IQ Botの大きな特長のひとつは、帳票をフォーマットごとに自動分類してくれる点です。
この自動分類は、AIの教師なし学習のアルゴリズムで行われていて、人間が手動で分類を指定したり、変更したりすることはできません。
慣れるまでは、なかなか分類が意図どおりにいかない場合があるかもしれません。
この記事では、IQ Botの分類の仕組みに触れながら、分類がうまくいかない場合に確認するべきポイントを確認します。
IQ Botが帳票を分類する仕組み
IQ Botの内部仕様やソースコードは公開されていないのですが、帳票の分類を教師なし学習というAIの仕組みで行っていることは公開されています。
分類はインスタンス作成時に入力したフォームフィールド/テーブルフィールドの項目と、その項目の帳票上の分布に応じて行われます。
分類がうまくいかない場合
「分類がうまくいかない場合」とは、以下のようなケースを想定しています。
- Groupが「Unclassified」になってしまう場合
- 分類の結果が意図どおりにいかない場合
- 同じように見えるフォーマットが違うグループに分類されてしまう
- 違うフォーマットが同じグループに分類されてしまう
いずれの場合も、原因を端的に言えば「IQ Botが分類に必要な項目を正しく認識できていない」という一点に集約されます。
ただ、「何が原因でIQ Botが分類に必要な項目を認識できないのか」という観点でいくつかの原因に分かれ、それによって対処も異なるので、以下で整理してみます。
分類が意図通りにならない原因とその対処
原因①:分類に必要な数の項目を定義できていない
例えば以下の帳票①と帳票②は、全体を見ると全然違うフォーマットに見えますが、「お客様コード」と「お客様名」だけを抽出するフィールドに指定して分類をかけると、同じグループとして認識されます。
なぜならこの2項目だけを見比べてみると、分布の類似性が非常に高いからです。
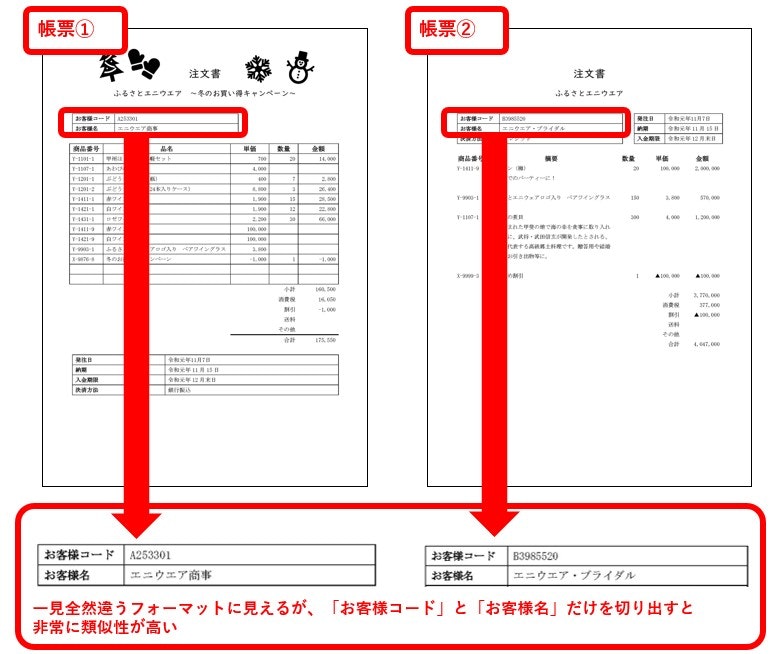
IQ Botは「最初にインスタンスを作成する際に定義した項目の分布」をベースに帳票を分類します。
言い換えれば、最初にインスタンスを作成する際に定義していなかった項目は、いくら帳票上にあっても分類の根拠として使われません。
このような原因で分類がうまくいっていない場合は、定義項目を増やすという対処が考えられます。
なお、補足として以下を書いておきます。
ちょっと難しいかもしれないので、後日もう少しわかりやすく整理して別の記事に切り出したいと思います。
-
ドメインを「その他」にして抽出項目を手動で定義した場合
- 抽出項目としてインスタンス作成時に設定した項目が分類の根拠に使われます
- 一度インスタンスを作成した後で、編集画面で後から追加した項目は、分類の根拠としては使われません
-
カスタムドメインを使用した場合
- 抽出項目としてチェックした項目も、チェックを外した項目も、分類の根拠として使われます
- つまり抽出は不要な項目でも、分類の根拠に使うことができるので、カスタムドメインがオススメな理由のひとつ
- カスタムドメインを上書きすることで後から項目を追加することができますが、インスタンス作成時に存在しなかった項目が分類の根拠に使われることはありません(これはわかりづらいですね。今後補足します)
- 抽出項目としてチェックした項目も、チェックを外した項目も、分類の根拠として使われます
原因②:定義した項目名が帳票上のラベルとヒットしていない
IQ Bot が帳票からラベルを取得する条件は、**「定義した項目に対して、帳票上のラベルが前方一致していること」**です。
いくつか具体例を挙げてみます。
| 定義した項目名 | 帳票上のラベル | 取得可否 | 備考 |
|---|---|---|---|
| 金額 | 金額 | 〇 | 完全一致なので取得可能 |
| 合計 | 合計金額 | 〇 | 前方一致なので取得可能 |
| 合計金額 | 金額 | × | 前方一致していないので取得不可 |
| 請求金額 | 合計金額 | × | 前方一致していないので取得不可 |
| 合計金額 | 請求金額 | × | 前方一致していないので取得不可 |
上記のように、定義した項目名と帳票上のラベルがズレていることにより、IQ Botによる項目の取得が空振りし、結果的に原因①と同じ現象が起こっていることが考えられます。
特に日本語の帳票では、ラベルが均等割り付けの書式(例:「品名」というラベルで、「品」と「名」の間がすごく空いている)となっている例が多いです。均等割り付けのラベルの場合、SIRは「品」1文字で1つ、「名」1文字で1つ、という形で形成されがちなので、ラベルを「品名」としてしまうと取得ができません。
こうした事象への対応は、以下が考えられます。
対処②-1:ラベル後方の文字数を減らす
IQ Botが前方一致でラベルを検知する性質を使って、ラベル後方の文字列を減らすことで検知する方法です。
詳細は以下のリンクを参考にしてください。
対処②-2:カスタムドメインを使用する
カスタムドメインを使用し、取得できるラベルの文字列を複数定義しておくことで、分類をうまくいかせやすくする方法です。
カスタムドメインが何かの説明については、以下のリンクを参考にしてください。
【リンク】IQ Bot:カスタムドメインとは
カスタムドメインの作り方は、以下のリンクを参考にしてください。
【リンク】IQ Bot:カスタムドメインの作り方
原因③:画質が粗い
画質の粗さゆえにOCRが文字を文字として認識できなかったり、誤読することによって、結果的に原因①や②と同じ現象が起こっている場合もあります。
こうした場合は、以下の対処が考えられます。
対処③-1:スキャンの解像度を上げる
特にOCRがABBYYの場合、精度は解像度に大きく依存します。ABBYYで読み取りを行う場合は、スキャナの解像度を高く(300dpi以上)設定しておくことが精度を上げる最大のポイントです。
ただし、スキャンする時点で既に何度もFAXやコピーを繰り返してきた紙の場合、スキャナで解像度を上げてもどうしようもない場合もあります。。。
対処③-2:低解像度に強いOCRを使用する
低解像度に強いOCRは、GoogleとTegakiです。
ただしGoogleはインターネット経由で帳票を投げる必要あり/Tegakiは逆にオンプレのみなど、それぞれに癖があります。
以下の記事を読み、ユースケースに合ったOCRがあれば、そちらを使ってみるのも手です。
【リンク】IQ Bot:OCR選定のコツ
原因④:OCRの切り替えがうまくできていない
上記③に似ていますが、意図しないOCRを設定してしまっていることで、OCRの結果が思わしく出ず、分類がうまくいかなくなっている可能性もあります。
以下の記事を参考に、意図したOCRを選択できているかを確認してみてください。
https://qiita.com/IQ_Bocchi/items/11c7a7640d6d0cc1054f
分類不能(Unclassified)になる原因
これまでは、分類が意図しない結果になる原因を説明してきましたが、IQ Botにはさらに「分類不能(Unclassified)」という概念があります。
分類不能(Unclassified)になる原因は非常にシンプルで、端的に言えば「分類に必要な数の項目をIQ Botが帳票から取得できなかったから」という一点に集約できます。
これまでに説明してきた原因①~④が、「分類に必要な項目を取得できない」=分類不能(Unclassified)になる原因にもなります。
ですので、対処については上記の記事を見ていただくとして、ここではIQ Botが分類を行うのに必要な項目の数について説明します。
IQ Botが帳票を分類するのに必要な項目数
IQ Botが帳票を分類するのに必要な項目は、インスタンスを作成する際に選択したドメインの種類によって変わります。
| ドメインの種類 | 分類に必要な項目数 |
|---|---|
| ドメイン「その他」を選択し手動で項目を定義した場合 | 1 |
| プリセットドメイン カスタムドメイン |
定義項目が4つ以下の場合は4つ以上 定義項目が5つの場合は5つ 定義項目が6つの場合は6つ 定義項目が7つの場合は7つ |
「その他」のドメインで項目を手動定義した場合は、最低1つの項目を取得できれば分類できるのですが、カスタムドメインを使った場合は、分類に必要な項目が増えます。
「分類をうまくいかせようとしてカスタムドメインを作ったのに、今度はUnclassifiedになってしまった! なぜ?」という場合は、大抵これが原因です。
カスタムドメインの場合、抽出対象としてチェックしていない項目であっても、ドメインの定義に含まれてさえいれば、分類の根拠として使用することができます。
したがって、カスタムドメインを作成する場合は、項目を手動で定義する場合以上に、分類の根拠となり得る項目を多く定義しておくのがコツです。
まとめ
- 分類がうまくいかない原因は、「項目数が分類に必要な数に達していないこと」に集約されます
- 上記は画質の粗さや、定義項目と帳票上のラベルの名称のズレによっても起こりえます
- 対処方法には以下があります
- OCRの設定を確認する
- 項目数を増やす
- 項目の名称を帳票上のラベルに合わせる
- カスタムドメインを作成する
- 画質を上げる