概要
個人的な備忘録を兼ねたPyTorchの基本的な解説とまとめになります。今回から自然言語の内容となります。自然言語の初回は単語の分散表現とPyTorchの埋め込み層 (Embedding Layer) の概略についてです。

1. 単語とID(数値表現)の対応表
1.1 ID文
言葉をニューラルネットワークで扱うには、言葉を数値で表現する必要がありそうです。文章を数値化の手順は大きく3つに分けられます。
- トークン化: 文章を単語のような意味のある塊(トークン)に分割1
- 辞書の作成: 文章に登場したすべてのトークンに固有の番号(ID)を割り当てた対応表を作成
- ID化: 文章をID(数値表現)の列として表現
例えば、「私はりんごが好きです。」という文章は、
- トークン化: [ "私", "は", "りんご", "が", "好き", "です", "。" ]
- 辞書の作成: {"私": 0, "みかん": 1, "りんご": 2, "が": 3, "は":4, "好き": 5, "です": 6 ..."。": 100,...}
- ID化: [0, 4, 2, 3, 5, 6, 100 ]
という形になります。
トークンの分割には様々な方法が考案されています。形態素解析(MeCabなど)を利用した分かち書き分割、サブワード分割(BPE)、文字レベル分割など、目的に応じて選択されるようです。
興味深い例として、文字の視覚的構造や表記の多様性を考慮した方法も提案されています。具体的には漢字の「篇」や「旁」を分解するような方法です。
- 字形分解の例: 「鮪」を「魚」と「有」に分解する手法
- 俗字当て字例: カタカナの「ネ」と漢字の「申」を組み合わせ、「ネ申」を「神」として認識する手法
これらは本来の言語学的な分割とは異なりますが、インターネット上の多様な表現方法に対応するユニークなアプローチと言えます。
今回は埋め込み層の理解に集中するため、日本語文章はすでにID化された数値ベクトル( [ 0, 4, 2, 3, 5, 6, 100 ]のような形 )で表現されているとします。
1.2 単語ID辞書と文の数値表現
例1
例文1と例文2から「今日」「明日」「は」「晴れ」「雨」の5単語を抽出し、単語とIDの辞書を表1のように作成したとします。
- 例文1:「今日は晴れ」
- 例文2:「明日は雨」
表1: 辞書1
| 単語 | ID |
|---|---|
| 今日 | 0 |
| 明日 | 1 |
| は | 2 |
| 晴れ | 3 |
| 雨 | 4 |
辞書1を利用して文をIDベクトルで表現したものが表2です。
表2:ID文・IDベクトル
| 文 | IDベクトル |
|---|---|
| 今日/は/晴れ | [0, 2, 3] |
| 明日/は/雨 | [1, 2, 4] |
| 今日/は/雨 | [0, 2, 4] |
| 明日/は/晴れ | [1, 2, 3] |
表2のようにIDベクトルを利用して文を数値の列とみなすことが確認できます。蛇足ですが辞書が変わると当然IDベクトルの数値も変わります![]()
IDによる数値表現では、語彙数に応じて利用される数値が大きくなっていきます。しかも、「今日」のID=0と「明日」のID=1では、あたかも「今日 < 明日」という関係があるかのようにも見えてしまいます。もちろん、単語間に順序関係はありません。
この問題を解決する一つの方法として、one-hotベクトルと呼ばれる表現方法があります。これは、語彙数と同じ次元のベクトルを用意し、自分自身に対応する位置だけ1、それ以外を0とする表現です。
表3:one-hotベクトルによる表現
| 単語 | ID | one-hotベクトル |
|---|---|---|
| 今日 | 0 | (1,0,0,0,0) |
| 明日 | 1 | (0,1,0,0,0) |
| は | 2 | (0,0,1,0,0) |
| 晴れ | 3 | (0,0,0,1,0) |
| 雨 | 4 | (0,0,0,0,1) |
表3は表1をone-hotベクトルで表現したものとなります。辞書1の総単語数が5個なので5次元となります2。one-hotベクトルを利用すると例文1は
\begin{matrix}
今日 \\
は \\
晴れ
\end{matrix}
\begin{pmatrix}
1 & 0& 0& 0& 0 \\
0 & 0& 1& 0& 0 \\
0 & 0& 0& 1& 0 \\
\end{pmatrix}
という行列で表現されます3。
one-hotベクトルは、1箇所だけ「1」で残りは「0」 です。語彙数が増えるとベクトルの次元も増えていきます。このone-hotベクトルは、単語IDの「スカラー値」よりも表現力の高いベクトルでの特徴づけを単語に対して行っているのですが、冗長な気もします。
- 次元: 語彙数に比例して次元が増えるため、効率が悪そう
- 単語間の関係: 単語の意味までは表現できなさそう
これらの問題を解決するのが分散表現 (distributed representation) です。
1.3 分散表現・埋め込みベクトル
2つの問題を解決するひとつのアイディアが、one-hotベクトルに行サイズが単語数(one-hotベクトルの次元数)の行列を掛け算する方法になります。例2では、5行2列の行列を掛け算しています。
例2
\begin{matrix}
今日 \\
は \\
晴れ
\end{matrix}
\begin{pmatrix}
1 & 0& 0& 0& 0 \\
0 & 0& 1& 0& 0 \\
0 & 0& 0& 1& 0 \\
\end{pmatrix}
\begin{pmatrix}
1& 2 \\
3& 4 \\
5& 6 \\
7& 8 \\
9& 0 \\
\end{pmatrix}=
\begin{pmatrix}
1 & 2 \\
5 & 6 \\
7 & 8 \\
\end{pmatrix}
単語「今日」は、(1,0,0,0,0)という粗なベクトルから(1, 2)という密なベクトルで表現されていることがわかります。
one-hotベクトルで特徴付けられた文を表す行列に「総単語数」×「表現したい次元数」の行列(埋め込み行列)を掛け算することで、文をより密度の高い表現に変換することができそうです。変換された密なベクトルは、「単語の埋め込みベクトル」や「単語の分散表現」 などと呼ばれています。
one-hotベクトルと埋め込み行列の掛け算は、事実上、one-hotベクトルの1に対応する行を埋め込み行列から抽出しているだけだな〜![]()
例3
- 「今日」を埋め込みベクトルに変換した例
\begin{matrix}
今日 \\
\end{matrix}
~~
\begin{pmatrix}
1 & 0& 0& 0& 0 \\
\end{pmatrix}
\begin{pmatrix}
1& 2 \\
3& 4 \\
5& 6 \\
7& 8 \\
9& 0 \\
\end{pmatrix}=
\begin{pmatrix}
1 & 2 \\
\end{pmatrix}
「今日」の埋め込みベクトルは、埋め込み行列の1行目に相当します。
2. 「晴れ」を埋め込みベクトルに変換した例
\begin{matrix}
晴れ \\
\end{matrix}
~
\begin{pmatrix}
0 & 0& 0& 1& 0 \\
\end{pmatrix}
\begin{pmatrix}
1& 2 \\
3& 4 \\
5& 6 \\
7& 8 \\
9& 0 \\
\end{pmatrix}=
\begin{pmatrix}
7 & 8 \\
\end{pmatrix}
「晴れ」の埋め込みベクトルは、埋め込み行列の4行目になります。埋め込み行列の行が事実上の単語の分散表現になっています。
2. nn.Embeddingの使い方
PyTorchではnn.Embeddingを使うことで、単語の分散表現を簡単に計算することができます。使い方は、「総単語数」と「表現したいベクトル(分散表現)の次元数」の2種類を指定するだけです。
PyTorchのEmbedding層
- embed = nn.Embedding(num_embeddings, embedding_dim)
- num_embeddings: 総単語数
- embedding_dim: 分散表現の次元数(埋め込みベクトルの次元数)
使い方
- y = embed(x)
- x: ID化された入力データ(ID文)
- y: 分散表現の行列(系列長×分散表現の次元)
2.1 数値例1
次のような数値を持つ5×2の埋め込み行列を利用して、実際にEmbedding層の使い方と計算結果を確認していきます4。
\begin{pmatrix}
1& 2 \\
3& 4 \\
5& 6 \\
7& 8 \\
9& 0 \\
\end{pmatrix}
コードから見てわかるように、Embedding層の出力結果が、入力したID文に対応した行列となっていることが確認できます。
import torch
import torch.nn as nn
# (1) 埋め込み行列を指定
pre_weights = torch.tensor([
[1, 2], # ID=0の単語の埋め込みベクトル
[3, 4], # ID=1の単語の埋め込みベクトル
[5, 6], # ID=2の単語の埋め込みベクトル
[7, 8], # ID=3の単語の埋め込みベクトル
[9, 0] # ID=4の単語の埋め込みベクトル
])
# (2) Embeddingレイヤーを作成・指定の重みを使うケース
embed = nn.Embedding.from_pretrained(pre_weights, freeze=True)
# (3) 使う
x = torch.LongTensor([0, 1, 4, 0]) # 入力データ
output = embed(x) # 埋め込みベクトルを計算
print(output) # 埋め込み行列の行と対応している
# (4) outputの出力(分散表現行列)
#
# tensor([[1, 2],
# [3, 4],
# [9, 0],
# [1, 2]])
説明メモ
- (1) 埋め込み行列をpre_weightsとして作成。総単語数が5、分散表現の次元数は2として重みを指定しました。
- (2) nn.Embedding.from_pretrained() によって指定した埋め込み行列を重みとして指定できます。embed.weightsで設定した行列を確認できます。
freeze=Falseにするとニューラルネットワークでの学習時に重みが更新されることになります。 - 通常は、学習済みの重みが未知なのでfrom_pretraind()ではなく、embed = nn.Embedding(num_embeddings=総単語数, embedding_dim=分散表現の次元数)
として利用します。 - (3)
x=[0, 1, 4, 0]というID列を入力データとします。 - (4) 出力結果は、IDに対応した行の値になっていることが確認できます。
2.2 ニューラルネットワークでの利用を想定した使い方
数値例1は分散表現行列の重みを事前に与える形になっていました。ニューラルネットワークで埋め込み層を使う場合、分散表現行列の重みを更新することができます。 from_pretrained(pre_weights, freeze=True) の形を利用しないので、使い方は、更にやさしくなります。
import torch
import torch.nn as nn
# (1) Embeddingレイヤーを作成
embed = nn.Embedding(num_embeddings=5, embedding_dim=2)
# (2) 入力データ
x = torch.LongTensor([0, 1, 4, 0]) # 入力データ
# (3) 使う
output = embed(x)
print(output)
print(output.shape)
# tensor([[ 0.3843, 0.1750],
# [-0.3712, 2.5252],
# [-1.3783, 0.2281],
# [ 0.3843, 0.1750]], grad_fn=<EmbeddingBackward0>)
# torch.Size([4, 2])
nn.Embedding(num_embeddings=5, embedding_dim=2)の引数として、総単語数であるnum_embeddingと分散表現の次元であるembedding_dimの数値を指定すればOKです。
Embeddingを利用すると文章が、「系列長」×「分散表現の次元」という行列の形 で表現できそうですね ![]()
![]()
![]()
文章が画像のように行列の形に特徴づけられるのです。
2.3 可視化してみた
単語がベクトルで表現ということは?グラフ上にプロットできるということなので、実行してみたいと思います。機械学習すると類義の単語は近くに、対義の単語は反対側に位置すると期待されるはず![]()
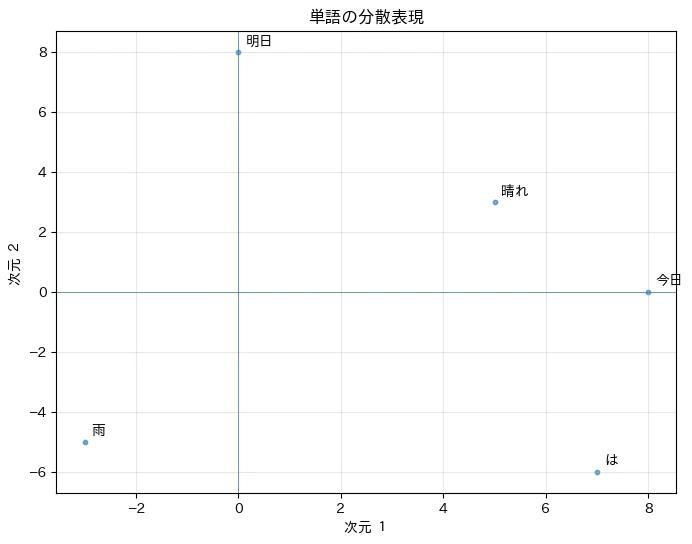
単語が平面に並んでいる図を描いてみたい!上記のグラフを出力するコードは次のようになります。分散表現の行ベクトルが対応するIDの単語の分散表現になります。分散表現行列の行を抽出して、描画すれば平面図の描くことができそうです。
サンプルのコードでは単語の埋め込みベクトルを事前に与えてあります。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import japanize_matplotlib
# (1) 重みを指定(作図ように変更してある)
pre_weights = torch.tensor([
[8, 0], # ID=0の単語の埋め込みベクトル
[0, 8], # ID=1の単語の埋め込みベクトル
[7, -6], # ID=2の単語の埋め込みベクトル
[5, 3], # ID=3の単語の埋め込みベクトル
[-3, -5] # ID=4の単語の埋め込みベクトル
])
# (2) Embeddingレイヤーを作成
embed = nn.Embedding.from_pretrained(pre_weights, freeze=True)
# (3) 単語リスト
# "今日":0, "明日":1, "は":2, "晴れ":3, "雨":4
words = ["今日","明日","は","晴れ","雨"]
# (4) 重みを取得
weights = embed.weight.detach().numpy()
# (5) 可視化
# (5-1) scatterで重みの散布図を描画
plt.figure(figsize=(8, 6))
plt.scatter(weights[:, 0], weights[:, 1], s=10, alpha=0.6)
# (5-2) 各点に単語ラベルを追加
for i, word in enumerate(words):
plt.annotate(word,
xy=(weights[i, 0], weights[i, 1]),
xytext=(5, 5), # ラベルの位置をずらす
textcoords="offset points",
#fontsize=12,
ha='left')
# (5-3) お化粧
plt.xlabel("次元 1")
plt.ylabel("次元 2")
plt.title("単語の分散表現")
plt.grid(alpha=0.3)
plt.axhline(y=0, linewidth=0.5)
plt.axvline(x=0, linewidth=0.5)
plt.show()
説明メモ
基本的なアイディアは、単語を対応した埋め込みベクトルの座標に表示させるだけです。
- (1) 埋め込み行列をpre_weightsとして作成する
- (2) Embeddingの重みとしてpre_weightsを利用する
- (3) 単語ID辞書のID順に単語のリストを作成
- (4) embedの重みをnumpyに変換(TorchTensorになっているので一旦numpyに戻します。)
- (5-1) 単語に対応する座標に、「●」をプロットします。散布図と同じ要領となります。
- (5-2) 単語を対応する座標「●」よりも少し右上に表示させます。サンプルコードでは、forループでplt.annotate()を利用して順番に単語をプロットしています。
xytext=(5,5)を変更して好みの位置に修正してください。右下に単語を表示させるにはxytext=(0, -10)という感じです。 - (5-3) この部分は必要に応じて加筆修正してください。
次回
分散表現の行列を利用した文章分類に入っていきたいと考えています。準備にやや時間がかかりそうな予感![]()
目次ページ