大っきくてうまいんです
公式
https://github.com/xingyizhou/CenterNet
日本語のスライド
https://www.slideshare.net/DeepLearningJP2016/dlobjects-as-points
手順参考
https://qiita.com/sonodaatom/items/fe148a177b1d1b40c34d
CenterNetの特徴
YOLOv3やM2Detよりも速くて、精度がいいらしいです。
Objects as Pointsという中心点を推測するやり方で、NMS(Non-Maximum Suppression)をすっ飛ばせるらしいです。
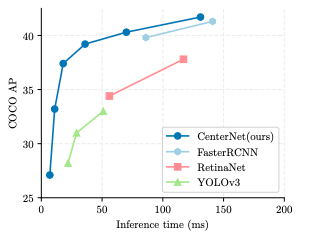
GPUが必要、ならGoogleColaboratoryで
まずマウントします
from google.colab import drive
drive.mount('/content/gdrive')
僕はGPUを確認します。ワクワクするからです。
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
-> physical_device_desc: "device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0"
GoogleCoraboratoryで僕がみたことあるのは、P100、T4、K80、P4です。T4、P100が当たると嬉しいです。
マイドライブ配下にcenternetというディレクトリを作って、作業します。
%cd /content/gdrive/My\ Drive/centernet
!git clone https://github.com/xingyizhou/CenterNet.git
%cd CenterNet
!wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64-deb
!dpkg --install cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64-deb
!sudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub
!sudo apt-get update
!sudo apt-get install cuda-9-0
!nvcc --version
!pip install -U torch==0.4.1 torchvision==0.2.2
!pip install -r requirements.txt
%cd /content/gdrive/My\ Drive/centernet/CenterNet/src/lib/models/networks/DCNv2/src/cuda
!apt install gcc-5 g++-5 -y
!ln -sf /usr/bin/gcc-5 /usr/bin/gcc
!ln -sf /usr/bin/g++-5 /usr/bin/g++
!nvcc -c -o dcn_v2_im2col_cuda.cu.o dcn_v2_im2col_cuda.cu -x cu -Xcompiler -fPIC
!nvcc -c -o dcn_v2_im2col_cuda_double.cu.o dcn_v2_im2col_cuda_double.cu -x cu -Xcompiler -fPIC
!nvcc -c -o dcn_v2_psroi_pooling_cuda.cu.o dcn_v2_psroi_pooling_cuda.cu -x cu -Xcompiler -fPIC
!nvcc -c -o dcn_v2_psroi_pooling_cuda_double.cu.o dcn_v2_psroi_pooling_cuda_double.cu -x cu -Xcompiler -fPIC
%cd /content/gdrive/My Drive/centernet/CenterNet/src/lib/models/networks/DCNv2
!python build.py
!python build_double.py
%cd /content/gdrive/My Drive/centernet/CenterNet/src/lib/external
!make
%cd ../../
https://github.com/xingyizhou/CenterNet/blob/master/readme/MODEL_ZOO.md
ここからモデル(ctdet_coco_dla_2x.pth)をダウンロードして、下記におきます。
/content/gdrive/My\ Drive/centernet/CenterNet/models/
import sys
import cv2
import matplotlib.pyplot as plt
from detectors.detector_factory import detector_factory
from opts import opts
%matplotlib inline
MODEL_PATH = "../models/ctdet_coco_dla_2x.pth"
TASK = 'ctdet' # or 'multi_pose' for human pose estimation
opt = opts().init('{} --load_model {}'.format(TASK, MODEL_PATH).split(' '))
detector = detector_factory[opt.task](opt)
coco_names = ['person', 'bicycle', 'car', 'motorbike', 'aeroplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'sofa', 'pottedplant', 'bed', 'diningtable', 'toilet', 'tvmonitor', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush',]
https://github.com/mozilla/Fira/blob/master/otf/FiraMono-Medium.otf
フォントファイルを/content/gdrive/My Drive/centernetとかにおきます。
from PIL import Image, ImageFont, ImageDraw
import numpy as np
import colorsys
from pylab import rcParams
rcParams['figure.figsize'] = 10,10
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / len(coco_names), 1., 1.)
for x in range(len(coco_names))]
colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
colors))
np.random.seed(10101) # Fixed seed for consistent colors across runs.
np.random.shuffle(colors)
def write_rect(image, box, cl, score):
font = ImageFont.truetype(font='/content/gdrive/My Drive/centernet/FiraMono-Bold.otf', size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
# font = 1
thickness = (image.size[0] + image.size[1]) // 300
label = '{} {:.2f}'.format(coco_names[cl], score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
left, top, right, bottom = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=colors[cl])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=colors[cl])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
画像の物体検出してみます。
img = "/content/gdrive/My Drive/centernet/CenterNet/images/33823288584_1d21cf0a26_k.jpg"
rets = detector.run(img)['results']
img = Image.open(img)
print(img)
for i in range(len(rets)):
ret = rets.get(i+1)
if ret.shape[0]==0:
continue
ret = ret[ret[:,4]>0.6]
for box in ret:
write_rect(img, box[:4], i, box[4])
plt.imshow(img)
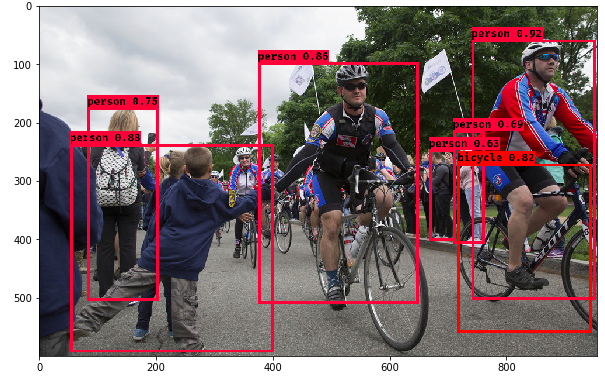
本当はOpenPoseをやりたかったのですが、よくわからなかったので一旦物体検出で
動画を吐き出してみます。
def cv2pil(image):
new_image = image.copy()
if new_image.ndim == 2:
pass
elif new_image.shape[2] == 3:
new_image = cv2.cvtColor(new_image, cv2.COLOR_BGR2RGB)
elif new_image.shape[2] == 4:
new_image = cv2.cvtColor(new_image, cv2.COLOR_BGRA2RGBA)
new_image = Image.fromarray(new_image)
return new_image
def pil2cv(image):
new_image = np.array(image, dtype=np.uint8)
if new_image.ndim == 2:
pass
elif new_image.shape[2] == 3:
new_image = cv2.cvtColor(new_image, cv2.COLOR_RGB2BGR)
elif new_image.shape[2] == 4:
new_image = cv2.cvtColor(new_image, cv2.COLOR_RGBA2BGRA)
return new_image
fourcc = cv2.VideoWriter_fourcc('m','p','4','v')
_video = cv2.VideoWriter('footsal.mp4', fourcc, 10.0, (568, 320))
適当な動画をgdriveにあげて、解析結果を動画にします。
video = "/content/gdrive/My Drive/centernet/CenterNet/images/IMG_6880.mov"
cam = cv2.VideoCapture(video)
counter = 0
while cam.isOpened():
counter += 1
_, img = cam.read()
if counter % 3 != 1:
continue
if _:
rets = detector.run(img)['results']
img = cv2pil(img)
for i in range(len(rets)):
ret = rets.get(i+1)
if ret.shape[0]==0:
continue
ret = ret[ret[:,4]>0.6]
for box in ret:
# print('box',box)
write_rect(img, box[:4], i, box[4])
plt.imshow(img)
_video.write(pil2cv(img))
plt.pause(.01)
else:
break
_video.release()
こんな感じです。
— 竹石 (@takezou23) December 5, 2019
まとめ
実運用を考えると、JetsonNanoでYOLOv3と速度比較したいです。