背景・目的
- 以前、「VPC内のLambdaからインターネットに接続する」と「DynamoDBを試してみた」で作成したLambdaとDynamoDB(以降、DDBという。)を使用してQiitaの記事一覧を取得し、その内容をDDBに登録する。
内容
前提
DynamoDBテーブル
- DDBのテーブル名は「qiita_user_articles」、各項目は以下の通りとする。
| 項目名 | キー/インデックス | タイプ | 例 |
|---|---|---|---|
| user_id | パーティションキー | 文字列 | test |
| article_id | ソートキー | 文字列 | 00001 |
| title | グローバルセカンダリーインデックス | 文字列 | test title |
| url | 文字列 | https://qiita.com/Qiita/items/c686397e4a0f4f11683d | |
| page_views_count | 数値 | 100 | |
| likes_count | 数値 | 100 | |
| reactions_count | 数値 | 100 | |
| comments_count | 数値 | 100 | |
| created_at | 文字列 | 2000-01-01T00:00:00+00:00 | |
| updated_at | 文字列 | 2000-01-01T00:00:00+00:00 |
開発環境の準備
- 「JupyterLabはじめの一歩」で作成した、Cloud9上のJupyterLabを使用する。
boto3のインストール
- 早速だが、Cloud9にboto3がインストールされていないようなのでインストールする。(以下は、ModuleNotFoundErrorになっている。)
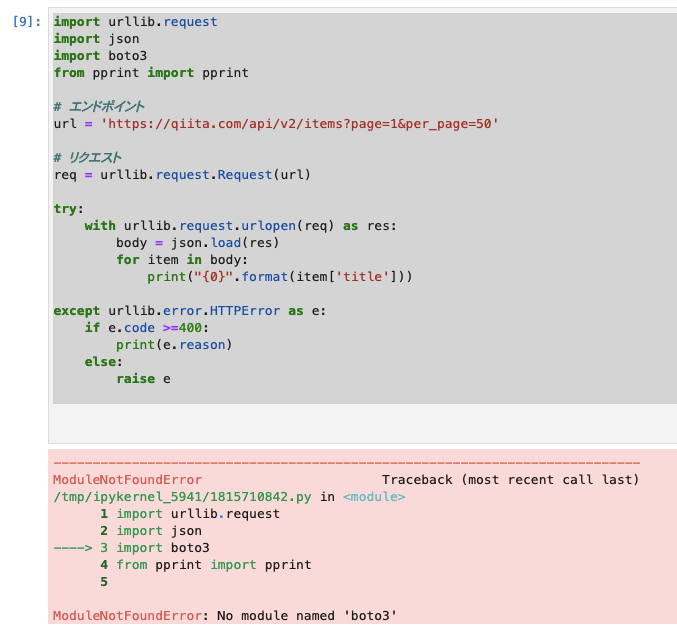
1.あらためてboto3が入っているか確認。やはり無い。
$ pip freeze | grep boto3
$
2.boto3をインスール
$ pip install boto3
Defaulting to user installation because normal site-packages is not writeable
Collecting boto3
Downloading boto3-1.21.32-py3-none-any.whl (132 kB)
|████████████████████████████████| 132 kB 24.5 MB/s
Collecting s3transfer<0.6.0,>=0.5.0
Downloading s3transfer-0.5.2-py3-none-any.whl (79 kB)
|████████████████████████████████| 79 kB 18.1 MB/s
Requirement already satisfied: jmespath<2.0.0,>=0.7.1 in /usr/local/lib/python3.7/site-packages (from boto3) (1.0.0)
Collecting botocore<1.25.0,>=1.24.32
Downloading botocore-1.24.32-py3-none-any.whl (8.6 MB)
|████████████████████████████████| 8.6 MB 57.7 MB/s
Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in /usr/local/lib/python3.7/site-packages (from botocore<1.25.0,>=1.24.32->boto3) (2.8.2)
Requirement already satisfied: urllib3<1.27,>=1.25.4 in /usr/local/lib/python3.7/site-packages (from botocore<1.25.0,>=1.24.32->boto3) (1.26.9)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/site-packages (from python-dateutil<3.0.0,>=2.1->botocore<1.25.0,>=1.24.32->boto3) (1.16.0)
Installing collected packages: botocore, s3transfer, boto3
Successfully installed boto3-1.21.32 botocore-1.24.32 s3transfer-0.5.2
$
3.インストール後にあらためて確認する。
$ pip freeze | grep boto3
boto3==1.21.32
$
4.JupyterLabであらためて確認する。
- エラーが消えて取得できた。これで環境が整った。

DynamoDB操作のためにポリシーをアタッチ
-
Cloud9が利用しているEC2のIAMロールのポリシーにDynamoDBFullAccessポリシーをアタッチする。
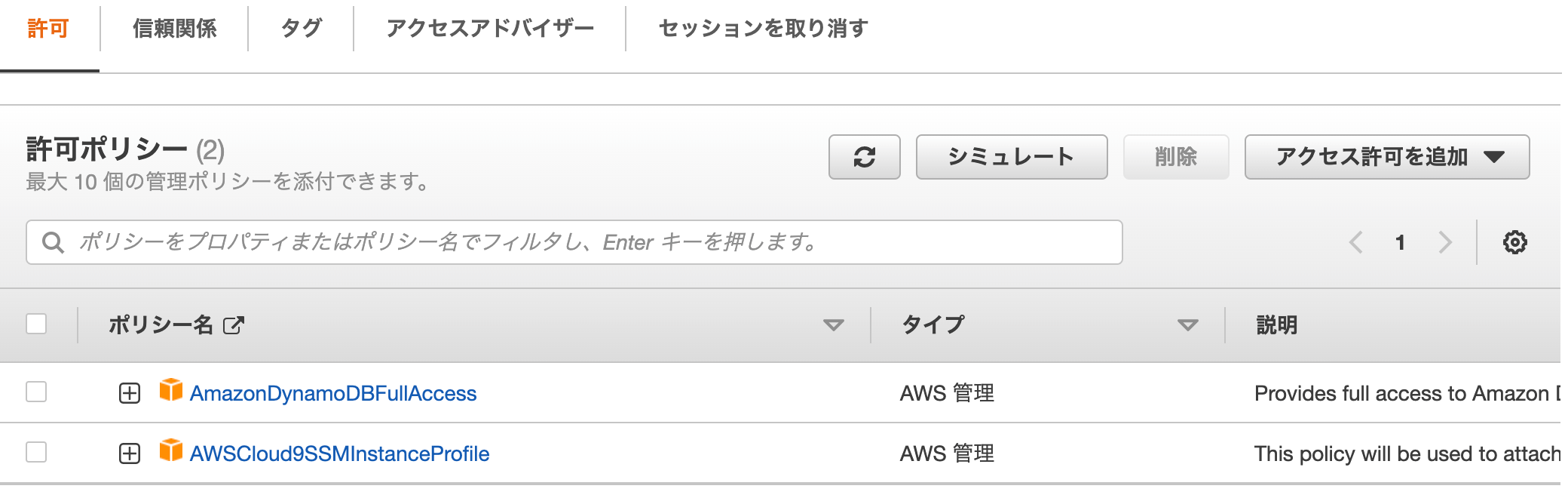
-
同様に、Lambdaのロールにもアタッチしておく。
AMTCを無効化
- AMTCとは、「AWS Managed Temporary Credentials」のこと。詳細はクラスメソッドさんのブログに詳しく書かれている。
- Cloud9ではデフォルトで、AMTCが有効化されているのでこれを無効化する。(出典:クラスメソッドさんのブログ。)
1.Cloud9のPreferencesをクリック。
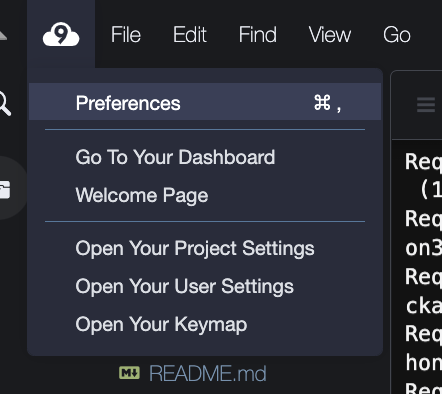
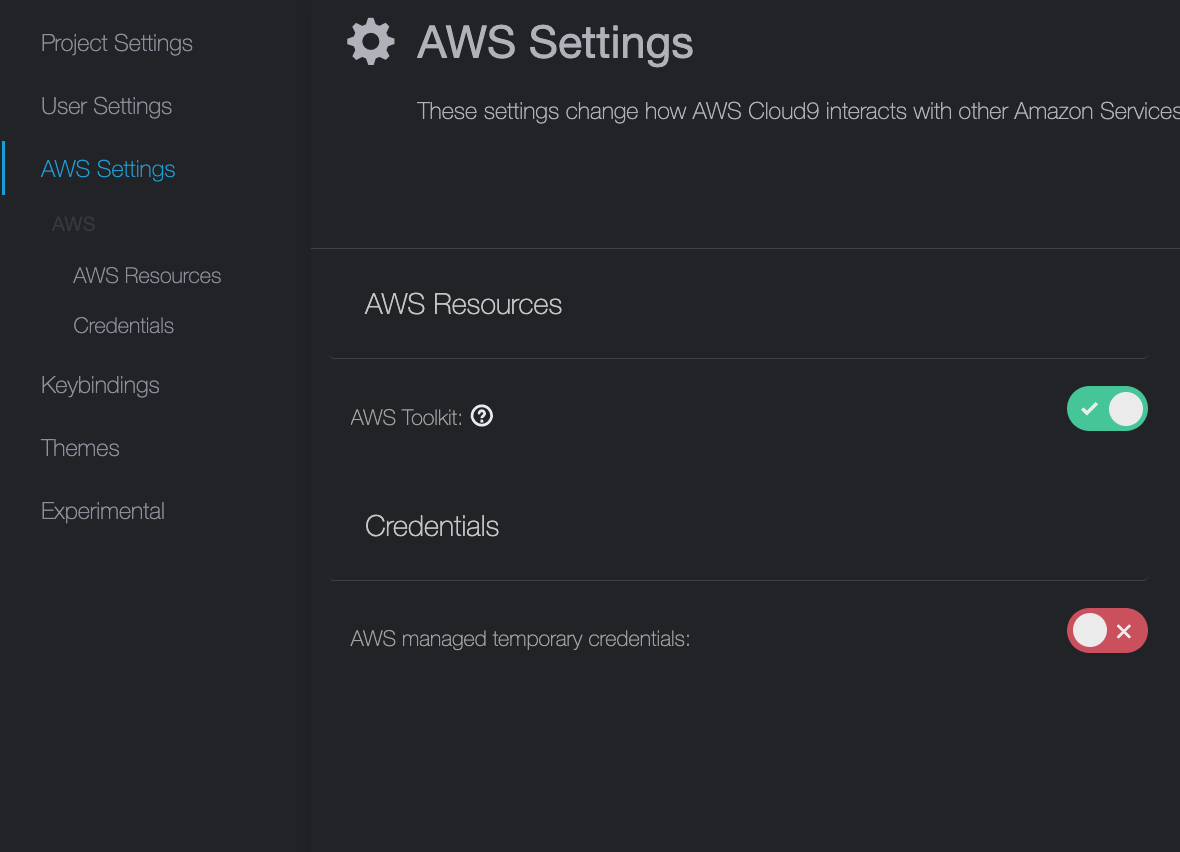
2.AWS Setting>CredentialsのAWS resource temporary credentialsをdisableに変更。
DynamoDBと疎通
- 取得できました。
$ aws dynamodb list-tables --region ap-northeast-1
{
"TableNames": [
"qiita_user_articles"
]
}
$
実践
修正前のコード
修正前のコード
import urllib.request
import json
import boto3
from pprint import pprint
# エンドポイント
url = 'https://qiita.com/api/v2/items?page=1&per_page=50'
# リクエスト
req = urllib.request.Request(url)
try:
with urllib.request.urlopen(req) as res:
body = json.load(res)
for item in body:
print("{0}".format(item['title']))
except urllib.error.HTTPError as e:
if e.code >=400:
print(e.reason)
else:
raise e
修正後のコード(Cloud9)
import urllib.request
import json
import boto3
from pprint import pprint
def get_table():
dynamodb = boto3.resource("dynamodb")
return dynamodb.Table('qiita_user_articles')
def put_item(ddb_table,item_json):
return ddb_table.put_item(Item=item_json)
# エンドポイント
url = 'https://qiita.com/api/v2/items?page=1&per_page=10'
# リクエスト
req = urllib.request.Request(url)
try:
ddb_table = get_table()
with urllib.request.urlopen(req) as res:
body = json.load(res)
for item in body:
print("{0}".format(item['title']))
item_json={
'user_id': item['user']['id'],
'article_id': item['id'],
'title': item['title'],
'url': item['url'],
'page_views_count': item['page_views_count'],
'likes_count': item['likes_count'],
'reactions_count': item['reactions_count'],
'comments_count': item['comments_count'],
'created_at': item['created_at'],
'updated_at': item['updated_at']
}
response = put_item(ddb_table,item_json)
pprint(response)
except urllib.error.HTTPError as e:
if e.code >=400:
print(e.reason)
else:
raise e
- Lambdaで実行する際には、lambda_handler関数を書く
lambda版
import urllib.request
import json
import boto3
from pprint import pprint
def get_table():
dynamodb = boto3.resource("dynamodb")
return dynamodb.Table('qiita_user_articles')
def put_item(ddb_table,item_json):
return ddb_table.put_item(Item=item_json)
# エンドポイント
url = 'https://qiita.com/api/v2/items?page=1&per_page=10'
def lambda_handler(event, context):
# リクエスト
req = urllib.request.Request(url)
try:
ddb_table = get_table()
with urllib.request.urlopen(req) as res:
body = json.load(res)
for item in body:
print("{0}".format(item['title']))
item_json={
'user_id': item['user']['id'],
'article_id': item['id'],
'title': item['title'],
'url': item['url'],
'page_views_count': item['page_views_count'],
'likes_count': item['likes_count'],
'reactions_count': item['reactions_count'],
'comments_count': item['comments_count'],
'created_at': item['created_at'],
'updated_at': item['updated_at']
}
response = put_item(ddb_table,item_json)
pprint(response)
except urllib.error.HTTPError as e:
if e.code >=400:
print(e.reason)
else:
raise e
JypyterLab(Cloud9)実行結果
- 200で返ってきた。(キャプチャなし)
- DDBのテーブルを雑に確認したところ、データは入っている。(11件)
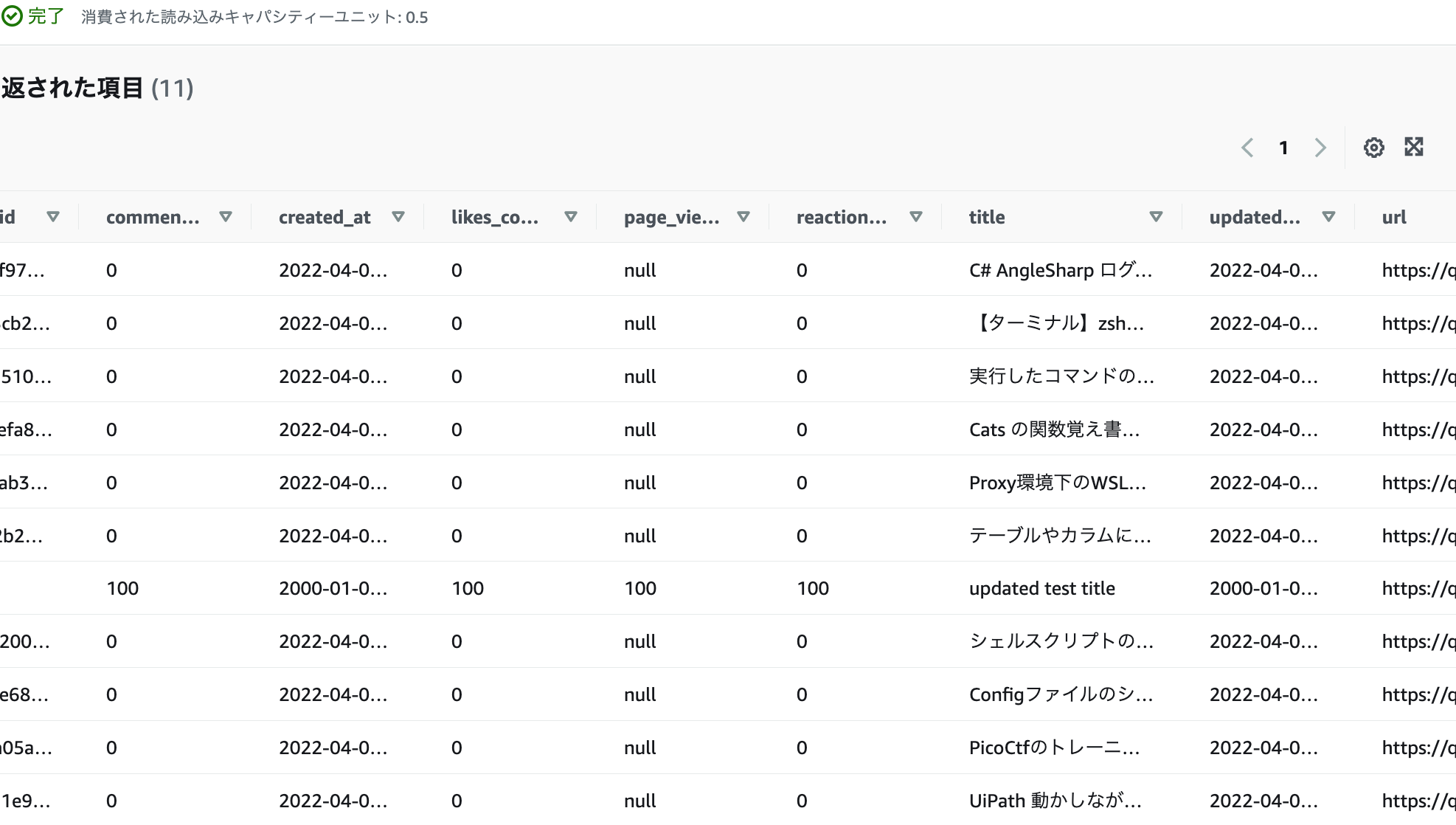
Lambdaの実行結果
- 200で返ってきた。(キャプチャなし)
- DDBのテーブルを雑に確認したところ、データは入っている。(20件)
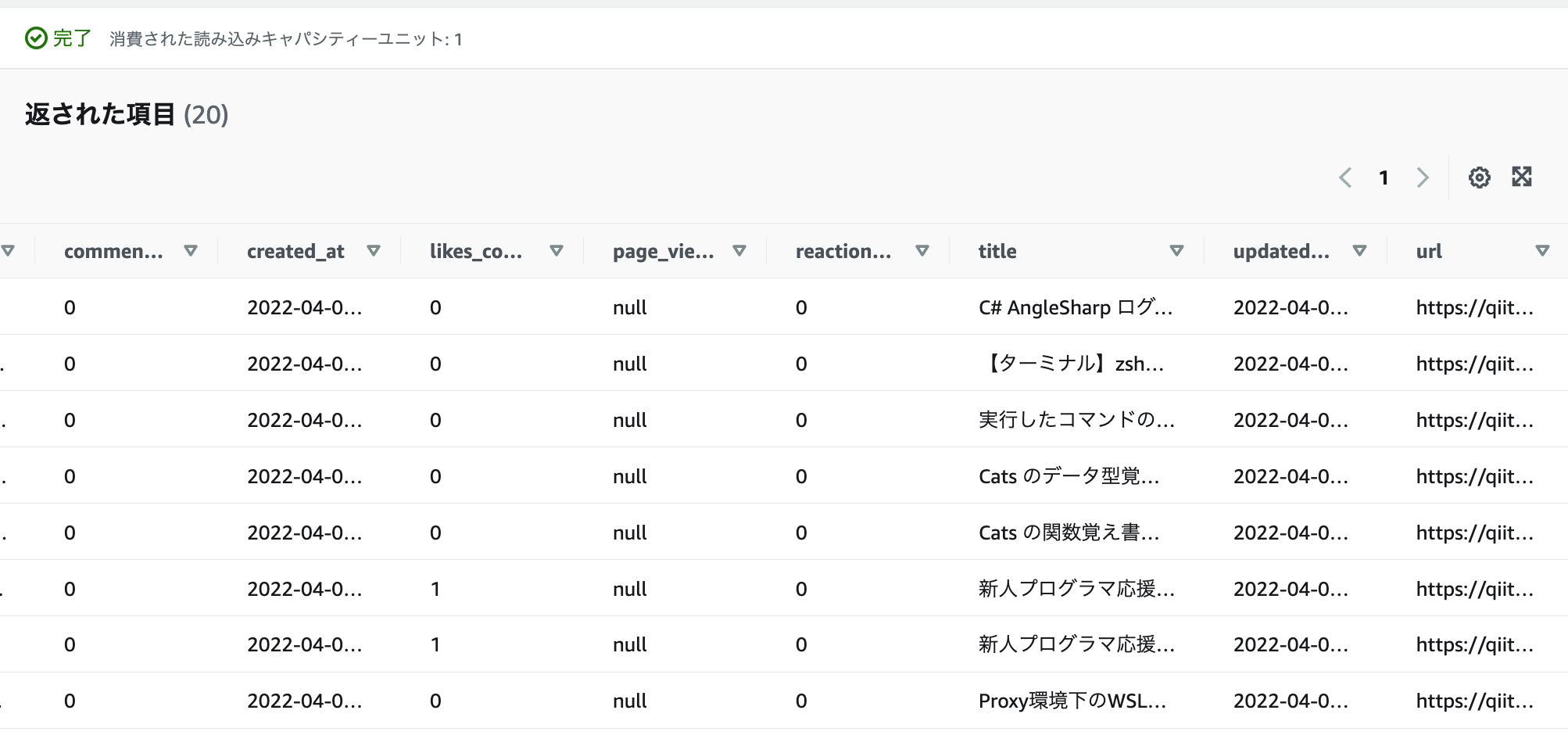
考察
- AMTCを完全に理解できてないので、後日確認する。
参考