1.有報キャッチャーAPIでTDNET決算短信XBRLファイルを取得して値を読み込む
import requests
from bs4 import BeautifulSoup
import os
import zipfile
import re
import xml.etree.ElementTree as ET
import pandas as pd
def fn_parse(sic , xbrl_path):
# htmファイル読み込み
ff = open( xbrl_path , "r" ,encoding="utf-8" ).read()
soup = BeautifulSoup( ff ,"html.parser")
#ファイル名には命名規則があるので、ファイル名から必要属性情報等を取得するとか?
rpt_nm = xbrl_path.split("-")[1]
print(rpt_nm )
# summaryとci以外の書類(bs,pl,cf,ss)には、h2タグがあるのでそこから判定するとか?
#if 'Summary' not in xbrl_path:
# #if 'ci' not in hs:
# h2 = soup.find("h2")
# if h2 != None: print('★' + str(h2.text) )
#ix:nonnumeric
print( "■ix:nonnumeric" )
nms = soup.find_all("ix:nonnumeric")
for nm in nms:
# print(str(nm.get("name")))
lst = ['SecuritiesCode','URL','CompanyName','FilingDate','FiscalYearEnd']
lst = lst + ['AccountingStandardsDEI','EDINETCodeDEI','CurrentFiscalYearStartDateDEI','CurrentPeriodEndDateDEI']
x = [print(i,nm.text) for i in lst if i in "tse-ed-t:"+nm.get("name") ]
#ix:nonfraction
elems = soup.find_all("ix:nonfraction" )
print( "■ix:nonfraction" )
for elem in elems:
print(str(elem.get("name")))
print(str(elem.get("contextref")))
#print(str(elem.get("decimals")))
#print(str(elem.get("scale")))
#print(str(elem.get("unitref")))
print(elem.text)
'''
'''
def fn_htm(sic,url):
#XBRLダウンロード
fn = str(sic) +".zip"
os.system("wget -O " + str(fn) + " " + str(url))
# ZIP解凍
with zipfile.ZipFile( str(fn), 'r' ) as myzip:
infos = myzip.infolist()
for info in infos:
base, ext = os.path.splitext(info.filename)
# htmの読み込み
if ext == '.htm':
if str(base).find('Summary')>0 or str(base).find('Attachment')>0 :
myzip.extract(info.filename)
print('■□■' + info.filename)
dict = fn_parse(sic , info.filename)
def fn_srch(sic):
# 有報キャッチャー検索
url='http://resource.ufocatch.com/atom/tdnetx/query/'+str(sic)+'0'
r = requests.get(url)
soup = BeautifulSoup( r.text,'html.parser')
enty = soup.find_all("entry")
for i in enty:
ttl=i.find_all("title")
# 決算短信のXBRL
if str(ttl).find('決算')>-1and str(ttl).find('訂正')==-1:
lnks=i.find_all("link")
print(ttl)
print(lnks[0])
print(lnks[1])
url =lnks[1].get('href')
fn = fn_htm(sic, url) if url !=''else 'hoge'
# main
if __name__ == '__main__':
sic=4382 # 4382_Heroz ※2019.06.12に短信[本決算]を発表
fn_srch(sic)
※ スクリプト実行結果イメージ (google colab上で実行)
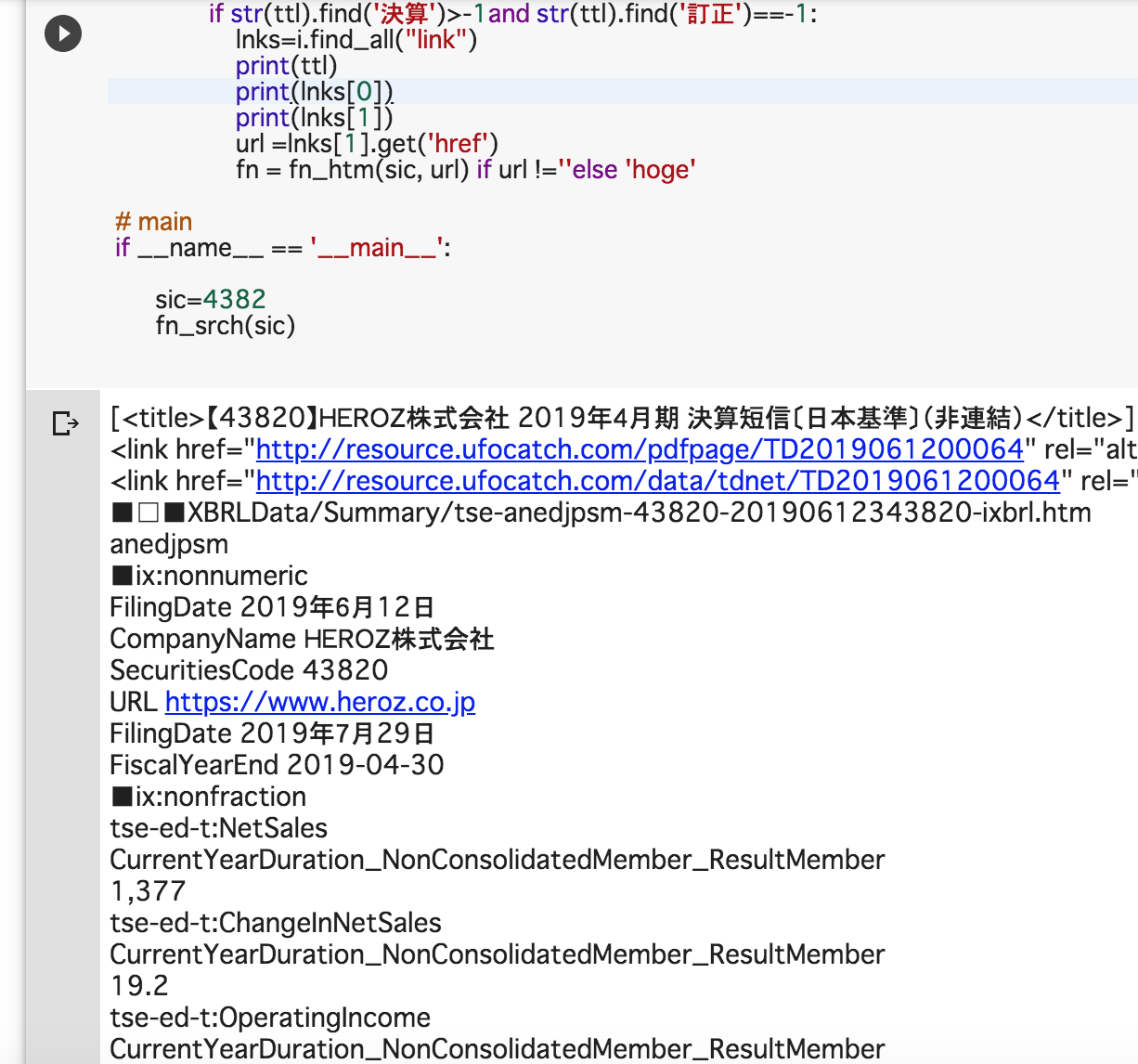
・EDINETのXBRLファイル(拡張子が.xblr)をpythonで読み込むにはXMLを処理するライブラリ(ElementTreeなど)を利用したが、今回の適時開示情報の決算短信XBRLを処理する際には、Webスクレイピングでおなじみのpythonライブラリ「BeautifulSoup」を利用する。
・TSEのXBRLを操作する際には、ElementTreeは使用しない。
・適時開示情報なり有報キャッチャーAPIを検索して、任意の銘柄の決算短信XBRLのZIPファイルをダウンロードして、ZIP解凍すると、中のディレクトリは決算短信一面(サマリー情報)のファイルが収録されているsummaryフォルダと、財務諸表のファイルが格納されているAttachmentフォルダで構成されている。
・各フォルダ内には、インラインXBRL(人間も読むことができるXBRL構造のファイルで拡張子が.htmのファイル)が収録されているので、このhtmファイルをbeautifuSoupで読み込んで、find_all()で「ix:nonnumeric」と「ix:nonfraction」のタグを取得して、あとはループ処理で任意のタグをピックアップすれば値の取得は可能。
・htmファイルのファイル名には命名規則があって、ファイル名でどの銘柄の連結単独、報告書の種類や決算年月日(PeriodStart/PeriodEnd)などが判明する。
・htmファイル内には、h2タグがあって、報告書の種類(貸借対照表BSか損益計算書PLかキャッシュフローCFかなど)のタイトルとして記述されているので、最初はこのh2タグでファイルの種類を判定しようかと思ったのだが、観察してみるとサマリー(短信一面)と包括利益計算書(ci ← Comprehensive Income)には、h2タグがなさそうだったので、読み込むhtmファイルのファイル名を取得して、属性方法等を判定取得する方法のほうが手っ取り早いかもしれない。
・証券コードや提出会社名、提出日や会計基準、会計年度や決算年月日(periodstart/periodend)などは「ix:nonnumeric」で取得可能。
・項目のタグ名やタグのcontextRef(XMLのアトリビュート値)、タグ内の値は「ix:nonfraction」タグで取得可能。例えば売上高のタグは「tse-ed-t:NetSales」であり、今期の値か前期の値かはcontextRefの値で判定。
2.JPX適時開示ページを閲覧して、tseのXBRLファイルを読み込んで値を取得する
import datetime
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
import requests
import os
import zipfile
import re
def fn_parse(sic , xbrl_path):
# htmファイル読み込み
ff = open( xbrl_path , "r" ,encoding="utf-8" ).read()
soup = BeautifulSoup( ff ,"html.parser")
#ファイル名には命名規則があるので、そこから属性情報等を取得する...
rpt_nm = xbrl_path.split("-")[1]
print(rpt_nm )
#ix:nonnumeric
print( "■ix:nonnumeric" )
nms = soup.find_all("ix:nonnumeric")
for nm in nms:
# print(str(nm.get("name")))
lst = ['SecuritiesCode','URL','CompanyName','FilingDate','FiscalYearEnd']
lst = lst + ['AccountingStandardsDEI','EDINETCodeDEI','CurrentFiscalYearStartDateDEI','CurrentPeriodEndDateDEI']
x = [print(i,nm.text) for i in lst if i in "tse-ed-t:"+nm.get("name") ]
#ix:nonfraction
elems = soup.find_all("ix:nonfraction" )
print( "■ix:nonfraction" )
for elem in elems:
print(str(elem.get("name")))
print(str(elem.get("contextref")))
#print(str(elem.get("decimals")))
#print(str(elem.get("scale")))
#print(str(elem.get("unitref")))
print(elem.text)
def fn_htm(sic,fn):
url = 'https://www.release.tdnet.info/inbs/' + str(fn)
#XBRLダウンロード
fn = str(sic) +".zip"
os.system("wget -O " + str(fn) + " " + str(url))
# ZIP解凍
with zipfile.ZipFile( str(fn), 'r' ) as myzip:
infos = myzip.infolist()
for info in infos:
base, ext = os.path.splitext(info.filename)
# htmの読み込み
if ext == '.htm':
if str(base).find('Summary')>0 or str(base).find('Attachment')>0 :
myzip.extract(info.filename)
print('■□■' + info.filename)
dict = fn_parse(sic , info.filename)
def fn_make_df(url):
#変数設定
a,b,c,d,e,f = [],[],[],[],[],[] #リストを6つ用意
df = pd.DataFrame() #取得結果格納用のデータフレーム
#ページの閲覧
html = urlopen(url)
bsObj = BeautifulSoup(html, "html.parser")
tbl3 = bsObj.findAll("table")[3]
trs = tbl3.findAll("tr")
for tr in trs:
lst=[]
tds = tr.findAll('td')
for td in tds:
#各tdの値を各リストに各々格納
if td.get("class")[1] =="kjTime":a += [td.text ] #開示時刻
if td.get("class")[1] =="kjCode":b += [td.text ] #コード
if td.get("class")[1] =="kjName":c += [td.text ] #社名
if td.get("class")[1] =="kjTitle": d += [td.text ]
if td.get("class")[1] =="kjTitle": #pdfのリンクURL
e += [td.a.get("href") ] if td.a is not None else [td.a ]
if td.get("class")[1] =="kjXbrl" : #XBRLのDLリンク
f += [td.a.get("href") ] if td.a is not None else [td.a ]
#取得結果格納リスト群からデータフレーム生成
df = pd.DataFrame(
data={'A': a, 'B': b, 'C': c, 'D': d, 'E': e, 'F': f},
columns=['A', 'B', 'C', 'D', 'E', 'F'])
return df
def fn_tkjkj(date):
# URL文字列の生成
url0 = 'https://www.release.tdnet.info/inbs/'
url1 = url0 + 'I_list_{}_{}.html'.format('001',date)
print(url1)
# 該当URLを閲覧
html = urlopen(url1)
bsObj = BeautifulSoup(html, "html.parser")
tbl1 = bsObj.findAll("table")[1]
dv1 = tbl1.findAll("div",{"class":"kaijiSum"})
dv2 = tbl1.findAll("div",{"class":"pager-O"})
dv3 = tbl1.findAll("div",{"class":"pager-M"})
if dv1 ==[]:
print('開示0件')
else:
#print(str(dv1).split('全')[1].split('</')[0])
lst =[ int(i.string) for i in dv3]
if lst ==[]:
df = fn_make_df(url1)
# print(df)
else:
# ページ数の取得
mxpg= max(lst)
print( mxpg )
# 再度URL文字列の生成
for i in range(mxpg):
s = str(i + 1)
print(date,url0 )
url1= url0 + 'I_list_{}_{}.html'.format(s.zfill(3) , str(date))
print(s , url1)#
# ページを逐次閲覧して開示情報を取得
df = fn_make_df(url1)
# 短信XBRLに限定(短信訂正は除外、XBRLの付いてないものも除外)
df = df[df["D"].str.contains('短信')]
df = df[~df["D"].str.contains('訂正')]
df = df[~df["F"].isnull()]
# XBRL(htm)の読み取り
x = [fn_htm(sic,fn) for sic, fn in zip(df["B"], df["F"])]
#x = [print(sic,fn) for sic, fn in zip(df["B"], df["F"])]
# main
if __name__ == '__main__':
# 日付
date = datetime.datetime.today().strftime("%Y%m%d")
#
date = '20190614'
fn_tkjkj(date)
※ スクリプト実行結果イメージ (google colab上で実行)
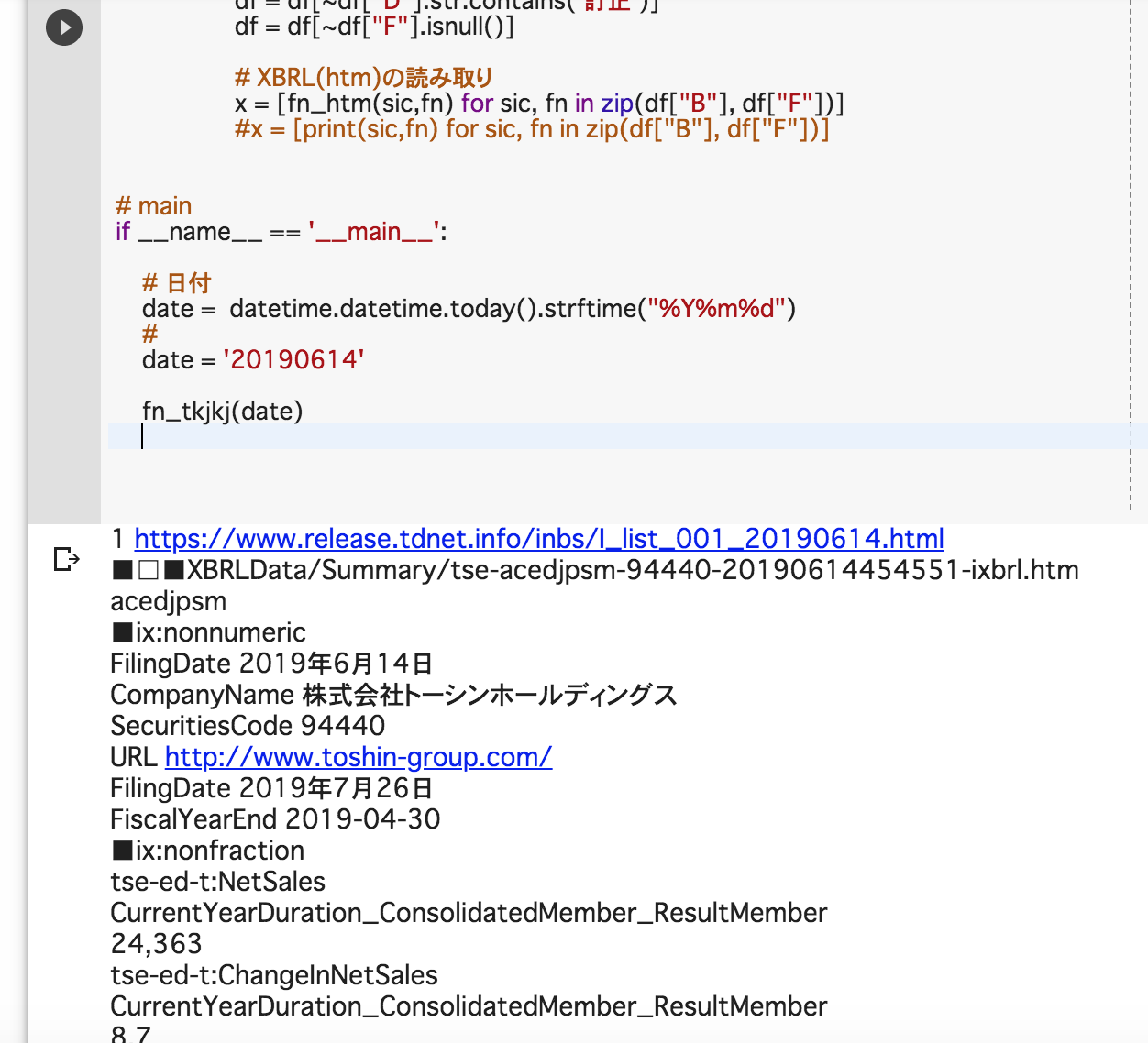
・前回JPX適時開示情報のページを閲覧するスクリプトについて考察したが、このページから開示会社の証券コード及び会社名、提出日時や開示ファイルの表題、pdfのURLとXBRLファイルのURLが取得可能なので、まずBeautifuSoupでこのWebページをスクレイピングした結果を、pandasでdfオブジェクトを生成して、必要な情報のみに限定(← 決算短信に限定する、短信訂正は今回は除外、XBRLファイルのリンクURLがついていないレコードも割愛)して、XBRLのリンクURLのリスト群にした上で、上記1.で考察試作したスクリプトのように1件ずつXBRLファイルのURLファイルをwgetでダウンロードして、ZIPファイルを解凍して該当フォルダ(summaryとattachment)内の拡張子.htmのファイルを再度beautifulSoupで読み込んで、find_all()で「ix:nonnumeric」と「ix:nonfraction」のタグを取得すれば、発表直後の決算短信のデータの値を速やかに取得することが可能。
・上記のスクリプトのロジックでは、前回決算発表が集中した日(2019/05/10)の適時開示情報のページが10ページを超えたケースには、まだ対応していないので、これは後日修正する必要あり。
・決算の発表が集中する閑散期でない期間を想定して、決算発表日時を15時台発表分とか16時台発表分とかで絞る処理を加えたほうがいいかもしれない(← 適時開示の決算が集中するのは、主に2月、5月、8月、11月。それは日本の東証等に上場している会社は決算期が3月の会社が多いためで、それ以外の月はだいたい閑散期とみなしてよい)。
3.補足
・塩漬けマンさんは、適時開示情報のXBRLの読み込みを断念した模様ですが、一応上記のpythonスクリプトで開示された短信データを即数値読み込み取得は可能かと思われ。某バフェッ◯コードのAPIやEXCELアドインよりも数値が手元に到達するスピードは、おそらく早いでっせ...
・さはさりながらも、適時開示の決算短信の発表って、東証(マーケット)が閉まった15時以降の開示が多いので、それほどスピード勝負で発表された適時開示XBRLを秒殺でさばく必要性ってあるのかな?(翌営業日の東証(マーケット)が開く朝9時までに作業を終えればいいのでは?)と思いつつ。
・自分ほぼGAFA(と言うよりGoogle神)の下僕?なので、google Colaboratory(← 無料)を使って上記スクリプトを実行することをイメージしています。なお上記pythonスクリプトでは、print()で取得した値を表示させていますが、今後想定される後続処理としては、例えばHerokuのpostgressのRDBなどに接続して、取得した結果をpandasのデータフレームオブジェクトとして生成して、pandasのto_sql()でHerokuのpostgressのRDB環境に書き込むような処理を夢想or妄想想像!
・参考にした先人のブログ。
https://yasu-investor.com/dev_report1/
ここに適時開示情報のTSE-XBRLの操作について詳細が書かれているので、これを轍(わだち)にして作業すればよろしいかと。
・JPXの適時開示情報のXBRL化の仕様pdf群
https://www.jpx.co.jp/equities/listing/xbrl/03.html
...後できっちり読むべし。
・TSE-XBRLのファイル名の命名規則
http://tecaweb.net/archives/166
以下、抜粋
a)決算短信サマリのインスタンスファイル名:
tdnet-{報告書}[{報告書詳細区分}]-{証券コード}-{開示番号}.xbrl
b)決算短信財務諸表部分のインスタンスファイル名:
tdnet-{報告書}[{報告書詳細区分}]-{証券コード}-{期末日}-{提出回数}-{提出日}.xbrl
| 項目 | 設定値 | 説明 |
|---|---|---|
| {報告書} | [{期区分}{連結・非連結区分}]{報告区分} | 区分に該当する値がない場合は省略 |
| {期区分} | a | 通期(annual) |
| s | 特定事業会社第2四半期 | |
| q | 四半期(quarterly) | |
| {連結・非連結区分} | c | 連結(consolidated) |
| n | 非連結(non-consolidated) | |
| {報告区分} | edjp | 決算短信(日本基準) |
| edus | 決算短信(米国基準) | |
| edif | 決算短信(国際会計基準) | |
| rvff | 業績予想修正に関するお知らせ | |
| rvdf | 配当予想修正に関するお知らせ | |
| rvfc | 新・業績予想修正に関するお知らせ | |
| {報告詳細区分} | sm | 決算短信サマリ部分(USのみ、新版あり) |
| fr | 決算短信財務諸表部分 | |
| nt | 注記部分(※未使用) | |
| qi | 定性情報部分(※未使用) | |
| 提出回数 | {数字} | 2桁の数字(01~99) |
| 期末日 | YYYY-MM-DD | 報告期間の期末日 |
| 提出日 | YYYY-MM-DD | 報告期間の提出日 |
| 開示番号 | {数字} | 14桁の数字 |
※ 提出回数
最初の報告を「01」とし、同一年度、同一の報告書についてXBRLデータを再提出するごとに1ずつ増加。「02」以上のものは修正再提出されたものとみなす。
※ 特定事業会社第2四半期
特定事業会社とは、企業内容等の開示に関する内閣府令第17条の15第2項各号に掲げる事業を行う会社(銀行業、保険業、信用金庫)を指し、その会社の第2四半期を意味する。つまり普通の一般会社と銀行保険業などの特定事業会社の第2四半期と区別しており、一般事業会社の第2四半期は「q」だが、銀行や保険会社の第2四半期は「q」ではなく「s」で区分するとのこと...めっちゃややこしいことしよるわーorz
例)昨日の夜19時に適時開示情報にて発表された会社(証券コード:9440)
c)短信サマリーファイル↓
XBRLData/Summary/tse-acedjpsm-94440-20190614454551-ixbrl.htm
・4文字目:a 通期(annual)
・5文字目:c 連結(consolidated)
・6-9文字目:edjp (決算短信_日本基準)
・10-11文字目:sm 決算短信サマリ部分
・13-16文字目:9440 証券コード
d)決算短信財務諸表ファイル↓
XBRLData/Attachment/0103010-acss01-tse-acedjpfr-94440-2019-04-30-01-2019-06-14-ixbrl.htm
・acss01 :通期(annual)の連結(consolidated)のss(株主資本等変動計算書)
・edjp :決算短信_日本基準
・fr :決算短信財務諸表部分
・94440 :証券コード
・2019-04-30 :決算期末
・01 :提出回数
・2019-06-14 :提出日
※ おそらく「ac(通期annual-連結consolidated)」の次にある報告区分は、以下のような計算書類を指していると思われ...
| 項目 | 設定値 | 書類名 | 書類名(英語) | h2タグの有無(※推定) |
|---|---|---|---|---|
| {報告区分} | bs | 貸借対照表 | Balance sheet | あり |
| pl | 損益計算書 | Profit and loss statement | あり | |
| cf | キャッシュフロー計算書 | Cash flow statement | あり | |
| ci | 包括利益計算書 | Comprehensive income statement | なし | |
| ss | 株主資本等変動計算書 | Statements of shareholders' equity | あり |