更新しながら投稿いたしますのでご容赦ください
前回の記事
【超初心者向け】kaggleのはじめかた part1
https://qiita.com/mozi/items/f2f42a96bfdc235a60aa
前回はkaggleのチュートリアルの存在と、kernelを利用することでpythonの環境構築に煩わされることなく始められることをお伝えしました。今回は実際にチュートリアルのLevel 1をやってみたいと思います。
Level 1 の全体を見てみる
Level 1は全部で8つの記事から構成されています。どれも英語で書かれていますが、10分かからずに終わる内容なので、サクサク進めることができるかと思います。
https://www.kaggle.com/learn/machine-learning
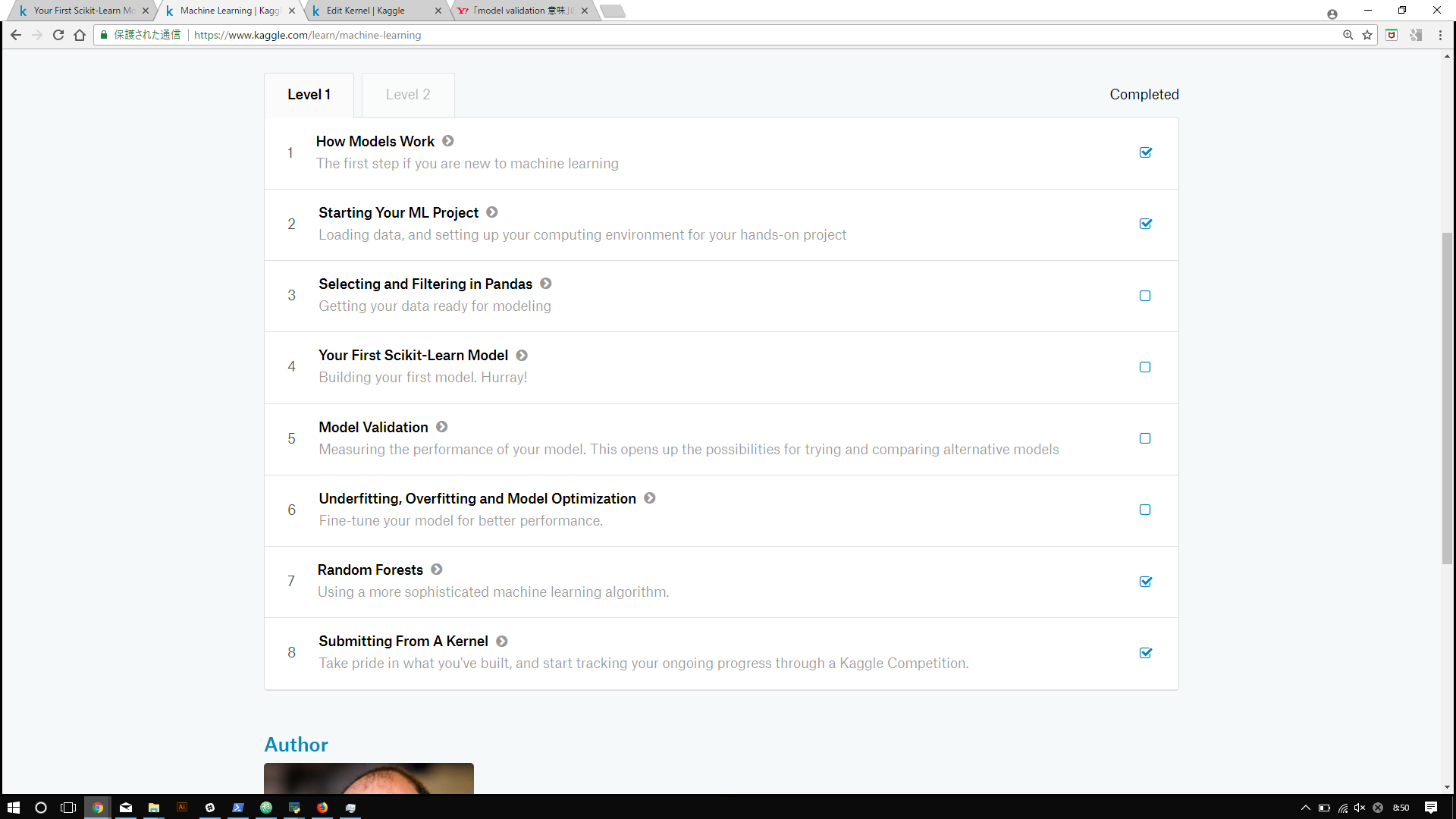
こんな感じですね。
それぞれ、
-
How Models Work
-
Starting Your ML Project
-
Selecting and Filtering in Pandas
-
Your First Scikit-Learn Model
-
Model Validation
-
Underfitting, Overfitting and Model Optimization
-
Random Forests
-
Submitting From A Kernel
-
機械学習って何よ、どう使われるのよ
-
機械学習を始める準備(kernel?, pandasを使ったデータの取り扱い)
-
データの取り扱い(どのcolumnを使うか、それらをどう表示するか)
-
予測対象(y)と予測因子(x)の定義, 機械学習モデルの構築
-
実際そのモデルがどれだけ妥当なのかを検証する
-
じゃあ違うモデルでもやってみようよ
-
決定木⇒ランダムフォレスト
-
結果をkaggleへどうやってアップロードするか
では、順番に見ていきます
1. 機械学習って何よ、どう使われるのよ
ここでは決定木というモデルを引き合いに出して、”機械学習って何?”ということについて説明しています。kaggleを始めようとしている方々であれば、なんとなくふーんぐらいの気持ちで読んでいただいてよいかと思います。
決定木について詳しく知りたい方はこちら
[入門]初心者の初心者による初心者のための決定木分析
2. 機械学習を始める準備(kernel?, pandasを使ったデータの取り扱い
やっとコードが書けます
みなさんはjupyter notebookなどを使用していらっしゃるかと思いますが、今回はせっかくなのでkaggle備えつけのkaggle notebookを使用してやっていきたいと思います(jupyetrやcolaboratoryと使用感は同じです。
3. データの取り扱い(どのcolumnを使うか、それらをどう表示するか)
ここでやっとコーディングが始まります。
①データを仕入れる
import pandas as pd
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
print(melbourne_data.columns)
pandas...pythonでよく使われるライブラリで、データ解析に特化しています。
2行目で、melbourne_file_pathという変数に今回使用したいデータ(csv形式)のpath(csvファイルの所在地)を与えてあげることで扱いやすくしてあげます。
3行目でmelbourne_dataという変数に先ほどのデータセットを格納してあげています。
4行目でしっかり格納されているのか、columns(属性、ラベル)を表示させています。
②一つのcolumnを指定して取り出すこともできますよ
melbourne_price_data = melbourne_data.Price
print(melbourne_price_data.head())
先ほどはmelbourne_dataに格納しただけでしたが、今回はmelboune_price_dataにmelbourne_data.Priceを格納しています。(全体のデータ.取り出したいデータ)のように"."を使ってあげることでさらに詳しくデータを指定できます。
2行目は確認用のprintです。
③2つ以上のcolumnsを指定して取り出すこともできますよ
columns_of_interest = ['Landsize', 'BuildingArea']
two_columns_of_data = melbourne_data[columns_of_interest]
④表示してみましょう
two_columns_of_data.describe()
4. 予測対象(y)と予測因子(x)の定義, 機械学習モデルの構築
- でいい感じにデータが取り扱えることが分かったので、早速機械学習モデルを構築して実行してみましょう!
4.1. 予測したいデータを決めてあげる
y = melbourne_data.Price
今回は回帰(予測)をしたいので、データセットの中で予測したいデータを決定してあげます。今回はPriceを予測するので、yに格納してあげました。
4.2. 予測に使うデータを決めてあげる
melbourne_predictors = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
先ほど予測したいyを決めてあげたので、y=f(x)に当たるような変数xを決めてあげる必要があります。今回は、部屋の数、バスルーム、敷地面積、緯度、経度を予測因子として採用して、melbourne_predictorsに格納してあげました。
4.3. Xに格納
X = melbourne_data[melbourne_predictors]
4.4. 先ほど定義したyとXを使って機械学習モデルを構築する
from sklearn.tree import DecisionTreeRegressor
# Define model
melbourne_model = DecisionTreeRegressor()
# Fit model
melbourne_model.fit(X, y)
1行目で、sklearnという機械学習ライブラリから、DecisionTreeRegressorというモデルをインポートしてあげています。
2行目、このままだと長いので、melbourne_modelという名前に面倒くさいですが変更してあげて
3行目で、fit、つまり学習させています。fit(予測因子、予測対象)ですね。
4.5. 学習結果を表示
print("Making predictions for the following 5 houses:")
print(X.head())
print("The predictions are")
print(melbourne_model.predict(X.head()))
2行目はhead()、つまり先頭の5行ほどを取り出して表示していて
4行目では4.4. で学習させたmelbourne_data.fit(X, y)から、予測値(X.head()の範囲内で)を取り出して表示しています。
学習と出力の結果はこのような形であっけなく終わりますが、ここからが大切です。
5. 実際そのモデルがどれだけ妥当なのかを検証する
- までで確かにそれっぽい値は出るには出るんですが、
「本当にその予測はあってるの?」とか「ほかの方法でもいいのがあるんじゃないの?」
という当たり前の質問に答えるため、モデルがどれだけ妥当か定量的に説明してあげる必要があります。
from sklearn.metrics import mean_absolute_error
predicted_home_prices = melbourne_model.predict(X)
mean_absolute_error(y, predicted_home_prices)
そこで、sklearnからmean_absolute_error(MAE:平均絶対誤差)という関数をインポートしてあげます。予測値、.predict(X)をあらためてpredicted_home_pricesに格納してあげて、mean_absolute_error(実際の値、予測値)を計算させてあげることで、モデルがどれだけ妥当かを評価してあげるのです。
次に、学習させるデータをtrainデータとvalidationデータにランダム分割します。これは、機械学習モデルを訓練させる際に、訓練データにのみ過剰に適応してしまう"過学習"を未然に防ぐためです。
from sklearn.model_selection import train_test_split
# 訓練データと検証データに分ける
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)
# モデルを定義
melbourne_model = DecisionTreeRegressor()
# モデルを学習
melbourne_model.fit(train_X, train_y)
# MAEを計算
val_predictions = melbourne_model.predict(val_X)
print(mean_absolute_error(val_y, val_predictions))
ここで、「なぜtest dataがないの?」と感じる方がいらっしゃるかもしれません。validation data と test dataを区別しているのは、validationがあくまで与えられたデータを分割して生み出したもので全く新しいデータで対応するかは別々に評価してあげる必要があるからだと考えられます。
6. じゃあ違うモデルでもやってみようよ
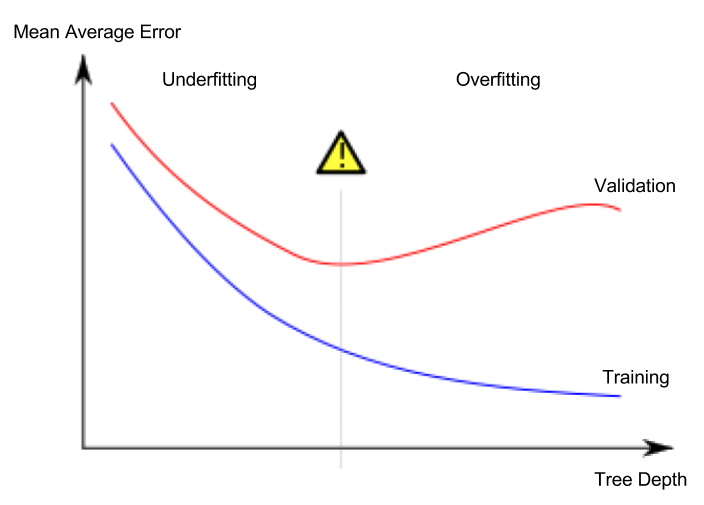
違うモデルというか、今回は決定木の深さ(=分類の細かさ)を調整しているだけなのですが、それでも上図のような違いが起こります。決定木を深くしていけば深くしていくほどtrainデータに対するerrorは減少(=精度が向上)していますが、ある点を境にvalidationデータに対するerrorが上昇しているのが分かるかと思います。この場合、汎化性能(未知のデータに対する適応力)は真ん中あたりでもっとも優れているのです。
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, predictors_train, predictors_val, targ_train, targ_val):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(predictors_train, targ_train)
preds_val = model.predict(predictors_val)
mae = mean_absolute_error(targ_val, preds_val)
return(mae)
これから実験をしてみたいので、def get_maeで学習と結果のプロセスをまとめこれからは重要なパラメータを代入することで結果を出してくれるこの関数を使用していきます。ではそれぞれの深さ(=決定木の葉の数)でMAEがどうなっているのかを確認してみましょう。
# compare MAE with differing values of max_leaf_nodes
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
このコードを実行すると5, 50, 500, 5000それぞれの深さにおけるMAEが表示されます。
たしかに、500が最も低いerror値となっているのが分かりますね。
7. 決定木⇒ランダムフォレスト
機械学習モデルの構築と検証の流れはある程度つかめたかと思いますので、次は他のモデルを使用してみます。
決定木と似ている、ランダムフォレストというモデルを今回は使用しています。
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# モデルの定義
forest_model = RandomForestRegressor()
# モデルの訓練
forest_model.fit(train_X, train_y)
# 出力結果
melb_preds = forest_model.predict(val_X)
# 出力結果の表示
print(mean_absolute_error(val_y, melb_preds))
このように他のモデルでも使えることが分かりましたね。
8. 結果をkaggleへどうやってアップロードするか
ここではチュートリアルにおけるアップロード方法が説明されています。
まず、一通りのコードを掲載します。
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
# Read the data
train = pd.read_csv('../input/train.csv')
# pull data into target (y) and predictors (X)
train_y = train.SalePrice
predictor_cols = ['LotArea', 'OverallQual', 'YearBuilt', 'TotRmsAbvGrd']
# Create training predictors data
train_X = train[predictor_cols]
my_model = RandomForestRegressor()
my_model.fit(train_X, train_y)
こんどはテストデータを入手して、いよいよテスト本番です
# テストデータの読み込み
test = pd.read_csv('../input/test.csv')
# 訓練データと同じように扱っていきます
test_X = test[predictor_cols]
# 予測値を生成します。
predicted_prices = my_model.predict(test_X)
# 確認
print(predicted_prices)
データを提出用のcsvファイルにまとめます
my_submission = pd.DataFrame({'Id': test.Id, 'SalePrice': predicted_prices})
# 名前は何でもいいですよ~
my_submission.to_csv('submission.csv', index=False)
最後に、右上のcommit&runを押して(重要)、左上の<<を押して出てきたページのOutputタブをクリックして、submit to competitionをクリックして終了です。
お疲れさまでした ^^) _旦~~