IQ Botは様々なOCRエンジンをインスタンスごとに切り替えて使用することができます。
OCRエンジンの切替方法は以下の記事で案内していますが、それぞれのOCRにはどのような特徴があるのでしょうか?
【リンク】IQ Bot:OCRエンジンの切り替え
ということで、各OCRの特徴を一覧にしてみましたので、選定時の参考にしてみてください。
IQ Botで使えるOCRの選択肢(2021年1月27日現在)
記事公開日時点で使用できるIQ BotのOCRには、以下の選択肢があります。
|OCRエンジン|特徴|
|:-----------------|:------------------|:------------------|
|Tessaract4|完全オンプレに対応・クラウド版でも使用可能
日本語の精度は低い(英数字用)
手書きは未対応|
|ABBYY (オススメ)|完全オンプレに対応・クラウド版でも使用可能
日本語の活字に対応
手書きには未対応|
|Microsoft Computer Vision|オンプレ・クラウド版ともに使用可能だが、オンプレ版で使用する際もインターネット接続が必須
英数字の手書きに対応
日本語の精度は低い
単独の文字の抽出に弱い|
|Google Vision (オススメ)|オンプレ・クラウド版ともに使用可能だが、オンプレ版で使用する際もインターネット接続が必須
日本語の活字・手書きに対応
手書きの精度はTegakiには劣るが、インフラを軽くしたい人にはオススメ
文脈を認識し確度の高い結果を抽出1単独の文字の抽出に弱い ← 最近かなり改善された(しかし完璧ではない)|
|Tegaki (超オススメ)|オンプレ必須
※CR,IQ Bot,Tegakiともにオンプレで構える必要あり(IaasはOK)
手書きの他、低画質の帳票の活字もかなり読める
単独の文字の検出は完璧ではない(Google Visionよりはかなりましだが完璧ではない)
|
※ バージョンによって利用できないOCRもあります。
2020年前半頃までは「実質ABBYY一択」だったが、Google Visionの精度が徐々に向上
この記事を最初に執筆したのは2020年5月末頃だったのですが、その当時はこんなこと↓を書いていました。
こんなこと
上記のとおり、さまざまなOCRの選択肢がありますが、筆者がこれまで約1年間IQ Bot案件に携わってきた経験上、実質的にはABBYY一択と言っていいと思います。
上記の表に挙げた特徴と対応しているバージョンを合わせ、OCR選定のフローを図に示したのが以下です。
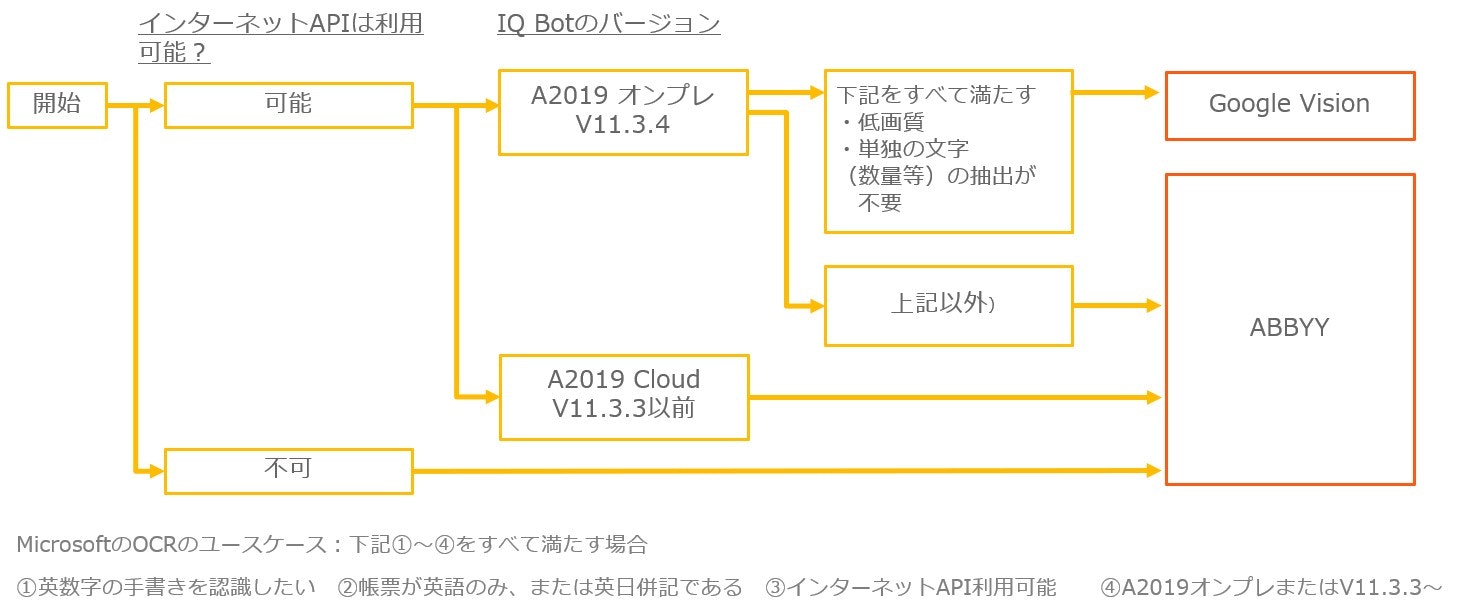
オンプレ対応が可能である点、対応しているバージョンの幅が広い点、単独の文字も含めバランスよく識字が可能である点などから、これまで筆者が実施してきたIQ Bot案件ではOCRはほぼABBYY一択の状態でした。
ABBYYは低画質の帳票(200dpi以下)になると精度が著しく下がるので、帳票の画質を上げる対策とセットで利用した方がいいです。
日本語の手書きを正式サポートしている新しいエンジンが入ってくれば状況は変わると思いますので、その際はまた記事を更新します。
ところが、最近になってGoogle側の「単独の文字をミスる問題」がかなり改善され、IQ Botで読み取る際に重要になる位置の識別なども安定してきたことから、今(2020年7月末現在)となってはインターネット利用さえOKなら、Googleはかなりオススメといえるクオリティになってきました。
一概にGoogleがABBYYより優れていると言えるわけではなく、帳票による向き不向きもあります。
ABBYYだと処理できない帳票がGoogleだと処理できたり、逆もまたしかりです。
インターネット利用が可能な場合は、両方を比べてみて結果の良かった方を採用すると良いと思います。
(インターネット不可の場合は、依然としてABBYY一択)
ABBYYとGoogleそれぞれで処理をかけて結果を突合し、不一致があった場合のみ人間が検証、といったフローの構築も現実味を帯びてきました。
Googleはクラウドサービスであるため、IQ Botのバージョンに関わらず、Google側のアップデートは常に反映されます。
2021年2月、待望のTegakiがリリース!
2021年2月からは、IQ BotのOCRの選択肢としてTegakiが使えるようになります。
テスト版はすでにリリースされていますが、精度が高くて非常にオススメです。
※「精度が高い」という言い方は本当はあまりしたくないです。詳細はこちら参照。
ただし、クラウド推しのAutomation Anywhereにしては少し意外な「オンプレ限定」の制約があるため、精度のためにインフラに投資できるかという部分がTegaki利用可否の鍵になると思います。
Tegakiと接続するためにはSettingファイルをいじる必要があるため、CR/IQ Botもオンプレで構える必要があります。
今後、Tegakiもクラウドで利用できるようになればよいのですが、まだ明確なロードマップはないようです。
-
例えば「ABC株式会社」と帳票に書いてあった場合に、「株式会社」の「株」の文字がつぶれて印刷されていたとしても、「式会社」の前に来る文字は「株」しかないだろう、というような感じで文脈から正解を推測してくれます。したがって、Googleは単体の文字を認識させたときと、ある程度の長さのある言葉や文の中で文字を認識させたときとで精度が変わります(後者の方が高い)。また、文字単体としてはまったく形の同じ画像を文脈上のどこに置くかによって読み取り結果が変わるという挙動も見られます。たとえば、縦の線を「● am Japanese」の●の位置に置くとI(大文字のアイ)、●2345の●の位置に置くと「1」(数字のイチ)、「●ove」の●の位置に置くとl(小文字のエル)、と読むなどです。 ↩