この学習計画について更新しています。
「文学系の人はデータ分析に向いていますか」
「プログラミング経験がありませんが、データアナリストになれますか」
「データ分析を勉強するなら、RとPythonを勉強しなければならないですか」
などはよく聞かれる話です。
実際にデータ分析は皆さんの想像以上に難しくありません。私の知り合いにHRまたはマーケティングからデータ分析に転職した人は少なくありません。データ分析において、データ分析ツールとプログラミングなどのデータ分析手法より、問題点に対する認識、分析の考え方と流れおよび結果の解説は重要なものです。
かといって、短時間で優秀なデータアナリストになれるわけではありません。データ分析の基礎知識を振り返えて、十週間ぐらいの学習計画に要約しました。
学習計画
データ分析の考え方
Excel上級
データベースとSQL入門
統計学
データ分析ソフトの運用
データ可視化
ビジネスフレームワーク
Python/R言語
ビジネス理解と指標設計
グロースハッカー(Growth Hacker):データを成長の原動力とする
第一週:データ分析の考え方を養う
なぜデータ分析の考え方は重要ですか?
例えば、問題点を分析する際に、考え方がなければ、どこから着手すればいいのかわからないでしょう。
従って、データ分析の考え方を養う必要があります。このように、問題にあった時、素早く分析の切り口を見いだせるのです。
よく使われるデータ分析の思考法:
1)ロジックツリー
問題を分類して、分解して、全面的に問題を考えること。まず思いついた要素を書いて、それからロジックツリーにまとめます。マインドマップで自分の考え方を記すのを推薦します。
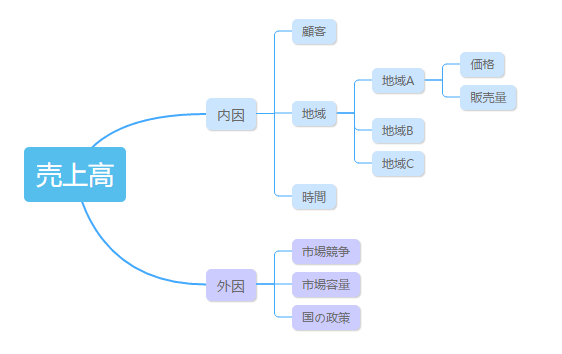
これは私の使用しているマインドマップのソフトです。
2)数式化
構造化してから、要素間の相互関係を見つけて、+、-、×、÷などの計算をしてみます。これらの要素を数値化して分析することで、仮説を検証することができます。
3)ビジネス理解
データ分析の一つの目的は業務状況を踏まえて、その具体的な状況と結び付いて分析を行って、それに分析の結果をビジネスに運用することです。「構造化+数式化」した結論は所詮現象であり、結果を起こす原因を説明しません。だから、ビジネス観点から問題点を考えて、結果の背後に潜む原因を究明するのも大事です。
ビジネスの理解を深めるステップ:①業務部門との交流を強化する②ビジネス(業務部門と顧客)観点から考える③経験を積み重ねる
また、このようなデータ分析の考え方は特定の業務シーンで、象限法、多次元法、仮説法、インデックス法、28法、対比法、ファンネルなどのデータ手法と結合することが多いです。
データ分析の思考法は、物事や問題の視点を構築するのに役立つ視点や考え方の仕組みを提供することです。思考法の学習と訓練によって、成功の可能性を増やします。
関連記事:
データ分析に欠かせない五つの考え方【データ分析手法をたくさん知っても活用できない根本理由】
第二週:Excel上級
Excelの学習はステップバイステップ(Step by step)の過程です。
基礎:簡単な表のデータ処理、フィルタリング、ソート
関数と公式:共通関数、高度データ計算、配列式、多次元参照、function
可視化グラフ:グラフィックアイコン表示、高度チャート、チャートプラグイン
ピボットテーブル、VBAプログラム開発
私のやり方は、基礎知識をおおむね勉強した上で、事例で練習することです。 よくどのようにエクセルの活用で問題を解決するかを考えてください。チャートプラグインの活用も必要とされます。
1) データ分析のテンプレートの作成に必ず身に着けるExcel関数:
日付関数:day,month,year,date,today,weekday,weeknum。日付関数はデータ分析に必須な関数です。それによってデータの表示を制御し、指定する範囲のデータを検索することができます。
数学関数:product,rand,randbetween,round,sum,sumif,sumifs,sumproduct
統計関数:large,small,max,min,median,mode,rank,count,countif,countifs,average。平均値、最大値、最小値、中央値などはよく使われる関数です。
クエリと参照関数:choose,match,index,indirect,column,row,vlookup,hlookup,lookup,offset。
vlookup関数が使いこなせないと、やや複雑な帳票を作成できません。
テキスト関数:find,search,text,value,concatenate,left,right,mid,len。テキスト関数はデータの整理段階に使用されます。
論理関数:and,or,false,true,if,iferror。
2) ピボットテーブル
ピボットテーブルの役割は、大量のデータをインタラクティブなレポートに転化することです。ピボットテーブルには、以下の重要な機能があります。
小計、平均値、最大値、最小値、自動ソート、自動スクリーニング、自動グループ化、比率、前期比、同期比、カスタム数式
第三週:データベースの原理とSQL
データはどこから取得しますか?——データベースから。
データをどう取り出しますか?——SQL。
入門の段階で、データベースを習熟しなくてもかまいません。常用するデータベースのタイプを知って、そしてデータのクエリ、再エンコーディング、追加および整理をマスターすることが優先です。また、データの並べ替え、データの交差、データの変換、データテーブルのマージなどもマスターしたほうがいいです。データのインポートとエクスポートならほかのツールを利用できます。データベースへの接続には、ODBCやその他のインターフェイスを使用できます。
Progateは、スライドによるレッスンで基礎を学び、オンラインエディタでプログラミングをして実行結果を見ることができます。SQLの学習は三つのコースに分かれて、学習完了後に実践的な演習問題があります。
ここでコアなスキルを挙げます。
1) selectでフィールドを追加し、必要なデータを見出す
select cola,colb,colc into newtable from oldtable wherecola=’x’ and colb is not null;
この文をほとんどのデータの検索に使えます。
「select」の後ろはフォードです。「into newtable」は新しいテーブルに入れることを指します。新しいテーブルがない場合、データを検索します。「where」の後ろは条件です。
select cola from oldtable group by colaもよく使われます。
次はjoin、unionおよび曖昧検索です。
2) alterでフィールドを追加し、削除する
alterでフィールドと主キーの追加と削除を実現でき、とても有用です。
a:フィールドの追加
alter table tablename add colname varchar;
ヌルのフィールドを追加できます。varcharはデータのタイプです。
b:フィールドの削除
alter table tablename drop column colname;
3) updateでデータを更新する
a:一つの固定値に更新する
update table set col=1;
b:ほかのテーブルからデータベースを導入し、更新する
update table set col=tableb.col from tablebwhere table.id=tableb.id;
これは「table」と「tableb」の二つのテーブルのidを関連することです。
関連記事:
第四週:数理統計学
統計学はデータアナリストに必要な基礎知識だといえます。
データを抽出してから、解決すべき問題は:
最も一般的で予測可能な観察は何ですか?
観察の制限は何ですか?
データはどのように見えますか?
以上の問題を解決するには、統計ツールを使う必要があります。統計学をよく利用すれば、分析の深さと専門性を高められます。
従って、第四週に身に着けるべき知識は以下の通り:
-
中心化傾向(中央値、モード、平均)
-
変動(四分位、四分位範囲、異常値、分散)
-
正規化(標準得点)
-
正規分布
-
標本分布(中心極限、標本分布)
-
推定(信頼度、信頼区間)
-
仮説検定
-
t検定
https://bellcurve.jp/statistics/course/
このサイトで統計学の知識(初級編、基礎編、中級編)とオンラインでの練習があります。
第五週:データ分析ソフトの運用
統計学の基礎知識を勉強したうえで、データの分析を開始できます。
第五週にExcel以外の分析ツールをマスターしなければなりません。
ここでSPSS、R、Pythonなどのツールはさておき、まずBIツールを勉強しましょう。BIツールによって、整理されたデータを短時間で分析し、Excelよりよっぽどいい効果を呈します。ほどんどの初心者にとって使いやすいと思います。
また、BIツールでデータの変換と加工もできます。でも、BIツールをあまり上手に使えない場合、やはりSQLで処理したほうがいいです。
第六週:データ可視化
データ可視化は簡単なデータ分析の過程なわけではありません。
どう適当なチャートを選択します?傾向、分布、周期、場所などを考慮しなければいけません。
見た目のいい可視化効果には、色、フォントなどのスタイルを設定する必要があります。
一番重要なのは、レイアウトの設計、つまりテーマ、指標間の関係および可視化の目的を明らかにすることです。
データを可視化するには、以下の四つの方法があります。
-
Excelで通常のチャートを作成します。 ダイナミックチャート、フィルタリング表示などの複雑なものなら、VBAで実現できます。
-
RやPythonなどに、データを視覚化するためのチャートパッケージを利用します。
-
Echarts、HighCharts、D3.jsなどのオープンソースのチャートプラグイン。これはソフトウェア製品とツールを開発する時によく使われる方法です。
-
データ可視化ツール。例えば、FineReportの独自開発のHTM5グラフはほとんどの可視化ニーズを満たすといえます。特に、gis地図マップですごくオシャレな視覚効果を出せます。必要があれば、サードパーティーのEchartsを統合することもできます。
データ分析や可視化ツールについて、【2019年】データ分析・可視化に本気でおすすめのツール30選(ノーコード型ツール含め)をご参照てください。

 資料提供: [FineReport](http://www.finereport.com/jp/?utm_source=Qiita&utm_medium=media&utm_campaign=dataplan&utm_term=fr_top2)
資料提供: [FineReport](http://www.finereport.com/jp/?utm_source=Qiita&utm_medium=media&utm_campaign=dataplan&utm_term=fr_top2)
関連記事:
第七週:ビジネスフレームワーク
象限法、多次元法、仮説法、インデックス法、28法、対比法、ファンネルなどのデータ手法に基づいて、特定の業務シーンには共通なビジネスフレームワークがあります。よく使われるフレームワークはRFMモデル、ファンネル分析、顧客ライフサイクル、バスケット分析です。

関連記事:
データ分析に最低限押さえるべき10つのビジネスフレームワーク
第八週:Python/R言語
データ分析能力の向上と就職活動の成功のために必ずPython/R言語を習得すべきです。
データ解析用のプログラミング言語はPythonとRです。 R言語は、統計分析や描画などに向いています。 Pythonは人気、実用性、使いやすさの点で最高の言語と思いますから、まずPythonの学習をおすすめします。
Pythonに多くのブランチがありますが、ここのテーマはデータ分析なので「Head First Python ―頭とからだで覚えるPythonの基本」をおすすめします。
学習サイトならCode Academyをおすすめします。それはPythonに関する基本知識と練習を含めており、とりあえずすべての練習を完成しましょう。https://www.codecademy.com/catalog/language/python
次に、Numpy、Pandas、Matplotlibの三つのライブラリを身につけます。
Numpyは、Pythonによる科学計算の基本パッケージです。Numpyをよく理解すれば、Pandasなどの他のツールを効果的に利用するのに役立ちます。 N次元配列、インデックス、配列スライス、整数インデックス、配列変換、一般関数、配列によるデータの処理と一般的な統計手法などが含まれます。
Numpy Basics TutorialでNumpyの関数とその使い方調べられます。https://docs.scipy.org/doc/numpy-1.15.0/user/basics.indexing.html
Pandasには高度なデータ構造と操作ツールが用意されているため、Pythonのデータ分析をより迅速かつ容易に行うことができます。series、data frams、axisからのデータの削除、損失データの処理などが含まれます。
Index PandasでPandasを勉強できます。https://pandas.pydata.org/pandas-docs/version/0.22/generated/pandas.Index.html
Matplotlibは強力なPython可視化ライブラリです。 数行のコードで散布図、折れ線グラフ、ヒストグラム、ボックスプロットなどを描画できます。
第九週:業務知識と指標設計
前八週の学習内容から見ると、この計画はビジネス場面のデータ分析を重んじることがわかります。データアナリストとして、短期間で会社や部門のビジネスを理解し、業務の知識をしっかり身に付ける必要に迫られることがよくあります。入門の段階においてまずロジックとデータ分析の能力の向上に力を入れて、それから、通常の業務をこなし、業務知識も習得します。
あとは指標システムの設計です。 ほとんどのデータ分析職に「部署のデータの指標システムの確立と最適化する」という仕事内容があります。 優れたデータの指標システムは、データニーズを迅速に解決できるだけでなく、データの価値を掘り出して、現時点で最も対処すべき問題を反映します。 したがって、今週はビジネス指標を整理する考え方を習得しなければなりません。
関連記事:
小売業:
ECサイト:
第十週:グロースハッカー(Growth Hacker):データを成長の原動力とする
データアナリストとして、会社に貢献するには、まず自分の価値と未来の進路を明確にしましょう。
例えば、最近とても流行っているデータアナリストの一種はグロースハッカー(Growth Hacker)で、仕事がデータの分析でグロースを駆使させることです。

今週、伝統産業とWeb業界におけるデータを企業の成長の原動力とする成功事例を学習し、それに以下の問題を考えてください。
1.グロースハッカーになるために何の準備をしおかなければいけませんか?
2.仕事の際、他人にデータを提供してばかりいることをどう避けますか?
3.どうデータ活用を推進して、データの価値を最大限で発揮しますか?
4.どう周りの人と経営層がデータの価値に対する認識を変えますか?
ツイッターでデータ分析・可視化、仕事のスキルについての面白い情報をシェアしています。よかたっら覗いてください!![]()
前はデータ分析職につきたい方のために、十週間の学習計画を紹介しました。ここはインフォグラフィックにまとめてみます!記事と合わせてお読みください!
— HaileeKana (@HaileeKana) July 12, 2020
記事のURL:https://t.co/1wBiLQiRzi @HaileeKana #note https://t.co/wWH0jMBwHb