当するソースコード
from bs4 import BeautifulSoup
import requests
import pandas as pd
import time
from datetime import datetime as dt
from google.colab import files
def get_10reviews_list(soup):
"""
10件ごとの一覧ページから、指定範囲の投稿日の口コミurlを取得
投稿日をkey、口コミurlをvalueとした辞書を出力
"""
read = soup.select("p.read")
review_urls = [s.a.get("href") for s in read]
#各口コミのURLはp class="read"内のaタグに格納されているので
#p class="read"をリスト取得して、それぞれのhrefを取得
for i in range(len(read)):
soup.select_one("p.reviewer-rating").decompose()
#投稿日はdiv class="rating clearfix"内のp class="date"もしくは"mobile-date"
#に格納されている。deteとmobiledateで2種類あるため、rating clearfixにある
#ほかの内容(p class="reviewer-rating)を削除して、div内に投稿日情報のみ残す。
div = soup.select("div.rating.clearfix")
review_dates = [dt.strptime(i.text.strip(),"%Y/%m/%d %H:%M:%S") for i in div]
#投稿日を上から順に、datetime情報に変換しながらリストとして取得
dic = dict(zip(review_dates,review_urls))
#投稿日をkey、口コミURLをvalueとした辞書を作成
return dic
def next_check(soup):
"""10件ごとの一覧ページに「次に」があるかどうかを判定
「次に」があればTrue、なければFalseを返す"""
next = soup.select_one("li.next span")
return next == None
#最終ページの「次へ」がspanになっていることを利用。
def get_review_data(url):
"""
指定のアットコスメ口コミurlからデータを抽出
投稿者情報などをリストで出力
"""
rev_response = requests.get(url).text
soup = BeautifulSoup(rev_response,"html.parser")
#レビューページのレスポンス
review = soup.select_one("div.body p.read").text
if soup.select_one("span.buy"):
buy = soup.select_one("span.buy").extract().text
#購入情報があれば抽出してテキスト化
else:
buy = "-" #購入情報がない場合はハイフン
#購入情報がないことがあるため、ifで分岐
if soup.select_one("span.repeat"):
repeat = soup.select_one("span.repeat").extract().text
#リピート情報があれば抽出してテキスト化
else:
repeat = "-"#購入情報がない場合はハイフン
#リピート情報がないことがあるため、ifで分岐
if soup.select_one("div.rating.clearfix p.reviewer-rating"):
score = soup.select_one( \
"div.rating.clearfix p.reviewer-rating").extract().text
else:
score = "-"
#スコア情報を取得。スコアなしのエラーを防ぐためif分岐
if soup.select_one("dl.item-status.clearfix ul"):
status = soup.select_one( \
"dl.item-status.clearfix ul").text
else:
status = "-"
#購入品、サンプル品、プレゼント情報を取得。スコアなしのエラーを防ぐためif分岐
if soup.select_one("div.rating.clearfix p.date"):
date = soup.select_one("div.rating.clearfix p.date").text
else:
date = soup.select_one("div.rating.clearfix p.mobile-date").text
#日付情報を取得
reviewer_name = soup.select_one( \
"div.reviewer-info span.reviewer-title").text
#投稿者名を取得
revewer_profs = soup.select("div.reviewer-info li")
age = revewer_profs[0].text.replace("歳","")
skin = revewer_profs[1].text
#年齢と肌情報が並列で並んでいるため、リストとして入手して分割
datalist = [date,reviewer_name,age,skin,score,buy,review,status,repeat]
return datalist
#ここからメイン
code = input("クチコミを読みたい商品コードを入力してください")
start = dt.strptime(input("開始日時 yyyy/mm/dd hh:mm:ss"),"%Y/%m/%d %H:%M:%S")
end = dt.strptime(input("終了日時 yyyy/mm/dd hh:mm:ss"),"%Y/%m/%d %H:%M:%S")
file_name = input("口コミリストを保存するファイル名を入力してください")
product_url = "https://www.cosme.net/product/product_id/" + str(code) + "/reviews/p/"
page_count = 0 #アットコスメは0ページ目スタート
all_urls = [] #ループの外側にてURLsをリストと宣言
craw_frag = True
while craw_frag:
print(f"{page_count + 1}ページ目") #進捗表示
list_response = requests.get(product_url+str(page_count)).text
soup = BeautifulSoup(list_response,'html.parser')
dic = get_10reviews_list(soup)
for date in dic.keys():
if start <= date <= end:
all_urls.append(dic.get(date))
elif date < start:
craw_frag = False
break
#投稿日が設定範囲に入る場合、その口コミurlをall_urlsリストに蓄積。
#アットコスメ口コミはデフォで新しい順に並ぶので収集開始日時よりも
#古い口コミが出てきた時点で一覧のクローリングをストップする。
if next_check(soup):
page_count += 1
time.sleep(3)
continue
else:
craw_frag = False
print(f"一覧読み込み完了 レビュー{len(all_urls)}件 各レビュー読み込みを開始します")
rev_count = 1
columns = ["date","name","age","skin","score","buy","review","status","repeat",]
df = pd.DataFrame(columns=columns)
error_url_list = []
for url in all_urls:
print(f"{rev_count}件目 / {len(all_urls)}件 / エラー{len(error_url_list)}件")
#口コミ取得の際にエラーが出るとこれまでの読み込みが止まってしまうので
#回避のtryブロックを追加。その場合は結果のエクセルとリストに対象urlを吐き出す。
try:
se = pd.Series(get_review_data(url),columns).str.strip()
except:
error_message_dl = ["Error",f"No.{rev_count}","-","-","-","-",url]
se = pd.Series(error_message_dl,columns).str.strip()
error_url_list.append(url)
df = df.append(se, columns)
rev_count += 1
time.sleep(3)
df.to_csv(file_name+".csv", index = False, encoding = "utf_8_sig")
files.download(file_name+".csv")
print("プログラムを終了します")
自分で試したこと
URLの様式が古かったのでその部分だけ修正したが、うまくできない。
0 likes