Heroku Postgres(hobby)について
例えばTDNET(決算短信)やEDINET(有価証券報告書や大量保有報告書)などの開示資料のXBRLファイルを読み込んでタグの値を取得した後に、どこかのDBに格納しようと考えた場合(仕事ないし会社の業務ではなく、個人でお金をかけずにやろうとした場合)に、例えばHeroku Postgresの利用が選択肢の一つとして考えられる。
Heroku Postgresは、10000行までならば無料(hobby-dev)で利用することが可能(2019年7月時点)
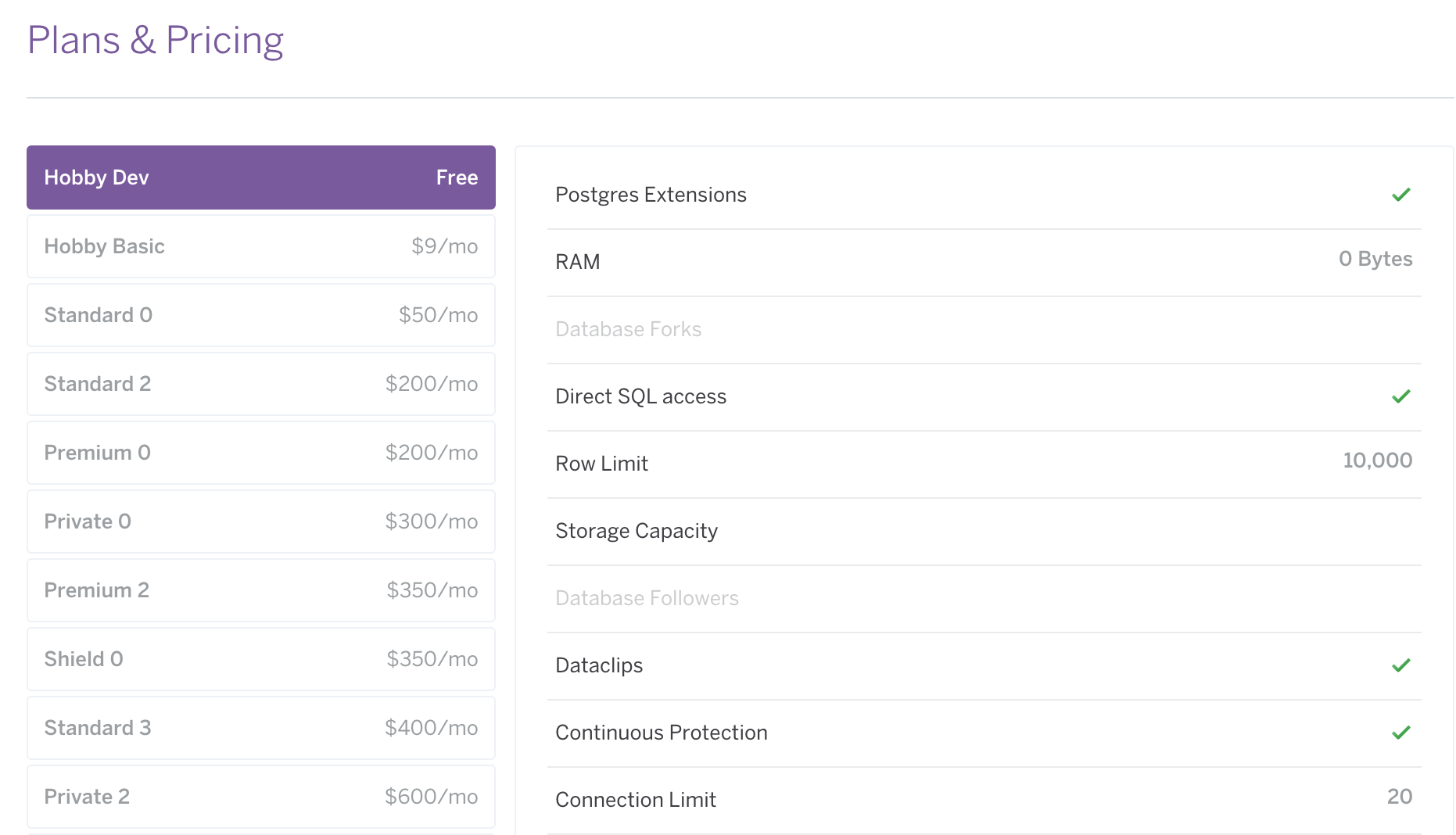
なおHeroku Postgres(hobby-dev)で10000行以上の利用になりそうな場合は、hobby-basic(月額9USD)へのアップグレードが必要になる。hobby-basicにすると、レコード格納上限が1000万行まで引き上げられる。
https://elements.heroku.com/addons/heroku-postgresql
Heroku PostgresとGoogle Colaboratoryの併用
Heroku Postgresの利用イメージだが、ローカルのAnaconda環境のpythonスクリプトでも、Google Colaboratoryでもなんでもいいが、最寄りのpython実行環境からHerokuのPostgresqlのDBに接続して利用するといった使い方などは、どうだろうか?
import pandas as pd
import sqlalchemy
from sqlalchemy import create_engine
engine = create_engine('postgres://user:pwd@hostname:5432/dbname')
lst=[i for i in range(999)]
df = pd.DataFrame(lst)
print(df)
df.to_sql('testtbl', engine, if_exists='append', index=False)
※上記スクリプトのcreate_engineで記述しているDB接続情報(user,pwd,hostname,dbname)に、Heroku上で作成したPostgresqlのDB設定情報を指定する。
Heroku PostgresをHerokuのアプリ(例えばpythonスクリプト)上で利用するというのが、ごく一般的な使い方だと思うが、プログラミング初心者的には、Herokuにpythonのアプリをデプロイするとか、gitコマンドでHerokuにpythonスクリプトをherokuにアップロード?push?するといったことが煩雑というか、gitコマンドが心理的ハードルが少し高いように感じられるので、例えばGoogle Colaboratoryならば利用は簡単(Googleアカウントを作ってログインしてGoogleドライブを開けば誰でも利用可能)なのではないか?、gitコマンドでherokuを利用するのGoogleログインするのとを比較すると、利用障壁は後者の方が低いのではないかと思うのだが、如何?
postgresSQLに対応した無料のSQLクライアントツールについて
なのでSQLを書かなくても、Herokuの管理画面でHeroku Postgresのボタン押してDBをこしらえて、pythonというかpandas(sqlalchemy)にてスクリプトを書いてデータをハンドリングすることが可能...なのだが、一応SQLクライアントツールとして、例えば「DBiever」みたいなものをPCに入れておくと、HerokuのpostgreSqlのDBに接続してSQLで確認できるようにしておくといいかも。
https://dbeaver.io/download/
DBieverは、postgresqlにも対応したSQLクライアントツール(無料)であり、最近「teamSQL」という無料のクライアントツールがサービス終了して、別の無料の代替RDBクライアントツールを探していた時に見つけたもので、WindowsOSやMac、Linuxに対応しているとのこと。
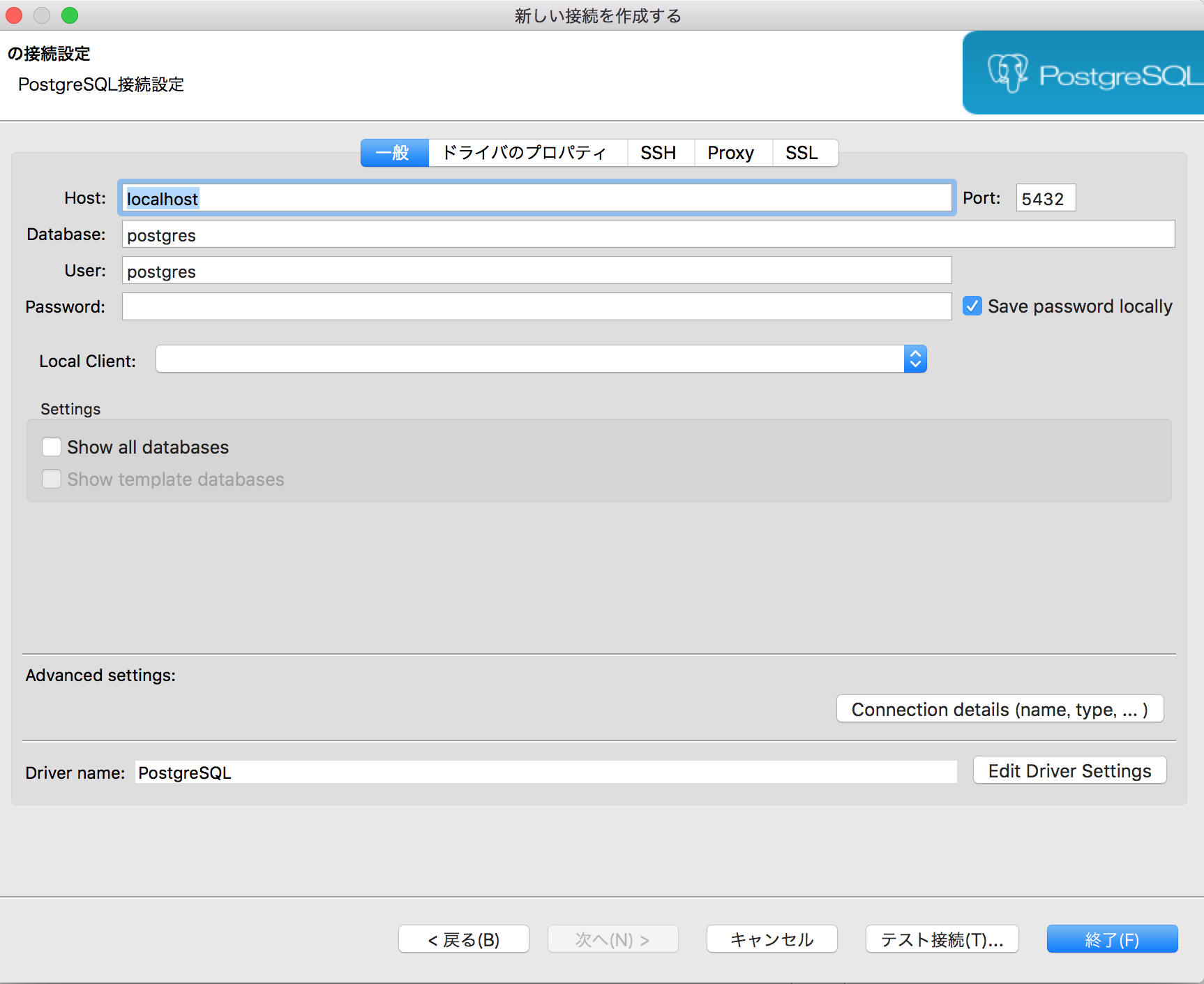
DBieverを以下のURLからダウンロードして手持ちの端末にインストールした後、DBieverを起動して、利用するRBBを選択(ここではpostgresqlをチョイス!)し、以下のような画面にてDB接続先設定を入力してあげると、GUIでRDBを管理利用することが可能になる。
注:RDBクライアントツールとしては、上記DBieverの他にも、いろいろなものがある模様↓
・Oracle SQL developer
Oracle社謹製の無料のクライアントツール、一応OracleのHPでID登録が必要
http://tizio1976.blogspot.com/2017/02/oracle-sql-developer-postgresql.html
・Azure Data Studio
Microsoft社謹製の無料のクライアントツール。MSSQLだけでなくPostgresqlも利用可能になったっぽい
https://azure.microsoft.com/ja-jp/blog/azure-data-studio-an-open-source-gui-editor-for-postgres/
Heroku Postgresqlを無料で利用する話とデータ格納方法との関連性について
Heroku Postgresqlを無料で利用するためには、格納レコード数を10000件以内に抑える必要があるが、上記のスクリプト(test1.py)のようにto_sql()で格納するデータフレームのデータの持たせ方を縦長にしてしまうと、Postgresqlにデータ格納した際のテーブルの格納件数は、999件(999rows × 1columns)になる。
これを例えば以下のように、データフレームをT転地するなり、pandasのlong-formatからwide-format形式に横長にデータの持たせ方を変形してからto_sql()でHeroku PostgresのDBにテーブル格納しにいけば、10000行の上限に達する時間をより後ろに長びかせることができるのではないかと、超セコイことを考えたりしつつ(汗
# 縦のデータフレームを横の形に転地した状態でpostgresqlのDBのテーブルに格納
df.T.to_sql('testtbl', engine, if_exists='append', index=False)
※例えばデータフレームをT(転地)すると、1行(1rows x 999columns)で格納されるとか?

リレーショナルデータベースにおけるテーブル設計を鑑みるに、一般的には正規化した縦長な形でテーブル構造を持っておくと、テーブル検索する際のインデックスが縦長のテーブルに効きやすく、テーブル検索が早い(一方の非正規化の横長な形でテーブル構造を持つとインデックスが効かずテーブル検索が激遅になる)ということだと思うのだが。。。
例えばHeroku Postgres(hobby-dev)を10000件の格納上限になるべく引っかからないように、横長にデータフレームを作成して、to_sql()でDBにテーブル格納する。またそのDBを参照する際は、postgresqlでviewなどを介して、横長テーブルを縦長?(に変換する必要性がそもそもあるのかという疑問もあるが)にした上でpandasでread_sql()で参照する、その場合に横長にテーブルを持たせた場合に、テーブルのインデックスが果たして効くのだろうか?テーブル検索で速さが担保できるのか?という話であり、そこはテーブル設計とHeroku Postgres(hobby-dev)の10000行の利用上限とのバランスというかトレードオフというか。実際のHeroku Postgresの利用状況に応じて、適宜考える必要あり。
(まあHeroku Postgresqlをhobby-basicにして、月額9ドルくらい払いなさいよという事でファイナルアンサーなのかもしれないですけど爆)
補題:PostgreSqlでSQLを実行する
--現在日時を取得
select current_timestamp;
--CTE
with hoge
as(
select current_date --現在の日付
, current_time --現在の時刻
)
select *
from hoge;
※ DBieverで実行
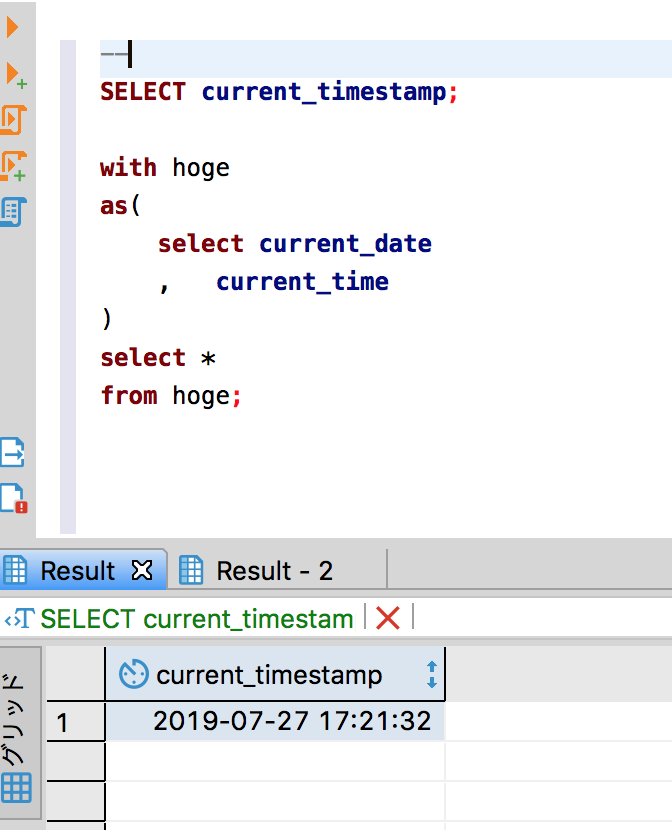
現在日時はPostgreSqlの場合はcurrent_timestampで取得。どうやら日本時間がselect文で普通に返ってきた。多分DB作成時にtimezoneがTokyoになっているのであろうと思われ...
https://www.postgresql.jp/document/9.4/html/functions-datetime.html#FUNCTIONS-DATETIME-CURRENT
あとPostgreSqlでもCTEが記述可能。クエリーの実行のショートカットキーは「ctrl」+「Enter」、ハイライトした箇所のみのクエリー実行も可能。