IQ Botの研修は基本的に、OCR側がラベルや値をきれいにとれたケースを前提に進みます。
ですが、現場で実際に帳票を扱ってみると、OCRが期待したとおりに文字を読み取ってくれるとは限りません。
IQ Botは座標指定型と違い、マッピング設定の画面からOCRをかけ直すことはできません。
(自動検出型なので、OCRをかけ直す意味がない)
※座標指定型/自動検出型の違いについては、以下の動画を参照してください。
ただ、OCRが誤読したらIQ Bot側では手の打ちようがないのかというと、打ちようはあります。
この記事では、OCRの誤読に対する対処方法を見ていきます。
誤読のパターン別 対応方法
誤読に対する対応方法は、誤読が発生する箇所がラベルなのか、値なのかによって変わります。
ラベルと値については、以下の記事を参照してください。
ラべルも値も関係なく、帳票全体が誤読だらけという場合は、そもそも帳票がOCRの想定する品質/ユースケースに適合していない可能性があります。
以下は、「全体的にはだいたい上手に読めているけれども、一部誤読してしまう項目がある」という前提で、ラベル/値ごとに対処方法を見ていきます。
ラベルの誤読が発生する場合
ラベルの誤読が発生する場合には以下の3種類の対処があります。
結論から言うと、一番万能な対処となるのは③ですが、一応①と②も紹介しておきます。
① 誤読のパターンをパイプ区切りで登録する
ラベルの誤読のパターンがある程度予測できるとは、たとえば「数量」というラベルを一定の割合で「類量」と読んでしまうケースがあるが、それ以外の誤読のしかたはしない、というようなパターンです。
そのような場合は、以下の要領でラベルの別名を登録していく方法がとれます。
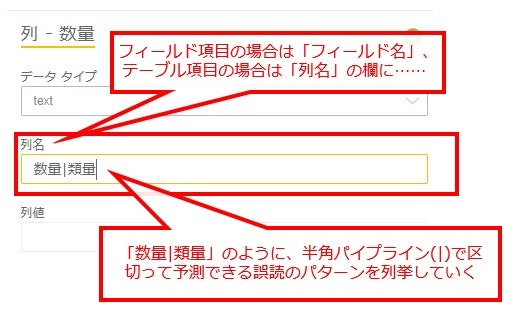
パイプラインで区切られたラベル名に、正規表現を使うことはできません。
なので、このやりかたが使えるケースは非常に限定的です。
② ラベル後方の文字数を減らす
IQ Botが帳票からラベルを検知する方法は、前方一致です。
この仕組みを使って、以下のようにラベル後方の文字数を減らすことで、検出確率を上げることができます。
| 登録したラベルの文字列 | 帳票上の文字列(OCRの結果) | 検出結果 |
|---|---|---|
| 数量 | 数量 | ○ 一致しているので検出可能 |
| 数量 | 数● (「量」を誤読) |
✖ ラベルの検索要素には「数量」と登録されている → IQ Botは帳票から「数量」を前方一致で探しに行く → 「数●」は「数量」とは一致しないのでヒットせず → ラベルは検出できない |
| 数 | 数● (「量」を誤読) |
○ ラベルの検索要素には「数」と登録されている → IQ Botは帳票から「数」を前方一致で探しに行く → 「数●」は「数」と前方一致するのでヒットする → ラベルが検出できる |
上記の仕組みを使って、例えば「電話番号:」というラベルから「:」を除外しておくなど、ラベル後方にある認識が不安定な要素をあらかじめ除外しておくと、ラベルが検出しやすくなります。
ただし、お気づきのように、このやりかたはラベル後方の文字列を誤読する場合にしか使えません。
ラベル前方の文字列を誤読してしまう場合(「数量」における「数」を誤読してしまう場合)には使えません。
③ 仮のラベルを指定する
ラベルの誤読のパターンが予測できない場合は、仮のラベルを指定するか、項目を固定座標的に取得する方法が考えられます。
いずれの方法も、以下の記事にやりかたが載っていますので参考にしてみてください。
値の誤読が発生する場合
値の誤読のパターンが決まっている場合
以下のように、誤読のパターンが決まっている場合はシンプルなカスタムロジックで対応できます。
カスタムロジックのやりかたは、それぞれのリンク先に載っています。
▼決まった文字が決まった形に文字化けする場合(都道府県欄の「東京」を必ず「棘」と読んでしまうなど)▼
▼数値項目しか入らない項目に、数値以外のノイズが入る(紙の汚れを記号として読み込んでしまう等)▼
▼印影の重なった社名など、文字列の一部が正しく読める場合▼
値の誤読のパターンが決まっていない場合
値の誤読のパターンが決まっていない場合は、無理に置き換えて正しい値を自動算出しようとせず、誤りを検知して人間の検証に回す方法を考えます。
IQ Botにおける誤りの検知については、以下の記事を参照してください。