言語処理100本ノック 2020 (Rev2)の「第9章: RNN, CNN」の88本目「パラメータチューニング」記録です。keras-tunerを使ってハイパーパラメータのチューニングをしています。複数モデルを用意して、ハイパーパラメータ最適化の方法やkeras-tunerの使い方を覚えて時間をかけて探索しましたが、結果的には大して良くならなかったというお話。
記事「まとめ: 言語処理100本ノックで学べることと成果」に言語処理100本ノック 2015についてはまとめていますが、追加で差分の言語処理100本ノック 2020 (Rev2)についても更新します。
参考リンク
| リンク | 備考 |
|---|---|
| 88_パラメータチューニング.ipynb | 回答プログラムのGitHubリンク |
| 言語処理100本ノック 2020 第9章: RNN, CNN | (PyTorchだけど)解き方の参考 |
| 【言語処理100本ノック 2020】第9章: RNN, CNN | (PyTorchだけど)解き方の参考 |
| まとめ: 言語処理100本ノックで学べることと成果 | 言語処理100本ノックまとめ記事 |
| Getting started with KerasTuner | |
| Visualize the hyperparameter tuning process | |
| 【公式 API】Hyperband Tuner | |
| 【公式チュートリアル】Keras Tuner の基礎 | |
| KerasTunerでのHyperBandハイパーパラメータ最適化 | このノックのために書きました |
環境
GPUを使いたかったので、Google Colaboratory使いました。Pythonやそのパッケージでより新しいバージョンありますが、新機能使っていないので、プリインストールされているものをそのまま使っています。
| 種類 | バージョン | 内容 |
|---|---|---|
| Python | 3.7.12 | Google Colaboratoryのバージョン |
| 2.0.3 | Google Driveのマウントに使用 | |
| tensorflow | 2.7.0 | ディープラーニングの主要処理 |
| nltk | 3.2.5 | Tokenの辞書作成に使用 |
| pandas | 1.1.5 | 行列に関する処理に使用 |
| keras-tuner | 1.1.0 | ハイパーパラメータチューニングに使用 |
第8章: ニューラルネット
学習内容
深層学習フレームワークを用い,再帰型ニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)を実装します.
88. パラメータチューニング
問題85や問題87のコードを改変し,ニューラルネットワークの形状やハイパーパラメータを調整しながら,高性能なカテゴリ分類器を構築せよ.
回答
回答結果
87本目ノック(CNN)との精度比較です。そんなに大差ないですね。時間かけて頑張ったのに・・・
| データセット | Loss | 正答率 |
|---|---|---|
| 訓練 | 0.332 |
88.7% |
| 検証 | 0.455 |
84.4% |
| 評価 | 0.420 |
86.1% |
参考に評価データセットの結果です。
> best_model.evaluate(X_test, y_test)
42/42 [==============================] - 1s 12ms/step - loss: 0.3973 - acc: 0.8578
回答プログラム 88_パラメータチューニング.ipynb
GitHubには確認用コードも含めていますが、ここには必要なものだけ載せています。
!pip install keras-tuner
import keras_tuner as kt
import numpy as np
import nltk
from gensim.models import KeyedVectors
import pandas as pd
import tensorflow as tf
from google.colab import drive
from tensorflow.keras.layers import concatenate, Bidirectional, Conv1D, Dense, Dropout, Embedding, Flatten, GRU, MaxPooling1D, Reshape, TextVectorization
drive.mount('/content/drive')
BASE_PATH = '/content/drive/MyDrive/ColabNotebooks/ML/NLP100_2020/'
max_len = 0
vocabulary = []
w2v_model = KeyedVectors.load_word2vec_format(BASE_PATH+'07.WordVector/input/GoogleNews-vectors-negative300.bin.gz', binary=True)
def read_dataset(type_):
global max_len
global vocabulary
df = pd.read_table(BASE_PATH+'06.MachineLearning/'+type_+'.feature.txt')
df.info()
sr_title = df['title'].str.split().explode()
max_len_ = df['title'].map(lambda x: len(x.split())).max()
if max_len < max_len_:
max_len = max_len_
if len(vocabulary) == 0:
vocabulary = [k for k, v in nltk.FreqDist(sr_title).items() if v > 1]
else:
vocabulary.extend([k for k, v in nltk.FreqDist(sr_title).items() if v > 1])
y = df['category'].replace({'b':0, 't':1, 'e':2, 'm':3})
return df['title'], tf.keras.utils.to_categorical(y, dtype='int32') # 4値分類なので訓練・検証・テスト共通でone-hot化
X_train, y_train = read_dataset('train')
X_valid, y_valid = read_dataset('valid')
X_test, y_test = read_dataset('test') # あまりこだわらずにテストデータセットも追加
# setで重複削除し、タプル形式に設定
tup_voc = tuple(set(vocabulary))
vectorize_layer = TextVectorization(
output_mode='int',
vocabulary=tup_voc,
output_sequence_length=max_len)
embedding_dim = 300
hits = 0
misses = 0
embedding_matrix = np.zeros((vectorize_layer.vocabulary_size(), embedding_dim))
for i, word in enumerate(vectorize_layer.get_vocabulary()):
try:
embedding_matrix[i] = w2v_model.get_vector(word)
hits += 1
# Words not found in embedding index will be all-zeros.
# This includes the representation for "padding" and "OOV"
except:
misses += 1
def get_model(model_type, cnn_filters, dense_dropout, gru_layers, gru_dropout):
input = tf.keras.Input(shape=(1,), dtype=tf.string)
in2emb = vectorize_layer(input)
in2emb = embedding_layer(in2emb)
if model_type[:3] == 'CNN':
in2emb = Reshape((max_len * embedding_dim, 1))(in2emb)
if model_type == 'CNN3':
conv1 = conv_layer(3, in2emb, cnn_filters)
conv2 = conv_layer(3, in2emb, cnn_filters)
conv3 = conv_layer(3, in2emb, cnn_filters)
elif model_type == 'CNN234':
conv1 = conv_layer(2, in2emb, cnn_filters)
conv2 = conv_layer(3, in2emb, cnn_filters)
conv3 = conv_layer(4, in2emb, cnn_filters)
last = concatenate([conv1, conv2, conv3])
last = Dropout(dense_dropout)(last)
elif model_type == 'RNN':
rnn = Bidirectional(GRU(gru_layers, dropout=gru_dropout,
return_sequences=True))(in2emb)
last = Bidirectional(GRU(gru_layers, dropout=gru_dropout))(rnn)
elif model_type[:8] == 'Ensemble':
rnn = Bidirectional(GRU(gru_layers, dropout=gru_dropout,
return_sequences=True))(in2emb)
rnn = Bidirectional(GRU(gru_layers, dropout=gru_dropout))(rnn)
in2emb = Reshape((max_len * embedding_dim, 1))(in2emb)
if model_type == 'Ensemble3':
conv1 = conv_layer(3, in2emb, cnn_filters)
conv2 = conv_layer(3, in2emb, cnn_filters)
conv3 = conv_layer(3, in2emb, cnn_filters)
elif model_type == 'Ensemble234':
conv1 = conv_layer(2, in2emb, cnn_filters)
conv2 = conv_layer(3, in2emb, cnn_filters)
conv3 = conv_layer(4, in2emb, cnn_filters)
last = concatenate([conv1, conv2, conv3, rnn])
last = Dropout(dense_dropout)(last)
last = Dense(4, activation='softmax')(last)
model = tf.keras.models.Model(inputs=input, outputs=last)
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['acc'])
return model
def model_builder(hp):
model_type = hp.Choice('model_type',
values = ['CNN3', 'CNN234', 'RNN', 'Ensemble3', 'Ensemble234'],
default='Ensemble3')
with hp.conditional_scope('model_type', ['CNN3', 'CNN234', 'Ensemble3', 'Ensemble234']):
cnn_filters = hp.Int('cnn_layers', min_value=2, max_value=4)
dense_dropout = hp.Float('dense_dropout', min_value=0.1, max_value=0.4, sampling='linear')
with hp.conditional_scope('model_type', ['RNN', 'Ensemble3', 'Ensemble234']):
gru_layers = hp.Int('gru_layers', min_value=32, max_value=96, step=32)
gru_dropout = hp.Float('gru_dopout', min_value=0.2, max_value=0.4, sampling='linear')
return get_model(model_type, cnn_filters, dense_dropout, gru_layers, gru_dropout)
tuner = kt.Hyperband(
model_builder,
objective='val_loss',
max_epochs=50,
factor=5,
directory="./",
project_name="nlp2020-88")
tuner.search_space_summary()
%load_ext tensorboard
%tensorboard --logdir /tmp/tb_logs
callbacks = [tf.keras.callbacks.TensorBoard("/tmp/tb_logs"),
tf.keras.callbacks.EarlyStopping(patience=5, restore_best_weights=False)]
tuner.search(X_train, y_train,
validation_data=(X_valid, y_valid),
callbacks=callbacks)
# Get the optimal hyperparameters
best_hps = tuner.get_best_hyperparameters(num_trials=1)[0]
print(best_hps.values)
tuner.results_summary()
def output_model(num):
# Get the top 10 models.
models = tuner.get_best_models(num_models=10)
best_model = models[num]
# Build the model.
# Needed for `Sequential` without specified `input_shape`.
best_model.build(input_shape=(1,))
best_model.evaluate(X_test, y_test)
best_model.summary()
tf.keras.utils.plot_model(best_model, show_shapes=True)
output_model(0)
回答解説
準備したモデル
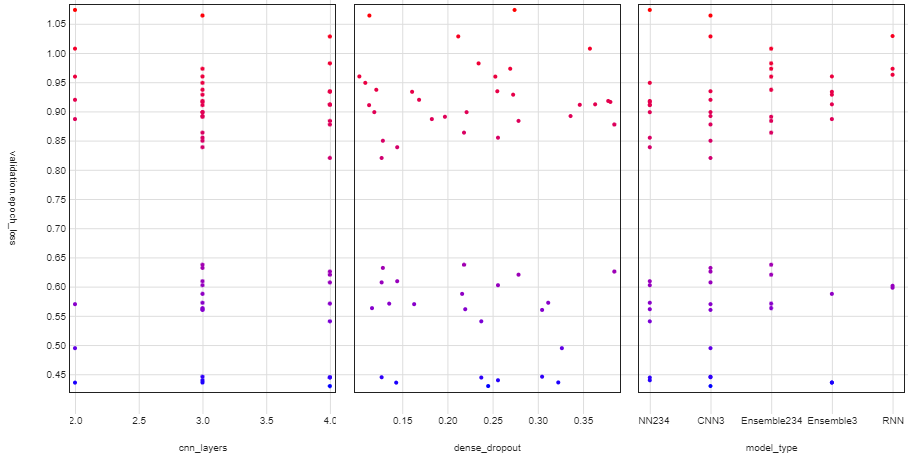
主に3種類(正確には5種類)のモデルを準備しました。条件分岐して、どのモデルが精度が良いかを探索しています。以下はモデルとしての一覧です。RNNとEnsemble234のLossとAccuracyがかなり悪いのはEpochを10で打ち切っているからです。
| ID | モデル内容 | 最高順位 | 最良検証Loss | 最良検証Accuracy |
|---|---|---|---|---|
| CNN3 | CNNのフィルタサイズ3のみ | 1位 | 0.43 | 85.3% |
| CNN234 | CNNのフィルタサイズが2と3と4の3種類 | 4位 | 0.44 | 84.6% |
| RNN | 双方向2層RNN | 17位 | 0.60 | 77.6% |
| Ensemble3 | CNN3とRNNのアンサンブル | 2位 | 0.44 | 85.6% |
| Ensemble234 | CNN234とRNNのアンサンブル | 12位 | 0.56 | 78.8% |
TensorBoardで見るとわかりやすいです。モデル種類ごとの評価LossとAccuracyを出しています。

主なモデル部分のコードです。長くなったのでget_model関数にしてハイパーパラメータの定義をしているmodel_builder関数と分けています。
def get_model(model_type, cnn_filters, dense_dropout, gru_layers, gru_dropout):
input = tf.keras.Input(shape=(1,), dtype=tf.string)
in2emb = vectorize_layer(input)
in2emb = embedding_layer(in2emb)
if model_type[:3] == 'CNN':
in2emb = Reshape((max_len * embedding_dim, 1))(in2emb)
if model_type == 'CNN3':
conv1 = conv_layer(3, in2emb, cnn_filters)
conv2 = conv_layer(3, in2emb, cnn_filters)
conv3 = conv_layer(3, in2emb, cnn_filters)
elif model_type == 'CNN234':
conv1 = conv_layer(2, in2emb, cnn_filters)
conv2 = conv_layer(3, in2emb, cnn_filters)
conv3 = conv_layer(4, in2emb, cnn_filters)
last = concatenate([conv1, conv2, conv3])
last = Dropout(dense_dropout)(last)
elif model_type == 'RNN':
rnn = Bidirectional(GRU(gru_layers, dropout=gru_dropout,
return_sequences=True))(in2emb)
last = Bidirectional(GRU(gru_layers, dropout=gru_dropout))(rnn)
elif model_type[:8] == 'Ensemble':
rnn = Bidirectional(GRU(gru_layers, dropout=gru_dropout,
return_sequences=True))(in2emb)
rnn = Bidirectional(GRU(gru_layers, dropout=gru_dropout))(rnn)
in2emb = Reshape((max_len * embedding_dim, 1))(in2emb)
if model_type == 'Ensemble3':
conv1 = conv_layer(3, in2emb, cnn_filters)
conv2 = conv_layer(3, in2emb, cnn_filters)
conv3 = conv_layer(3, in2emb, cnn_filters)
elif model_type == 'Ensemble234':
conv1 = conv_layer(2, in2emb, cnn_filters)
conv2 = conv_layer(3, in2emb, cnn_filters)
conv3 = conv_layer(4, in2emb, cnn_filters)
last = concatenate([conv1, conv2, conv3, rnn])
last = Dropout(dense_dropout)(last)
last = Dense(4, activation='softmax')(last)
model = tf.keras.models.Model(inputs=input, outputs=last)
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['acc'])
return model
def model_builder(hp):
model_type = hp.Choice('model_type',
values = ['CNN3', 'CNN234', 'RNN', 'Ensemble3', 'Ensemble234'],
default='Ensemble3')
with hp.conditional_scope('model_type', ['CNN3', 'CNN234', 'Ensemble3', 'Ensemble234']):
cnn_filters = hp.Int('cnn_layers', min_value=2, max_value=4)
dense_dropout = hp.Float('dense_dropout', min_value=0.1, max_value=0.4, sampling='linear')
with hp.conditional_scope('model_type', ['RNN', 'Ensemble3', 'Ensemble234']):
gru_layers = hp.Int('gru_layers', min_value=32, max_value=96, step=32)
gru_dropout = hp.Float('gru_dopout', min_value=0.2, max_value=0.4, sampling='linear')
return get_model(model_type, cnn_filters, dense_dropout, gru_layers, gru_dropout)
モデル1. CNN
基本的に87本目ノック(CNN)と同じです。conv_layer関数を定義して3回呼び出しているのは、フィルタサイズを変更できるようにしているためです。フィルタの枚数もハイパーパラメータにしています。
論文「A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification」と同じようにフィルタサイズを複数使うことにしました。
def conv_layer(kernel_token, in2emb, filters):
conv = Conv1D(filters=filters,
kernel_size=embedding_dim*kernel_token,
padding='same',
strides=embedding_dim,
activation='relu')(in2emb)
conv = MaxPooling1D(pool_size=2)(conv)
conv = Flatten()(conv)
return conv
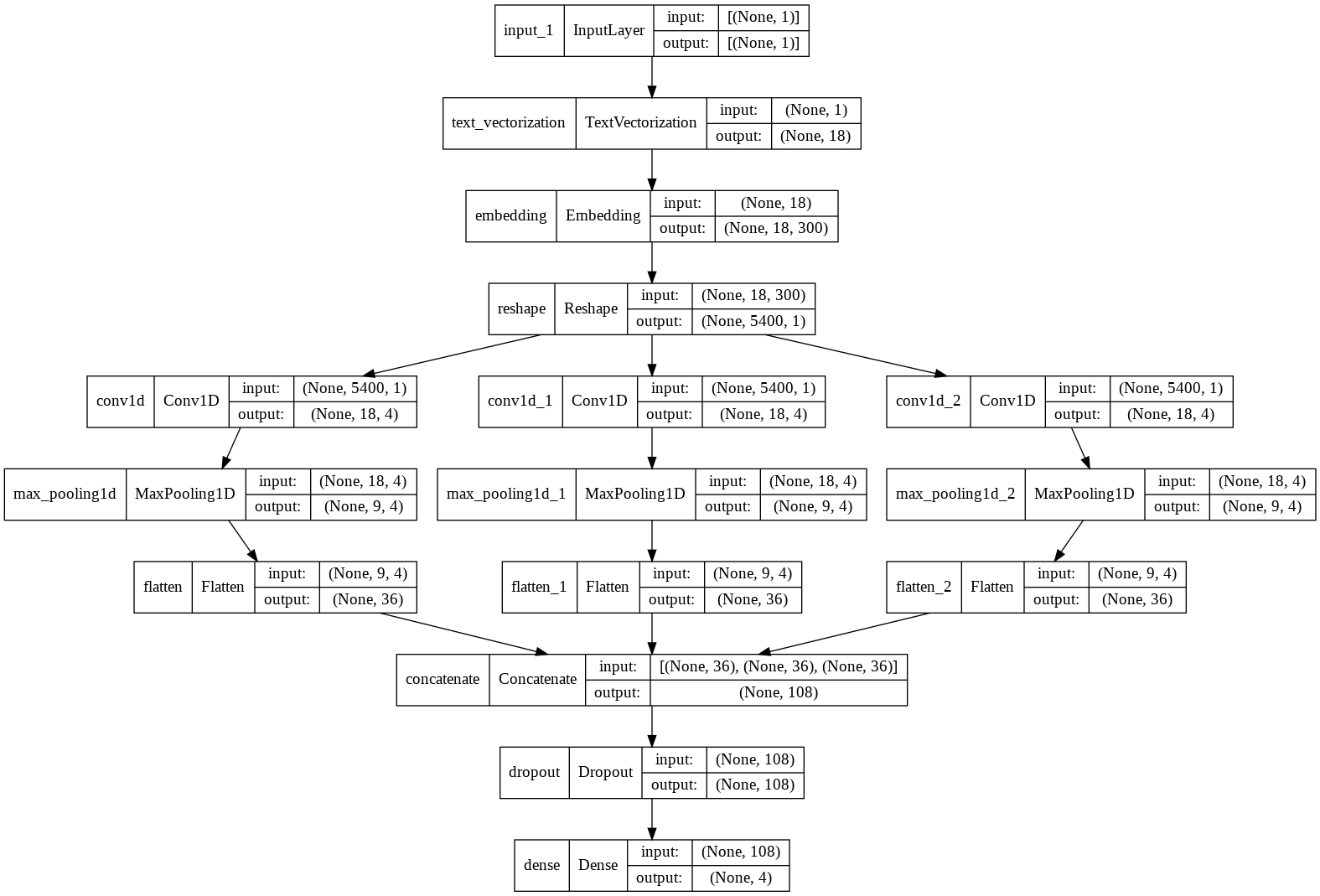
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 1)] 0 []
text_vectorization (TextVector (None, 18) 0 ['input_1[0][0]']
ization)
embedding (Embedding) (None, 18, 300) 2341200 ['text_vectorization[124][0]']
reshape (Reshape) (None, 5400, 1) 0 ['embedding[124][0]']
conv1d (Conv1D) (None, 18, 4) 3604 ['reshape[0][0]']
conv1d_1 (Conv1D) (None, 18, 4) 3604 ['reshape[0][0]']
conv1d_2 (Conv1D) (None, 18, 4) 3604 ['reshape[0][0]']
max_pooling1d (MaxPooling1D) (None, 9, 4) 0 ['conv1d[0][0]']
max_pooling1d_1 (MaxPooling1D) (None, 9, 4) 0 ['conv1d_1[0][0]']
max_pooling1d_2 (MaxPooling1D) (None, 9, 4) 0 ['conv1d_2[0][0]']
flatten (Flatten) (None, 36) 0 ['max_pooling1d[0][0]']
flatten_1 (Flatten) (None, 36) 0 ['max_pooling1d_1[0][0]']
flatten_2 (Flatten) (None, 36) 0 ['max_pooling1d_2[0][0]']
concatenate (Concatenate) (None, 108) 0 ['flatten[0][0]',
'flatten_1[0][0]',
'flatten_2[0][0]']
dropout (Dropout) (None, 108) 0 ['concatenate[0][0]']
dense (Dense) (None, 4) 436 ['dropout[0][0]']
==================================================================================================
Total params: 2,352,448
Trainable params: 11,248
Non-trainable params: 2,341,200
__________________________________________________________________________________________________
CNNで使っているフィルタ枚数(cnn_layers)とフィルタサイズ(dense_dropout)およびフィルタサイズ(model_typeがCNN3かCNN234の差)によるValidation Lossの違い。大差ないようにも見えます。
モデル2. RNN
基本的に85本目ノック(RNN)と同じです。gru_layer(GRUのユニット数)とgru_dropout(GRUのドロップアプト率)をハイパーパラメータとして定義。
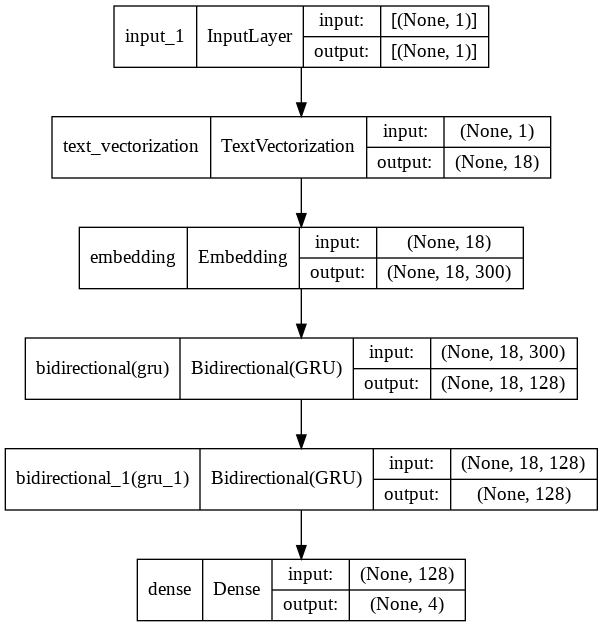
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 1)] 0
text_vectorization (TextVec (None, 18) 0
torization)
embedding (Embedding) (None, 18, 300) 2341200
bidirectional (Bidirectiona (None, 18, 128) 140544
l)
bidirectional_1 (Bidirectio (None, 128) 74496
nal)
dense (Dense) (None, 4) 516
=================================================================
Total params: 2,556,756
Trainable params: 215,556
Non-trainable params: 2,341,200
_________________________________________________________________
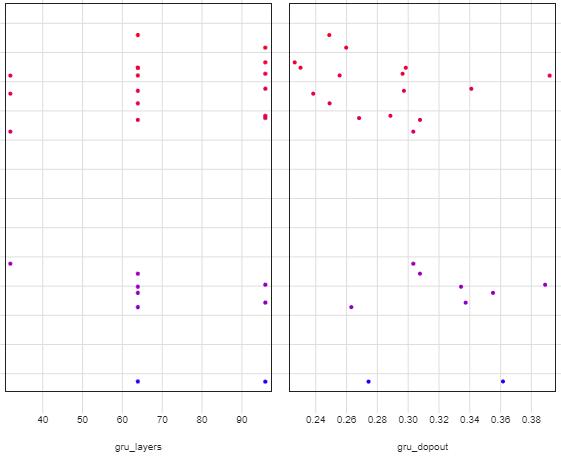
ハイパーパラメータによる差異。GRUユニット32は良くないようですね。
モデル3. CNNとRNNのアンサンブル
CNNとRNNのアンサンブルにしました。これが1位かと予測していましたが、意外とそうでもなかった。
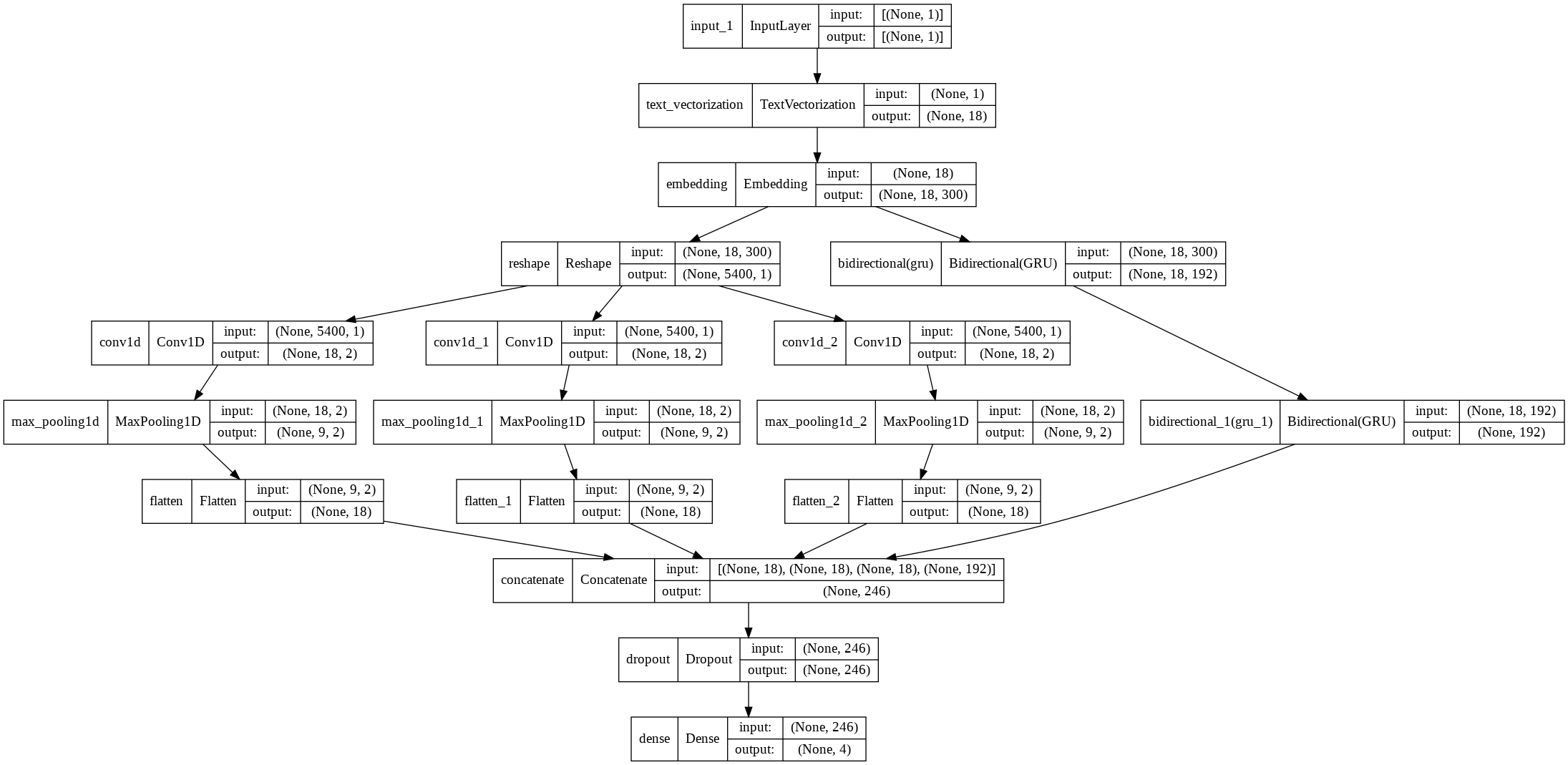
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 1)] 0 []
text_vectorization (TextVector (None, 18) 0 ['input_1[0][0]']
ization)
embedding (Embedding) (None, 18, 300) 2341200 ['text_vectorization[145][0]']
reshape (Reshape) (None, 5400, 1) 0 ['embedding[145][0]']
conv1d (Conv1D) (None, 18, 2) 1802 ['reshape[0][0]']
conv1d_1 (Conv1D) (None, 18, 2) 1802 ['reshape[0][0]']
conv1d_2 (Conv1D) (None, 18, 2) 1802 ['reshape[0][0]']
max_pooling1d (MaxPooling1D) (None, 9, 2) 0 ['conv1d[0][0]']
max_pooling1d_1 (MaxPooling1D) (None, 9, 2) 0 ['conv1d_1[0][0]']
max_pooling1d_2 (MaxPooling1D) (None, 9, 2) 0 ['conv1d_2[0][0]']
bidirectional (Bidirectional) (None, 18, 192) 229248 ['embedding[145][0]']
flatten (Flatten) (None, 18) 0 ['max_pooling1d[0][0]']
flatten_1 (Flatten) (None, 18) 0 ['max_pooling1d_1[0][0]']
flatten_2 (Flatten) (None, 18) 0 ['max_pooling1d_2[0][0]']
bidirectional_1 (Bidirectional (None, 192) 167040 ['bidirectional[0][0]']
)
concatenate (Concatenate) (None, 246) 0 ['flatten[0][0]',
'flatten_1[0][0]',
'flatten_2[0][0]',
'bidirectional_1[0][0]']
dropout (Dropout) (None, 246) 0 ['concatenate[0][0]']
dense (Dense) (None, 4) 988 ['dropout[0][0]']
==================================================================================================
Total params: 2,743,882
Trainable params: 402,682
Non-trainable params: 2,341,200
__________________________________________________________________________________________________
ハイパーパラメータ定義
エラーに悩み実装に意外と時間かかりました。
なぜか、hp.Choiceでdefaultに設定しないとエラーが発生。デフォルト値を含んでいないconditional_scopeを設定しているとエラーが起きました。defaultには2種類のconditional_scopeに共通となっているmodel_type(ここではEnsemble3かEnsemble234)を選択しないといけませんでした。バグだと思います。
def model_builder(hp):
model_type = hp.Choice('model_type',
values = ['CNN3', 'CNN234', 'RNN', 'Ensemble3', 'Ensemble234'],
default='Ensemble3')
with hp.conditional_scope('model_type', ['CNN3', 'CNN234', 'Ensemble3', 'Ensemble234']):
cnn_filters = hp.Int('cnn_layers', min_value=2, max_value=4)
dense_dropout = hp.Float('dense_dropout', min_value=0.1, max_value=0.4, sampling='linear')
with hp.conditional_scope('model_type', ['RNN', 'Ensemble3', 'Ensemble234']):
gru_layers = hp.Int('gru_layers', min_value=32, max_value=96, step=32)
gru_dropout = hp.Float('gru_dopout', min_value=0.2, max_value=0.4, sampling='linear')
return get_model(model_type, cnn_filters, dense_dropout, gru_layers, gru_dropout)
tuner定義
Hyperbandのtunerを定義します。max_epochsを50にしたのは少なかったかも。あまり徹底的にやるつもりもなかったので、factorを5にして試行数を少なくしています。
tuner = kt.Hyperband(
model_builder,
objective='val_loss',
max_epochs=50,
factor=5,
directory="./",
project_name="nlp2020-88")
tuner.search_space_summary()
Search space summary
Default search space size: 5
model_type (Choice)
{'default': 'Ensemble3', 'conditions': [], 'values': ['CNN3', 'CNN234', 'RNN', 'Ensemble3', 'Ensemble234'], 'ordered': False}
cnn_layers (Int)
{'default': None, 'conditions': [{'class_name': 'Parent', 'config': {'name': 'model_type', 'values': ['CNN3', 'CNN234', 'Ensemble3', 'Ensemble234']}}], 'min_value': 2, 'max_value': 4, 'step': 1, 'sampling': None}
dense_dropout (Float)
{'default': 0.1, 'conditions': [{'class_name': 'Parent', 'config': {'name': 'model_type', 'values': ['CNN3', 'CNN234', 'Ensemble3', 'Ensemble234']}}], 'min_value': 0.1, 'max_value': 0.4, 'step': None, 'sampling': 'linear'}
gru_layers (Int)
{'default': None, 'conditions': [{'class_name': 'Parent', 'config': {'name': 'model_type', 'values': ['RNN', 'Ensemble3', 'Ensemble234']}}], 'min_value': 32, 'max_value': 96, 'step': 32, 'sampling': None}
gru_dopout (Float)
{'default': 0.2, 'conditions': [{'class_name': 'Parent', 'config': {'name': 'model_type', 'values': ['RNN', 'Ensemble3', 'Ensemble234']}}], 'min_value': 0.2, 'max_value': 0.4, 'step': None, 'sampling': 'linear'}
ハイパーパラメータ探索実行
コールバック関数を指定してsearch関数でハイパーパラメータ探索をします。59のTrialをして約1時間半かかりました。
TensorBoard 使えるようにしておくと結果が見やすいです。
%%time
callbacks = [tf.keras.callbacks.TensorBoard("/tmp/tb_logs"),
tf.keras.callbacks.EarlyStopping(patience=5, restore_best_weights=False)]
tuner.search(X_train, y_train,
validation_data=(X_valid, y_valid),
callbacks=callbacks)
# Get the optimal hyperparameters
best_hps = tuner.get_best_hyperparameters(num_trials=1)[0]
print(best_hps.values)
Trial 59 Complete [00h 12m 32s]
val_loss: 0.43473121523857117
Best val_loss So Far: 0.4296127259731293
Total elapsed time: 01h 25m 35s
INFO:tensorflow:Oracle triggered exit
{'model_type': 'CNN3', 'cnn_layers': 4, 'dense_dropout': 0.24507070702674155, 'tuner/epochs': 50, 'tuner/initial_epoch': 0, 'tuner/bracket': 0, 'tuner/round': 0}
CPU times: user 55min 39s, sys: 6min 1s, total: 1h 1min 41s
Wall time: 1h 25min 35s
ハイパーパラメータ探索結果出力
ハイパーパラメータ探索結果を出力します。Trialごとに1行空けて欲しい。
> tuner.results_summary(20)
Results summary
Results in ./nlp2020-88
Showing 20 best trials
Objective(name='val_loss', direction='min')
Trial summary
Hyperparameters:
model_type: CNN3
cnn_layers: 4
dense_dropout: 0.24507070702674155
tuner/epochs: 50
tuner/initial_epoch: 0
tuner/bracket: 0
tuner/round: 0
Score: 0.4296127259731293
Trial summary
Hyperparameters:
model_type: Ensemble3
cnn_layers: 2
dense_dropout: 0.14334538160016333
gru_layers: 96
gru_dopout: 0.2745871530023718
tuner/epochs: 50
tuner/initial_epoch: 0
tuner/bracket: 0
tuner/round: 0
Score: 0.43473121523857117
後略