Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.0
/_/
2016年7月末にApache Spark 2.0.0がリリースされ、始めてみたので色々メモ
メモなのでご容赦ください🙇
また、この記事中にサンプルで載せているコードはjavaがメインですがscala、pythonの方がすっきりかけている気がじます。
これからも随時編集していきます
Apache Spark とは
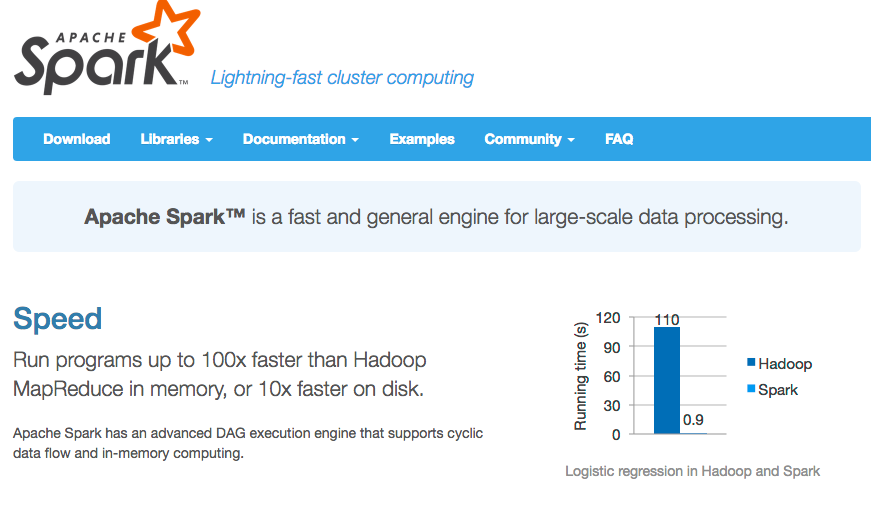
上の画像はhttps://spark.apache.orgから、場合によっては
HadoopのMapReduce100倍速いらしいです、強い、Spark
Sparkは巨大なデータに対して高速に分散処理を行うオープンソースのフレームワーク。
(Java MagazineにはSparkは高速でスケーラブルな汎用分散処理エンジンと書いてました)
重要なのは以下のポイントだと思いました(いろんなサイトやドキュメントを読んでいて)
以下の点についての詳細は後述します。
1. RDD(Resilient Distributed Datasets)の仕組み
2. Scala、Java、R、Pythonなどに対応(APIが用意されてる)
3. 多彩なライブラリ
4. 複数の導入シナリオ(スタンドアロン、YARN、Mesos、組み込み、クラウド)
5. 幅広い処理モデル(バッチ、インタラクティブ、ストリーミング)
ちなみに日経BP社が発表した「ITインフラテクノロジーAWARD 2015」において、
SparkはDockerに次ぐ準グランプリとされた。
SparkもHadoopと同じく分散処理のフレームワークです(厳密には担当してるところがちょっと違う)。Sparkはカリフォルニア大学バークレー校で開発が開始され、2014年にApache Software Foundationに寄贈されました。HadoopがJava言語で作られているのに対してSparkはScalaで作られています。
Sparkの得意不得意
得意
- Hadoopで加工したのちのドリルダウン分析
- TB級までのデータを扱うシステム
- サンプリングが有効でないロングテールのデータ分析
- 数秒~数分程度のHadoopよりも短いレスポンスが必要な処理
不得意
- クラスタ全体のメモリに乗りきらない巨大なデータ処理(TB以上)
- 大きなデータセットを少しずつ更新する処理
- 秒以下の時に短いレスポンスが必要な処理
Hadoopとの違い
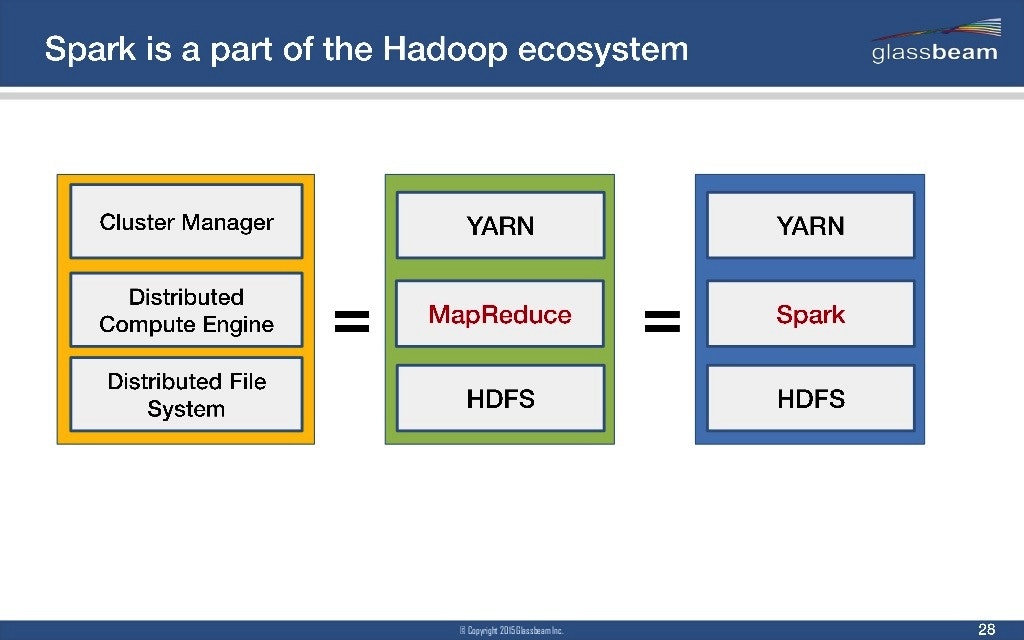
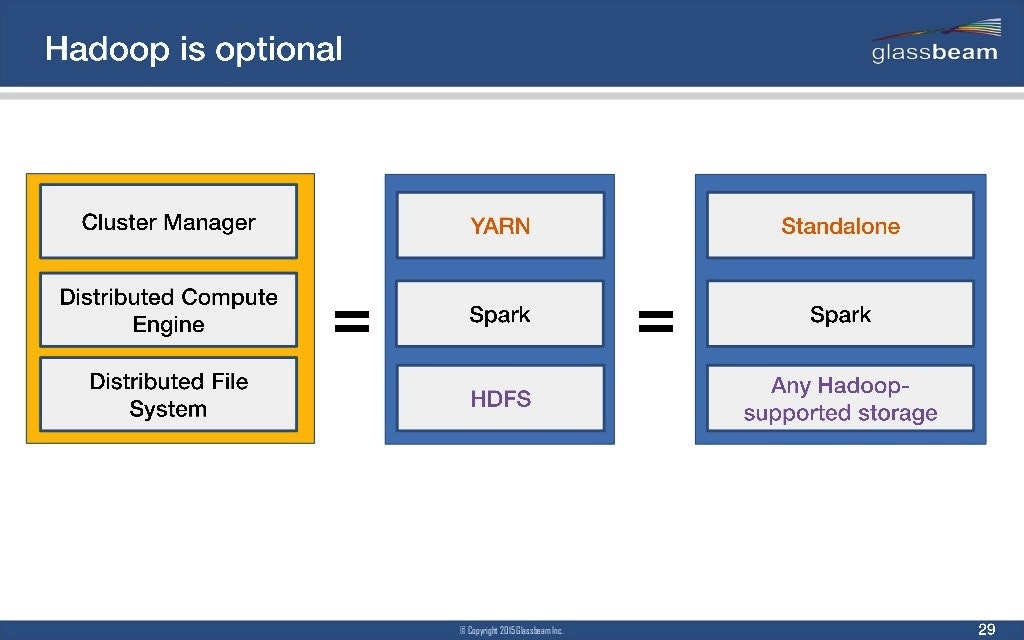
同じ分散処理のフレームワークとして、Hadoopが有名です。両者は以下の図(http://www.aerospike.com/blog/what-the-spark-introduction/ より引用)のように、そのまま比べられるものではない?ですが、あえてSparkがHadoopのどこにあたるかというと、MapReduceの部分のようです。
 |
 |
|---|
Hadoop自体とても便利ですが欠点もありました。その色々な欠点を解決?しようとしているのがSparkのようです。
Hadoopの欠点と言われていたのが主に以下の三つ
- 個々のメモリを活用できる設計でなかった(タスクごとにデータをディスク読み込み&書き込みしなきゃいけないのがボトルネック)
- 同じ処理を複数行う際に、その都度データアクセスが発生
- 同じデータでもなんども使うものは使う際に無駄にアクセスがいっぱい発生
この課題を解決するのがRDD(Resilient Distributed Datasets)というSparkの分散共有メモリの仕組みです。
すごくざっくり言うと、Hadoopでは毎回ストレージにアクセスしたりしていたのがインメモリで実行できるのでいいこといっぱいあるよねって感じだと解釈しました。
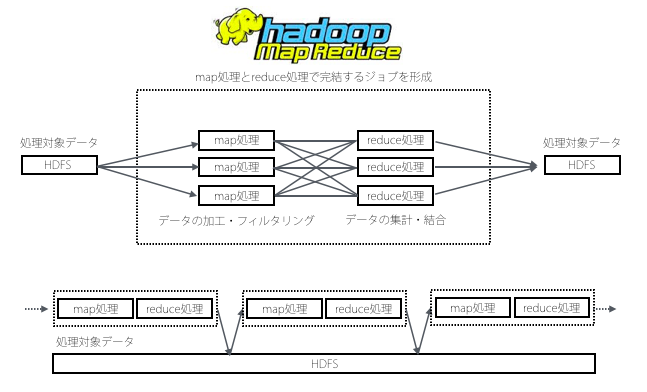
Hadoopの場合
例えばジョブが多段に構成される場合の課題のイメージとしては以下のような感じ
このようにHadoopの場合ジョブ間でのデータ受け渡しの度にHDFS(*1)へのI/Oが伴う
(*1)HDFS:MapReduceで処理するデータを扱う、分散ストレージとして複数のマシンを一つのストレージとして扱うことができる。
HDFSは管理するファイルのI/Oを高速化するため大きなファイルを一定の大きさ(初期設定では64MB)のブロックに分割して、
複数の記憶装置に分散して保存、I/Oを記憶装置の台数だけ並列に実行できるようにしている。
Sparkでは
RDDと呼ばれる部分故障への耐性を考慮した分散コレクションに対して典型的なデータ処理を繰り返すことで目的の結果を得ることができます
複雑な処理を少ないジョブ数で実現し、RDDごとに中間データをその都度出力しないのでHDFSなどの外部ストレージへのI/Oが抑えられる。

1. RDD(Resilient Distributed Datasets)の仕組み
RDDは耐障害性分散データセットで、繰り返し利用するデータについてはメモリ上に保持することが可能な機構でHadoopのMapReduceが保持していた(耐障害性、データ局所性、スケーラビリティ)はそのまま引き継いでいます。
I. RDDの性質
- イミュータブルで分割されたオブジェクトのコレクション(フォールトトレラント性を実現するため
RDDでは「得たいデータが失われていたら前のデータから再生成する」というアプローチを取っているため、それぞれイミュータブルである必要がある) - 読み取り専用
- 並列処理(
map,filter,groupBy,join)をストレージ上のデータに適応した結果を生成 - 再利用するためにメモリ上にキャッシュされる
- 遅延評価される(アクション系のメソッド(*2)が呼ばれるまで」実際の処理は行われない)
(*2)アクション系のメソッド(引用)
> RDDに保持したデータを操作するメソッドは大きく分けて2つに分類されます。
「Transformations」と「Actions」です。
「Transformations」はRDDを操作し、結果を新しいRDDとして返します。
「Actions」はRDDのデータを操作し、結果をRDD以外の形式で返すか保存を行います。
大雑把に言えば、RDDを返すのが「Transformations」、そうではないものが「Actions」であると言えると思います。
Ⅱ. RDDを生成するには
生成の方法は大きく2通りあります。
一つ目はSparkContextというドライバプログラムが持つ、Sparkにアクセスするためのオブジェクトを用いて
JavaRDD<String> lines = sc.textFile("README.md");
のようにテキストファイルなどを文字列からなるRDDとしてデータセットをロードする方法。
二つ目は、オブジェクトのコレクション(リストや集合)をドライバプログラムで分散させる方法がある。
例えばプログラム中の既存のコレクションを以下のようにしてSparkContextのparallelize()メソッドに渡す。
JavaRDD<String> lines = sc.parallelize(Arrays.asList("student","i am a student"))
ただしこの方法は一台のマシンのメモリ内にデータセット全体を持たなくてはならず、実用的ではない。
Ⅲ. RDDの再利用(永続化/キャッシュ)
RDDはそれに対するアクションが実行されるたびに計算し直されるのがデフォルト。あるRDDが何回もアクションで再計算されるようであれば、Sparkに対してそれを永続化できるように(linesはRDD)
lines.persist()
で依頼することができる。また、そのデータはSparkに対して指示することで様々な場所に置くことが可能です。
永続化の指示があったRDDが計算されるとき、SparkはそのRDDの内容をメモリに保存し(クラスタ内のマシン群にまたがって分割される)、それ以降のアクションで再利用します。またRDDをディスクに永続化することも可能です。SparkにRDDを永続化させると、RDDを計算する計算ノードは、自分のパーティションを保存することになります。データを永続化したノードに障害があった場合はSparkが失われたデータのパーティションを必要に応じて計算する。またノード障害があっても速度が落ちないように、データを複数のノードに複製しておくことも可能です。またJavaのデフォルトのpersist()ではデータをJVMのヒープにシリアライズされ体内オブジェクトとして保存します。タイミングに関して
RDDに対するpersist()は最初のアクションよりも前に呼ぶ必要があります。persist()やcache()は、RDDを永続化することを宣言しているだけで遅延評価されるためです。
org.apache.spark.storage.StorageLevelに永続化のレベルの指定に関して記述があります。
またメモリに収まらないデータをキャッシュしようとした場合などはLRUポリシー(*3)を使い、古いパーティションを退避させます。
退避されたデータがディスクに書き出されるか再計算されるかは永続化のレベル次第で変わってきます。
またunpersist()でそのRDDをキャッシュから取り除くことができます。
(*3)LRUポリシー:Least Recently Usedポリシー、
文字どおり最も最近使ったのを残していき、
最近使わなかったやつは外していく考え方
Ⅳ. RDDの操作
RDDはアクションと変換の二つの操作をサポートしていて、変換が新しいRDDを作成する操作(map,filterなど)に対して、アクションはそうでないもの(countなど)です。
Sparkのほとんどの変換アクションは、Sparkがデータの演算処理を行う際に使用する関数渡しに依存しています。
また、RDDのメソッドはクロージャ(*4)内で実行されます。言い換えればSparkのRDDメソッド実行はクロージャとして扱われます。RDDメソッドを実行すると、そのメソッドとそのメソッドへ引数として渡された関数、その関数内で参照されている変数はクロージャとしてまとめられてエグゼキュータに送信され、各エグゼキュータによって実行されます。
ただし、クロージャないから参照した外部の変数の値を書き換えようとしても、クロージャ内の実行なので更新できません、その際はAccumulatorを使います。(このAccumulatorはアクション内で使われる時に限りSparkのタスクの更新を各Accumulatorに一度だけ適応することが保証されてるみたいです)
(*4)クロージャ: 演算を実行する際に必要となる変数とメソッド群をカプセル化したもの。
A. 変換
RDDに対して変換処理をすると新しいRDDが返されます。変換されたRDDの演算は、遅延させられてアクションで使用する時点で初めて実行される。例えばログファイルからエラーのあるメッセージのみフィルターをかけたい場合、関数の渡し方は以下のようになります。
//A. 無名のインタークラスとしてインラインで定義し関数渡しする
JavaRDD<String> srcLog = sc.textFile("Log.txt");
JavaRDD<String> errorLog = srcLog.filter(
new Function<String,Boolean>(){
public Boolean call(String str){return str.contains("Error");}
}
);
//B. 名前付きクラスを使って関数渡し
JavaRDD<String> srcLog = sc.textFile("Log.txt");
class ContainsError implements Function<String,Boolean>{
public Boolean call(String str){return str.contains("Error");}
}
JavaRDD<String> errorLog = srcLog.filter(new ContainsError());
//C. パラメータありの名前付きクラスを使って関数渡し
JavaRDD<String> srcLog = sc.textFile("Log.txt");
class Contains implements Function<String,Boolean>{
private String argQuery;
public Contains(String arg){this.argQuery = arg;}
public Boolean call(String str){return str.contains(argQuery);}
}
JavaRDD<String> errorLog = srcLog.filter(new Contains("Error"));
//D. Java8のラムダ式を使って関数渡し(オススメ)
JavaRDD<String> srcLog = sc.textFile("Log.txt");
JavaRDD<String> errorLog = srcLog.filter(s->s.contains("Error"));
ここでの操作は`srcLogというRDD自体を変化させるのではなく、filter()関数が返すのは全く新しいRDDのerrorLogへのポインタであることに注意が必要です。
[補足]org.apache.spark.api.java.function内の主なJavaの関数インタフェース
| 関数 | 実装する必要のあるメソッド | 使用方法 |
|---|---|---|
| Function<T1,R> | R call(T1) | 入力を一つ取り、出力を一つ返す。map()やfilter()などと一緒に使う |
| Function2<T1,T2,R> | R call(T1,T2) | 入力を二つ取り、出力を一つ返す。aggregate()やfold()などと一緒に使う |
| FlatMapFunction<T,R> | Iterable call(T) | 入力を一つ取り、出力を返さないこともあれば、複数返すこともある。。flatMap()といった操作と一緒に使う |
要素単位の変換
要素単位の変換としてはmap()やfilterなどがあります。
| 関数 | 説明 |
|---|---|
| map() | 引数に関数を一つ取り、その関数をRDD内の各要素に適応し、その結果を新しい値とするRDDを返す |
| filter() | 引数に関数を一つ取り、そのフィルタ関数が真になる要素だけを含むRDDを返す |
例えば以下はRDD内の各値の絶対値を取る例です
JavaRDD<Integer> input = sc.parallelize(Arrays.asList(-1,2,-3,4,-5));
JavaRDD<Integer> output = input.map(i->Math.abs(i));
System.out.println(output.collect());
複数の出力
それぞれの入力から複数の出力を生成したい場合、flatMap()が有効です
| 関数 | 説明 |
|---|---|
| flatMap() | 引数に関数を一つ取り、その関数をRDD内の各要素に適応して呼ばれるが、この関数はその結果を返すIteratorを返します。それらのIterator全てから返された要素を値とするRDDを最優的に返します |
例えば以下はRDD内の文字列を空白で分割する例です
JavaRDD<String> input = sc.parallelize(Arrays.asList("Hello I am a dog"));
JavaRDD<String> output = input.flatMap(s -> Arrays.asList(s.split(" ")));
System.out.println(output.collect());
集合操作
和や積など数学の集合的な操作の関数も多く用意されています。
| 関数 | 説明 | A[1,2,3],B[3,4,5],C[1,1,2,3]だった場合 |
|---|---|---|
| union() | それぞれのRDDの和集合の重複を許したすべての要素からなるRDDを生成 | A.union(B) >>> [1,2,3,3,4,5] |
| intersection() | 重複を許さずそれぞれのRDDの積集合の要素からなるRDDを生成 | A.intersection(B) >>> [3] |
| subtract() | 片方の要素からもう一方の要素を除いた要素からなるRDDを生成 | A.substract(B) >>> [1,2] |
| distinct() | 一つのRDD内部での重複要素を一つにまとめた要素からなるRDDを生成 | C.distinct() >>> [1,2,3] |
B. アクション
アクションはドライバプログラム(main関数を持ってる)に最終的な値を返したり、データを外部ストレージに書き出す操作です。RDDにアクションを行う際、実際に出力を生成しなければならないので、そのRDDが必要とする変換の評価が実行される。例えば以下のような関数が用意されています。
| 関数 | 説明 |
|---|---|
| count() | 要素の個数を返す |
| take(int num) | 複数の要素を引数の数だけ集めてくる |
| collect() | RDD全体を取り出す(小さいサイズ場合のみ) |
| saveAsTestFile() | 分散ストレージシステムに書き出す |
| saveAsSequenceFile() | 分散ストレージシステムに書き出す |
また、アクションを呼ぶたびにRDDは最初から計算し直されることになっています。これは非効率な場合があるので、ユーザーが中間結果に対して永続化することが必要な場合があります。
集計
RDDの何かの値の合計をとりたい時など、集計を行うことに関してreduce()が有効です。
JavaRDD<Integer> input = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10));
Integer Result = input.reduce((a, b) -> (a + b));
System.out.println(Result);
reduce()はRDD内の任意の同じ型の2要素に対して操作を行い、その型の要素を返す関数を取る関数。
今回はjava8のラムダで二要素を加算して一つにして返す関数を渡しています。上の例だと結果は55となるはずです。他にも、reduceによく似ているfold()、返す型が操作対象のRDDと同じでなくても良いaggregate()などいろいろあります。
| 関数 | 説明 |
|---|---|
| reduce(func) | 結合処理を並列に行う |
| fold(zero)(func) | reduce()と見た目は同じ、中身は若干違うっぽく、単位元的な値(その操作を適応しても変わらない)を受け取る |
| aggregate(func) | reduce()と同じだが、返す型が扱うRDDの要素と違う場合に使う |
[補足]
また、rdd.reduceByKey(func)はrdd.groupByKey().mapValues(value -> value.reduce(func))と同じRDDを生成しますが、各キーに対する値のリストを生成するステップを省けることから効率が優れていると言えるらしい。
データをドライバプログラムに返すもの
collect()やtake()などデータの一部や全部を通常墓コレクションや値としてドライバプログラムに返すRDDのアクションがあります。この辺りはすでにコード上で紹介しているので詳しくは割愛します。
| 関数 | 説明 |
|---|---|
| take(n) | RDDからn個の要素を返す |
| top(n) | RDDの先頭からn個までの要素を返す |
| takeOrdered(n)(ordering) | 指定された順序でRDDからn個要素を返す |
| takeSample(withReplacement,n,seed) | RDDからランダムにn個要素を返す |
| collect() | RDDすべての要素を返す |
| count() | RDDの要素数を返す |
| countByValue() | RDDの各要素の出現回数を返す |
その他
RDDにアクションは行うがドライバプログラムには何も返さず、外部ストレージに書き込みなどしたい場合もあります。この時foreach()が有効です。
foreach()ではRDD内の各要素に対して演算を行い、ドライバプログラムには何も返さずに済みます。
| 関数 | 説明 |
|---|---|
| foreach(func) | RDD中の各要素に指定した関数を適用 |
Ⅴ. RDD変換の遅延評価
前述した通り、Sparkはアクションが行われるまで変換の処理を始めません。Sparkはその操作を即座に実行せず、その操作が要求されたことを示すmetadataを内部的に記録していきます。その上でSparkは遅延評価を行い操作をグループとしてまとめ、データに対する操作の回数を減らしています(内部的にある程度最適化)。そのためHadoop Mapreduceの回数を最小限にすべくどのように操作をまとめるかみたいな事は考えなくても大丈夫そう。
Ⅵ. RDDの依存関係
-
RDDの変換において、変換の元(親)のRDDと変換後(子)との間には依存関係が定義される。 - 依存関係はスケジューリング(RDDの変換チェインを処理可能なタスクに分割する)に関係する。
- 狭い依存関係(親のパーティションが単一の子のパーティションの生成に関わっている依存関係)と、広い依存関係(親のパーティションが複数の子のパーティション生成に関わっている依存関係)がある
Ⅶ. RDDの耐故障性
-
RDDはデータそのものではなく、「RDDを構築するためにデータに対して行った変換」を記録することで効率的な耐障害性を実現している。 - もし
RDDの中の一部分がロストした場合、RDDはそのデータが他のRDDからどのように変換されて生じたデータかを保持しているため、コストの大きなレプリケーション(*5)なしに迅速に再計算/復旧させることができる。
(*5)レプリケーション
レプリケーション、ソフトウェアやハードウェアの冗長な、リソース間で一貫性を保ちながら情報を共有する処理を意味する。
信頼性やfault tolerance性やアクセス容易性を強化する。
Ⅷ. PairRDD
http://www.task-notes.com/entry/20160131/1454214972
にとてもまとまっていました。Javaには組み込みのTuple(*6)型がないため、SparkのJavaAPIで定義されているTuple2クラスを用いてユーザはタプルを生成する必要があります。
(*6)Tupple:データベースやファイルでいう1行・1レコードのデータのようなもの。
つまり複数のデータを1つの塊として扱えるもの。
タプルを使って、メソッド・関数から複数の値を一度に返すことが出来るので、非常に便利らしい。
Spark処理の流れ[補足]
Ⅰ. 系譜のステージへの分割
-
DAGSchedulerが、系譜をスケジュールに分割する - ステージは系譜中で狭い依存関係が連続して発生する範囲(依存関係の種類は変換の種類できまる)
- 系譜中で広い依存関係が発生する変換関数を処理する場合はエグゼキュータ間でシャッフルと呼ばれる多数対多数の通信が発生する。
- この分割は、パーティションごとに一つのエグゼキュータがまとめて計算できる変換の範囲を決めるため
データのパーティショニングについて
分散プログラムでは通信は非常にコストが高く、ネットワークのトラフィックを最低限に抑えることはパフォーマンスの大幅な改善につながります。
SparkのプログラムはRDDのパーティショニングを制御して通信を削減していく必要があります。
例えばSparkはキーの集合がまとまってあるノードに現れることをプログラムで保証することができます。特にパーティショニングが役立つのはデータセットが結合のようなキー操作を複数回再利用される場合に限ります。というのもSparkの操作の多くはネットワーク越しにキーに基づくシャッフルを起こします。それらはすべてパーティショニングの恩恵を受けることができます。
JavaやScalaではpartitionerプロパティを用いてRDDのパーティショニングの方法を指定できます。ここでspark.Partitionerオブジェクトの値として、`RDDに対してそれぞれのキーの行き先のパーティションを知らせるものをセットします。
reduceByKey()のように単一のRDDに対して働く操作をパーティション化されたRDD上で動作させると、各キーのすべての値は、単一マシン上でローカルに計算され、ローカルにreduce()された最終の値だけが、各ワーカーノードからマスターに戻されます。
また、二つの
RDDに対して操作する場合は、事前にパーティショニングが行われていると、最低でも二つのRDDのうちの片方はシャッフルされません。
さらに驚くことに、
Sparkはそれぞれの操作がパーティショニングに及ぼす内部的な影響を知っているので、データパーテショニングを行う操作によって生成されるRDDに、自動的にpartitionerを設定します。
補足ですが
RDDに対してパーティショニングを行い、それによって生成されたRDDを変換の対象とするのであればpersist()で永続化すべきです。理由としては、それ以降のRDDのアクションはパーティショニングで生成したRDDの系統全体を評価し直すことになるので、パーティショニング前のRDDに何度もハッシュパーティショニングが行われてしまい意味がなくなってしまいます。
Ⅱ. ステージの実行要否を判定する
-
Sparkではスケジューラで制御されてる複数のジョブで同じRDDを共有することができる - 共有している
RDDがすでに計算済みで、ディスクやメモリに実態を持つ場合、そのRDDを生成するための前段のステージ実行を省略できる
Ⅲ. タスクを生成する
-
DAGSchedulerが実行対象の個々のステージについてタスクを定義する - 各ステージにおいて、ステージ内の最後の
RDDのパーティション数から当該ステージのタスク数が決まる - ステージに含まれる
RDDの変換チェインから、タスクあたりの処理範囲が決まる
Ⅳ. タスクを実行する場所を決める
- プリファードロケーションが
RDDにセットされている場合はそれをヒントにエグゼキュータを選ぶ - ない場合は親をたどって最初に見つかったものを使う
- プリファードロケーションは
RDDの種類ごとに定義される - データソースをもとに異性される
RDDはプリファードロケーションを持つので - いつかはプリファードロケーションが見つかる
Ⅴ. タスクの実行順序をスケジューリングする
- ステージを構築するタスク群は「タスクセット」として
TaskSchedulerに渡される -
TaskSchedulerはタスクセット単位で実行順序のスケジューリングを行う。 -
TaskSchedulerはタスクセットの実行順序を決定するまでに、タスクセットを登録しておく「プール」を一つ以上保持。スケジューリング方法によってプールの数や使い方が異なる - 標準で二つのスケジューリング方がある
| 名称 | 説明 |
|---|---|
| FIFO | 単一のプールを用いて、キューのように扱う。プールに登録されたタスクセットを順にスケジューリングする |
| FAIR | 複数のプールを用いて、各プールから公平にアスクセットを取り出しスケジューリングする |
キーワード
| キーワード | 説明 |
|---|---|
| クライアント | ジョブのキックを担当 |
| マスタ | ジョブのキックを担当 |
| ワーカ | 計算資源の提供・管理を担当 |
| ドライバ | ユーザがRDDの変換を記述したプログラム |
| エグゼキューター | ワーカー上で動作し、実際の計算を担当 |
| ジョブ | Sparkの処理内でアクション系のメソッドを実行するとジョブが作成される。SparkではRDDと呼ばれる抽象データセットの変換を繰り返して目的の結果を得る。この一連の処理をジョブという |
| ステージ | ジョブはデータのシャッフルが必要な場合に複数のステージに分割される |
| タスク | ジョブをエグゼキューターが実行可能な粒度に分割した処理単位。ステージは複数のタスクを持ち、ワーカーに対して送られる並列実行可能な処理をタスクという |
| スケジューラ | ジョブをタスクに分割したり、タスクのエグゼキュータへの割り当てを担当 |
以下のサイトにとても詳しく書いてあり参考にさせていただきました
http://www.ne.jp/asahi/hishidama/home/tech/scala/spark/RDD.html
http://dev.classmethod.jp/etc/apache-spark_rdd_investigation/
http://www.slideshare.net/hadoopxnttdata/apache-spark
データのI/O[補足]
ファイルのロードとセーブ
例えば以下のようなbin/data内のJSONファイルをまとめて一つのRDDとして読み込むことが可能です。(ここではJSONの扱いは触れませんがjavaのJSONライブラリにはhttps://github.com/FasterXML/jackson などがありますが、その場合も、一度テキストとして読み込んでから処理することとなります。)
![SaveFileSample.java - SparkTest - [~_Desktop_SORACOM_SoraPractice_IntelliJPractice].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.amazonaws.com%2F0%2F56510%2F94280aad-a56c-fd5b-cf62-e4fdaeb5c27a.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=88dc97a9a2f2f0255e3f0a19e6196754)
今回は例として、Twitterの6つのアカウントが直近の呟いたデータ200件をTwitterのRESTApiで取得してきたjsonファイルを用意していて、
それらのつぶやきのjsonファイルから呟いたテキストの行のみを抽出(input.filter(s -> s.contains("\"text\":")))そのテキスト中に「笑」と含まれているものだけ残すようにしました。最後にその結果をresult/output01というディレクトリに書き出します。
ここでsaveAsTextFile()メソッドの引数のパスはディレクトリとして扱われ、Sparkはその下に複数のファイルを出力します。こうすることで、Sparkは複数のノードから出力を書き出すことができます。
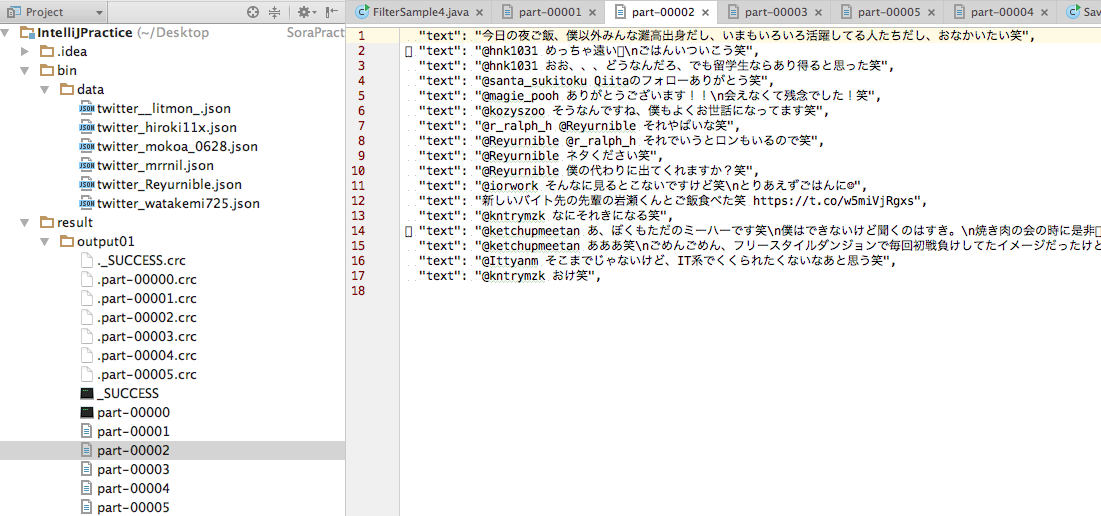
結果は上記の通りです、jsonのファイルごとに結果のファイルも生成されています。
part-00000に関しては、ファイルが開けませんでした、これは出力するものがなかったためだと思われます(「笑」が含まれていなかった)
最後にこのソースコードを載せておきます。
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* Created by hirokinaganuma on 2016/09/29.
*/
public class TwitterSample {
public static void main(String[] args) throws Exception {
String inputFile = "bin/data/*.json";//まとめて読み込むことも可能
String outputPath = "result/output01";
String master;
if (args.length > 0) {
master = args[0];
} else {
master = "local";
}
JavaSparkContext sc = new JavaSparkContext(master, "basicavg", System.getenv("SPARK_HOME"), System.getenv("JARS"));
JavaRDD<String> input = sc.textFile(inputFile);
JavaRDD<String> output = input.filter(s -> s.contains("\"text\":")).filter(s -> s.contains("笑"));
output.saveAsTextFile(outputPath);
sc.stop();
}
}
ファイルの圧縮
Sparkではストレージの容量節約や、通信コストを下げるために、textFile()などの入力フォーマット群で幾つかの種類の圧縮を自動的に処理してくれます。ただしこれらの圧縮は、ファイルシステムへ書き出されるもののみ利用可能でデータベース等にはSpark側からはできません。
また、圧縮のフォーマットによっては、分散させていろんなワーカーから読めないものも(先頭から読まなきゃダメみたいな制約があると)、ボトルネックとなってしまいます。複数のワーカーから読み出し可能なフォーマットを「スプリット可能」と言います。
2. Scala、Java、R、Pythonなどに対応(APIが用意されてる)
これは、文字通りです。
このような様々な言語をサポートしていて、サードパーティー製のライブラリも組み込みやすくなりました。
3. 多彩なライブラリ

-
Spark SQL: 構造化データや表形式データを扱う -
Spark Streaming: ほぼリアルタイムでストリーム・データを処理する -
MLlib: 機械学習を行う(コンポーネントとしてspark.mllibとspark.mlがあるが前者が非推奨になった模様) -
GraphX: グラフ処理を行う
4. 複数の導入シナリオ(スタンドアロン、YARN、Mesos、組み込み、クラウド)

Apache Mesos もサポートしているが、企業向けで最もメジャーなのはHadoop YARN(Hadoopコアの一部)でこれももちろんサポートしている。
またSpark Standaloneと呼ばれる小規模ビルトイン・クラスタ・システムも含まれており、小規模クラスタ・テストなどの用途でのデプロイに適しています。
分散モードでは、Sparkは一つのセントラルコーディネータ(ドライバ)と、多くの分散ワーカー(エグゼキュータ)を持つマスター/スレーブアーキテクチャを利用します。
またそのドライバ単体でjavaのプロセスとして動作し、各エグゼキュータも個別のjavaプロセスとして動作します。このドライバとエグゼキュータ群はまとめてSparkアプリケーションと呼ばれます。
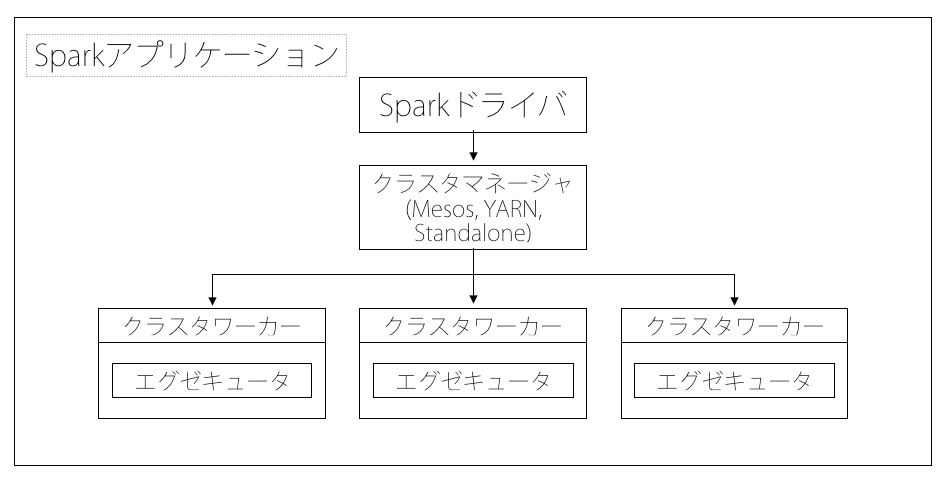
上記の図のように、Sparkのアプリケーションはクラスタマネージャーと呼ばれる外部サービスを使い、複数のマシン上で起動されます。その際にはspark-submitコマンドにてアプリケーションが投入されます。このコマンドはドライバプログラムを起動しユーザが指定したmain()メソッドを呼び出します。その後ドライバプログラムはクラスタマネージャに接続し、エグゼキューターを起動するためのリソースを要求します。その後クラスタマネージャがドライバプログラムの代理としてエグゼキュータを起動します。ドライバプログラムは、ユーザアプリケーションを実行し、プログラム中のRDDの変換やアクションに基づい、タスクという形で処理をエグゼキュータに送りつけます。エグゼキュータのプロセスでタスクが実行され計算結果が保存されます。最後に、ドライバのmain()メソッドが終了するか main()メソッドからSparkContext.stop()が呼ばれると、ドライバはエグゼキュータを終了させ、クラスタマネージャから取得したリソースを開放します。これが一連のSparkアプリケーションの流れになります。
ドライバ
作成するプログラムのmain()関数を実行するプロセス。SparkContextの生成やRDDの生成を行い、変換やアクションを実行することになります。
また、ユーザプログラムのタスクの変換とエグゼキュータ上のタスクのスケジューリングの処理を実行に際して責任を負います。
前者に関してはSpark処理の流れ[補足] / Ⅰ. 系譜のステージへの分割で説明した通り、ユーザのプログラムをタスクという実行単位に変換することです。SparkのプログラムはRDDを生成し、変換しアクションを行うという構造を取っており、その操作で構築される有向循環グラフを生成します。このグラフを最適に実行できるようステージ群に変換します。前述しましたがステージ群にはタスクが複数含まれたものです。
後者に関してもSpark処理の流れ[補足] / Ⅴ. タスクの実行順序をスケジューリングするで示した通り、Sparkのドライバはエグゼキュータ群の個々のタスクのスケジュールを調整します。エグゼキュータ群は起動時に自分自身をドライバに対して登録するため、ドライバは自分のアプリケーションのエグゼキュータの様子を常に把握できます。
エグゼキュータ
Sparkのエグゼキュータは、Sparkのジョブの個々のタスクの実行を受け持つワーカープロセスです。エグゼキュータはSparkのアプリケーション起動時に一度起動され、通常はそのアプリケーションが起動している間動作し続けます。またSparkのアプリケーションはエグゼキュータ群に障害があっても処理を継続できます。
主なエグゼキュータの役割としては、アプリケーションを構築するタスク群を実行し結果をドライバに返すことと、ユーザプログラムによってキャッシュされるRDDのインメモリストレージを各エグゼキュータ内で動作するブロックマネージャと呼ばれるサービスを通して提供することです。
5. 幅広い処理モデル(バッチ、インタラクティブ、ストリーミング)
特にインタラクティブシェルはとても便利です。
その都度ビルドする必要がないのでロジックの試作など、効果の確認サイクルを早く回せます。見た目も使い方もRubyでいうとこのirbみたいな感じです。
実際に動かしてみる
1. 環境構築
Ⅰ. Oracle Java SEをインストール
Javaのversion等切り替える際は以下のサイトがとても参考になりました
http://qiita.com/yohjizzz/items/194973bf2f34608ae85a
Ⅱ. Apache Sparkをダウンロードする。
https://spark.apache.org/downloads.html
今回は2.0.0をインストールします
- ダウンロード手順1 : 「
Chose a Spark release」で「2.0.0 (Jul 26 2016)」を選択。 - ダウンロード手順2 : 「
Chose a package type」で「Pre-build for Hadoop 2.7 and later」を選択。 - ダウンロード手順3 : 「
spark-2.0.0-bin-hadoop2.7.tgz」をクリックしてダウンロードする。
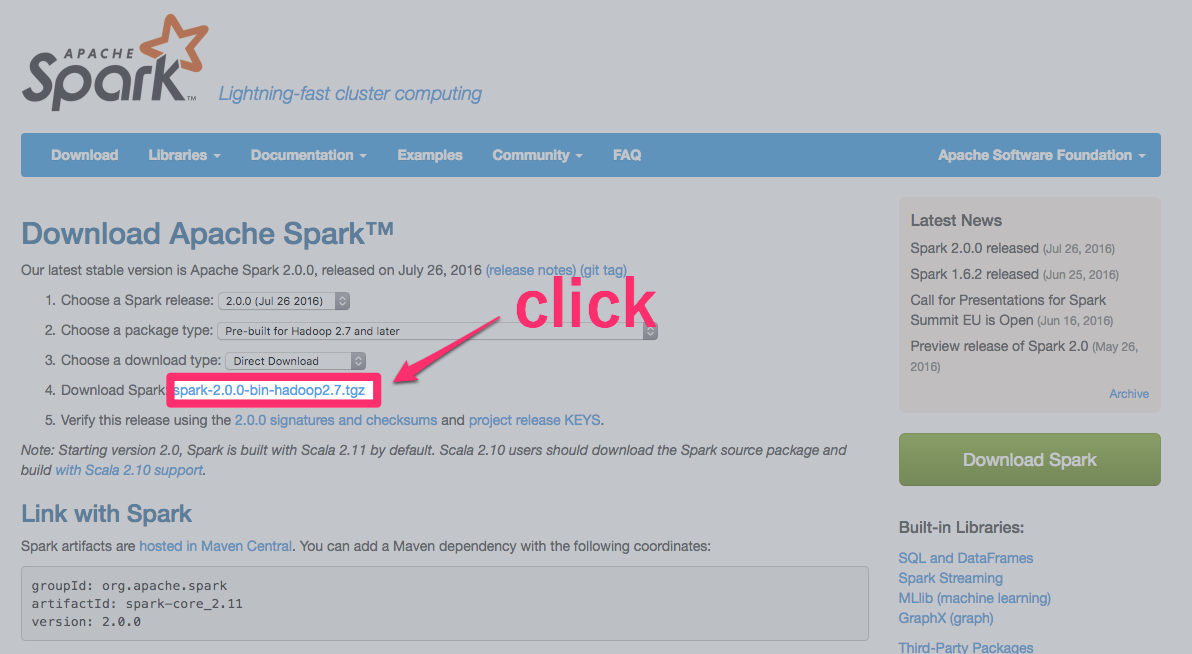
ダウンロードしたら任意のディレクトリで展開し、
spark-2.0.0-bin-hadoop2.7->bin->spark-shellを起動
成功すると以下のようなものが出てくるはずです
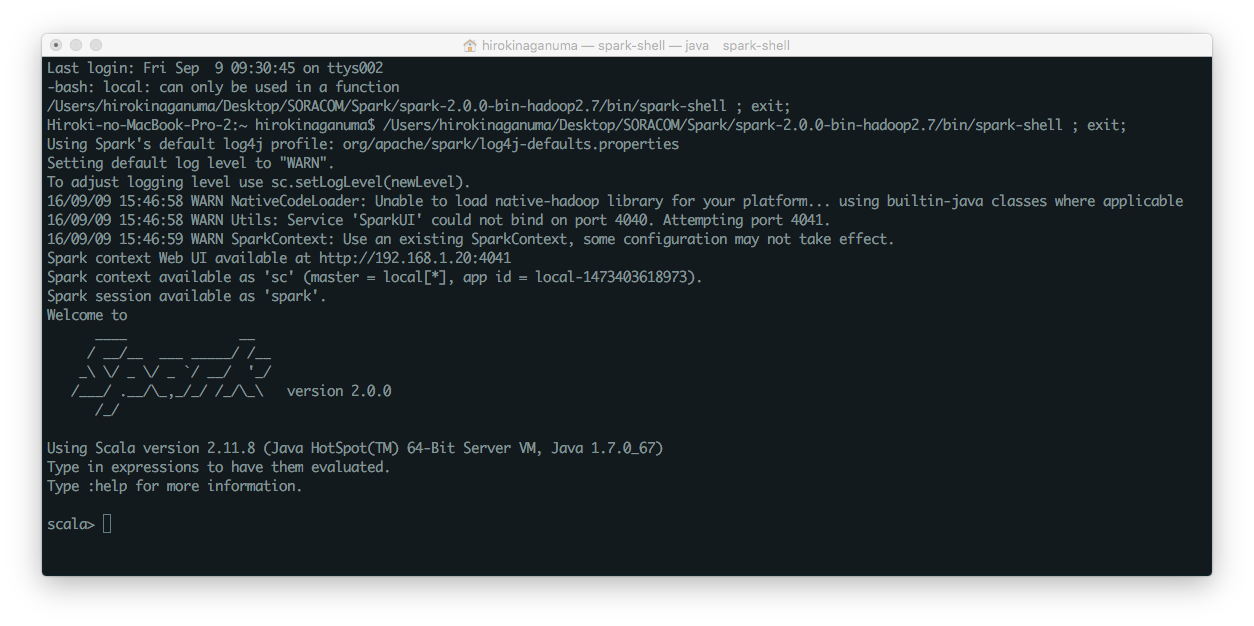
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
[init] error: error while loading <root>, Error accessing /Volumes/Transcend/Hack/SoraPractice/spark-2.0.0-bin-hadoop2.7/jars/._activation-1.1.1.jar
Failed to initialize compiler: object java.lang.Object in compiler mirror not found.
** Note that as of 2.8 scala does not assume use of the java classpath.
** For the old behavior pass -usejavacp to scala, or if using a Settings
** object programmatically, settings.usejavacp.value = true.
Failed to initialize compiler: object java.lang.Object in compiler mirror not found.
** Note that as of 2.8 scala does not assume use of the java classpath.
** For the old behavior pass -usejavacp to scala, or if using a Settings
** object programmatically, settings.usejavacp.value = true.
Exception in thread "main" java.lang.NullPointerException
みたいなのが出てきた場合、PATHを通してあげれば解決します!
$ cd
$ vim .bash_profile
.bash_profileには以下のように記述しました。
export SPARK_HOME="spark-2.0.0-bin-hadoop2.7までのpath"
export PATH="$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin"
最後に
$ source .bash_profile
で、もう一度.bash_profileを読み込み直せば完了です。これでspark-shellが起動できると思います。
これで、一旦の環境構築は終了です。
Hello World! 的なやつもやってみました。
scala>と表示されてるところに続けてsc....と以下のように入力してみてください。
scala> sc.parallelize(1 to 10,1).map(_*2).reduce(_+_)
すると以下のようになるはずです。今回の場合、1から10までの数字をそれぞれ二倍にして足しあげました。

2. WebUI
次にブラウザでlocalhost:8080を見てみましょう。
するとこんな画面が見えるはずです(一部情報を隠しています)
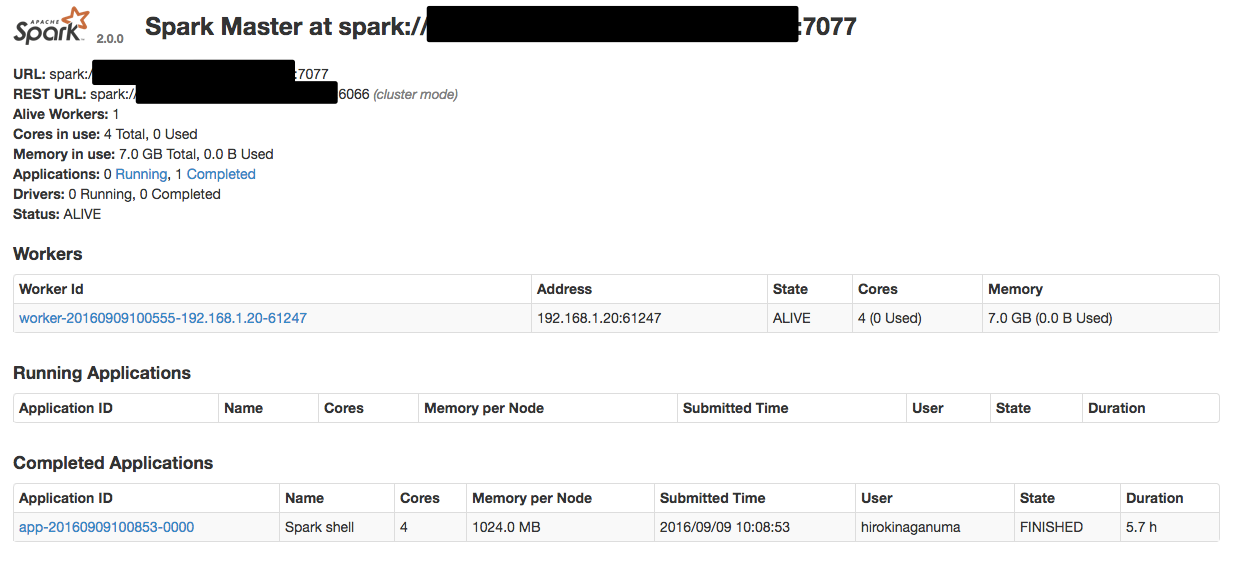
これはSparkの処理の状況を確認できる便利なWebのユーザインターフェースでクラスターやマスターの詳細が確認できます。
3. その他
| キーワード | 説明 |
|---|---|
| ジョブ | Sparkの処理内でアクション系のメソッドを実行するとジョブが作成される。SparkではRDDと呼ばれる抽象データセットの変換を繰り返して目的の結果を得る。この一連の処理をジョブという |
| ステージ | ジョブはデータのシャッフルが必要な場合に複数のステージに分割される |
| タスク | ステージは複数のタスクを持ち、ワーカーに対して送られる並列実行可能な処理をタスクという |
Tips
1. クラスタ起動の際
$ sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /Users/hirokinaganuma/Desktop/Hoge/SoraPractice/spark-2.0.0-bin-hadoop2.7/logs/spark-hirokinaganuma-org.apache.spark.deploy.master.Master-1-Hiroki-no-MacBook-Pro-2.local.out
failed to launch org.apache.spark.deploy.master.Master:
/Users/hirokinaganuma/Desktop/Hoge/SoraPractice/spark-2.0.0-bin-hadoop2.7/bin/spark-class: line 71: /Library/Java/JavaVirtualMachines/jdk1.8.0_101.jdk/bin/java: No such file or directory
full log in /Users/hirokinaganuma/Desktop/Hoge/SoraPractice/spark-2.0.0-bin-hadoop2.7/logs/spark-hirokinaganuma-org.apache.spark.deploy.master.Master-1-Hiroki-no-MacBook-Pro-2.local.out
localhost: ssh: connect to host localhost port 22: Connection refused
みたいなのが出たら、今回jdk1.8.0を指定したいので
export JAVA_HOME=`/usr/libexec/java_home -v 1.8`
とすれば直りました。
その後
$ sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /Users/hirokinaganuma/Desktop/Hoge/SoraPractice/spark-2.0.0-bin-hadoop2.7/logs/spark-hirokinaganuma-org.apache.spark.deploy.master.Master-1-Hiroki-no-MacBook-Pro-2.local.out
localhost: ssh: connect to host localhost port 22: Connection refused
みたいになる(解決できてない)
2. Amazon Web Service の EC2 インスタンスで動かす
http://cyborg-ninja.com/ittips/3103
http://qiita.com/ledmonster/items/8138d7cf0990ea1017da
http://qiita.com/mikoto/items/4273cd35dce254727363
SparkにはAmazon EC2でクラスタを起動するためのスクリプト(EC2スクリプト)が用意されています。
ただ、現在の最新版(2.0.1)にはなくなってる気がするのでもう推奨されていないのか?!
このスクリプトは、ノード群を起動しStandaloneクラスタマネージャをそれらにインストールするので、クラスタが立ち上がれば、あとはStandaloneモードとして使うことができます。EC2スクリプトは、名前をつけた複数のクラスタを管理できます。それらのクラスタはEC2のセキュリティグループによって識別できます。EC2スクリプトはそれぞれのクラスタに対してマスターノード用のclustername-masterとclustername-slavesというセキュリティグループを作成します。
インスタンスの作成までやってくれるっぽいけど、これはこの記事を見た方が良さそう。
http://qiita.com/mychaelstyle/items/b752087a0bee6e41c182
Standaloneクラスタマネージャ
Standaloneクラスタマネージャには基本的なスケジューリングポリシー(メモリとコア数とかを制限できるくらい)が用意されており、それぞれのアプリケーションリソースの上限を設定して複数のアプリケーションを並列させて実行できます。
まずはここから、初めてのデプロイはここで慣らしましょうと書籍にも書いてた。他のアプリケーションとともに動作させたい場合やより豊富なスケジューリング機能を使う場合はMesosやYARNを使うのがいいみたいです。
YARNはキューの概念があり、Mesosはアプリケーションの動作中のもっと動的な共有をサポートしてくれる。
高可用性として、Standaloneクラスタを実運用の設定で動作させている場合ワーカーノードの障害を問題ないようにアポートしています。クラスタのマスターの可用性も高めるためには、Apache ZooKeeper(分散協調システム)を使って複数のスタンバイマスターを用意しておけば、Sparkは障害があった場合新しいマスターへの切り替えをサポートしています。
この時、クラスタマネージャはドライバプログラムに対して、2つのデプロイモードをサポートしています。
- クライアントモード
クライアントモードでは、ドライバはspark-submitを実行したマシン上で、spark-submitのコマンドの一部として動作する。(ドライバプログラムに直接入力を行えたり、出力を直接見たりできるから) - クラスタモード
クラスタモードではドライバはStandaloneクラスタ内でいずれかのワーカーノード上のプロセスとして起動され、リクエストのエグゼキュータに対して接続します。切り替えるのにはspark-submit --deploy-mode clusterに渡さなきゃいけません。
Apache Mesos
概要に関してはこちら
Apache Mesosは汎用のクラスタマネージャで、分析的なワークロードや、ウェブアプリケーションやキー/値ストアなどの長期間にわたって動作するサービスもクラスタ上ではしらせることができます。
マルチマスターモードで動作させる際に、ZooKepperを使ってマスターを選択させるように設定することもできます。またMesos上のSparkがサポートするアプリケーションの動作モードはクライアントデプロイモードだけです。これが意味するのは「ドライバはアプリケーションを投入したマシン上で動作します」ということです。ドライバをMesos上のクラスタ上で動作させたい場合は、AuroraやChronosなどのフレームワークが別途必要です。
また、他のクラスタマネージャとは異なり、同一クラスタ上でのエグゼキュータ間のリソース共有に関して、Mesosは二つのモードを提供しています。
-
fine-grainedモード
エグゼキュータはタスクを実行しながらMesosに要求するCPU数を増減させるので、複数のエグゼキュータはタスクを実行しているマシンはエグゼキュータ間のCPUリソースを動的に共有できます。ただし、タスクをスケジューリングするレイテンシが大きくなってしまう。 -
coarse-grainedモード
Sparkはかくエグゼキュータが使用するCPU数をあらかじめ決めておき、仮にエグゼキュータがタスクを実行していなくても、アプリケーションが終了するまではCPUを開放しません。
参考
-
http://www-bcf.usc.edu/~minlanyu/teach/csci599-fall12/papers/nsdi_spark.pdf
-
http://dev.classmethod.jp/etc/apache-spark_rdd_investigation/
-
http://www.intellilink.co.jp/article/column/bigdata-kk01.html
-
http://www.intellilink.co.jp/article/column/bigdata-kk04.html
-
http://www.oracle.com/webfolder/technetwork/jp/javamagazine/Java-MJ16-Spark.pdf
-
http://www.oracle.com/technetwork/jp/articles/java/overview/index.html
-
http://www.ne.jp/asahi/hishidama/home/tech/scala/spark/RDD.html
-
http://www.ne.jp/asahi/hishidama/home/tech/scala/spark/index.html
-
http://www.ne.jp/asahi/hishidama/home/tech/scala/spark/partition.html
-
こちらのスライドが最初の全体の概要理解としてめちゃわかりやすかったです
http://www.slideshare.net/dragan10/apache-spark-53507780 -
導入にイメージとしてはこちらも参考になりました
https://oss.sios.com/guest-blog/guest-bog-20150624820 -
@kimutansk さんのはてなブログの記事がめちゃ参考になりました(まだ全部読めてません🙇)
これが全部わかれば理解できるんだろうなと思いました。
http://kimutansk.hatenablog.com/entry/20130901/1378023152 -
Sparkの公式ドキュメント
http://spark.apache.org/ -
Sparkの公式ドキュメント(日本語訳)
http://mogile.web.fc2.com/spark/spark200/index.html -
O'Reillyの「初めてのSpark」
https://www.oreilly.co.jp/books/9784873117348/

- 株式会社NTTデータの「Apache Spark入門 動かして学ぶ最新並列分散処理フレームワーク」
http://www.shoeisha.co.jp/book/detail/9784798142661
