はじめに
前回までの記事で画像分類の学習に取り組んできたので、次のステップとして転移学習/ファインチューニングを用いて画像分類に取り組んでみた。今回はKaggleコンペから犬と猫の画像(各25000枚)をもってきて、そのうちの一部(訓練1000, 検証400枚)を使用した(Kaggleへの登録(無料)とAPIトークンのダウンロードが必要)。また、転移させるモデルはVGG16とした。
転移学習
別の分類問題などで既に学習されているモデルをそのまま流用する手法のこと。学習に必要な大量のデータを集めたり、膨大な時間をかけてモデルを学習させる手間を省くことができる。既に学習されている分類モデルは別カテゴリの分類でも有用なことがあり、幅広く応用することができる。逆に、データ間の関連が低く、未知の分野の分類問題などに対しては効果が薄い。そのような場合には、自力でモデルを作成する必要がある。
ファインチューニング
転移学習と同じで既に学習されているモデルを流用するが、自らの持っているデータで学習させて重みやパラメータを微調整する。基本モデルで学習された特徴抽出の機能を引き継ぎつつ、より手元のデータに適合したものへと変えるため、少ないデータ数でも良好な結果を得やすい。
VGG16
ImageNetの120万枚の画像を1000カテゴリに分類した畳み込みニューラルネットワーク
VGG16の構造についてはこちらのブログがとても分かりやすかった。
事前学習済みモデル例(画像認識)
VGG16
VGG19
ResNet-50
Inception V3
XCeption
環境
google colaboratory Pro
Python 3.7.13
Keras 2.8.0
実装
1.ライブラリインポート
必要なライブラリを読み込む。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import os
import math
import urllib.request
import zipfile
from keras.models import Sequential, load_model, Model
from keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense
from keras.layers import Activation, BatchNormalization, Input
from keras.optimizers import adam_v2, sgd_experimental
from keras.utils import np_utils
from keras.callbacks import EarlyStopping
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
from google.colab import files
2.Kaggleからデータをダウンロード
Kaggle APIをインストールする
!pip install kaggle
データを保存するディレクトリを作成する。
# ディレクトリのパス
train_dir = "./dataset/trainData"
valid_dir = "./dataset/validData"
all_data_dir = "./tmp/Data"
source_dir = "./tmp/trainData"
# ディレクトリ下のデータ置き場所
os.makedirs("%s/dogs" %train_dir)
os.makedirs("%s/cats" %train_dir)
os.makedirs("%s/dogs" %valid_dir)
os.makedirs("%s/cats" %valid_dir)
os.makedirs("%s" %all_data_dir)
os.makedirs("%s" %source_dir)
事前にKaggleに登録して、アカウントページでAPIトークン(Kaggle.json)を生成しておく。
①Kaggle.jsonをGoogleドライブ上に置いて、ドライブからcolab上にダウンロードする方法
②Kaggle.jsonをローカルにダウンロードして、ローカルからcolab上にアップロードする方法
の2つがあるが、今回は②で行った。トークン生成と①, ②についてはこちらを参照
# ファイルをアップロード
uploaded = files.upload()
# keyに対する処理
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(name=fn, length=len(uploaded[fn])))
!mkdir -p ~/.kaggle/ && mv kaggle.json ~/.kaggle/ && chmod 600 ~/.kaggle/kaggle.json
データをKaggleからダウンロードして保存、解凍したあと、犬猫それぞれ最初の1000枚を訓練データ、その次の1000枚を検証データにして、それぞれのディレクトリに格納する。
# Kaggle APIでデータをダウンロード
!kaggle competitions download -c dogs-vs-cats-redux-kernels-edition
# コンペデータ(.zip)を解凍
with zipfile.ZipFile("./dogs-vs-cats-redux-kernels-edition.zip", mode="r") as f:
f.extractall("%s" %all_data_dir)
# コンペデータの中のtrainデータを解凍
with zipfile.ZipFile("%s/train.zip" %all_data_dir, mode="r") as f:
f.extractall("%s/" %source_dir)
# 最初の1000枚をtrainDataフォルダに格納
for i in range(1000):
os.rename("%s/train/dog.%d.jpg" %(source_dir, i+1), "%s/dogs/dog%04d.jpg" %(train_dir, i+1))
os.rename("%s/train/cat.%d.jpg" %(source_dir, i+1), "%s/cats/cat%04d.jpg" %(train_dir, i+1))
# 次の1000枚をvalidDataフォルダに格納
for i in range(1000):
os.rename("%s/train/dog.%d.jpg" %(source_dir, 1000+i+1), "%s/dogs/dog%04d.jpg" %(valid_dir, i+1))
os.rename("%s/train/cat.%d.jpg" %(source_dir, 1000+i+1), "%s/cats/cat%04d.jpg" %(valid_dir, i+1))
ディレクトリの構造と中身はこんな感じ。(sample_dataはcolabにデフォルトであるので関係ない)
3.VGG16の構造を確認
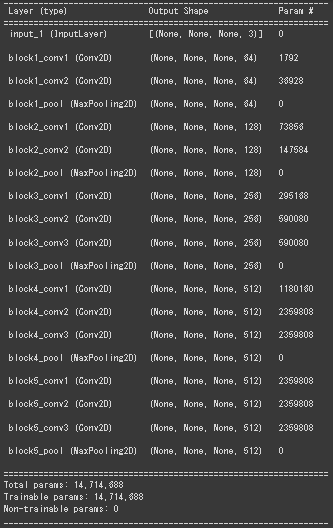
summaryでVGG16の構造を見ておく
まず入力層があり、次に畳み込み層とプーリング層が固まったブロックが1~5まである。全結合層以下は使わないので読み込んでいない。(include_top=False)
model = VGG16(include_top=False, weights="imagenet")
model.summary()
layersで層を出力することもできる。
model_vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=Input(shape=(224,224,3)))
model_vgg16.layers
4.学習用のデータを作成
データセットを生成するジェネレータを作成する。
ImageDataGeneratorはディレクトリを指定するとその中の画像を読み込んでテンソル型のデータセットに変換した画像データを生成してくれる優れもの。同時に画像を色々と拡張して、学習データを増やしている。クラスごとにディレクトリを作っておけばクラスも認識してくれる。パラメータの詳細はKerasのドキュメントを参照。使い方はこのブログがとても分かりやすかった。
num_slass = 2
batch_size = 32
# データ拡張しながら,テンソル画像データのバッチを生成
train_data_generator = ImageDataGenerator(rescale=1.0/255,
rotation_range=45,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=math.pi/4,
zoom_range=0.5,
horizontal_flip=True)
valid_data_generator = ImageDataGenerator(rescale=1.0/255)
# ディレクトリからデータを生成
train_generator = train_data_generator.flow_from_directory(
train_dir,
target_size=(224,224),
batch_size=batch_size,
class_mode="binary",
shuffle=False
)
valid_generator = valid_data_generator.flow_from_directory(
valid_dir,
target_size=(224,224),
batch_size=batch_size,
class_mode="binary",
shuffle=False
)
5.モデルを構築
転移学習で学習させるモデルの中身を作る
VGG16を読み込んで、手元のデータに合った出力をするように作った全結合層と合体させる。入力は(224,224,3)である必要はないが、VGG16の学習がそのshapeでされたそうなので準拠する。
# VGG16をインポート
model_vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=Input(shape=(224,224,3)))
# 全結合層を作成
x = model_vgg16.output
x = Flatten()(x)
x = Dense(256)(x)
x = Activation("relu")(x)
x = Dropout(0.5)(x)
prediction = Dense(1, activation="sigmoid")(x)
# モデル合体
model = Model(inputs=model_vgg16.input, outputs=prediction)
6.転移学習
VGG16を転移させたモデルを学習させる。
VGG16から転移させた部分(18層目まで)は学習させないので、重みの更新をキャンセルしておく。それ以外は普通にkerasを使うのと同じ。学習の設定でoptimizerを設定しようとしてエラーが出たので記事にまとめた。過去のブログや記事を見ると学習部分でfit_generatorが使われているが、今のKerasはfitがgeneratorもサポートしているらしい。
# block5_pool(18層目)までの重みの更新をキャンセル
for layer in model_vgg16.layers[:19]:
layer.trainable=False
# 学習の設定
model.compile(loss="binary_crossentropy",
optimizer=adam_v2.Adam(learning_rate=0.001),
metrics=["accuracy"])
# 学習
history = model.fit(train_generator,
epochs=50,
verbose=1,
validation_data=valid_generator,
callbacks=[EarlyStopping(patience=10)])
# モデル保存
model.save("./CNN_VGG16.h5")
7.学習経過の確認
historyを使って学習経過を描画する。
# lossとaccuracyを可視化
print("-"*100)
plt.figure(1, figsize=(13,4))
plt.subplots_adjust(wspace=0.5)
# 学習曲線
plt.subplot(1, 2, 1)
plt.plot(history.history["loss"], label="train")
plt.plot(history.history["val_loss"], label="valid")
plt.title("train and valid loss")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.grid()
# 精度表示
plt.subplot(1, 2, 2)
plt.plot(history.history["accuracy"], label="train")
plt.plot(history.history["val_accuracy"], label="valid")
plt.title("train and valid accuracy")
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.legend()
plt.grid()
plt.show()
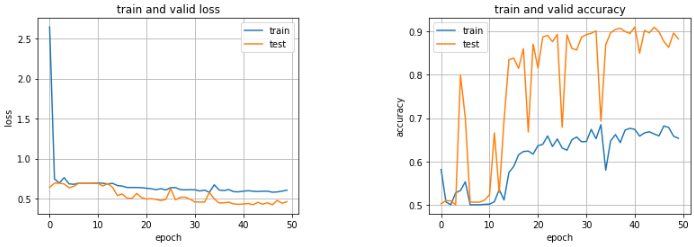
validデータの正解率が90%近くまで達している。trainデータとvalidデータ各1000枚ずつで過学習せず、この精度が出ているのはすごい。
8.ファインチューニング
次に、ファインチューニングを行う。
ファインチューニングでは、全結合層に加えてVGG16のblock5の畳み込み層の重みも更新していく。畳込みニューラルネットでは浅い層ほどエッジやブロブなど汎用的な特徴が抽出されているのに対し、深い層ほど学習データに特化した特徴が抽出される傾向がある。そこで、浅い層の汎用的なフィルターはそのまま、深い層の重みのみ今回用意したデータに合うように再調整する。
層の更新をキャンセルしていた部分と学習の設定以外は転移学習とほぼ同じで、重み更新のキャンセルを18→14層目までに変えればよい。学習が進まなくなるのでAdamの学習率を一桁下げるか、SDGに変更する。
# 浅い層の重みはそのまま使いたいので、block4_pool(14層目)までの重みの更新をキャンセル
for layer in model_vgg16.layers[:15]:
layer.trainable=False
# 学習の設定
model.compile(loss="binary_crossentropy",
optimizer=adam_v2.Adam(learning_rate=0.0001),
metrics=["accuracy"])
# model.compile(loss="binary_crossentropy",
# optimizer=sgd_experimental.SGD(learning_rate=0.001, momentum=0.9),
# metrics=["accuracy"])
正解率が97%まで達しており、非常に高い精度が得られた。VGG16の深い層の重みを更新することで、用意した犬猫の画像データにより適したモデルになっていることが分かる。
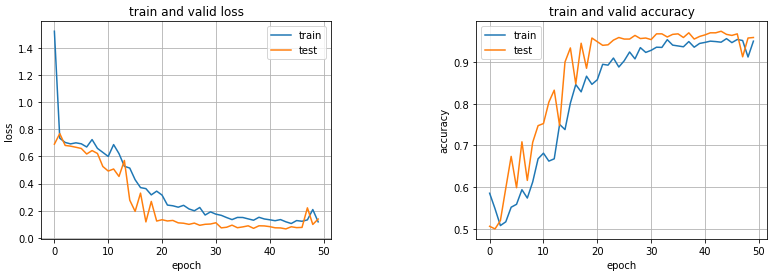
おわりに
VGG16を転移させた転移学習とファインチューニングをやってみて、少ない画像データでもここまでの結果が出るVGG16はやはりすごいなぁとなった。これだけ強力な学習済みのモデルがあるのはとても便利。しかも1000クラス分類できる。また時間があるときにデータ数もっと落としたらどうなるかや1000クラスにない物体の分類はどうなるか、PyTorchで実装、他の学習済みモデル使用とかもやれたらやりたいと思います。
参考
転移学習とファインチューニング
転移学習とは?ファインチューニングとの違いや活用例をご紹介
転移学習とは | メリット・デメリット・ファインチューニングの意味
Keras / Tensorflowで転移学習を行う
ColabにKaggleのデータをダウンロードする
【Google Colab対応】kaggle-apiの使い方|データの読み込みから提出まで
Kaggle:Dogs vs. Cats Redux: Kernels Edition
KerasでVGG16を使う
VGG16のFine-tuningによる犬猫認識 (1)
VGG16のFine-tuningによる犬猫認識 (2)
KerasでVGG16のファインチューニングを試してみる
VGG16を転移学習させて「まどか☆マギカ」のキャラを見分ける
Kerasによるデータ拡張