皆さんこんにちは!これまであまり知られて来なかったブラウザ版のSPSS Modeler Flow をシリーズでご紹介したいと思います。
IBM Cloudで始めるブラウザ版SPSS Modeler Flow ⑥ では、Modeler Flowの処理をジョブにしてスケジュール実行する設定をご紹介します。
シリーズ①サンプルプロジェクトを使ってみる
シリーズ②ファイルからデータを読み込んでみよう
シリーズ③データベースからデータを読み込んでみよう
シリーズ④SPSS Modelerで作成したストリームをIBM CloudのSPSS Modeler Flowに取り込む
シリーズ⑤IBM Cloudで始めるブラウザ版SPSS Modeler Flow⑤ SPSS Modelerのモデルをオンラインで呼び出そう
シリーズ6回目のこの記事では、以下の流れでご説明します。
Modeler Flowの処理をジョブにしてスケジュール実行しよう
- データ資産エクスポートノードを追加する
- ジョブの設定をする
- 実行結果を確認する
- 入力のデータを変えて実行してみる
1. データ資産エクスポートノードを追加する
プロジェクトにアップされているcars.csvを読み込み、output.csvファイルをプロジェクト内にエクスポートするフローを作成し、ジョブとして保存します。
IBM Cloudのwatsonxにログインし、watsonxのトップページで左上の 四本線のメニューアイコンから「プロジェクト」>「すべてのプロジェクト」 をクリックします。
シリーズ①サンプルプロジェクトを使ってみるで作成したプロジェクト「SPSS Modeler Project」を開きます。
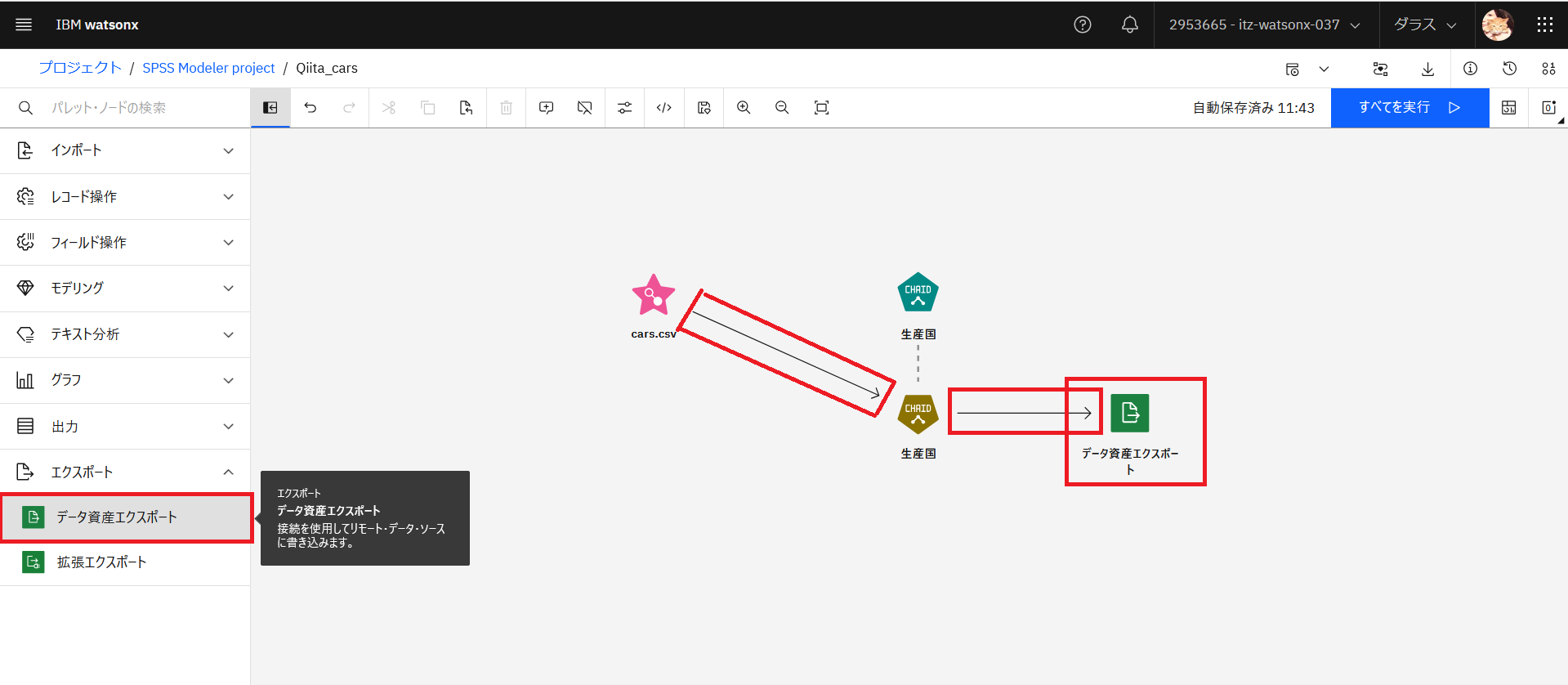
シリーズ④SPSS Modelerで作成したストリームをIBM CloudのSPSS Modeler Flowに取り込むで作成したフロー(Qiita_cars)を開きます。
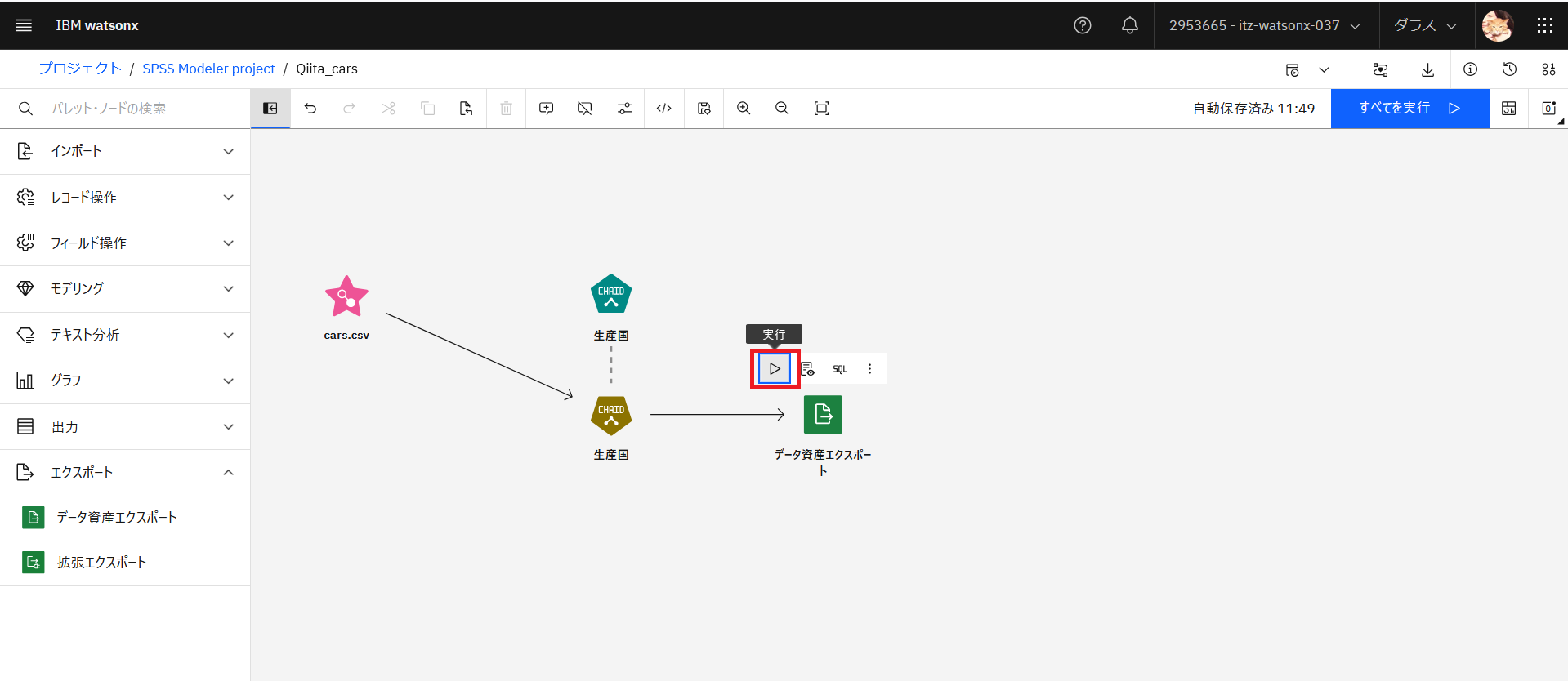
「ユーザー入力ノード」と「表」ノードを削除し、新たに、「データ資産エクスポート」ノードをダブルクリックして追加します。「cars.csv」とモデル「生産国」を接続し直し、モデル「生産国」と「データ資産エクスポート」を接続します。以下の画面のようにしてください。
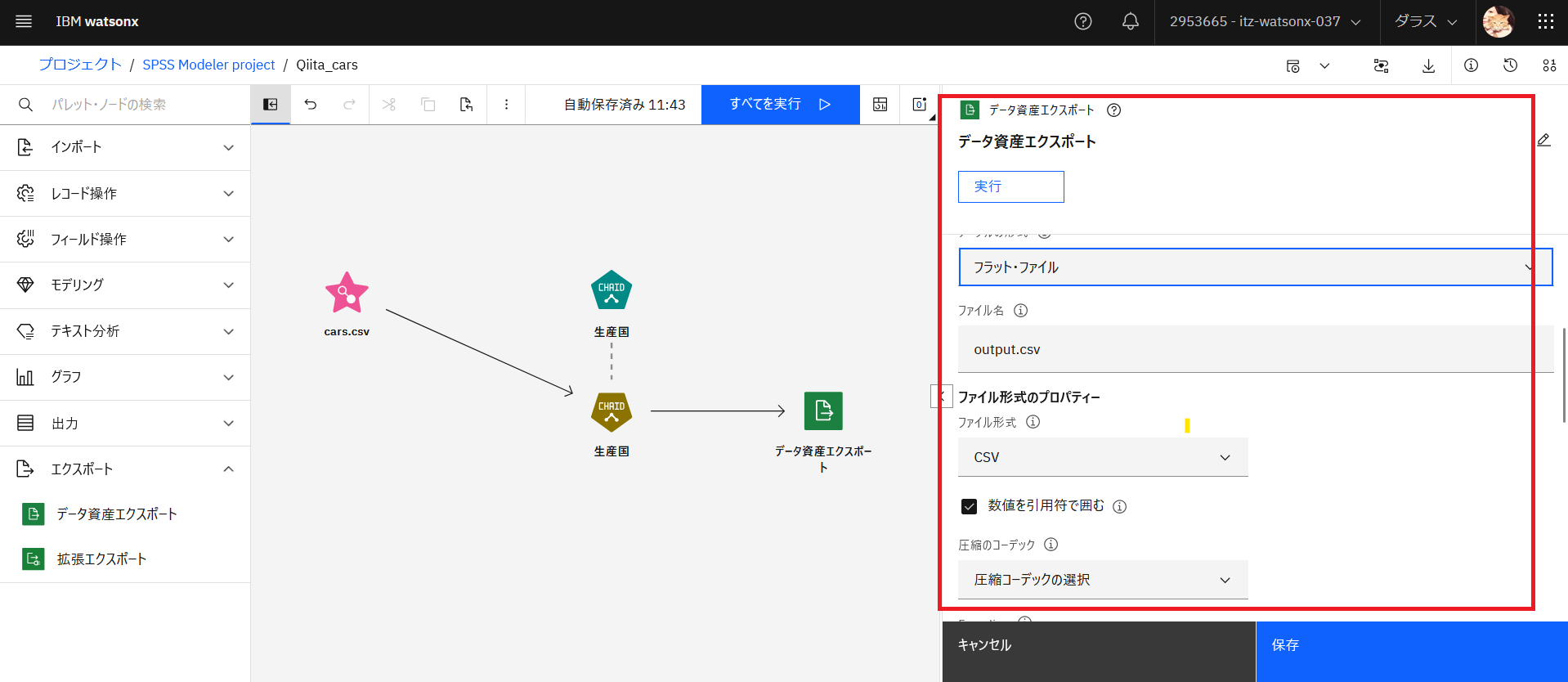
「データ資産エクスポート」をダブルクリックし、プロパティー画面を開きます。「テーブル形式」、「ファイル名」、「ファイル形式」、「エンコーディング」等を確認します。
データ資産エクスポートを実行して、プロジェクトに「output.csv」がエクスポートされるか確認します。
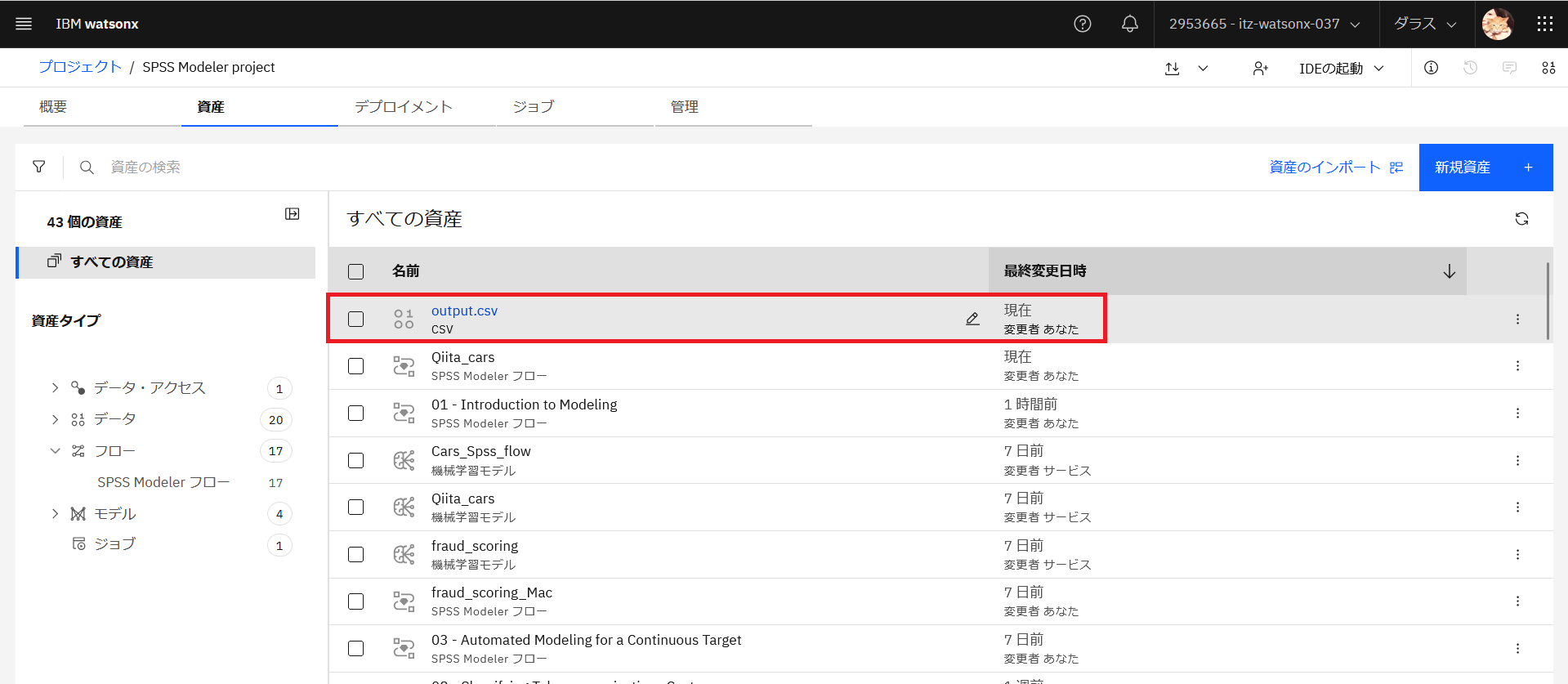
プロジェクトの「資産」タブを見てみると、エクスポートされているのが確認できました。
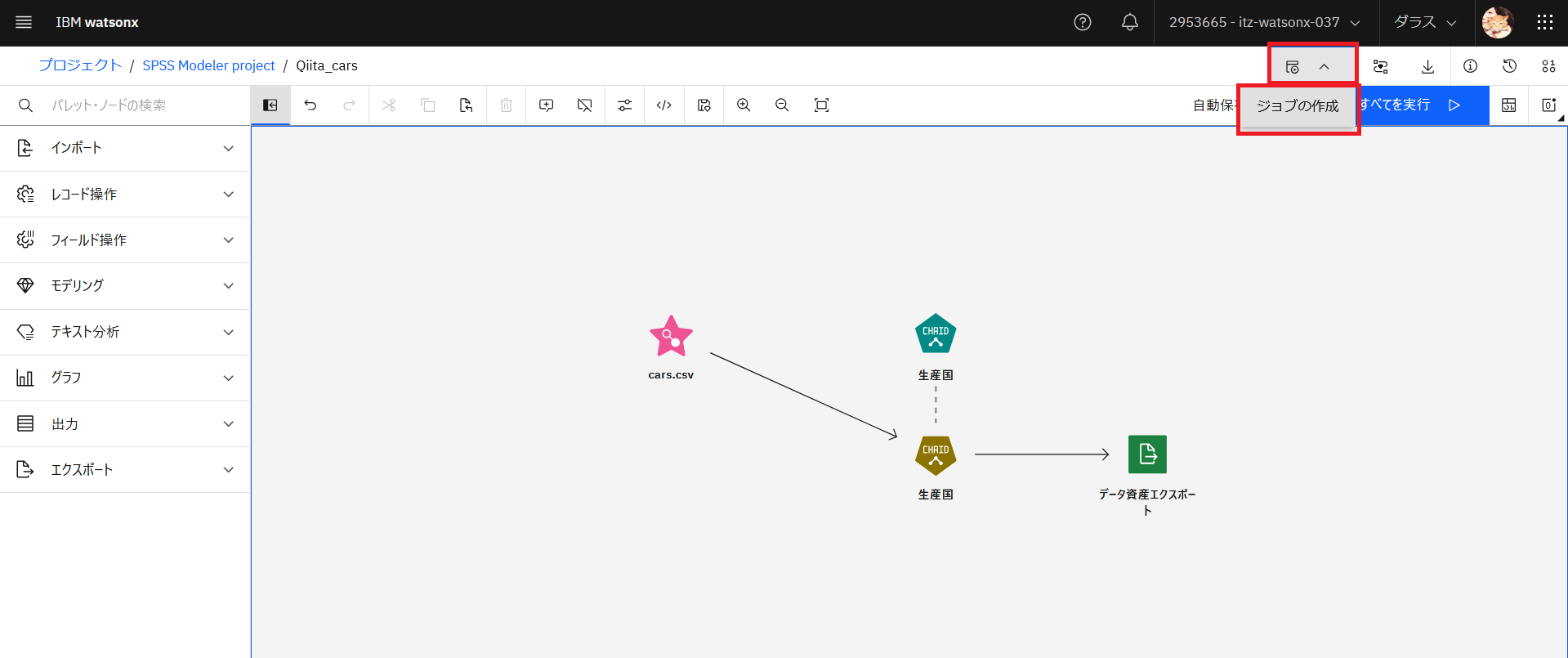
2. ジョブの設定をする
もう一度「Qiita_cars」のフローをクリックして開き、「新規ジョブ(のアイコン)」→「ジョブの作成」の順でクリックします。
ジョブの名前を入力し、環境定義を指定します。
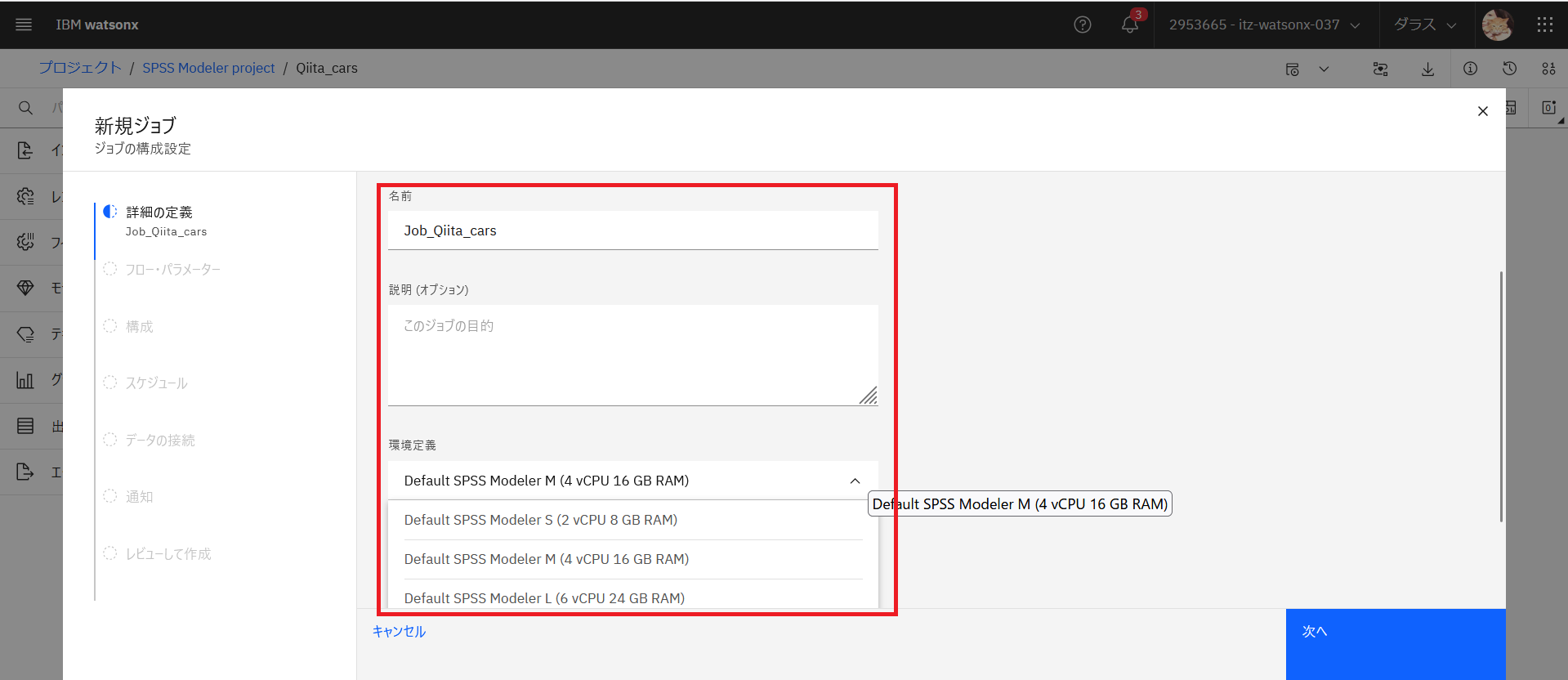
ジョブ実行の保存設定を変更したい場合はチェックボックスにチェックをして、日数や量を設定します。デフォルトでは、ジョブ実行と関連成果物は永続的に保持されます。 保存設定が有効になっている場合は、終了したジョブの実行期間と成果物が保存される期間 (デフォルトは 7 日) を調整するか、終了したジョブの実行回数 (デフォルトは 200) によって保存を指定することで、保存を管理できます。
「次へ」をクリックします。
フロー・パラメータを設定している場合は、この画面で設定します。「次へ」をクリックします。
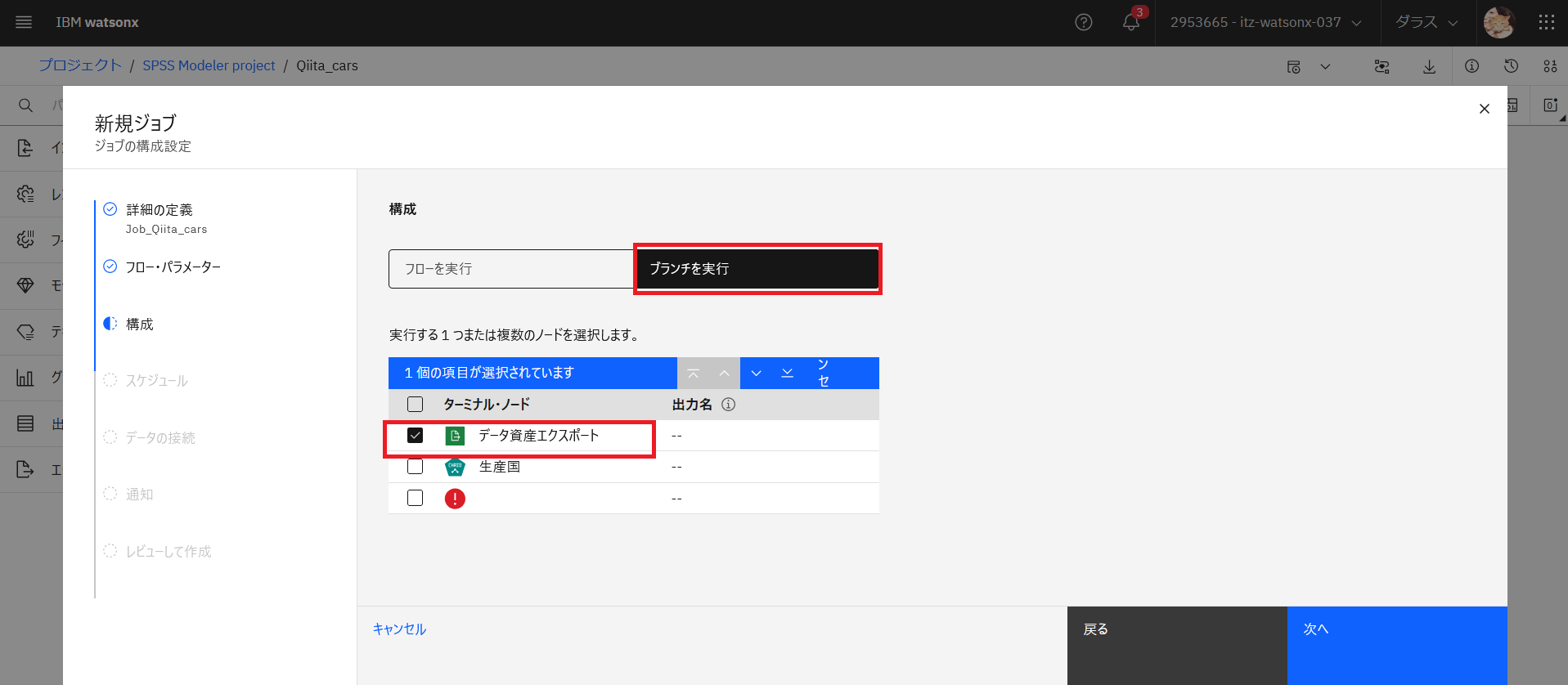
ブランチを実行をクリックし、「データ資産エクスポート」ノードを選択します。「次へ」をクリックします。
ジョブの動作確認をしたいので、「ジョブ作成後に実行」にチェックをします。スケジュール実行する場合は、「スケジュールで実行」にチェックをして、
- 「スケジュールの開始」の日時(ジョブが実行される時日時ではなく、スケジュールが有効になる日時)
- 「ジョブの繰り返し」(ジョブが実行される日時)
- 「スケジュールの終わり」(スケジュールが無効化する日時)
を設定します。「次へ」をクリックします。

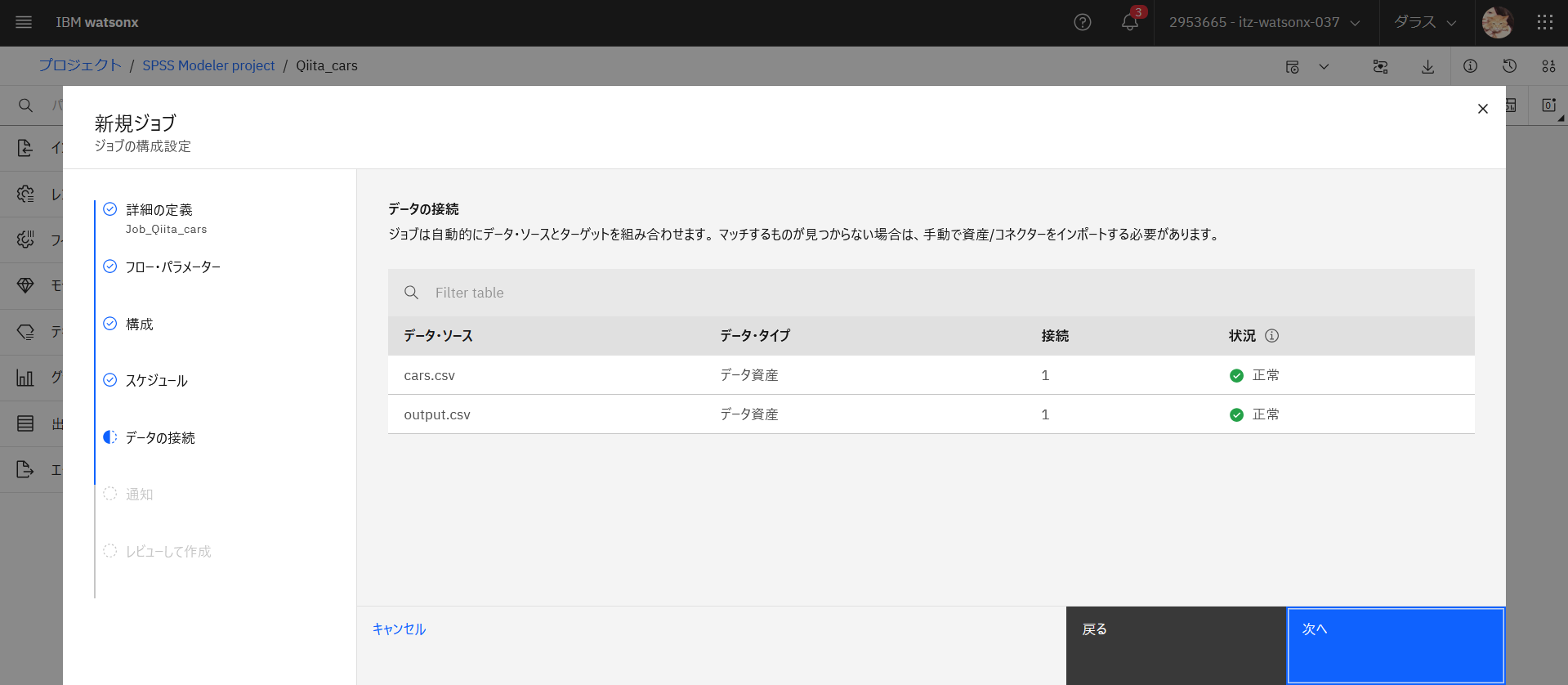
データソースが正常に接続されているか確認します。「次へ」をクリックします。
通知が必要な場合は、オンにしてアラート対象を設定します。「次へ」をクリックします。
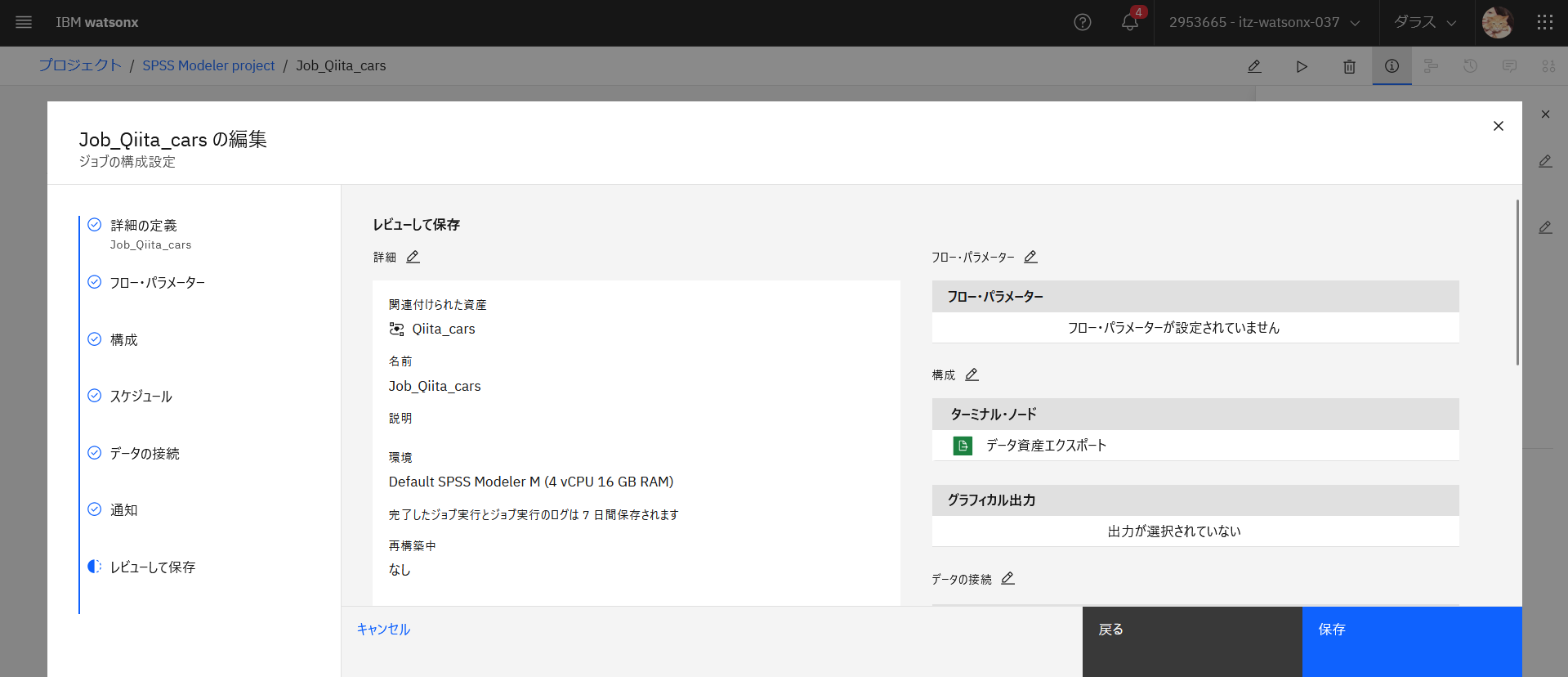
設定内容をレビューして問題なければ、「作成して実行」をクリックします。
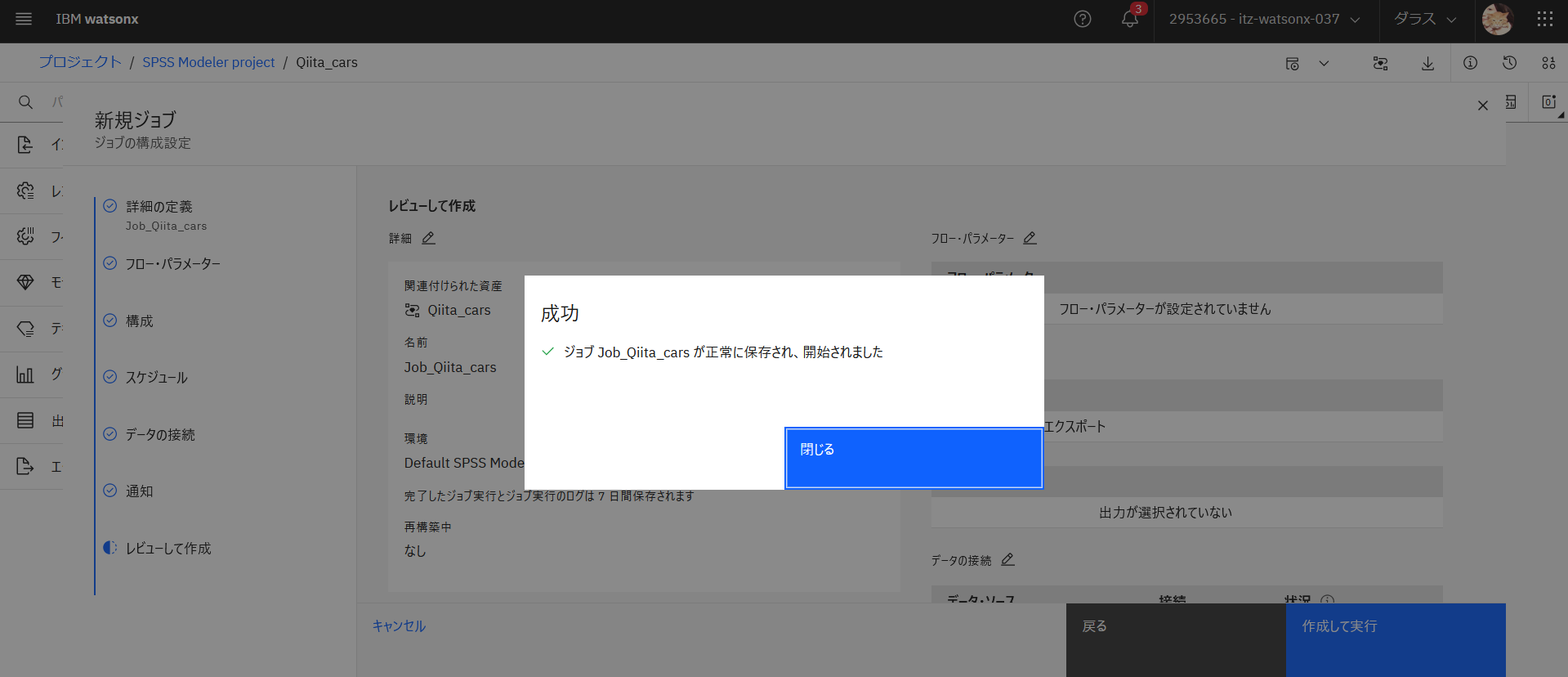
ジョブが正常に保存されると以下のメッセージが表示されます。
3. 実行結果を確認する
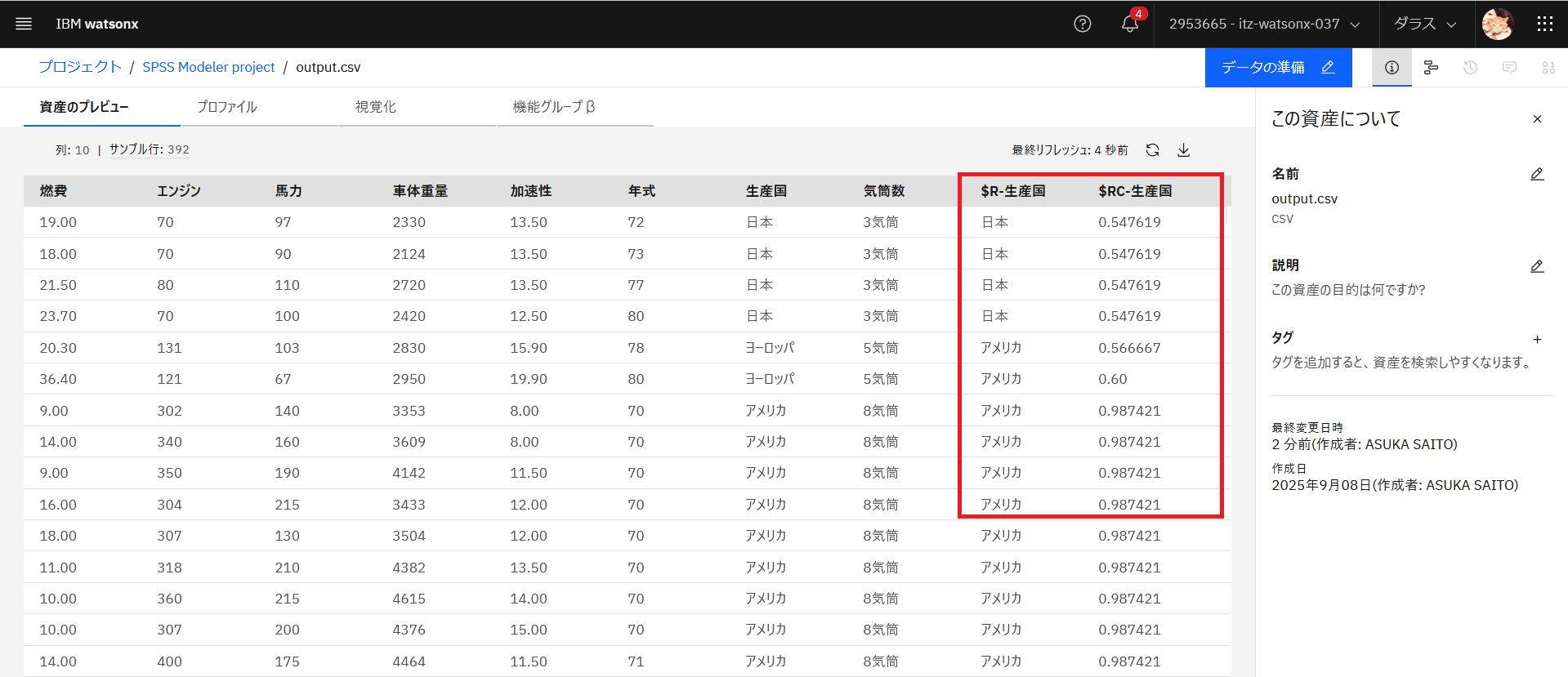
プロジェクトの資産の一覧を表示し、「output.csv」ファイルをクリックします。予測と確信度が追加されているのを確認することができます。
プロジェクトの資産の一覧に戻り、先ほど作成したジョブ名をクリックします。
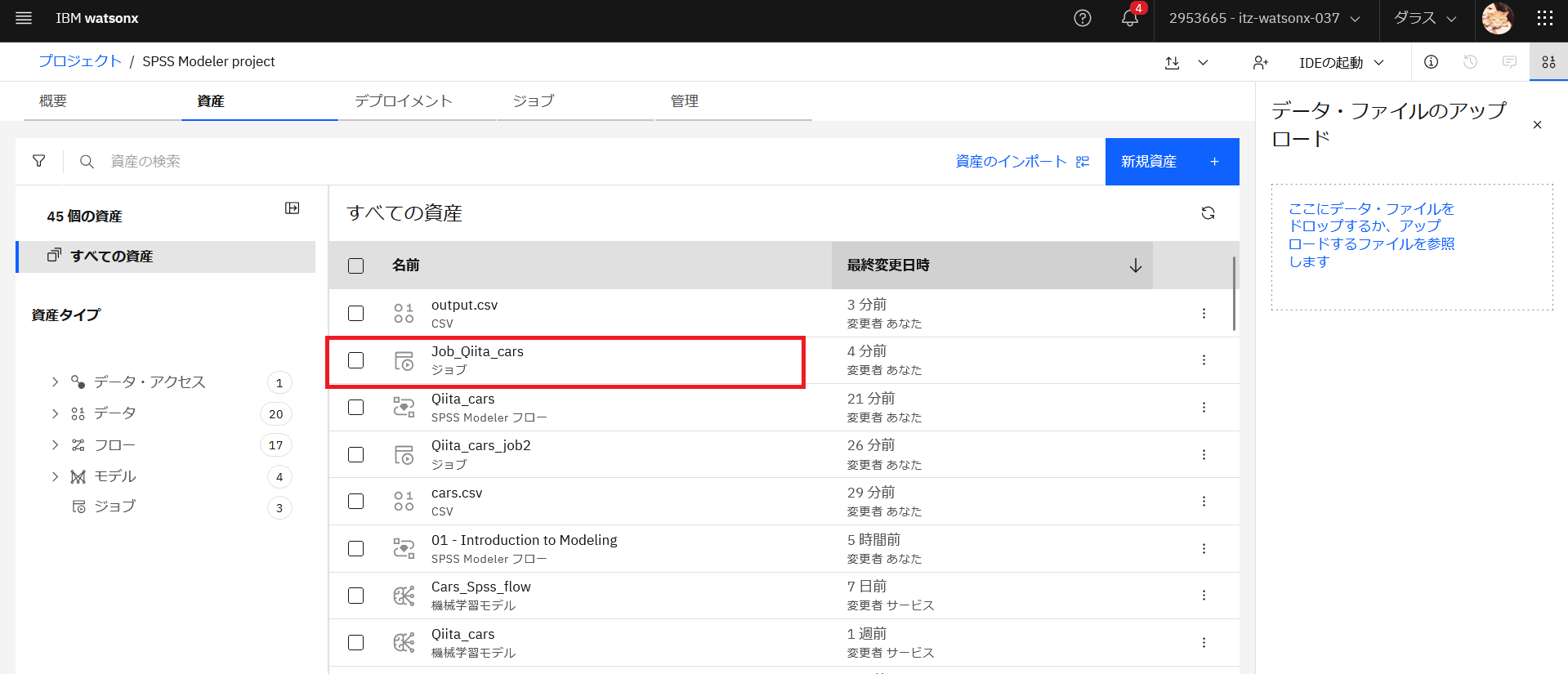
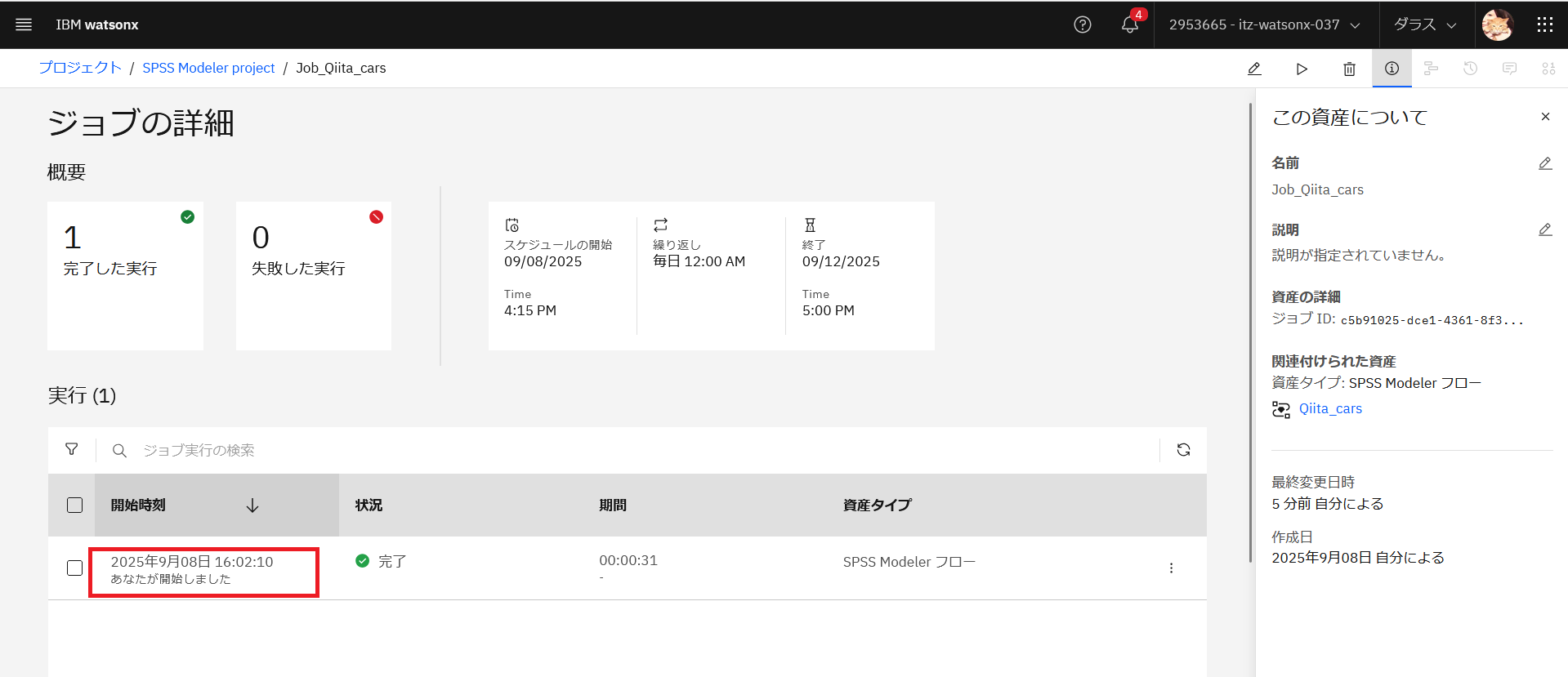
ジョブの詳細で実行結果を確認することができます。実行結果の開始時刻をクリックすると、ログを確認できます。
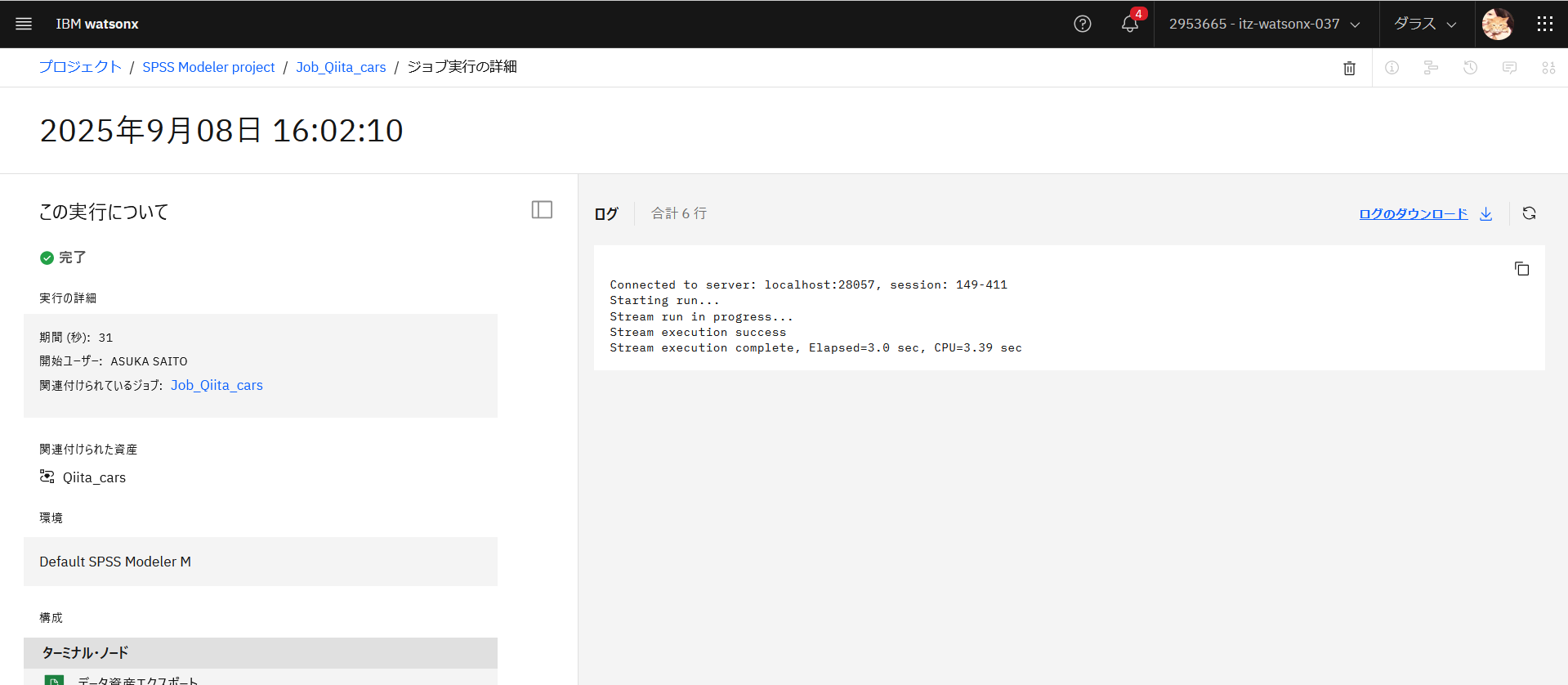
4.入力のデータを変えて実行してみる
ジョブの入力データであるcars.csvのファイル名は変えずにデータを変更したものを準備します。

プロジェクトの資産の一覧のページの右上にあるアイコンをクリックして、ファイルアップロードのインターフェースを表示します。
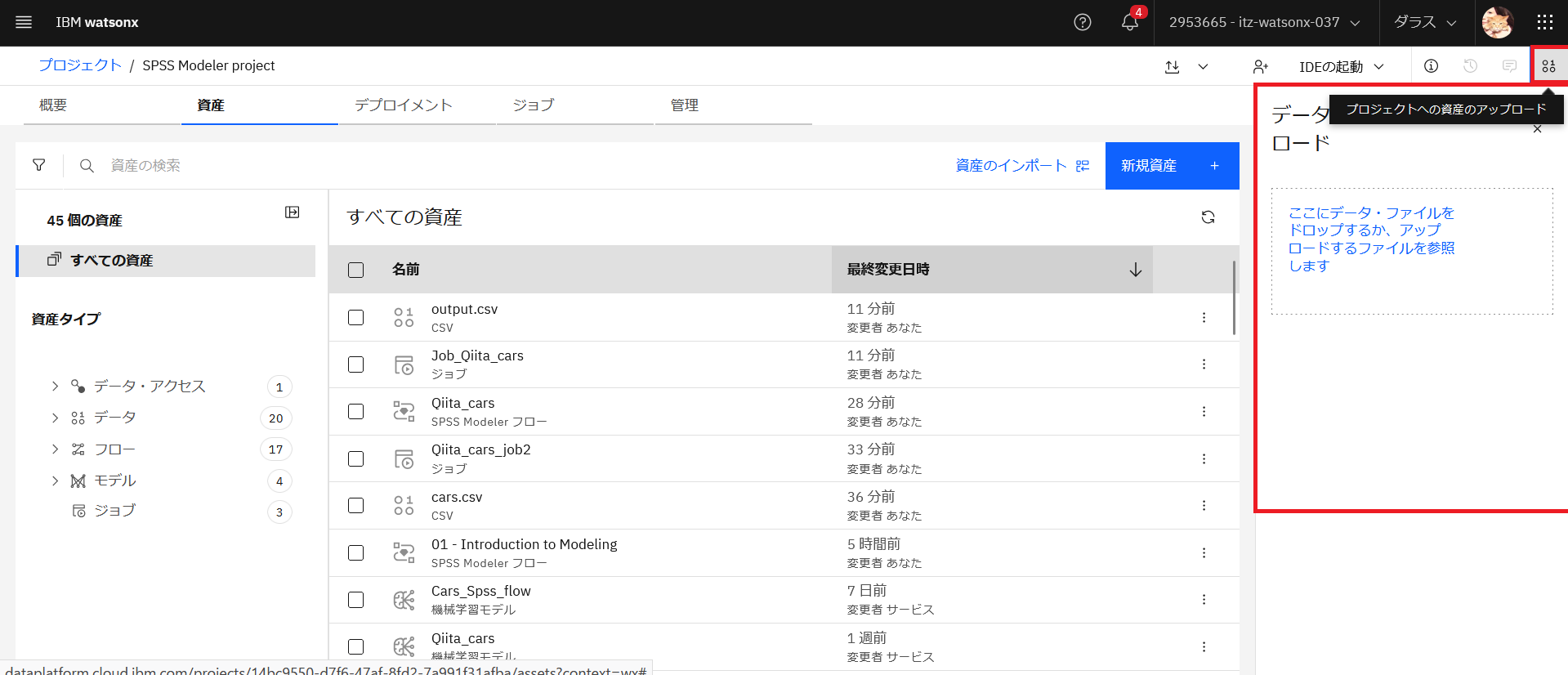
ファイルをドラック&ドロップするか指定してアップロードします。「既存のファイルを上書き」を選択し、「実行依頼」をクリックします。
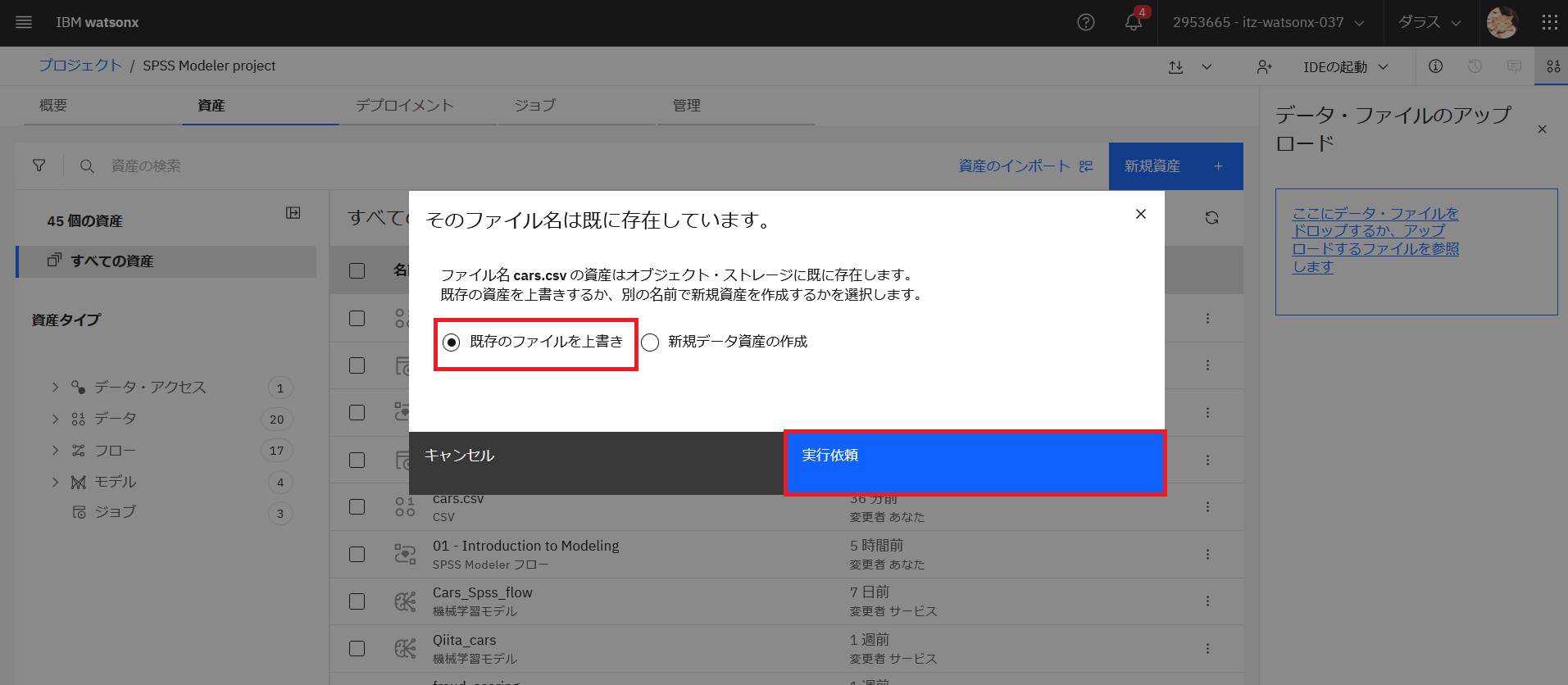
ファイルがアップロードされました。最終変更日時を確認してください。
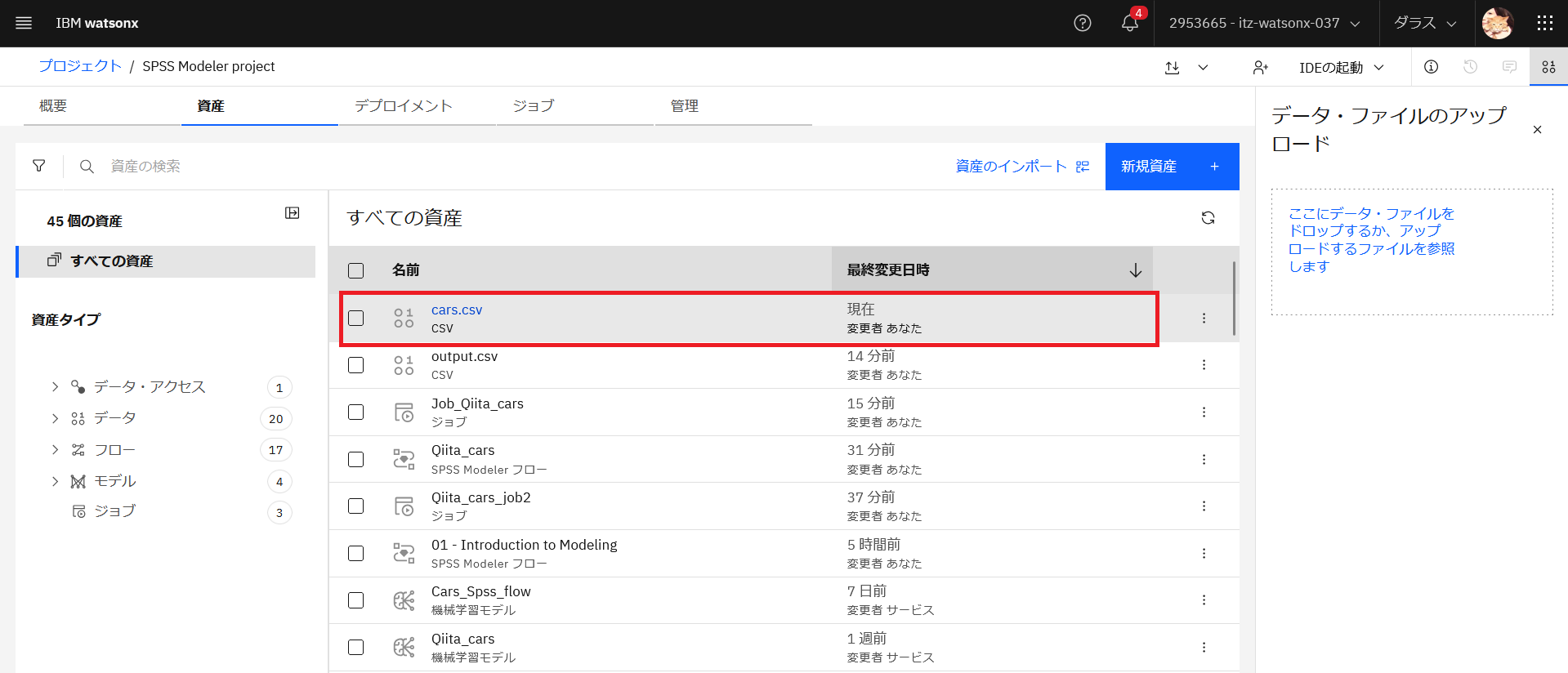
次にすぐにジョブを起動したいので、設定を変更します。先ほど作成したジョブの名前をクリックします。
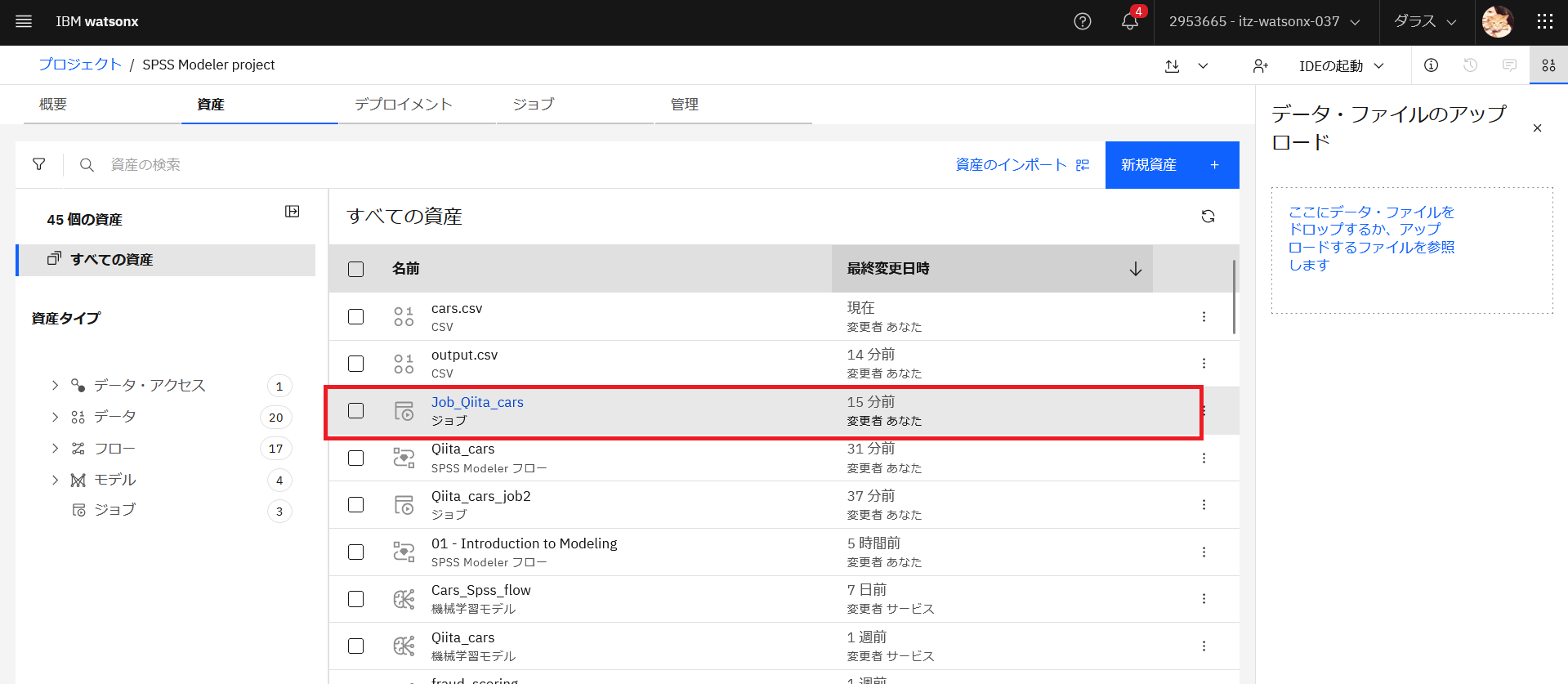
「構成の変更」をクリックします。
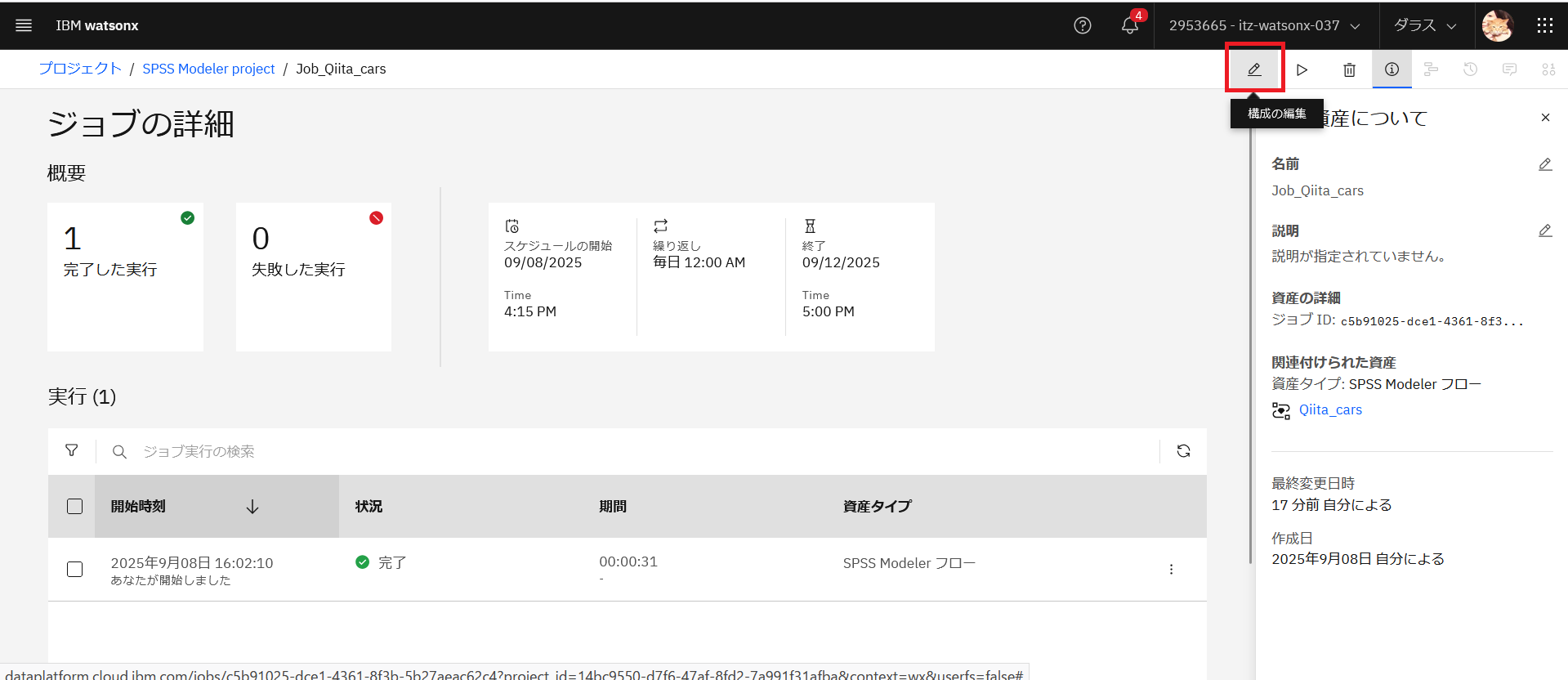
「スケジュール」で「スケジュールの開始」「ジョブの繰り返し」の時刻を調整します。
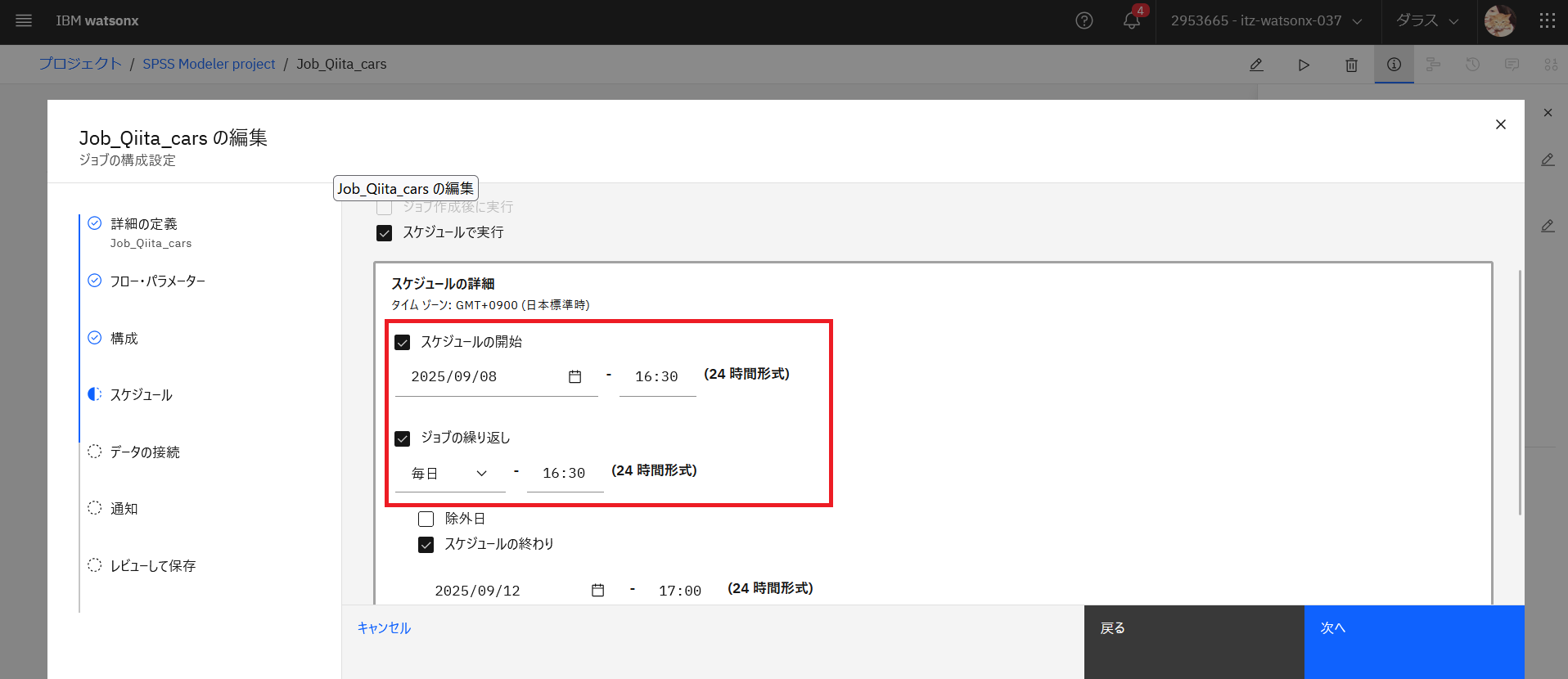
保存をクリックします。
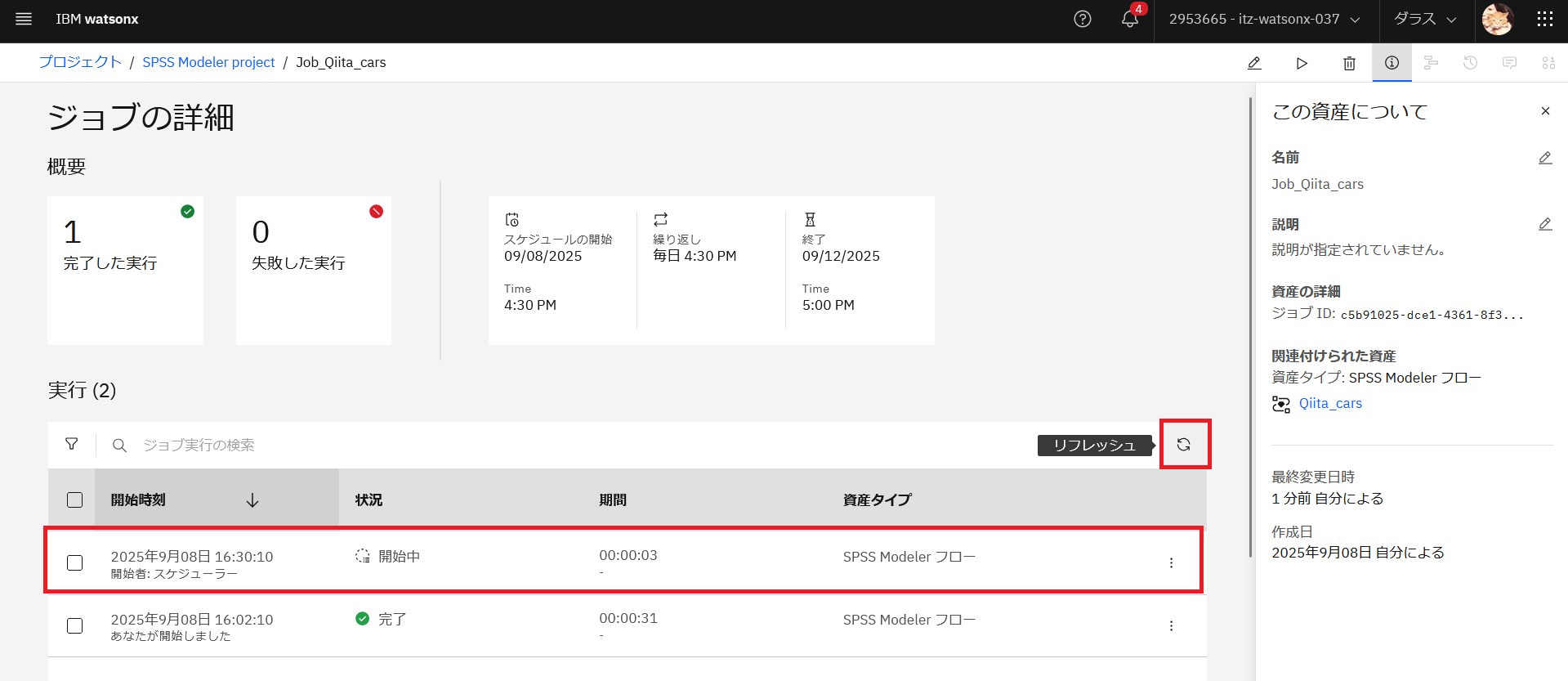
時刻が来たら、「リフレッシュ」をクリックして実行が開始されたか確認します。
ジョブが終了したら、プロジェクトの資産の一覧を表示します。
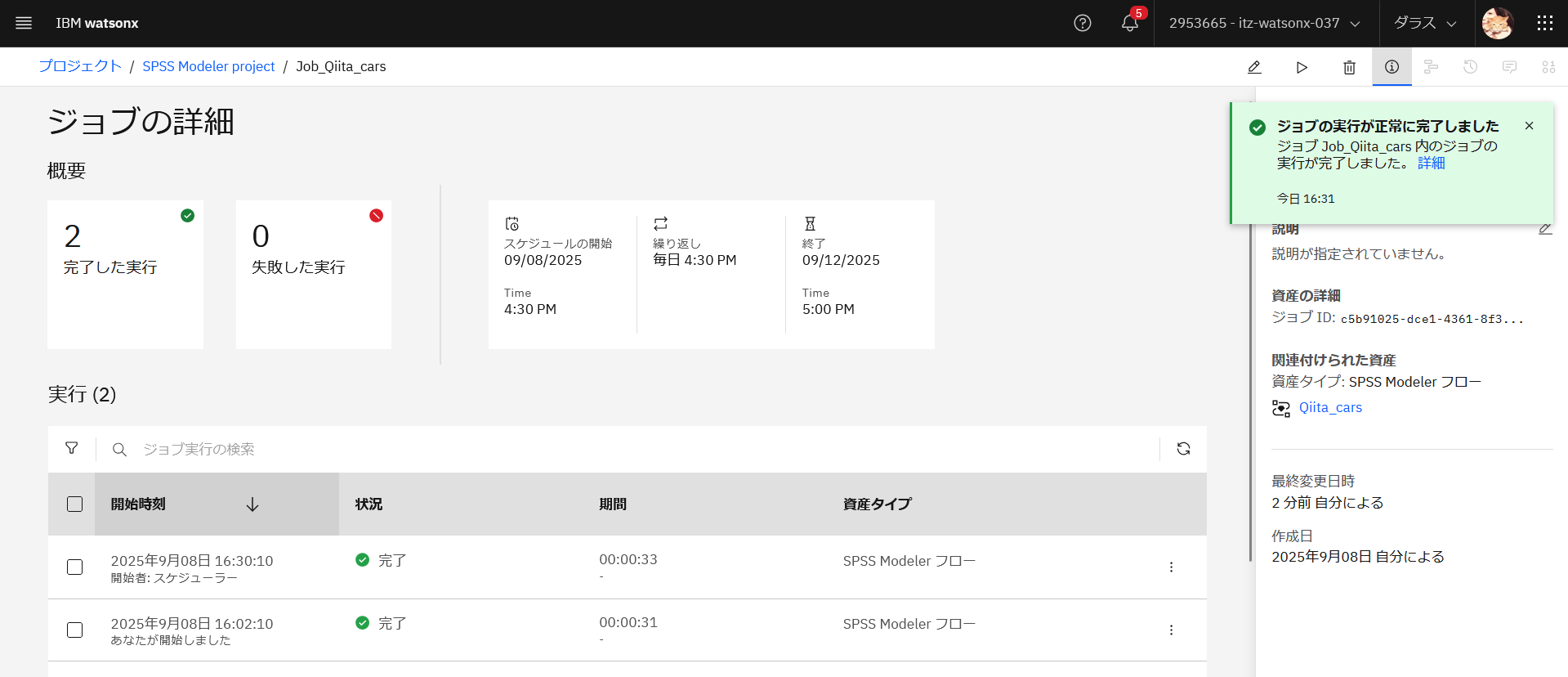
「output.csv」をクリックして中身を確認し、「リフレッシュ」をクリックして表示を最新にします。更新したデータ(cars.csv)を使用して予測した結果の内容がoutput.csvに上書きされているのが確認できました。
以上となります。
次回は、シリーズ⑤SPSS Modelerのモデルをオンラインで呼び出そうで作成したモデルをPythonのコードからオンライン呼び出しする方法をご案内します。