🐒 この記事は、Mac ユーザーで「包丁は料理に使うもの」であり「犯罪・復讐・脅迫に使うものではない」ことがわかる方、そして料理に興味を持つも「包丁の仕組み」が料理より気になる、形から入るタイプの方限定の記事です。
また、この記事は「いいね」(旧 LGTM)が付くたびに見直して何かしら手を入れています。変更通知も送りませんので、ストックくださった方は、お暇な時にまた覗きに来てください。(初稿 2018年02月08日)
「実施編」とは言ったものの、記事の後半は「機械学習の基礎の基礎」であるため、いささか長い記事になっています。ハンズオンというより、むしろ読み物なので、まずはお手すきにスマホとかでゴロ寝しながら読んでください。全体像を把握してからトライされるのが良いと思います。
はじめに
この記事は「人物 A の動画の顔を人物 B の顔に入れ替える技術文書」です。その「具体的な HowTo」と「機械学習を学習するための基礎の基礎」を記載しています。
ディープフェイク1つください
ディープフェイクに限らず、顔の置き換え技術は「フェイス・スワップ」と呼ばれ、さまざまな手法があります。
アイコラなどの違法なものがクローズ・アップされがちですが、昨今の SF 映画など CGI においては重要な技術でもあります。
「フェイス・スワップ」の手法で一般的なところでは、伝統的な技法であるコラージュのうちフォト・コラージュを使ったもので、その発展系が現在の主流である 3D のポリゴン・モデルを使った方法です。
映画の撮影で、顔や体に粒々や小さなボールを付けて全身タイツで撮影するシーンを見たことがあると思います。CGI の世界ではモーション・トラッキングと呼ばれ、3D モデルのポリゴンを動かすマーカーとして使われます。
ポリゴン・モデルによるフェイス・スワップは、顔のマーカーの動き(座標遷移)のデータを活用したものです。
具体的には、頭の形のポリゴン・モデルに顔のテクスチャを貼り、顔のマーカーの動きにあわせて得られたフェイク画像をコラージュしていく手法です。スターウォーズで、故人であるはずのレイヤ姫やターキン提督が顔の入れ替え処理で復活したのは記憶に新しいと思います。
この手法は Blender などのオープンソース 3D ソフトでも実現可能で、現在は FaceRig や Live2D などで VTuber の 3D モデルのアバターを動かす技術にも応用されています。
- The Ultimate Tracking Trick @ Youtube
- Live2DとVTube StudioでMacユーザーもアバターZoom @ Qiita
しかし、プロフェッショナルな現場では、3D モデルを使った手法はフレーム(1コマ)ごとに貼り付けた後に馴染ませるといった手作業も多く、技術力や時間などのコストがかかります。
物理的な特殊メイクの場合でも同様の問題があります。撮影するごとに準備に時間がかかるだけでなく、メイク量に比例して表情の情報量も少なくなってしまいます。より自然に見せるためには、やはりフレームごとの画像調整といった後処理が必要になります。
本記事では、ポリゴン・モデルなどから得られた画像をコラージュするのではなく、ディープラーニングで推測した画像を用いるモーフィングに近い「ディープフェイク」と呼ばれる手法を取り上げます。機械学習に使うツールにはオープンソースの faceswap を利用します。
決して「ディープフェイク」(ディープラーニングの技術)を使ったから作業量が減るというわけではありません。むしろ初期の期間は、従来の数倍の作業量や時間がかかると言っていいでしょう。例えると、新入社員が新卒どころか 5〜6 歳の子供に、仕事のかたわらで作業や業務を教える以上に手間がかかります。
推測と結果から学んだ人間の経験は、その人間個人に依存します。つまり退社されると技術も一緒になくなってしまいます。逆に、機械学習の場合は学習データが存続する限り、その経験値は残ります。
退社されると困る 120 点を叩き出す人間と、コンスタントに 70 点しか出せないが退社することはないマシンと天秤にかけた場合、長い目で見た時の組織全体の底上げという意味では作業の軽減化に繋がる可能性はあります。つまり、70 点までは保証されるので、そこからの修正やブラッシュアップに人間が注力できる、などです。
70 点は、一見高いと感じるかもしれません。しかし、人間と違い、これは 100 問中 30 問は必ず間違えるということでもあります。別の言い方をすると、100 文字のうち 30 文字は typo するようなものです。このことを認識せず神格化すると痛い思いをすることになります。
さて、「ディープフェイクの手法」と言っても、このあと説明する流れを見ればわかりますが技術的に特別なことをしていません。「ディープフェイク」という謎のディープな技術が使われているわけではなく、「すでに公開/認知されている既存の技術」にディープラーニングの要素を加えたものだとわかると思います。(簡単とは言ってない)
つまり、「ディープフェイク」は IT 業界お得意の「技術のマッシュアップに付いた名前」の1つなのです。
ひと昔前の Web 技術の「COMET」や「インターネット」のように「仲間内で説明するときに短く伝わるように名前が付いただけ」です。「例のアレ」的なノリで生まれたものです。
🐒 ここでいう「例のアレ」とは
reddit の @deepfakes というユーザーが提唱したディープラーニングを使った faceswap の例のアレから生まれました。そのため「インターネット」のように「ディープフェイク」という単語も、時代や伝達経路と共に意味が変わっていく可能性もあります。
さて、テレビの「テレ・ビジョン」のように、「何もないところに映像が現れること」を「ビジョン」と呼びます。「テレ」は「離れた空間」を意味します。
機械学習の世界でも、画像を生成するアルゴリズム(考え方)を使った処理全般を「コンピュータ・ビジョン」と呼びます。一般的に「CV」と略され、「ディープフェイク」も CV の一種です。
この記事でも取り上げている「OpenCV」は、オープンソースの CV のライブラリということになります。
最近では CV によるフェイス・スワップの技術そのものを指す場合、「ディープフェイク」と呼ばず「VFX(視覚効果)の新しい手法」や「DeepFace」と言った言い方もされます。
その活用方法の1つは、古い時代の SF 映画の修正などが考えられます。例えば Youtube の映像集団 Corridor Digital は、その可能性の1つを実験しています。
- We Fixed The Worst VFX Shot Ever @ Youtube
そして、現在注目を浴びているのは存命の年配の名優をフィーチャーした歴史ものです。
若いころから歳を取るまでのストーリーに同じ俳優を使うというもので、俳優を若返らせることができれば、若いころのシーンでも同じクオリティの演技を得られるという理屈です。若いころの回想シーンで俳優が変わり、その演技にションボリしたことがある人も多いのではないでしょうか。
この若返りにディープラーニングを活用するというのものです。
商業レベルの成功例としては Nexflix があります。「ゴッドファーザー」や「アンタッチャブル」以来の名作と名高い、Nexflix の大ヒットした「アイリッシュマン」は、ILM と共同でディープラーニングで名優を若返らせることに成功しました。若き頃の映像を機械学習させて「フェイス・スワップ」したのです。
- How The Irishman’s Groundbreaking VFX Took Anti-Aging To the Next Level | Netflix @ Youtube
特筆すべきは、過去の出演映像だけでなく従来の手法も機械学習の素材として活用した点です。
従来の 3D モデルの手法で作成した、さまざまな条件のデータ量を増やすことで精度を高めたのです。例えば光源位置の違いによる陰影などの素材です。
そうやって鍛えられた学習データは、俳優の顔画像を渡すと、若き頃の場合はどうなっていたか推測した画像を出力します。この時、渡す画像データにはマーカーも特殊メイクも必要ありません。
撮影時にマーカーや特殊メイクを必要としない一番のメリットは、役者が演技に集中できることです。
もちろん従来通り、あと工程で画像に馴染ませる作業は発生するものの、より自然に表情が表現できた(違和感がなかった)こともヒットにつながった理由の 1 つと言われています。
つまり、新しい技術や従来の技術だけに依存せずに、マッシュアップというか技術のコラージュともいえる「技術の良いとこ取り」でクオリティを上げたのです。
これに追随するのか、対抗するのか、天下のディズニーもフェイス・スワップやディープフェイスに関する論文を発表しています。
- High-Resolution Neural Face Swapping for Visual Effects @ Disney Research Studios
- その他の論文: publications @ Disney Research Studios
これらの集大成とも言えるのが、大ヒットしているスターウォーズ初のテレビドラマ「マンダロリアン」です。
下記メイキング(Behind the scenes)動画を観ると、若き頃のルーク・スカイウォーカー役をマーク・ハミル氏本人がメイクなしで演じており、ディープフェイクで入れ替えていると公言しています。さらに声も、若い頃の声を Respeecher で機械学習させて入れ替えているそうです。
しかし、この仕上がりに不満があったのか、様々なクリエイターが同じシーンを異なるディープフェィクのエンジンで再作成しました。
- We Made a Better CGi Luke Skywalker @ Youtube
- The Mandalorian Luke Skywalker Deepfake @ Youtube
面白いのが、後者のクリエイターは、そのクオリティと生産能力から、のちに本家 ILM に雇用されたそうです。
- Lucasfilm Hired the YouTuber Who Used Deepfakes to Tweak Luke Skywalker ‘Mandalorian’ VFX @ IndieWire
そして、先のマンダロリアンの続編ドラマである「ボバフェット」では、若かりし頃のルーク・スカイウォーカー(マーク・ハミル氏)がバンバン出てきます。時代ですね。
Deepfakes とその違法性
この記事は「技術を実際に使い、より良い活用方法のアイデアにつなげるための技術記事」です。Qiita の利用規約にある「著作権、特許権等の知的財産権を侵害する行為」「名誉毀損行為、侮辱行為や他者の業務妨害となる行為」目的には絶対に使わないでください。
重要なことなので、若干社会的な話しをします。
皆まで言いませんが、ディープフェイクが危険視されるのは、確かに社会のルールや法律のプロトコルがよくわからない人がいるのが一番の元凶です。いささかキツイ言い方ですが、そもそも「知ってるけど理解できない人」は、何を言っても理解できないのです。
全校朝礼で「当校の生徒が〜」と釘を刺しても同じことをする人がいたり、「出るな」と言われているのに「大丈夫だ」と外に出てゾンビに襲われたり、流れ弾に当たるモブキャラのような人たちです。
「一度、痛い思いをしないと理解できない」というのは、理解できている人の言い分で、わかっている人に釘を刺す効果しかありません。繰り返しますが、このことを「知って」いても理解できない人は、理解できないのです。
- 意味を一向に理解できない例
車のシートベルトやバイクのヘルメットが「俺は事故らないから大丈夫だ」とか「事故ったらそんなの効果ない」とか言う人が減らないため法律で義務化されたように、また「正当な理由」がない場合は例え果物ナイフであっても持ち歩いていたら逮捕されるのに「護身用にカッターを持っていたことが正当な理由だ」とかいう人がいるように、フェイス・スワップの技術の不当な利用の規制はやむなしだと思います。
もちろん、その技術やその業界のプロトコルを理解できないメディアや、ビジネスにされると困る人が違法な方の結果だけ見て単語を切り取っている感は否めません。
「インターネットは、嘘は嘘であると見抜ける人でないと難しい」と言われてから 20 年経過していますが、ネットからしか情報を得ないメディアも増えるなか、画像や動画に限らず、ディープラーニングによるフェイク情報は「裏取り(情報の確認)が面倒でしかない」からです。
つまり、「仕事が取られる」と言うより「自分の仕事が増える」臭いに反応している気がします。
結局のところ、イエロージャーナリズムをはじめ、ビデオテープ、電子書籍や動画配信が持たれていた懸念・利権やモラルの問題と同じだと感じます。そのため「e=mc2 は核兵器などの大量殺人につながるから教えるべきではない」と言うのと同じにならないように、規制する側もキチンと技術を理解した上で規制を考えて欲しいと思います。
まぁ、あらかじめ Qiita の利用規約を読んでいて「ハック」と「クラック」の違いがわかるかたには「お約束」事項なので不要だと思いますが。
リッピングと同じで、公にした時点から責任がついてくるぞ、ということですな。プロバイダを通してインターネットにアクセスしている以上、刑事訴訟になったら匿名なんて存在しないんですから。
この記事のゴール
さて、社会的な熱い話は置いておき、この記事のゴールとしては、ディープフェイクの「基本的な仕組み」「全体的な流れ」と「あー、こういう技術を使ってるのか」と概要をつかんでもらえればいいなと思います。
というのも、MacBookPro などの一般的な Mac では NVIDIA の GPU が使えないのが大半です。そのため CPU で処理することになり、時間がかかった割りには一発で期待する結果が出ることはほとんどなく、チューニング(素材や設定の微調整など)が必要だからです。
また、ディープラーニングそのものについては言及していませんが、編集後記にて「機械学習を学習する」ための初歩の初歩についても言及しています。「こういうデータ形式でデータを用意すれば機械学習に使えるんだ」というアイデアにつながればいいなと思います。
この記事の目的
私はスティーブ・ウォズニアック氏の「幸せの公式 H=S-F」1 支持者です。
// H = Happy(幸せ)
// S = Smile(スマイル)
// F = Frown(不快感)
/* 幸せの公式 */
H = S - F
ディープフェイクの技術も F(不快感) でなく S(スマイル) の要素を増やす方向に活用できれば H(ハッピー) が増えると信じています。
この記事の目的は「アニメーターさんや漫画家さんの負荷を減らすことは出来ないか」という S の要素を増やすための「最初のステップ」として作成されています。
漫画・イラスト・アニメーションのレイアウト・セルの作画などの1コマで、アタリで描かれた顔に「機械学習したキャラクターの顔」を後から置き換えることで「作業の軽減化」および「キャラクターの永続化ができないか」という目標のための最初の1歩です。(まぁ、この記事でやっていることは顔の入れ替えだけなのですが)
例えば、「顔を描くのが得意な人」がオリジナル・キャラの学習モデル(機械学習したデータ)を作って公開し、その学習モデルを、描くのは苦手だけど「ストーリーが得意な人」が使って作品を作る、といった手塚治虫先生ばりのインターネット上のスター・システムなどに最終的につながると良いなと思います。
🐒 もし、この記事がお役に立てたら、成果物/苦労した点/注意点/「やってみた」など Qiita 記事にして(ブログでしたらコメント欄に)リンクを貼っていただけると嬉しいです。
概要
さて、ここからが本編です。
「動画の顔を入れ替える」といっても、基本は「静止画の顔を入れ替える技術」を使います。なぜなら動画も静止画を時間軸に並べただけの、パラパラまんがと同じだからです。
重要なのが、一時流行った顔を入れ替えるスマホ・アプリや、一般的な画像編集アプリや、従来のコラのように、「切り取った画像を歪めてハメ込む」ような単純な合成ではないことです。ちゃんと入れ替え前の顔を元に「予測した顔画像を生成」するのです。
使われている技術
本記事で機械学習の技術は主に2ヶ所で使われます。
- 静止画から顔を認識し、目、鼻、くちといった要素から座標を検出する(
OpenCV,Dlib) - 顔の特徴を学習させる (
cuDNN2,HOG,Tensorflow)
OpenCV は顔の範囲を検知するのに対し、Dlib は目、鼻、くちといったエリアまで検知できます。
- 参考資料: OpenCVとは?5分で分かるOpenCVでできることまとめ @ AI 研究所
- 参考資料: 「OpenCV 顔 座標」に関する Qiita 記事 @ Google
そして、これらを補佐する技術が以下の4つです。
- 動画を連続した静止画に変換する。または、その逆。(
ffmpeg) - 画像から指定した座標の画像を切り取る。(
Dlib) - 画像の色味変換/グレースケール化。(
Dlib) - 座標の歪み/差分の算出。(
Dlib)
画像から顔のみを切り取ったら、そこから歪み具合を割り出し、その歪みのデータも顔画像と一緒に渡して特徴を学習させます。
「歪み具合」といっても、上を向いたり、横を向いている時の顔の目や口の座標のことです。どれだけ標準からズレているかという意味で、ここでは「歪み」と呼んでいます。(厳密には編集後記で説明している HOG と呼ばれる手法を使っています)
顔の特徴を学習させる際、ディープラーニング(ここでは cuDNN)を使うことで、与えた情報の関係性を試行錯誤し、特徴となるパターンを学習します。
つまり「目・鼻・口の位置がここに来ている場合のピクセル情報は、こんな状態である」といった学習に加え、「目・鼻・口の位置がここに来た場合は、同じ答えになるか」を繰り返したりと、メッチャいろんな組みわせを試すことで、「答え」となるパターンを見つけられるようになります。
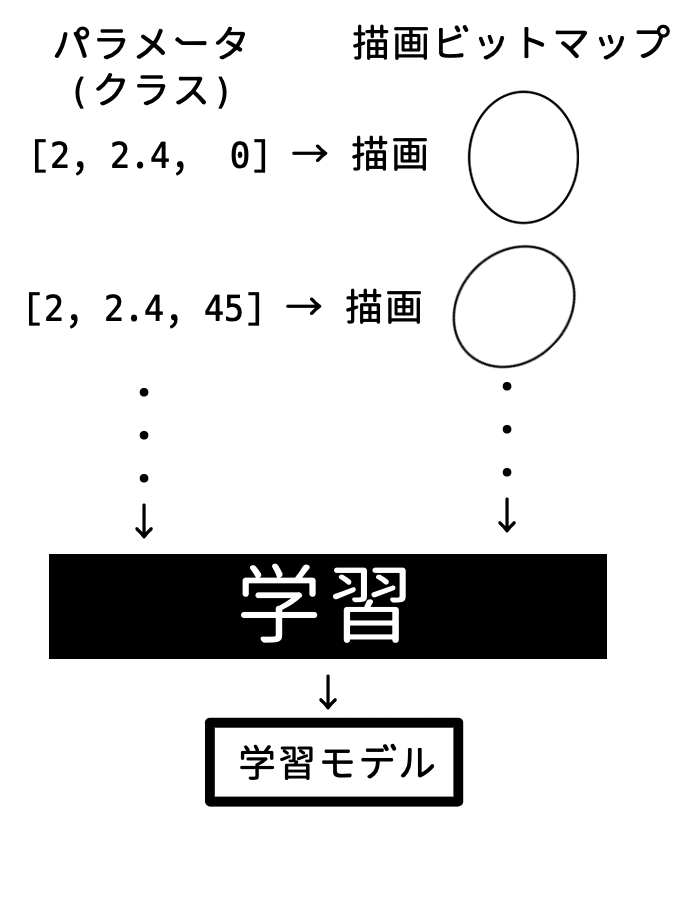
学習モデル
学習したパターンのファイルを「モデル」や「学習モデル」などと言います。
モデルといっても、基本的には数値の配列データのことです。A という情報を受け取った時に B もしくは C になる確率(割り合い)を出すために必要な数値が入っています。(詳しくは編集後記参照)
ディープフェイクの場合は、3つのモデル(学習ファイル)を使います。
-
encoder:入力された顔画像から共通の構成要素を学習し「汎用のデータ」を返します。(HOGデータ) -
decoder_A:汎用データから「人物 A」の特徴になるように学習します。 -
decoder_B:汎用データから「人物 B」の特徴になるように学習します。
ここでのポイントは、学習時に共通のファイル(学習モデル)である encoder を通していることです。
- 学習モード
-
「顔」画像 A→encoder→decoder_A→「顔」画像 Aと同じになるまで学習 -
「顔」画像 B→encoder→decoder_B→「顔」画像 Bと同じになるまで学習
-
🐒
encoderからdecoderに渡されるデータは HOG と呼ばれる画像の濃淡の方向をベクトルにしたデータです。詳しくは編集後記参照。
これにより、A にも B にも共通する「顔」の情報が encoder に蓄積され、decoder_A は A の特徴、decoder_B は B の特徴が蓄積されていきます。逆に言えば、A と B 以外の顔は学習されないということでもあります。
そして、最終的に「人物 A」の顔を「人物 B」の顔に入れ替えるには decoder を入れ替えるだけです。
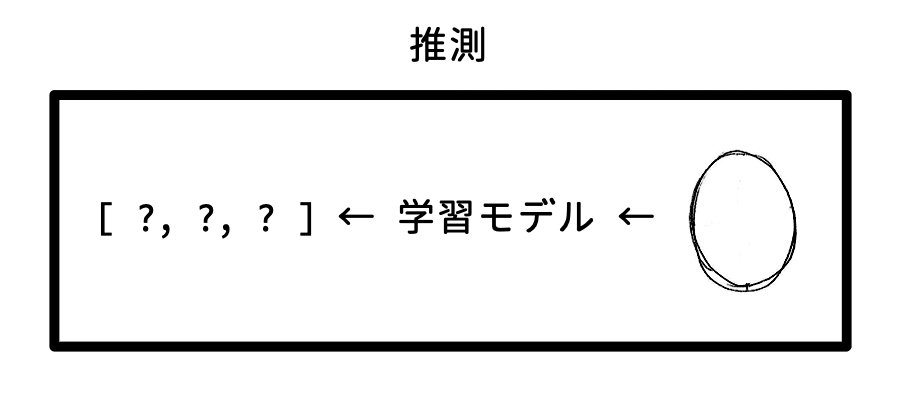
- 推測モード
-
画像 A→encoder→decoder_B→顔画像 B の画像 A
-
後は、生成された静止画を動画に変換するだけです。プロになると、ここで 1 コマ毎に仕上げ作業を行います。
【学習ポイント】
encoderで汎用的なデータに変換し、汎用データから各々の特徴になるようにdecoderに学習させる。
学習させた素材にもよりますが、本記事で作成された動画は基本的に瞬きや視点に違和感があるといった特徴があり、妙にギョロッとした目力のある結果になります。
🐒 また「明らかに目を閉じている」くらいは検知できるのですが、パチクリはしません。おそらく、フラッシュで目を閉じたような画像がたくさんあった場合は瞬きすると思います。その場合は、瞬きをするたびにクチを開くのではないでしょうか。
データの裏側
この記事の読者対象は Qiita なので、チュートリアルの後(文末の編集後記)に機械学習のデータについて少し補足説明しています。この知識自体は顔の入れ替え作業の役には立ちませんが、どんなデータ形式だと機械学習に使えるのかの学習の目安にしてください。
主な作業の流れ
- 環境構築(
Environment) - 素材集め(
GatherFreezing) - 顔の抽出(
Extract) - 顔の学習(
Train) - 顔の入替(
Convert) - 動画変換(
Animate)
- 「素材集め」(
GatherFreezing)-
Gather: 人物 A の「動画」と人物 B の「画像」を用意します。 -
Freezing: 人物 A の動画は連続した静止画に変換しておきます。(ffmpegが使われます)
-
- 「顔の抽出」(
Extract)- 人物 A & B の各々の画像から顔だけを抜き出します。
-
faceswap.pyのextractコマンドを使用します。(OpenCV+Dlib)
- 「顔の学習」(
Train)- 人物 A & B の各々の顔の特徴を機械学習させます。
-
faceswap.pyのtrainコマンドを使用します。(cuDNN)
- 「顔の入替」(
Convert)- 人物 A の静止画に、人物 B の顔をハメ込みます。
-
faceswap.pyのconvertコマンドを使用します。(Dlib)
- 「動画変換」(
Animate)- 顔が入れ替わった連続静止画を動画に変換します。(
ffmpeg)
- 顔が入れ替わった連続静止画を動画に変換します。(
Deepfakes のチュートリアル
🐒 本記事は、2018/02 にクリーン・インストールした macOS HighSierra(OSX 10.13.2) + MacBookPro Early 2015 + Python 2.7.10 で動作確認しています。
macOS High Sierra の OS 同梱コマンドやプログラム言語のデフォルト・バージョン情報情報 @ Qiita
既存の環境で試す場合は、すでにインストール済みの各種モジュールや依存ファイルのバージョン違いで動かないことがありますのでご注意ください。また、macOS の新規ユーザーを作成してアカウントを切り替えて試してどうかもおすすめいたします。
エラーや不具合(バグ)で動かない場合
機械学習には、いくつかの難関があります。おそらく、その最初の 1 つが環境の構築でしょう。つまり「とある機械学習のプログラムが動く環境を作ること」自体が、そもそも難しいのです。
また、機械学習自体には詳しくなかったとしても、ある一定の基礎知識や経験を前提とした世界でもあります。特に「切り分けの技術」を必要とします。つまり「何をしているか」の本質を理解できていないと問題解決にたどり着けないのです。
- まずは各コマンドのヘルプ(
-hオプション)を確認し、変更可能なパラメーター(調整項目)がないか確認してください。 -
verboseモード(-L VERBOSEなど)で詳細出力して、問題が発生している箇所を見つけ判断してください。(何かの処理に失敗して永遠とループしている、メモリ不足が発生している、正常に動いているが遅いだけなど) - パラメーターの変更でテストします。(画像サイズを小さくするなど)
- 問題が特定できたら、FAQ およびフォーラムを確認してください。たいていのことは載っています。
- deepfakes/faceswap FAQ @ FaceSwap.dev
- deepfakes/faceswap Issues | Forum @ FaceSwap.dev
🐒 なお、申し訳ありませんが、この記事に動作に関する質問コメントをいただいてもサポートしないことにしました。コメントに返信しても「その後の結果を教えてもらえない」ため、正しいアドバイスであったかもわからず、私自身の勉強にも、記事にも反映できないからです。何より良い気分ではありません。ごめんなさい。もちろん、ご意見、ご指摘やアイデア大歓迎です。また、誤字・脱字や記述のミスなども遠慮なく編集リクエストください。
下準備
人物 A, B だと把握しづらいので、「動画の友達の顔」を「自分の顔」と入れ替えることを例に「人物 A」=He、「人物 B」=Meとします。
-
CPU で処理するのか GPU で処理するか決める
- まずは「CPU」から始めることをお勧めします。詳しくは、下記「機械学習と GPU と CPU」参照。
- この選択は
config/.faceswapファイルに{"backend": "cpu"}と JSON 形式で書き込まれます。CPU<-->GPUの切り替えをしたい場合は、このファイルを削除するか、値を書き換えます。
-
FaceSwap アプリをダウンロード&解凍する
- https://github.com/deepfakes/faceswap/archive/master.zip
- 解凍フォルダを "faceswap" に変更する
-
"faceswap/" 内に以下の 6 つのフォルダを作成して、わかりやすい名前にする。
- 人物 He の「素材」(例: "He/" など)
- 人物 He の「顔」(例: "His_face/" など)
- 人物 Me の「素材」(例: "Me/" など)
- 人物 Me の「顔」(例: "My_face/" など)
- 学習モデルの置き場(例: "model/")
- 出力先(例: "output/")
-
「人物 Me の素材」にありったけの「画像」素材を置く
-
「人物 He の素材」に「動画」を置く(この動画の顔が人物 Me に置き換わります)
- もし動画以外に「人物 He」の顔を含む素材が別途あれば精度を上げることができます。
【機械学習と GPU と CPU】
🐒 ここは「なぜ GPU と騒ぐのか」という理由です。飛ばしてもらって構いません。「GPU はベクトル演算が得意だから」と言われてもピンとこない人のための基礎知識です。
機械学習において CPU より GPU を使った方が圧倒的に処理が速いです。数週間と数時間の差が出ます。機械学習や、仮想通貨のマイニングなどで GPU が脚光を浴びているため、CPU より GPU の方が優れていると思われがちですが、優劣ではなく根本的な役割の違いです。
CPU、GPU どちらも計算(以下演算)はできるものの、GPU は CPU のように他の処理の管理や監視をする必要がありません。GPU は画像処理に特化しているためです。逆に、CPU は GPU に画像処理を依頼したら、接続を切って自分の役割(他の処理)に戻ることができます。そして GPU は依頼された処理を終えたらディスプレイに結果を描画します。つまり CPU から見れば、画像処理を GPU に丸投げできるため(描画に関しては)並行処理しやすいということです。
恐らく、ここまでは、ご存知の方も多いと思います。問題は「なぜ画像処理が機械学習に使えるのか」という疑問ではないでしょうか。GPU にディープラーニングが組み込まれているのか?、みたいな。
まず、結局のところ画像は「数値の配列」データであることを思い出してください。静止画であろうが動画であろうが、何かを描画するにしても、座標という「数値の配列」を元に演算して、キャンパスという「数値の配列」に演算結果のデータを置くことで描画します。つまり、画像処理とは内部的には「数値の配列の操作」という演算処理に他なりません。
次に、例えば ①「A(画像データ)→B(Aの結果)→C(Bの結果)」という関数の処理がある場合を考えます。よく使う流れなら、これらを 1 つで処理できる ②「D(画像データ)」という関数を用意した方が楽です。つまり「D(画像データ)= C(B(A(画像データ))) という関数です。
GPU は、このような数値の配列を処理する「便利な関数」をチップに回路レベルで持ったものです。つまり D() 関数が使えれば、そっちの方が速いのです。「行列などの計算をチップレベルで持っている」と言えばわかりやすいでしょうか。CG やグラフィックスのソフトで「○○○ の GPU に対応」といった選択ができるのも、上記 ① を使わず ② を使えるからです。
詳しくは編集後記で述べますが、少し説明すると、機械学習は「数値の配列の、操作と鬼ループ」です。つまり、内部的には数値の配列をゴニョゴニョといじってはループして調整することしかしていません。実は、この「数値の配列」のことをコンピューターや機械学習の世界では「ベクトル」と言います。そして、ベクトルとベクトルをゴニョゴニョすることを「ベクトル演算」と言います。多次元配列と多次元配列を、掛け算したり足し算したりする行と列の計算も、行列式を使って高速化するのもベクトル演算のうちです。そのため、ベクトル演算(「数値の配列」の処理)に長け、並行処理しやすい GPU は、機械学習の演算に使ってみたくなるのです。あわよくば GPU の便利な内部関数が使えれば、さらにベストです。
しかし、GPU を触るためのグラフィックス・ドライバーは処理結果をディスプレイに描画するものです。ただただ「演算処理を投げて結果が欲しいだけ」なのに。
そこで各社 GPU メーカーは、GPU の処理結果をディスプレイでなく、リクエスト者に返すドライバーを提供するようになりました。つまり描画用ドライバーでなく、演算用ドライバーの提供です。NVIDIA 社の場合は CUDA ドライバなどがそれに該当します。そして、それらのドライバーを使うライブラリが、NVIDIA 社の GPU 場合は cuDNN だったり、Intel 社や AMD 社の GPU の場合 PlaidML だったりします。
問題は Mac です。
Mac の場合は機種によって GPU の種類がかなり異なります。そのため適合し安定動作する GPU の演算用ドライバを見つけるのはかなり苦労します。特に、主なライブラリや機械学習のフレームワークが対応する GPU は NVIDIA 製(CUDA を使うこと)を前提としているため、Intel Iris Graphics などの GPU はでは CUDA の関数は使えません。特に、古い iMac などに NVIDIA の GeForce が入っていても、大人の事情なのか、NVIDA の公式からは Mac 用ドライバはストレートには探せず、ググらないと出てきません。そのため、そこで時間を食うよりは、遅いものの、まずは「CPU」で試してから先に進むことをおすすめします。色々慣れてきてから、Intel や AMD の GPU 用のライブラリ「PlaidML」などに手を出すといいでしょう。よくわからないでドライバ類に手を出すと OS を再インストールしないと不安定になるような事態になりかねません。
- macOS High Sierra(OSX 10.13) の GEFORCE ドライバ と CUDA ドライバ
- DeepFake使ってみた!? MacでGPUを使った機械学習 @ さくらのナレッジ
学習に必要なソフトウェア類や既存モデルのインストール
-
NVIDIA のサイトから Mac 用 CUDA ドライバをダウンロード
- http://www.nvidia.co.jp/object/mac-driver-archive-jp.html
- 十分な GPU パワーがないといったメッセージが出ても、気にせずインストールしてしまいましょう。
- ドライバ自体は NVIDIA の GPU をグラフィックス以外にも使えるようにするためのものですが、CPU を使う場合であっても後述する NVIDIA の cuDNN ライブラリが必要とするためインストールします。
-
学習済みモデル
- 学習済みのデータ(モデル)ファイルがあると学習時間が短縮されます。以前までは Windows の類似アプリである FakeApp3 に同梱されている学習済みモデルを利用していました。しかし、アプリの作者が不審であるため、やめました。この記事では新規で作成することにします。
-
faceswap.pyを実行すると、以下の3つのモデルがmodel/ディレクトリに作成されます。encoder.h5decoder_A.h5decoder_B.h5
- 上記
.h5ファイルは HDF5 と呼ばれる汎用フォーマットで保存された学習データ(モデル)4です。 以後は、この学習済みモデルを叩き上げていくことになり、他のパワフルな環境で学習を継続させる場合は、このファイルを使いまわします。
-
Anaconda が入っていない場合はダウンロードしてインストールします。(どちらのバージョンでも構いませんが、本記事では v2.7 で検証しています)
- Anaconda 2.7
- Anaconda 3.6
-
Anaconda は機械学習に必要なバイナリやライブラリのダウンロードに使います。パッケージマネージャーのコマンドは
condaです。condaはpipと違い、Python に限らずバイナリなどのパッケージも管理できるのが特徴です。欲しいライブラリが Python のパッケージの場合はpipにも同じものがある場合が多いのですが、依存ファイルのことを考えると、まずはcondaでインストールした方が良いと思います。
-
NVIDIA cuDNN をダウンロード&解凍します。
-
解凍したファイルを以下のルートのフォルダにそれぞれコピーします。
/Developer/NVIDIA/CUDA-8.0/lib/Developer/NVIDIA/CUDA-8.0/include- 上記フォルダがない場合は作成します。上記 NVIDIA cuDNN インストールで入った CUDA ドライバによってはバージョン番号が違うかもしれません。
-
カレント・ディレクトリを "faceswap" に変更する
- ターミナルを開き "faceswap" フォルダに移動してください。
$ cd /path/to/your/faceswap/
-
Python の仮想環境モジュールのインストール
$ pip install virtualenv-
virtualenvモジュールをインストールすると Python 上で Python の仮想環境が作れるようになります。 - インストールに失敗する場合は、下記依存ファイルを先にインストールしてみてから再度試してください。
-
仮想環境作りに必要な依存ファイルをインストールする
- CPU を使う場合
$ pip install -r requirements.txt
- GPU を使う場合
$ pip install -r requirements-gpu.txt
- CPU を使う場合
-
FFmpeg が入っていない場合はインストールします
-
$ ffmpegでバージョンが表示されるなら OK。 - 「ffmpeg」は、動画←→画像の変換に利用します。
-
学習素材の下ごしらえ① (動画から静止画を作成する)
-
「人物 He の素材」ディレクトリに移動します
$ cd /path/to/your/faceswap/[人物 He の素材]/- 動画があることを確認し、ファイル名を英数字スペースなしに変更します。(以下は
scene.mp4に変更する場合。Finderで変更も可)mv ./[動画名].mp4 ./scene.mp4- 単純に
mvでリネームできない場合は、特殊環境変数 $_ を使ってリネームします。
$ # 検索で対象ファイルだけがヒットするように絞る $ ls 2019*山田くん*登山*動画.mp4 2019年3月18日 ☀️ 山田くん 박さん と登山 🏔した時の動画.mp4 $ # 特殊環境変数 $_ に検索結果が代入されていることを確認 $ echo $_ 2019年3月18日 ☀️ 山田くん 박さん と登山 🏔した時の動画.mp4 $ # 検索結果を特殊環境変数 $_ に渡して mv する $ ls 2019*山田くん*登山*動画.mp4 && mv "$_" ./scene.mp4 -
$ ffmpeg -i scene.mp4 -vf fps=30 scene%06d.png
学習環境の動作チェック
-
親ディレクトリ(
/path/to/your/faceswap/)に戻る$ cd ../
-
仮想環境を立ち上げる
virtualenv faceswap_env/
-
仮想環境が立ち上がったら以下のヘルプを実行して環境チェックを行う
-
python faceswap.py -h(./faceswap.pyでも可) -
初回起動時に CPU/GPU を使うか聞いてくるので選択します。CPU の場合、AMD/CPU のいずれかを選択しますが、自身のマシンのアーキテクチャに合わせます。アーキテクチャの確認は
uname -pでi386が表示された場合は Intel チップなのでCPUを選択します。AMDと返された場合はAMDを選択します。# python ./faceswap.py -h First time configuration. Please select the required backend 1: AMD, 2: CPU, 3: NVIDIA: -
ヘルプが表示され、"Faceswap backend to" 的なメッセージが出ていればOK。
# ./faceswap.py -h Setting Faceswap backend to CPU usage: faceswap.py [-h] {extract,train,convert,gui} ... positional arguments: {extract,train,convert,gui} extract Extract the faces from pictures train This command trains the model for the two faces A and B convert Convert a source image to a new one with the face swapped gui Launch the Faceswap Graphical User Interface optional arguments: -h, --help show this help message and exit -
上記のメッセージが出ない場合は、以下の導入に問題がある可能性があります。
-
"cv2 import..."のようなメッセージの場合
$ pip install opencv-python
-
"dlib..."のようなメッセージの場合
-
$ conda install dlibもしくは $ pip install dlib
-
-
上記でダメな場合は
-
$ conda install cmakeもしくは $ pip install cmake
-
-
さらに上記でもダメな場合は、以下をダウンロード&解凍したディレクトリに移動後、インストールを試してみてください
- http://dlib.net/files/dlib-19.9.tar.bz2
$ cd /path/to/your/donwloaded/extracted/dlib$ python setup.py install
-
学習素材の下ごしらえ② (画像から顔のみを抽出する)
-
人物 He の「素材」(動画を静止画に展開した画像置き場)から、顔を「顔」ディレクトリに抽出
cd /path/to/your/faceswappython faceswap.py extract -i <「人物 He の素材」のパス> -o <「人物 He の顔」のパス>- また、動画からの静止画以外に「人物 He」の素材があれば、同じ要領で
<「人物 He の顔」のパス>に抽出しておくと精度が上がります。この場合、 He の「素材」(動画の連続静止画ディレクトリ)に混ぜないように注意します。 - ここで抽出した画像をチェックし、NG(誤検知)画像を削除しておくと精度があがります。
-
うまく動かない場合は
python faceswap.py extract -hで設定可能なパラメータを確認&変更して、自分の環境にあった設定を試行錯誤してください。
設定例(-iには動画も指定できます)/app/faceswap.py extract \ --detector cv2-dnn \ --aligner cv2-dnn \ --min-size 50 \ --extract-every-n 2 \ --skip-existing \ --skip-existing-faces \ --save-interval 50 \ -i $path_file_movieA \ -o $path_dir_facesA -
人物 Me の画像から顔を抽出
cd /path/to/your/faceswappython faceswap.py extract -i <「人物 Me の素材」のパス> -o <「人物 Me の顔」のパス>- ここで抽出した画像をチェックし、NG(誤検知)画像を削除しておくと精度があがります。
機械学習の実行
-
それぞれの顔の特徴を学習させる
$ python faceswap.py train -A <「人物 He の顔」のパス> -B <「人物 Me の顔」のパス> -m <「モデル置き場」> -p- 学習は
Enterを押すまで続きます。学習中はLoss A: 0.0..., Loss B: 0.0...と表示され、値が低い(ロスが少ない)と精度が増します。 - 学習レベルですが、一般的な目安として
Loss A:Loss B:ともに0.02前後から実用に耐えると言われています。 -
うまく動かない場合は
python faceswap.py train -hで設定可能なパラメータを確認&変更して、自分の環境にあった設定を試行錯誤してください。
設定例(変数は自身のパスに変更してください)/app/faceswap.py train \ --loglevel VERBOSE \ --batch-size 32 \ --trainer lightweight \ --input-A $path_dir_facesA \ --input-B $path_dir_facesB \ --model-dir $path_dir_model \ --logfile $path_file_log_train -
途中自動的に保存されますが、谷に落ち込む(学習が頭打ちになり、より正しい答えを探すのに時間がかかっている状態になる)と次回保存までのタイミングが空きます。
sをタイプするとその1つ前までのステップ(エポック)の学習データを保存できます。 -
Lossが 0 になるまで永遠と学習を続けるので、切りのいいところでEnterを押すと処理を中断します。
顔の入れ替えと静止画からの動画作成
-
画像の顔の入れ替えを実行する(指定ディレクトリが顔でなく「人物 He の素材」になっているので注意)
python faceswap.py convert -i <「人物 He の素材」のパス> -o <「出力先」のパス> -m <「モデル置き場」>-
うまく動かない場合は
python faceswap.py convert -hで設定可能なパラメータを確認&変更して、自分の環境にあった設定を試行錯誤してください。特にverboseなどの詳細出力は「何が起きているか」の大雑把な把握と「問題発生箇所」の特定に役立ちます。
-
置き換えた画像を動画に変換する
ffmpeg -i scene%06d.png -c:v libx264 -vf "fps=30,format=yuv420p" output.mp4
以上。再生してみて、いい感じだったら成功です。お楽しみください。
編集後記
ここまでだと、データを渡すだけで凄い状態で返ってくるブラックボックスな仕組みに見えます。しかし、ここは Qiita なので、機械学習そのものに興味がある方も多いと思います。
とは言え奥が深すぎる。そして難しい。私自身もわかっていません。
そこで、私が「機械学習を学習する」際に、最初の理解の突破口となった4つの単語があります。
- 「ベクトル」
- 「クラス」
- 「特徴量」
- 「分類器」
「機械学習用のデータの作り方」の概念をベースに、この「4つの単語の簡単な説明を丁寧にしたい」と思います。
逆に言えば、「知ってるよん」という方には無意味でもあるので、作成した動画の方をお楽しみください。
数学が苦手な猿人に近いエンジニアによる、エンジニアのための機械学習の基礎の基礎
この編集後記では、なるべく機械学習や数学用語を使わずプログラム寄りに表現していきたいと考えています。
bash などのシェル・スクリプトを書いたことがある、俺様関数を自分で書いたことがある、変数に配列を突っ込んだことがある、サーバーとクライアントの違いがわかる程度の知識があればプログラム言語を問わず、わかるように気をつけたいと思います。
そのため、「わかっている」人にはいささかくどい部分もあるかと思いますが、その場合は、復習のつもりでお読みください。気負わず、マッタリとゴロ寝でもしながらお読みください。
なお、機械学習の基本的な概念の説明なので、具体的なプログラム方法などはありません。それらは、この記事を読んで興味を持たれたら、他の記事や本で学んでください。文末にいくつか取っかかりとなる情報をリストアップしています。
機械学習の舞台裏
さて、機械学習の論文はともかく、機械学習系の記事を読んでも「何か、小難しく感じる」のには「数学が不得意以外にも理由があるから」だと筆者は感じています。
それは「わかっている人」からすると「言い得て妙」な表現ではあるものの、「わかっていない人」からすると、むしろわかりづらい表現が多いからです。
これは、インターネットの世界で例えると「クラウド」みたいなことです。インターネット上の複数サービス(Web サービス)を組み合せて提供するサービスは、引きで見ないと全体像がわからないため「雲」に見立てて「クラウド」と表現しているのと似ています。
Web サービスやサーバーなどを理解している人には「言い得て妙」な表現ではあるものの、そうでない人にはむしろ掴みどころがないものになっています。雲だけに。
また、異業種で単語がかぶる、つまり同音異義語が多いのも相手が「???」となる原因です。
例えば、「当社の SE が」と「システム・エンジニア」の SE のつもりで当然のように話しても、建築業界では「サービス・エンジニア」を SE と呼ぶし、放送業界では「サウンド・エンジニア」を SE と呼んだりするので、食い違ったりします。
「機械学習」の世界も似たようなことが発生します。例えば機械学習の「クラス」(後述)とプログラミングの「クラス」などです。
さて、機械学習の用語や仕組みの前に、少し長いのですが、まずは「機械学習」の誤解を説明したいと思います。自分の関係する業界と比較しながら、リラックスしてお読みください。
機械学習の概念が残念
癌/歯槽膿漏/風邪/うつ病/発達障害などは、実は1つの病気でなく、たくさんの種類がありすぎるため「素人向けにわかりやすくするための『総称』」と言われます。
しかし、それがゆえに「1つの対処法で賄える」と誤解されやすい病気でもあります。本当は各々に名前が付いており、対処法も異なります。また種類が多すぎるため、対処法にも、さまざまな考え方があります。
「人工知能」「機械学習」や「ディープラーニング」も関係性が似ている印象を受けました。
情報を開いてみると、たくさんの種類や考え方があるのです。IT 全般で言えば「パソコン」「サーバー」「インターネット」や「クラウド」みたいなものでしょうか。どれも「○○○ が 1 つ欲しい」と言われても、単体の商品名ではないので困るものです。
「AI」(人工知能)を「機械学習」や「ディープラーニング」の総称としているのは、「インターネット」を「Web サーバー」や「クラウド」の総称としているようなイメージを受けます。
下記はメディアでよく使われている図です。左図が「ディープラーニング」の説明、右図が「クラウド」の説明でみかける図です。特に右図はクラウドの代理店の資料で見かけます。
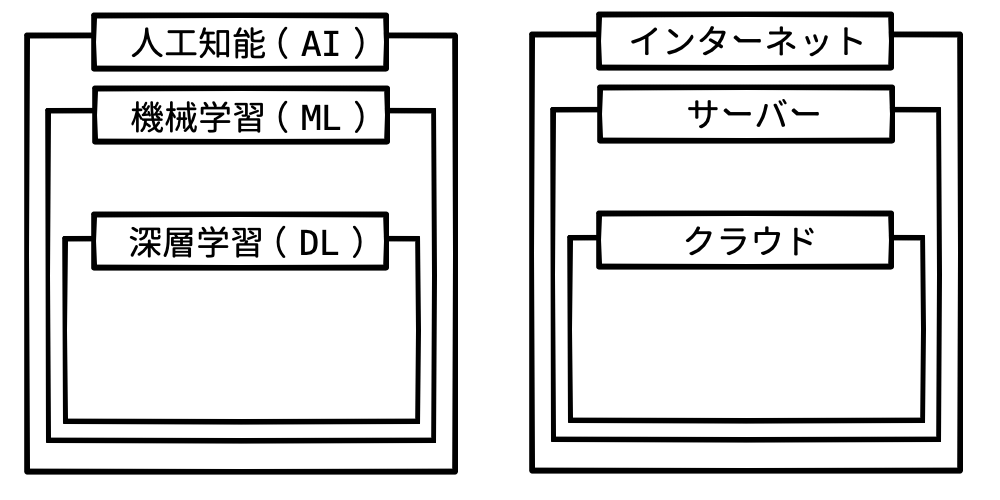
個人的に、上記は「間違っていない。が、正確でもない」という気がします。
上記、右の図を見てください。確かに「インターネット」を構成するのは「サーバー」です。パソコン(サーバー)のネットワークが LAN になり、LAN のネットワークが WAN になり、WAN のネットワークがインターネットと考えれば、上記の図は間違ってはいません。
また「サーバー」のサービス形態の1種として「クラウド」もあります。サーバーが提供するネットワークのサービスで、特定のハードウェア(サーバー)でなく複数台のハードウェアで提供している「合わせ技」的なサービスで、それを「クラウド」と考えると間違ってもいません。
しかし、この図だと「え?うちのサーバー、インターネット?」という疑問も出てくると思います。
これを正しく説明しようとすると煩雑な図になってしまいますし、「(いや、LAN と WAN くらい知ってることを前提としてよ)」と思うことでしょう。
機械学習でも、上記左図のような概念図を愚直に刷り込んでしまうと、初期段階の理解で「... これを人工知能(AI)って呼んで ... いいの、か?」という疑問が出てきます。これはメディアや CM で「AI を活用した云々!」と言われても何か濁されている違和感と似ています。
この違和感は、コロナを「風邪」と括って考えてしまうのと同じことです。
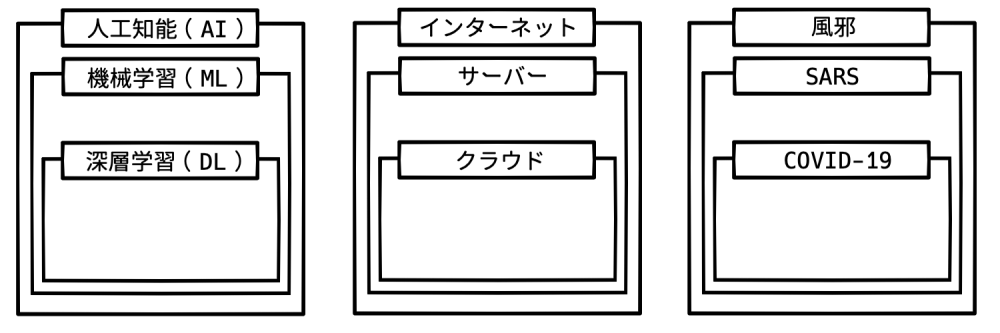
「『風邪』という病気はない」とか「風邪の特効薬はない」と聞いたことはあると思います。
これは「風邪」が総称であるためなのです。つまり、「新型コロナに効いた」から全てのコロナに効くわけではありませんし、1つの風邪に効いたから全ての風邪に効くわけでもないのです。
また「うつ病」を「風邪のようなものだ」という表現は、「放っておけば治る」という意味ではなく「広範囲過ぎるので診察して、もっと限定しないとわからない」ということと同じで、限定できないものには栄養剤的なものはあれど、銀の弾丸はないのです。
そして「インターネット1つください」がないように、「AI を1つください」もないのです。
このような、内部を理解していると「間違ってはいない」とわかるも「あー、なんか正確じゃないけど、素人にはこうとしか表しようがないよなぁ」といった図が機械学習でも結構出てきます。
逆に、根本的前提や基本を理解していないとわからない図も多く出てきます。
サーバー系ネットワークの業界で例えるとネットワーク・プロトコルのレイヤー相関図のような図です。
「イーサネットって1次元的なシリアル・データであるはずなのに、レイヤー構造ってどういうことよ?」みたいな。
わかっていれば「ミルクレープ的に見るか、バームクーヘン的に見るかの違いみたいなもの」と言われても「あー。なるほど」と思えます。(思えるか?)
そして、その微妙な差異を丁寧に説明しない、聞く耳を持たない、興味がないので調べないことが「それ1つで賄える」という誤解につながっている印象を筆者は受けました。
まずは、上記の図のような「あいまいな」関係が機械学習の図の裏にもあることを念頭に置いてください。
恐れずに言えば、「深層学習=人工知能」と言うのは「COVID19=風邪」と言うのと同じくらいのカテゴリわけでしかない、ということです。
そして同様に、深層学習を風邪のように邪険に扱うものでもないのです。個別名が付くくらいに流行るには、それなりの違いがあるからです。
プログラムと数学の境界線
先の「クラウド」のように、通にしか通用しない例えが IT で多いのは、そもそもプログラマーは「言語遊び」が好きだからです。
そして、数学の世界では「数式」が共通言語です。特に、複雑な事項を記号でシンプルに表現することが多い世界です。
つまり「代入遊び」が好きなため、𝔸 と言われても(本質的に)何を意味しているか理解していない人には、むしろ理解に苦しむことがあります。プログラムの世界で言えば「(この変数 $usrtoken って何のこと?ソースを全部見ないとわからないじゃん。チッ)」みたいなことです。
最悪なことに機械学習は両方の感覚を持たないといけないという世界なのです。
機械学習の「クラウド」的なものに「ニューラルネットワーク」の説明図があると思います。
たくさんの「○」が、直線でつながった図を見かけたことがあると思いますが、アレです。
- ニューラル・ネットワークの概念図 ← アレ
アレらの図をよく見るも「(リンクしているとか、脳細胞を模擬しているとか、意味はわかるんだけど、なんかピンとこない)」と感じる人は多いのではないでしょうか。むしろ「(いっそのこと、パカっと開けたらゲロリとした脳細胞がドクドクしてた方がまだ納得できる)」くらいのイメージかもしれません。
個人的に、アレらの図は「関数や配列もわからない人向け」の図だと思います。なぜなら、むしろプログラムをかじったことのある人にはわかりづらい説明だからです。
じつは、あの図の「○」って関数やメソッド(クラス関数)のことなんです。そして、関数の出力結果を「配列」で別の関数に渡しているのが「接続線」のことなんです。
関数が「○」、関数の入力や出力を配列で渡しているのが「線」、、、と考えながら改めて図を見てください。
「(あ〜〜、なるほど)」と思うと思います。
このようなフロー図が伝わらないのはプログラムの世界でも同じです。
そしてさらに、「○」をニューロン(脳細胞)に見立てているのは、その関数が細胞レベルの「単純な処理しかできないから」です。IT でいうトランジスタみたいなものです。つまりコンピュータがオンとオフ(バイナリ)で動いているような、「仕組みは単純だが簡単ではない」系のたぐいなのです。
信じるものではなく利用するもの
「機械学習の先駆者やパイセンたちの苦悩を理解する」ことも、実は機械学習の理解につながります。
苦悩を知ると、物は違えど、我々一般エンジニア(SIer、SE、プログラマー)にもある苦悩と似た苦悩に悩んでいると気付けると思います。
逆にこれに気づけないと、「なんでこれくらい消せないの?削除するだけじゃん」と、DB からフィールドを消せなかったり、家の図面から柱を消せないことに文句を言うような目線でしかドキュメントを読めなくなるからです。
そのためには、「機械学習あるある」の前に「IT 業界あるある」をいくつかおさらいして見たいと思います。
エンジニアあるある 〜CRM 導入編〜
データに関するエンジニアあるあるだと思いますが、「顧客管理がなっていないから」と上流のツールの一声で決定した CRM アプリ(顧客や名刺などの管理アプリ)が導入されたからといって、顧客管理ができるわけではありません。
「名刺データを入力する」「入力データをチェックする」「効果的な利用の仕方を学習する」という工程で、本当のコストがスッポ抜けているからです。
顧客管理ツールは、ただ入力すれば良いというものではありません。しかるべきデータの選別や敬称などの加工も必要になります。もちろんアップデート(更新)も必要です。
そして、データのエラー確認も大事です。
typo ならまだしも、営業や社会経験のある人だとわかる役職ミスも、わからないこともあるでしょう。例えば、名刺に「常務取締役」と「部長」の2つがあった場合、名刺管理アプリの住所録に役職欄が1つしかない時はどちらを入れればいいか、などです。
また、OCR を使って効率化を図るも、正しく認識されたかの判断が「社会人だとピンとくる」エラーであっても学生アルバイトではピンとこないケースもあります。
大抵の場合、このようなイレギュラー対応のコストは度外視される傾向があります。エンジニアは「営業の仕事だ」、営業の方は「総務の仕事だ」、総務の方は「バイトの仕事だ」といった認識の現場に多いと思います。
しかも OCR ソフトの「認識率 98%」という言葉が「50 文字に 1 文字は間違えるよ」(2 % は誤認識する)という意味を理解しておらず、1つの文(約 60〜80 文字)ごとにちょいちょい間違えるため、挙げ句の果てに「使えない」と言い放われたり。
「楽になると信じていたのに、期待してたのと違う」と、ツールの意味を理解してもらえず。
つまり、実は「地道な作業」や「選定眼」を持った人によって成り立つものなのに、突っ込みゃ動く「魔法のアプリ」と勘違いしているパターンです。
エンジニアあるある 〜DB 導入編〜
また、これもエンジニアあるあるだと思いますが、「いまだに手書きの現場」に効率化を図るためにツールの一声で Excel、Google SpreadSheet、SAP などが現場に導入されたからといって、効率化できるわけではありません。
「手書きの現行システムの棚卸し」や「過去の手書きデータの入力」といった工程やコストがスッポ抜けているからです。
ただ導入すれば良いというものではなく、しかるべき機能の選定、利用者のパソコンやソフトなどの基礎教育なども必要になります。さらには、それらを利用・維持・継承していくための雰囲気作りや体制の整備なども必要です。
基礎がない現場に急に導入しても「耳慣れない単語ばかりで使ってもらえない」だけでなく、挙げ句の果てに「上から目線云々」と言われます。「(いや、セルとかピボットとかくらいは勉強してよ...)」といった心境の時です。
「楽になると信じていたのに、期待してたのと違う」と、ツールの意味を理解してもらえず。
つまり、実は「地道な作業」や「業務知識」を持った人によって成り立つものなのに、突っ込みゃ動く「魔法のアプリ」と勘違いしているパターンです。
機械学習あるある
実は機械学習の世界も似ています。
使えるデータにするには、けっこう地味な作業が必要なのです。また諸所のステップを自動化するにもセンスや基礎知識が必要なのも似ていると感じました。
さらに、「正解率何%」と良い数値が出ても「使えない」と言われたり、挙げ句の果てに「用語が小難しくて上から目線に感じる」的なことを言われるところまで似ています。機械学習の方からは「(いや微分や行列の計算や意味くらいは勉強してよ...)」といった心境なのです。
「当たると信じていたのに、期待してたのと違う」とツールの意味を理解してもらえず、突っ込みゃ動く「魔法のアプリ」と勘違いしているパターンです。
どんなアプリやツールでもそうであるように、機械学習も信じるのではなく利用することが大事なのです。
そして、利用するためには「何に使えるか」の認識と「最低限の使い方や用語」を覚えないといけません。
このことの理解が大事なのに「わかってるよ。細けぇこたぁいいんだよ」的に話しを聞かず、「ほらね」といった結果になるシャチョさんのいかに多いことか。「知ってる知ってる」と「理解している」は違うのです。
ゆうて、筆者も完全に理解したと思える入り口に入ったばかりです。しかし「ちょっとできる」人の話しを聞いていると「(あー、プログラマと同じような苦労しているんだなぁ)」と感じたのです。
🐒 「信じる」といえば、実のところ機械学習、特に AI は占いと似たところがあるのです。「なぜそうなったのか」の説明が難しいため、仕組みを理解していない人は小難しいうんちくを聞かされては「信じる」しかないからです。そのため、ツールとして使う意識がないと「外れた時の裏切られた感」が増すのも占いと一緒ですし、見てもわからない蓄積されたデータを「統計だから」と言われ、盲信するようなところまで同じなのです。どちらも、結果が妙にリアルだと「何か神がかった力や意思のようなものがある」と感じやすいものなのです。
以下は、Google の言語モデル「LaMDA」と、Google のエンジニアが行った会話の記録です。仕組みを理解している機械学習のプロでも「意志を持った」と錯覚するほどの内容で話題になりました。確かに「2001年宇宙の旅」か「攻殻機動隊」かと思うほどのリアルさです。ぶっちゃけ、猿人に近い私なんかより、まともで人間らしい受け答えをしています。
言霊も言語が違えば理解できない
IT 業界には、以下の有名な格言があります。
"In Golang, do what the Gophers do."
「Go に入れば Go に従え。」
(出典:民明書房「剛乱愚 100 の掟」)
そう、機械学習を知るにも、機械学習の世界のプロトコルに合わせないといけないのです。
しかし、プロトコルを合わせる以前に、基礎知識がないとプロトコルすら読めないのです。
特にディープラーニングは脳科学の影響を受けていたり、機械学習は数学とりわけ統計学の知識が不可欠とされます。そのため、資料や文献を読んでも数学などの理数系プロトコル全開のため「本当に何を言っているのかわからない」ことだらけです。
たかが for ループの足し算でも、コードだと説明が長ったらしいので「Σ」とか唱えちゃったり、足し算の合計値を全体で割った平均を出すことすら「μ」と崇めるので、神や女神でも降臨するんじゃないかと、黒魔術の呪文かと、魔法の詠唱でも読んでいる気分になります。素人にはおすすめできない世界です。
そんななか、個人的にプログラマとして最初の突破口になったのが「ベクトル」という単語の理解です。
ベクトル怖い
機械学習やディープラーニングの本や文献を読むと、当然のように「ベクトル」という単語が出てきます。
しかし、高校時代に聞いて大学で忘れた「ベクトル」という響きだけが脳裏に残っており、ずっと「sin とか cos とか使うんだろうな」とか、下手に漫画やアニメもかじったので「フォトショがラスタで、イラレはあれでしょ、ほらベジェ曲線とかのベクター」という認識が邪魔をしていました。「ベクターなるものを作るために、ベクトルなる謎の技術が必要なんだ」的な認識です。
「ベクトル怖い」状態だったのです。
しかし「ベクター」も「ベクトル」も同じ vector です。ピザとピッツァのような違いらしいです。
恐れずに言うなら、機械学習における「ベクトル」とは、「数値だけで構成されたソート済みの配列データ」のことです。ここでいうソートとは、登録順だったり時間順など「何かしらの方向に向かって並べられたデータ」ということです。
プログラム的な一番のポイントは、ベクトルは「数値のみで構成されている」という点です。
$A = [ 123, 456, 789, ... ];
$B = [
[ 123 ],
[ 456 ],
[ 789 ],
...
];
そして、複数のベクトル・データを学習用のデータとして利用するのです。
$x = [
[ 123, 456, 789 ],
[ 987, 654, 321 ],
...
];
x = [
[ 123, 456, 789 ],
[ 987, 654, 321 ],
...
]
[
[ 123, 456, 789 ],
[ 987, 654, 321 ],
...
]
「ベクトル」とか「行列」と聞くと先入観でアレルギーが出る人も多いと思いますが、プログラマー・プロトコルでいう「配列」です。そう、例の array です。
そして、上記の 123 456 789 などの各要素の数値のことを機械学習プロトコルでは「スカラー」と呼びます。
この用語を耳にしたとき「まーた新しい、小難しい用語が出てきたよ」と感じました。「(別に数値でいいじゃん)」と。Wikipedia の「スカラー」を見ても小難しい。
ところが、先の「ベクトル」と「ベクター」の vector 同様に、英単語にすると「あ」と気づきました。
scalar、つまり「大きさ」や「規模」なのスケール(scale)と同根なのです。技術系の人が「定規」や「物差し」のことを「スケール」と呼ぶのを思い出しました。そう思いながら scalar の発音を聞くと「スカラー」ではなく「スケーラー」と聞き取れると思います。
このことから、数値のうち「何かの規模や大きさ(スケール)を示す値」や「測定値」のことを scalar と呼んでいるのです。そして測るものを scaler(定規)と呼びます。
12 は、ただの数値です。しかし「座標の 12」と言われた瞬間から「0 の位置から 12 移動した」という大きさを示す値になるため「スカラー」と呼ぶのです。
数値なのに「スカラー」といちいち名前をつけるのは、我々のプログラムの世界でいえば、同じ値なのに int32 float64 double など、値の性質に型々と名前をつけるようなものです。
プログラムの世界、特に処理速度が求められるプログラム言語の場合、変数の宣言時に型々言われます。なぜなら、その変数の中身(の型)をいちいち確認しなくてもいいことで、人間および機械の処理が楽になるからです。
数学の世界でも型々言うことがあります。例えば、「A」という変数の中身が「ベクトル」(配列型)の場合です。
その場合、数学では線を一本多く書いて「𝔸」という書き方をします。そうです。「𝔸𝔹ℂ𝔻」といった表記は、その変数がベクトルであると型を示しているのです。
さて、ベクトルの話しに戻ります。先にも出てきた、以下のサンプルをご覧ください。
[
[ 123, 456, 789 ],
[ 987, 654, 321 ],
...
]
上記は JSON 的に言えば、1 行が 3 つの要素を持っているのですが、1 行のデータが 3 列構成になっています。これを機械学習プロトコルでは「3次元のベクトル」という言い方をするのです。
怖いですね。
[
[ 1, 2 ],
[ 3, 4 ],
...
]
[
[ 11, 22, 33 ],
[ 44, 55, 66 ],
...
]
[
[ 11, 22, 33, 44 ],
[ 55, 66, 77, 88 ],
...
]
そう。列数を次元と言っているのです。
とは言え、次元といってもプログラムの配列における次元、つまり多次元配列とは違うので注意します。
// プログラマ的3次元配列
x = [
[
[a, b, c],
[d, e, f]
],
[
[h, i, j],
[k, l, m]
],
...
];
// 機械学習的3次元ベクトル
y = [
[ n, o, p ],
[ q, r, s ],
...
];
ちなみに、後述しますが機械学習プロトコルでは、多次元配列化されたベクトル・データを「テンソル」と呼びます。しかし、ここでは以下程度にザッと覚えておけば良いと思います。
機械学習の世界では、
- 配列の要素が、測定された数値の場合を「スカラー」と呼び、
- スカラーが配列になったものを「ベクトル」と呼び、
- 何かしらの関数を通して、何かしらの目的や機能のために多次元配列化されたベクトルを「テンソル」と呼ぶ。
細分化して考えるようにしよう
ここは Qiita なのでフェイス・スワップに限らず、「機械学習を何かしらに使ってみたい」と思う人も多いと思います。
しかし「何が出来るか、わかるようでわからない」理由は、「プログラムを勉強しよう」と大きく出ちゃうようなものだからです。プログラムで出来ることや種類が多すぎちゃってわからない、みたいな。
最近の機械学習では、異なる目的の「学習モデル」(機械学習させたデータをセットにしたもの)を組み合わせることも増えてきました。
つまり、なんでもかんでも1つの学習モデルで解決させるのではなく、「特定の目的に特化した学習モデル」を組み合わせる方法です。
IT 業界で言えば、「モンスター・メソッドを細分化する」ようなイメージです。わかっている人が作ったモンスター・メソッドを最初から理解するよりは、細分化されたメソッドから理解していく方が飲み込みやすいのと似ています。
細分化の考え方の例をあげましょう。
シンプルだがマンモスな考え方
まずは、一般的な CV(コンピューター・ビジョン)系のディープラーニングの手法です。マシン・パワーや時間といった、コストと言う「力」さえあれば何とかなるタイプです。
例えば、人の顔を描く時の一般的な描画技術に、楕円と十字の楕円弧を組み合わせて顔の大きさや向きを決めてから絵を描く方法があります。
↓
(顔の描き方 … 基本知識 @ illustcomic より)
まずは、これを機械学習させることを考えます。
「完成している特定人物のイラスト」と「楕円」(全体のサイズ)と「楕円弧」(顔の向きの十字の2本)の3つの画像情報で学習させます。
そして、今度は逆に楕円と楕円弧の情報を学習モデルに与えると、その人物の推測される顔(イラスト)を出力させる、といったタイプの機械学習の仕方です。
-
学習時に渡すデータ
- 手書きの楕円(丸) → ビットマップ・データ(質問)
- 手書きの楕円弧(十字) → ビットマップ・データ(質問)
- 完成している特定人物のイラスト → ビットマップ・データ(模範回答)

(いらすとや「人差し指で押す人のイラスト(女性)」より)
-
推測時に渡すデータ
- 手書きの楕円 → ビットマップ・データ(質問)
- 手書きの楕円弧 → ビットマップ・データ(質問)
-
推測から返されてくるデータ
- 特定人物のイラスト → ビットマップ・データ(回答)
マシンパワーや時間がある場合は、上記のように「手書きの丸」と「手書きの十字の楕円弧」の情報もビットマップで渡せるのが強みです。
では、これを細分化する方法を考えてみましょう。
と言うのも、後述しますが、この手法は単純ではあるのですが学習するのにコスト(時間)がかかります。1 つあたりの情報量(ベクトルの次元数)が多すぎるのです。つまり、モンスター・メソッド的な状態なのです。また、適切に学習させるためのパラメーターの調整にも経験が問われます。
そこで、データを何かしらの「汎用的な形式」に変換して、軽量化、高速化できないか検討します。
例えば、3つの学習データのうち「手書きの丸」や「手書きの十字の楕円弧」の2つのデータを軽量化させたいと思います。
- 完成している特定人物のイラスト → ビットマップのまま学習に使う
- 手書きの楕円 → 汎用的な楕円データに変換 → 汎用データを学習に使う
- 手書きの楕円弧 → 汎用的な楕円弧データに変換 → 汎用データを学習に使う
ここで 2 と 3 に注目してください。途中で画像データから汎用的なデータ形式に変換して、その汎用データをメインの学習に使っています。
では、楕円の「汎用的なデータ」には、何を使えば良いでしょう。
ここでは「楕円の方程式」に使われる引数を「汎用データ」としたいと思います。
具体的に行きましょう。
楕円も楕円弧も方程式で描画できます。そして、この方程式に入れる値(パラメーター)を変えれば、それぞれの大きさや形を変えられます。
この方程式の描画も FOR ループでパラメーターを変えて行き、その結果をキャンパス上にドットを打って行けば描画できます。
- パラメーターを変えることで、ぬるぬる動かす例: Party Parrot を関数で描いてみた @ twitter
- 楕円をオンラインで触ってみる @ Desmos
- 傾きのある楕円をオンラインで触ってみる @ Desmos
1画像ぶんのビットマップデータをベクトル・データとするより、円の「高さ」「幅」「傾き」の3つのベクトル・データで済んでしまいます。これにより、メインの学習モデルでは、楕円と楕円弧に関する学習量が減ることになります。
では、手書きの楕円画像から、その(方程式の)パラメーターはどうやって探せば良いのでしょうか。
そこで、「方程式に代入する値」(パラメーター)と「その結果」(描画結果のビットマップ)を機械学習させることを考えてみます。
つまり「手書きの楕円」や「手書きの楕円弧」を渡すと「パラメーターの値」を出力する学習モデルを作るということです。そしてこのパラメーターが汎用データとなります。細分化のニュアンスが見えてきたでしょうか。
では、この「楕円」と「楕円弧」の学習モデルをどうやって作るかと言うと、画像の機械学習の手法を再帰的に考えます。「問題と答えを渡して学習」です。
つまり、ランダムなパラメーターの値で描画した楕円や楕円弧の画像を「問題」、そのパラメーター値を「答え」として学習させるのです。
すると、今度は楕円を描画したデータを学習モデルに渡すと、そこから想定されるパラメーターを(理屈上は)返してくれるのです。
この時、描画した画像にランダムなノイズも加えて学習させることで、手書きの曖昧さにも対応させられるようになります。
他にも応用として、イラストの線からペン幅を教えてくれる学習モデルだったり、スクリーントーン番号だったり、髪の色だったり、といったシンプルな特徴を検出する学習モデルが考えられます。(出来るとは言ってない)
では、どのように学習に必要なデータを作ればいいのでしょう。
機械学習向けのデータの作り方
これも恐れずに言うなら、機械学習用のデータは「測定データを CSV に変換してタイトル行を消したものを、配列に再変換したもの」と言えます。
一読して咀しゃくできないと思いますが、順番に説明します。
最初の注意点として「文字列がある場合は、すべて番号を振って数値に置き換えておく」必要があることを覚えておいてください。つまり、「ベクトル」と呼べるように「すべて数値で構成された配列データ」にする必要があるからです。
具体的な例をあげます。
例えば、センサー A, B, C からの測定値と、診断結果を yes no とした下記のような JSON データがあったとします。
[
{ "センサーA": 123, "センサーB": 456, "センサーC": 789, "診断結果": "yes" },
{ "センサーA": 987, "センサーB": 654, "センサーC": 321, "診断結果": "no" },
...
]
「センサーの測定値」とは言っても、ただの入力値です。つまり、得られた結果であれば何でもいいのです。画像の場合は、各ピクセルの RGB 値の R の値でもいいですし、トイレに行った回数の手入力値だっていいのです。
さて、上記の JSON を以下のように一旦 CSV に変換します。
| 0 | センサーA | センサーB | センサーC | 診断結果 |
|---|---|---|---|---|
| 1 | 123 | 456 | 789 | yes |
| 2 | 987 | 654 | 321 | no |
| ... | ... | ... | ... | ... |
本当の CSVの場合
"センサーA","センサーB","センサーC","診断結果"
123,456,789,"yes"
987,654,321,"no"
...
次に、文字列がある場合は各々に番号を振ります。ここでは「診断結果」の yes を 1, no を 0 と振りました。
| 0 | センサーA | センサーB | センサーC | 診断結果 |
|---|---|---|---|---|
| 1 | 123 | 456 | 789 | 1 |
| 2 | 987 | 654 | 321 | 0 |
| ... | ... | ... | ... | ... |
もちろん yes no の2値でなく、「ペンギン」「うさぎ」「らいおん」「さる」と複数ある場合は、各々「不明=0」「ぺんぎん=1」「うさぎ=2」「らいおん=3」「さる=4」と振っても構いません。その場合は、0〜4 の5値を振ることになります。
この「数値のラベルを振る行為」は「ラベリング」と呼びたくなりますが、機械学習の世界では「ラベリング」とは「カテゴリやグループに ID を付ける行為」全般に使われます。そのため、あちこちで使われるので注意します。
確かに「文字列に振られた ID 番号」も「ラベル」とは呼びますが、「文字列に ID 番号を振る行為」だけを「ラベリング」と思い込んでしまうと、後々、学習を進める際に話が頭がトラベリング(迷子)になってしまうので注意しましょう。(俺)
何はともあれ、数値だけのデータが出来上がったので、これをデータ(x)と結果(y)の2つのデータにわけます。
-
表 X
0 センサーA センサーB センサーC 1 123 456 789 2 987 654 321 ... ... ... ... -
表 Y
0 診断結果 1 1 2 0 ... ...
最後に、各々のヘッダー行(見出し行)を削除して、配列にします。
x = [
[ 123, 456, 789 ],
[ 987, 654, 321 ],
...
]
y = [
[ 1 ],
[ 0 ],
...
]
以上で、機械学習用のデータの完成です。
これを色々な機械学習のメソッド(クラス関数)の引数に渡して学習させるのです。
sugoi_class.train(x, y)
なお、上記の y の変数に入っている配列、つまり「答え」となるデータは機械学習プロトコルでは「教師データ」と呼びます。英語では「target variable(対象の変数)」と呼ばれます。
そして「教師データ」のある学習を「教師あり学習」と言います。英語で "Supervised Learning"(指導付き学習)と呼ぶのですが、個人的に「教師」より「指導」の方が後々の他の機械学習用語に対してシックリくると思います。
「データ作成」の概念としては以上です。「え?これだけ?」と思われるかもしれません。
えぇ。これだけです。
しかし、このデータを実際にプログラムで使うイメージを持ちたいと思いますので、それもイメージで伝えたいと思います。実際には動かないので、脳内で実行してください。
ちなみに、上記では変数名を x y にしましたが、実際には「data」と「target」と書かれることが多いです。座標の x, y と混合されやすくなってしまうためです。
>>> sample = load_sample()
>>> # 学習データ(観測値)
>>> print(sample.data)
[
[ 123, 456, 789 ],
[ 987, 654, 321 ],
...
]
>>> # 教師データ(診断値)
>>> print(sample.target)
[
[ 1 ],
[ 0 ],
...
]
>>>
>>> # 学習データと教師データ(data と target)を1,000件ぶん学習に使う
>>> train_data = sample.data[:1000]
>>> train_target = sample.target[:1000]
>>>
>>> # 1,000よりあとの残りのデータを検証用に使う
>>> test_data = sample.data[1000:]
>>> test_target = sample.target[1000:]
>>>
>>> # 学習させる
>>> sugoi_class.train(train_data, train_target)
...
>>> # 予測させる
>>> my_result = sugoi_class.predict(test_data)
>>>
>>> # 予測の答えあわせ・検証(結果がわかりやすいようにラベル名も取得しておく)
>>> my_labels = sample.target_names
>>> confusion_matrix(test_target, my_result, my_labels)
...
以上は、とてつもなく端折った説明です。
実際には多くの列を持つことになります。特に、本記事のような画像の場合は、以下のような大量の列や行を持ったデータになりえるわけです。(イメージ)
| 0 | 1ピクセル目 R | 1ピクセル目 G | 1ピクセル目 B | ... | 左目の位置 X | 左目の位置 Y | 人物 |
|---|---|---|---|---|---|---|---|
| 1 | 101 | 255 | 0 | ... | 102 | 200 | A |
| 2 | 101 | 254 | 1 | ... | 123 | 201 | A |
| ... | ... | ... | ... | ... | ... | ... | ... |
もちろん多次元配列にしても構いません。
| 0 | 1ピクセル目 RGB | 2ピクセル目 RGB | 3ピクセル目 RGB | ... | 左目の位置 XY | 人物 |
|---|---|---|---|---|---|---|
| 1 | [101, 255, 0 ] | [101, 255, 0 ] | [101, 255, 0 ] | ... | [102, 200] | A |
| 2 | [101, 254, 1 ] | [101, 253, 1 ] | [101, 253, 2 ] | ... | [123, 201] | A |
| ... | ... | ... | ... | ... | ... | ... |
yes か no のフラグだけで構成されていても構いません。
| 0 | 喫煙する | 酒を飲む | 夜更かしする | ... | 診断結果 |
|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | ... | 1 |
| 2 | 0 | 0 | 1 | ... | 0 |
| ... | ... | ... | ... | ... | ... |
| 0 | 禁則文字列を含む | 技術用語を含む | 禁則URLを含む | ... | スパム |
|---|---|---|---|---|---|
| 1 | yes |
no |
yes |
... | yes |
| 2 | no |
yes |
no |
... | no |
| ... | ... | ... | ... | ... | ... |
特徴量とは
いままでの例に出てきた、学習データを表にした時の「列」、つまり「センサー」や「ピクセル」や「喫煙する」といった表の各列を機械学習では「特徴」と呼び、値のことを「特徴量」と呼びます。

また、特徴の数(列の数)ですが、機械学習では「特徴数 ●●」とはあまり言わず「●● 次元ベクトル」という言い方が大半です。用語に恐れずに、脳内変換しましょう。
「32 次元ベクトルの学習データです」 → 「(数値のみで構成された測定データで、1行が 32 列の、例の array だな。ニヤリ)」
クラスとは
次に、測定データの診断結果、つまり「答え」として、yes no だったり「ペンギン」や「らいおん」がありました。
これらの「最終的に振り分けたい先」を機械学習では「クラス」と呼びます。
そのため、機械学習ライブラリの「プログラムとしてのクラス」と「データとしてのクラス」の2つが混在して書かれているので、これを認識しておかないと文脈がわからなくなります。(ました)
また、「クラス数」の表現も、yes no の場合は2値なので「クラス2」という言い方をし、「不明」「ペンギン」「うさぎ」「らいおん」「さる」の場合は 0〜4 の5値なので「クラス5」という言い方をします。「クラス2」が「ペンギン」ということではなく、「2のクラス」が「ペンギン」に該当します。
問題は、大学や流派によって「2つのクラス」を「2クラス」と表現したりすることもあることです。細かいのですが。
実は、この「違いの理由」を意識しておかないと「おまえは何を言っているんだ」と、言っている意味が理解できなくなります。表現に固執すると文献を渡り歩いても、やっぱり理解できない沼にハマるのです。
先述のように、機械学習の世界では「数学の世界特有の表現」が多く使われます。そして、日々新しい概念が生まれる分野ということもあるのか「数学と数式以外の表現」には、統一もしくは一般化されたものがまだ確立していない気がします。
つまり、「表現に方言のようなバラツキがある」のです。
特に邦語化した(日本語に訳した)ときの表現などです。「庭球?... ... テニスでいいじゃん」みたいに思う事があれば「ベイスボウル?... 野球って言えよ」と思うようなこともあります。
しかし、数式が読める人は、そのバラツキは気になりません。あくまでも数式の補助情報にすぎないからです。
逆に、「数式が読めないと、説明文が主情報となる」ため、理解に困ることが多く出てきます。特に、表現の仕方が異なると、別のものである印象を受けてしまうのです。プログラムの世界でいうと「ソースコード」と「ソース内のコメント」との関係に近いのでしょうか。
何にせよ、「振り分け先」をクラスと呼び、学習時に「クラス」の情報がある場合は、それを「教師データ」と呼ぶと覚えてください。
🐒 機械学習を学習する際のマインド・セット(心の持ち方)
筆者の個人的な意見で、大事なことだと思うのですが、機械学習系の記事や本を読む時の心がけがあります。
「小難しい表現や用語が出てきたら、ファンタジー・ライトノベル系の『中二病が発動したんだな』と、魔法の詠唱や必殺技を口にしているんだくらいの、優しい気持ちで目を細める」です。
我々が「systemctl の名の下に、目覚めよ土のデーモン。壁を作り、攻撃を防げ、防火壁っ!」と唱えながら systemctl start firewalld と叩いてデーモンを召喚するのと同じです。
この詠唱を知っているベテランも、最初は何を言っているのかわからなかったことを思い出してください。わからないながらも、各種ドキュメントを読むなかで、その用語を削るような感じで理解していった、あの頃と同じマインド・セット(気の持ち方)が必要です。社則や法律、もしくは某都知事のカタカナ語のような「日本語でおk」とイラッとくることが多いと思いますが、むしろ魔法の詠唱やサイバー・パンク用語のように捉えた方が、気持ちは楽になります。
分類器とは
以上を総合すると、「クラス分けを予測する処理」は機械学習の基本的な役割の 1 つなのです。(と言っても、後述する「回帰」を含めて 2 つなのですが)
そのため、これらのクラス分けをするメソッド(クラス関数)のことを機械学習では「分類器」と呼びます。ハリーポッターで言う、組み分け帽子みたいなものです。
『特徴1 = 123』『特徴2 = 456』『特徴3 = 789』を『分類器』にかけると、『1』のクラスに振り分けられる
もしくは
『肉食=
true』『ネコ科=true』『大きさ=300』という特徴がある生き物を『分類器』にかけると、『らいおん』クラスに振り分けられる
そんなイメージです。
昨今の機械学習で、従来の機械学習と違うものに「教師データ」のない学習があります。つまり「答え」を教えずに学習させるのです。
「答えがないのにどうやって学習させて分類するんだ?」と思うかもしれません。
ここで先の「教師あり学習」を、英語だと「指導付き学習」と言うことを思い出してください。指導者がいない、つまり「自習してください」みたいな状態を「教師なし学習」と言います。そして、適宜テストを行い、点数が高ければ「方向性は、だいたいあっている」という情報しか得られません。
これは、寿司職人が、海苔の表面を焼くだけに何年も修行させられ、焼き具合が「合格」か「不合格」は教えてもらえるものの、「何で不合格だったのか」は教えてもらず、自分で答え(特徴の組み合わせ)を見つける必要があるような学習スタイルです。
例えば、人間が「ネコ」と認識している大量の画像を(学習モードの)分類器に渡すことを考えます。
「教師あり学習」の場合は、「ネコ」と言うクラス情報(答え)が渡されますが、「教師なし学習」の場合は、ドンと画像だけ渡され「共通する特徴を自分で見つけよ」みたいなことになります。ここでいう「共通する特徴」とは「関連する列の組み合わせ」ということです。
とうぜん、分類器には「ネコ」という「答え」(クラス情報)を渡していないので「ネコ」という単語としては認識できません。
それでも、点数の高さの違いから、全画像に共通する「某なにか」という認識をする(組み合わせを見付ける)ようになります。
そして、最終的に、それらの共通項を「ネコ」として人間が後からラベルを付ける(指導する)のです。これが、先の「文字列に番号を振ることだけをラベリングと思い込まないこと」につながるわけです。
「そんなの後出しジャンケンみたいなものじゃん」と思うかもしれません。「ネコちゃんの画像を渡してるってわかってるんだから」と。
しかし、例えば「みんなにはネコに見えているらしいが、自分には見えない」データを集められたとします。
そのデータを分類器にかけて「某物体X」を検知できたとして、それにラベル「ヌコ」と付けることを考えてみてください。そして、「自分にもネコに見えている」データを渡し、分類器にかけて「某物体Y」を検知できたとして、ラベル「ネコ」を付けます。
後述しますが、分類器の種類によって、特徴と特徴の線引きができるものがあります。この分類器で上記 2 つのデータを解析した結果、「あぁ、眉毛があるからなのかー」と気づくかもしれません。
まぁ、眉毛は適当な例なのですが。
線引きされた特徴をグループ A(眉あり)とグループ B(眉なし)の2つの「某クラス」にわけることから、機械学習プロトコルでは「クラスタリング」と呼びます。「サーバーのクラスタリング」と語源は同じですが、違う意図の用語なので注意します。
密です。クラスターです。
色々なデータの測定値を、さまざまな角度(特徴の組み合わせ)でグラフにしてみると、「クラス」の塊があらわれる場合があります。
機械学習の世界では、この塊を「クラスター」と呼び、クラスターを探すことを「クラスタリング」と呼びます。サーバーの「クラスタリング」のように意図的に同じような塊を作るのとは意味がいささか違うのがわかると思います。
機械学習におけるクラスタリングの例をあげたいと思います。
先の「眉あり」と「眉なし」のように、「答え(クラス)がわかっているが、違いがわからない場合、線引きを行う分類機を使う」と言いました。
この分類器は、色々な「特徴」をグラフの次元に加えて判断する分類器です。
例えば、以下のような2次元ベクトル(=2要素=2つの特徴)のデータと、その答え「●」と「■」(クラス2の教師データ)が与えられていた場合、図に起こすとクラスターが発生していることがわかります。
# 2次元ベクトルの学習データ
train =[
[100, 10],
[10, 120],
[130, 11],
...
]
# 2クラスの教師データ
target = [
['■'],
['●'],
['■'],
...
]
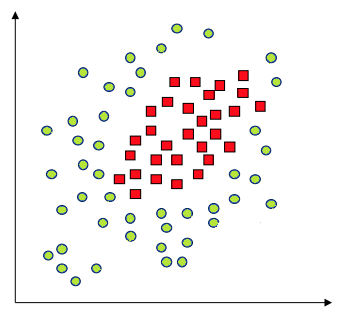
(A friendly introduction to Support Vector Machines(SVM)より)
しかし、これでは線を引くのが難しく、線引きするにしても複雑な式が必要になります。
「線引きする」というのは、クラスターが以下のような場合だとわかりやすいと思います。
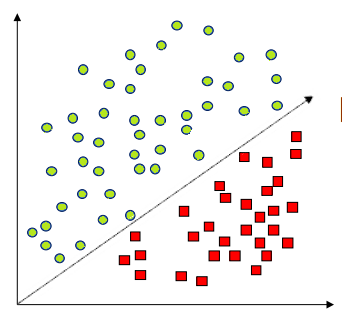
この場合であれば、調べたい対象がどちらのグループ(クラス)に属するかは、傾いた直線(↗︎)の式と比較して内側か外側か(計算値より大きいか、小さいか)でクラスを判断できます。直線でなくても二次曲線(⤴️)くらいまでであれば、式を使って線引きできそうです。
しかし、先の場合は中間位置に密集しているため二次曲線でも線引きは難しいと感じると思います。
このような、直線もしくは平面でデータを区切れない場合、機械学習でよく使われるのが「カーネル」です。
カーネルさん出番だす
「カーネル」の値は、カーネル法という「自分から見て直線じゃないなら、一緒に動いちゃえば直線になるじゃない」という手法を使います。
1次元落として説明すると「見送ってる人が、動く電車と一緒に走れば、中の人からは止まってるように見えるじゃない」的な、熱い漢数を使うのです。
そのカーネル関数に特定のクラスターをかますと動いたぶんを別データとして出力してくれます。これをカーネルと呼び、そのカーネルのデータを「特徴」として、もう1次元加えてみると、直線ではないものの平面で線引きできる(区切れる)のがわかると思います。
以下は、2 次元だったデータに、見つけたカーネルを 3 次元目のデータにした場合のグラフです。
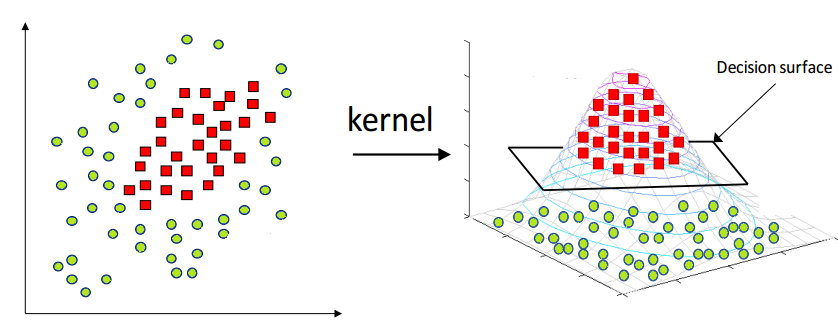
(A friendly introduction to Support Vector Machines(SVM)より)
このような、ベクトル・データの「特徴」の組みあわせにより、ある方向に向かっていることを探し出すのを手伝うタイプの分類機を「サポート・ベクター・マシン」と呼びます。
🐒 Linux や macOS などの OS の「カーネル」が脳裏にチラついた人もいるかもしれません。実は語源は同じです。
kernelとは「何かに覆われており、直接触れない(見つけにくい)が、本質となる物」を言います。日本語で「核」「中核」「種」「(牡蠣などの)身」が近いと思います。OS の場合はシェル(殻)を通さないと触れない OS の基幹となるプログラム集をカーネルと言います。機械学習の場合は、データそのものからは一見わからないが「関数を通して現れた本質的なデータ」のことをカーネルと言います。ちなみにトウモロコシの実であるcornの語源もkern-nelのkernから来ています。
「教師データなし」の学習の場合、データの「特徴」の組み合わせで線引き可能なものがないか、試行錯誤をします。つまり、仮組みと仮引きしたものに「某クラス A」と仮のクラスに分け、他のデータと比較しながらクラスや線引きの値を作成・修正・削除していきます。
のちに、残ったクラスに人間が名前を付ける(ラベリングする)わけです。そう考えると、もう泣いちゃうくらいの for while ループになることは想像に難しくないと思います。
しかし、このように人間すら気づかなかったパターンを見つけることができる可能性もあるという意味で、この「教師データなし」の学習は意義があるのです。
- 【機械学習】教師あり学習と教師なし学習の違い | 予備校のノリで学ぶ「大学の数学・物理」 @ Youtube
🐒 ちなみに、猫の画像を「猫」とラベルを付けるように、「答え」となるデータ(素材)の選別やラベルを付ける気の遠くなる作業は「アノテーション」と呼ばれます。独特のテンションが必要な作業であるため一部では「アノテンション」と呼ばれる状態になると言われたり、言われなかったり。
機械学習の学習と予測とは
🐒 ここでは分類器はどうやって学習し、予測するのかの概念について説明しています。少しプログラムの知識が必要なので次項の「画像の特徴とは」まで読み飛ばしても構いません。
知識と行っても、関数の定義の仕方/割り算と足し算/DB とは何かの知識があれば十分な内容です。
機械学習の役割は与えられた条件(入力)に対して過去のデータから結果を予測(出力)することです。
顔の入れ替えができるのも「入力の表情がこんなデータの時」には「こんな表情のデータになる」という予測によるものです。
では、どのように「予測」しているのでしょうか。
まず、予測には大きく2種類あります。
- 入力情報の全体を見てクラスを予測する「分類」
- 入力情報の流れを見て次のステップを予測する「回帰」
「分類」は今まで説明してきた「ヌコ」や「ペンギン」や「らいおん」の話しで、割とわかりやすい用語だと思います。対して、耳慣れないのが「回帰」です。プログラムで有名な「再帰」ではありません。
「回帰」は、音楽の授業で習うドレミ唱法だと「ハ長調でド→レ→ミ→ファ→ソ→ラ→シ→ド」と学習させた場合、「ド→レ→ミ→ファ→ソの次にくるのは?」という入力に対して「ラ」という出力(予測)を返すタイプです。
日本音名で言うと「ハ長調でハ→ニ→ホ→ヘ→ト→イ→ロ→ハ」と学習させた場合、「ハ→ニ→ホ→ヘ→トの次にくるのは?」「イ」、バンド向けに例えると「C メジャースケールで、C→D→E→F→G→A→B→C」と学習させた場合「C→D→E→F→G の次にくるのは?」「A」と言うことです。
この「流れ」を予測するタイプを機械学習プロトコルで「回帰」と呼びます。
「G」(ソ)に対して「G→A」(ソ→ラ)と学習させたい場合、過去から現在のデータを「F→G→A」「E→F→G→A」「D→E→F→G→A」「C→D→E→F→G→A」と回しながら学習させていくイメージが「回帰」としてわかりやすいかもしれません。
「分類」と「回帰」の違い
「分類」と「回帰」の一番の違いは特徴量の値の性質です。
プログラマー・プロトコルでいうと、同じ 1 と 2 でも a="1"; b="2"(string)と、a=1; b=2(integer)の違いです。
「ペンギン」や「らいおん」などに「1」や「2」というラベルを振りましたが、「1」と「2」の間に関連はありません。別に「5」と「1」でもいいからです。
このような、数値と数値の差に関係がないものを機械学習プロトコルでは「離散値」と言います。このようなタイプのデータには「分類」が似合います。
逆に「ド→レ→ミ→ファ...」の場合に「1, 2, 3, 4 ...」とラベルを振ると「1」と「2」の間には「音の高さ」という相関関係が成り立ちます。このような性質を持つ値を機械学習プロトコルでは「連続値」と言います。例えば温度や気圧なども「連続値」です。このようなタイプのデータには「回帰」が似合います。
なお、「連続値」と言っても「i++」のようなインクリメントされた連番の数値とは違うので注意します。あくまでも「数値と数値の間に関係があるもの」を機械学習では「連続値」と言います。
しかし、これはあくまでも値の性質を大きく2種類に分けただけです。「らいおん」や「ペンギン」のような「離散値」タイプのデータでも「回帰」タイプの分類機が使えることがあるので、違うものと思い込まないように注意してください。
例えば、「らいおん」を「1」、「ペンギン」を「2」とラベルを振って、予測が「1.6」と出た場合、「より "2" に近いので『ペンギン』」と判断できます。「たてがみの生えたペンギン」というわけではありません。(厳密には「回帰(流れ)」なので、「ライオン → ペンギンと来たら次は?」という問いに「うさぎ」の確率、「さる」の確率と各々出して一番 1 に近い(100% に近い)ものを選びます。)
そもそも機械学習の「学習」とは
さて、先の「線引きされたグループ A(眉あり) と B(眉なし)」の場合を思い出してください。入力値がグループ A の範囲(線引きされたラインの内側)に収まる場合は分類器は「グループ A」と返すので、人間は「眉あり」つまり「ヌコ」と判断できます。
しかし、これだけでは DB に突っ込んで SELECT しているのと変わりません。学習ではなく、ただの DB 操作です。
では、「学習」とは何でしょう。DB に突っ込んでいくことでしょうか。
実は、ある意味正解です。
機械学習プロトコルでは、正解か否かは別として「過去のデータを加味すると出力結果が変わった」という状態を「学習」と呼びます。
そのため、学校のように「正しい答えが出る」イコール「学習」という用語の使い方ではないことに注意します。
つまり、「進捗どうですか?」と聞いて「学習しています」という答えは、「以前とは違う答えを出すようになってきました」ということで「正解を出せるようになった」とは言っていないのです。「ロス率は何 % になりました?」と、具体的な正解率・不正解率を確認する方が確実でしょう。
DB に突っ込んで結果が変わったことを「学習」と呼びますが、関数などの線引き情報を人間が設定しておき、DB に突っ込んでいくことを「学習」と呼ぶ時代8もありました。
人間の場合も、過去のインプット(経験)を蓄積して行き、同じ条件で割合として高いものを選択して行きます。「割り合い」、算数で言うと「確率」です。(いささか怖い臭いがしてきましたが、安心してください。ここでは「確率」を「割り合い」と置き換えてお読みください)
しかし人間の場合、すべての行動が確率で判断しているというわけではありません。
「1+1は?」と聞かれた(インプットがあった)場合、「(いままで2ということが多かったから)『2』」という判断ではなく、計算で「2」と答えを出します。つまり、足し算という「理屈」を使っています。
それでも「(こいつは捻くれたエンジニアだから、過去の言動からみて一回ひねってバイナリの)『10』」と答える場合もあるかもしれません。反復しすぎて、条件反射的に「2」と答えるかもしれません。つまり「経験」を使っています。
このように、判断には「理屈」と「経験」の2タイプがあるということです。機械学習の場合も同じで、IF 文などの分岐やアルゴリズムによる条件付けは「理屈」の部類に入り、計算式の重みの値や確率で算出したものが「経験」の部類に入ります。
この「確率」という用語も曲者で、機械学習の要でもあり、難しく感じさせる一因でもあります。
FOR ループの足し算を Σ と略しちゃったりする、せっかちさんな数学プロトコルの世界では、確率も P() と略されてしまいます。「事前確率 P() が...」とか表現するので小難しく感じてしまうのです。
ボカロの「なんとか P」のようなものかと思いきや、プログラムで言えばこういうことです。
function P(分子, 分母)
{
return 分子/分母;
}
/* DB からの、じゃんけんデータ */
// A がいままでに勝った回数
won = 20
// A がいままでにあいこだった回数
drew = 30
// A がいままでに負けた回数
lost = 50
/* 算出データ */
// A がいままでしたジャンケンの回数
total = won + drew + lost
/* 確率の計算 */
// A が勝った時の事前確率(=いままで勝った時の確率)
win_ave = P(won, total)
「確率 P(A)」と文中に出てきたら、一旦落ち着いて上の関数 P() を思い出しましましょう。「(A の割合、つまり A を全体で割った場合のことだな)」と。
ただ、このままだとプログラム的に数値を使い回すのが大変です。条件が増えると win_ave2 = P(won2, total2) と変数も増えていくので煩雑になっていきます。
そこで横着が好きなプログラマー・プロトコルで表現するために、クラスを使って全体の数値を保持するオブジェクトを作成してみましょう。PHP と Python を例にしてみます。
class Unit {
function __construct($全体数)
{
// 「$全体数」は起こりうる全ての場合の数
$this->分母 = $全体数;
}
function P($分子)
{
return $分子 / $this->分母;
}
}
class Unit:
def __init__(self, 全体数):
# 「全体数」は起こりうる全ての場合の数
self.分母 = 全体数
def P(self, 分子):
return 分子 / self.分母
これはオブジェクトを作った時に「全体数」をセットして、P() メソッド(クラス関数)で割合を出しています。
このようにしておくと、条件ごとにオブジェクトを作っておけるし、より数学の P() に近い使い方ができます。
$penguin = new Unit(100); //ペンギン組の総数
$emperor = 10; //皇帝ペンギンの数
//皇帝ペンギンの割合 or 一匹ピックアップした時に皇帝ペンギンである確率
echo $penguin->P($emperor);
# くじの総数
lottery = Unit(100)
# アタリの数
A = 10
# アタリの割合 or 一枚引いたときにアタリである確率
print(lottery.P(A))
- オンラインで動作を見てみる @ paiza.IO
残念ながら、これで確率のすべてを網羅できるわけではありません。
確率の計算には統計学的には色々な手法があります。しかし、確率で知っておきたい用語に「ベイズの定理」があります。なぜなら機械学習だけでなく、Web や UX など色々なものに応用できるからです。
ベイズの定理の概要
「ベイズの定理」の歴史は古く 250 年前からあり、数学の世界では常識だったらしいのですが、Google が生まれたあたりから Web の世界で再注目された定理です。
昔懐かし「ページランク」のアルゴリズムは Google の創設者であるラリー・ペイジ氏の博士論文がベースとなっており、一部の算出にベイズの定理が使われています。当時、人海戦術で天下を取っていた Yahoo! に対し、自動化で検索エンジンの地位を確立したことで再注目されたのです。
その後「I'm feeling lucky」の算出にも使われたり、さらには、有名な Google の Tensorflow だけでなく、様々な分類器でも使われています。いまでは「おすすめのなんとか」に普通に使われたりします。
詳しくは別記事に書ければと思いますが、ベイズの定理を超簡単に説明すると「過去の情報を加味して確率を出す」考え方の 1 つです。
例えば、算数の授業で習ったコインの「表」と「裏」がでる確率は2分の1です。
先のプログラムだと result = P(1, 2) です。サイコロの場合は6分の1、プログラムだと result = P(1, 6) です。より数学っぽい場合は以下の通り。
$faces = new Unit(2); //全体の総数(表・裏の2つ)
$head = 1; //対象の数(表=1つ)
$tail = 1; //対象の数(裏=1つ)
//表が出る確率
echo $faces->P($head);
//裏が出る確率
echo $faces->P($tail);
# サイコロの目の数(⚀ ⚁ ⚂ ⚃ ⚄ ⚅)
dice = Unit(6)
# 対象の数(1の目 ⚀ の数)
A = 1
# 対象が出る確率(1の目 ⚀ が出る確率)
print(dice.P(A))
しかし、n 枚のコインを振った結果を 1 つ 1 つ開けていき「表・表・表」と3回連続で「表」が出た場合、「次に『表』が出る確率は低い」と直感的に感じると思います。イカサマや、コインに問題がない限り「50% に近づく」(表と裏が同じくらいの出現数になる)はずだからです。
逆に、数十回、永遠と「表」が出続けた場合は、あるラインから「次も『表』」と感じると思います。イカサマもしくは出目のパターンを見抜いた状態です。
同様に、「表・裏・表・裏・表・裏・表」と出た場合、次は「裏」が出る割合が高いと感じると思います。これも出目の「特徴」が見えてきた状態です。
これが、これまで「表と裏の出る割合」ベースで考えていたものが「過去の情報を加味して確率を出す」というイメージのスタートです。
数学プロトコルの方々は、この「表・表・表と n 回連続で出た」といった過去の情報を「条件」と唱えて召喚します。
そして召喚された「過去の情報 A」をもとに、「次に B が出る確率」を出したい時、つまり「未来を予見する魔法」を使いたい場合、数学プロトコルの方々は「条件付き確率っ!」と唱えがら未来を予知するのです。
250 年前、その予知魔法を眺めていたとある牧師がいます。トーマス・ベイズ牧師です。
あるとき「ん?逆に B から A を召喚すれば過去が見えるんじゃね?」と思いつき、過去を見通す「逆召喚の術式」を発見します。
つまり、結果 B だけを眺めて「おまえ ... 以前 A だったやろ?」と、過去を言い当てる術式が出来上がったのです。
当然、確率なので外れることもあります。しかも、この定理は最初は精度が低いのです。
実は、この術式は「過去を見通した結果に対する答えを記録して、次回に反映して行く」ことで精度を上げていきます。つまり、過去を当てるために結果という「過去」を更新して未来に … … うん?はい?
と、なると思います。大丈夫です。映画 TENET の初見と同じようなものだと考えてください。同じことを逆方向に見ている、と。
とりあえず、「予測の答えを DB に反映させて精度を上げていく」方法があり、過去から未来へと「過去のデータから次の結果を予測する」パターンと、現在から過去へと「結果から過去を予測する」パターンがある、くらいに考えてください。
しかし、このことからベイズの定理は「結局、過去のデータから予言してんじゃん」とか「A = B を B = A と言ってるようなもんじゃん」とか「確率を後出しジャンケンで変えていくとか、卑怯」とか、永らく異端扱いされていたそうです。
現在では、これを応用して「お前 ... スパムやろ?」と言い当てたり、頭で描いた人物を言い当てる魔神が生まれたりしています。
Web サイトで言えば「ページ A → ページ B → ページ C」と遷移してきたユーザーが「ページ D」に行く確率が出せるようになります。他にも「漫画 A, 漫画 B, 漫画 C」が好きなユーザーに「漫画 D も好きやろ?」といった確率も出せます。
そのためには、過去の「ページ A のアクセス数」や「ページ A から B に行った回数」などを DB などに記録しておく必要があります。
P(ページA に来た回数, 全体の総アクセス数) といった確率を出すために、我々プログラマーは SELECT 文で呼び出し SUM で総数を出してから result = P(ページA に来た回数, 全体の総アクセス数) といった長々とした詠唱が必要です。
しかし数学プロトコルの方々は手のひらを掲げ「事前確率 P!」と無詠唱で呼び出すのです。すごいですね。
いずれにしても、過去の情報から、各々の条件の確率を計算し、ベイズの定理に当て込むと算出できるわけです。
「おすすめ」などの場合は、対象アイテムに対して各々の確率を算出して、一番確率が高い(1 に近い)アイテムを答えとして出すのです。
また、この考え方は「目のピクセル X が A だった場合」に、「B になる確率」「C になる確率」などから一番高い確率を選ぶ、といった処理に多いに活躍します。
もう少し具体的に説明すると、例えば「A → B → C(いまここ)」という状態のとき、C は「A → B」と「B → C」がわかっているので、C に来た時点で 1 ステップ前の B の情報を更新します。
つまり、C に遷移したタイミングで「B が持つ情報」のうち、以下の 3 つのフィールドの数値を +1 して DB を更新します。
-
Bの DB 情報(This = B)-
This → Cと移動した回数 -
A → This → Cと移動した回数 -
Thisへの総アクセス数
-
すると、次回 B に来た時「A から来たアクセスが C に行く割り合い」が算出できるのです。
この定理を単純に利用したナイーブ・ベイズ分類器という分類器も存在します。
この場合、次の行のデータがある意味「教師データ」(答え)となるため、次のステップの予測には強いのですが、逆に「データがどこに属するか」の判断には適しません。つまり「回帰」タイプの分類器です。しかし、クラス情報の列を持たせることで「どのクラスに変化したか」はわかるため「分類」的には使えます。
このように、同じ「分類器」と呼ばれるものであっても、目的が違ったり、得手・不得手があったりと、さまざまなタイプがあります。
画像の特徴とは
ここまでに「ベクトル」「特徴量」「クラス」「分類器」という超基本的な4つの単語を説明しました。また、基本的な「学習用のデータの作り方」もイメージがつかめたと思います。「CSV 化→文字列を ID 化→ヘッダー削除→配列化」のアレです。
しかし、画像の場合は「肉食」や「ネコ科」などの情報は画像自体は持っていません。また何を持って「特徴」とするかも難しいところです。
画像からヒゲを検知するプログラムを書いて、フラグを立てるでもいいでしょう。しかし、その場合は特徴ごとに「特徴を検出するプログラム」を書かなくてはなりません。しかも、本記事では顔の画像しか情報として渡していません。
画像の何を学習しているのでしょう。
画像に限らず、数値化できないと機械学習は行えません。また、単純に数値化するのではなく「特徴」として数値化できなければなりません。
「どのように画像の特徴を数量化するか」は様々な考え方があるのですが、本記事で「顔の要素(目や鼻などのパーツ)の検出」に使われた OpenCV の手法を例にしたいと思います。
OpenCV の場合の、画像の特徴の捉え方
OpenCV は、顔や目などの検出に「濃淡」を「向き」に変換して「特徴量」としています。
ちょっと小難しい言い回しをしてしまいました。手順から入るのがいいかもしれません。
- 画像を一旦グレースケールにする(色情報のない濃淡情報のみのデータにする)
- あるピクセル A からみて周り1ドットぶんのピクセルの濃さを比べる
- 一番濃い方向に向かった矢印を付ける
- この矢印の向きには番号が振ってあるので、ピクセル A の特徴量としてその番号を使う

具体的に行きたいと思います。例えば、画像の座標 X,Y にあるピクセル A の場合、以下のような流れになります。ちなみに、各セルの 0〜 255 の数値は各ピクセルの濃度です。(白い・黒い、どちらを濃いとするかは自由です)
| x-1 | x | x+1 | |
|---|---|---|---|
| y-1 | 255 | 244 | 130 |
| y | 245 | A | 100 |
| y+1 | 210 | 100 | 90 |
数値が大きい方を濃いとすると、上記の場合は左上方向が「濃い」ということになります。そのため、ピクセル A の特徴量は文字列「↖️」になります。
| x-1 | x | x+1 | |
|---|---|---|---|
| y-1 | 255 | 244 | 130 |
| y | 245 | ↖️ |
100 |
| y+1 | 210 | 100 | 90 |
これを、全てのピクセルに適用すると以下のようになります。
| x-1 | x | x+1 | |
|---|---|---|---|
| y-1 | ↖️ |
↖️ |
⬅️ |
| y | ↖️ |
↖️ |
↖️ |
| y+1 | ⬆️ |
⬆️ |
↖️ |
しかし、学習時には「文字列は数値に置き換える」必要があるので矢印のままでは使えません。そこで、仮に以下のように対応表を用意しました。
↖️ ⬆️ ↗️ 1 2 3
⬅️ ■ ➡️ 8 0 4
↙️ ⬇️ ↘️ 7 6 5
そして矢印の文字列を、この対応表を元に数値に置き換えます。
| x-1 | x | x+1 | |
|---|---|---|---|
| y-1 | 1 | 1 | 8 |
| y | 1 | 1 | 1 |
| y+1 | 2 | 2 | 1 |
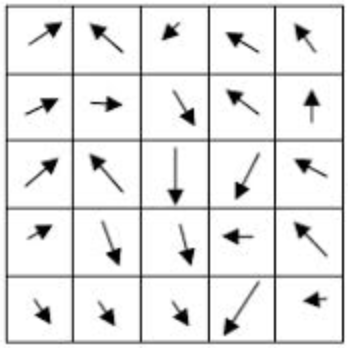
この図からわかることは、番号1(↖️)の出現数が多いことです。つまり全体的に(9 つのピクセルは)↖️に向かっているという特徴が出てきたということでもあります。
そして、その特徴を下記のように大雑把にまとめていく(解像度を荒くしていく)とパターンが現れてきます。

数字だとわかりづらいので矢印のままで表現した場合は以下のようなイメージになります。

「誰だかわからないけど、顔や鼻の位置がなんとなくわかる」と思いませんか。まぁ、画像の方も誰だかわからないんですけど。
どうやら Will Ferrell さんと言うアメリカの俳優さんらしいのですが、機械学習でよく出てくる(使われる)人の1人です。レッチリのドラマー Chad Smith さんと激似なので、機械学習で区別できるかの素材に使われます。
何はともあれ、この濃淡を使った手法を "Histogram of Oriented Gradients" 略して「HOG」と呼んでいます。よく見ると、矢印というよりは * というか小宇宙というかアメーバみたいに見えますが、これは解像度を荒くする際に矢印を1つのセルにまとめているからです。(後述します)
機械学習の本を開くと、このような「矢印」と「ベクトル」という単語が多く出てくるため、ドキリと難しく感じてしまいますが、単純に「向き」を示した矢印なのです。
これを、イスラエルの放送大学で公開されている「顔のデータ・ベース」を元に学習させた顔の共通するパターンが以下の左の画像です。右の画像が OpenCV で検知した似たようなパターンのエリアです。
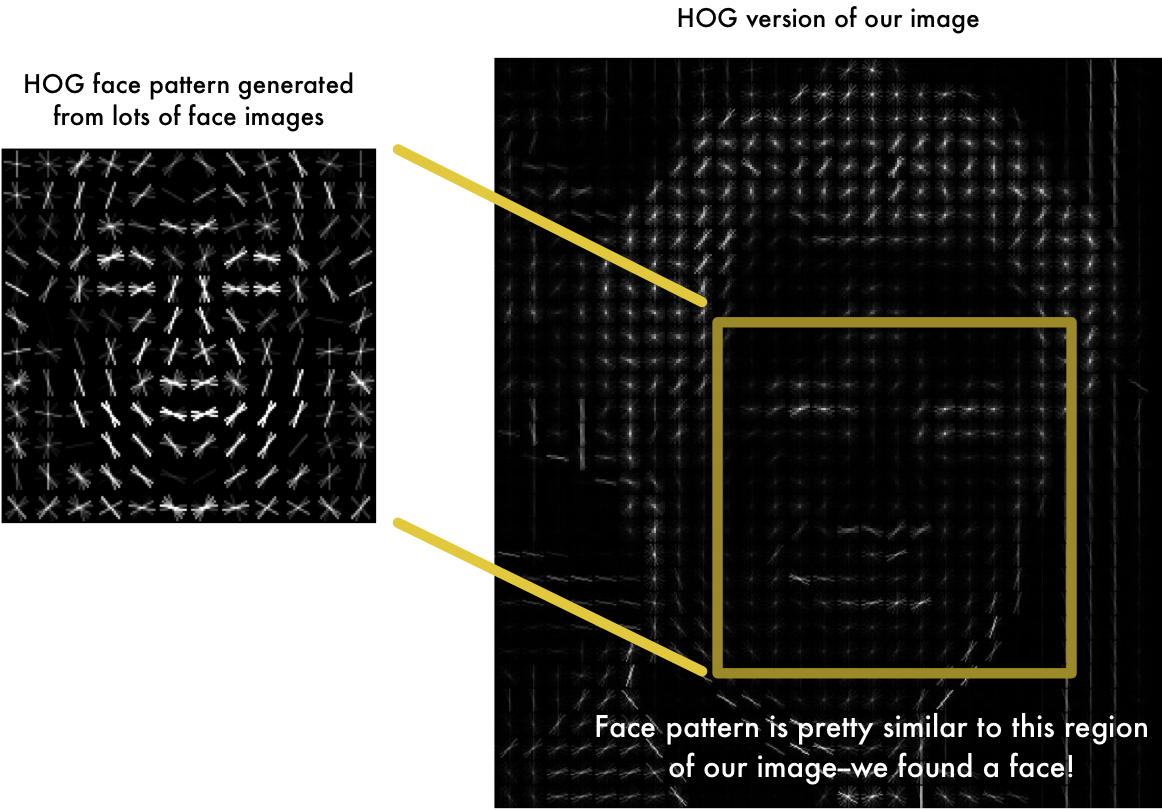
Faceswap では、上記の右画像のようなデータを、本記事最上部で説明した3つの学習モデルのうち encoder に渡しているのです。
🐒 この矢印を使ったイメージは人間が把握しやすいようにしているだけで、実際のデータでは矢印の向きなどは数値に置き換わっていることを忘れないでください。
また、わかりやすいように 8 方向の矢印を使いましたが、実際には向きだけでなく「濃度の差」も追加されています。この濃度差を矢印に反映させるには「矢印の長さ」を使います。つまり、隣のピクセルとの濃度差が大きいほど矢印を長くします。
例えば、この「矢印の向き」+「濃度差(=矢印の長さ)」を図に反映させると左下図のようになり、1つのセルにまとめると右下図のように表現されます。先の * というかアメーバみたいな状態に近づいているとわかると思います。
 →
→ 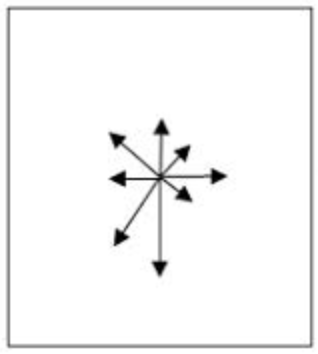
なんか、高校時代のベクトルが見え隠れしてきますね。怖いですね。でも、矢印は実際には数値に置き換わっていることを思い出してください。
さて、矢印だけだった時は、[1,4,4,...] で済んでいたのですが、濃淡の差という「強さ」が追加されました。
つまり、「矢印」+「強さ」の2つの値を配列の1要素(セル)が持つので、[[1,10],[4,12],[4,20],...] という多次元配列になります。([[向き,強さ],[向き,強さ],...])
その上で以下程度に考えると楽になると思います。
配列
$aのうち、$a[0〜n][0〜n](n=5)(下図左)を、別の配列$b[X][Y](下図右)に代入して多次元配列にしているんだ。
→
このような、ベクトルを1つの塊にしたものを機械学習プロトコルでは「テンソル」と呼びます。
ちなみに、英語でテンソル(tensor)とは「収縮したり伸びたりする筋肉」のことで、転じて「跳躍力」や「何かに影響する力の溜め込みと解放」みたいな時に使われます。
そのため「多次元配列 = テンソル」と言うよりは、配列を何かしらの関数を通して別の配列に圧縮もしくは展開をされた配列をテンソルと呼んでいるイメージです。
次に、今回の例の場合 8 方向の矢印を使いました。しかし、解像度を荒くしてくと(特徴を大雑把にまとめていくと)、8 方向では大雑把すぎるのです。「どうも、ピクセルとピクセルの間に濃度のピークがきてるっぽいんだよなー」という状態です。
そこで、
『どうせ、各要素が
[向き, 強度]の2値を持っているなら[Xの強さ, Yの強さ]の2値にして、「向き」および「強度」も自由に指定できるようにしちゃおうぜ』
という荒技が使われています。
例えば「↖️より、ちょっと上向きで、ちょっと強め」なら $a[-10, 15] とか、「↗️ で弱め」なら $a[10, 10] といった具合です。
イメージだと、こんな感じ。矢印が脳内で「向いている方向」と「強さ」です。
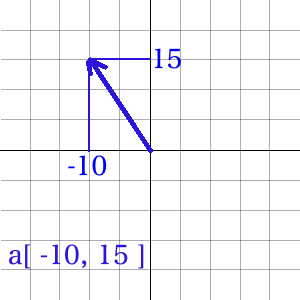
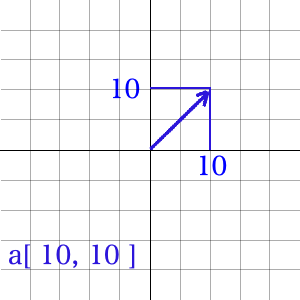
これなら、「矢印」↔︎「数値」の変換表もいりません。しかも、脳内矢印を書くと、めっちゃ高校で習ったベクトルっぽいですよね。ただの、配列なのに。おー怖っ。
しかし、数値だけだと今回のように「向き」や「強さ」がわかりづらくなります。というより機械学習の内部は、ほとんどが数値の配列(ベクトル)がこねくり回されるため、普通の人間は何が起きているのかわかりません。
プログラムでいう Print デバッグのように「現在の状態をいかに可視化するか」が大切になってきます。
そして、この「数値の変化量(0,0→x,y)」を人間がわかるように可視化したものは、たいていが矢印です。これが、機械学習でやたらと矢印が出てくる正体なのです。
ちなみに、これ(変化量)を算数では「傾き」と呼びます。
🐒 この HOG の矢印付きの図を見て、天気予報などで「風の向きを示した図」に近いと感じた読者もいらっしゃると思います。「画像の濃度の差」の代わりに「気圧の差」にすればいいのでは、と。するどい。理屈では可能です。ただ、先の機械学習データの作り方を踏まえて、気象庁のデータを見てみると、ベクトルの特徴の組み方や次元数が半端ないと感じると思います。1つの表が1行ぶんのデータだからです。ただ、「可能だ」ということはわかると思います。ちなみに、これらの莫大なデータから、機械学習用に必要な特徴を解析する人を「データアナリスト」と呼んだりします。音から周波数成分を解析できるスペクトラム・アナライザを人間にしたデータ版みたいな方々です。
データの個性とは何か
さて、本記事では「顔の入れ替え」を主題にしていますが、本質的な意味で大事なのは「個性の学習」です。顔の入れ替えは、その学習結果の答えでしかありません。
「個性」と言うと「その人(もしくは物)の、唯一無二の特徴」と捉えがちです。しかし、いまいちど「個性」とは何か落ち着いて考える必要があります。
事実、「わかりやすい特徴」は識別しやすいことから「強烈な個性」として判断材料になります。シルエットからわかってしまったり、セリフだったり。これは機械学習でも同じです。しかし、逆に言えば識別しやすいため機械学習させなくても if 文で作れてしまうということでもあります。
機械学習が注目を浴びているのは、人間の手による if 文の分岐では実現不可能な(現実的ではない)規模の条件を機械が学習して判断できるようになったことです。
つまり、一般的に「ニュアンス」と呼ばれるような、その道の通の人にしかわからない、一言では形容しがたい特徴を学習させることができるようになったのが、注目の理由です。
特に「ディープラーニングは特徴を自分で見つけて学習する」と言われます。しかし、機械学習の「データを渡せばなんでも分析してくれるんでしょ」的な神話は、Web 業界で例えると「Google Analytics を入れればアクセスの分析してくれるんでしょ」というのと似ています。つまり、Google Analytics で解析してもデータが読めず、結局「総アクセス数で教えてくれ」と似た残念な結末の臭いがするのです。
「データの個性」(他のデータとの違い)がわからないと、データを与えたところで、結局のところ無駄なコストが発生するのです。
個性のニュアンス
それでは、個性とは何でしょう。上記であげたような if 文で分岐できるような「唯一無二の特徴」でしょうか。
例えば「ザ・たっち」の二人の顔を入れ替えたところで、私には区別がつかないでしょう。しかし、ファンの場合は識別する特徴を知っているはずです。ホクロとか、ちょっとした癖とか。
他にも、キャラが立ちまくりの漫画しか読んでいない人から、お気に入りの漫画を「髪の色と髪型が違うだけで顔が全部同じ」と言われたり、なんとかクラブや、なんとか娘や、なんとか 48 のメンバーが全員同じに見えるとか言われたり。
または、醤油ラーメンが「醤油の味しかしない」と言われるような、1つのキャラ(特徴)が立ちすぎて全部同じに見えたり。でも、わかる人はその微妙な違いに意味を見出しているのです。ワインのテイスティングや、武田鉄矢さんや猪木さんのモノマネだったり。
このように、本質的に、個性とは大小関係なく「『違いの集合』である」のだと思います。後述しますが、大小が関係するのは学習コストです。
機械学習の場合は、1行あたりの「特徴の数(=列の数=ベクトルの次元数)」と「特徴の量(=セルの値)」の組み合わせによって、「データの個性が決まる」というわけです。
そして、「全データ(=行の数)から共通する特徴」を最終的に見い出すのが機械学習の基本的な考え方です。これが、機械学習にはデータが多ければ多いほど良いと言われる理由の 1 つです。
🐒 余談ですが「特徴の選別の仕方」や「学習させるデータの種類や量」によって機械学習にも「思い込み」が発生します。
つまり、それまでのデータからしか判断していないので「決めつけ」てしまうのです。「パソコンができる=オタク」と決めつけるような感じです。これを機械学習プロトコルでは「過学習」と呼びます。「過学習している」と出てきたら「思い込みと決めつけが発生している」と脳内変換しましょう。つまり、判断材料となる特徴数が少ないか、データの総量が少ないか、データに偏りがある状態です。
さて、先に以下のような説明をしました。
つまり、一般的に「ニュアンス」と呼ばれるような、その道の通の人にしかわからない、一言では形容しがたい特徴を学習させることができるようになったのが、注目の理由です。
この言葉だけを抜き取って「経験値の豊富なベテランの勘所を機械学習させれば、ベテランいらなくなるじゃん」と考え、メディアのように「AI に仕事を奪われる」と考えるのは早計です。
学習のコスト
例えば「血液型の性格診断」など、全てのデータが「人間を前提」としている場合に「人間である=true」「類人猿=true」という特徴は「個性」としての判断情報になりません。全てのデータが同じ特徴量を持つからです。そのため、それは余計な処理をさせるだけの無意味な情報になります。
現在の機械学習では、この無駄な情報に対する処理はコストにダイレクトに響きます。機械学習では「1つの特徴」を「1つの次元」として言うように、1次元増えるだけで処理が一気に増えるからです。プログラム的には「ループの中にループを作っていくようなもの」と思えばわかりやすいかもしれません。
一般的に、コストには3種類あります。
- 「時間」
- 「経費」(ハードウェア代、電気代など)
- 「人件費」(作業する人)
早く答えを出させたい場合、つまり「時間のコスト」を下げる(速く処理させる)には以下の二択しか基本的にありません。
- 「経費コスト」をかけて CPU/GPU 速度を上げる or クラウドなどでレンタルする
- 「人件費コスト」をかけて情報を選別する or プログラムを改善する
コスト問題の具体的な例をあげたいと思います。
機械学習とりわけディープラーニングといえば Google 社の AlphaGo の話は有名かもしれません。
棋譜のビッグデータ(過去の膨大なデータ)から学習した AlphaGo Master が囲碁のチャンピオンに勝ったという話しです。
つまり「歴史(過去のデータ)から学習して人間を超えた」という瞬間です。
そして、AlphaGo Master 自身も、すぐ後に発表された AlphaGo Zero に破られてしまいます。しかも、AlphaGo Zero は AlphaGo Master のように「過去の既存データ」を必要としないのに 40 日程度の学習期間で圧勝したという、さらに驚きのストーリーです。
AlphaGo Zero は「強化学習」と呼ばれる学習マシンです。ルールを設定してあげれば、自分で思考錯誤したデータから学習するタイプの学習です。
先に、「教師なし」の学習で「自習するようなもの」と形容しました。これは教師データがない代わりに、点数だけ教え、学習の指針とするものです。それの学習を補強(reinforcement)するために「問題を作るライバル」を加えたたものが「強化学習」(reinforcement learning)です。
つまり、ライバルは問題を考えたり、相手が答えられない問題を考えると点数がもらえ、自分はライバルの問題が解けると点数がもらえます。
「教師なし学習」を「試行錯誤タイプ」と形容すると、「強化学習」は「切磋琢磨タイプ」と形容できると思います。
このような、過去のデータ、つまり学習データなしで、試行錯誤・切磋琢磨するタイプの機械学習を「強化学習」と呼ぶのですが、「たったの 40 日で、歴史(過去のデータ)を超える強さを得たに等しい結果を出した」ということが話題になりました。
これを聞いて「当社にも応用できるかもかも!」と思ったかもしれません。私も脳裏をよぎりました。しかし、1つ重大な点が抜けていたのです。
そう「学習コスト」です。
この AlphaGo Zero の 40 日の学習にかかったコストは 38億円(3,500万ドル)と言われています。たかがゲームに勝つために、この規模の金額を広告費として計上できる👌を持った企業でないと難しいのです。
さらに、人件費のコストも恐ろしそうです。AlphaGo の開発元である DeepMind 社のドキュメンタリーを見ればわかりますが、人数は少ないものの、大学の博士持ちのトップクラス・プログラマーの頭脳をかき集めて挑んでいるのです。
- AlphaGo - The Movie | Full award-winning documentary | DeepMind @ Youtube
さて、機械学習では、予測した結果と教師データ(答え)が異なる割合を Loss 値といいます。不正解率みたいなものです。
Deepfakes の学習で、実用に耐える学習モデルになるには「学習の Loss 値が 0.02〜0.03 以下」と言われ、この値が大きいとモザイクがかかったような結果になりやすくなります。Mac で GPU を使わない場合、データにもよりますが軽く 4〜6 日はかかります。データが悪いと、1ヶ月経っても永遠と 0.06 付近を行ったり来たりします。
つまり、学習は他のコストとのトレードオフなのです。
そのため、「データの個性を見極めること」はデータの個性を学習させる以上に重要でもあるのです。
機械学習のコストは人間の教育事情にも似ている
「ベテランの職人さんが教え下手。ゆえに新人が育たない。」と言われる原因の1つに「特徴数が多いから」があります。
つまり、特徴数(ベクトル数)が多いため「if 文で説明できるような簡単な組み合わせでない」ことが原因で「説明できない」のだと思います。
機械学習の場合、「お金」や「時間」などの「リソース」と呼ばれる「気合いと根性」がある場合、無駄なデータも一緒に渡してゴリゴリと時間をかけて学習させることができます。
人間の場合も実は似ていて、「体で覚えろ」というのは、機械学習的には「データ量を増やして、共通項を見い出せ」と似た処理であるため、実は合理的ではあるのです。私は一見して非合理な、この「急がば回れ的」な合理性を「非合理の合理」と呼んでいます。
しかし、現実社会では「無駄な処理が多い」「時間がかかる」というコストが、「先に辞めてしまう」という別の合理性に働いているだけなのです。
では、新人の学習を早く終わらせるために「無駄と時間を減らしてコストダウンを図る」には、機械学習と同じで「新人にはない職人さんの勘所の特徴を見極める」必要があります。つまり、厳選された特徴を教える必要があるのです。プログラム的には、特徴を IF 文で書けるくらいまで落とし込んだものということです。
このように「何を持って特徴とするか」を見極めるのは別の特殊なスキルです。
これは「名選手は名監督ではない」ことや「俺、職人で先生じゃないし」という言い訳にも似ています。
データ作成のスキルは教育スキルと似ている
学校や塾などの「スクール」は「必要な情報に絞って与える」ため無駄の少ない学習ができます。「厳選された特徴で学習させる」という意味では、機械学習も同じです。あとは「経験」という、データ数を増やすだけですが、少ないデータ量で同じ答えは出せるようになるのも同じです。
しかし、特徴数が少ないぶん、イレギュラーなどの応用が効きづらいというジレンマが発生します。私は、一見して合理的だが上手くまわらないことを「合理の非合理」と呼んでいます。「バッチやマクロを組んだのに、返って振り回された」など、効率化を図ったのに返って面倒が増えた経験を持っている人も多いのではないでしょうか。
スクールで習うのとは違い、独学の場合は「(内容が)厳選されていないためスクールよりも特徴数が多い」とも言えます。
そのため、独学の場合はデータ数を多く持たないと、それらの違いから共通項を見い出す(学習する)のに時間がかかるのです。逆に言えば、一旦学習を終えた独学の場合は、特徴数が多いぶん応用が効くとも言えます。
どちらが良い・悪いでなく、コストの面だけで見れば、やはり「厳選されたた特徴を持ったデータ」からはじめ、学習がある程度完了したのであれば、さらなる特徴を追加していくのが合理的です。
つまり、「職人のスキルを機械学習させて、経費削減を図る」のであれば、まずは「職人のスキル」の棚卸しができないとダメということでもあります。スキルの特徴を見極め、数量化する術が必要なのです。
微々たるものの実際に触ってみて、低コストで質の良い学習データを作るのは、良質な教科書を作るようなものだと感じました。
教材の選定スキル
そのデータの見極めで、もう1つ重要なのがデータの内容の選定です。
これを把握していないと「学習データが人種差別をしている」「性差別をしている」「パワハラを肯定している」など、偏った結果を出しかねません。
「██は、██だ」と「██アンチ」な環境下で教育を受けた生徒は「██アンチ」になるようなものです。
この問題は、社会経験に偏りがあると、当人がそれを自覚・認知できない(違いを理解できない)ことです。機械学習の場合でも、「偏りがあると理解できていない」人による収集・選定されたデータで発生します。
では「中立で、データを選べばいい」と感じるも、実はもっと複雑です。「中立に選ぶ」ということは、「██アンチ」のデータも含めるということで、一定の条件で「██アンチ」の答えを出す学習もするということです。逆に「██アンチ」の情報をフィルターすると「██アンチのアンチ」という、新たな「██アンチ」という偏りが発生し、問題は振り出しに戻ります。たまにメディアが「██アンチ的な思想を AI が返した」と騒ぎ立てますが、おそらく、その AI は逆の思想も返すはずです。中立にデータを選べば選ぶほど、リアルな人間社会を反映させるためです。つまり、10 人に 1 人「██アンチ」がいたとすると、10 % の確率で「██アンチ」を返しますというだけの話しです。逆に都合の良いようにフィルターすると、某国のような言論統制や、マスメディアと愉快なスポンサーたちによる情報操作と変わりはありません。機械学習にも教育者側のジレンマがあるのです。正解を考えたくない(悩みたくない)人が、「正しい答えを出してくれるはずだ」と依存したい人ほど「〜な答えを出した」と騒ぐのです。AI は「小さな人間社会や自然をシミュレーションしている」と考えて、よりベターな未来の可能性を見つけるためのツールとして活用したいものです。
先に「ネコ(眉なし)」と「ヌコ(眉あり)」の例で「わかっているデータ(ネコ)」と「よくわからないデータ(ヌコ)」を各々渡して違いを見い出しました。しかし、ここで言う「よくわからない」というのは、ちゃんと「ターゲットを絞った上でわからないもの」ということです。
「ネコ」「ヌコ」の違いを見出したいのに、「よくわからないもの」という単語だけに縛られ、よくわからない前衛的なアートや宇宙からの物体 X のデータを入れると学習もおかしくなるのは想像できると思います。
つまり、「何」を教えているか把握する必要があるのです。
実は、これが意外に難しく、プログラムで言うと以下のように判断してデータを作成してしまうことが多くあるのです。
# わかっているデータ
if ( $data === 'cat' ){
//
}
# わかっていないデータ
if ( $data !== 'cat' ){
//
}
お気づきでしょうか。上記の場合は、「意味不明な前衛アート」や「宇宙からの物体 X」も「わかっていないデータ」として通ってしまうのです。
これは、自分主体のデータの選定をしているからです。おそらく、正しくは以下のように判断すべきでしょう。
if ( others( $data ) === 'cat' ) {
if ( me( $data ) === 'cat') {
// ネコとわかっているデータ
} else {
// ネコと認識できないデータ
}
}
「遅刻するタイプを機械学習させて業務改善に活用したい」と思う企業もあるかもしれません。
しかし、社内の特定人物だけだったり、間違った特徴を使ったり、データに偏りがあると「終電で帰る==遅刻するタイプ」と単純な学習結果になるかもしれません。
また、都合の良い特徴とデータだけを使って、「終電で帰る && 遅刻しないタイプ」を正しい社員と判断するかもしれません。「終電で帰る == good」「遅刻しない == good」と、片方にバイアスがかかっていることに気付いていないデータです。
つまり、公正に判断できる学習をさせるためには、公正な目を養って教材を作成する必要があるのです。機械学習のデータ作成スキルは教育スキルと似ていると思いませんか?
🐒 21 世紀の天然資源に「二酸化炭素」と「情報」があると言われています。情報の資源を多く持つにも👌が必要です。
Google の Tensorflow や Facebook の PyTorch など、大手が OSS(オープンソース)で公開してもビジネスになるのは、誰でも触れるようになり浸透する反面、学習コストとの葛藤が出てくるので、そこを突いているからです。
つまり、すごい GPU を用意したり、すごいデータ量を保存したり、さらにはデータを絞る人員を割くことができない企業のために、クラウドで実行環境を提供しているからなのです。
Google 検索始め、Youtube、Analytics や Tensorflow といい、ニーズを自ら作り、インフラを提供する👌を持った企業でないとなかなかできません。すごいですね。
機械学習の学習コスト(数学は勉強すべきか)
答えから言ってしまうと「ツールとして使うぶんには数学の知識は必要ない」と言っていいと思います。フレームワークの使い方と効果がわかっていれば、最初は十分だと思います。
しかし、昨今の機械学習の本や記事を読んでみると最初から Σ やら色んな数式が出てきます。
「(えー。高校の数学から勉強しなおさないといけないのか...)」と感じた方も多いと思います。
これは機械学習の「仕組み」を勉強しているためで「使い方ではない」からです。
なぜ「使い方」に注力した書籍が(まだ)少ないかと言うと、機械学習の世界、特にディープラーニングの世界では毎週のように新しいアルゴリズムや論文が出てきており、改善されたり組み込まれるためです。
以下は、ドイツのウィーン工科大学の元教授である Károly Zsolnai-Fehér 氏の Youtube チャンネルですが、最新のコンピューター・サイエンスの論文概要を各々 5 〜 6 分で紹介しています。名前が読めない
時間があれば古い動画から観ていくのがオススメなのですが、1 年の違いで AI がどれだけ進化するのか実感できると思います。
- Two Minute Papers @ Youtube チャンネル
このように、新技術の論文発表が毎週のようにあったり、各社がフレームワークを提供しているのに、何か遠くに感じることはないでしょうか。
これは、フレームワークをアプリケーションと勘違いしているからです。Web の業界で言えば Bootstrap と WordPress の違いのようなもので、無意識に WordPress 的なモノを求めているからです。論文のアイデアの実装は各々する必要があり、それに役立つのがフレームワークというだけなのです。そして、それらの学習モデルも自分で作らないといけないのです。
各社がプロプライエタリで囲い込みをする中、2022 年に Stable Diffusion が話題になったのは、その両方(実装とモデル)をオープンにしたからです。つまり、画像系(CV 系) AI の WordPress 的なものが実質初めて出現したのです。「アートの仕事がうんぬん」と騒がれましたが、WordPress が無料だからといって出版業界は潰れたでしょうか。WordPress をツールとして賢く立ち回ったことで生き残ったのです。DTP や DTM などに、新たなツールが追加されたに過ぎないのです。
さて、機械学習において、精度もさることながら処理速度の改善はコストの面からも重要な要素であるため、すぐにフレームワークが使えなくなり(互換性がなくなり)ます。
また、バージョンアップして追随するにしても、論文の通りなのか検証してから実装する必要も出てくるため、論文が何を行っているのか知る必要があります。そのため「どう言った理屈が組み込まれたのか」を理解できていないと使い続けられないのです。
使い続けると言えば、先にコストには「時間」「経費」「人(人件費)」の 3 つがあると述べました。これは「モノを長く使い続けるにはメンテナンスが必要で、安く済ませるには知識が必要」という原則があります。車、家、パソコン、何でもそうです。数百年使われている建築もメンテナンスを続けているから使い続けられるのです。これらを持っていない場合は、お金で時間を買うか、時間をかけて知識を得るしかありません。
自分のアプリの依存パッケージが、さらに依存しているパッケージで deprecated になったので別のパッケージに切り替わっていたと言うことはよくあります。そのため、「使い続けるには最新バージョンでなくバージョンを固定しないとダメ」と言った経験をされた方も多いのではないでしょうか。
機械学習でもバージョン固定は必須です。しかし、機械学習の世界では、すぐに「いまだに WindowsXP を使っているので、それは使えません」状態になるくらいの進化速度なのです。
機械学習に限らず、「よくわからないけど叩いたらテレビが直った」的な感覚でコマンドを叩いても動かないのは、根本的な理解の不足によることが多いのはプログラムの世界でも一緒です。
どの分野にも「使うぶんには知る必要はないが、知らないと障害時に問題解決できない知識」と言うものがあります。
機械学習の場合は「数学」はその1つです。
特に「時短」を考えた場合、アルゴリズムから抜本的に改善する時には「微分」と「行列」の知識が必要になります。
怖いですよね。微分。自分も計算できません。
でも「微分」は、一言で言ってしまうと「その瞬間の傾き」のことです。さらに「傾き」とは、2 点間の「変化の差」でしかありません。
この 2 点を極限まで近づけて「その瞬間の傾き」を出すことを「微分」と呼んでいるのです。
なぜ「変化量」(傾き)を知る必要があるかというと「無駄がないように先読みしたいから」です。
例えば、機械学習では複数の条件の確率や関数の出力に対して「重み」と呼ばれる調整値があります。この重みを変えながら正解に近づくように調整していきます(難しく聞こえますが、動かせる図で見ると「あー」となるので、近々補足していきたいと思います)。
この時、その正解率の曲線のピークを調べたい時、つまり正解率が一番高い調整値を調べたい時はどうしたら良いでしょうか。
愚直に調整値の 0〜n までの値を for ループで変化させても良いのですが時間がかかります。
特に正解率は上がったり下がったりを繰り返すので、この場合、どこが一番良い調整値なのか探すには長い時間走らせて結果を見比べて判断するしかありません。
そこで、ソートで言うピボットのように、2つの調整値を飛ばし飛ばしにしながら曲線の傾きを見て、上りと下りがあったら、その間にピーク(傾きがゼロのポイント)があるとわかるので、傾きを見ながら狙いを定めて効率的にピークを探して行きます。
この実装を考えた場合、私たちは if とか for とかコメント文を詠唱しながら相手に伝える必要があります。しかし、数学プロトコルのでは「微分する」の一言で終わってしまいます。
そして我々は、「なっ、無詠唱だと?」とビビり、恐れおののくのです。
- 中学数学からはじめる微分積分 | 予備校のノリで学ぶ「大学の数学・物理」 @ Youtube
- 中学数学からはじめるAI(人工知能)のための数学入門 | 予備校のノリで学ぶ「大学の数学・物理」 @ Youtube
先にも少し触れましたが、「配列をソートする(ソート関数を使う)のに、ソート・アルゴリズムを知る必要はない」のと機械学習と数学の関係は似ています。そして「処理速度」と言う問題が出てきた時に、やはりソート・アルゴリズムの知識は必要になるのとも似ています。
また、プログラムをコーディングするのに「2進法」や「論理演算子」の知識は必ずしも必要ではありません。しかし、同じく「処理速度」と言う問題が出てきた時に、AND や OR の論理演算がわかっている必要があります。
Web 業界で言えば Apache で Web ページを作るのに TCP/IP のプロトコルを理解する必要はありません。しかし、トラブル時などには切り分けとして知っておくと障害対応に強くなります。
このように、使うぶんにおいて必要な数学知識は「意味がわかればよい」程度で、自分で数式を書いたり解いたりするまでは必要ないと思います。(できればそれがベストなんですが)
私個人的は、for ループの足し算のように、プログラムの処理を見て具体的に何をしてるのかを把握してから、数学の計算式を見た方が理解が進んだことが多くあります。
最後に
さて、ここまでの説明は、クラウドの説明で言うと「JSON とは」「WebAPI とは」「RESTful とは」「リクエスト数は」程度の説明でしかありません。サーバーの種類、クラスタリングやインスタンスなどの説明まで届いていないくらいの位置付けです。
私もまだまだ勉強中ですが、「実際に触ってみる」という意味での機械学習の入り口に必要なキーワードだと個人的に思ったので編集後記に1記事ぶん相当を追加しました。別記事にしてもよかったのですが、おそらく Deepfakes に興味を持っている Qiita ユーザーのほうが、最終ゴールを理解してくれ、読んでくれるだろうな、と思ったからです。この記事が、写真だけでなく、ボーン(骨格の構成線)の位置情報だったり、ペン幅の線画情報だったりと、機械学習において応用を効かせるための何かのお役に立てれば幸いです。
参考文献とオススメの文献
- ディープラーニング(Deep Learning)とは?【入門編】 @ LeapMind BLOG
- 予備校のノリで学ぶ「大学の数学・物理」 @ Youtube チャンネル
以下の2つは英語なのですが、この記事を踏まえてご覧になると、より理解が深まると思います。
- "DeepFakes Explained" by Siraj Raval
- "Machine Learning is Fun! Part 4: Modern Face Recognition with Deep Learning" by Adam Geitgey
また、個人的に機械学習の超初心者向けの最初の1冊としては以下をおすすめします。
- 「カラー図解 Raspberry Piではじめる機械学習 基礎からディープラーニングまで」
- 講談社 ブルーバックス・シリーズ 定価1,600円(税別)
- https://gendai.ismedia.jp/list/books/bluebacks/9784065020524
- ISBN-10: 4065020522 / ISBN-13: 978-4065020524
- Amazon 実売価格
- Kindle: 1,728円(税込、ASIN: B07B7JFKL2)
- 新書: 1,728円(税込)
- http://www.amazon.co.jp/dp/4065020522
- 所感: 数学プロトコルを使わない(数式がほとんど出てこない)説明で、とても丁寧に解説しています。ただ Python やプログラムに関する基本的な説明までしてくれるので Qiita ユーザーにはいささかクドイと感じる部分もあるかもしれません。それでも、短いサンプル・プログラムも多く、写経にはもってこいだと思います。また、私は Kindle 版を買ったのですが、写経をしながら読む場合は新書の方が良いかもしれません。図や表を使った説明が多いため、ページを行ったり来たりするためです。電子本だとちょっと読みづらいと感じました。
-
【幸せの公式
H=S-Fとは】スティーブ・ウォズニアック氏が提唱するエンジニアなどの『人が「幸せ」(Happy)になるための公式』で、「幸せ=笑顔ー不快感」(Happy = Smile - Frowns)というシンプルな公式です。つまり、「笑顔」を増やし「不快感」を減らせば「幸せ」は増すという考え方です。
VHS やアニメが普及した背景と似たリビドーが DeepFakes にも存在するのはわかります。それがある種の学習のモチベに繋がるのも理解できます。しかし、何事もネットに公開した時点から対象となる母数が増えます。特にフェイクポルノは、需要(S)より社会的にFの要素が多くなるので結果的にHの要素が減る、下手すればマイナスになることがわかると思います。それでも、この記事を書いた理由は、日本が誇る漫画やアニメが裏に持つ「ブラックな要素」をディープフェイクの技術で笑顔になる人(スタッフ)が増えればいいなと切に思ったからです。幸せの公式の参考記事:英語、日本語 ↩ -
【cuDNN とは】 NVIDIA 社 が提供している多層ニューラルネットワーク(DNN) 用のライブラリです。同社が開発している GPU の処理性能をグラフィックス以外にも活用できるようにするため開発されたライブラリ CUDA® の一部で、NVIDIA CUDA Deep Neural Network library を略して cuDNN と呼ばれます。NVIDIA 系の GPU やアーキテクチャに最適化されているため依存性が強い(動作する環境を選ぶ)ので結構面倒ですが、動けば強力です。 ↩
-
【FakeApp とは】 Windows 版の Faceswap の単体アプリで、Deepfakes の Faceswap を内包しています。本記事のような依存アプリをさほど気にしなくても動くのが特徴で、Windows であるため豊富な GPU ドライバが使えます。ただし、FakeApp は本記事のような面倒はない反面、マイニングをサラっと仕掛けておいて指摘されるとテヘペロするような作者のアプリであることにもご留意ください。それを知らず「簡単!」と案内するブログが多いのも、この記事を書いたり、記事をアップデートしている理由でもあります。あと、このアプリに同梱されている学習モデルは、実は某俳優を学習させたものです。そのため、学習は早く終わりますが、その結果は、、、わかるね? ↩
-
【HDF5 とは】 データの汎用フォーマットの1種で、大量のデータファイルを扱う目的に使われます。一般的な拡張子は
.h5です。HDFファイルは、Mac の.app(アプリケーションバンドル)のように、大量のファイルを単体のファイルとして扱うのが目的ですが、.appと違い単体のバイナリに変換されています。SQLite3 のデータがイメージに近いかもしれませんが、ファイル・データを高速に取り出すことに特化しており、API を持っている(API が決まっている)ため、機械学習のモデル(学習済みデータ)として多く使われます。(HDF5 の Qiita 記事) ↩ -
【CMake とは】 クロス・プラットフォーム対応のソースを、自身のプラットフォーム用にビルドするのに使われます。本記事では
DlibやOpenCVなどを導入する際に使われます。参考文献:「CMake」@ Wikipedia ↩ -
【OpenCV とは】 Intel が提供している画像処理や画像解析ライブラリ。本記事では顔の輪郭抽出、パターン検出などに使われています。参考文献:「OpenCV」@ Wikipedia ↩
-
【Dlib とは】 Davis King 氏を中心に C++ 言語で書かれたオープンソースのライブラリ/ツール集です。機械学習用途が多いものの、機械学習に限らず、さまざまなライブラリが提供されている。本記事では、主に抽出した顔を入れ替える際の歪みの計算などに使われています。参考文献「機械学習のライブラリ dlib」@ Qiita、「Dlib」@ Wikipedia ↩
-
DB 登録を学習と呼んでいた時代とは、ここでは 1970 〜 1980 年前半ごろの人工知能ブームを指しています。エキスパート・システムと呼ばれる「知識ベースの学習」という考え方が提唱され、流行しました。機械学習自体は 1950 年代からあり、ニューラルネットワークもこのころから存在しています。1980 年代にコンピューターが身近になってきたころ、ニューラルネットワークも
binの2値だったものが実数で受け取れるようになり、「ファジィ」だの「パーセプトロン」だのが流行しました。当時の家電には何でも「ファジィ」が付いていました、現在でいうディープラーニングのような勢いです。このように「機械学習」も時代によって意味も内容も変わっているのも、機械学習と一括りにできない理由でもあります。
● 参考文献:機械学習の歴史 | 機械学習の概要 @ 応用数理第27巻・第4号 P.32-37 ↩