KerasでGridSearchCVをしてみた
機械学習のモデル精度はパラメータに左右されます。
モデル構築時に活性化関数や最適化アルゴリズム、中間層のユニット数等々、多数のパラメータを設定しますが、その時設定したパラメータが最適なものかは、トレーニングして実用してみるまでわかりません。
しかし機械学習の魅力は自動的に最適なモデルが生成されることです。
であれば、パラメータも自動的に最適化されても良いじゃないか!と思うわけです。
Pythonの機械学習で有名なscikit-learnにはGridsearchcvというモデル選択とパラメータチューニングまで可能なライブラリがあります。
実はKerasはscikit-learnをラッパーしており、GridsearchcvをKerasのモデル構築時に使用することができます。
というわけで、早速KerasのGridsearchcvしてみましょう。
目標
KerasでGridsearchcvを使って最適なモデルを作ります。
データはみんなに大人気のアヤメ(Iris)データを使い、品種分類を行います。
コーディング
さっそく書いていきましょう。
まずは必要なものをインポートします。
Irisデータはsklearnで用意されているものを使います。
import numpy as np
from sklearn import datasets, preprocessing
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.utils import np_utils
from keras import backend as K
from keras.wrappers.scikit_learn import KerasClassifier
Irisデータを7:3でトレーニングとテストに分割します。
iris = datasets.load_iris()
x = preprocessing.scale(iris.data)
y = np_utils.to_categorical(iris.target)
x_tr, x_te, y_tr, y_te = train_test_split(x, y, train_size = 0.7)
num_classes = y_te.shape[1]
関数としてニューラルネットワークモデルを定義します。
ここではレイヤー数を定義し、引数にパラメータをもたせます。
def iris_model(activation="relu", optimizer="adam", out_dim=100):
model = Sequential()
model.add(Dense(out_dim, input_dim=4, activation=activation))
model.add(Dense(out_dim, activation=activation))
model.add(Dense(num_classes, activation="softmax"))
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
各パラメータに選択肢を定義します。
Gridsearchcvではここに定義したパラメータの全パターンを検証します。
activation = ["relu", "sigmoid"]
optimizer = ["adam", "adagrad"]
out_dim = [100, 200]
nb_epoch = [10, 25]
batch_size = [5, 10]
モデル関数とパラメータをGridsearchcvに読み込ませます。
KerasClassifierでモデルを読み、dictにパラメータを設定しています。
GridSearchCVで両者を組み合わせる仕組みです。
model = KerasClassifier(build_fn=iris_model, verbose=0)
param_grid = dict(activation=activation,
optimizer=optimizer,
out_dim=out_dim,
nb_epoch=nb_epoch,
batch_size=batch_size)
grid = GridSearchCV(estimator=model, param_grid=param_grid)
トレーニング開始!
grid_result = grid.fit(x_tr, y_tr)
・・・待つこと30分・・・
・・・Irisデータの分類とは言え、CPUだと時間がかかります。・・・
・・・GPGPUだともっと速くなるのかな?・・・
・・・・・・
・・・
・・・GPUほしい・・・
・・・・・・・・・
・・・・・・
・・・
・・・完了!・・・
結果を出力します。
ベストスコアとそのパラメータです。
print (grid_result.best_score_)
print (grid_result.best_params_)

95%・・・まあまあですね。
それでは最初に残しておいたテストデータでモデルを検証してみましょう。
ちなみにKerasをgridsearchcvしてしまうと、model.evaluateできないようです。
ですのでテストデータの正解と推測値をアナログに比較しています。
grid_eval = grid.predict(x_te)
def y_binary(i):
if i == 0: return [1, 0, 0]
elif i == 1: return [0, 1, 0]
elif i == 2: return [0, 0, 1]
y_eval = np.array([y_binary(i) for i in grid_eval])
accuracy = (y_eval == y_te)
print (np.count_nonzero(accuracy == True) / (accuracy.shape[0] * accuracy.shape[1]))

98%!
だいぶ良い感じです。
モデルはこんな感じになっています。
model = iris_model(activation=grid_result.best_params_['activation'],
optimizer=grid_result.best_params_['optimizer'],
out_dim=grid_result.best_params_['out_dim'])
model.summary()
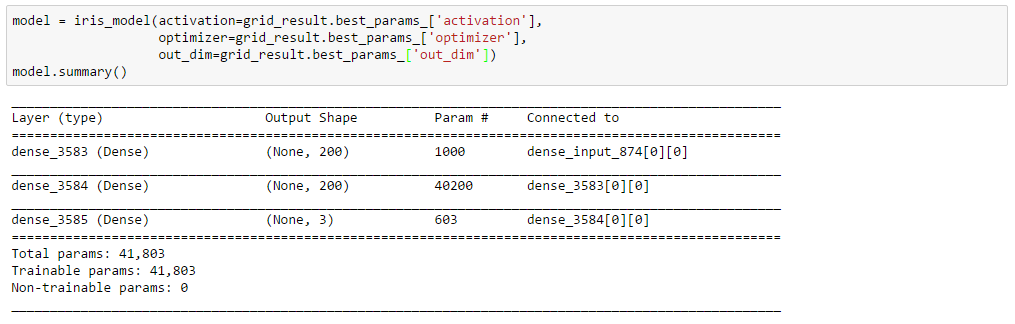
どうでしょう?
Irisデータはいくつか外れ値があるし、頑張ってもあまり100%にならないものです。
トレーニングをパラメータの組み合わせぶん回すので時間はかかりますが、パラメータを手作業で探索するよりは楽ですね。
以下、コード全文です。
import numpy as np
from sklearn import datasets, preprocessing
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.utils import np_utils
from keras import backend as K
from keras.wrappers.scikit_learn import KerasClassifier
# import data and divided it into training and test purposes
iris = datasets.load_iris()
x = preprocessing.scale(iris.data)
y = np_utils.to_categorical(iris.target)
x_tr, x_te, y_tr, y_te = train_test_split(x, y, train_size = 0.7)
num_classes = y_te.shape[1]
# Define model for iris classification
def iris_model(activation="relu", optimizer="adam", out_dim=100):
model = Sequential()
model.add(Dense(out_dim, input_dim=4, activation=activation))
model.add(Dense(out_dim, activation=activation))
model.add(Dense(num_classes, activation="softmax"))
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# Define options for parameters
activation = ["relu", "sigmoid"]
optimizer = ["adam", "adagrad"]
out_dim = [100, 200]
nb_epoch = [10, 25]
batch_size = [5, 10]
# Retrieve model and parameter into GridSearchCV
model = KerasClassifier(build_fn=iris_model, verbose=0)
param_grid = dict(activation=activation,
optimizer=optimizer,
out_dim=out_dim,
nb_epoch=nb_epoch,
batch_size=batch_size)
grid = GridSearchCV(estimator=model, param_grid=param_grid)
# Run grid search
grid_result = grid.fit(x_tr, y_tr)
# Get the best score and the optimized mode
print (grid_result.best_score_)
print (grid_result.best_params_)
# Evaluate the model with test data
grid_eval = grid.predict(x_te)
def y_binary(i):
if i == 0: return [1, 0, 0]
elif i == 1: return [0, 1, 0]
elif i == 2: return [0, 0, 1]
y_eval = np.array([y_binary(i) for i in grid_eval])
accuracy = (y_eval == y_te)
print (np.count_nonzero(accuracy == True) / (accuracy.shape[0] * accuracy.shape[1]))
# Now see the optimized model
model = iris_model(activation=grid_result.best_params_['activation'],
optimizer=grid_result.best_params_['optimizer'],
out_dim=grid_result.best_params_['out_dim'])
model.summary()