言語処理100本ノック 2020 (Rev2)の「第9章: RNN, CNN」の89本目「事前学習済み言語モデルからの転移学習」記録です。初めてBERT使いました。まだ、あまりBERTを深く理解できていませんが、AttentionとTransformerまで理解した状態です。学習済モデルを再利用するだけなので、理解しないでもこのレベルでは問題ないです。
記事「まとめ: 言語処理100本ノックで学べることと成果」に言語処理100本ノック 2015についてはまとめていますが、追加で差分の言語処理100本ノック 2020 (Rev2)についても更新します。
参考リンク
| リンク | 備考 |
|---|---|
| 89_事前学習済み言語モデルからの転移学習.ipynb | 回答プログラムのGitHubリンク |
| 言語処理100本ノック 2020 第9章: RNN, CNN | (PyTorchだけど)解き方の参考 |
| 【言語処理100本ノック 2020】第9章: RNN, CNN | (PyTorchだけど)解き方の参考 |
| まとめ: 言語処理100本ノックで学べることと成果 | 言語処理100本ノックまとめ記事 |
| BERTでテキストを分類する | TensorFlow公式チュートリアル |
| [Attention入門]seq2seqとAttentionの解説(TensorFlow) | Attentionに関する解説 |
| [Transformer入門]TensorFlowチュートリアル: Transformer | Transformerに関する解説 |
環境
GPUを使いたかったので、Google Colaboratory使いました。Pythonやそのパッケージでより新しいバージョンありますが、新機能使っていないので、プリインストールされているものをそのまま使っています。
tensorflow-textはPython上で明示的に使用していませんが、Importしないとエラーになったので使っています。
| 種類 | バージョン | 内容 |
|---|---|---|
| Python | 3.7.14 | Google Colaboratoryのバージョン |
| 2.0.3 | Google Driveのマウントに使用 | |
| pandas | 1.3.5 | 行列に関する処理に使用 |
| tensorflow | 2.10.0 | ディープラーニングの主要処理 |
| tensorflow-text | 2.10.0 | ディープラーニングのNLP処理 |
| tf-models-official | 2.10.0 | BERTのOptimizer用 |
第8章: ニューラルネット
学習内容
深層学習フレームワークを用い,再帰型ニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)を実装します.
89. 事前学習済み言語モデルからの転移学習
事前学習済み言語モデル(例えばBERTなど)を出発点として,ニュース記事見出しをカテゴリに分類するモデルを構築せよ.
回答
回答結果
88本目ノック(パラメータチューニング)との精度比較です。超向上してます。BERTやばいな。
| データセット | Loss | 正答率 |
|---|---|---|
| 訓練 | 0.346 |
88.3% |
| 検証 | 0.430 |
85.3% |
| 評価 | 0.400 |
85.8% |
参考に評価データセットの結果です。
> model.evaluate(X_test, y_test)
42/42 [==============================] - 4s 95ms/step - loss: 0.2419 - acc: 0.9259
訓練経過に至っては、(検証結果が良くないので採用はしていませんが)訓練Lossは0.1以下まで下がっています。
Epoch 1/30
334/334 [==============================] - 78s 217ms/step - loss: 0.6090 - acc: 0.7742 - val_loss: 0.3382 - val_acc: 0.8885
Epoch 2/30
334/334 [==============================] - 75s 225ms/step - loss: 0.2616 - acc: 0.9125 - val_loss: 0.2982 - val_acc: 0.9147
Epoch 3/30
334/334 [==============================] - 74s 221ms/step - loss: 0.1819 - acc: 0.9405 - val_loss: 0.3111 - val_acc: 0.9124
Epoch 4/30
334/334 [==============================] - 73s 219ms/step - loss: 0.1337 - acc: 0.9571 - val_loss: 0.3245 - val_acc: 0.9162
Epoch 5/30
334/334 [==============================] - 72s 216ms/step - loss: 0.0997 - acc: 0.9677 - val_loss: 0.3327 - val_acc: 0.9184
Epoch 6/30
334/334 [==============================] - 73s 219ms/step - loss: 0.0947 - acc: 0.9701 - val_loss: 0.3327 - val_acc: 0.9184
Epoch 7/30
334/334 [==============================] - 71s 214ms/step - loss: 0.0913 - acc: 0.9715 - val_loss: 0.3327 - val_acc: 0.9184
回答プログラム 89_事前学習済み言語モデルからの転移学習.ipynb
GitHubには確認用コードも含めていますが、ここには必要なものだけ載せています。
回答: パッケージインストール部分
特別なことはしておらず普通のpip installです。
!pip install -q -U tensorflow-text tf-models-official
回答: Script処理
Scrip処理の部分です
from google.colab import drive
from official.nlp import optimization # to create AdamW optimizer
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text # 明示的に使っていないが必要
drive.mount('/content/drive')
BASE_PATH = '/content/drive/MyDrive/ColabNotebooks/ML/NLP100_2020/'
def read_dataset(type_):
df = pd.read_table(BASE_PATH+'06.MachineLearning/'+type_+'.feature.txt')
df.info()
sr_title = df['title'].str.split().explode()
y = df['category'].replace({'b':0, 't':1, 'e':2, 'm':3})
return df['title'], tf.keras.utils.to_categorical(y, dtype='int32') # 4値分類なので訓練・検証・テスト共通でone-hot化
X_train, y_train = read_dataset('train')
X_valid, y_valid = read_dataset('valid')
X_test, y_test = read_dataset('test')
preprocessor = hub.KerasLayer(
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
name='preprocessor')
encoder = hub.KerasLayer(
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/2',
trainable=True, name='BERT_encoder')
def build_classifier_model(preprocessor, encoder):
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
encoder_inputs = preprocessor(text_input)
outputs = encoder(encoder_inputs)
net = outputs['pooled_output'] # [batch_size, 512].
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(4, activation='softmax', name='classifier')(net)
return tf.keras.Model(text_input, net)
model = build_classifier_model(preprocessor, encoder)
epochs = 5
# cardinality は データ件数/バッチサイズ を切り上げ
steps_per_epoch = (len(X_train)+32-1)//32 # 除算切り上げ
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = int(0.1*num_train_steps)
optimizer = optimization.create_optimizer(init_lr=3e-5,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
model.compile(optimizer=optimizer,
loss='categorical_crossentropy',
metrics=['acc'])
model.fit(X_train, y_train, validation_data=(X_valid, y_valid), epochs=30,
callbacks=[tf.keras.callbacks.EarlyStopping(
patience=5, restore_best_weights=False)])
model.evaluate(X_test, y_test)
回答解説
Scriptの一部分を解説します。
Import
import tensorflow_text as text は Python Script内で明示的に使用していないのが注意点です。
from google.colab import drive
from official.nlp import optimization # to create AdamW optimizer
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text # 明示的に使っていないが必要
モデル読込
BERTの前処理とEncoderをTensorFlow Hubから読み込みます。TensorFlow HubにはALBERTなど多くのモデルがあるのですが、公式チュートリアル「BERTでテキストを分類する」と同じものを使用します。
Preprocessor
preprocessor = hub.KerasLayer(
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
name='preprocessor')
text_preprocessed = preprocessor([X_train[0]])
print(f'Text : {[X_train[0]]}')
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')
3種類の出力(Word Ids, Input Mask, Type Ids)があるのがわかります。
Text : ['REFILE UPDATE car sale up for sixth month as economy recover']
Keys : ['input_type_ids', 'input_word_ids', 'input_mask']
Shape : (1, 128)
Word Ids : [ 101 25416 9463 10651 2482 5096 2039 2005 4369 3204 2004 4610]
Input Mask : [1 1 1 1 1 1 1 1 1 1 1 1]
Type Ids : [0 0 0 0 0 0 0 0 0 0 0 0]
BERTモデル
encoder = hub.KerasLayer(
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/2',
trainable=True, name='BERT_encoder')
bert_results = encoder(text_preprocessed)
print(f'Pooled Outputs Shape:{bert_results["pooled_output"].shape}')
print(f'Pooled Outputs Values:{bert_results["pooled_output"][0, :12]}')
print(f'Sequence Outputs Shape:{bert_results["sequence_output"].shape}')
print(f'Sequence Outputs Values:{bert_results["sequence_output"][0, :12]}')
こちらは2種類の出力(Pooled Output, Sequence Output)があるのがわかります。使うのはPooled Outputです。
Pooled Outputs Shape:(1, 512)
Pooled Outputs Values:[ 0.83857816 0.8714344 -0.05869783 -0.21945992 0.14879902 0.62879145
0.99516565 -0.9972128 0.15385738 -0.99931264 0.3135587 -0.8180948 ]
Sequence Outputs Shape:(1, 128, 512)
Sequence Outputs Values:[[ 0.33862212 -0.11791104 0.3418219 ... -1.1574944 0.29415578
0.9472706 ]
[ 0.28497177 0.39325225 0.60013586 ... -0.35047954 0.5410543
1.267122 ]
[-0.8773053 0.01777261 0.68712896 ... 0.60109943 -0.22280091
1.305879 ]
...
[ 0.00644314 0.17899063 0.6403154 ... -0.34970805 0.08075863
0.14510325]
[-0.33870348 0.36234245 0.05213176 ... -0.7976972 -0.43191314
0.8580584 ]
[-0.10936005 0.2492041 0.58715516 ... 0.34737933 -0.64347273
0.71053106]]
モデル全体作成
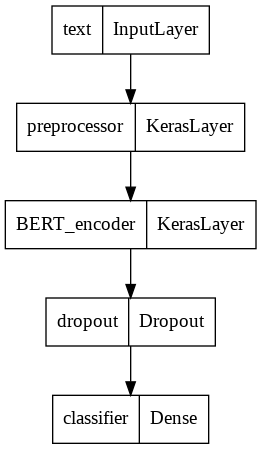
モデル全体を作成します。BERTからpooled_outputを受け取り、Dropout層と全結合層を経て4クラス分類にしています。
tf.keras.utils.plot_modelはshapeを出力しようとするとエラーとなったので、やめました。バグのようですが、重要ではないので出力をやめました。
def build_classifier_model(preprocessor, encoder):
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
encoder_inputs = preprocessor(text_input)
outputs = encoder(encoder_inputs)
net = outputs['pooled_output'] # [batch_size, 512].
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(4, activation='softmax', name='classifier')(net)
return tf.keras.Model(text_input, net)
model = build_classifier_model(preprocessor, encoder)
bert_raw_result = model(tf.constant([X_train[0]]))
print(tf.sigmoid(bert_raw_result))
model.summary()
# show_shapes=True , then error
tf.keras.utils.plot_model(model)
tf.Tensor([[0.5128579 0.56176686 0.63317573 0.5385126 ]], shape=(1, 4), dtype=float32)
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
text (InputLayer) [(None,)] 0 []
preprocessor (KerasLayer) {'input_type_ids': 0 ['text[0][0]']
(None, 128),
'input_word_ids':
(None, 128),
'input_mask': (Non
e, 128)}
BERT_encoder (KerasLayer) {'encoder_outputs': 28763649 ['preprocessor[0][0]',
[(None, 128, 512), 'preprocessor[0][1]',
(None, 128, 512), 'preprocessor[0][2]']
(None, 128, 512),
(None, 128, 512)],
'sequence_output':
(None, 128, 512),
'default': (None,
512),
'pooled_output': (
None, 512)}
dropout (Dropout) (None, 512) 0 ['BERT_encoder[0][5]']
classifier (Dense) (None, 4) 2052 ['dropout[0][0]']
==================================================================================================
Total params: 28,765,701
Trainable params: 28,765,700
Non-trainable params: 1