この記事はNIFTY Advent Calendar 2017の24日目の記事です。
昨日は@megane42さんのNeo4j を駆使して格ゲーに勝つという記事でした。
1 はじめに
1.1 モチベーション
普段はネットワークとかインフラ寄りのエンジニアをしているニフティ4年目の@licht110です。
今回は完全に趣味でやっていることの話で、この記事を書いたモチベーションは以下の通りです。
- ブロックチェーンを調べているうちに仮想通貨の取引にハマった
- 機械学習・深層学習を学ぶことによるスキルアップ
仮想通貨で大儲けして遊んで暮らしたいなどとは微塵も思っていませんよ。
※この記事を参考にして行った仮想通貨の取引によって生じた損害またトラブルについては一切の責任を負いかねます。
1.2 この記事で取り扱う内容
- 仮想通貨取引所のAPIを使って価格データを取得する
- kerasとscikitlearnを使って取得した価格データから今後の仮想通貨の価格を予測する
1.3 取り扱わない内容
- LSTMアルゴリズムの詳細な解説
- kerasやscikit-learnの詳しい使い方
参考文献を読んでやってみた結果が中心です。
上記の詳しい説明が欲しい方はこの記事の末尾に参考文献を載せておりますのでそちらをご参照ください。
1.4 実行環境について
- OS X Yosemite バージョン10.10.5
- Python 3.6.1
- scikit-learn (0.19.0)
- Theano (1.0.1)
- Keras (2.1.2)
- poloniex (0.4.6)
pythonに関してはpyenv、 virtualenvを使ってこの記事用の実行環境を作っています。
Kerasはバックエンドの機械学習ライブラリをtheanoかtensorflowを選択でき、今回はtheano(デフォルト)を使っていますが特別な理由はありません。
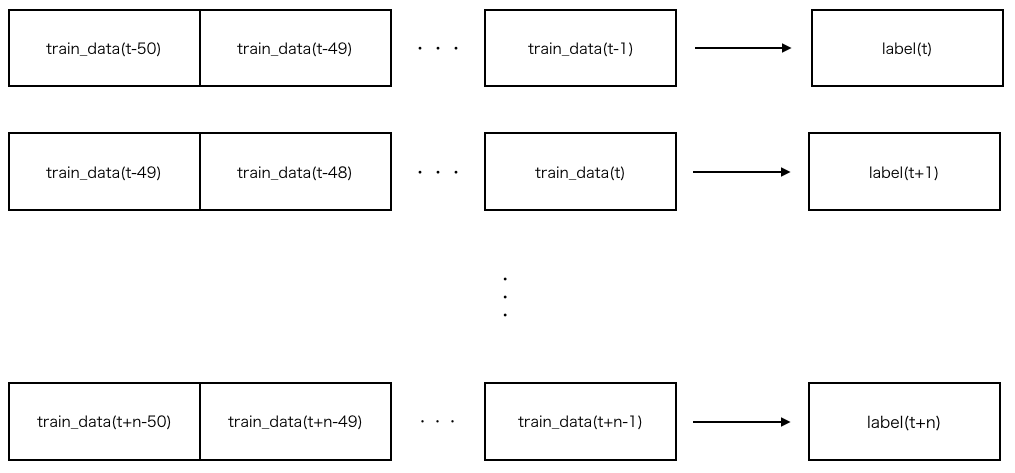
1.5 今回作成するニューラルネットワークの概要
今回は学習データ50ステップ(直前250分の価格データ)からラベルデータを1つ(5分後の価格)学習させます。
図で表すと↓のような感じ。
2 仮想通貨価格データの取得・前処理
2.1 価格データの取得
Poloniexという仮想通貨取引所のAPIを使ってデータを取得できます。
今回は5分間隔のデータを実行時から過去半年(180日)分取得します。
import poloniex
import time
polo = poloniex.Poloniex()
polo.timeout = 2
rawdata = polo.returnChartData('USDT_BTC',
period=300,
start=time.time()-polo.DAY*180,
end=time.time())
- returnChartDataの第一引数で米ドルとBTCのペアを指定しています(他の仮想通貨の組み合わせもできる)。
- periodでデータの取得間隔を指定している、単位は秒。
- 指定できる値は300、900、1800、7200、14400、86400、polo.DAY(1日)
※ソースコード参照
- 指定できる値は300、900、1800、7200、14400、86400、polo.DAY(1日)
- start, endはunixtimeで指定します。
2.1 データの前処理
機械学習においてデータの前処理は予測の精度を左右します。
今回、そのままの価格データを使ってもうまくいかなった(値のスケールが大きかったせい?)ので、ひとまずmin-maxスケーリングをしてみます。
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
price_data = pd.DataFrame([float(i.get('open')) for i in rawdata])
mss = MinMaxScaler()
input_dataframe = pd.DataFrame(mss.fit_transform(price_data))
2.2 訓練データと検証データの分割
上記でスケーリングしたデータを訓練データと検証データに分割します。
今回は前半90%を訓練データ、後半10%を検証データとします。
import numpy as np
def _load_data(data, n_prev=50):
docX, docY = [], []
for i in range(len(data)-n_prev):
docX.append(data.iloc[i:i+n_prev].as_matrix())
docY.append(data.iloc[i+n_prev].as_matrix())
alsX = np.array(docX)
alsY = np.array(docY)
return alsX, alsY
def train_test_split(df, test_size=0.1, n_prev=50):
ntrn = round(len(df) * (1 - test_size))
ntrn = int(ntrn)
X_train, y_train = _load_data(df.iloc[0:ntrn], n_prev)
X_test, y_test = _load_data(df.iloc[ntrn:], n_prev)
return (X_train, y_train), (X_test, y_test)
(X_train, y_train), (X_test, y_test) = train_test_split(input_dataframe)
3 学習の実施
データは準備できました。
実際に学習させてみましょう。
3.1 ニューラルネットワークモデルの作成
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
in_out_neurons = 1
hidden_neurons = 300
length_of_sequences = 50
model = Sequential()
model.add(LSTM(hidden_neurons, batch_input_shape=(None, length_of_sequences, in_out_neurons), return_sequences=False))
model.add(Dense(in_out_neurons))
model.add(Activation("linear"))
model.compile(loss="mean_squared_error", optimizer="adam",)
上記では(None, 50, 1)の入力を300個のLSTM中間層に投げて、それから出力される1個の値を活性化関数にかけて合わせています。
ニューラルネットワークにLSTMを用いていますが、LSTMはRNNの一種で、従来のRNNでは学習できなかった長期依存(long-term dependencies)を学習可能です。時系列データの深層学習について調べる中で用いられているのを見て今回使ってみました。
活性化関数(Activation)は入力信号の総和がどのように活性化するかを決定する役割を持ちます。kerasではlinearの他、ReLU、シグモイドなどが一通り準備されています。
損失関数(loss)は出力と教師データの差異を表現する関数で、その出力は0が理想的な値です。今回用いた平均二乗誤差の他、kerasでは交差エントロピーなど一通り準備されています。
3.2 学習の実施
準備が整いましたので学習を実施してみましょう。
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', mode='auto', patience=0)
history = model.fit(X_train, y_train, batch_size=600, epochs=10, validation_split=0.1, callbacks=[early_stopping])
ここで、収束判定コールバックを使って学習の収束を検知したらその時点で自動的にループが止まるよう設定してあります。
patience=0だとval_lossが一つ前のループのときより大きくなったら止まります。
Train on 41945 samples, validate on 4661 samples
Epoch 1/5
41945/41945 [==============================] - 176s 4ms/step - loss: 0.0014 - val_loss: 1.5268e-04
Epoch 2/10
41945/41945 [==============================] - 170s 4ms/step - loss: 2.5672e-06 - val_loss: 2.1015e-05
Epoch 3/10
41945/41945 [==============================] - 179s 4ms/step - loss: 1.7848e-06 - val_loss: 1.9281e-05
Epoch 4/10
41945/41945 [==============================] - 170s 4ms/step - loss: 1.7653e-06 - val_loss: 1.8596e-05
Epoch 5/10
41945/41945 [==============================] - 170s 4ms/step - loss: 1.7388e-06 - val_loss: 1.6472e-05
...
計算が終わったら結果を見てみましょう。
from matplotlib import pyplot as plt
pred_data = model.predict(X_train)
plt.plot(y_train, label='train')
plt.plot(pred_data, label='pred')
plt.legend(loc='upper left')
plt.show()
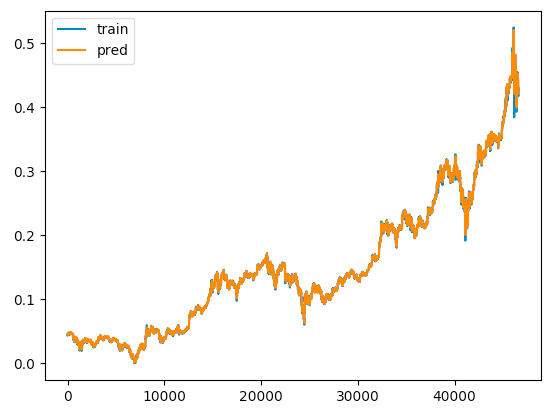
概ね一致してますね!まあこれは訓練データなので。
つぎは検証データで試してみましょう。
pred_data = model.predict(X_test)
plt.plot(y_test, label='test')
plt.plot(pred_data, label='pred')
plt.legend(loc='upper left')
plt.show()
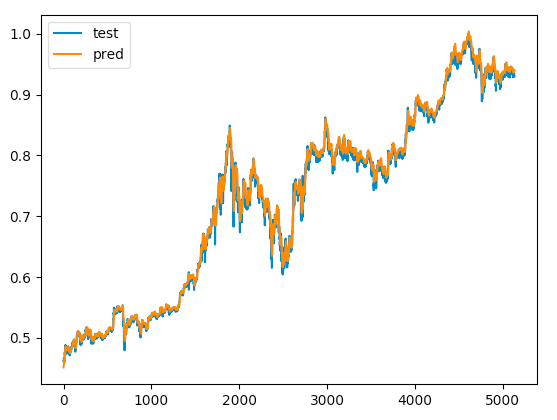
検証データについてもうまく予測できているように見えます。
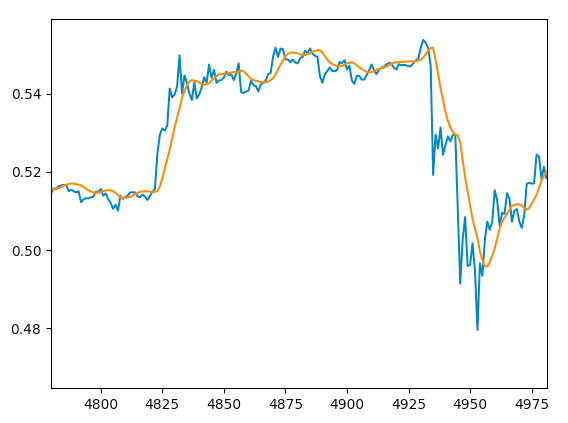
今回のモデルを少し変更すると1日後や1週間後の価格も予測できます。
これで会社を辞めて遊んで暮らすことができますね。ニフティのみなさん、お世話になりました。機会がありましたらまたお会いしましょう(ジョーク(?))。
……とまあ、そうそうおいしい話は世の中には存在せず、一部を拡大して見てみると予測の反映に少し時間遅れがあるように見えます。
実用に際してはもっと改良をしなければいけなさそうですね。
4 課題
- データの前処理はどういったものが最適なのかの議論
- そもそも時系列データを解析をする前に、どんな特性を持っているかといった検定が様々存在するらしい
- 移動平均や差分を使ったほうがいいかも
- 価格データのみではなく他の要素も学習に取り入れる
- 他の仮想通貨の価格(イーサリアムなど)
- 仮想通貨やそれを取り巻く環境のニュース
- (個人的な主観によると)暴騰・暴落は大抵良いニュース、悪いニュースがあったときに起こる
- ニュースサイトから記事を取得してTF-IDFなど用いて感情分析してやるとできるかも
明日は最終日、@nunaさんの記事です。