概要
時系列用SOTAなモデルたちを一同に実装したimeseriesai、tsaiを評価した。fastaiの時系列特化版パケージである。
LSTMのようなNNモデルはハイパラ調整で苦労することが多い。そんな中、この非NNなminiROCKETは軽くて調整に苦労することもなさそうだったので少し突っ込んでみた。
そのときの備忘録
- 実施期間: 2022年7月
- 環境:Ubuntu20.04 LTS
- Anaconda: Python3.8.13
- Package: tsai, sktime, sklearnなど
miniROCKET
時系列データのclassificationやregressionを行うモデルはたくさんあり、最新のモデルを簡単に評価できるパケージがtsaiである。(実装済みモデル一覧参照)
最近の週末はこれをちょこちょこ評価していて、感じたことをあげると
良い点
- SOTAなモデルを最小のコード変更で比較可能
- scikit learn互換な書き方もサポート(つまりpipelineやoptunaに組み込める)
- PyTorchで高速GPU演算
イマイチな点
- ドキュメントが完成していない(これが一番痛い)
- multi labelのbugに未対応
- early stoppingは自分で実装(callback()はあり)
- PyTorchが入るため、condaへのinstallにひと癖あり
実装されているモデル中、試していて気になったモデルがinception timeとminiROCKET。
前者はCNNを組み合わせたもので、LSTMよりも圧倒的に少ないepoch数でlossが低下してくれ(LSTMが遅いだけという話もあるが)、accも良さげ。tsaiでもっと評価して、使えそうならKerasで実装する方法も次回以降投稿してみよう。
後者のminiROCKETは、convolution kernelを複数回(10000回とか)当てて、time step次元のデータを圧縮し、featureの次元方向にdatasetを広げているように見えた。この前処理がROCKETの特徴であり、その後は普通のML同様に線形モデルでclassificationする。この線形モデルはpaperではRidgeClassifierCV()が試されている。
miniROCKETのpaperのabstractより(by DeepL)
「Rocketは、ランダムな畳み込みカーネルを用いて入力時系列を変換し、変換された特徴量を用いて線形分類器を学習することにより、既存の多くの手法と比較してわずかな計算量で最先端の時系列分類精度を達成することができます。我々は、Rocketを新しい手法であるMiniRocketに再定式化した。
MiniRocketは、大規模なデータセットにおいてRocketの最大75倍高速で、ほぼ決定論的(オプションで完全決定論的)であり、基本的に同じ精度を維持することができます。この方法を用いると、UCRアーカイブの109個のデータセットのすべてについて、分類器の学習とテストを10分以内に最先端の精度で行うことが可能である。
MiniRocketは、同等の精度を持つ他の手法(Rocketを含む)よりも大幅に高速であり、遠隔的に同様の計算費用を要する他の手法よりも大幅に高精度です。」
0. データ
今回はtsaiのget_UCR_data()関数で取得できるデータを使用する。X.shapeでわかるとおりXは下記の形になっている。
(samples, feature(s), time series)
この形のnumpy.array型にreshapeすると、自分のseries datasetも簡単に使用できた。
1. GPU非対応版(scikit learn friendly)
1-1. Packages
from tsai.basics import *
import sktime
import sklearn
my_setup(sktime, sklearn)
from sklearn.metrics import accuracy_score, mean_squared_error
os : Linux-5.13.0-52-generic-x86_64-with-glibc2.10
python : 3.8.13
tsai : 0.3.1
fastai : 2.6.3
fastcore : 1.4.4
sktime : 0.12.1
sklearn : 1.1.1
torch : 1.10.2
device : 1 gpu (['NVIDIA GeForce RTX 3070'])
cpu cores : 12
RAM : 31.23 GB
GPU memory : [7.79] GB
"import *"はなるべく避けたいところだが、何分ドキュメントが貧相なためチュートリアルのままとした。
1.2. Training
チュートリアル通りにTrainingする。
sktimeのminiROCKETをwrapしているとどこかに書かれていた(気がする)。従いsktimeで実装していないGPUには非対応なのだと。
ただ、miniROCKET自体非常に高速なのでデータ数が少なければCPUでも問題ない。
## sklearn-type API (<10k samples)
from tsai.models.MINIROCKET import *
# Univariate classification with sklearn-type API
dsid = 'OliveOil'
X_train, y_train, X_valid, y_valid = get_UCR_data(dsid) # Download the UCR dataset
# Computes MiniRocket features using the original (non-PyTorch) MiniRocket code.
# It then sends them to a sklearn's RidgeClassifier (linear classifier).
model = MiniRocketClassifier()
timer.start(False)
model.fit(X_train, y_train)
t = timer.stop()
print(f'valid accuracy : {model.score(X_valid, y_valid):.3%} time: {t}')
1.3 Prediction
predictionも可能 下記ではもちろん前述のmodel.scoreと同じスコアとなる。
preds = model.predict(X_valid)
accuracy_score(y_valid, preds)
2. GPU対応版 Classification
チュートリアルではOffline feature calculationとOnline feature calculationの2パターンが掲載されている。
違いは、前者がtraining前にdatasetへ明示的にconvolutionを当ててdatasetをfixさせ、後者がmodel内部でtraining中にconvolutionを当てる。後者のほうがやや遅い(多分fitが)らしいが、将来scaleしやすくコードもやや読みやすいので後者を残す。
2.1 Packages
## Pytorch implementation (any # samples)
from tsai.models.MINIROCKET_Pytorch import *
from tsai.models.utils import *
2.2 Training
まずデータの読み込み。datasetのshapeは下記のようになっている。validation用のX,yは無いが内部ではRidgeClassifierCV()でcloss validationするため指定が無いのだと思う。
であればfold数など指定できてしかるるべきだが何分ドキュメントが…
# Create the MiniRocket features and store them in memory.
dsid = 'LSST'
X, y, splits = get_UCR_data(dsid, split_data=False)
print(X.shape, y.shape)
print(y[:10])
(4925, 6, 36) (4925,)
['6' '6' '6' '6' '6' '6' '6' '6' '6' '6']
tfのようにbatchに分けてモデルに入力するdata loader、get_ts_dls()を使用している。
最適なLearning rateがSuggestedLRsとして表示されている。この値が自動的にfit時に適用されるわけではない。あくまで確認だけ。
## Online feature calculation
# (したければ)lrの確認
tfms = [None, TSClassification()]
batch_tfms = TSStandardize(by_sample=True)
# onlineではmodel内部でconvolutionしてくれるので、そのままXをdata loaderへ入れる
dls = get_ts_dls(X, y, splits=splits, tfms=tfms, batch_tfms=batch_tfms)
model = build_ts_model(MiniRocket, dls=dls)
learn = Learner(dls, model, metrics=accuracy, cbs=ShowGraph())
print(learn.lr_find())
model
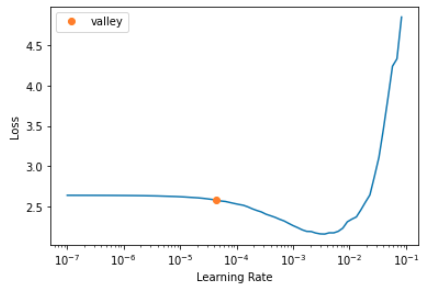
SuggestedLRs(valley=4.365158383734524e-05)
MiniRocket(
(backbone): MiniRocketFeatures()
(head): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): BatchNorm1d(9996, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Linear(in_features=9996, out_features=14, bias=True)
)
)
上記はlrを確認するだけなので、実行しなくてもOK。
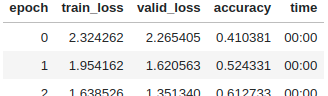
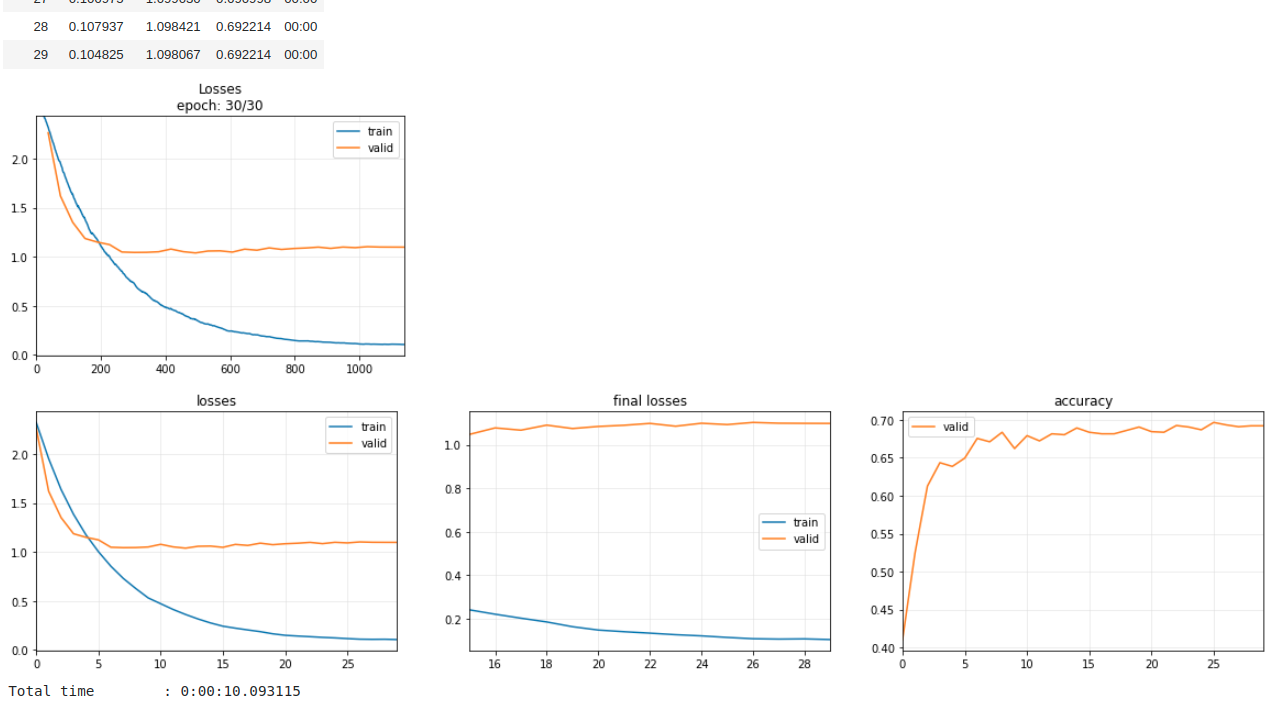
本番のTrainingは下記となる。
コメントアウトしているがdatasetはもはやtime seriesではないためか、なんとData Augmentationが可能!!
確かにAugmentationさせると精度の向上が確認できた。
time series dataではaugmentなど絶対にできないのでちょっと感動した。
# 本番
tfms = [None, TSClassification()]
batch_tfms = TSStandardize(by_sample=True)
# MiniRocket with data augmentation
# batch_tfms = [TSStandardize(by_sample=True), TSMagScale(), TSWindowWarp()]
dls = get_ts_dls(X, y, splits=splits, tfms=tfms, batch_tfms=batch_tfms)
model = build_ts_model(MiniRocket, dls=dls)
learn = Learner(dls, model, metrics=accuracy, cbs=[ShowGraph()])
timer.start()
learn.fit_one_cycle(30, 3e-4)
timer.stop()
2.3. model保存と読込
# model保存
PATH = Path('./models/MiniRocket_aug.pkl')
PATH.parent.mkdir(parents=True, exist_ok=True)
learn.export(PATH)
del learn
# model読込
PATH = Path('./models/MiniRocket_aug.pkl')
learn = load_learner(PATH, cpu=False)
2.4. Prediction
前図のaccuracyチャートとほぼ同じaccを確認できる。
probas, _, preds = learn.get_X_preds(X[splits[1]])
accuracy_score(y[splits[1]], preds)
0.6828872668288727
2.5 その他
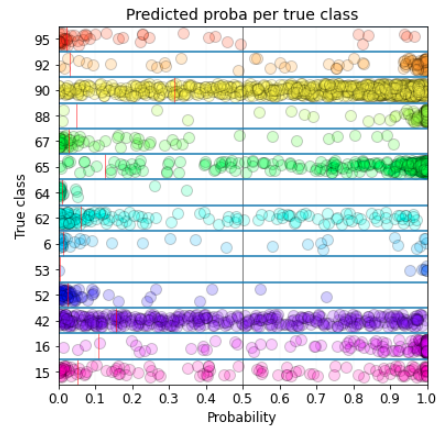
viz用のutilityもあるので表示させてみるが、そもそもacc=6.8って相当悪いので覚悟が必要
各labelについての出力確率をプロットしている。
learn.show_probas()
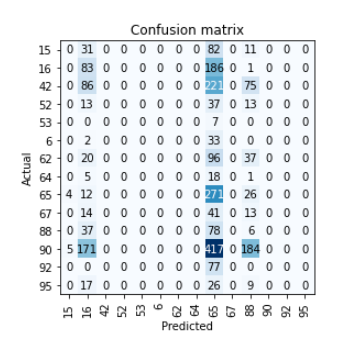
confusion matrixは対角に数字が並ぶものだが、16と65の誤判定が目立つ。
EDAをしていないので、そもそもかなりinbarrancedなdatasetだったことがここでわかった。
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
3. GPU対応版 Regression
チュートリアルはClassificationだけだったので自作。だが大した変更はない。
3.1 Training
Regression用に違うdatdasetの読込と、lrの確認
del learn # 前のモデルが残っていると追加でfitするのであってもなくても消す
dsid = 'AppliancesEnergy'
X, y, splits = get_regression_data(dsid, split_data=False)
print(X.shape, y.shape, y[:10])
> (137, 24, 144) (137,) [19.38 12.68 5.34 12.72 13.25 26.28 13.1 14.06 10.92 10.46]
tfms = [None, [TSRegression()]]
batch_tfms = TSStandardize(by_sample=True, by_var=True)
dls = get_ts_dls(X, y, splits=splits, tfms=tfms, batch_tfms=batch_tfms, bs=128)
model = build_ts_model(MiniRocket, dls=dls)
learn = Learner(dls, model, metrics=[mae, rmse], cbs=ShowGraph()) # InceptionTime
learn.lr_find()
model
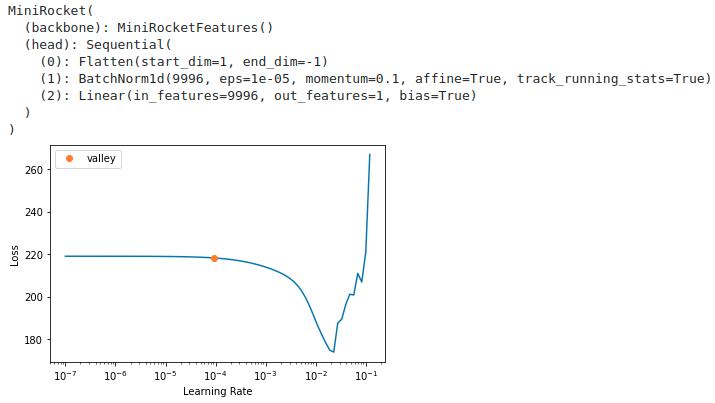
で、Training
learn = ts_learner(dls, model, metrics=[mae, rmse], cbs=ShowGraph())
learn.fit_one_cycle(50, 1e-2)
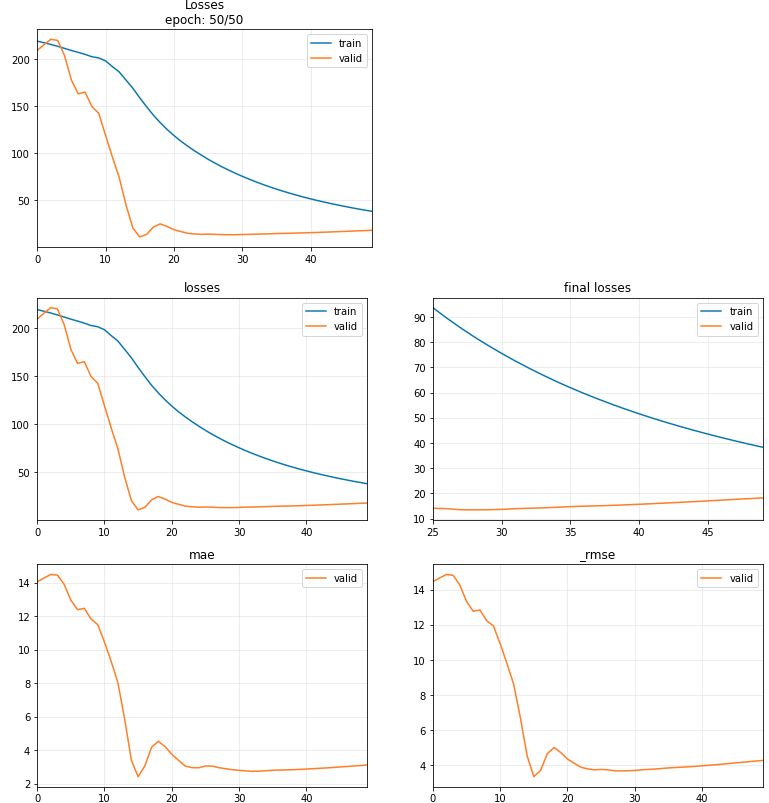
early stoppingの実装が望まれる。
lilacsさんにfastaiのearly stoppingが使用できることを教えていただいた。
ありがとうございます!
上記最後のセルについて下記を実行すると、early stoppingする。
learn = ts_learner(dls, model, metrics=[mae, rmse], cbs=ShowGraph())
learn.fit_one_cycle(100, 1e-2,
cbs=[EarlyStoppingCallback(monitor='valid_loss', min_delta=0.001, patience=20)])
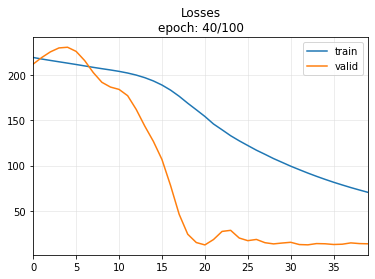
No improvement since epoch 20: early stopping
3.2 Prediction
probas, _, preds = learn.get_X_preds(X[splits[1]])
mean_squared_error(y[splits[1]], preds, squared=False)
4.265168326494313
4. Convolutionを当てると…
前出の通りOff-lineでは明示的にConvolutionを当てる。shapeがどのように変わるか確認できる。
dsid = 'LSST'
X, y, splits = get_UCR_data(dsid, split_data=False)
print(X.shape)
# convolution kernelを当てると、
mrf = MiniRocketFeatures(X.shape[1], X.shape[2]).to(default_device())
X_train = X[splits[0]]
mrf.fit(X_train)
X_feat = get_minirocket_features(X, mrf, chunksize=1024, to_np=True)
print(X_feat.shape)
(4925, 6, 36)
(4925, 9996, 1)
36 time stepの元データが1個になり、6 featuresが10000個近いfeaturesに広がっている。
CNNやってる人にとっては当たり前のことだけど、正直この部分だけでもかなりワクワクしてしまう。
5. 手元のデータでお試し
下記のデータを使用する。
5.1 Data Preparation
GPUを使用しない方のモデルを使用する。
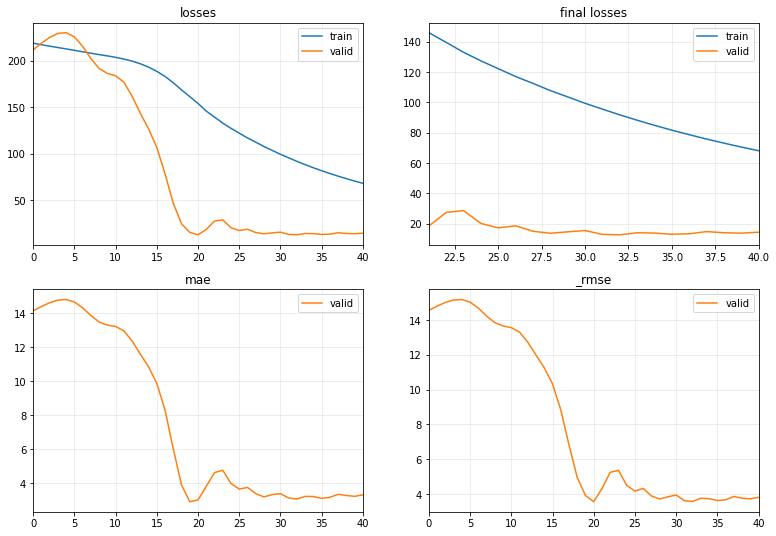
GPU版で試したが下図のようにLossの挙動が変だったので、途中からこのCPU版に切り替えた。
splitsタプルでTrainとvalのそれぞれに使用するsampleのindexを指定したりもしなければならず面倒だったし…
データ量が大きくなればGPU版が有効なのかもしれない。
import datetime
from datetime import datetime as dt
import statistics
import matplotlib.pyplot as plt
from tsai.models.MINIROCKET import *
intOpen = 0
intHigh = 1
intLow = 2
intClose = 3
df_raw = pd.read_csv('data/all_stocks_2006-01-01_to_2018-01-01.csv')
clm_lst = list(df_raw.columns)
print(clm_lst)
comp_name_lst = list(df_raw['Name'].unique())
print(comp_name_lst)
['Date', 'Open', 'High', 'Low', 'Close', 'Volume', 'Name']
['MMM', 'AXP', 'AAPL', 'BA', 'CAT', 'CVX', 'CSCO', 'KO', 'DIS', 'XOM', 'GE', 'GS', 'HD', 'IBM', 'INTC', 'JNJ', 'JPM', 'MCD', 'MRK', 'MSFT', 'NKE', 'PFE', 'PG', 'TRV', 'UTX', 'UNH', 'VZ', 'WMT', 'GOOGL', 'AMZN', 'AABA']
月曜から金曜の行にする。元データになければ-1.0とする(あとで内挿する)。
start_str = '2006-01-03'
start_date = dt.strptime(start_str, '%Y-%m-%d')
end_str = '2017-12-31'
end_date = dt.strptime(end_str, '%Y-%m-%d')
td = datetime.timedelta(days=1)
lst = [start_date.date()]
wk_date = start_date
for d in range((end_date - start_date).days):
wk_date = wk_date + td
if (wk_date.isoweekday() >= 1) & (wk_date.isoweekday() <= 5): # 月曜から金曜 pythonのisoweekdayとPandasのdt.weekdayは違う
lst.append(wk_date)
df_0 = pd.DataFrame(lst, columns=['Date'])
df_0['Weekday'] = df_0['Date'].dt.weekday
df_0.set_index('Date', inplace=True)
df_wk = pd.DataFrame(data = df_raw[df_raw['Name'] == comp_name_lst[0]][clm_lst[:-1]]) # 'MMM'
df_wk['Date'] = pd.to_datetime(df_wk['Date'])
df_wk.set_index('Date', inplace=True)
df_wk = pd.merge(df_0, df_wk, how='outer', left_index=True, right_index=True)
df_wk = df_wk.fillna(-1.0) # merge()でnanになる要素を-1.0に置き換え(.loc[]でnanの指定方法がわからなかったから)
内挿(前後の平均)処理 連休中は同じ値とする(「途中」で対応)。
date_idx = list(df_wk.index)
nan_flag = False
date_lst1 = []
date_lst = []
date_all_lst = []
open_lst = []
high_lst = []
low_lst = []
close_lst = []
volume_lst = []
for i in range(len(date_idx)):
if (df_wk.loc[date_idx[i], 'Open']==-1.0) & (nan_flag==False): # 始まり
date_lst1.append(date_idx[i])
open_lst.append(df_wk.loc[date_idx[i-1], 'Open'])
high_lst.append(df_wk.loc[date_idx[i-1], 'High'])
low_lst.append(df_wk.loc[date_idx[i-1], 'Low'])
close_lst.append(df_wk.loc[date_idx[i-1], 'Close'])
volume_lst.append(df_wk.loc[date_idx[i-1], 'Volume'])
nan_flag = True
elif (df_wk.loc[date_idx[i], 'Open']==-1.0) & (nan_flag==True): # 途中
date_lst1.append(date_idx[i])
print(date_lst1)
elif nan_flag==True: # 終わり
open_lst.append(df_wk.loc[date_idx[i], 'Open'])
high_lst.append(df_wk.loc[date_idx[i], 'High'])
low_lst.append(df_wk.loc[date_idx[i], 'Low'])
close_lst.append(df_wk.loc[date_idx[i], 'Close'])
volume_lst.append(df_wk.loc[date_idx[i], 'Volume'])
date_lst.append(date_lst1)
date_lst.append((round(statistics.mean(open_lst),3),
round(statistics.mean(high_lst),3),
round(statistics.mean(low_lst),3),
round(statistics.mean(close_lst),3),
round(statistics.mean(volume_lst),3)))
date_all_lst.append(date_lst)
nan_flag = False
date_lst1 = []
date_lst = []
open_lst = []
high_lst = []
low_lst = []
close_lst = []
volume_lst = []
内挿済み全データを一旦df_wkとする。
for l1 in date_all_lst:
for l2 in l1[0]:
df_wk.loc[l2, ['Open', 'High', 'Low', 'Close', 'Volume']] =
[l1[-1][0], l1[-1][1], l1[-1][2], l1[-1][3], l1[-1][4]]
モデルに使用するdatasetの作成
df_cp = df_wk[['Weekday', 'Open', 'High', 'Low', 'Close']].copy() # 説明変数の指定('Weekday'は必須)
append_lst = []
wday_prv = 0 # 生データが1始まりだから
for row in df_cp.itertuples():
wday_now = row.Weekday
now = (wday_prv, wday_now)
append_lst.append(tuple(row)[1:]) # Weekdayは入れない
wday_prv = wday_now
row_prv = row
sample_num = len(append_lst)
モデルの入力データ型にreshapeし、train&val(CV)とtestにデータをスプリット
lst = []
ts_len = 12 # 3次元目のtime series長 唯一のハイパラ
fst_flag = True
for i in range(sample_num-ts_len):
lst = []
for j in range(ts_len):
lst.append(list(append_lst[i: i+ts_len][j][1:])) # overlapあり
# lst.append(list(append_lst[i*ts_len: (i+1)*ts_len][j][1:])) # overlapなし
wk_arr = np.array(lst).T
wk_arr = wk_arr[np.newaxis, :, :]
if fst_flag == True:
data_arr = wk_arr
fst_flag = False
else:
data_arr = np.concatenate([data_arr, wk_arr])
X = data_arr[:2800]
print(X.shape)
X_test = data_arr[2800+ts_len:-1] # +ts_len:leakage対策, -1:tgtが1time step先だから最後は使えない
print(X_test.shape)
tgt_lst = [data_arr[i+1][intOpen][-1] for i in range(len(append_lst) - ts_len - 1)]
tgt_arr = np.array(tgt_lst)
y = tgt_arr[:2800]
print(y.shape)
y_test = tgt_arr[2800+ts_len:]
print(y_test.shape)
# GPU版API用
train_idx = [i for i in range(0, 2000)]
val_idx = [i for i in range(2000, 2800)]
splits = (train_idx, val_idx)
## CPU版
model = MiniRocketRegressor(random_state=47)
model.fit(X, y)
preds = model.predict(X_test)
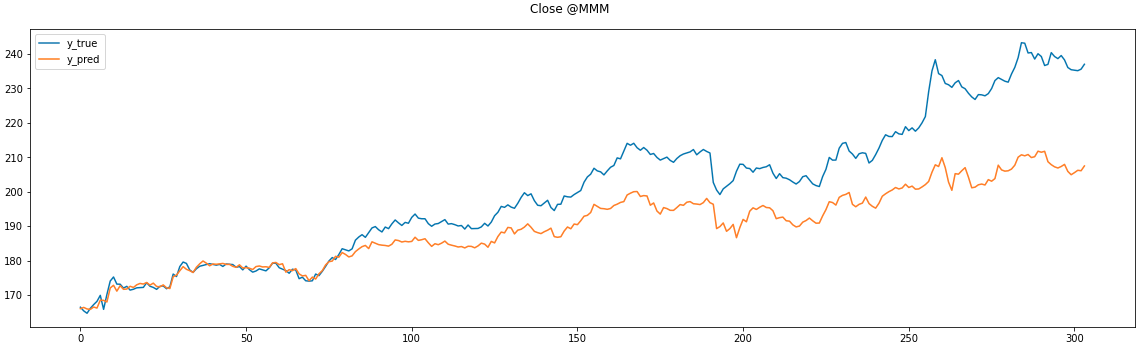
print('MSE: {0:.3f} , R^2: {1:.3f}'.
format(mean_squared_error(y_test, preds, squared=False), r2_score(y_test, preds)))
fig, ax = plt.subplots(figsize=(16,5), tight_layout=True)
plt.suptitle('Close @' + comp_name_lst[0])
ax.plot(y_test[:], label='y_true')
ax.plot(preds[:], label='y_pred')
ax.legend()
plt.show()
全test datasetについてはこんな感じ
※図のタイトルはCloseではなく、Openの間違い
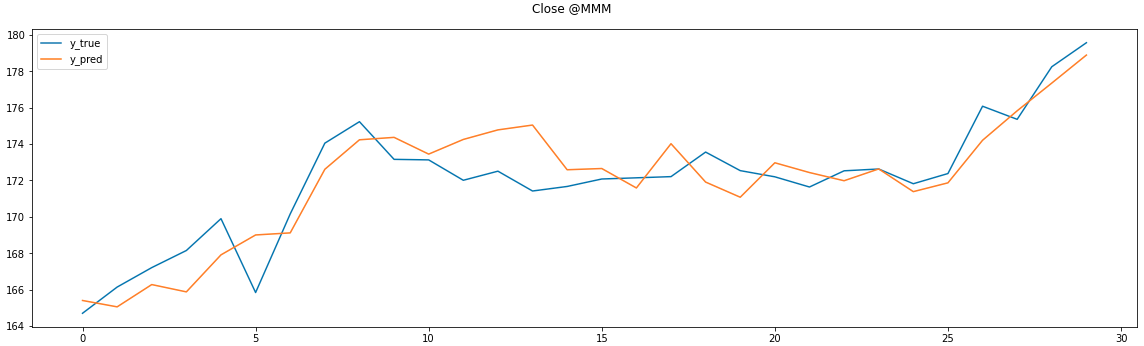
直近30日分はこう 傾向はつかめているがラグがあり致命的
参考まで続く2銘柄 これらも上図と同じ傾向
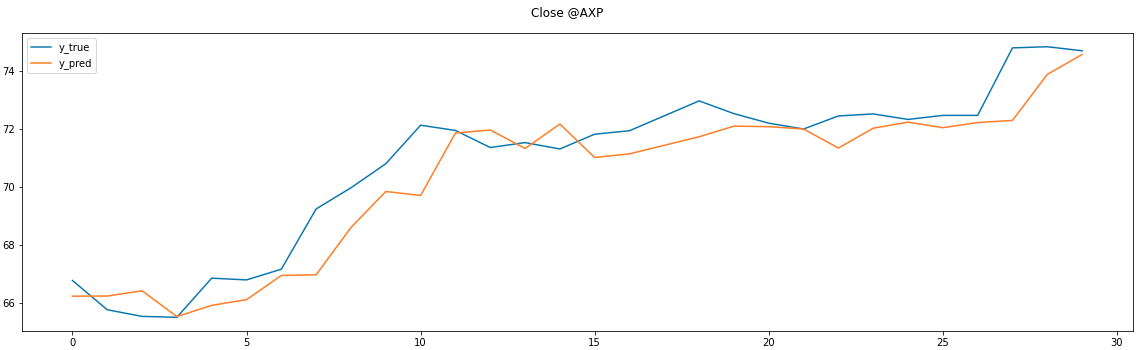
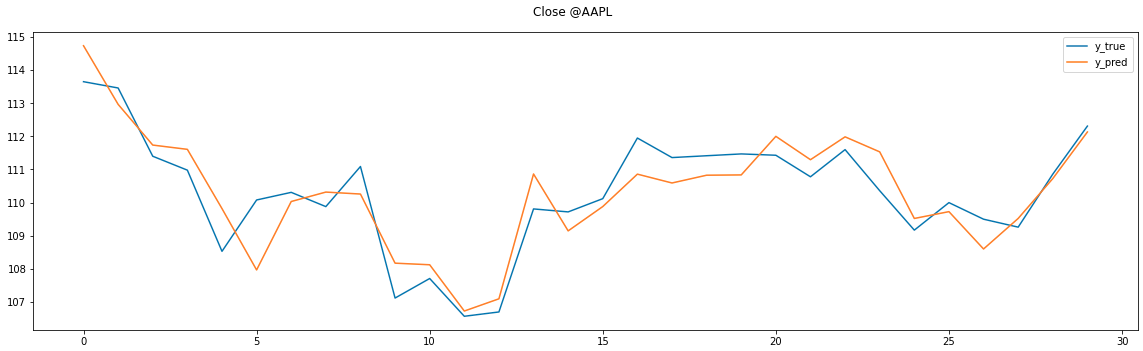
説明変数にはお試しなので安直にOpen,High,Low,Closeを入れただけだが、工夫をすればレスポンスは良くなる可能性あり。
以上