はじめに
今更な内容ですが、課題でまとめたものをせっかくなので記事として投稿します。
間違いや不適切な表現があればコメントでお知らせください。
前置き:DeepLearningの登場まで

第3次AIブームのビッグウェーブ
出典:『人工知能は人間を超えるか ディープラーニングの先にあるもの』
松尾 豊(著)KADOKAWA発行
しばしばAIと呼ばれることのあるDeepLearning(MachineLearning)ですが、
最近になって登場した技術というイメージとはギャップがありその歴史は60年前まで遡ります。
第1次AIブーム
第1次AIブームは 「推論・探索の時代」 と呼ばれており、探索木をしらみつぶしに探ったり行動計画を与えあたかも知能があるかのように見せるような手法がメインで現在のようなリッチな技術はありませんでした。それでも迷路や言葉で指示を与え積み木を操作させたり、チェスや将棋に挑戦させることは可能でした。しかし冷静に現実を見つめ直すと、
知能があるかのように振る舞えていたのは限定的な状況で実際に問題には対応できないことが判ってきました
チェスの例では場面ごとに次の手を選択することは可能でも相手の手のパターンまで考慮し戦略的に戦うことができないことが判りました。
期待された人工知能でしたが限界を感じられ第1次AIブームは冬の時代を迎えました。
第2次AIブーム
第2次AIブームではAIに「知識」を与えることがメインの時代です。
病気の知識を与えれば医者の代わりになり、法律の知識を与えれば犯罪を裁けるのでは!?
と探索では限界があったタスクに対して期待が高まりました。
しかし、現実は甘くなくいくつかの問題が浮き出て来ました。
1. 知識を与えることの難しさ
知識を与えることの難しさというのは、知識を体系的に評価することの難しさと言えます。
言葉には上下関係があり、大きく分けてpart of関係とis-a問題があります。
詳しくは書きませんが
例えば「車輪は自転車の一部」ですが「車輪」は自転車が無くても成り立つが「自転車」は車輪がないと成り立ちません。
また「木は森の一部」ですが、自転車の例とは違い木が1本無くなっても森は森です。
このような知識の体系的な評価をすべて記述しコンピュータに与えると言うのはとても難しく、これ自体が現在も研究となっています。(オントロジー研究)
2. 知識を与えた上での難しさ
これは知識を与えたとしても、「人間が無意識に行っている処理」を行えないことが原因の問題です。
これには必要な知識だけを取り出せずに永遠に考え出してしまう「フレーム問題」と
「特徴+科名」でモノがなんなのか判断できな「シンボルグラウンディング問題」の二つが挙げられます。
これらの知識を与える方針の難しさに直面し、AIブームは二度目の冬に入りました。
機械学習の登場
限界を感じられ世間が忘れていた人工知能ですがここ最近で第3次ブームが来ました。
その着火剤となったのが 「コンピュータの普及とそれに伴う膨大なデータ」 です。
イメージは容易だと思いますが、ここ数年でパソコンをはじめインターネットやスマートフォン、各種ネットサービスなどのITが爆発的に普及しました。そのことにより多種多様なデータの取得が容易になり、データを基盤とする機械学習の分野が急成長しました。
その中で機械学習に含まれる深層学習(DeepLearning)も成長しました。
DeepLearningの普及
DeepLearningはニューラルネットを利用しており、これは古くから研究が行われていました。
DeepLearning自体もパーセプトロンという前身が1957年に始まりそれなりに歴史がありますが、有用なメカニズムが考案されていなかったりそもそも脳の解明が足りず1990年代後半に冬の時代を迎えていました。普及したのはここ最近です。
DeepLearningの衝撃
DeepLearningは機械学習の一部で分類や回帰を根幹としていますが、その応用先は言語処理や画像認識、音声認識など現代の技術に大きく貢献しています。
代表的な出来事としては
・2012年トロント大学のヒントン教授らが世界的な人工知能の競技会でDLを用いたシステムで圧勝
・2016年人工知能囲碁プログラム「AlphaGo」が韓国のプロ棋士に勝利
などがあります。
こういった局所的なところから注目を浴びはじめビジネスで用いられ界隈は盛り上がり始めました。
そして昨今では「ML/DLやデータサイエンスを根幹とした教育」にまで波及しています。
そこにはどういった背景があったのか調査しました。
ビッグデータの登場による火付け
これまで一部の業界でしか確保できなかった 「大量のデータ」 がデジタル化で生み出されました。
またそれに伴い詳細なデータも採れるようになり、有用な特徴量の確保が可能になりました。
あらゆる分野がデジタル化することで幅広い分野で成果を見込めることで注目を浴びました。
コンピュータ性能の向上
DLは大量のデータでニューラルネットの演算(脳の再現)を行うため大量の計算が必要となります。
分かりやすい例でいえば 「スパコン」 や 「量子コンピュータ」 が挙げられます。
スパコンは従来のノイマン型コンピュータの最高峰で、
現在世界1位の富岳の計算速度は1秒間に41京5530兆回です。
さらに量子コンピュータは全く異なる原理で大きな単位の演算を可能としています。
昨秋、グーグル社を中心とする研究グループは、当時の世界最速のスーパーコンピュータが1万年を要する計算を、同社が開発した量子コンピュータが3分20秒で実行したことを発表しました。特筆すべきは計算速度だけでなく、両者を構成する素子数の違いです。たった53個の量子素子が、1京個を超える半導体素子を持つスーパーコンピュータを桁違いのスピードで凌駕した点です。
(引用:国産スパコン「富岳」が世界1位に! 量子コンピュータはそれよりスゴい?)
トップ性能が上がると共に一般レベルのマシンも性能が飛躍的に向上しています。
こういったマシンのパワーアップによって将来性と技術者の養成ハードルが改善されたことが
DL普及の前提にあると考えます。
① GPU
DLでは非常に大量の演算を行うため、CPUでは力不足な場合がほとんどです。
そのためコア数の多いGPUに並列処理をさせることで演算の高速化をします。
近年ではGPUの発展もすさまじくゲーム用途と思われがちなGPUですが、DLに大きく貢献しています。
GPU大手のNVIDIAが覇権を握っており、アルゴリズムもNVIDIAのCUDAに最適化されている場合が多いです。
② TPU
TPUはGoogleが開発した機械学習用に特別開発された集積回路です。
Tensor Processing Unitの略でTensor(多次元配列)に特化しています。
同社が提供する機械学習ライブラリ「Tensor Flow」に最適化されています。
2018年12月に行われた機械学習ベンチマーク「MLPerf v0.5」の結果でトップに立ちました。
※現在はNVIDIAのGPU A100がトップ
NVIDIA が最新の MLPerf ベンチマークで 16 の AI 性能の記録更新
③ intel FPGA
FPGAとはその場でハードウェア言語にて修正が出来る集積回路です。
新人エンジニアの赤面ブログ 『FPGAとは?超初級編』
これの高性能製品をIntelが開発しました。
Intelの新FPGA「Agilex」、高い柔軟性を実現 (1/3)
これにより高速なデータ活用コンピューティングが可能となります。
④ IBM ASIC
ASICはユーザに合わせてカスタマイズされた集積回路です。
FPGAと同様にハードウェア開発されますが修正ができません。また開発費と開発期間を要します。
しかしユーザに合わせて最低限の構成なため高性能かつ部品コストを抑えることが可能です。
実装面積も抑えられます。
このASICの開発はIBMが先導しています
IBM由来の5nm ASIC、Marvellがビジネスを開始
優秀なネットワークの考案
ML/DLに取り組むハード的なハードルと心理的なハードルの両方が改善されたことで研究者が増えました。そのおかげか、分野内での発明と改良が加速します。
パーセプトロンの存在と限界
DLの全身としてパーセプトロンが存在しました。
最も簡易的なアルゴリズムであるパーセプトロンから掘り下げてみようと思います。
第1世代:単純パーセプトロン(1960~)
入力値の線形結合+活性化関数による非線形変換

出典:農学情報科学 - パーセプトロン
$$y = f(v)\v = W_t x - θ$$
原理的に非線形な識別が不可能という限界がありました。
第2世代:多層パーセプトロン(1980~)
多数の単純パーセプトロンを階層的に組み合わせ、活性化関数にシグモイド関数を採用しました。
誤差逆伝播法でパラメータの更新を行います。
線形分離できなかったデータもパーセプトロンを組み合わせることで分離可能になりました。
しかし実際には逆伝播が遅かったり過学習しやすいなどの問題点がありました。
(訓練データへの過度な適応)

ここで順伝播、逆伝播、誤差関数、勾配などの仕組みが登場します。
順伝播(フィードフォワードニューラルネットワーク)
構築されたネットワークに沿って計算を行い予測値を求める。
入力層→中間層→出力層→確率
逆伝播(バックプロパゲーション)
順伝播で誤差を求めたら誤差関数を元に逆伝番でパラメータ更新を行う。(誤差逆伝播)
名の通り出力層←確立へと逆に伝播を行う。
誤差関数(目的関数)
ネットワークを評価する指標を目的関数といい、その中でも誤差関数(予測値と真値の誤差)
が用いられ事が多いです。
・分類では交差エントロピー
・回帰では平均二乗誤差
など目的に応じて使い分けます。
勾配
関数のある地点の傾き
傾きが0=関数の最小値である。
誤差関数の最小値を求めるために勾配法が用いられる
最適化アルゴリズム
前述の目的関数(誤差関数)を最適化(勾配を最小に)するためのアルゴリズムが
最適化アルゴリズムです。最急効果法をはじめとし様々な派生形が存在します。
ニューラルネットワークの学習プロセスの問題
パーセプトロンの層を増やすことで決定境界も形が直線からドーナツ型に近づくことが段々わかり多層にする手法に光を見ましたが他にも大きな問題がありました。
それが 「局所最適化」と「勾配消失」 です。
従来の最適化手法では勾配を減らしきれず、局所的な最小値に収束してしまったり過学習を起こすことがありました。
また勾配消失(+勾配爆発)はシグモイド関数のS字の端に勾配が寄ってしまい誤差の減少が止まる不具合がありました。
実際にはこれらの問題が原因で英語の過去形を識別できない不具合などが生じていたそうです。
まだネットワークに問題があることに加えSVMやランダムフォレストといった新しい統計的学習モデルの波もあり停滞期に入りました。
第3世代:Deep Learning(深層学習)
従来よりも多層のニューラルネット(現在は20層を超えるものも)の考案により
音声認識や画像認識、自然言語処理など様々な分野で性能を発揮しました。
代表的なブレークスルーとしては画像認識や囲碁で人間に勝った事例があります
これ以後DLは安定期に入り、精度向上や効率化のフェーズに移行しました。
大企業や大学の力と恩恵
マシン性能の部分でGoogleやNVIDIAに触れましたが、それらの会社は広く深く昨今のDL界に貢献しています。
DLフレームワークの提供
ML/DLには多くの手法やパラメータが存在しておりすべてをプログラムで構築するのは大変です。
そこで活躍するのが DLフレームワーク です。
フレームワークは数多のアルゴリズムを内包しており、メソッドを呼び出すだけで簡単に利用することができるようになっています。
代表的なものを例に挙げると
- TensorFlow (Google)
- Chainer (PFN)
- Caffe (Yangqing Jia, UC Barkeley)
- MXNet (ワシントン大学)
- PyTorch (Facebook)
- The Microsoft Cognitive Toolkit (CNTK) (Microsoft)
- Theano (モントリオール大学)
などが挙げられます。
参考:Qiita - Deep Learning フレームワークざっくり一覧
DL界隈ではこれらのツールを無料で利用でき、またリファレンスも充実しています。
最前線を走る研究者の方々がライバルとして切磋琢磨しており、
さらに技術の利用ハードルを下げるために相当な労力を費やしています。
このことからも業界の勢いと発展に対する姿勢が分かります。
各種手法の改善
DLでは手順の中でいくつかの役割が分かれており組み合わせることで機能しますが
完璧な手法というのは存在していません。目的に応じて最適な手法を選択する必要があります。
その上で、いくつか課題をなるべく抑えるようにアルゴリズムの考案、改良が行われています。
活性化関数の改善
出力の要となる活性化関数では主に
- 精度
- 計算速度
- 勾配消失・勾配爆発
- 苦手な入力値
などが挙げられます。精度と計算速度についてはトレードオフという認識で問題ありませんが、
最近ではReLU関数のようなシンプルで高精度な関数も登場しています。
勾配消失は勾配が偏ることで起きる誤差変動の停止です。これもReLU関数で解決されました。
勾配爆発は、層を重ねることで活性化関数の行列積が繰り返され勾配サイズが大きくなってしまう問題です。これはクリッピングという操作を加え勾配に上限を付けることで解決しています。
目的関数の改善
ここでは損失関数について扱います。
予測値を評価するための損失関数にも種類があり、それぞれ特徴があります。
考慮しなければいけないのは
- 外れ値の影響
- 計算速度
- 適切か
などが挙げられます。
代表的な手法は
- 平均二乗誤差 / Mean Squared Error
- もっともメジャー。分かりやすいが外れ値に弱い。
- 平均絶対誤差 / Mean Absolute Error
- 外れ値に強い。
- 平均二乗対数誤差 / Mean Squared Logarithmic Error
- 予測値が実値を上回りやすい。
- 交差エントロピー誤差 / cross entropy error
- 分類問題用。
などがあります。回帰と分類で枠組みが違うのでタスクとその性質ごとに選択が必要です。
最適化手法の改善
目的関数の最小化に用いられる最適化(optimizer)にも種類があり
- 精度(局所解)
- 収束速度
- 安定性
などが挙げられます。
最適化の難しさは以下の図が分かりやすいです
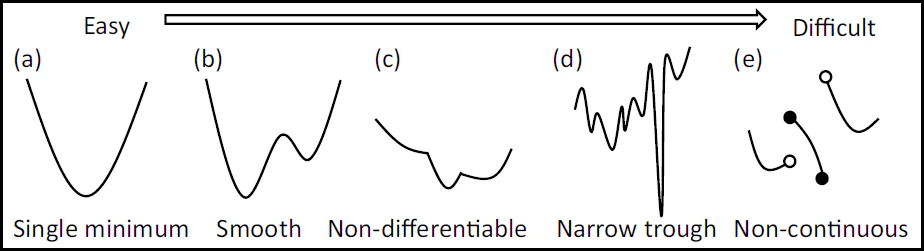
引用:最適化アルゴリズムを評価するベンチマーク関数まとめ
詳しくは最適化超入門
過学習の抑制:重み減衰(Weight Decay)
ネットワークが教師データに過度に適応する過学習を防ぐために
重み減衰(Weight Decay) という操作も考案されています。正則化とも呼ばれます。
厳密には目的関数で作用します。
最適化と重み減衰の組み合わせによって過学習を防止します。
過学習の抑制:Dropout
DLはモデルの複雑さと過学習が比例します。
そのためシンプルなモデルの方が汎化性能が高くなります。
この原理を元に考案されたのがDropoutで、
いくつかのノードを無効化し強制的にモデルの自由度を下げ過学習を防ぎます。
過学習の抑制:Batch Normalization
勾配消失・爆発を防ぐための手法です。
これまでの目的関数や最適化、重み減衰、Dropoutとは違い
ネットワーク全体を安定化させることが目的です。
ネットワーク全体を安定させることで
- 学習の高速化
- 初期値の依存からの脱却
- 過学習抑制
などが見込めます。
こういった手法の考案や改善がハイスピードで行われています。
ニューラルネットワークの種類
NN(ニューラルネットワーク)にも種類があり、こちらも考案、改良が研究されています。
タスクごとに特化したモデルがあります。特化したアルゴリズムの開発が幅広い分野への適応に繋がり、DLの普及につながっているとも言えます。
CNN(畳み込みニューラルネットワーク)
NNでは各層のノードが密に結合する全結合層がありますが、
CNNではそれらに加え畳み込み層,プーリング層というフィルタ処理により特徴量を処理します。
主に画像データや非連続データの解析に用いられます。
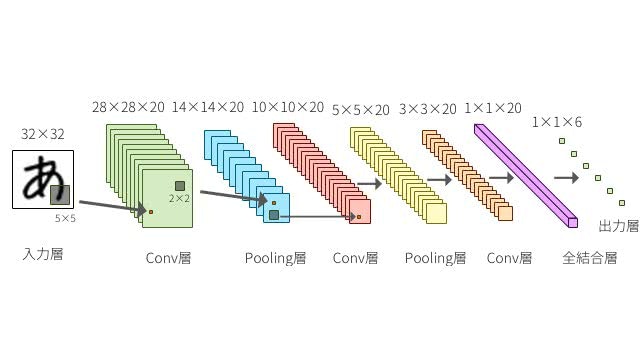
出典:DeepAge - 定番のConvolutional Neural Networkをゼロから理解する
RNN(再帰型ニューラルネットワーク)
RNNは時系列データを得意とするネットワークです。
連続データの他データポイントを利用することでよりよい予測を行います。

出典:AISIA - リカレントニューラルネットワーク_RNN (Vol.17)
その他
上記2種類の代表的なネットワークのほかに
- LSTM : 長期の時系列データに特化。自然言語処理で活躍
- BERT : 最近登場した双方向Transformer。多くのベンチマークで記録更新。
- GAN : 最新の生成モデル。2つのNNで構成されている。
など様々なネットワークがあり、派生形を含めかなりの数のネットワークが提案されています。
高めあいの精神
同じタスクでもデータセットごとに適したアルゴリズムが違います。
ML/DL界ではSOTA(state-of-the-art:最新技術)を目標に研究されることが多く、
タスクごとのベンチマークを指標にアルゴリズムのランク付けが行われています。
自然言語処理のテキスト分類だけでもいくつものデータセットが用意されており
絶対的なアルゴリズムが存在しないこと、アルゴリズムの種類が豊富であることが判ります。
参考:
Browse SoTA > Natural Language Processing > Text Classification
またデータ分析コンペというのも頻繁に開催されており、
論文が出たばかりの新手法はコンペ内で試され話題になるということも多いです
例:XGBoost(アンサンブル手法というアルゴリズムたちに多数決させる手法)
まとめ
DLの普及の流れをまとめると

といった感じだと認識しています。