やりたいこと
- ディープラーニングで日経平均を予測したい
- 簡単にディープラーニングを体験したい
方法
- ディープラーニングの手法は、時系列データの取扱に優れたLSTMを使用
- コードが簡単な、TensorFlow + Kerasで実装
環境
Windows 10 64bit
TensorFlow + Keras
環境構築はこちら→ Windowsで簡単にAI開発の環境構築<人工知能を体験したい人向け>
ディープラーニングの実装
日経平均株価のデータ取得
ダウンロードセンターより、日経平均株価のCSVをダウンロード
https://indexes.nikkei.co.jp/nkave/index?type=download
そのままではデータを取り込めなかったので、前処理として下記の処理を行う
- 1行目は、date, close, open, high, low と書き換える
- 最終行の日本語を削除する
ディープラーニングで使用する主なフレームワーク
-
汎用のフレームワーク
- numpy: 行列計算のため
- pandas: データの取り込みのため
- matplotlib: グラフ描写のため
- sklearn.preprocessing: データの前処理のため
-
ディープラーニングのフレームワーク
- keras.models.Sequential: ディープラーニング(深層学習)の各層を積み重ねたモデルを作成するフレームワーク
- keras.layers.core: Coreレイヤーとして、Denseレイヤー、Activationレイヤーをインポートする。Denseレイヤーは、通常の全結合ニューラルネットワークレイヤー。Activationレイヤーは、活性化関数を適用するレイヤー
- keras.layers.recurrent.LSTM: LSTMを適用するレイヤー。
具体的なソースコード
参考文献や、すでにQiitaで公開されている株価予測のコードを参考にして、書いてみる。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
# データ読み込み
df = pd.read_csv("stock_nikkei_180321.csv")
df['date'] = pd.to_datetime(df['date'], format = '%Y-%m-%d')
# データの標準化
df['close'] = preprocessing.scale(df['close'])
df = df.loc[:, ['date', 'close']]
# 訓練、テストデータの作成
maxlen = 10
X, Y = [], []
for i in range(len(df) - maxlen):
X.append(df[['close']].iloc[i:(i+maxlen)].as_matrix())
Y.append(df[['close']].iloc[i+maxlen].as_matrix())
X=np.array(X)
Y=np.array(Y)
# 訓練用のデータと、テスト用のデータに分ける
N_train = int(len(df) * 0.8)
N_test = len(df) - N_train
X_train, X_test, y_train, y_test = \
train_test_split(X, Y, test_size=N_test, shuffle = False)
# 隠れ層の数などを定義: 隠れ層の数が大きいほど精度が上がる?
n_in = 1 # len(X[0][0])
n_out = 1 # len(Y[0])
n_hidden = 300
# モデル作成 (Kerasのフレームワークで簡易に記載できる)
model = Sequential()
model.add(LSTM(n_hidden,
batch_input_shape=(None, maxlen, n_in),
kernel_initializer='random_uniform',
return_sequences=False))
model.add(Dense(n_in, kernel_initializer='random_uniform'))
model.add(Activation("linear"))
opt = Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
model.compile(loss = "mean_squared_error", optimizer=opt)
early_stopping = EarlyStopping(monitor='loss', patience=10, verbose=1)
hist = model.fit(X_train, y_train, batch_size=maxlen, epochs=50,
callbacks=[early_stopping])
# 損失のグラフ化
loss = hist.history['loss']
epochs = len(loss)
plt.rc('font', family='serif')
fig = plt.figure()
fig.patch.set_facecolor('white')
plt.plot(range(epochs), loss, marker='.', label='loss(training data)')
plt.show()
# 予測結果
predicted = model.predict(X_test)
result = pd.DataFrame(predicted)
result.columns = ['predict']
result['actual'] = y_test
result.plot()
plt.show()
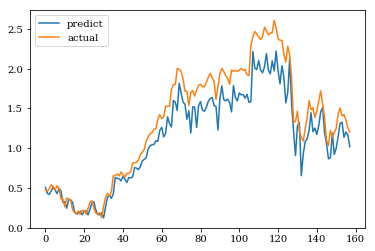
結果
縦軸は標準化された株価です。株価が平均値から外れているとうまく予測できていません。
今後の課題
今回は、うまく予測できていないという結果でしたが、株価予測の結果に影響しそうな下記のパラメータについて、影響を検討したいと思います。
データの前処理の方法
今回は、scikit learnのscaleを使用しましたが、MinMaxScalerなど他の標準化方法で前処理を行うと、予測精度にどう影響するのか検討する必要がありそうです。また、3年分のデータに対して標準化を行うと、3年の平均株価から離れた株価がうまく予測できない傾向がありそうです。このため、単純に全データを標準化するのでなく、移動平均を使って標準化したほうがいいかもしれません。
データの前処理に関して、トレンドと周期性に分けるという、手法もあるようです。
【Day-13】『Prophet入門』簡単に高精度を実現するFacebook謹製の時系列予測ライブラリ
LSTMのモデル
LSTMのモデルは、下記3つの手法によって精度が高くなることが知られていますが、Kerasのモデルには覗き穴結合が含まれていません。このため、精度が低い可能性があります。
- CES・入力ゲート・出力ゲートの導入
- 忘却ゲートの導入
- 覗き穴結合の導入
データ不足
今回は、過去10日間の株価の終値から、翌日の株価を予測しましたが、実際は終値だけでなく、始値、高値、安値も含めたり、他の関連する情報を含めたり、あるいは学習のもとになる期間をもっと長くしたりして、より大きな情報量をあたえることで、予測精度が上がるかもしれません。
補足
コメントで、arutema47様に指摘された通り、このモデルは、X-9日目~X日目の10日間のデータから、X+1日目の株価を予測するモデルです。
X+2日の株価の予測には、X+1日目の実際の株価も含めた10日間のデータ (X-8日目~X+1日目)を使用しているため、全体の傾向は実際の株価と似てしまいます。
