こちらの記事を理解します
いきなり数式を理解しようとすると数学の知識がちゃんとしてなくて感電死する可能性があるので一度概念を理解しようと思います。
まずseq2seqを理解
入力を内部表現(特徴量)に変換するエンコーダ部分と内部表現から出力を得るデコーダで構成。
LSTMで文章を順序のある単語の固まり(Sequence)として学習して、順序のある単語の固まりを吐く。
実用例としては以下のようなものがあります。
翻訳: 英語 -> フランス語 のペアを学習。英語を入力するとフランス語に翻訳してくれる。
構文解析: 英語 -> 構文木 のペアを学習。英語を入力すると構文木を返してくれる。
会話bot: 問いかけ -> 返答 のペアを学習。「お腹減った」に対して「ご飯行こうぜ」などと返してくれる。
参考
今更ながらchainerでSeq2Seq(1)
seq2seq で長い文の学習をうまくやるための Attention Mechanism について
そもそもDeep Learningって何なの?っていう方へ
LSTMの理解が怪しい
ループ構造を持つリカレントニューラルネットワーク(RNN)を元に構成されるもの。
以前に入力された情報を保持する構造を持つ。例えば映画で前の内容を元に次の展開を予想するなどにイメージは近い。
しかしRNNはギャップの大きい(参照すべき情報が直前よりももっと前にある)場合、うまく学習できないことがあった。
LSTMは「Long Short Term Memory ネットワーク」で、ギャップの大きいケースにも対応できるように設計されたネットワーク。詳細は参考ページにあるが、すごくダイジェストするとRNNは単一の直線的な構造を持つ一方で、LSTMは情報に対して修正・削除することのできる層を持つ。
seq2seqの課題を理解
入力でかくなりすぎ問題
エンコーダ部分の情報が多くなる(≒文章が長くなる)ほど、デコーダ直前に詰め込む層への情報量が増えて計算時間が爆発、精度が落ちるという課題が。
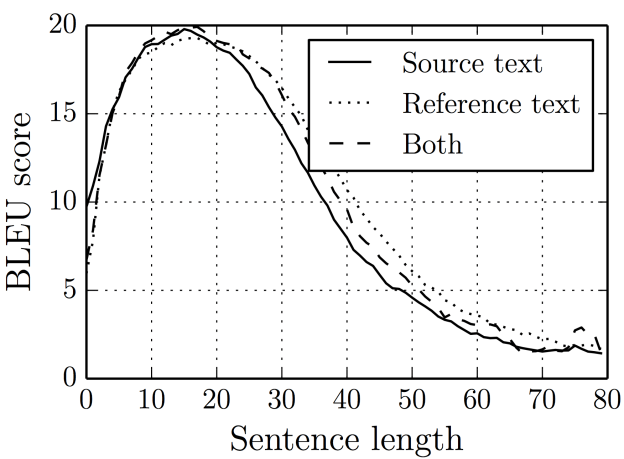
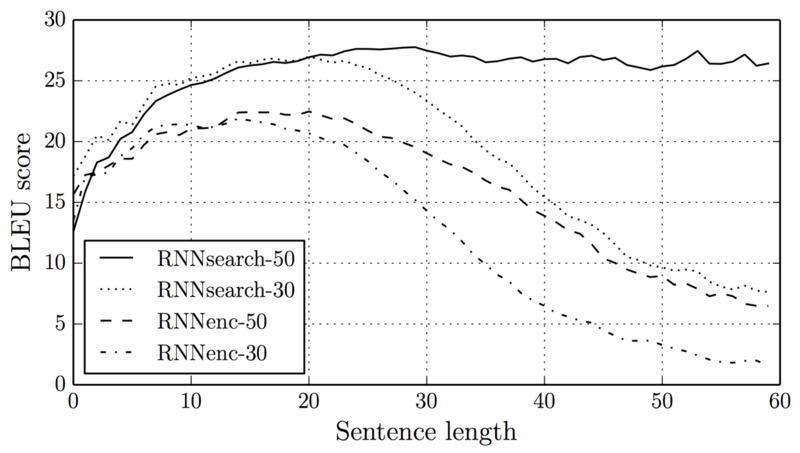
そこでAttentionメカニズムを使うと、「どの入力と出力が対応するか」を判定しながら学習を行うため長文にも対応できるようになったとのこと。
参考
seq2seq で長い文の学習をうまくやるための Attention Mechanism について
深層学習による自然言語処理 - RNN, LSTM, ニューラル機械翻訳の理論
Attentionメカニズムを理解
ある時刻の出力が、どの時刻の入力と最も関連がありそうかというパラメータ(隠れ状態)を持たせることで、最終的に得られるベクトルのサイズを小さくする...ので合ってるのかな。
参考
深層学習による自然言語処理 - RNN, LSTM, ニューラル機械翻訳の理論
出力が決まっていないとseq2seqうまくいかない問題
Pointer Networksを理解
翻訳のように「固定された語彙リストからの選択」ではなく、「入力系列のいずれかそのものを選択する」というニューラルネットワーク。
最近のDeep Learning (NLP) 界隈におけるAttention事情 - 51ページ
例としては「巡回セールスマン問題」が挙げられていました。
巡回セールスマン問題(じゅんかいセールスマンもんだい、英: traveling salesman problem、TSP)は、都市の集合と各2都市間の移動コスト(たとえば距離)が与えられたとき、全ての都市をちょうど一度ずつ巡り出発地に戻る巡回路の総移動コストが最小のものを求める(セールスマンが所定の複数の都市を1回だけ巡回する場合の最短経路を求める)組合せ最適化問題である。
これができて何が嬉しいのかというと、読解先にそもそも書いてましたが、
「入力される未知語そのものを出力に利用できる」という点なんですね。なるほど、めっちゃアハ。
(この問題をOOV Out Of Vocabularyと呼ぶそう)
参考
Pointer Networks - DeepLearningを勉強する人
Seq2Seq+Attentionのその先へ
Sequence-to-Sequence with Pointer(Copy)機構、Copy Netを理解
Copy Netは上述のPointer NetworksとSeq2seqを組み合わせたもの。
未知語を入力されてもそれをボキャブラリとして扱って、Seq2seqで処理するらしい。
Pointer Sentinel Mixture Modelsに関して、Copy Netとの差異は下記とのことで一旦スキップ。
CopyNetと違うところは、「Vocabから単語を生成する際にAttentionを使用していないこと」と「Vocabから出力するかPointerから出力するかをゲーティングで制御していること」。
Pointer-Generator Networkを理解
Pointer-Generator NetworkはGet To The Point: Summarization with Pointer-Generator Networksの論文で提案された生成型要約のモデルです。
各所の計算方法は違いますが、全体的な構造はCopyNetとPointer Sentinel Mixture Modelsのいいとこ取りといったところです。
Coverage MechanismはDecode時に同じ単語、あるいはフレーズを何度も生成してしまうのを防ぐことを目的とします。
どういいとこ取りしてるかというと「未知語に対して対応が可能で」「同じフレーズを繰り返してしまう課題をクリア」しているという感じですか。
なんで同じフレーズ繰り返すんだ?
 [会話モデルをSeq2seqで動かしてもちっとも対話できないので焦ってネタ元論文を翻訳してみる - 腹腹開発](https://fight-tsk.blogspot.com/2017/03/seq2seq.html)
怖すぎる
[会話モデルをSeq2seqで動かしてもちっとも対話できないので焦ってネタ元論文を翻訳してみる - 腹腹開発](https://fight-tsk.blogspot.com/2017/03/seq2seq.html)
怖すぎる
調べたがわからなかった。課題として認識されているのはわかったが。。高頻度の語が繰り返されるのでペナルティを課してみる...などはあったけど、課題が起きる原因自体は不明。
単語出現頻度予測機能付き RNN エンコーダデコーダモデル
その他
・UNKがUnkoだと思うのはNLPあるあるですか?