はじめに
こんにちは。
この記事はApache Spark Advent Calendar 2015の19日目の記事です。
Sparkを使うにあたって困る点
Sparkを使っている皆さんなら実感しつつあると思いますが、Sparkには困った点もあります。
とりあえずサンプルを動かすだけ、であればそれほど苦労することは無いのですが、実際に大規模データを用いて使用し出すと、下記のような問題が頻発します。
- 適切なチューニングが施されていないとスピードが出ない
- 一部のコンポーネントはそもそも動かない(特にMLlib)
- 問題が発生した時、どこで発生したかがぱっとはわかりにくい
そのため、ある程度内部構造か、チューニングの勘所をおさえておかないと苦労することになります。
優れてはいるんですが、その分ピーキーなフレームワーク、というのがMapReduceと比べた私の印象です。
そんなわけで、Sparkの内部構造を説明した資料は無いのかな、という形で手頃な資料がないかを確認した所、SparkInternalsという資料が見つかったため、それを読んだ結果をまとめてみます。
若干古いバージョンのSparkの内容になりますが、それでも大体の流れは見える構成となっています。(未完結、かつこの投稿では全部は訳せていませんが)
尚、文を全て訳しているわけではなく、大体意味が通りそう、というレベルの読込みですので、そのあたりはご了承ください。
・・といいつつ、大部分はそのまま訳してしまっていますが。
以後、下記の判例となります。
SparkInternals訳文
コメント
SparkInternals
Overview of Apache Spark
この章では下記の質問に対して焦点を当てて記述する。
- デプロイ成功後、各ノードでどのようにサービスが実行されるか?
- どのようにSparkアプリケーションが生成実行されるか?
デプロイ図
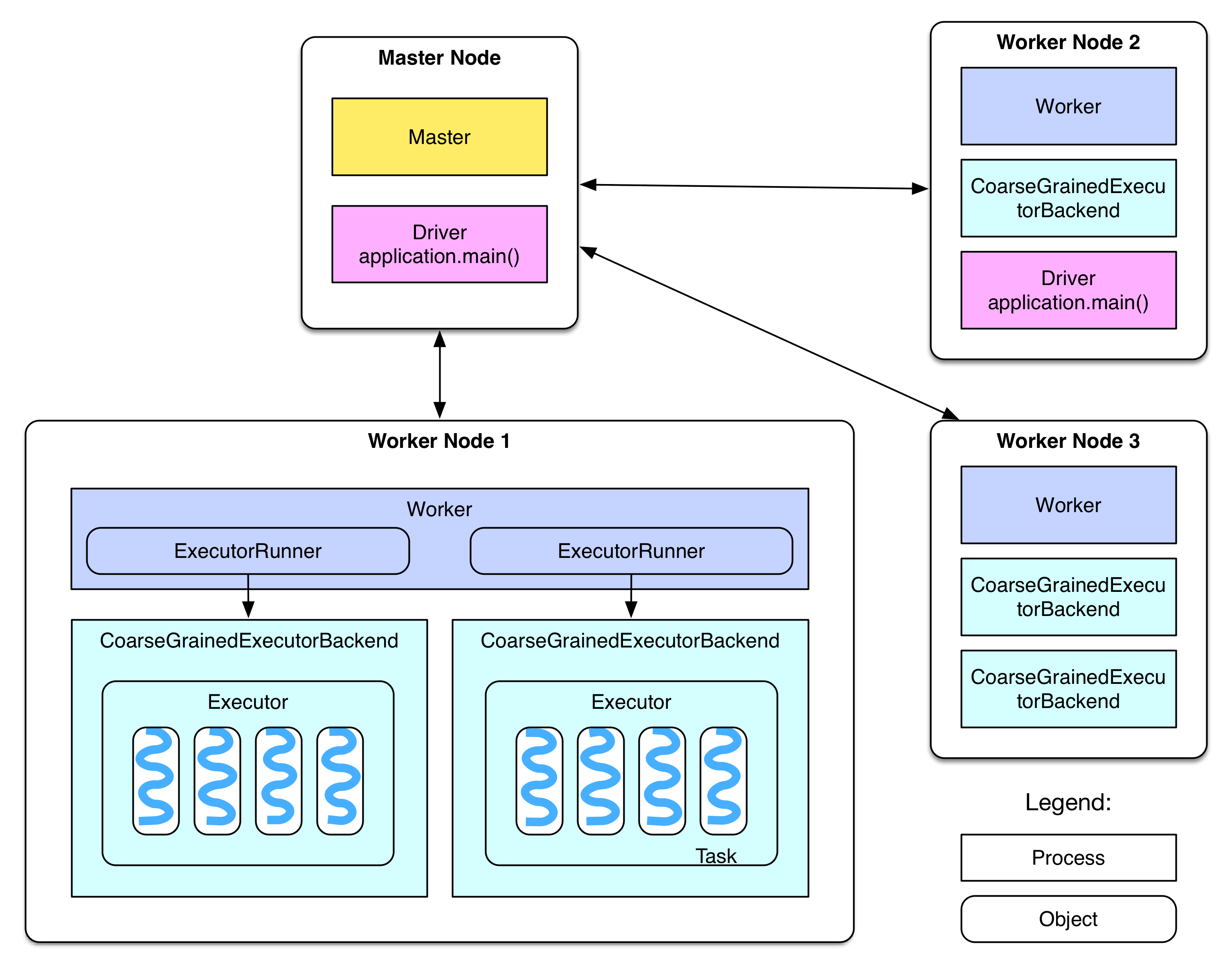
Standalone Clusterモードの場合、デプロイの流れは上記に示した図のようになっている。
- SparkClusterはMasterNodeと複数のWorkerNodeからなり、Hadoopと類似した構成になっている。
- MasterNodeはMasterDaemonProcessを保持し、WorkerNodeの管理を行う。
- WorkerNodeはWorkerDaemonProcessを保持し、MasterNodeとの通信と、LocalExecutorの管理を行う。
公式ドキュメント中ではDriverはmain関数の実行とSparkContextの作成を行うという記述がある。
Driverプログラム、例えばWordCount.scalaはSparkアプリケーションとみなされている。Driverプログラムは下記のようなコマンドでMasterNodeで起動される。
./bin/run-example SparkPi 10
SparkPiプログラムはMasterNode上でDriverプログラムとして動作する。しかしながら、DriverプログラムがYARNクラスタにsubmitされた場合、DriverプログラムはWorkerNode上にスケジューリングされることもある。(例えばWorkerNode 2のような)
Driverプログラムがローカルマシンで下記のようなコードを実行して起動した場合はまた状況が変わる。
val sc = new SparkContext("spark://master:7077", "AppName")
...
Driverプログラムはローカルマシン上で動くが、この方法はローカルマシンがWorkerNodeと同一ネットワークに所属していないことも多く、DriverとExecutor間での通信速度の問題によって実行が遅くなるケースが多いため、お勧めしない。
各WorkerNodeは複数のExecutorBackendプロセスを管理している。各ExecutorBackendプロセスは起動後Executorを管理する。各Executorはスレッドプールを保持し、各Taskがスレッド上で実行される。
Sparkにおいて各アプリケーションはDriverと複数のExecutorを保持する。同一Executor上で実行されるTaskは全て同一プロセスに所属する形になる。
Standalone Clusterモードの場合、ExecutorBackendはCoarseGrainedExecutorBackendとして初期化される。
WorkerNodeは各CoarseGrainedExecutorBackendプロセスをExecutorRunnerインスタンスとして管理する。
A simple Spark application
以下のサンプルはspark-exampleパッケージに含まれるGroupByTestアプリケーションである。
MasterNodeで下記のようなコマンドを実行することで起動される。
/* Usage: GroupByTest [numMappers] [numKVPairs] [valSize] [numReducers] */
bin/run-example GroupByTest 100 10000 1000 36
上記のコマンドで実行されるプログラムは下記。
package org.apache.spark.examples
import java.util.Random
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
/**
* Usage: GroupByTest [numMappers] [numKVPairs] [valSize] [numReducers]
*/
object GroupByTest {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("GroupBy Test")
var numMappers = 100
var numKVPairs = 10000
var valSize = 1000
var numReducers = 36
val sc = new SparkContext(sparkConf)
val pairs1 = sc.parallelize(0 until numMappers, numMappers).flatMap { p =>
val ranGen = new Random
var arr1 = new Array[(Int, Array[Byte])](numKVPairs)
for (i <- 0 until numKVPairs) {
val byteArr = new Array[Byte](valSize)
ranGen.nextBytes(byteArr)
arr1(i) = (ranGen.nextInt(Int.MaxValue), byteArr)
}
arr1
}.cache
// Enforce that everything has been calculated and in cache
pairs1.count
println(pairs1.groupByKey(numReducers).count)
sc.stop()
}
}
上記のようなコードが頭の中では下記のように実行されると思われる。
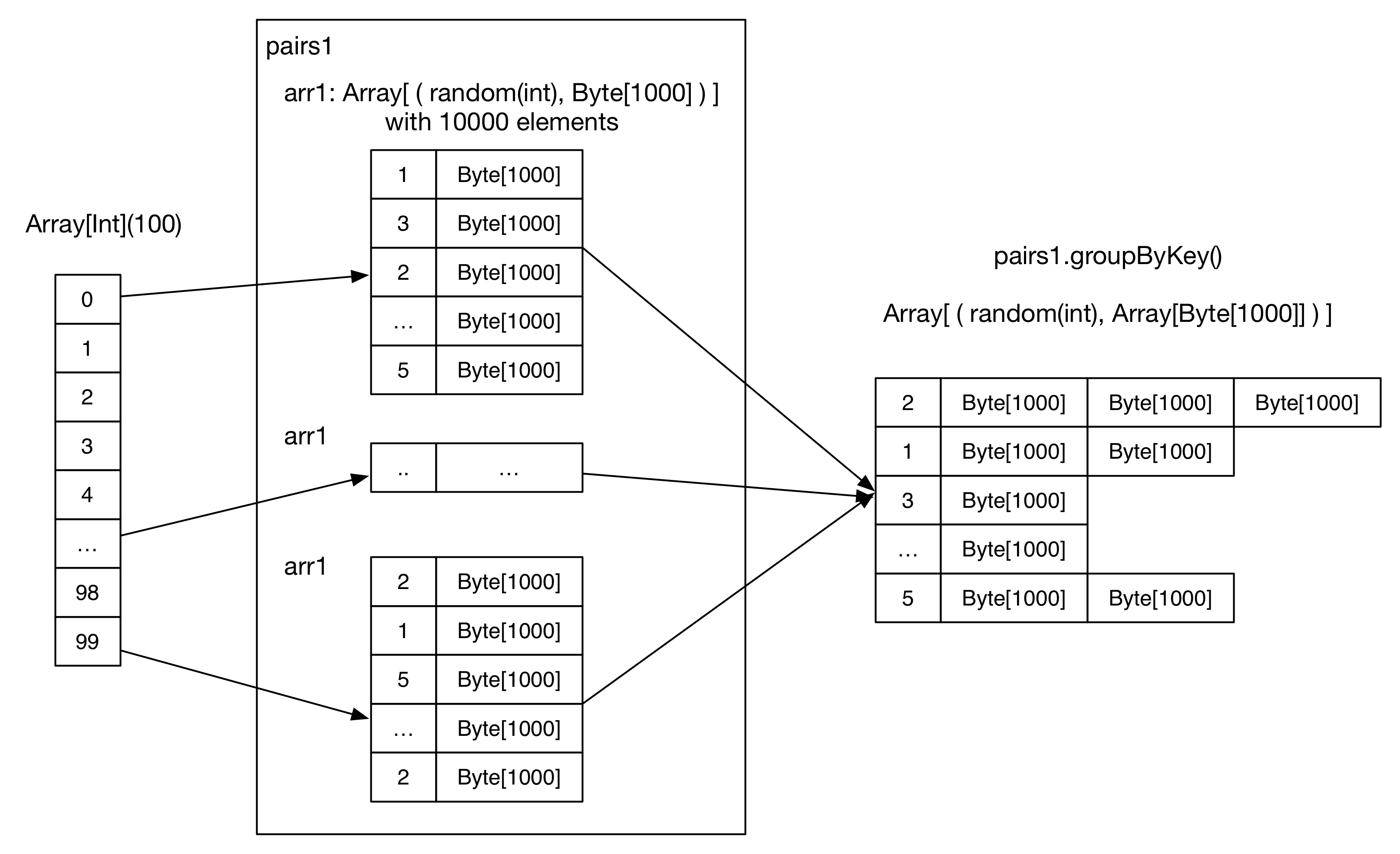
これは単純なアプリケーションなので、各ステップでデータがどのように変動するかを追ってみる。
- SparkConfが初期化される。
-
numMappers=100, numKVPairs=10,000, valSize=1000, numReducers=36として初期化される。 - SparkContextが初期化され、Driverに必要なオブジェクトとアクター類が生成される。
- 各Mapperでは
arr1: Array[(Int, Byte[])]を生成し、numKVPairs個の要素を保持する。各Int値はランダムの整数値となっており、各Byte配列のサイズはvalSizeとなっている。 arr1のサイズはnumKVPairs * (4 + valSize)より10MBと計算されるため、pairs1のサイズはnumMappers * Size(arr1)より1000MBとなる。 - 各Mapperはarr1をメモリ上にキャッシュするよう指定されている。
- count()アクションが全Mapper上のarr1の要素数の合計を取得するよう動作し、結果は
numMappers * numKVPairsから1,000,000となる。このアクションによって実際にarr1の計算がおこなわれ、キャッシュされる。 - groupByKeyオペレーションはキャッシュされたpairs1に対して実行される。Reducer数(=パーティション数)はnumReducersで示される。 理論上、もしhash(key)が上手く分散された場合、各Reducerは
numMappers * numKVPairs / numReducerより27,777個の(Int, Array[Byte])ペアを受信する。そのため、各Reducer上におけるデータサイズはSize(pairs1) / numReducerより27MBとなる。 - Reducerは同一のIntキー値を保持するレコードをマージし、
(Int, List(Byte[], Byte[], ..., Byte[]))の結果を生成する。 - 最後にcount()アクションが各Reducer上でのレコード数の合計値を取得し、最終的な結果はparis1中のキー重複を排除した個数となる。
Logical Plan
実際の実行手順は前述のものよりも複雑なものとなっている。大まかな流れとして、SparkはまずLogicalPlan(DataDependencyGraphと呼ばれる)を各アプリケーションに対して作成し、LogicalPlanを基にPhysicalPlan(Map/ReduceのStageのDAG)を作成する。その後、Stageを更に分割したTaskをMap/Reduceとして起動し、入力データを処理する。あるアプリケーションのLogicalPlanは以下のようになっている。
RDD.toDebugString関数を実行するとRDDのLogicalPlanが出力されるが、階層に示すと下記のようになる。
MapPartitionsRDD[3] at groupByKey at GroupByTest.scala:51 (36 partitions)
ShuffledRDD[2] at groupByKey at GroupByTest.scala:51 (36 partitions)
FlatMappedRDD[1] at flatMap at GroupByTest.scala:38 (100 partitions)
ParallelCollectionRDD[0] at parallelize at GroupByTest.scala:38 (100 partitions)
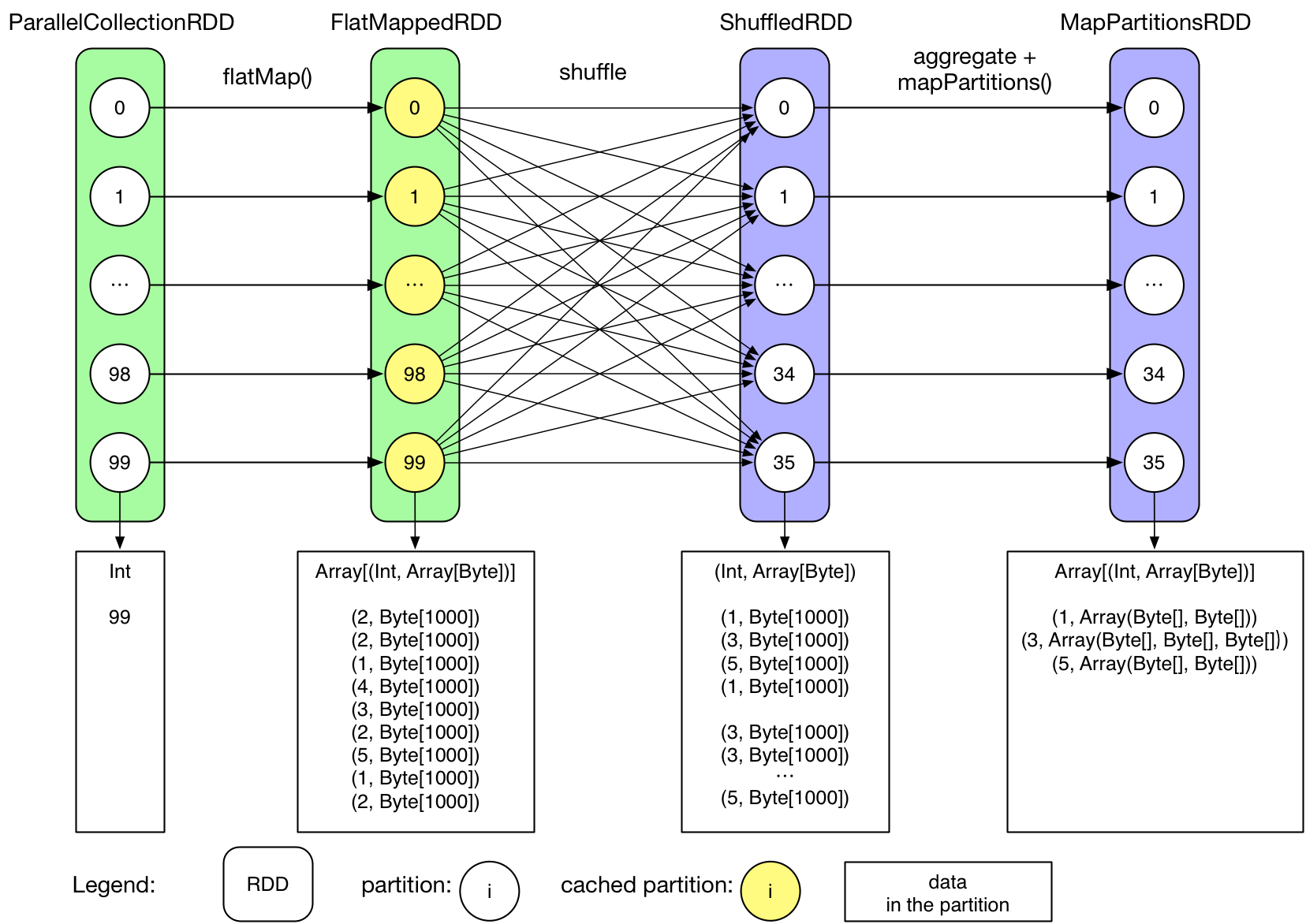
なお、各Partitionは独立して処理されるため、全データが同一のタイミングでメモリ上に存在するわけではない。
詳細は以下の通り。
- ユーザ側で100の整数値を保持する配列(今回の場合0~99)を初期化する。
- parallelize()は各要素が整数値iを含むParallelCollectionRDDを生成する。
- flatMapメソッドによってParallelCollectionRDDからFlatMappedRDDが生成される。
- FlatMappedRDDの各Partitionは[(Int, Array[Byte])]の配列を保持する。
- count()がFlatMappedRDDに対して実行される。
- FlatMappedRDDがメモリにキャッシュされる。(色を変えてある)
- groupByKey()が続く2つのRDD(ShuffledRDD and MapPartitionsRDD)を生成する。(詳細については後の章で説明)
- ShuffleRDDはLogicalPlan中ではShuffleが必要なジョブとして示されている。ShuffleはHadoop MapReduceでのShuffleと共通。
- MapPartitionRDDがgroupByKey()の結果を保持する。
- MapPartitionRDD(Array[Byte])の各要素がIterableに変換される。
- 最終的なcount()アクションがMapPartitionRDDに対して実行される。
- LogicalPlanはアプリケーションのデータフロー(Transformation群、内部RDD、RDD間の依存関係 )を示している。
Physical Plan
LogicalPlanがデータフローの定義に焦点を当てており、実際の実行フローについては触れていない。データフローと実行フローはHadoopでは同一のものとなっている。Hadoopにおいてはデータフローは事前定義、かつ固定化されたものとなっており、その中で実行されるMap/Reduceをユーザが定義している。Map/Reduceタスクは固定された実行ステップに従って実行される。しかし、Sparkにおいてはデータフローは柔軟かつ複雑なものとなっているため、単純にデータフローと実行フローを同一化することは困難である。そのため、Sparkはデータフローと実際にタスクを実行する実行フローを切り分け、データフローを実行フローに変換する仕組みを導入している。ここではそのデータフローから実行フローへの変換について示す。
では、前述のサンプルアプリケーションを基にPhysicalDAGPlanについて見ていく。
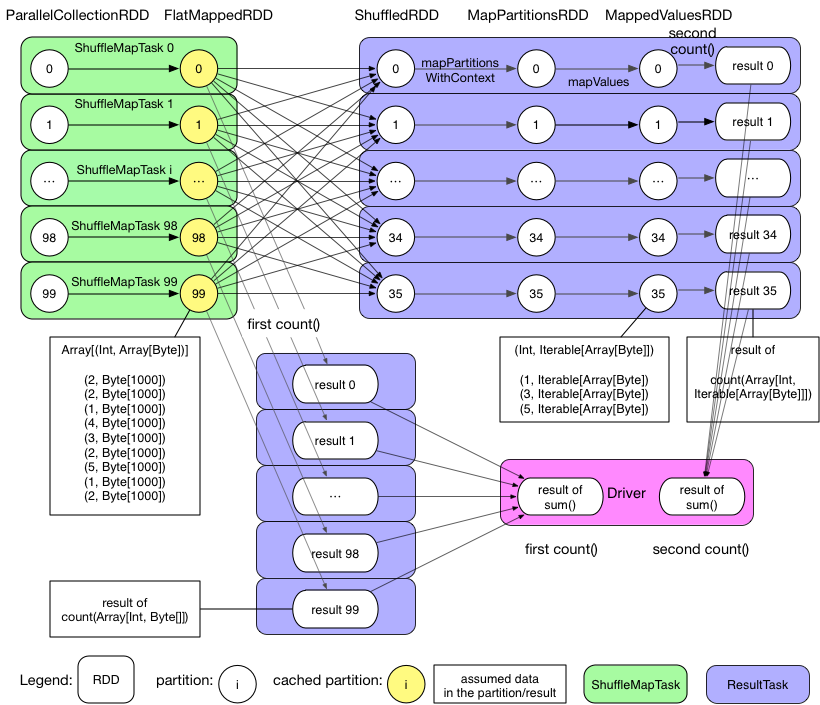
上記の図から、GroupByTestアプリケーションは2個のSparkジョブを生成することがわかる。
はじめのジョブは初回に実行されるcountアクションであり、詳細は以下のとおりとなる。
ジョブは1Stage(100のResultTaskを保持)から構成される。ここでのStageはHadoopのMap Stageと似ている。(図中では示されないが)
最初のジョブはつまりは下にあるfirst count()で示されるresut 1 ~ result 99が表示されている部分のみを示すわけですね。
各TaskはflatMap関数を実行し、FlatMappedRDDを生成する。その後countアクションを実行することで各Partitionが保持するレコード数をカウントする。例えば、Partition99は図中では9個のレコードを保持するため、Partition99のcount結果は9となる。
pairs1はキャッシュされることを指定されているため、本Task実行時にFlatMappedRDDのPartition群はExecutorのメモリ上に保存され、それは実行中常時保持される。
ResultTask群終了後、Driverは各Taskの結果から結果を収集し、それを合計して結果を算出する。
これでジョブ0が終了となる。
次のジョブはpairs1.groupByKey(numReducers).countの実行によって起動される。
このジョブは2個のStageから構成される。
左上のShuffleTaskと、右上のResultTaskが対象となります。
Stage0は100個のShuffleMapTaskを保持し、各Taskはparis1のPartitionをキャッシュから読み込み、Repartitionを行い、そのRepartition実行結果をローカルディスクに出力する。この過程はHadoop MapReduceにおいてMapが結果の各Partitionを出力する処理と共通。
尚、この先を読んだ限りでもRepartitionが走る処理を実行した場合にはデータを全てローカルディスクに出力する処理が常時走り、設定で無効化することも出来ないようです。
Stage1は36個のResultTasksを保持する。各Taskは各プロセスが必要とするデータを取得し、Shuffleする。データ取得後データを統合し、mapPartitions処理をパイプラインのように実行する。最終的に、countアクションが実行され、各結果の取得が行われる。
ResultTasks終了後、DriverはTaskの実行結果を取得し、合計する。
これでジョブ1が終了となる。
以上でわかるように、SparkのPhysicalPlanは単純ではない。Sparkアプリケーションは複数のジョブを内包し、各ジョブは複数のStageを内包し、各Stageは複数のTaskを内包している。
以後の章ではこれらのジョブ、Stage、Taskがどう生成されるか、詳細を見ていく。
Conclusion
この章でSparkジョブの生成、実行の基礎について示した。以後の章でキャッシュのメカニズムやジョブの生成、実行の詳細について説明する。章構成は以下のようになっている。
- Logical plan generation
- Physical plan generation
- Job submission and scheduling
- Task's creation, execution and result handling
- How shuffle is done in Spark
- Cache mechanism
- Broadcast mechanism
Logical plan of a job (data dependency graph)
An example of general logical plan
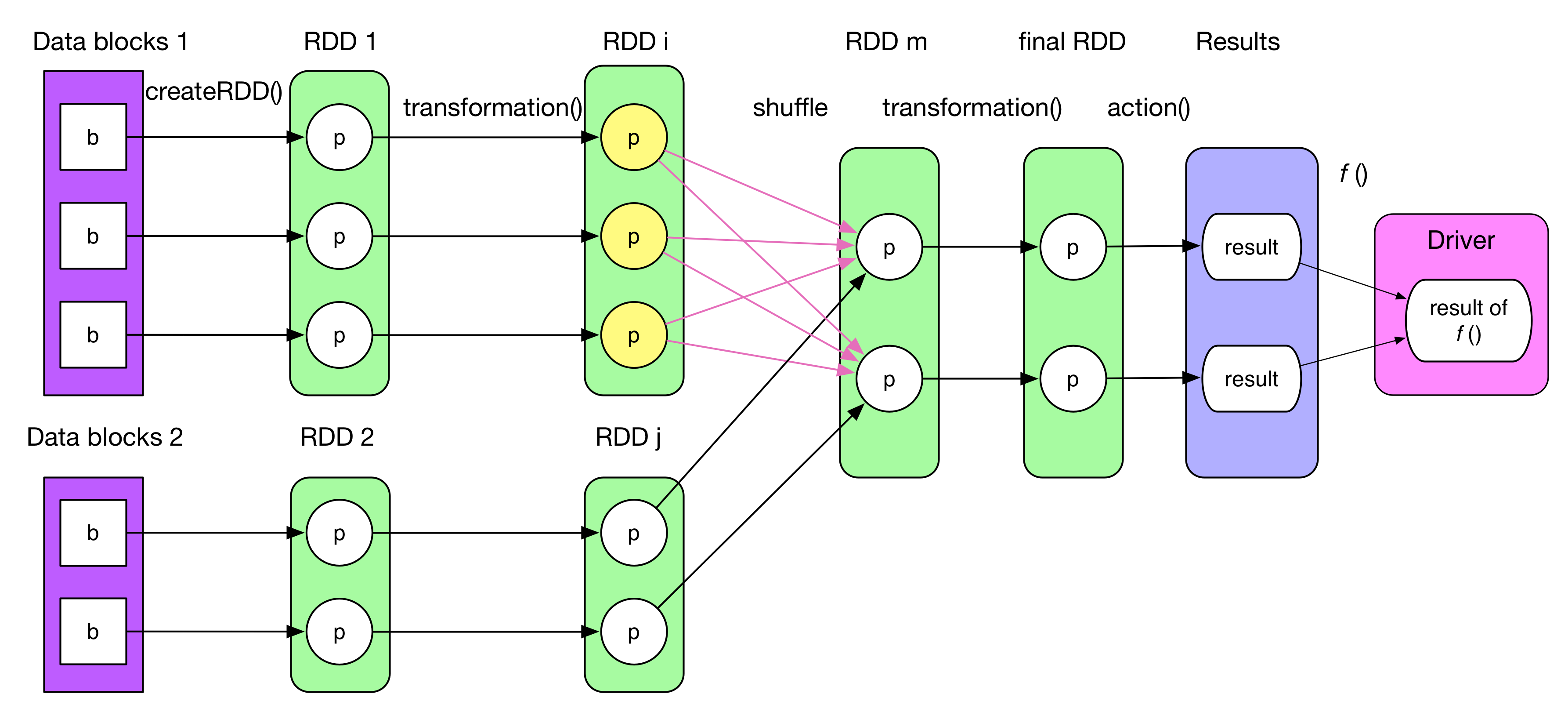
上記の図は一般的なジョブのLogicalPlanを示したもので、最終的な結果を算出するまでに4つのStepからなる。
最初のRDDを何かしらのデータソース(メモリ、ローカルファイル、HDFS、HBase etc..)から生成する。尚、createRDDは前章のparallelizeと記述された箇所と動作としては同じ。
RDDに対する変換オペレーション群はtransformation()として記述される。各transformation()は1個、または複数のRDD[T]を生成する。(TはScalaの型)
もしTが(K, V)というKeyとValueのペアだった場合、Kはコレクション型(ArrayやList等)を設定することは出来ない。理由は、コレクション型の場合Partitionを定義して分割することが困難となるため。
actionと記述されるアクションオペレーションは最後のRDDに対して実行され、各Partitionから結果を生成する。
各結果はDriverプログラムに送信され、f(List[Result])が最終的結果として計算される。例えば、countはactionとsumの2ステップを経る。(各RDDでactionを実行して要素数をカウントし、Driverに送信して合計値計算)
RDDはcache/persist/checkpointメソッドを実行することでメモリ上にキャッシュするか、ディスク上に保存することが出来る。Partition数は基本はユーザによって指定される。2RDD間のPartitionのマッピングは1:1 or M:Nの2種類がある。上記の図の中では両方のパターンが記述されている。
Logical Plan
Sparkのコードを書いている最中に実装者は頭の中でLogicalPlan(例えば、いくつのRDDが生成されるか)を思い浮かべているかもしれない。だが、実際は更に多くのRDDが実行中に生成されていることが多い。
LogicalPlanの生成方法を明確にすることで、与えられたSparkProgramにおいていくつRDDが生成されるか、といった質問にも答えられるようになるだろう。
どのようにRDDが生成されるのか?
どのような種類のRDDが生成されるのか?
どのようにRDD間が接続されるのか?(例えば依存関係にあるRDD)
1. どのようなRDDがどうやって生成されるのか?
transformationは基本は新たなRDDを一つ生成するが、いくつかのtransformationでは複数のフェーズに分けて演算が行われたり、サブtransformationを含むため複数のRDDを生成している。それが考えているよりも多くのRDDが生成される理由となる。
LogicalPlanは言ってしまえば演算の連鎖とも言い表すことが出来る。あらゆるRDDはcompute()メソッドを保持しており、前のRDDかデータソースから取得した入力レコードを基にtransformation()を実行して新たなレコードを出力することが出来るためである。
どのようなRDDがtransformation()の実行によって生成されるかを知るために、基本的なtransformation()に対してどのようなRDDが生成されるかを記述する。
transformation()がSparkサイドで持つ意味について学ぶために、まずは各transformation()の詳細について下記の表に記述した。iterator(split)のカラムはPartition中の各レコードに対してどのように処理が行われるかを記述している。
下記の表の中にはいくつかブランクになっている個所があるが、それは複雑なtransformation()となっており、複数のRDDを生成するためである。
詳細はこの後記述する。
| Transformation | Generated RDDs | Compute() |
|---|---|---|
| map(func) | MappedRDD | iterator(split).map(f) |
| filter(func) | FilteredRDD | iterator(split).filter(f) |
| flatMap(func) | FlatMappedRDD | iterator(split).flatMap(f) |
| mapPartitions(func) | MapPartitionsRDD | f(iterator(split)) |
| mapPartitionsWithIndex(func) | MapPartitionsRDD | f(split.index, iterator(split)) |
| sample(withReplacement, fraction, seed) | PartitionwiseSampledRDD | PoissonSampler.sample(iterator(split)) BernoulliSampler.sample(iterator(split)) |
| pipe(command, [envVars]) | PipedRDD | |
| union(otherDataset) | ||
| intersection(otherDataset) | ||
| distinct([numTasks])) | ||
| groupByKey([numTasks]) | ||
| reduceByKey(func, [numTasks]) | ||
| sortByKey([ascending], [numTasks]) | ||
| join(otherDataset, [numTasks]) | ||
| cogroup(otherDataset, [numTasks]) | ||
| cartesian(otherDataset) | ||
| coalesce(numPartitions) | ||
| repartition(numPartitions) |
2. どのように複数RDD間のデータ依存が生成されるのか?
この質問は3個の小さな質問に分割される。
- 対象のRDDは1個の親RDDに依存するのか?それとも複数の親RDDに依存するのか?
- RDDにはいくつのPartitionが存在するのか?
- 対象のRDDと親RDDの関係はどうなっているのか?対象RDDの1個のPartitionは親RDDの1個のPartitionに依存するのか?それとも複数のPartitionに依存するのか?
2個目の質問への回答としては、Partition数はユーザによって指定されるが、指定がない場合、子RDDの保持するPartition数は依存する親RDDの中で最も多いPartitionを持つRDDのPartition数と同一の値となる。
3個目の質問への回答は複雑になる。何故なら、transformation()のセマンティクスを考える必要があるため。異なるtransformation()は異なるデータ依存性を持つ。例えば、map()は1:1の対応を持つtransformation()だがgroupByKey()はShuffledRDDを生成し、ShuffledRDDの各Partitionは親RDDの全てのPartitionに依存している。別のtransformation()では、更に複雑になるパターンもある。
Sparkにおいては下記の2種類のRDD間のPartition依存が存在している。
- 1.NarrowDependency (e.g., OneToOneDependency and RangeDependency)
子RDDの各Partitionは親RDDのいくつかのPartitionに依存する。FullDependencyと書いた場合、子Partitionは親Partitionの全体に依存する。
- 2.ShuffleDependency (or Wide dependency mentioned in Matei's paper)
子RDDの複数のPartitionが親RDDのPartitionに依存するというパターン。PartialDependencyと書いた場合、各子Partitionは親Partitionの一部の値に依存する。
例えば、map()はNarrowDependencyを示し、join()は基本はWideDependencyを示す。
また、子Partitionは親RDD中の1Partitionと、別の親RDDの1Partitionに依存するパターンもある。
参考として、NarrowDependencyの場合、子Partitionがその親Partitionに依存するかは子RDDが保持するgetParents(partition i)を用いて取得することが出来る。
ShuffleDependencyの場合、MapReduceのShuffleDependencyと同じ構成となっている。(Mapperが各Partitionの値を出力し、各Reducerが全ての必要Partitionの値をhttp.fetchで取得)
この2種類の依存関係は下図のように表わされる。
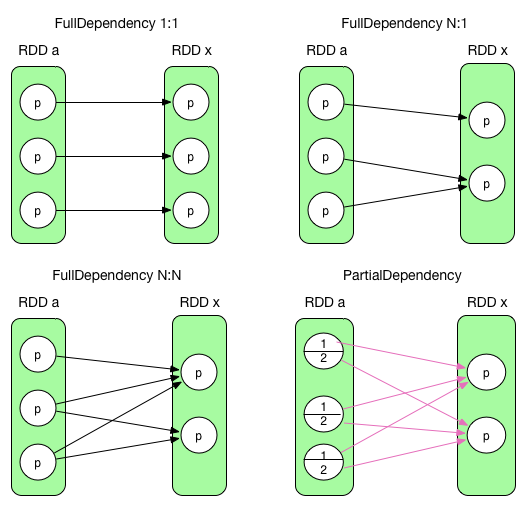
定義からすると、最初のケースがNarrowDependencyで、最後のケースがShuffleDependencyになる。
追記しておくと、左下のケースはN:N NarrowDependencyだが、レアケースとなる。ShuffleDependencyとも似てはいるが、これはFullDependencyである。これはいくつかの特殊なtransformation()群でのみ生成される。NarrowDependencyはSparkにおいて本質的には各子Partitionはたかだか1個の親Partitionに依存する物のため、ここではこの特殊ケースは扱わない。
まとめると、Partition間の依存性は下記のパターンがある。
- NarrowDependency (black arrow)
- RangeDependency => only used for UnionRDD
- OneToOneDependency (1:1) => e.g., map(), filter()
- NarrowDependency (N:1) => e.g., co-partitioned join()
- NarrowDependency (N:N) => a rare case
- ShuffleDependency (red arrow)
この章ではこれ以降、NarrowDependencyを黒矢印で、ShuffleDependencyを赤矢印で記述する。
NarrowDependencyとShuffleDependencyの特徴はPhysicalPlanを作成するのに必要になるが、詳細は次の章で述べる。
3. どのようにRDD中のレコードは計算されるのか?
OneToOneDependencyの場合、下記の図のように示される。
だが、Partition間の関係は1:1であっても、それは各Partition中のRecordを1レコードずつ処理することとイコールではない。
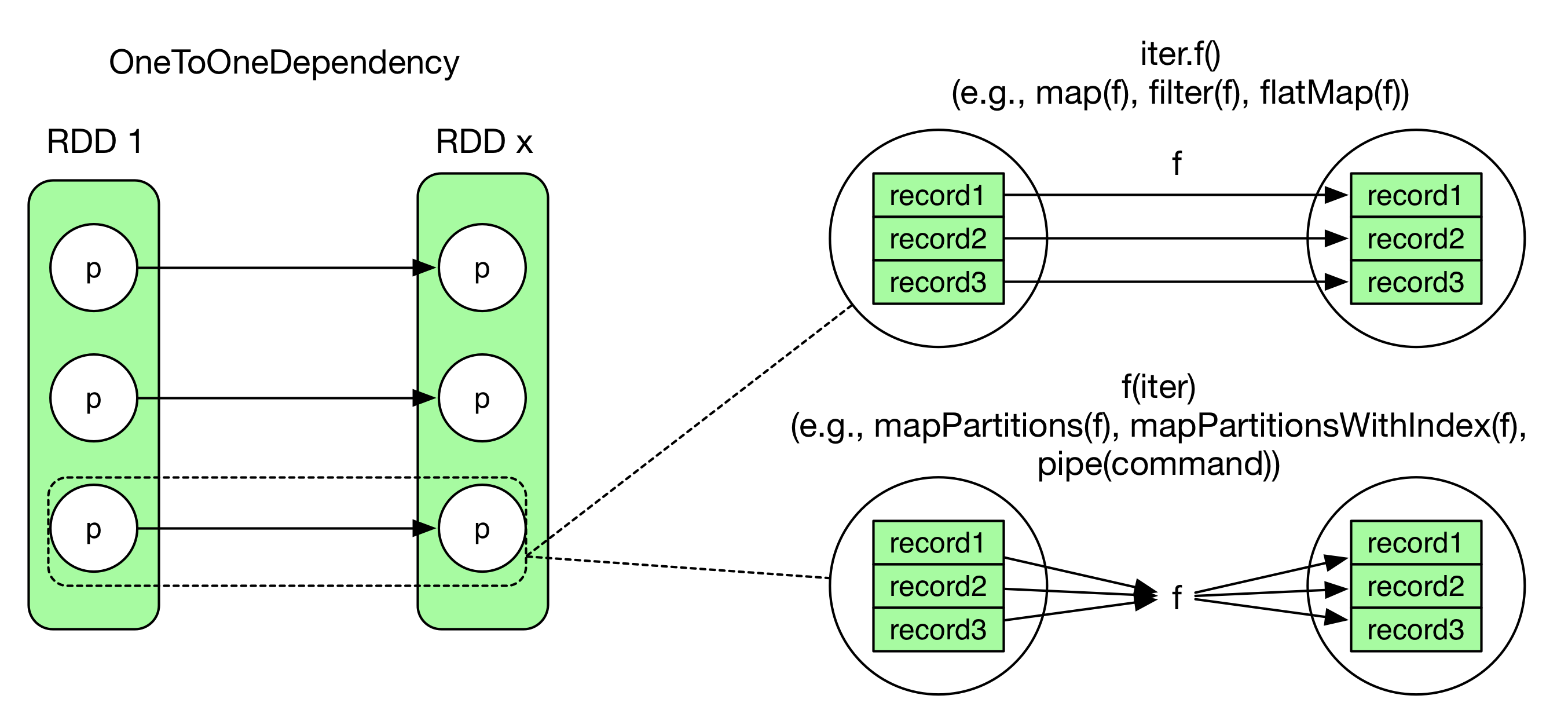
図の右側に示した2パターンの違いについては下記のソースコードスニペットとして示すことが出来る。
Code of iter.f():
int[] array = {1, 2, 3, 4, 5}
for(int i = 0; i < array.length; i++)
output f(array[i])
Code of f(iter):
int[] array = {1, 2, 3, 4, 5}
output f(array)
4. 基本のPartition間の依存を図示してみると?
1) union(otherRDD)
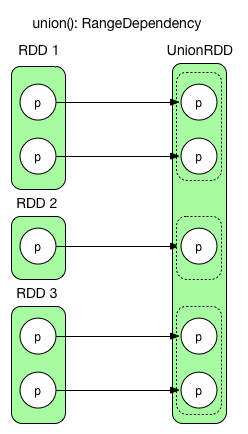
union()は単純に2個かそれ以上のRDDを結合するのみ。union()では各Partition中のデータは変更されない。RangeDependency(1:1)は元のPartitionを再取得するのを容易にするために、元のRDDのPartition間の区切りをそのまま維持する。
2) groupByKey(numPartitions)
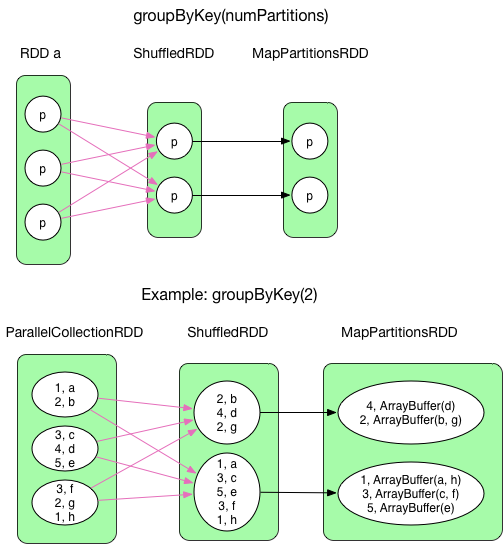
既に前groupByKeyのデータ依存について述べてるが、ここではより明確に記述する。
groupByKey()は同じキー値を持つレコードをShuffleによって集約する。
そのため、ShuffledRDDに対するcompute()関数は各Partitionに必要な必要なデータを取得し、後段のmapPartition()に対してOneToOneDependencyと同じようにデータを流す。最終的に、ArrayBufferがIterableにキャストされた上で後のRDDからアクセス可能となる。
groupByKey()はMapSideCombineはデータ量が削減されない上、全Mapperの出力データをHashTableに入れ込むことが必要になり、データ量が溢れる関係上実施していない。
ArrayBufferは基本的にはCompactBufferが使われる。CompactBufferはArrayBufferに似たappend-onlyなバッファとなっており、小規模バッファにおいてメモリを有効活用することが出来る。
3) reduceyByKey(func, numPartitions)
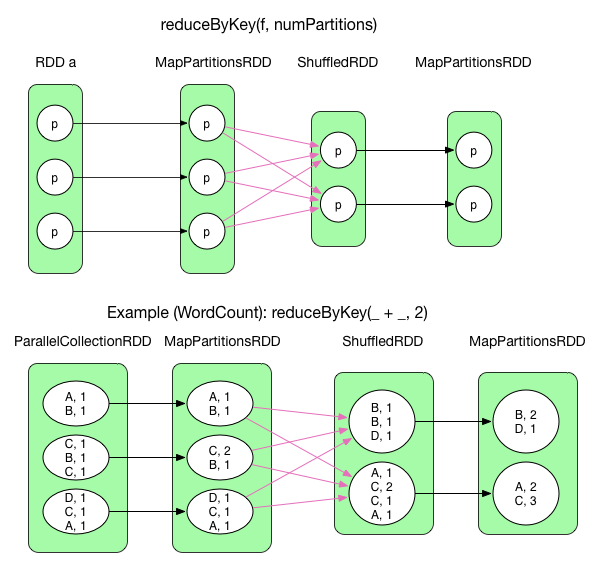
reduceByKey()はMapReduceでのreduce()とにており、データフローとしては同等となっている。redcuceByKey()はデフォルトではshuffle前にMapSideCombineを実行している。shuffle後、再度各MapPartitionに対してaggregateを実行し、結果としてはMapPartitionsRDDが生成される。
4) distinct(numPartitions)
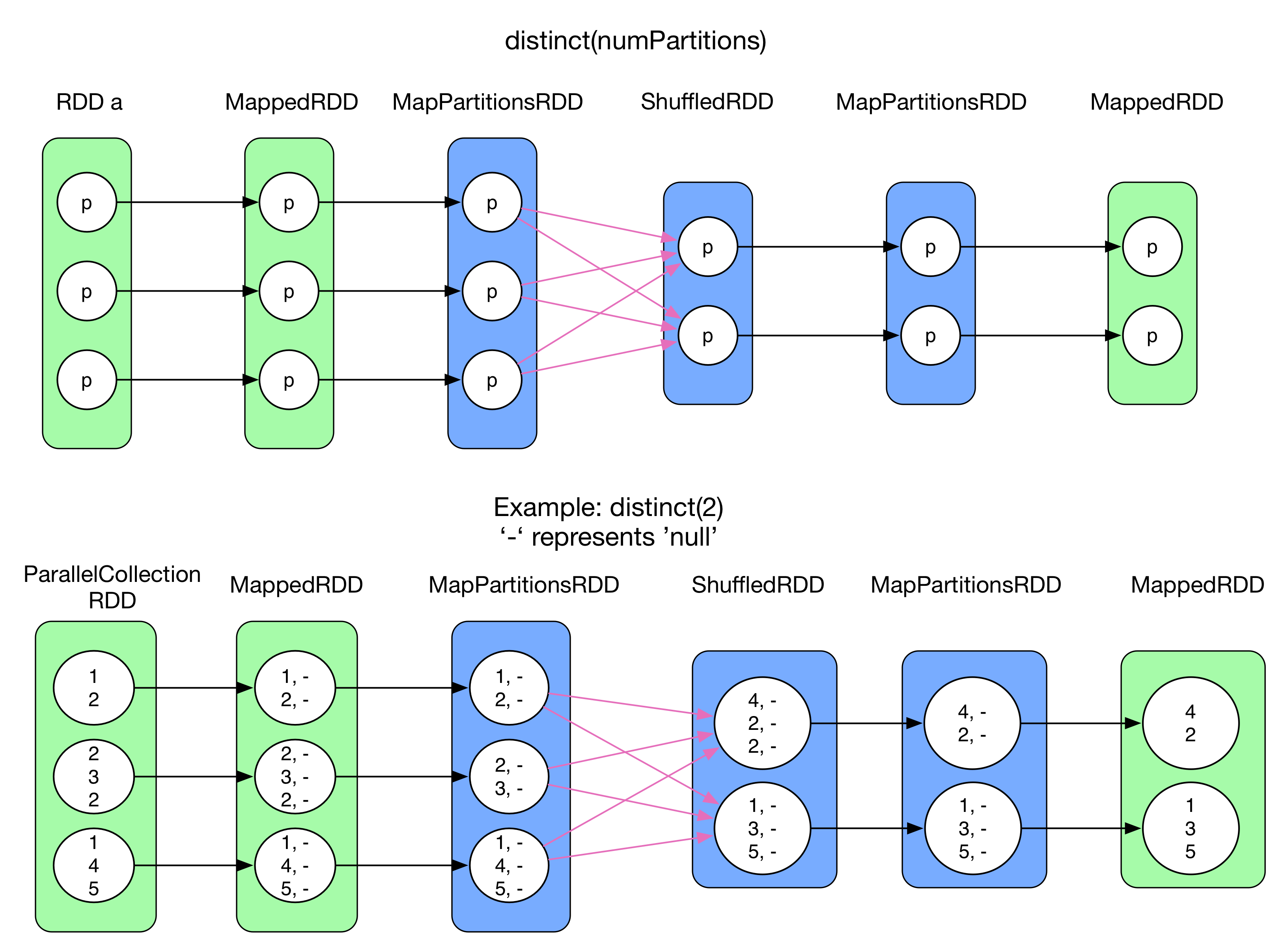
distinct()はRDD中の重複したレコードを除去することを目的としている。異なるPartition中に重複したレコードが存在する場合、除去するためにはshuffle + aggregationが必要となる。だが、shuffleを実行するにはRDDの型がRDD[(K,V)]である必要があるため、元のRDDが単一の値しかもたないレコード(例えば、RDD[Int])だった場合、一度map() transformを適用しての形式に変換している。その後、reduceByKey()はいくつかのshuffle処理(mapSideCombine => reduce => MapPartitionsRDD)を実行する。最終的に形式のレコードからキーのみを抽出し、元のRDDの型に合わせている。上記の図の中では純粋にreduceByKey()部を示しているのは青のRDDのみとなっている。
5) cogroup(otherRDD, numPartitions)
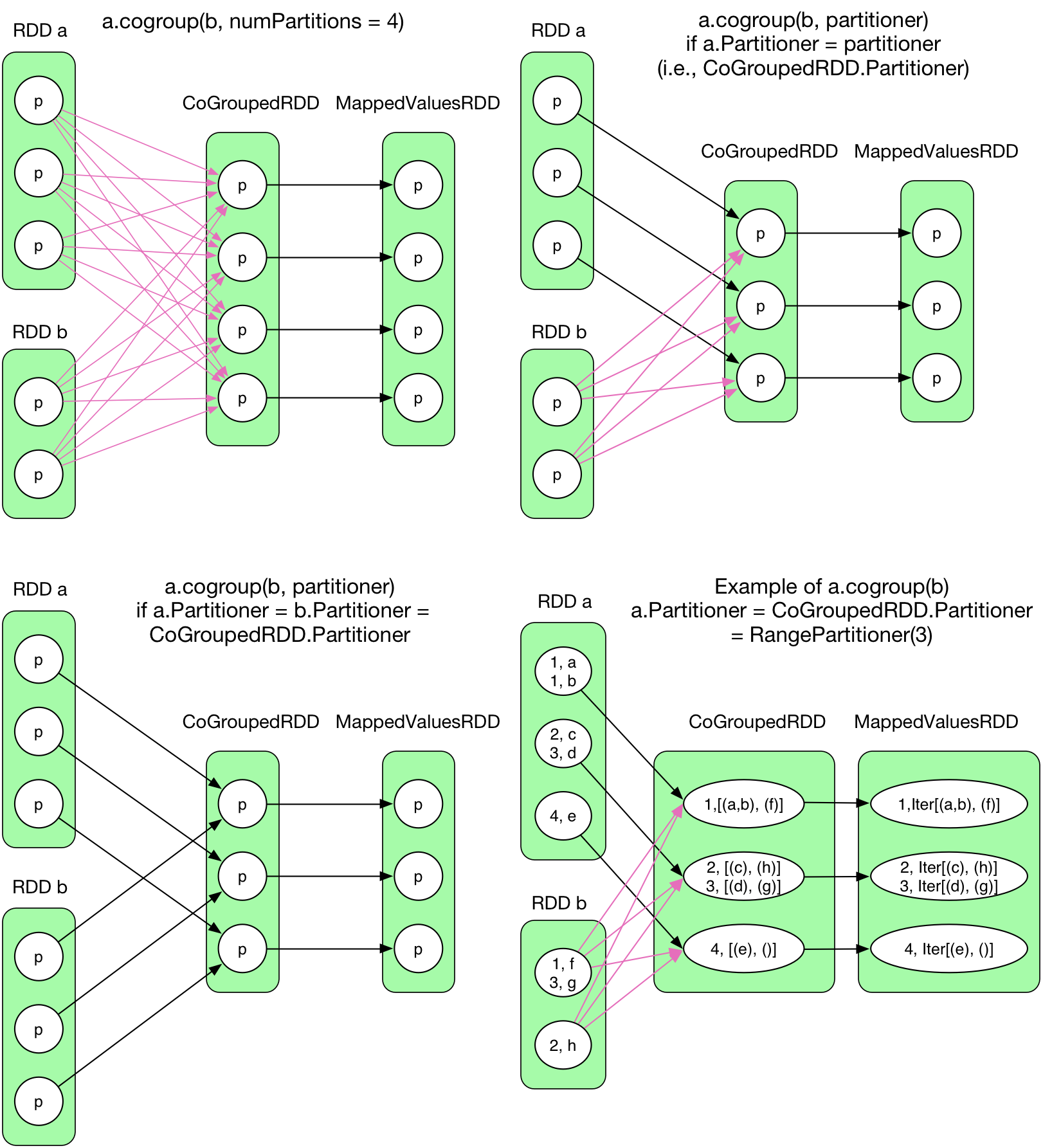
groupByKey()と異なり、cogroup()は2個かそれ以上のRDDを統合している。
そのため、質問が生じる。親RDDとCoGroupedRDDのPartition間の依存はShuffleDependencyなのか、OneToOneDependencyなのか? この質問は以下の2つの要素に依存するため、いささか複雑になる。
パーティション数
CoGroupedRDDのPartition数はユーザによって指定され、親となるRDD aとRDD bとは関係がない。
だが、CoGroupedRDDのPartition数がRDD aやRDD bと異なる場合、Partition依存はOneToOneDependencyでは解決できない。
Partitionerの型
cogroupを行う際にデータをどう配分するかのPartitionerもユーザによって指定される(デフォルトはHashPartitioner )。もしRDD a、RDD b、CoGroupedRDDのPartition数が同じであってもPartitionerが違う場合、Partition間の依存は OneToOneDependencyに出来ない。
そのため、上記の図の最後のパターン(RDD a is RangePartitioner, RDD b is HashPartitioner, and CoGroupedRDD is RangePartitioner with the same # partition as RDD a)について考えてみる。RDD a側の各Partition中のレコードは対応するCoGroupedRDDに対して送ってしまって問題ない。だが、RDD bの各Partition中のレコードはCoGroupedRDDに併せてShuffleして対応ずける必要がある。
結論として、OneToOneDependencyは親RDDとCoGroupedRDDのPartitionerとPartition数が同一である場合のみ適用される。そうでない場合、ShuffleDependencyとなる。これ以上の詳細はCoGroupedRDD.getDependencies()のコードを読んでほしい。
SparkはどのようにしてCoGroupedRDDの各Partitionの複数の依存Partitionを維持しているのか?
まずはじめに、CoGroupedRDDは全ての親RDDをRDDsに入れ、下記の処理を行う。
Foreach rdd = rdds(i):
if the dependency between CoGroupedRDD and rdd is OneToOneDependency
Dependecy[i] = new OneToOneDependency(rdd)
else
Dependecy[i] = new ShuffleDependency(rdd)
最終的に上記のコードは各親RDDに対する依存性配列であるdepsを返す。
Dependency.getParents(partition id) は Partitions: List[Int] は与えられた依存性に対応するPartitionを返す。
getPartitions()メソッドはRDDにいくつのPartitionが存在しており、どのようにシリアライズ化されるかも返す。
6) intersection(otherRDD)
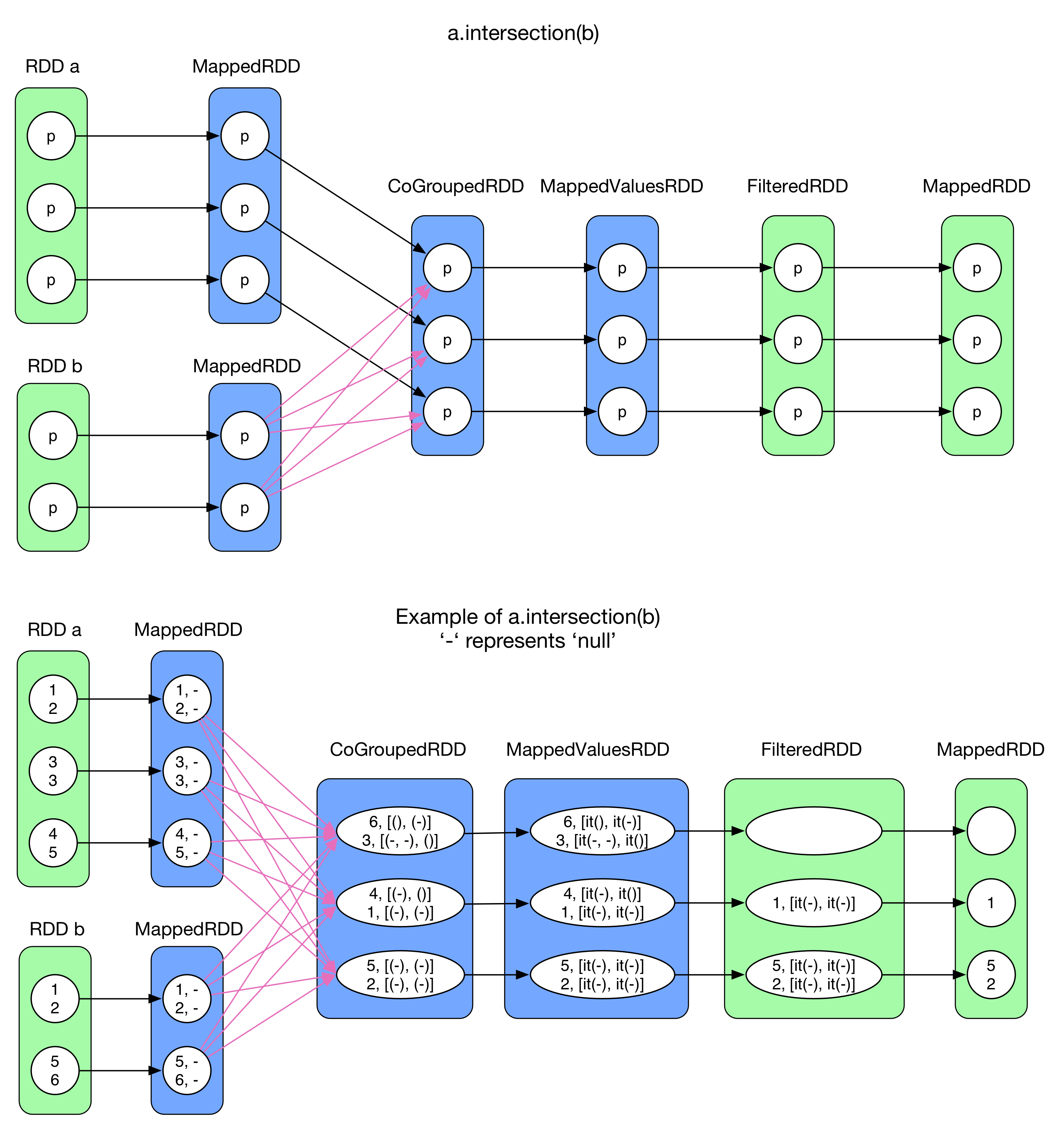
intersection()はRDD aとRDD bの間に存在する共通要素を抽出することを目的としている。はじめにRDD[T]をRDD[(T,null)]に変換する。(そのため、Tはコレクション型であってはいけない)その後、a.cogroup(b)を実行(青い部分)する。次にFilterを行い、RDD a起源の要素とRDD b起源の要素の両方が存在していない要素をフィルタリングする。最終的にキー部分のみを抽出したMappedRDDに変換を行う。
7) join(otherRDD, numPartitions)
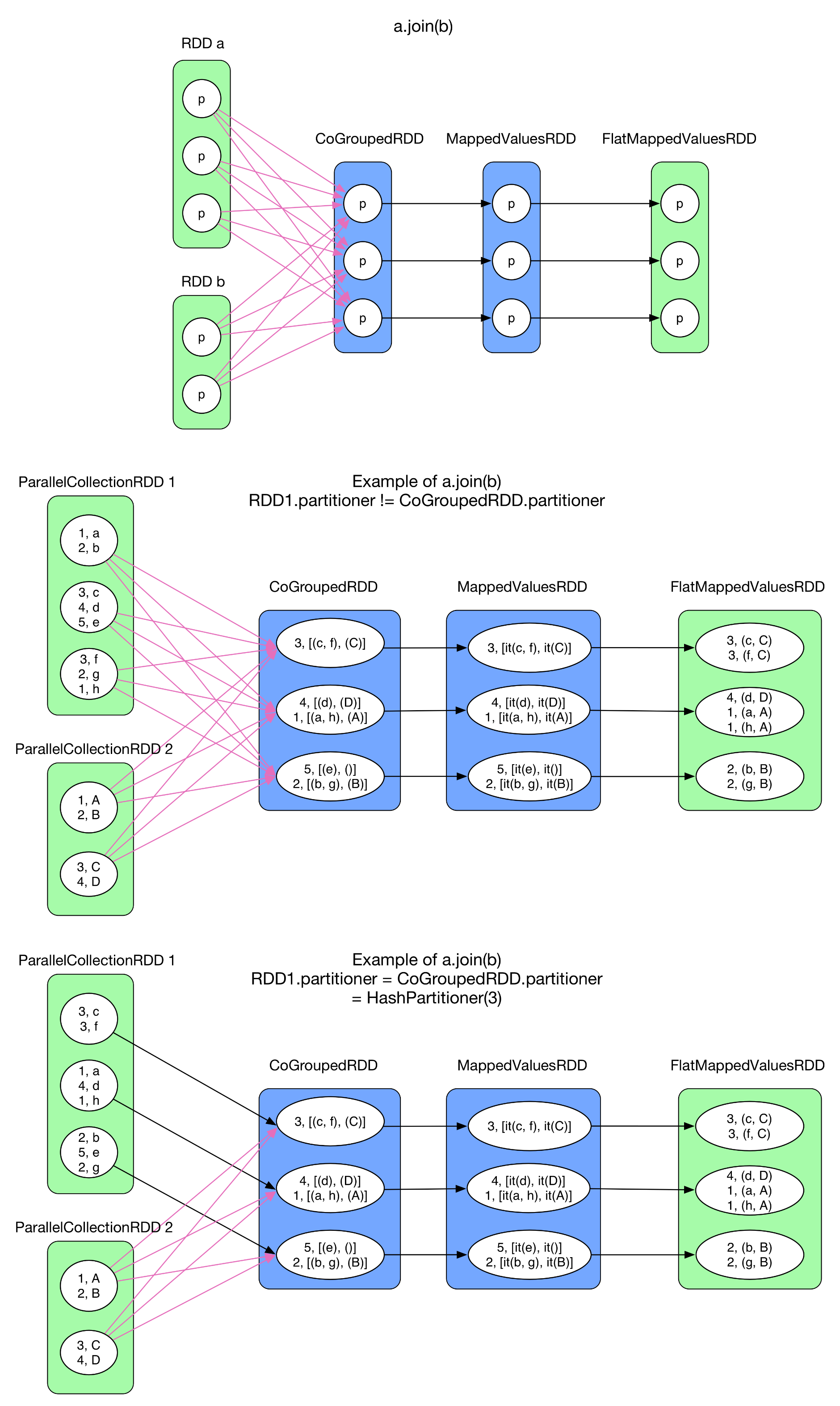
join()はKey値とValue値を保持するRDD(RDD[(K,V)])を2個もちいてSQLのjoinのように結合を行う。処理としてはintersection()と同じようにはじめにcogroup()処理を呼び出し、各要素をIterableにしたRDD[(K, (Iterable[V1],Iterable[V2]))]を生成する。その後、各レコードが保持する要素の直積集合をflatMap()を用いて生成する。
図中では2パターンの例を示している。
1個目の例はRDD 1とRDD 2がRangePartitioner、CoGroupedRDDがHashPartitionerを使用しているため、各Partition間の依存がShuffleDependencyになったパターン。2個目の例がRDD 1がCoGroupedRDDと同一のPartition数、Partitionerだったため依存がOneToOneDependencyとなったパターン。もし仮にRDD 2も同一のPartition数、Partitionerだった場合、全依存がOneToOneDependencyとなる。このようなケースのJoinはhashjoinと呼ばれる。
8) sortByKey(ascending, numPartitions)
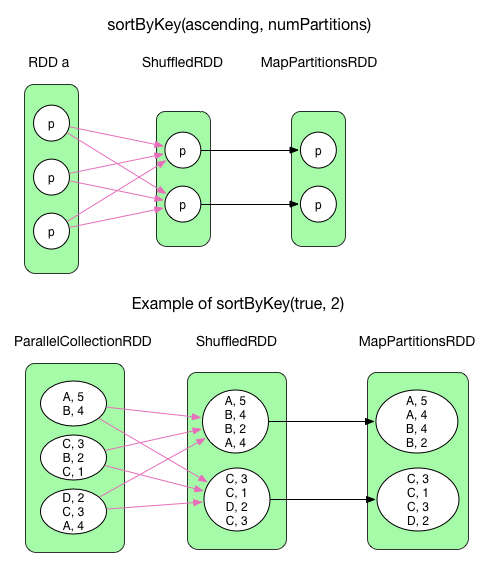
sortByKey()はRDD[(K,V)]形式のRDDをKey値でソートする。ascendingは当然わかる通りBooleanフラグ。sortByKey()はRangePartitionerで区切ったShuffledRDDを生成する。RangePartitionerはRDD中の各Partitionの区切りを設定する。例えば、1Partition目がA-B、2Partition目がC-Dのように。各Partition内ではレコードはKey値によってソートされている。最終的に、ソートされたレコードを保持しているMapPartitionsRDDを出力している。
sortByKey()は各レコードをArrayを用いてソートを行う。
9) cartesian(otherRDD)
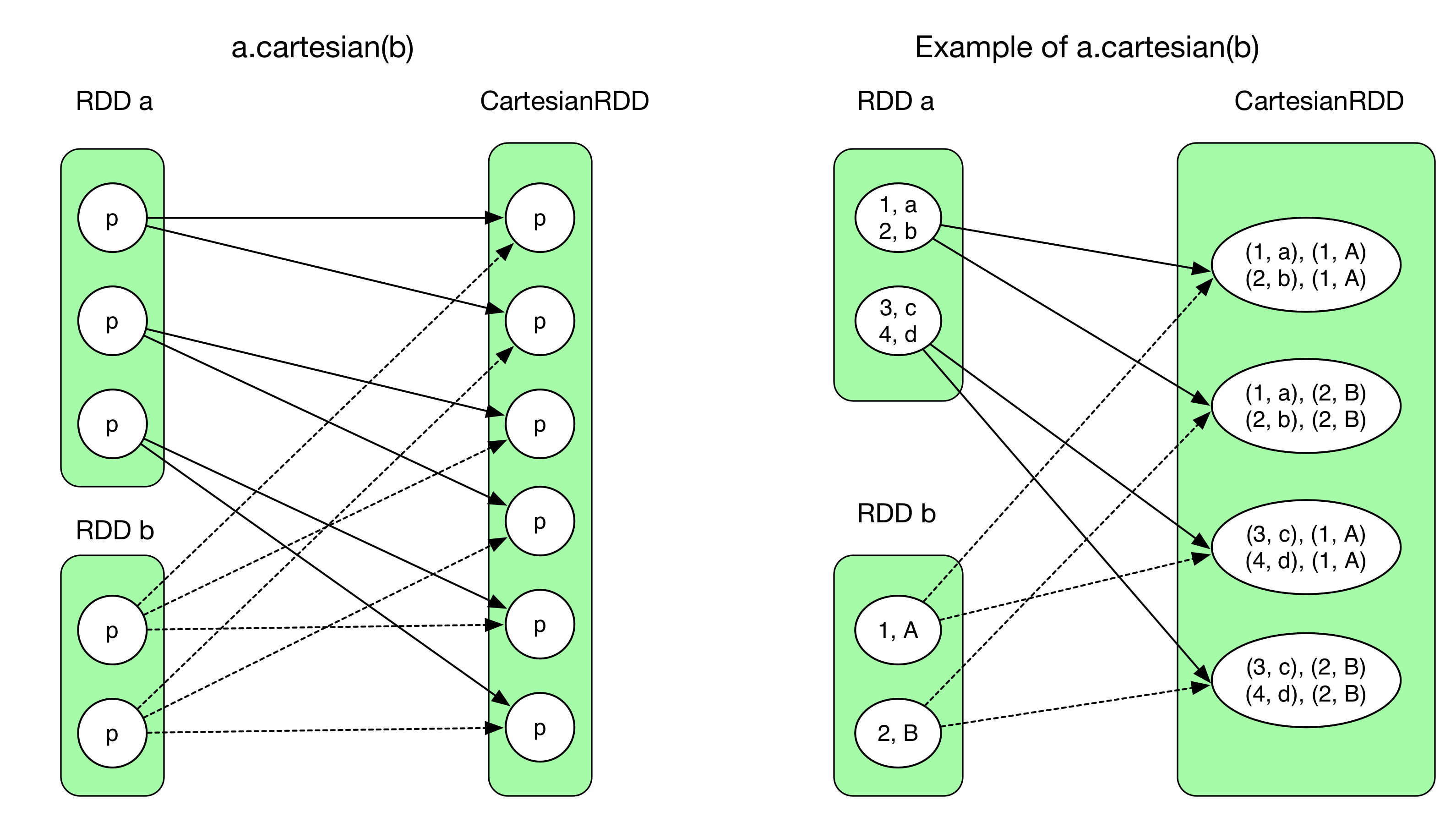
Cartesian()は2個のRDDの要素同士の直積集合を保持するRDDを返す。出力されるRDDのPartition数は(RDD aのPartition数)* (RDD bのPartition数)となる。
依存関係で注意するべきこととして、結果の各Partitionは2つの親RDDの全要素に依存している。そのため、全てNarrowDependencyの構成となっている。
CartesianRDD.getDependencies() はrddsとして Array(RDD a, RDD b) を返す。
尚、CartesianRDDのi番目の依存Partitionは下記のようになる。
a.partitions(i / #partitionA)
b.partitions(i % #partitionB)
10) coalesce(numPartitions, shuffle = false)
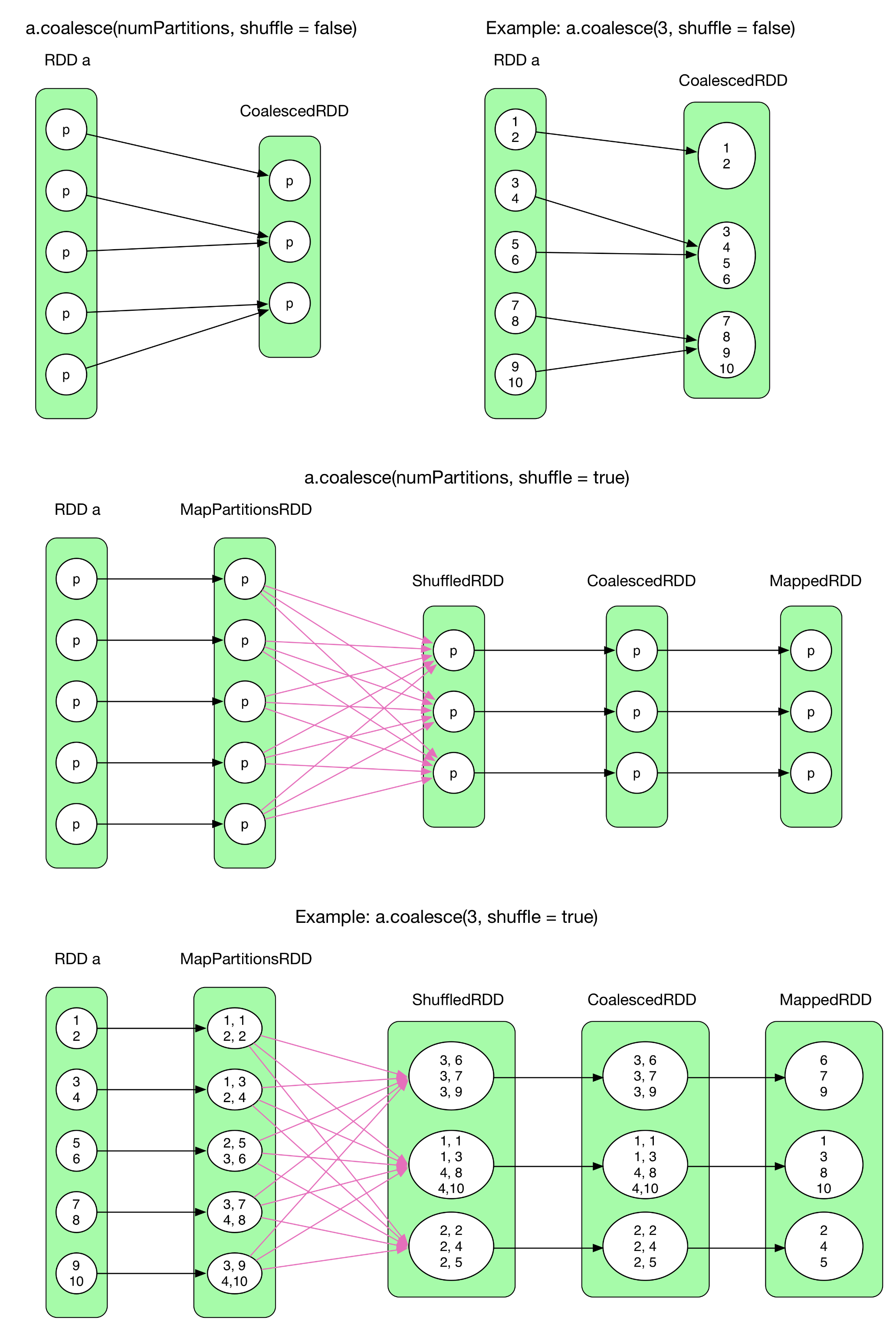
coalesce()はPartitionの再構成を行う。例えば、Partition数を5>3に減らしたり、5>10に増やしたりすることが可能。
ただし、注意すべき点としてはshuffleをfalseにしていた場合、Partition数を増やすことは出来ない。必ずPartition数増加にはshuffleが必要になるため。
coalesce()を理解するためにCoalescedRDDのPartitionと親Partitionの関係を知る必要がある。
coalesce(shuffle = false)のケースの場合shuffleが出来ないため、単純にRDD中のPartitionをマージするのみで、子Partitionは親Paritionの全要素に対しえ依存する。実際の所、Partitionの有効なグループ化については多くの要素や考えることがある。例えば、Partition数の保持するレコード数、局所性、Partition間のバランス等。これらを達成するためにSparkは複雑なアルゴリズムを保持している。(ここでは説明しないが)
coalesce(shuffle = true)としてshuffleが有効化されている場合、coalesceは単純にRDDの全レコードを結果であるN個のPartitionに下記のようにして分割する(ラウンドロビンのようなアルゴリズムとなっている。)
各Pertition中の全レコードに対して増加する数値をキーとして割り振る。
割り振ったキーをHashPartitionerで分割すると各レコードが異なるPartitionに均等に割り振られる。
図中の2番目の例においてはMapPartitionRDDの左側の要素が割り振ったキーとなっている。割り振られるキーの初期値は (new Random(index)).nextInt(numPartitions) で算出される。ここでindexは元のRDDでのPartitionのインデックス番号、numPartitionsはCoalescedRDDのPartition数となっている。キーは1ずつ増加させて割り振る。Shuffle後、ShffledRDDの各レコードは均等に分散されている。最終的にキーは除去されて元の値に戻される。
11) repartition(numPartitions)
中身はcoalesce(numPartitions, shuffle = true)と同一。
共通的な基本処理
combineByKey()
これまで複数のLogicalPlanについてみてきたが、いくつかのものは非常に似通っている。それは皆同じshuffle + aggregateのふるまいを持つためである。
transform実行時にShuffleDependencyの基となるRDDはRDD[(K,V)]となり、変換後のRDDにおいて同じキーを用いて統合する際に異なるアルゴリズムを用いて行うという差分があるのみとなっている。
実際、複数のtransformation()(例えばgroupByKey()、reduceBykey())では論理的に同じタイミングでaggregateを実行している。そのため、共通点はaggregate()とcompute()を同時に実行することからくる。SparkではcombineByKey()を to aggregate() + compute()の処理の実装として用いている。
combineByKey()の定義は下記のようになっている。
def combineByKey[C](createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)]
上記のコードの中には3個の重要なパラメータがある。
- createCombiner, 各Valueを結合(例えば1個目の要素を単一要素のリストとして結合可能なものに変換)
- mergeValue, 各Value値と結合済みの値を結合(例えばリストに対して値を追加)
- mergeCombiners, 結合済みの値を結合(例えばリスト同士を1つのリストに結合)
上記のパラメータは以下のように用いられる。
(K, V)の値を保持するレコード群がcombineByKey()に渡された場合、最初の要素をcreateCombinerを用いてリスト化する。
2個目以降の値はmergeValueを使用してリスト化した要素に対して1個ずつ追加していく。
sumを例として考えてみると、mergeValueは combiner = combiner + record として示せる。
このようにして、全てのレコードを1個の値にマージしていく。
もし異なるキーを持つレコードが投入された場合、combineByKey()はcreateCombinerを用いて再度異なるcombinerを生成する。最終的な結果はマージされた値同士をmergeCombinersを用いてマージすることで生成される。
Conclusion
ここまでで、ジョブ中のLogicalPlanがどのようにSparkにおいてPartitionに分割され、依存性を関連付けて処理されるかについて述べてきた。
tranformation()によってどのようなRDDが生成されるか決まり、一部のtranformation()では他のtranformation()を再度利用しているものもあった。(例えばcogroup)
RDD間の依存はtranformation()のセマンティクスに依存している。例えば、cogroup()で生成されるCoGroupdRDDがどのような依存構成を取るか、等。
RDD中のPartition間の関連はNarrowDependencyとShuffleDependencyで示される。
前者はFullDependencyで後者はPartialDependencyとなる。
依存性はtransformation()中のパラメータ次第で変化するケースもあった。例えば、RDDのPartition数とPartitionerが等しい場合のみNarrowDependencyになる等
データフローの視点で言えば、MapReduceはmap() + reduceByKey()というモデルとなる。厳密に言えばMapReduceのreduce()reduceByKey()より高機能ではあるが。
Shuffleの設計実装の詳細については今後の章で記述する。
まとめ
SparkInternalsのはじめの2章を読んでみましたが、読むごとにどのように動いているかの概要が見えてきますね。
特に2章のRDDに対するTransformationについてはわかっているかいないかで理解に大きな違いが出てくるのではないかと思います。
さすがに7章全てを1投稿にまとめるのは無理でしたが、ここまででもデータフローのイメージは1段階は出来るようになるかと。
これから年末に入っていくので、折を見て続きも訳してみようと思いますが、ひとまず今回はここまでです。
それでは、皆さん、良い年末を!