BERTを勉強していてTransformerについて整理しました。モデル部分は理解しましたが、訓練ジョブを流す部分などはほとんど見ていないですし解説もしていません。
seq2seqについては記事「【Keras入門(7)】単純なSeq2Seqモデル定義」で以前解説をしました。
seq2seqとAttentionについては記事「[Attention入門]seq2seqとAttentionの解説(TensorFlow)」で解説しました。
もともとは以下のオンライン講座を受講していて、Transformerに関する理解を深めようとしたのがきっかけでした(オンライン講座にはTransformerについても含んでいたが、より深く理解したいと考えました)。
以下のTensorFlowのチュートリアルを使って学習しました。学習途中にチュートリアルが更新され、この記事と一部違う点があります。
理解にあたり以下を参考にしました。私がPyTorchを使っていないことには、深い理由はないです。
レイヤ解説
Attention 解説
モデル全体を解説する前に Attention 部分を解説します。Attentionがモデル内で複数箇所使われているためです。下図の一番左がモデル全体で、その中で(Masked)Multi-Head Attentionが使われ、その中でScaled Dot-Product Attentionが使われています。
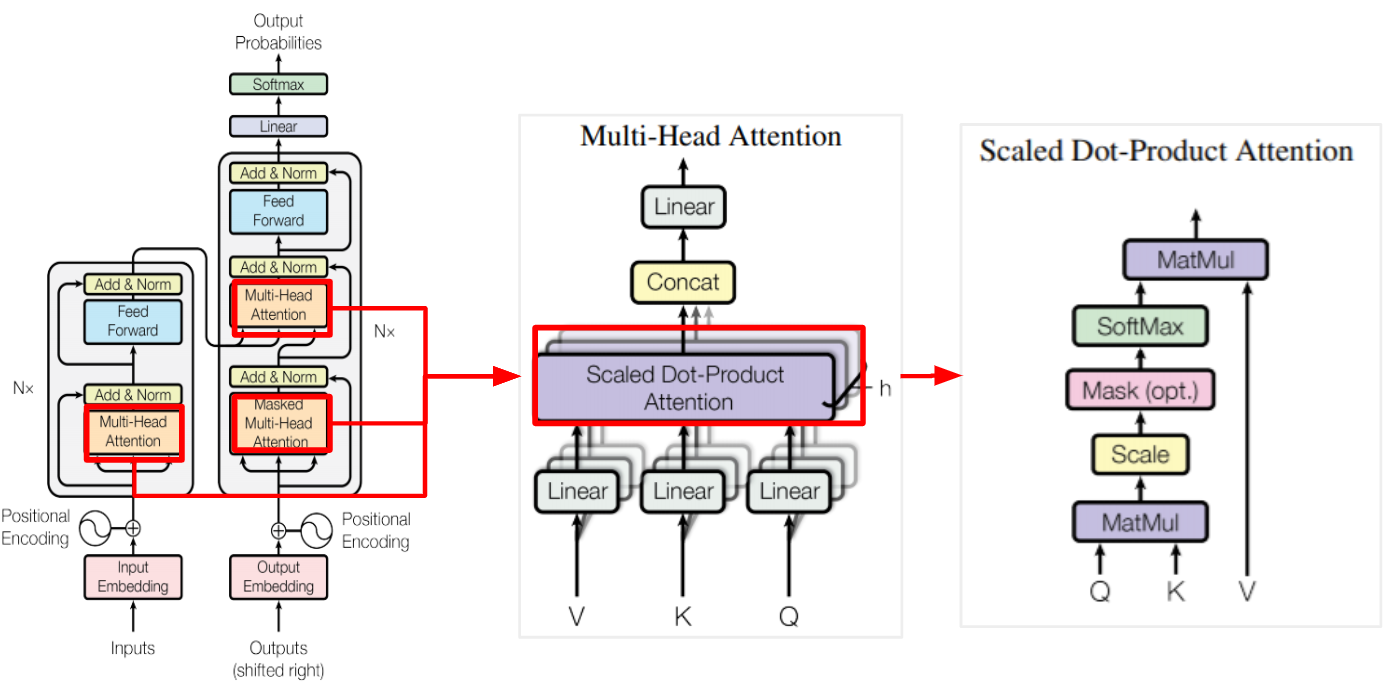
Scaled Dot-Product Attention
最小単位のScaled Dot-Product Attentionから解説します。
記事「[Attention入門]seq2seqとAttentionの解説(TensorFlow)」で使ったのはBahdanau's additive attentionで、今回使うのはdot-product attention(内積Attention)。
下図モデルで、QKV(Query, Key, Value)のインプットを受けるのはadditive attentionと変わりません。QKYのそれぞれが何を示すかはAttentionがどこで使われるかに依存します。
Scaled Dot-Product Attentionの処理図です(元の図にAttention Weightを加えました)。QueryとKeyからAttetion Weightを作成し、Valueと乗算して焦点を当てたいTokenを出力をします。
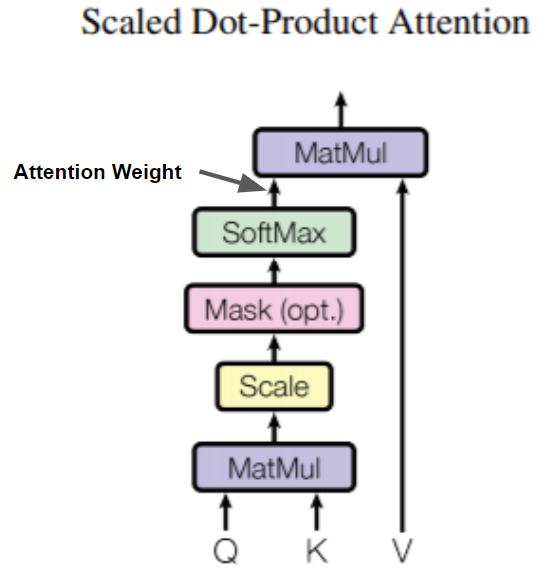
dot-product attention の数式です。 $\sqrt{d_k}$ で除算しているのでScaled Dot-Product Attentionと呼びます。この数式に"Mask(opt.)"処理は含んでいません。
\mathrm{Attention}(Q, K, V)=\mathrm{softmax}_k(\frac{QK^T}{\sqrt{d_k}})V \\
- Query: 次元$d_k$(総要素数)を持つ
- Key: 次元$d_k$(総要素数)を持つ
- Value: 次元$d_v$(総要素数)を持つ
内積の注意は、深さの平方根の係数でスケーリングされます。これは、深さの値が大きい場合、ドット積の大きさが大きくなり、勾配が小さいソフトマックス関数を押して、非常にハードなソフトマックスになるためです。
たとえば、 QとKの平均が0で分散が1であるとします。これらの行列の乗算は、平均が0で分散がdkになります。したがって、 dkの平方根がスケーリングに使用されるため、 dkの値に関係なく一貫した分散が得られます。分散が低すぎる場合、出力がフラットすぎて効果的に最適化できない可能性があります。分散が高すぎると、初期化時にソフトマックスが飽和し、学習が困難になる可能性があります。
上記はチュートリアル「Scaled dot product attention」内の日本語説明文です。分散が大きいと学習がすすまないのでScaleをしていることの説明です。
Pythonでガウス分布の配列を作成して分散について確認してみました。
import math
import numpy as np
def check_dot(d1, d2):
size = d1*d2
a = np.random.normal(size=size).reshape(d1, d2)
b = np.random.normal(size=size).reshape(d1, d2)
dot = np.dot(a, b.T)
if d1*d2 < 10:
print(f'a: \n{a}')
print(f'b: \n{b}')
print(f'dot product: \n{dot}')
print(f'average: {dot.mean()}')
print(f'variance: {dot.var()}')
print(f'scaled variance: {dot.var()/math.sqrt(size)}')
総次元数で正規化しないと分散が大きくなっていくことがわかります。
> check_dot(2, 3)
a:
[[-1.00909328 -0.40230197 0.32471939]
[ 1.41880302 -1.34959901 -1.332655 ]]
b:
[[ 0.51595355 -0.65731419 0.10551541]
[-1.18201672 -0.52490031 0.52338299]]
dot product:
[[-0.22194357 1.57388616]
[ 1.47853139 -1.6661329 ]]
average: 0.29108526871573576
variance: 1.7873769938079478
scaled variance: 0.7296936021365334
> check_dot(10, 10)
average: 0.08405168619719078
variance: 5.157999880963599
scaled variance: 0.51579998809636
> check_dot(100, 100)
average: -0.11233147437872655
variance: 99.42723752685359
scaled variance: 0.9942723752685358
The mask is multiplied with -1e9 (close to negative infinity). This is done because the mask is summed with the scaled matrix multiplication of Q and K and is applied immediately before a softmax. The goal is to zero out these cells, and large negative inputs to softmax are near zero in the output.
Maskは-1e9(-10億)でSoftmax前に乗算しています。Softmaxは$\frac{\exp(x_i)}{\sum_{k=1}^n \exp(x_k)}$なので-1e9を乗算することで結果はほぼ0です。Softmaxとその微分は、こちらのページがわかりやすいです。
Attention部分のコードです。コードが非常にわかりやすいです。
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
Multi-head attention
Transformer内でMasked Multi-Head Attention と「Masked」がついていることもあるAttentionです。「Masked」の有無は実質的にはScaled Dot-Product Attention内での処理の差異です。論文内の図に入出力のShapeなど少し補足しました。「BS」はバッチサイズの略。
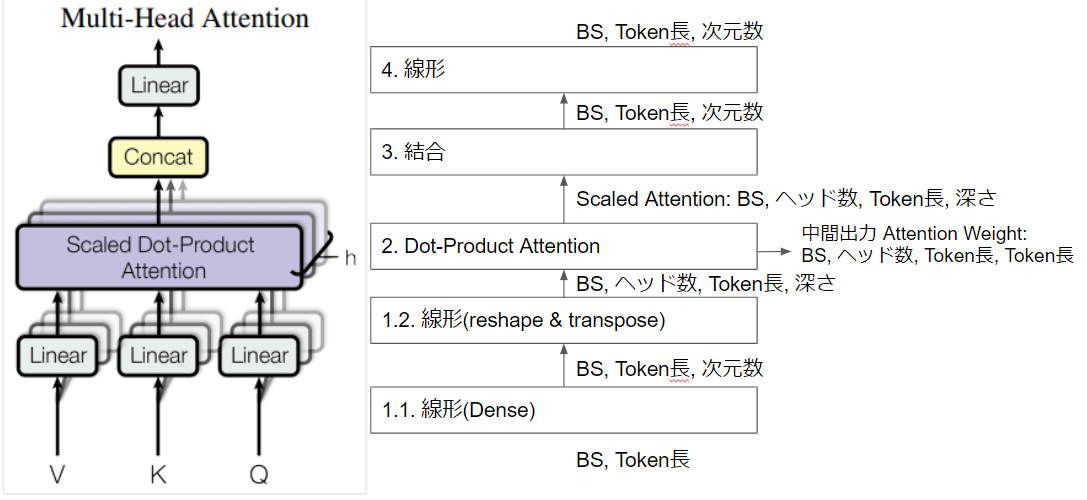
| 処理 | 入力Shape | 出力Shape |
|---|---|---|
| 1.1. 線形(Dense) | VKQ各々共通: BS * Token数 | VKQ各々共通: BS * Token数 * 次元数 |
| 1.2. 線形(reshape & transpose) | VKQ各々共通: BS * Token数 * 次元数 | VKQ各々共通: BS * ヘッド数 * Token数 * 深さ |
| 2. Dot-Product Attention | BS * ヘッド数 * Token数 * 深さ | Scaled Attention: BS * ヘッド数 * Token数(Q) * 深さ Attention Weight: BS * ヘッド数 * Token数(Q) * Token数(K) |
| 3. 結合 | Scaled Attention: BS * ヘッド数* Token数(Q) * 深さ | BS * Token数(Q) * 深さ |
| 4. 線形 | BS * Token数(Q) * 深さ | BS * Token数(Q) * 深さ |
コード部分は非常にわかりやすいです。Keras v2.9でMultiHeadAttentionが出来ました。実装する場合には使いましょう。理解に役立つので、MultiHeadAttention使わないコードも残しておきます。
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self,*, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
# 割り切れる数値になっていることを確認: %は剰余演算
assert d_model % self.num_heads == 0
# モデルの次元 = ヘッド数 * 深さ: //は整数除算(切捨除算)
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth)) # 次で次元順番変更していることに注意
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
Point wise feed forward network
Attention とともにモデル構成要素の1つであるPoint wise feed forward networkについても解説します。
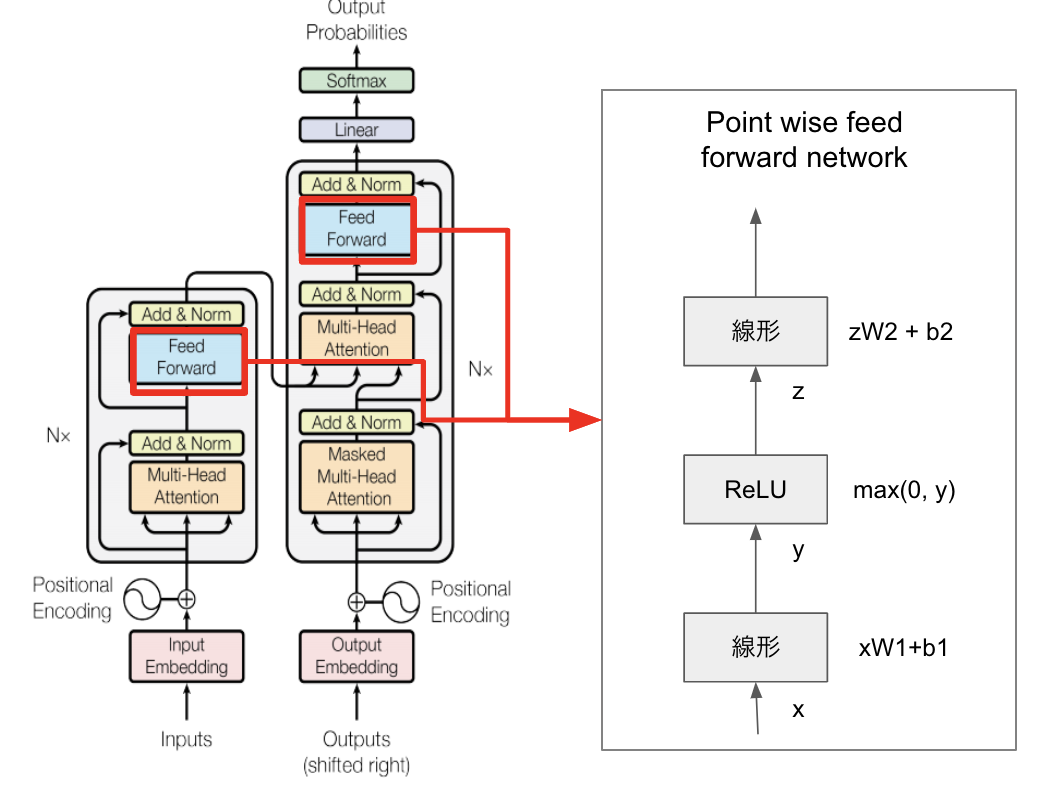
コードはDenseを2つ重ねているだけなので非常にシンプルです。
def point_wise_feed_forward_network(d_model, dff):
# ここでdffはdimension of feed forward
return tf.keras.Sequential([
# 一度、dffで次元を増やす(直後に元のd_modelに戻す)
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
Positional Encoding
レイヤ説明の最後としてPositional Encoding(位置エンコーディング)です。
EncoderおよびDecoderに使われています。
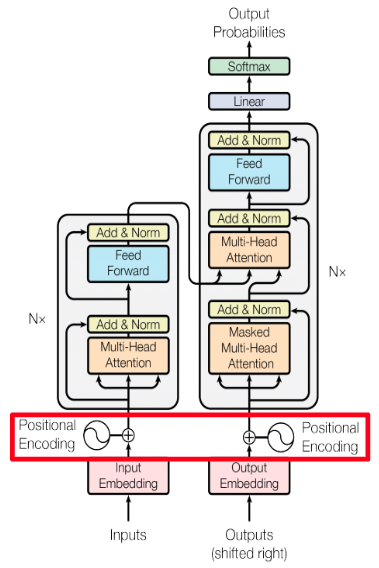
Positional Encodingの元ネタは以下の論文です。
Positional Encodingの計算式です。入力内容(文字)に関係ない固定値を作成し、加算します(加算部分はコードに記述なし)。
\Large{PE_{(pos, 2i)} = \sin(pos / 10000^{2i / d_{model}})} \\
\Large{PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i / d_{model}})}
コードとともに見ていきます。
入力のlengthはTokenの最大長、depthは直前のEmbeddingから受け取る次元数です。depthを2で割っているのは、sinとcosの計算で2回同じ値を使うためです。
def positional_encoding(length, depth):
depth = depth/2
# Token Length の配列([[0, ,1, ..., length]])
# np.newaxisはNoneのエイリアスで、次元を増やす場合に使用
positions = np.arange(length)[:, np.newaxis] # (seq, 1)
print(f'pos: {positions}')
# Dimension の配列([[0], [2/(depth)],...,[(depth-2)/depth]])
depths = np.arange(depth)[np.newaxis, :]/depth # (1, depth/2)
print(f'dep1: {np.arange(depth)[np.newaxis, :]}')
print(f'dep2: {depths}')
angle_rates = 1 / (10000**depths) # (1, depth/2)
print(f'angle_rates: {angle_rates}')
angle_rads = positions * angle_rates # (pos, depth/2)
print(f'angle_rads: {angle_rads}')
pos_encoding = np.concatenate(
[np.sin(angle_rads), np.cos(angle_rads)],
axis=-1)
return tf.cast(pos_encoding, dtype=tf.float32)
細かく解説します。
試しにlength=8, dpeth=10で呼び出します。
pos_encoding = positional_encoding(length=8, depth=10)
各計算式と値の推移です。
>> np.arange(length)[:, np.newaxis]
[[0] [1] [2] [3] [4] [5] [6] [7]]
>> np.arange(depth)[np.newaxis, :]
[[0. 1. 2. 3. 4.]]
>> np.arange(depth)[np.newaxis, :]/depth
[[0. 0.2 0.4 0.6 0.8]]
>> 1 / (10000**depths)
[[1.00000000e+00 1.58489319e-01 2.51188643e-02 3.98107171e-03
6.30957344e-04]]
表形式。depthのindexが多くなるにつれて1から0に近づいていくのがわかります。

行列計算をすることで、position/2×depthのshapeになります。
positions * angle_rates
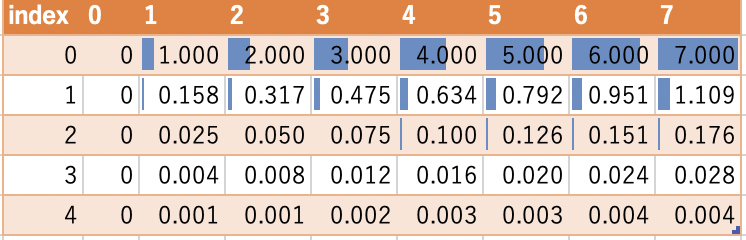
最後に三角関数で周期化します。depth(行)のsinの後ろ(3・4行目)はほぼ0付近で、cosの後ろ(8・9・10行目)はほぼ1付近に値が張り付いています。
pos_encoding = np.concatenate(
[np.sin(angle_rads), np.cos(angle_rads)],
axis=-1)
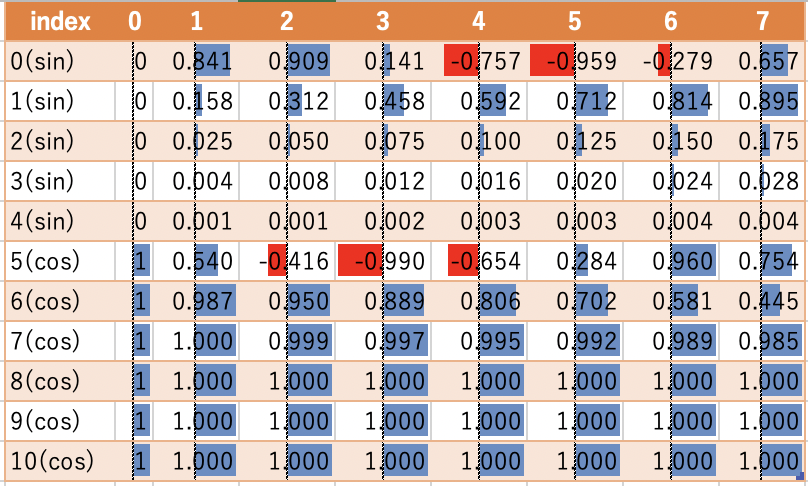
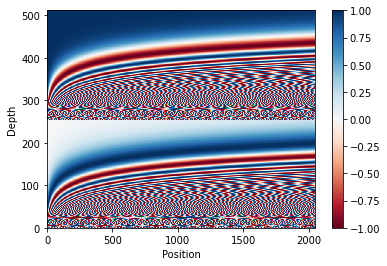
三角関数の復習としてグラフを表示しておきます。

元のdepth512とposition2048をグラフ表示するとこんな。Depthが0から100や256から356くらいは-1から1までまばらになっているのがわかります。これは周期関数であるsinやcosを使っているからですね。
Embeddingと繋げてPositionalEmbeddingというレイヤを作ります。Embeddingとの間にあるtf.math.sqrt(tf.cast(self.d_model, tf.float32))は論文内でも以下の説明しかありません。Embedding結果に対してPositional Encoding結果を加算をしているのがわかります。
In the embedding layers, we multiply those weights by $\sqrt{d_{model}}$.
class PositionalEmbedding(tf.keras.layers.Layer):
def __init__(self, vocab_size, d_model):
super().__init__()
self.d_model = d_model
self.embedding = tf.keras.layers.Embedding(vocab_size, d_model, mask_zero=True)
self.pos_encoding = positional_encoding(length=2048, depth=d_model)
#マスクを作成
def compute_mask(self, *args, **kwargs):
return self.embedding.compute_mask(*args, **kwargs)
def call(self, x):
length = tf.shape(x)[1]
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x = x + self.pos_encoding[tf.newaxis, :length, :]
return x
モデル解説
モデル全体の流れは、以下の記事が非常にわかりやすいです。具体例を元に解説してくれています。
逆に私はもう解説することあまりありません。
Encoder
Masked Mulit-Head Attentionでないのに、なぜattention_maskがあるのか一瞬混乱しました。ここのMaskは<PAD>部分なので問題ないです。Masked Mulit-Head Attentionは、カンニングを防ぐためにDecoderで使います。
MultiHeadAttention Layerがv2.9で加わって便利になりました。
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self,*,
d_model, # Input/output dimensionality.
num_attention_heads,
dff, # Inner-layer dimensionality.
dropout_rate=0.1
):
super().__init__()
# Multi-head self-attention.
self.mha = tf.keras.layers.MultiHeadAttention(
num_heads=num_attention_heads,
key_dim=d_model, # Size of each attention head for query Q and key K.
dropout=dropout_rate,
)
# Point-wise feed-forward network.
self.ffn = point_wise_feed_forward_network(d_model, dff)
# Layer normalization.
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
# Dropout for the point-wise feed-forward network.
self.dropout1 = tf.keras.layers.Dropout(dropout_rate)
def call(self, x, training, mask):
# A boolean mask.
if mask is not None:
mask1 = mask[:, :, None]
mask2 = mask[:, None, :]
attention_mask = mask1 & mask2
else:
attention_mask = None
# Multi-head self-attention output (`tf.keras.layers.MultiHeadAttention `).
attn_output = self.mha(
query=x, # Query Q tensor.
value=x, # Value V tensor.
key=x, # Key K tensor.
attention_mask=attention_mask, # A boolean mask that prevents attention to certain positions.
training=training, # A boolean indicating whether the layer should behave in training mode.
)
# Multi-head self-attention output after layer normalization and a residual/skip connection.
out1 = self.layernorm1(x + attn_output) # Shape `(batch_size, input_seq_len, d_model)`
# Point-wise feed-forward network output.
ffn_output = self.ffn(out1) # Shape `(batch_size, input_seq_len, d_model)`
ffn_output = self.dropout1(ffn_output, training=training)
# Point-wise feed-forward network output after layer normalization and a residual skip connection.
out2 = self.layernorm2(out1 + ffn_output) # Shape `(batch_size, input_seq_len, d_model)`.
return out2
class Encoder(tf.keras.layers.Layer):
def __init__(self,
*,
num_layers,
d_model, # Input/output dimensionality.
num_attention_heads,
dff, # Inner-layer dimensionality.
input_vocab_size, # Input (Portuguese) vocabulary size.
dropout_rate=0.1
):
super().__init__()
self.d_model = d_model
self.num_layers = num_layers
# Embeddings + Positional encoding
self.pos_embedding = PositionalEmbedding(input_vocab_size, d_model)
# Encoder layers.
self.enc_layers = [
EncoderLayer(
d_model=d_model,
num_attention_heads=num_attention_heads,
dff=dff,
dropout_rate=dropout_rate)
for _ in range(num_layers)]
# Dropout.
self.dropout = tf.keras.layers.Dropout(dropout_rate)
# Masking.
def compute_mask(self, x, previous_mask=None):
# 2つ目のパラメータ previous_mask は無意味
# https://github.com/keras-team/keras/blob/v2.10.0/keras/layers/core/embedding.py#L173
return self.pos_embedding.compute_mask(x, previous_mask)
def call(self, x, training):
seq_len = tf.shape(x)[1]
# Sum up embeddings and positional encoding.
mask = self.compute_mask(x)
x = self.pos_embedding(x) # Shape `(batch_size, input_seq_len, d_model)`.
# Add dropout.
x = self.dropout(x, training=training)
# N encoder layers.
for i in range(self.num_layers):
x = self.enc_layers[i](x, training, mask)
return x # Shape `(batch_size, input_seq_len, d_model)`.
Decoder
ここの1つ目のAttentionがMasked Mulit-Head Attentionで、use_causal_mask=Trueとしています。これによってカンニングを防ぎます。
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self,
*,
d_model, # Input/output dimensionality.
num_attention_heads,
dff, # Inner-layer dimensionality.
dropout_rate=0.1
):
super().__init__()
# Masked multi-head self-attention.
self.mha_masked = tf.keras.layers.MultiHeadAttention(
num_heads=num_attention_heads,
key_dim=d_model, # Size of each attention head for query Q and key K.
dropout=dropout_rate
)
# Multi-head cross-attention.
self.mha_cross = tf.keras.layers.MultiHeadAttention(
num_heads=num_attention_heads,
key_dim=d_model, # Size of each attention head for query Q and key K.
dropout=dropout_rate
)
# Point-wise feed-forward network.
self.ffn = point_wise_feed_forward_network(d_model, dff)
# Layer normalization.
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
# Dropout for the point-wise feed-forward network.
self.dropout1 = tf.keras.layers.Dropout(dropout_rate)
def call(self, x, mask, enc_output, enc_mask, training):
# The encoder output shape is `(batch_size, input_seq_len, d_model)`.
# A boolean mask.
self_attention_mask = None
if mask is not None:
mask1 = mask[:, :, None]
mask2 = mask[:, None, :]
self_attention_mask = mask1 & mask2
# Masked multi-head self-attention output (`tf.keras.layers.MultiHeadAttention`).
attn_masked, attn_weights_masked = self.mha_masked(
query=x,
value=x,
key=x,
attention_mask=self_attention_mask, # A boolean mask that prevents attention to certain positions.
use_causal_mask=True, # A boolean to indicate whether to apply a causal mask to prevent tokens from attending to future tokens.
return_attention_scores=True, # Shape `(batch_size, target_seq_len, d_model)`.
training=training # A boolean indicating whether the layer should behave in training mode.
)
# Masked multi-head self-attention output after layer normalization and a residual/skip connection.
out1 = self.layernorm1(attn_masked + x)
# A boolean mask.
attention_mask = None
if mask is not None and enc_mask is not None:
mask1 = mask[:, :, None]
mask2 = enc_mask[:, None, :]
attention_mask = mask1 & mask2
# Multi-head cross-attention output (`tf.keras.layers.MultiHeadAttention `).
attn_cross, attn_weights_cross = self.mha_cross(
query=out1,
value=enc_output,
key=enc_output,
attention_mask=attention_mask, # A boolean mask that prevents attention to certain positions.
return_attention_scores=True, # Shape `(batch_size, target_seq_len, d_model)`.
training=training # A boolean indicating whether the layer should behave in training mode.
)
# Multi-head cross-attention output after layer normalization and a residual/skip connection.
out2 = self.layernorm2(attn_cross + out1) # (batch_size, target_seq_len, d_model)
# Point-wise feed-forward network output.
ffn_output = self.ffn(out2) # Shape `(batch_size, target_seq_len, d_model)`.
ffn_output = self.dropout1(ffn_output, training=training)
out3 = self.layernorm3(ffn_output + out2) # Shape `(batch_size, target_seq_len, d_model)`.
return out3, attn_weights_masked, attn_weights_cross
class Decoder(tf.keras.layers.Layer):
def __init__(self,
*,
num_layers,
d_model, # Input/output dimensionality.
num_attention_heads,
dff, # Inner-layer dimensionality.
target_vocab_size,
dropout_rate=0.1
):
super().__init__()
self.d_model = d_model
self.num_layers = num_layers
self.pos_embedding = PositionalEmbedding(target_vocab_size, d_model)
self.dec_layers = [
DecoderLayer(
d_model=d_model,
num_attention_heads=num_attention_heads,
dff=dff,
dropout_rate=dropout_rate)
for _ in range(num_layers)
]
self.dropout = tf.keras.layers.Dropout(dropout_rate)
def call(self, x, enc_output, enc_mask, training):
attention_weights = {}
mask = self.pos_embedding.compute_mask(x)
x = self.pos_embedding(x) # Shape: `(batch_size, target_seq_len, d_model)`.
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, mask, enc_output, enc_mask, training)
attention_weights[f'decoder_layer{i+1}_block1'] = block1
attention_weights[f'decoder_layer{i+1}_block2'] = block2
# The shape of x is `(batch_size, target_seq_len, d_model)`.
return x, attention_weights
Transformer
最後にTransformer全体です。
class Transformer(tf.keras.Model):
def __init__(self,
*,
num_layers, # Number of decoder layers.
d_model, # Input/output dimensionality.
num_attention_heads,
dff, # Inner-layer dimensionality.
input_vocab_size, # Input (Portuguese) vocabulary size.
target_vocab_size, # Target (English) vocabulary size.
dropout_rate=0.1
):
super().__init__()
# The encoder.
self.encoder = Encoder(
num_layers=num_layers,
d_model=d_model,
num_attention_heads=num_attention_heads,
dff=dff,
input_vocab_size=input_vocab_size,
dropout_rate=dropout_rate
)
# The decoder.
self.decoder = Decoder(
num_layers=num_layers,
d_model=d_model,
num_attention_heads=num_attention_heads,
dff=dff,
target_vocab_size=target_vocab_size,
dropout_rate=dropout_rate
)
# The final linear layer.
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inputs, training):
# Keras models prefer if you pass all your inputs in the first argument.
# Portuguese is used as the input (`inp`) language.
# English is the target (`tar`) language.
inp, tar = inputs
# The encoder output.
enc_output = self.encoder(inp, training) # `(batch_size, inp_seq_len, d_model)`
enc_mask = self.encoder.compute_mask(inp)
# The decoder output.
dec_output, attention_weights = self.decoder(
tar, enc_output, enc_mask, training) # `(batch_size, tar_seq_len, d_model)`
# The final linear layer output.
final_output = self.final_layer(dec_output) # Shape `(batch_size, tar_seq_len, target_vocab_size)`.
# Return the final output and the attention weights.
return final_output, attention_weights