自然言語処理においてSequence-to-Sequenceモデル、そしてAttentionは大きな影響を与えてきました。
いまやSequence-to-Sequence + Attentionモデルは自然言語処理とディープラーニングを語る上では欠かせない存在となりつつあります。
近年の自然言語処理ではこのSequence-to-SequenceとAttentionをベースにしたモデルが多く提案されています。
この記事ではSequence-to-Sequenceをベースとしたモデルがどういった進化を遂げているかを歴史を追いながらまとめていこうと思います。
Sequence-to-Sequenceモデル (2014)
Sequence-to-SequenceモデルはSequence to Sequence Learning with Neural Networksの論文で提案され、「Seq2Seqモデル」「Encoder-Decoderモデル」「系列変換モデル」といった名前で呼ばれています。
特徴は系列を入力として系列を出力する機構です。文章を単語の系列として捉えれば、Sequence-to-Sequenceモデルを使うことで文章を入力として文章を出力するようなモデルを作れることになります。
例えば英独機械翻訳で使用されているSequence-to-Sequenceモデルは、英語の単語の系列を受け取りその翻訳に対応するドイツ語の単語の系列を出力しています。
Sequence-to-SequenceモデルはEncoderとDecoderの2つのRNNで構成されています。EncoderのRNNで入力系列をベクトルに圧縮し、そのベクトルをDecoderに渡し出力系列を生成します。
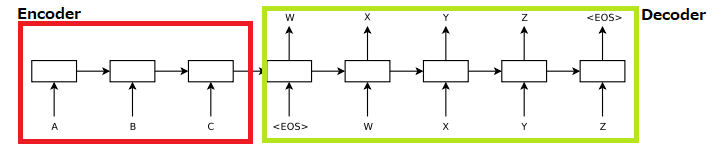
Sequence-to-SequenceモデルでDecoderがある時刻tで出力する単語は、時刻tのDecoderの隠れ層のベクトルを使って以下のように計算されます。
p(y_t | y_{<t},x) = softmax(W_o h_t + b_o)
Attentionメカニズム (2014?)
Sequence-to-Sequenceモデルでは入力系列の情報をEncoderで圧縮したベクトルとしてしかDecoderに伝えることができないため、入力系列が長いと入力系列の情報をDecoderにしっかりと伝えることが難しくなります。
そこでDecode時に入力系列の情報を直接参照できるようにする仕組みがAttentionメカニズムです。
Attentionの計算方法はいくつか種類があるのですが、今回はSoft Attentionと言われる手法のみ紹介します。
Effective Approaches to Attention-based Neural Machine Translation
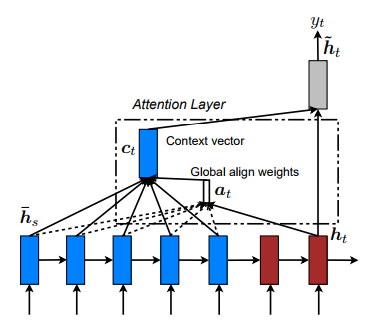
Attentionメカニズムでは時刻tにおけるDecoderの隠れ層のベクトル$h_t$とEncoderの各時刻の隠れ層のベクトル$\overline{h_s}$のスコアを計算し時刻tでどの入力単語に注視するかのスコア$\alpha_t$を決定します。このスコアをもとにEncoderの隠れ層のベクトルの加重平均$c_t$を求めそれをもとに時刻tの隠れ層のベクトル$\tilde{h_t}$を計算します。
\begin{align}
\alpha_t(s) = \frac{exp(score(h_t, \overline{h_s}))}{\sum_{s'} exp(score(h_t, \overline{h_{s'}}))}
\end{align}
c_t=\sum_{s}\alpha_t(s) \overline{h_{s}}
\tilde{h_t} = tanh(W_c[c_t;h_t])
式を見ると、時刻tのDecoderの隠れ層のベクトルと各入力に対するEncoderの隠れ層のベクトルのスコアを計算、Softmaxを取ることで時刻tの出力に影響を与える入力の情報の割合を計算し($\alpha_t(s)$)、その割合にもとづいて入力の隠れ層を足し合わせ($c_t$)、Decoderの隠れ層と結合して変換し時刻tのDecoderの最終的な隠れ層のベクトル($\tilde{h_t}$)を得ています。
$score()$という関数はEncoderとDecoderの隠れ層のベクトルの関連度を計算する関数で論文中では内積や結合といった3種類の計算方法が提案されています。
この$\tilde{h_t}$を使用して出力する単語$y_t$を計算します。
p(y_t | y_{<t},x) = softmax(W_o\tilde{h_t} + b_o)
Pointer Networks (2015)
Sequence-to-SequenceモデルではDecoderの出力したベクトルを行列変換しSoftmaxを取ることで出力の分布を得ます。
これは機械翻訳のように使用する語彙があらかじめ決まっており出力の分布の次元が固定の場合はよいのですが、入力に合わせて出力の分布の次元も可変となるような場合にはうまくいきません。
例えば巡回セールスマン問題を解く場合、都市を入力し回る都市の順番の系列を出力するように学習します。
この時ある時刻でDecoderが出力する都市の候補の数は入力となる問題の都市数に依存します。
この問題を解決するために提案されたのがPointer Networksです。
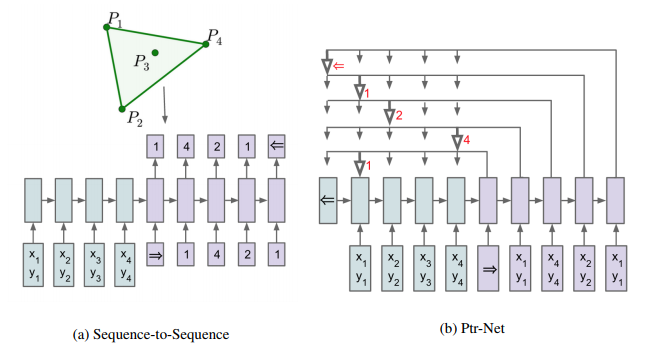
構造はとてもシンプルで、Encoderで入力系列を読み込み、DecoderではAttentionを使ってどの入力を選択するかを決定します。Attentionを使ってどの入力を選択するかの分布を求めることで分布の次元が可変という問題を解決しています。
Pointer Networksが出力する単語の計算は以下のようになります。 $X$は入力単語の集合です。
特徴はAttentionによって得られる入力単語の分布をそのまま出力単語の分布としていることです。
\begin{array}{r@{\;}ll}
u^t_j &= v^{T}tanh(W_1\overline{h_j} + W_2h_t) \\
p(y_t | y_{<t}, x) &= softmax(u^t) &(y_t \in X)
\end{array}
Sequence-to-Sequence with Pointer(Copy)機構 (2016)
Pointer Networksの良いところは、Decoderの出力の際に入力を選ぶことができるということです。
これが何故嬉しいかというと、Out-of-Vocabulary(OOV)を解決できる可能性があるからです。
OOVは自然言語処理に古くからある課題の1つで、学習データに出現しない単語(未知語)は予測時には使用することができないというものです。
そこでPointer Networksが行っていたような入力から出力を選ぶという機構を使えば、たとえ学習データの語彙に含まれていなくても入力からコピーしてくることでOOVの問題を緩和することができます。
このPointer Networksの機構と通常のSequence-to-Sequenceを組み合わせたモデルがいくつか提案されています。
ここでは「CopyNet」と「Pointer Sentinel Mixture Model」の2つを紹介します。
CopyNet(2016)
CopyNetはIncorporating Copying Mechanism in Sequence-to-Sequence Learningの論文で提案されたモデルで、特徴は今までのSequence-to-SequenceモデルとPointer Networkの機構を組み合わせたモデルであることです。
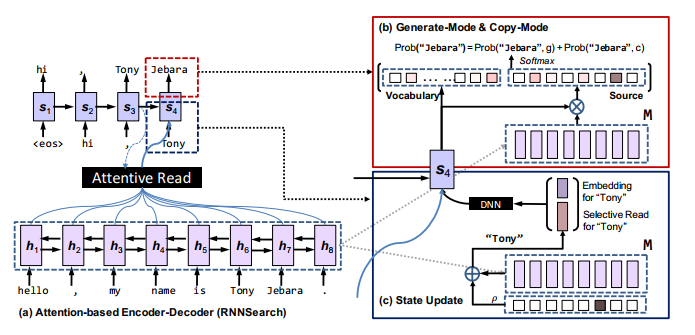
Decoderで単語を出力する時は、モデルが保持しているvocabularyの分布と入力から単語を選択する分布を合わせて単語の選ばれる確率を計算します。
これによりSequence-to-SequenceモデルのようにVocabularyから単語を選択する能力を持ちつつ、未知語を入力から選択する能力も併せ持つためOOVの問題が緩和されることになります。
モデルが出力する単語は以下のように計算されます。$c_t$はAttentionで得れるベクトル、$\bf{M}$ はEncoderの隠れ層のベクトルです。
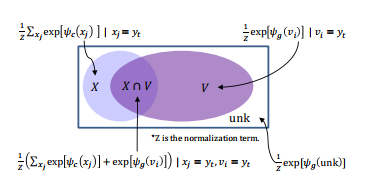
次の図はモデルが出力できる単語とその確率の計算式の対応表です。$V$がVocabularyの集合,$X$が入力単語の集合です。

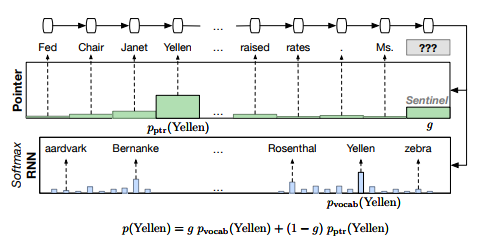
Pointer Sentinel Mixture Models(2016)
Pointer Sentinel Mixture ModelsはCopyNetと同じようにSequence-to-SequenceモデルとPointerの機構を組み合わせた構造をしています。
CopyNetと違うところは、「Vocabから単語を生成する際にAttentionを使用していないこと」と「Vocabから出力するかPointerから出力するかをゲーティングで制御していること」です。
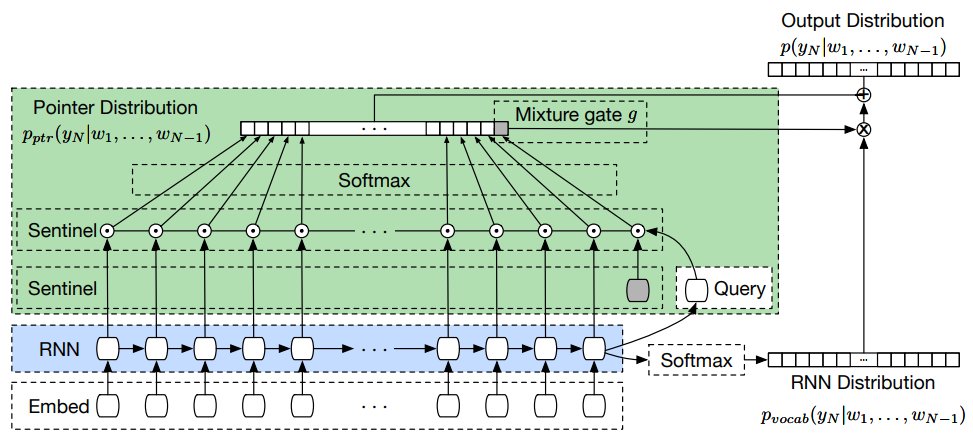
CopyNetやPointer Sentinel Mixture ModelsのようにVocabularyとPointer(Copy)機構を併せ持つモデルでは、VocabularyとPointerの切り替えが難しいという課題があります。
この切り替えの制御をRNNの隠れ層のやりとりだけで制御するには隠れ層のベクトルの表現力はあまりにも低いです。
そこでPointer Sentinel Mixture Modelsではsentinelベクトルを用意し、このベクトルと隠れ層のベクトルなどを使ってゲーティングを制御します。ゲーティングの仕事をRNNの外側に移すわけです。
モデルの出力する単語はVocabとPointerをゲーティングで制御した以下の式で計算されます。
p(y_t|y_{<t},x) = g * p_{vocab}(y_t|y_{<t},x) + (1 - g) * p_{pointer}(y_t|y_{<t},x)
Pointer-Generator Network (2017)
さてやっと2017年になりました。
Pointer-Generator NetworkはGet To The Point: Summarization with Pointer-Generator Networksの論文で提案された生成型要約のモデルです。
各所の計算方法は違いますが、全体的な構造はCopyNetとPointer Sentinel Mixture Modelsのいいとこ取りといったところです。
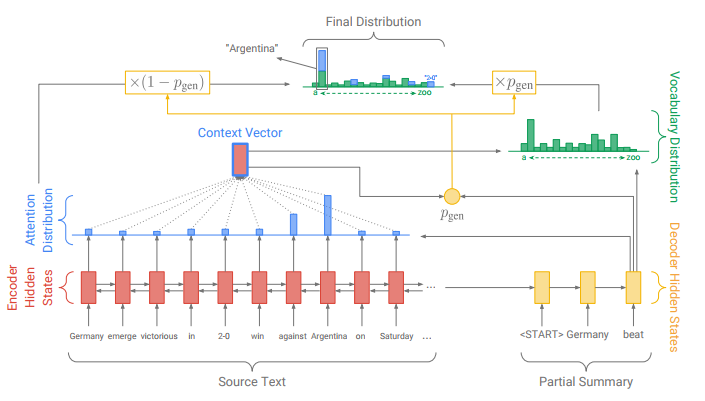
モデルの構造は先の2つのモデルと大きな差異はないのですが、Sequence-to-Sequenceモデルの課題である「Decode時にフレーズを繰り返してしまう問題」に対してCoverage Mechanismで対処しています。
Coverage MechanismはDecode時に同じ単語、あるいはフレーズを何度も生成してしまうのを防ぐことを目的とします。
過去のDecode時のAttentionの分布を利用してCoverage Vector $c_t$を求めます。
c_t = \sum_{t'=0}^{t-1}a^{t'}
この$c_t$には過去のDecode時にどの入力単語が注目されたかの情報が含まれています。すなわち既に注目された単語に対応する次元には高い値が入っているはずです。
この$c_t$を次のAttentionの分布を生成する際に利用することで、過去にどんな単語に注目したかという情報を渡した上で新しくAttentionの分布の計算を行うことが可能になります。$s_t$はDecoerの隠れ層のベクトル、$h_i$はEncoderの隠れ層のベクトルです。
\begin{align}
e^{t}_{i} &= v^{T}tanh(W_hh_i + W_ss_t + w_cc^{t}_{i} + b_{attn}) \\
a^t &= softmax(e^t)
\end{align}
また$c_t$を使った損失関数も定義することで学習の過程で明示的に単語の重複がないように最適化されることになります。
\begin{align}
covloss_t &= \sum_imin(a^t_i, c^t_i) \\
loss_t &= -log(y^*_t) + \lambda * covloss_t
\end{align}
最終的にモデルが出力する単語は以下で計算されます。式の形はPointer Sentinel Mixture Modelsと変わっていませんが、内部でいくつか工夫が施されているわけです。
\begin{array}{r@{\;}ll}
p(y_t|y_{<t}, x) &= p_{gen} * p_{vocab}(y_t|y_{<t}, x) + (1 - p_{gen}) * p_{pointer}(y_t|y_{<t}, x) & (p_{gen}はゲーティング)
\end{array}
最後にPointer-Generator Networkの生成する文章をちょっと見てみようと思います。
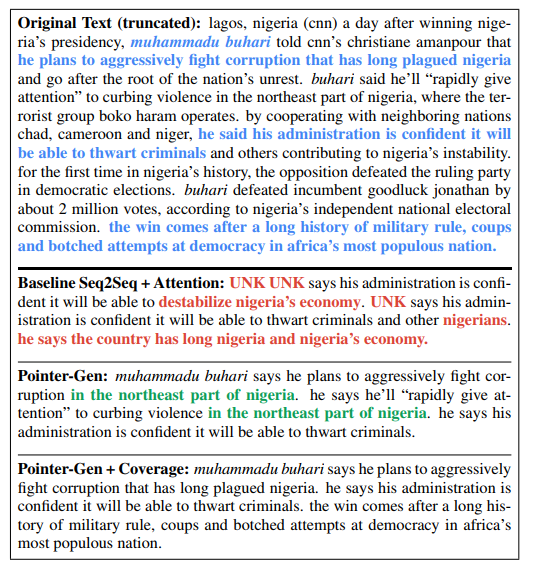
ベースラインのSequence-to-Sequence + Attentionモデルでは学習データに出現しない「muhanmmadu buhari」は、未知語としてUNK(Unknown)のトークンで処理されてしまっています。
Pointer機構を組み合わせたPointer-Gen(without Coverage Mechanism)では入力文からコピーしてくることで、この未知語をうまく処理できるようになっています。しかし、「in the northeast part of nigeria」というフレーズが生成される文章の中で重複してしまっています。
これにCoverage Mechanismを追加することでフレーズの重複を抑えて文章を生成することができるようになっていることが分かるかと思います。
終わりに
2014年のSequence-to-Sequenceモデルから始まり、Attentionや特にPointer機構を中心としたモデルの進化の歴史を紹介しました。
Sequence-to-Sequenceモデルの進化の形はもちろんこれだけではないですが、1つの形として紹介しました。
その他の進化の形といえば、「入力/出力の形式の改良(Seq2Tree,Tree2Seq,Graph2Seqなど)」や「Attentionの工夫(Attention重ね掛け,双方向Attentionなど)」などいろいろありますが、それはまた別の機会にでも書こうと思います。
Attentionメカニズムは紹介した論文より前から似た形で使用されたいたらしくAttentionの概念の原論文というわけではないのですが、Attentionの説明のために紹介しました。
またCoverage mechanismのように重複を防ぐ仕組みは、ニューラル機械翻訳の分野であったり要約分野でも異なる手法で実現され採用されています。
来年はこれらのモデルがどういった形で進化していくのか、あるいはまた別の形のモデルが台頭してくるのか今から楽しみです。
来年も楽しく自然言語処理ができるといいですね!
参考文献
Sequence to Sequence Learning with Neural Networks
最近のDeep Learning (NLP) 界隈におけるAttention事情
Effective Approaches to Attention-based Neural Machine Translation
Neural Machine Translation by Jointly Learning to Align and Translate
Describing Multimedia Content using Attention-based Encoder--Decoder Networks
Pointer Networks
Incorporating Copying Mechanism in Sequence-to-Sequence Learning
今更ながらchainerでSeq2Seq(3)〜CopyNet編〜
Pointer Sentinel Mixture Models
Stanford - Pointer Sentinel Mixture Models
Teaching neural networks to point to improve language modeling and translation
Get To The Point: Summarization with Pointer-Generator Networks
Diversity driven attention model for query-based abstractive summarization
深層学習による自然言語処理 (機械学習プロフェッショナルシリーズ)