概要
個人的な備忘録を兼ねたPyTorchの基本的な解説とまとめです。テキスト分類問題の3回目となります。2020年代、文章といえばTransformer。ということでTransformer Encoderを利用したテキスト分類、いわゆるBERT風のネットワークでテキスト分類の演習してみたいと思います。利用するデータは第21回【文章分類・Conv1d】で使用した「架空のwebサービス利用に関するテキストデータ」となります。ネットワーク構造を真似るだけなので事前学習などはありません。
参考
BERT風ということなので定番のこの論文を参考にしています。
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova (2018) "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
方針
- できるだけ同じコード進行
- できるだけ簡潔(細かい内容は割愛)
- 特徴量などの部分,あえて数値で記入(どのように変わるかがわかりやすい)
演習用のファイル
1. テキスト分類とTransformer
分類問題とは、データを適切なカテゴリー(クラス)に振り分ける問題です。テキスト分類では、次のような応用例が考えられます。
- 商品レビュー:「好意的/中立的/否定的」の判定
- アンケートの自由回答:意見の自動分類
- メール:「スパム/通常メール」の判別
テキストデータをニューラルネットワークで扱うには、第19回で見たように次のような手順を踏むことが大半でした。
-
トークナイズ(IDベクトル化)
文章を単語やサブワード単位に分割し、各要素をIDに変換- 例:"アカウント/を/作り/たい" → [46,45,77,16]
-
埋め込み(Embedding)
IDを意味を持つベクトル(分散表現)に変換- 各単語をベクトル(分散表現ベクトル)で表現する
-
文章の行列化:
分散表現ベクトルを利用して文章を行列で表現- 文章を行列(分散表現行列)で表現する
- ベクトル表現された単語を文の単語順に並べることで「単語数 × 分散表現ベクトル」の行列が構成される
分散表現行列同士の掛け算をすることで単語同士の関連度を求めたいという発想が注意機構と呼ばれるものになります。今回演習するTransformerは、この注意機構を中心に構築されたネットワークモデルです。文章全体の文脈を効率的に捉えることができるため、高精度な分類が可能とされています。
Transformerを用いたテキスト分類の実装を通じて仕組みを実際に体験できればと思っています1。できれば、「さすがTransformer様!」となるのか![]()
PyTorchによるプログラムの流れを確認します。基本的に下記の5つの流れとなります。Juypyter Labなどで実際に入力しながら進めるのがオススメ
- データの読み込みとtorchテンソルへの変換 (2.1)
- ネットワークモデルの定義と作成 (2.2)
- 誤差関数と誤差最小化の手法の選択 (2.3)
- 変数更新のループ (2.4)
- 検証 (2.5)
2. コードと解説
2.0 データについて
利用するデータについて簡単に紹介します。ある架空のwebサービスを利用する場面を想定しています。利用サービスに関するテキスト分類で、「ログインに関する内容」、「登録に関する内容」、「解約に関する内容」の3種類のカテゴリーで分類するものとなります。文の長さが短い上、<bos>でも代用できる思われるので、句点は省略しました。具体的には、次のような形になります。
| 文章 | 分類名 |
|---|---|
| ログインできない | ログイン |
| 入会したい | 登録 |
| 退会したい | 解約 |
MeCabなどで形態素解析を行い、単語IDの辞書を作成します。4種類のタグを準備しました。<unk>は辞書にない単語、<bos>は文の開始記号、<eos> は文の終端記号、<pad>は文の長さを調整する記号をそれぞれ表しています。
<unk> : 0
<bos> : 1
<eos> : 2
<pad> : 3
ID:4
︙
ログイン:67
︙
辞書を利用して、文章をIDベクトルで表現します。データの形を固定するために、<pad>を用いて文を同じ長さを等しくします。
等長化した文のIDベクトルは次のようになります。分類IDは分類名を番号で記したものです。
| 文章 | IDベクトル | 分類名 | 分類ID |
|---|---|---|---|
| ログインできない | 1,67,67,19,24,2,3,3,3,3,3,3 | ログイン | 1 |
| 入会したい | 1,86,11,16,2,3,3,3,3,3,3 | 登録 | 2 |
| 退会したい | 1,141,11,16,2,3,3,3,3,3,3 | 解約 | 0 |
等長化されたIDベクトルが入力データ、分類IDが教師データとなります。
2.1 データの読み込みとtorchテンソルへの変換
まず利用するライブラリを読み込みます。2.1は前回と全く同じ。
import numpy as np
import torch
import torch.nn as nn
from sklearn.model_selection import train_test_split
データの読み込み
numpyのloadtxtを利用してcsvファイルを読み込みます。$x$ がIDベクトルになった文、$t$ が分類IDで0,1,2という整数値の教師データです。train_test_splitを利用して、学習に利用するデータとテスト(検証)に利用するデータに分割します。
# (1) デバイスの選択
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("利用デバイス:", device.type)
# (2) データの読み込み
# x: IDベクトル(文)
# t: ラベル(0, 1, 2)
# torchテンソルに変換
x = np.loadtxt("data_90/x_id_vector.csv", delimiter=",")
t = np.loadtxt("data_90/y_labels.csv", delimiter=",")
x = torch.LongTensor(x)
t = torch.LongTensor(t)
# (3) 学習用データと検証用データに分割
x, x_test, t, t_test = train_test_split(x,t, stratify=t, random_state=55)
# (4) GPU使える場合はGPUへ
x = x.to(device)
t = t.to(device)
x_test = x_test.to(device)
t_test = t_test.to(device)
# x.shape: torch.Size([67, 11])
# x_test.shape: torch.Size([23, 11])
説明メモ
- (1) 利用するデバイスの設定。GPUあるときは使うぞ。
- (2) np.loadtxt(ファイル名,句切り記号)を利用してCSVファイルを読み込みます。
- 入力データも教師データも整数なので、torch.LongTensor()を使います。
- (3) train_test_splitのオプション stragify=t を指定すると、学習用データと検証用データで分類IDの比率を元のデータと同じに保つように分割できます。tと同じような割合で分割という意味です。
2.2 ネットワークモデルの定義と作成
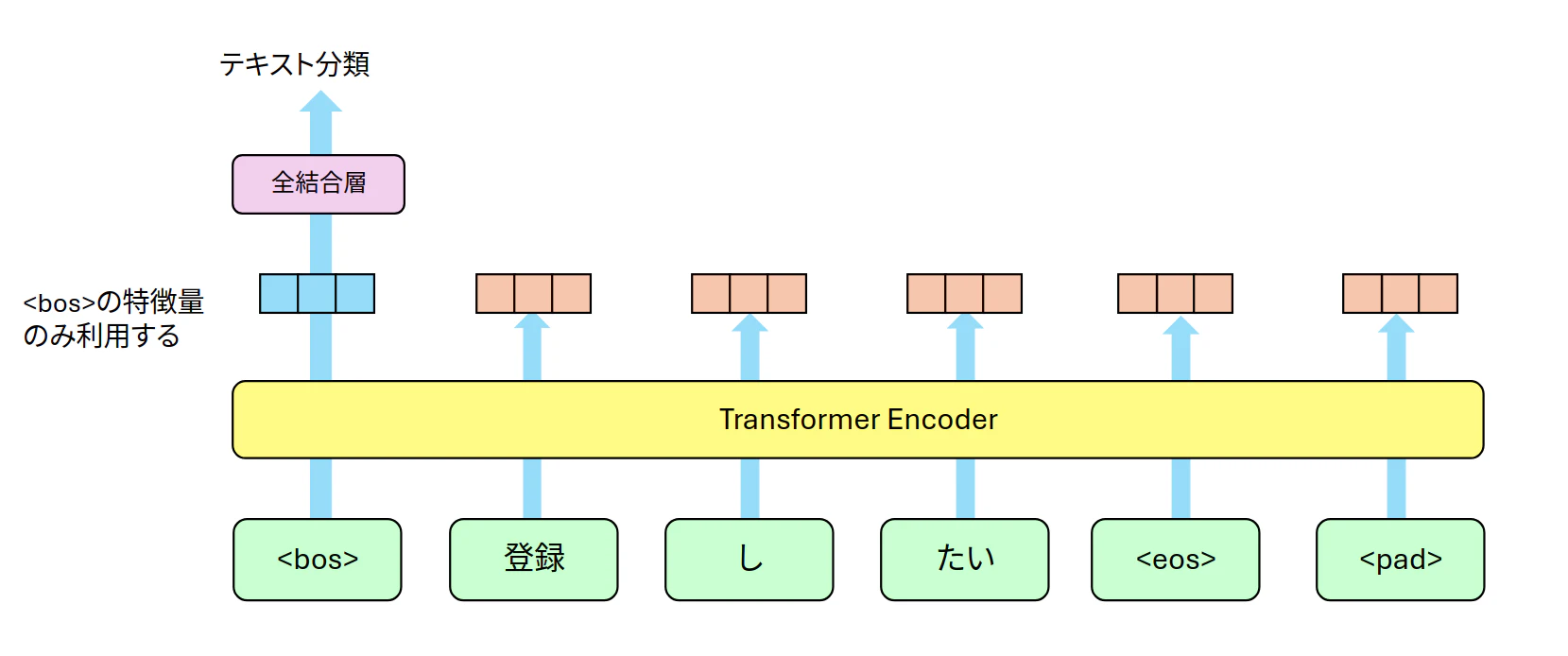
今回は図1のように埋め込み層などから抽出された特徴量をTransformer Encoder層で関連度を考慮した特徴量に変換、<bos>行のみを利用して全結合層による3種類のクラス予測をする形をとります。学習の過程で<bos>にテキストの分類に関する特徴が集まってくる予定です。
図1:概要
Transformer Encoderの部分を大雑把に覗いて見てみます。Transformer Encoder層は、基本的に分散表現行列の$Q, K, V$を使い $\text{softmax}(QK^T)V$ と計算するだけです。分散表現行列の内積を計算している $\text{softmax}(QK^T)$ で単語間の関連度を確率で表現できるようになっています。細かい説明は注のサイト1や書籍を参考にしてください。
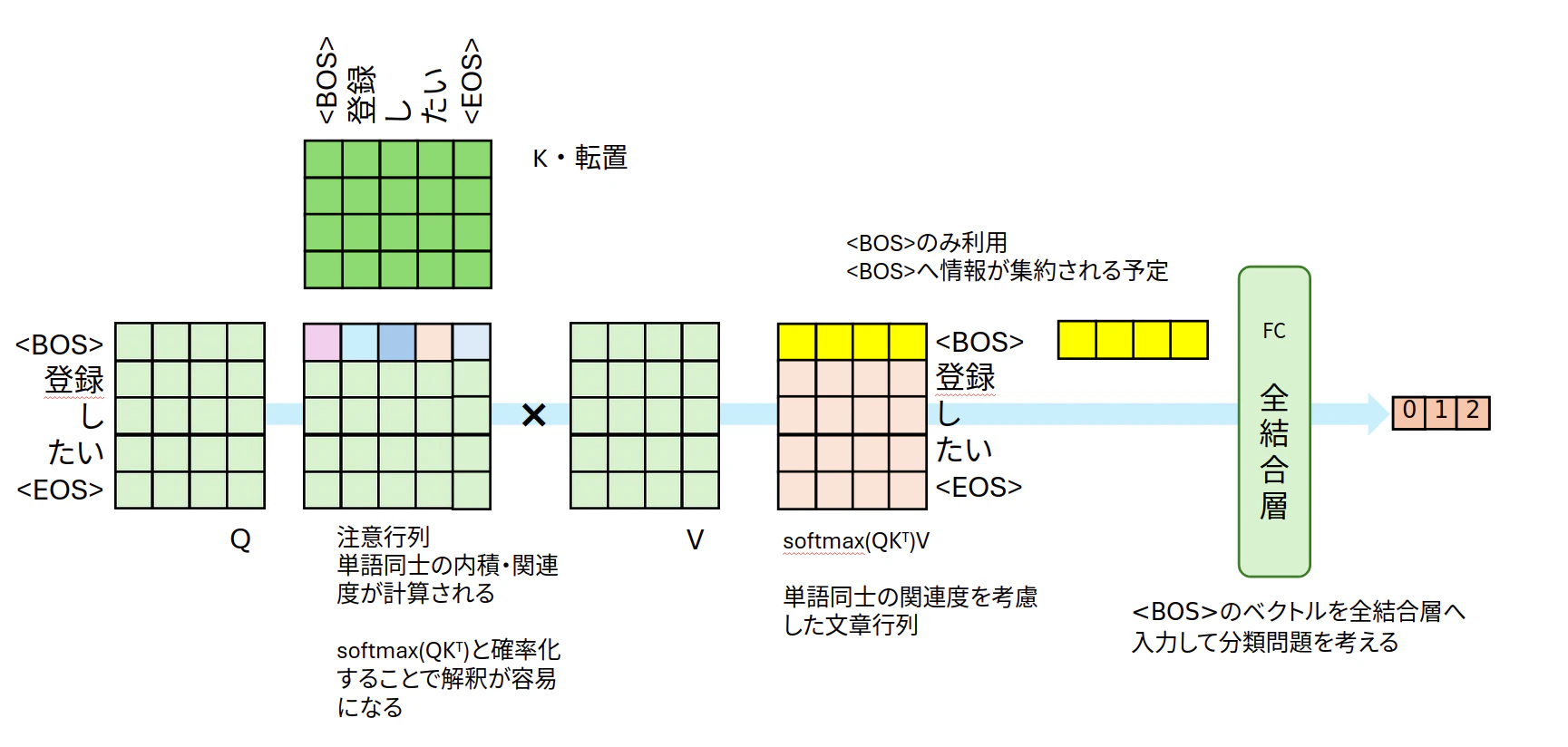
図2:Transformer Encoder層から分類までの概要
ネットワークの書き方はこれまで同様にクラスを利用して記述します。
(1) __init__() : 利用するネットワーク名・活性化関数をすべて記述
(2) forward() : 実際の流れを記す
ネットワーク構造の概要は
(x:単語IDベクトル)→【埋め込み層】→【Transformer】→【全結合層】→(y:3種類)
という3ブロックから構成されます。複雑なTransformerの内部構造もPyTorchのTransformerEncoderLayerを使えば数行で表現できます![]()
# 初期設定
WORDS = 146 # 単語数
SEQ_LEN = 11 # x.shape[1]、入力するIDベクトルの長さ
D_MODEL = 16 # 分散表現ベクトルの次元
CLASSES = 3 # 分類数
class DNN(nn.Module):
def __init__(self, pad_token_id: int=3): # ここでpadding token idを指定。デフォルトは0になっている
super().__init__()
self.pad_token_id = pad_token_id
# (1) トークン埋め込み <pad>を0に設定
self.token_embedding = nn.Embedding(num_embeddings=WORDS, embedding_dim=D_MODEL, padding_idx=self.pad_token_id)
# (2) 学習可能な位置埋め込み(0〜max_len-1)
self.pos_embedding = nn.Embedding(num_embeddings=SEQ_LEN, embedding_dim=D_MODEL)
# (3) Transformer Encoder
encoder_layer = nn.TransformerEncoderLayer(
d_model=D_MODEL, # 分散表現ベクトルの次元
nhead=4, # multi head attentionのheadの数
dim_feedforward=32, # 中間層の次元数(d_modelの4倍程度が多いみたい)
dropout=0.1,
batch_first=True, # (batch, seq_len, d_model) で扱えるように
)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer,num_layers=6)
# (4) 文ベクトル → クラス数
self.fc = nn.Linear(in_features=D_MODEL, out_features=3)
def forward(self, x):
# (5) TransformerEncoderの<pad>用マスク
# pad ID=3でpadのところが True になるように mask を作成する
src_key_padding_mask = (x == self.pad_token_id)
# ---- 埋め込み ----
# トークン埋め込み
tok_emb = self.token_embedding(x) # (batch, seq_len=11, d_model=16)
# 位置埋め込み
# ハードコードされている「11」は何を表しているの?
# 文の長さが11。0〜10までの数値で単語の位置をあらわしています。
pos_emb = self.pos_embedding(torch.arange(11, device=x.device)) # (seq_len=11, d_model=16)
# (6) 分散表現行列=トークン埋め込み + 位置埋め込み
x = tok_emb + pos_emb.unsqueeze(0) # (batch, seq_len=11, d_model=16)
# (7) Transformer Encoder
h = self.transformer_encoder(x, src_key_padding_mask=src_key_padding_mask)
# (8) <BOS>トークン(先頭)に情報を集約
pooled = h[:, 0, :] # [batch, d_model]
y = self.fc(pooled) # [batch, num_labels=3]
return y
model = DNN()
model.to(device)
説明メモ1 (__init__の部分)
- (1) トークンの埋め込み:単語を分散表現ベクトルへ変換します。
- (2) 位置の埋め込み:単語の出現位置の番号を分散表現ベクトルへ変換します2。
- トークンの埋め込みベクトルと位置の埋め込みベクトルを足し算して、位置情報を考慮した単語の分散表現とします。
- (3) PyTorchのTransformerEncoderLayerとTransformerEncoderを利用してエンコーダー用のTransformerネットワークを作成します。ヘッド数(n_head)や途中で利用される特徴量の次元(dim_feedforward)、Transformerの繰り返し回数(num_layers)を適当に指定します。
- (4) 分類問題なので最後に全結合層を付け加えます。
説明メモ2 (forwardの部分)
- (5) TransformerEncoderを使うとき、<pad>の部分を利用しないようにマスクをつけます。マスクの作成方法はいくつか考えられると思います。入力されたIDベクトルのIDがpad_token_idならマスクする(maskがTrue)という形で書いてみました3。
- (6) 単語の分散表現と単語の位置の分散表現を足し算します。
- (7) padのマスクと位置情報を考慮した分散表現行列がTransformerの入力に利用されます。src_key_padding_maskの値は表1のようになります。ちょっと見づらい

- (8) ここがポイント!
Transformerの出力は行列の形になっています。分類問題用のFCに接続するために、文頭<bos>の情報だけを利用します。他の部分は計算したけど、全部削除してしまいます4。<bos>の特徴量だけでなく、すべての単語の特徴量を利用してFCへ入力しても面白いと思います。
表1は形態素ごとに分割された文、IDベクトル、<pad>をマスクしたsrc_key_padding_maskの例となります。<pad>マスクを利用することで注意行列の<pad>列に相当する部分の値が0となります5。
| 文章 | <bos> | 登録 | を | 取り消し | たい | <eos> | <pad> | <pad> | <pad> | <pad> | <pad> |
| ID | 1 | 128 | 45 | 95 | 16 | 2 | 3 | 3 | 3 | 3 | 3 |
| マスク | False | False | False | False | False | False | True | True | True | True | True |
| 文章 | <bos> | 入会 | の | 方法 | を | 教え | て | <eos> | <pad> | <pad> | <pad> |
| ID | 1 | 86 | 29 | 115 | 45 | 111 | 18 | 2 | 3 | 3 | 3 |
| マスク | False | False | False | False | False | False | False | False | True | True | True |
表1:src_key_padding_maskの例
参考
TransformerEncoderLayer単体でも利用できるのですが、TransformerEncoderと合わせることで層を繰り返す部分をきれいに書くことが可能となります。
TransformerEncoderLayerの使い方
- encoder_layer = nn.TransformerEncoderLayer(d_model, nhead, batch_first=True)
- d_model: 分散表現の次元(入力データの特徴量の数)
- nhead: マルチヘッドアテンションを使うときのヘッド数
TransformerEncoderの使い方
- transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers)
- encoder_layer: TransformerEncoderLayerのインスタンス
- num_layers: 繰り返す回数
2つを利用すると、forwardの部分で transformer_encoder(x) として使えます。
2.3 誤差関数と誤差最小化の手法の選択
分類問題なのでおなじみのCrossEntropyLoss()を使います。
criterion = nn.CrossEntropyLoss() # 損失関数:cross_entropy
optimizer = torch.optim.AdamW(model.parameters(), lr=0.003) # 学習率:lr=0.001がデフォルト
- nn.CrossEntropyLoss() は予測値と実測値(教師データ)のクロスエントロピー損失
- torch.optim.AdamW() は誤差の最小値を求める方法の一つ
2.4 変数更新のループ
LOOPで指定した回数、
- y=model(x) で予測値を求め、
- criterion(y, t) で指定した誤差関数を使い予測値と教師データの誤差を計算、
- 誤差が小さくなるようにoptimizerに従い全結合層の重みとバイアスをアップデートします。
LOOP = 50
for epoch in range(LOOP):
optimizer.zero_grad()
y = model(x)
loss = criterion(y, t)
acc = accuracy(y,t)
loss.backward()
optimizer.step()
print(f"{epoch}:\tloss:{loss.item():.3f}\tacc:{acc:.3f}")
平均精度について
予測値と教師データで等しい値なら正解として、正解数/問題数で精度を求める単純な平均精度を求めます。
def accuracy(y, t):
_,argmax_list = torch.max(y, dim=1)
accuracy = sum(argmax_list == t).item()/len(t)
return accuracy
2.5 検証
2.1のデータ分割で作成したテストデータ x_test と t_test を利用して学習結果をテストしてみましょう。x_testをmodelに入れた値 y_test = model(x_test) が予測値となります。accuracyで平均精度を求めれば完成です。
model.eval()
y_test = model(x_test)
acc = accuracy(y_test, t_test)
print(f"検証精度: {acc}")
# 検証精度: 0.9130434782608695
- 10回くらい試したけど、90%は1回だけ、ほとんど70〜80%の範囲。
- 数値を大きくするとほんのすこしだけ精度上昇っぽいが、1〜2個多く当たるだけ。テストデータ23個だしね。
prediction
解約 ログイン 登録
true 解約 8 0 0
ログイン 0 8 0
登録 0 2 5
検証精度90%はたまたま、ほとんどが70〜80% 悪いと60%になるぞ
検証精度: 0.9
- D_MODEL = 16
- head = 4
- layer=6
- dim_feed=32
第21回のConv1dを利用したtext cnnのほうが学習結果も安定しており精度も80%台でした。長文での単語の依存関係を抽出できるというTransformerの効果が不要なほど分類させる文章が短いというのが原因の一つです。ニュース記事やレビューなどの長い文章で試したくなってきますね![]()
傾向
- layer数を大きくすると精度が上昇しやすいけど、大きすぎてもNGっぽい
- 基本的に数値が大きいほど精度も緩やかな上昇傾向にあるけど、計算速度もどんどん遅くなるし、90%が多分上限ぽい
- 正規化やドロップアウト入れたほうが精度にばらつきが少ない傾向にある
def __init__():
#〜〜〜略〜〜〜
self.layer_norm = nn.LayerNorm(D_MODEL)
self.dropout = nn.Dropout(0.1)
#〜〜〜 〜〜〜
def forward(self, x):
#〜〜〜略〜〜〜
# 例えばtransformerの前に正規化やドロップアウトを入れてみるなど
x = tok_emb + pos_emb.unsqueeze(0)
# Layer Normalization と Dropout
x = self.layer_norm(x)
x = self.dropout(x)
h = self.transformer_encoder(x, src_key_padding_mask=src_key_padding_mask)
次回
次回、Transformerの注意機構に登場する注意行列・Attention Weightsを眺めてみたいと思います。
目次ページ
注
-
Transformer自体の解説や詳しい実装は他の方に委ねたいと思います。
QittaならyukioroさんのQKV注意機構の原理と...とTransformerブロックを...。解説例が日本語であるHarumitsu Nobuta@halhornさんの作って理解する Transformer / Attentionなどなど沢山の方々が解説しています ↩ ↩2
↩ ↩2 -
位置埋め込みについて、Transformerの原論文だと、sinやcosを使った固定型となります。今回は先頭から0,1,2,…という絶対的位置埋め込みになっています。ほかにも回転したり、相対的に位置を決める方法もあるようです。 ↩
-
<pad>をマスクしなくてもTransformerEncoderは動きますが、マスクをつけておいたほうが効率的かと思います
 ↩
↩ -
BERTだと文頭のトークンは[CLS]という呼称になります。classificationやclassあたりの略語かな? ↩
-
<pad>列の値は0になりますが、<pad>行は計算されます。可視化をする回で確認したいと思います。 ↩