seq2seqの第三弾、CopyNetの説明とその実装
はじめに
前回までのあらすじ
http://qiita.com/kenchin110100/items/b34f5106d5a211f4c004
http://qiita.com/kenchin110100/items/eb70d69d1d65fb451b67
ノーマルのseq2seq、Attention Modelときて、今回はCopyNetの実装しました。
まずCopyNetに関する説明をしてから、実装とその結果を述べます。
CopyNet
CopyNetとは
CopyNetの説明のために、まずSeq2Seqの復習から入ります。
| Sequence to Sequence |
|---|
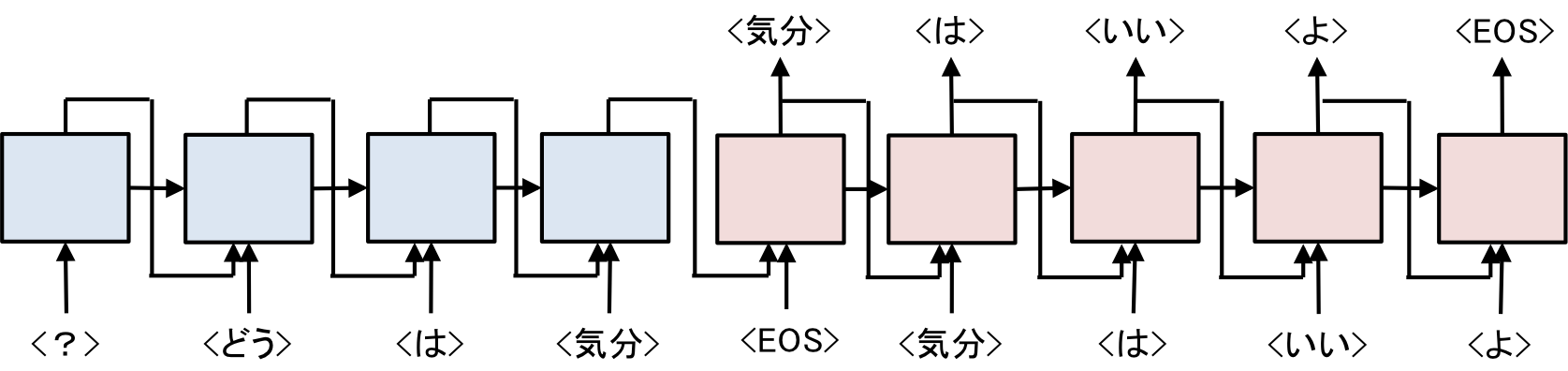 |
Seq2SeqはEncoderDecoderモデルの一種で、Encoderによって、発話文(「気分はどうですか?」)をベクトルに変換して、Decoderでそのベクトルから応答文(「気分はいいよ」)を出力するモデルでした。
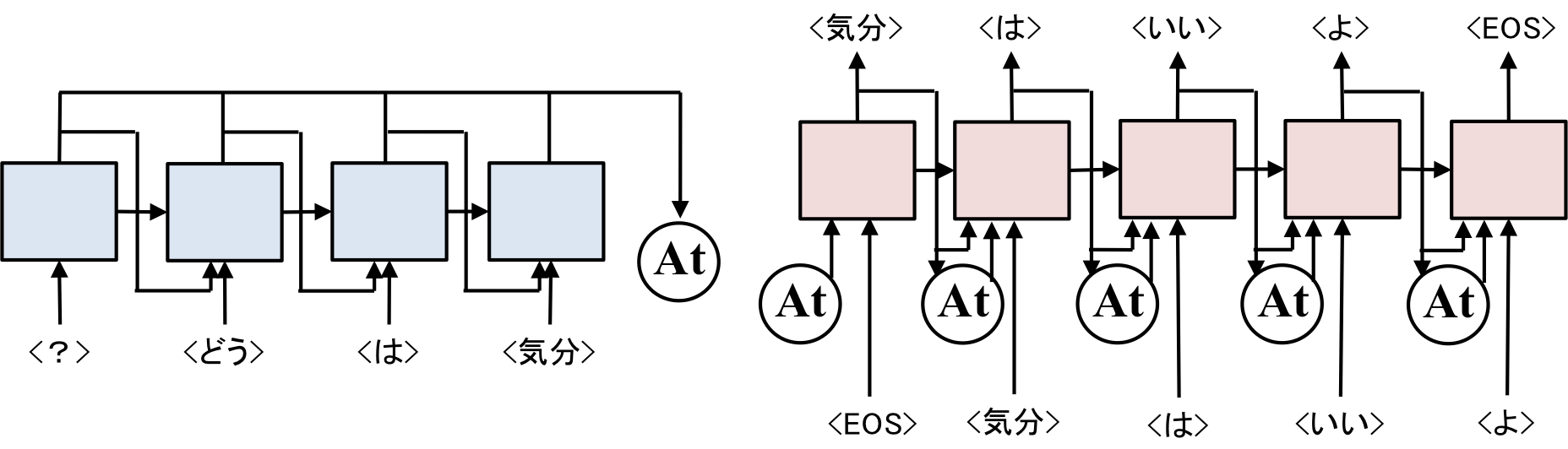
Seq2SeqのEncoderでは、最後に出力された中間ベクトルしか考慮しなかったですが、もっといろんな中間ベクトルを考慮しようというのがAttention Modelでした。
| Attention Model |
|---|
 |
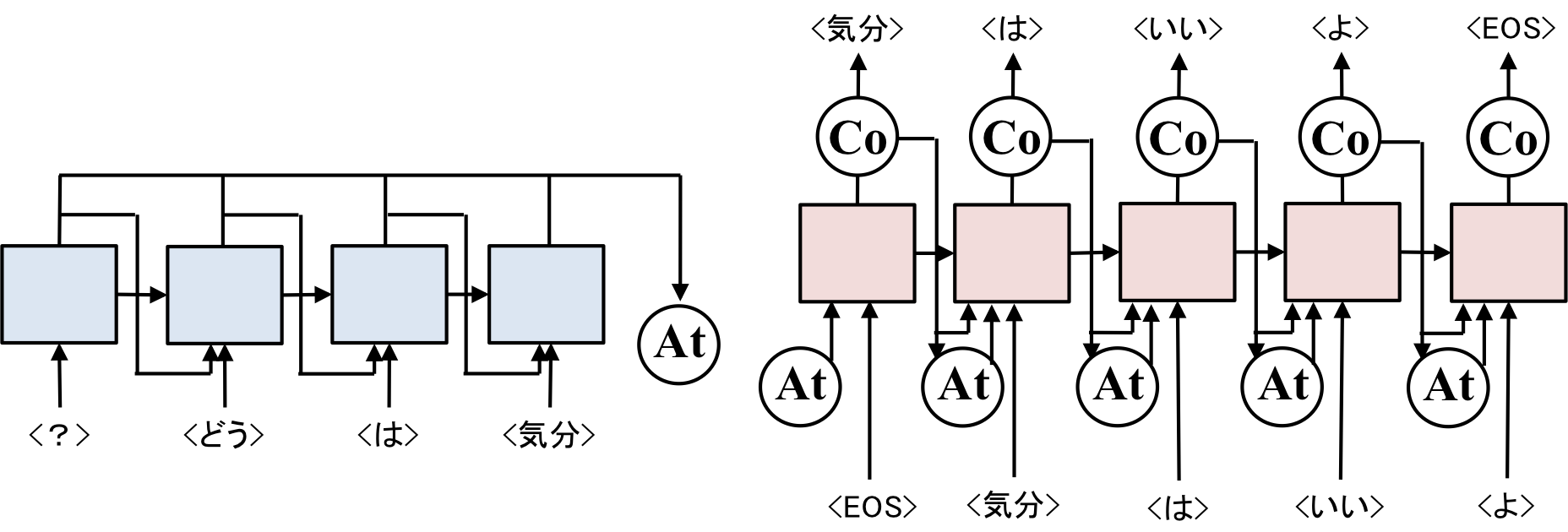
では、CopyNetでは何をするのか、発話が「気分はどうですか?」、応答が「気分はいいですよ」の場合を考えてください。
<気分>という単語は発話でも応答でもどちらでも使われています。
発話で使われている単語をDecoder側で生成しやすくしてあげようというのがCopyNetの考え方です。
| CopyNet |
|---|
 |
| (図はあくまでイメージです) |
CopyNetがなぜ良いのか、それは未知語に対応することができるからです。
例えば、学習の際に<気分>という単語がなくても、Copyすることで、<気分>という単語を用いて応答することができます。
以降では、CopyNetに関する論文を2つ紹介します。
Jiatao Gu et al.
これがCopyNetの元論文です
Gu, Jiatao, et al. "Incorporating copying mechanism in sequence-to-sequence learning." arXiv preprint arXiv:1603.06393 (2016).
| Gu, Jiatao, et al |
|---|
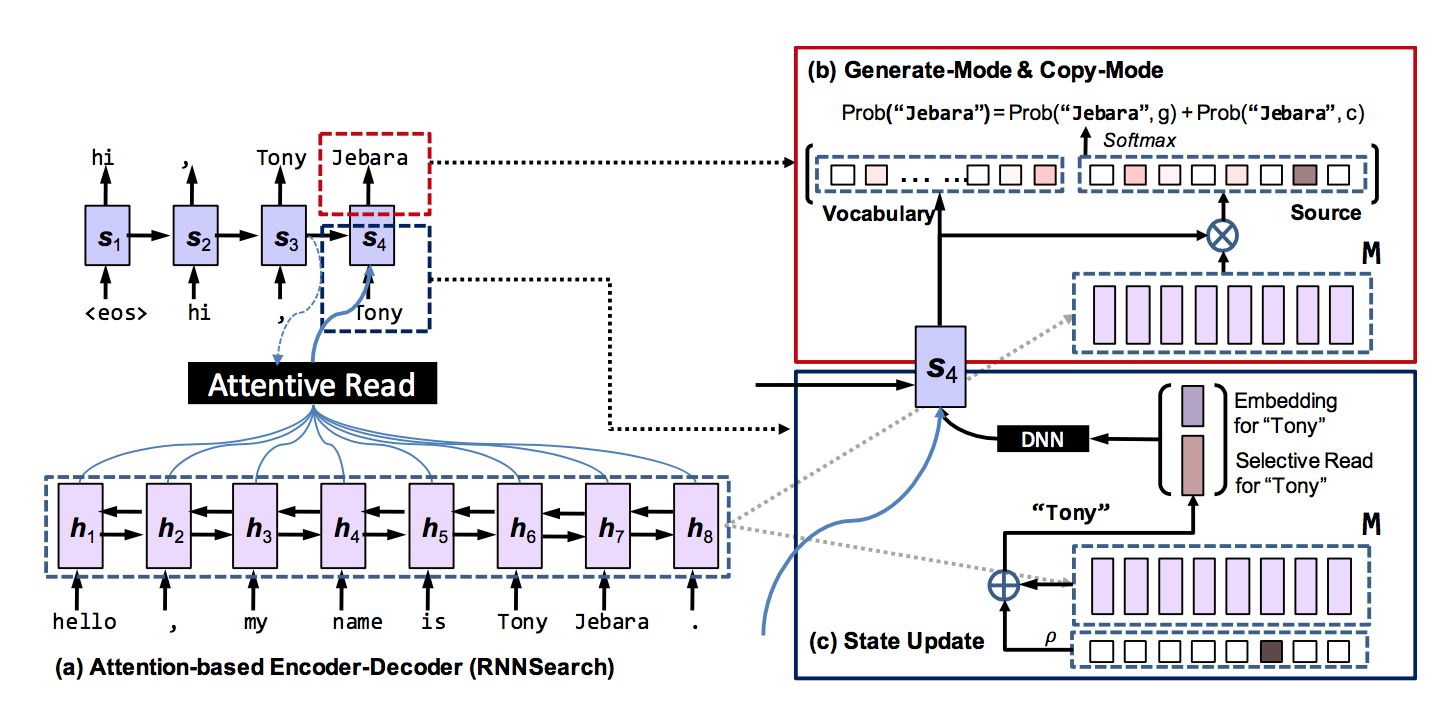 |
論文内で使用されている図は上のものになりますが、もう少しかいつまむと以下の図のようになります。
| Copy mode and StateUpdate |
|---|
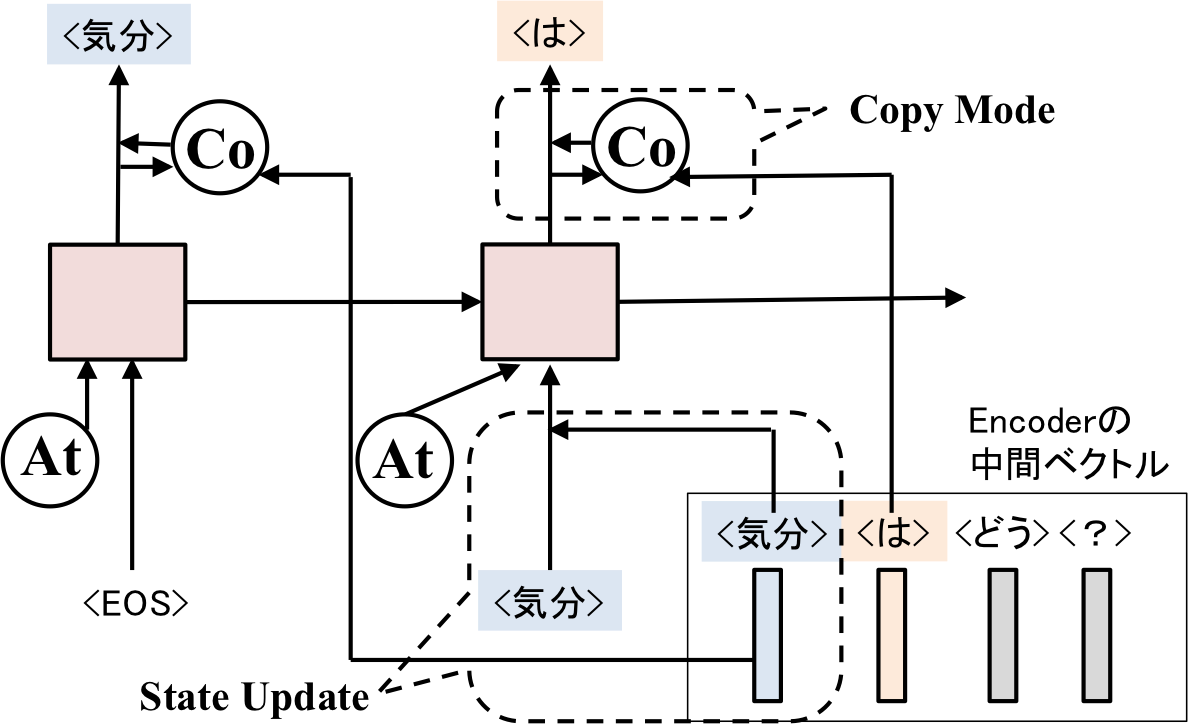 |
Guらの提案した手法では、StateUpdate、CopyModeという主に2つの仕組みがあります。
StateUpdateでは、Decoderに入力された単語が発話に含まれている単語(<気分>)なら、その単語の中間ベクトル(Encoderで出力されたもの)を入力するという処理を行います。
CopyModeでは、出力を期待する単語が、発話文に含まれるものなら(<は>)、その単語が出力されやすくなるように、中間ベクトルを使って<は>の出現確率を大きくします。
(説明がかなり下手くそですが、詳しくは論文を読んでください・・・)
Ziqiang Cao et al.
CopyNetがらみでもう一つ論文を紹介します。
厳密には、CopyNetではないですが、似たような仕組みを実装している論文に以下のものがあります。
| Ziqiang Cao et al. |
|---|
 |
| (論文内で使用されている図) |
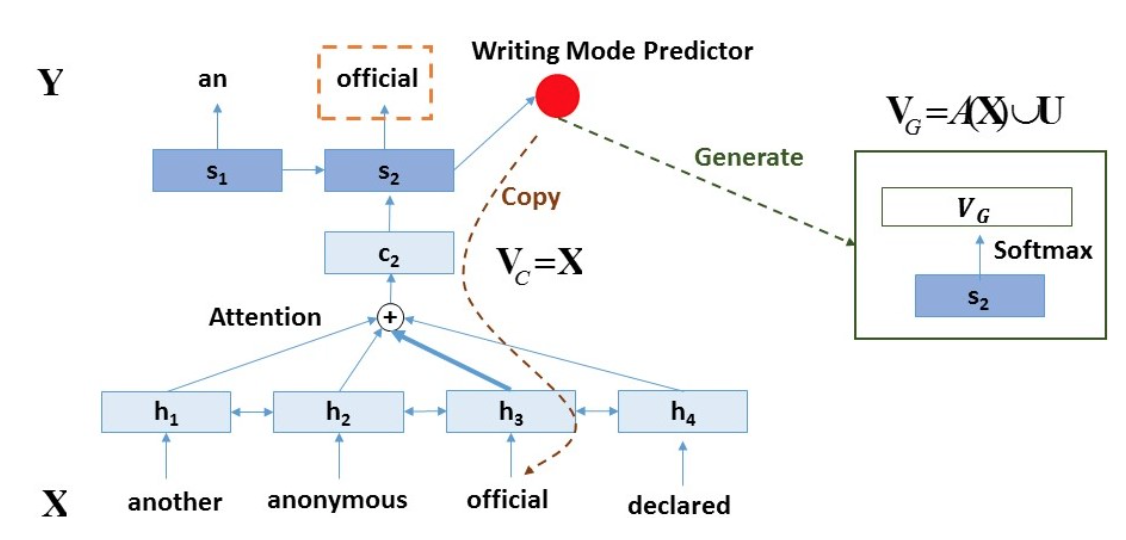
こっちの方はもう少しシンプルです、かいつまんで説明すると以下のような図になります。
| Restricted Generative Decoder |
|---|
 |
Attention Modelで計算された重みをそのまま使ってやろうという方針です。
もし、出力が期待されている単語が入力になければ、Generateされた単語の確率をそのまま使う。
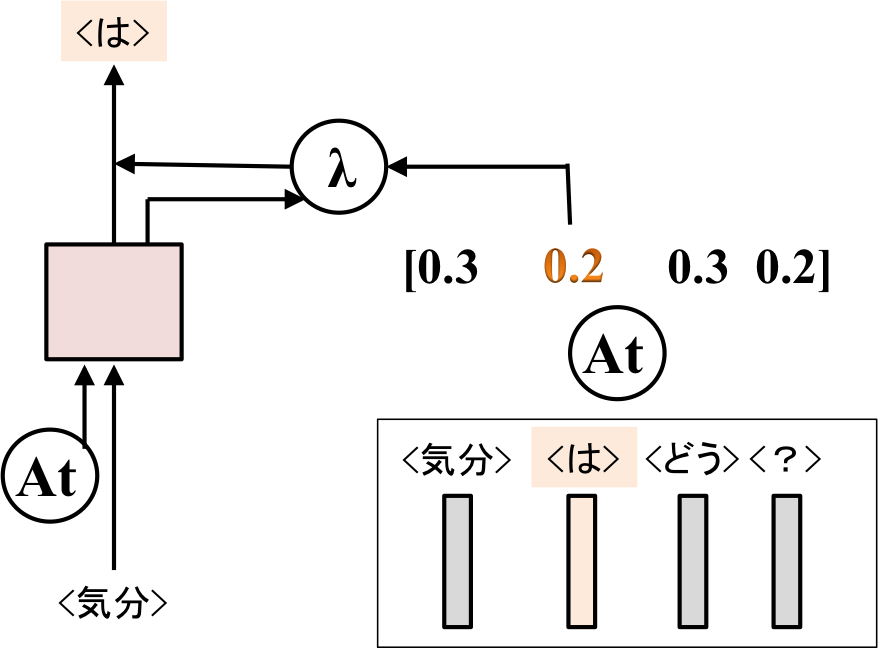
出力が期待されている単語が入力にもあれば(<は>)、Generateされた単語の確率とAttention Modelによって計算された重みをλで平均したものを用います(λは0~1の間のスカラ)。
このλのバランスをいかに取るかがポイントですが、λも学習していきます。
(詳しくは論文を読んでください・・・)
実装
今回は、Ziqiang Cao et al.の手法の実装をChainerで行いました。
CopyNetの実装はあまりネット上になく、間違っていたらすいません・・・
Encoder、DecoderはAttention Modelの時に使用したモデルをそのまま使います。
Attention
基本的にAttention Modelの時と同じですが、各中間ベクトルの重みも出力するように変更します。
class Copy_Attention(Attention):
def __call__(self, fs, bs, h):
"""
Attentionの計算
:param fs: 順向きのEncoderの中間ベクトルが記録されたリスト
:param bs: 逆向きのEncoderの中間ベクトルが記録されたリスト
:param h: Decoderで出力された中間ベクトル
:return att_f: 順向きのEncoderの中間ベクトルの加重平均
:return att_b: 逆向きのEncoderの中間ベクトルの加重平均
:return att: 各中間ベクトルの重み
"""
# ミニバッチのサイズを記憶
batch_size = h.data.shape[0]
# ウェイトを記録するためのリストの初期化
ws = []
att = []
# ウェイトの合計値を計算するための値を初期化
sum_w = Variable(self.ARR.zeros((batch_size, 1), dtype='float32'))
# Encoderの中間ベクトルとDecoderの中間ベクトルを使ってウェイトの計算
for f, b in zip(fs, bs):
# 順向きEncoderの中間ベクトル、逆向きEncoderの中間ベクトル、Decoderの中間ベクトルを使ってウェイトの計算
w = self.hw(functions.tanh(self.fh(f)+self.bh(b)+self.hh(h)))
att.append(w)
# softmax関数を使って正規化する
w = functions.exp(w)
# 計算したウェイトを記録
ws.append(w)
sum_w += w
# 出力する加重平均ベクトルの初期化
att_f = Variable(self.ARR.zeros((batch_size, self.hidden_size), dtype='float32'))
att_b = Variable(self.ARR.zeros((batch_size, self.hidden_size), dtype='float32'))
for i, (f, b, w) in enumerate(zip(fs, bs, ws)):
# ウェイトの和が1になるように正規化
w /= sum_w
# ウェイト * Encoderの中間ベクトルを出力するベクトルに足していく
att_f += functions.reshape(functions.batch_matmul(f, w), (batch_size, self.hidden_size))
att_b += functions.reshape(functions.batch_matmul(f, w), (batch_size, self.hidden_size))
att = functions.concat(att, axis=1)
return att_f, att_b, att
Seq2Seq with CopyNet
Encoder、Decorder、Attentionを組み合わせたモデルが以下のようになります。
class Copy_Seq2Seq(Chain):
def __init__(self, vocab_size, embed_size, hidden_size, batch_size, flag_gpu=True):
super(Copy_Seq2Seq, self).__init__(
# 順向きのEncoder
f_encoder = LSTM_Encoder(vocab_size, embed_size, hidden_size),
# 逆向きのEncoder
b_encoder = LSTM_Encoder(vocab_size, embed_size, hidden_size),
# Attention Model
attention=Copy_Attention(hidden_size, flag_gpu),
# Decoder
decoder=Att_LSTM_Decoder(vocab_size, embed_size, hidden_size),
# λの重みを計算するためのネットワーク
predictor=links.Linear(hidden_size, 1)
)
self.vocab_size = vocab_size
self.embed_size = embed_size
self.hidden_size = hidden_size
self.batch_size = batch_size
if flag_gpu:
self.ARR = cuda.cupy
else:
self.ARR = np
# 順向きのEncoderの中間ベクトル、逆向きのEncoderの中間ベクトルを保存するためのリストを初期化
self.fs = []
self.bs = []
def encode(self, words):
"""
Encoderの計算
:param words: 入力で使用する単語記録されたリスト
:return:
"""
# 内部メモリ、中間ベクトルの初期化
c = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
h = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
# 先ずは順向きのEncoderの計算
for w in words:
c, h = self.f_encoder(w, c, h)
# 計算された中間ベクトルを記録
self.fs.append(h)
# 内部メモリ、中間ベクトルの初期化
c = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
h = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
# 逆向きのEncoderの計算
for w in reversed(words):
c, h = self.b_encoder(w, c, h)
# 計算された中間ベクトルを記録
self.bs.insert(0, h)
# 内部メモリ、中間ベクトルの初期化
self.c = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
self.h = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
def decode(self, w):
"""
Decoderの計算
:param w: Decoderで入力する単語
:return t: 予測単語
:return att: 各単語のAttentionの重み
:return lambda_: Copy重視かGenerate重視かを判定するための重み
"""
# Attention Modelで入力ベクトルを計算
att_f, att_b, att = self.attention(self.fs, self.bs, self.h)
# Decoderにベクトルを入力
t, self.c, self.h = self.decoder(w, self.c, self.h, att_f, att_b)
# 計算された中間ベクトルを用いてλの計算
lambda_ = self.predictor(self.h)
return t, att, lambda_
実はこれもAttention Modelの時とあまり変わっていません。
変更点は、Copy ModeとGenerative Modeのバランスを取るためのλを計算する、Attentionの重みも出力するという点です。
forward
大きな変更点はforward関数の中にあります。
forward関数では、入力された文と出力したい単語を見て、Copy Modeを計算するかしないかを判断しています。
def forward(enc_words, dec_words, model, ARR):
"""
forwardの計算をする関数
:param enc_words: 入力文
:param dec_words: 出力文
:param model: モデル
:param ARR: numpyかcuda.cupyのどちらか
:return loss: 損失
"""
# バッチサイズを記録
batch_size = len(enc_words[0])
# モデルの中に記録されている勾配のリセット
model.reset()
# 入力文の中で使用されている単語をチェックするためのリストを用意
enc_key = enc_words.T
# Encoderに入力する文をVariable型に変更する
enc_words = [Variable(ARR.array(row, dtype='int32')) for row in enc_words]
# Encoderの計算
model.encode(enc_words)
# 損失の初期化
loss = Variable(ARR.zeros((), dtype='float32'))
# <eos>をデコーダーに読み込ませる
t = Variable(ARR.array([0 for _ in range(batch_size)], dtype='int32'))
# デコーダーの計算
for w in dec_words:
# 1単語ずつをデコードする
y, att, lambda_ = model.decode(t)
# 正解単語をVariable型に変換
t = Variable(ARR.array(w, dtype='int32'))
# Generative Modeにより計算された単語のlog_softmaxをとる
s = functions.log_softmax(y)
# Attentionの重みのlog_softmaxをとる
att_s = functions.log_softmax(att)
# lambdaをsigmoid関数にかけることで、0~1の値に変更する
lambda_s = functions.reshape(functions.sigmoid(lambda_), (batch_size,))
# Generative Modeの損失の初期化
Pg = Variable(ARR.zeros((), dtype='float32'))
# Copy Modeの損失の初期化
Pc = Variable(ARR.zeros((), dtype='float32'))
# lambdaのバランスを学習するための損失の初期化
epsilon = Variable(ARR.zeros((), dtype='float32'))
# ここからバッチ内の一単語ずつの損失を計算する、for文を回してしまっているところがダサい・・・
counter = 0
for i, words in enumerate(w):
# -1は学習しない単語につけているラベル。これは無視する。
if words != -1:
# Generative Modeの損失の計算
Pg += functions.get_item(functions.get_item(s, i), words) * functions.reshape((1.0 - functions.get_item(lambda_s, i)), ())
counter += 1
# もし入力文の中に出力したい単語が存在すれば
if words in enc_key[i]:
# Copy Modeの計算をする
Pc += functions.get_item(functions.get_item(att_s, i), list(enc_key[i]).index(words)) * functions.reshape(functions.get_item(lambda_s, i), ())
# ラムダがCopy Modeよりになるように学習
epsilon += functions.log(functions.get_item(lambda_s, i))
# 入力文の中に出力したい単語がなければ
else:
# ラムダがGenerative Modeよりになるように学習
epsilon += functions.log(1.0 - functions.get_item(lambda_s, i))
# それぞれの損失をバッチサイズで割って、合計する
Pg *= (-1.0 / np.max([1, counter]))
Pc *= (-1.0 / np.max([1, counter]))
epsilon *= (-1.0 / np.max([1, counter]))
loss += Pg + Pc + epsilon
return loss
コード内では、Generative Mode、Copy Mode、λのそれぞれの学習をするために、Pg、Pc、epsilonという3つの損失を定義してそれぞれ計算しています。
functions.log_softmaxを使っていることがポイントです。log(softmax(x))としてしまうと、softmaxの計算が0になってしまった時にエラーが起きますが、この関数によってうまくやってくれています(どういう風にうまくやっているかは謎・・・)。
functions.softmax_cross_entropy関数を使えば、こんなめんどくさい計算はいらないのですが、今回はλでCopy Modeの損失とGenerative Modeの損失のバランスを取りたいので、functions.get_items、functions.log_softmax関数を使って、損失を計算しています。
もう少しうまい実装を知っている方は是非教えてください・・・
作成したコードは、
https://github.com/kenchin110100/machine_learning/blob/master/sampleCopySeq2Seq.py
にあります。
実験
コーパス
今までと同じように対話破綻コーパスを使用しました。
https://sites.google.com/site/dialoguebreakdowndetection/chat-dialogue-corpus
実験結果
発話内容は以下の4種
- token1 = 'おはよう'
- token2 = '調子はどうですか?'
- token3 = 'お腹が空きました'
- token4 = '今日は暑いです'
Epochごとに応答結果を見ていきます。
Epoch 1
発話: おはよう => 応答: ['おはよう', '</s>'] ['copy', 'copy']
発話: 調子はどうですか? => 応答: ['調子', 'は', 'は', 'です', 'です', '</s>'] ['copy', 'copy', 'copy', 'copy', 'copy', 'copy']
発話: お腹が空きました => 応答: ['お腹', 'が', 'が', 'が', 'た', 'た', 'です', '</s>'] ['copy', 'copy', 'copy', 'copy', 'copy', 'copy', 'gen', 'copy']
発話: 今日は暑いです => 応答: ['今日', 'は', 'は', 'です', 'です', '</s>'] ['copy', 'copy', 'copy', 'copy', 'copy', 'copy']
完全に壊れてますね・・・
Epoch 3
発話: おはよう => 応答: ['おはよう', '</s>'] ['copy', 'copy']
発話: 調子はどうですか? => 応答: ['調子', 'は', '</s>'] ['copy', 'gen', 'copy']
発話: お腹が空きました => 応答: ['お腹', '</s>'] ['copy', 'copy']
発話: 今日は暑いです => 応答: ['暑い', 'は', '好き', 'です', 'ね', '</s>'] ['copy', 'copy', 'gen', 'gen', 'gen', 'copy']
Epoch 5
発話: おはよう => 応答: ['おはよう', '</s>'] ['copy', 'copy']
発話: 調子はどうですか? => 応答: ['調子', 'は', '好き', 'です', 'か', '</s>'] ['copy', 'copy', 'gen', 'copy', 'gen', 'copy']
発話: お腹が空きました => 応答: ['お腹', '</s>'] ['copy', 'copy']
発話: 今日は暑いです => 応答: ['暑い', 'です', '</s>'] ['copy', 'gen', 'copy']
お腹と宣言されましても・・・
Epoch 7
発話: おはよう => 応答: ['おはよう', 'ござい', 'ます', '</s>'] ['copy', 'gen', 'gen', 'copy']
発話: 調子はどうですか? => 応答: ['調子', 'は', '</s>'] ['copy', 'gen', 'copy']
発話: お腹が空きました => 応答: ['お腹', 'が', '空き', 'まし', 'た', '</s>'] ['copy', 'gen', 'copy', 'copy', 'gen', 'gen']
発話: 今日は暑いです => 応答: ['暑い', 'です', '</s>'] ['copy', 'gen', 'copy']
学習には<調子>という単語は含まれていないので、その点うまくコピーできているとはいえます。
ただ、正直もう少しうまく回答してほしい点もあります。
Copy ModeとGenerate Modeの両方を学習するので、Decoderが言語モデルを学習しきれていないように思えます。
論文内では対話タスクではなく、要約タスクで評価していたのもこの辺が関係しているのかもしれません。
(まあ、一番の原因は実装にあるかもしれませんが・・・)
結論
chainerを使ってCopyNetの実装を行いました。
対話モデルを3回やってきたので、もうお腹いっぱいかな笑
次はまた別のことを何かしらやります。