0 前章
0.1 概要
聞くところによると業務の8割がソースコードを読む時間らしい。しかし、8割という規模感の割には世間でソースコードの読み方についての議論が活発にされている印象はない上に、体系的かつ順序立てたソースコードの読み方をまとめたWebサイトや書籍も少ない。疑問に思いながらもそれなりに長いことデバッガーを使った読み方・リーダブルコードの内容・Web記事を参照にしてソースコードを読んでいた。
しかし、ソースコードリーディングの方法についての情報がメモアプリ内で散らかってしまい、いつまで経ってもソースコードリーディングの技術が体系的に身についていないと感じた。そのため、本稿では本・Web記事・YouTubeなど媒体を問わず、様々な文献からソースコードを効率的に読む方法をチートシートにしてまとめた。チートシートにする目的は「見返して反復し長期記憶化しやすいようにするため」と「ソースコードリーディングについての知識を体系的にまとめ、情報を一元化することで情報の取り出しを容易にするため」である。また、本稿で想定している言語は私に馴染みのあるRubyとする。
0.2 コードリーディングにおける階層
コードリーディングには以下の階層があるとのこと。
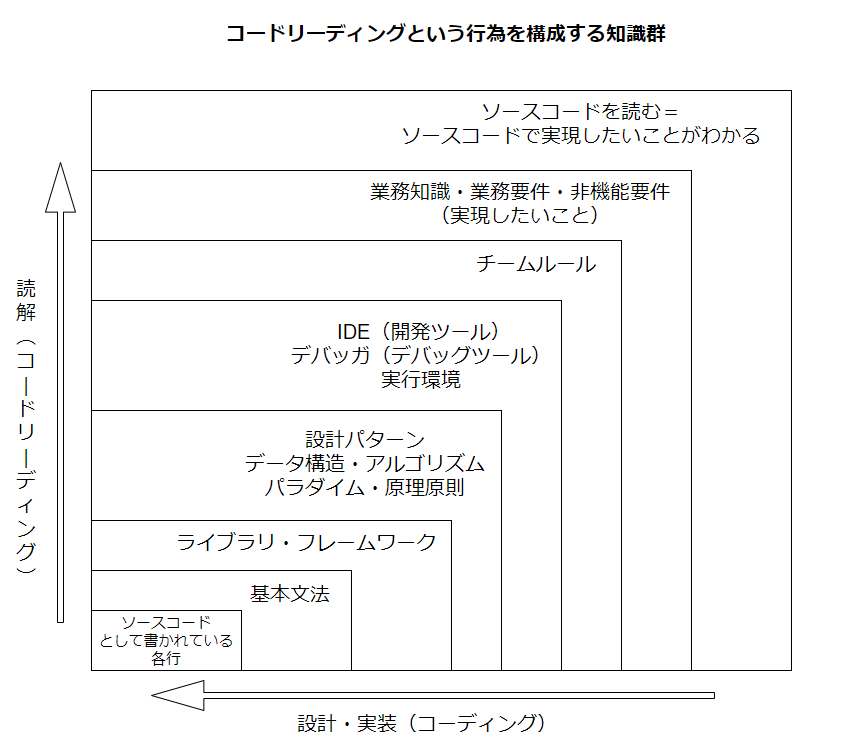
それぞれ通し番号を以下のように設定する。
- 業務知識・業務要件・非機能要件(実現したいこと)
- チームルール
- IDE(開発ツール)、デバッガ(デバッグツール)、実行環境
- 設計パターン、データ構造・アルゴリズム、パラダイム・原理原則
- ライブラリ・フレームワーク
- 基本文法
- ソースコードとして書かれている各行
この「コードリーディングという行為を構成する知識群」という画像における「読解(コードリーディング)」と「設計・実装(コーディング)」は、通し番号でいうとそれぞれ7→1(詳細から全体)と1→7(全体から詳細)の流れで読むものと定義している。
しかし、7→1(詳細から全体)の流れで読むのはある程度プログラムを把握し終えた時の読解方法であり、プロジェクト参画1日目、今まで触れてこなかったサービスの概要を知るときなどの場合は全体から詳細に向かって読むのがプログラムを把握するのには向いているのではないかと私は考える。
まとめるとこうだ
全体から詳細
「プロジェクト参画1日目」「今まで触れてこなかったサービスの概要を知る時」「issueを解決し始める時」に読む流れ
詳細から全体
「ある程度プログラムを把握し終えた時」「エラーが発生し、原因のコードを把握する時」「実装中に実装目的を振り返りたい時」「既存の関数があるか探したい時」に読む流れ
そして、私は、「全体から詳細」と「詳細から全体」を行き来することがソースコードを読む上で重要なのではないかと考える。反復横跳び。
それでは次稿からソースコードを読むための技術を詳説していく。
1 業務知識・業務要件・非機能要件(実現したいこと)
読むプログラムが決まった。さてどうするか。なんの方針もなくただ ただ mainから読んでいってもコードが言おうとしていることは理解できないだろう。まずコードを読む目的を明確に決め、それにだけ 集中するようにする。全てを読まなければいけないときでも、パスを分けて部分ごとに読む。(※1)
自社のサービスをよくしていくには、ビジネスサイド・エンジニアサイド問わず全体の目的を把握する必要がある。それが業務知識・業務要件・非機能要件を把握することである。シチュエーションとしては「プロジェクト参画1日目」「今まで触れてこなかったサービスの概要を知る時」「issueを解決し始める時」などが挙げられる。
業務知識・業務要件・非機能要件の段階で僕がやることはそれぞれ
業務知識の把握
ビジネスサイドの目的把握。プロジェクト参画1日目、今まで触れてこなかったサービスの概要を知るときにまず行う。具体的な把握内容として
そのシステムがなぜ作られたか。目的。経緯の把握。(Why)
どんな価値をユーザーに提供しているのかの把握。(How)
システム上で具体的にどんな業務フロー・顧客の流れかを把握。(What)
がある。
メリットとして、業務知識があることにより、ビジネスサイドと協業・ディスカッションしながらサービスをよりよくすることができる。業務知識については大体ドキュメントが存在する。ない場合は聞く。
業務要件・非機能要件の把握
エンジニアサイドの目的把握。ビジネスサイドなどから投げられたissueを技術的にどう解決するかをメモやコメント欄、ソースコードに日本語で記載していく。
ちなみに筆者は、早く目的を達成するために日頃から業務や自主勉強を通して得た知識を、機能要件・非機能要件に分けてチートシート形式で蓄えている。検索機能を作りたい!()と思った時には機能要件のこれを参照にするし、カラムを変更したい!と思った時には非機能要件のこれを参照にする。一度ハマったエラーなどもチートシート形式で保存をしておくと、同じエラーに遭遇した際に二度手間にならずにURLを参照できる。これは心理的安定にも繋がる。
また筆者は、とりあえずのメモ帳としてはScarpboxを使ってチートシートを作成し、外部にアウトプットする時はブログやQiitaなどを使っている。標準ライブラリのコードやサードパーティ製のライブラリ、OSSなど読んでよさそうだと思ったソースコードは、ScarpboxやGitHubに逐一蓄えておくと再利用が可能なのでとてもよい
備考:ドキュメントがない、ソースコードにコメントがない時に実装者の意図を把握したい場合
①git blame ファイル名
git blame ファイル名で「最終コミットのハッシュ値」「コミットした人」「コミット日時」「行番号」「行の内容」が取得できる。
「最終コミットのハッシュ値」をGitHubの検索欄に入れて検索かけると、issueが出現するので、issueの内容やコメントなどから前任者の実装の意図を把握する。
②GitHubのHistory欄を使う
GitHubのプロジェクト内のファイルページの右上にあるHistoryを押下すると、そのファイルの過去のコミットが見える。これによって、issueの内容やコメントなどから前任者の実装の意図を把握する。
2 チームルールや組織文化
コーディング規約やコミットの粒度、コメントやプルリク作成の際のルールなどを把握する。
コーディング規約を知れば「なんでこういう書き方してるねん」が分かる。
コミットの粒度がどの程度の定義か分かれば、コミットメッセージで実装の意図を把握することができ、ソースコードの理解度が上がる。
プルリク作成の際のルール(とりわけ実装の背景ややったことなどを記載)することでも実装の意図を把握することができ、ソースコードの理解度が上げることができる。
コメントやドキュメントを残すことで、前任者の実装の背景や意図が分かるので、ソースコードの理解度が上がる。
微妙に逸れるのでここでは割愛するが、ソースコードを効率的に読むためには、そもそもソースコードの書き方に気を配る必要があり、その意味でチームルールや組織文化が成熟している必要がある。リーダブルコードで言ってることや言語仕様を把握し、読みやすいコードを書くことも回り回ってソースコードを読むための技術として重要である。
3 IDE(開発ツール)、デバッガ(デバッグツール)、実行環境
ソースコードをより効率的に読むための技術という字面から「ソースコードを左から右へと追う行為をより早くすること」を想像している人もいると思うが、実はそれだけではない。
エディタの設定を変えたり、デバッガーを使ってソースコードを読んでいったり、Dockerなどの仮想化技術を使って開発者の環境を揃え、環境要因によるエラーの可能性を考えなくすることで余計なことを考えずにソースコードを読めるようにすることもソースコードをよりよく読むための技術である。
3.1 IDE(開発ツール)
Jetbrain社のIDEやVSCode,Vimなど色んな開発ツールがあるが、標準機能や拡張機能を使いこなせばより効率的にソースコードを読むことができる。これもソースコードを読むための技術だ。やっていきましょう。
VSCodeのオススメ拡張機能 24 選 (とTipsをいくつか)
3.2 デバッガ(デバッグツール)
大雑把に言って解析手法は静的な手法と動的な手法に分類できる。 静的な手法とは、ソースコードそれ自体を読むこと。 動的な手法とは、デバッガなどを使って実行時の動きを追うことだ。
基本的に解析は動的解析から始めるのがよい。 静的解析とは、多かれ少なかれ、プログラムの動作を予想することである。 対して動的解析で見るのは事実である。 まず事実を見ておいたほうが方向付けがしやすいし、間違いも減る。 最適化する前にプロファイルを取れ、というのと似ているだろうか。 事件解決はまず現場から、というのでもよい。(※1)
らしい。よって、動的手法から解説していく。
3.2.1 動的解析
また、本稿では「エラーを解決することを目的」として動的解析を行っているが、「プロジェクトの理解が目的」でも同様にしてソースコードを動的解析する。「エラーが起きたら〜」部分を「プロジェクトで気になるソースコードが見つかったら」と適宜、変換してしてほしい。
3.2.1.1 デバッガーを使う
Webプログラミングというのはクライアントがパラメーター付きのリクエストを送り、それをサーバーサイドで加工しクライアントにレスポンスするものだと考えている。時にはパラメーターの値を参照にデータベースから値を持ってきて、サーバーサイドで加工しクライアントにレスポンスすることもある。つまり、Webプログラミングはバケツリレー大会であり駅伝大会である。バケツの水やタスキが変数になっただけなのだ。そして、エラーは変数の値が予想と違ったり、大会のルールがロジカルではないなどの原因で発生する。
そのバケツリレーの流れの中でどの地点がエラーになったのかを分析するのがデバッガーである。先述の「1 目的の設定」で決めた目的に合致するエラーの箇所をブラウザ・URL・バックトレースから判別し、プロジェクトファイルから該当のフォルダとファイルを、付与された名前を駆使して類推・探索する。それによってそれっぽいファイル名・関数名・変数名・型名・メンバ名を特定し、特定地点にデバッガーを挿し込んで変数の流れを把握する。
静的な文字情報として脳内で認識していたプログラムをデバッガーを使用することで、一気に動的な風景として脳内で認識することができる。個人的には80年前の写真が突如動画になって動き始めるた時の感動に近いものを感じる。プログラムをイメージで把握することで右脳や空間知覚を使用することができる。記憶容量の大きい右脳に処理の流れをストックできるので、空いた左脳でソースコードの分析ができる。
デバッガーは、IDEであればEclipseやJetBrain系IDEに予め内蔵されているものを使う。そうでない場合はRubyであればbyebugやpryなどのサードパーティ製のライブラリを使うといいだろう。
3.2.1.2 ソースコードの処理の流れを日本語や図でメモに記載する
3.2.1.1ではバックトレースを読んだりデバッガーを使用し、ソースコードの処理の流れを把握した。処理の流れを把握したらその次は把握した内容を日本語や図でメモなどに記載することをする。
なぜ「ソースコードの処理の流れを日本語に置き換えメモをする」のか。理由は2つある。
1つ目は「ソースコードは抽象的だから」だ。
ソースコードを解読するということは抽象概念を具象概念に落とし込むことであると考えている。天才や業務経験の長いエンジニアであれば抽象を抽象のまま理解しそれを活用することができるが、プログラミングに関して私は凡人であり業務経験も少ない。そのため、抽象概念を具象概念に落とし込み日本語でメモをすることは業務効率、学習、思考の外部記憶装置の面で重要なファクターだと考えている。故に「ソースコードの処理の流れを日本語に置き換えメモをする」ことは重要である。
2つ目は「ソースコードは英語で記載されているから」だ。
まず我々は日本人だ。24時間日本語を使っている。日本語で記載されているものは0秒で理解できるしイメージ理解が容易である。しかし、残念なことにソースコードは英語で記載されている。母国語ではない英語には馴染みがない。英語でGiraffeと言われてもすぐに理解はできないが、日本語でキリンと言われれば0秒で動物のキリンが頭の中にイメージできる。つまり、英語で記載されている単語の意味は0秒で理解できないし、増してやイメージ記憶は日本語に比べて難解だということだ。そのため、英語で書かれた抽象的なソースコードの流れを具体的に日本語や図でメモに記載することは、業務を早くするという面で重要なファクターを持つ。
仮にソースコードを英語のまま理解したいのであれば、英語を英語で理解する習慣を意識的に作り、英語脳を養うことが必要であると考える。しかし、恐らく英語脳習得にはかなりの時間がかかると見ている。ライティングは特に。またプログラミングやマーケティングなど学ぶことも多いため、英語ばかりにリソースを割けないというのも実情だ。そのため、取り急ぎ英語で記載されたプログラムを日本語に変換し、処理の流れを順次メモし整理することは、重要なことであると考える。
以上の理由から、ソースコードの処理の流れを日本語や図で記載することは重要であると考えた。実は3つ目に「処理の流れを俯瞰で理解できる点」というものを用意していたが、詳細の文章をどう書けばいいかわからなくなったため記載を省きました。
3.2.2 静的解析
3.2.2.1 ドキュメントを読む
そもそもソースコードを読まない
ソースコード読んだら負けかなと思っています。
リファレンスマニュアル、ドキュメント
設計関連の文書・資料
自然言語で書かれた素晴らしいものがたくさんあるはずなので、まずはそちらを読みましょう。そういったものがあまり頼れないとき、そういったもので解決しないときは、しょうがないのでコードを読みます。それでもコメントや識別子の命名を重視して、まずはできるだけ意味的に解釈してみます。
コメント皆無、変数名適当……というケースでは、仕方ありません。他にどうしようもないので、コードロジックを見ていきましょう。
読むのは面倒くさいので、できればやりたくないことの筆頭です。できるだけやらないで済ませる方法を考えます。
初心者だと読解力不足で捗らないということも多々あるでしょうし、よほどの必要性に迫られていなければ「コード読むのは、もう少し上達してからでいいよ」なのでは。
前任者がドキュメントを残しているはずなので、それを読む。
https://teratail.com/questions/147782
これも前項と似ていて、まず仕様を知っておこうということ。 また内部構造を解説したドキュメントが付いていたらそれもぜひ見ておきたい。 「HACKING」「TOUR」などという名前のファイルがあったら要チェック。
「コードリーディングという行為を構成する知識群」における⑥チームルールにあたるものだ。
せっかく前任者が工数をかけて自然言語や図でドキュメントを残しているので、あるならドキュメントを先に読解するのがいい。
4 設計パターン、データ構造・アルゴリズム、パラダイム・原理原則
4.1 ディレクトリ構造を読む
どういう方針でディレクトリが分割されているのか見る。 そのプログラムがどういう作りになっているのか、 どういうパートがあるのか、概要を把握する。 それぞれのモジュールがどういう関係にあるのか確かめる。
4.2 ファイル構成を読む
ファイルの中に入っている関数(名)も合わせて見ながら、 どういう方針でファイルが分割されているのか見る。 ファイル名は衰えないコメントのようなものであり、注目すべきである。
また関数名の名前付けルールについてもあたりをつけておきたい。 C のプログラムなら extern 関数にはたいていプリフィクスを 使っているはずで、これは関数の種類を見分けるのに使える。また オブジェクト指向式のプログラムだと関数の所属情報がプリフィクスに 入っていることがあり、貴重な情報になる。(例: rb_str_push)
4.3 関数同士の呼び出し関係を把握する
関数名の次に重要な情報。 特に関数の数が多い場合はこれが重要である。 このへんはツールを活用したい。 図にしてくれるツールがあればそれが一番いいが、 なければ特に重要な部分だけでいいので自分で図を書いておくといい。 図に凝る必要はないので、裏紙にざっと描けば十分だろう。
ちなみにこのこの呼び出しの関係を図にしたもののことを コールグラフ (call graph) と言うことがある。 ソースコードに書いてある呼び出し関係を そのまま図にしたのが静的なコールグラフ (static call graph) で、 実際に動作させたときに呼び出した関数だけを書いた図が 動的なコールグラフ (dynamic call graph) である。
ただ、検索した感じでは、日本語の文章だと「コールグラフ」 は暗黙のうちに dynamic call graph を指し、 static call graph は「関数呼び出し関係」と言うことが多いようだ。 だが static と dynamic で対になっているほうがわかりやすいので 筆者は動的コールグラフ・静的コールグラフと呼ぶことにしている。
コールグラフはJavaをやっていた頃にEclipseの機能の1つとしてみた気がします。「Ruby コールグラフ」や「vscode コールグラフ」で調べても出てこない上にあまり詳しく内容を把握していないので、とりあえず頭の片隅に置いておきます。知りたい人は検索してみてください。
4.4 デザインパターン
デザインパターンとは「オブジェクト指向において、よく使われる設計をパターン化したもの」「何度も遭遇する似たような問題に関する解法」である。デザインパターンを知っておくことでソースコードを読み書きする際に以下のメリットを享受できる。
メリット
- プログラムの再利用性が高い
- 効率的に品質の高い構造を作れる
- 可読性が高い故に保守性に優れる
- デザインパターンを知っていれば設計の意図が読めるようになるので、引継ぎする際に保守しやすくなる
- 転じてデザインパターンを知ることで開発者同士の意思疎通がスムーズになる
凡人の凡人による凡人のためのデザインパターン第一幕 Public
4.5 アルゴリズムとデータ構造
プログラムなんて、データ構造がどうなっているのか分かれば もう半分勝ったようなものだ。コードを書くときも、 コードに逐一コメントを付けるよりデータ構造 (だけ) を 解説するほうがはるかに役に立つ。 (と、何かの本に書いてあったんだけど、なんだっけ?)
※ 追記:『プログラム書法』だった。以下、同書の p.168 より引用する。 「プログラムに解説をつけるための、もっとも効果的な方法の一つは、 単にデータの割り付けかたをくわしく説明する、というものである。 おもな変数について、その値としてはどんなものが可能かを示し、 それが変って行くようすを説明すれば、それだけでプログラムの解説は、 ずいぶん進んだといってよい。」
ちなみにこの本の原書は 1974 年に出版されている。※ 追記2:『Cプログラミング診断室』でも似たようなコメントを発見した。 以下、同書の p.78 より引用する。 「フローチャートは禁止しましょう。フローチャートは、 制御の流れを「もろ」に書けてしまうのでよくありません。 プログラムは、データを処理するためにあり、データの違いによって 制御の流れが変更されます。あくまでも、データが主体です。 変数、引数などのデータをどう定義するかで、プログラムの組みやすさは 大幅に改良されます。データ構造がどうなっているかの図のほうが、 フローチャートよりはるかに役立ちます。データの意味だけは、 しっかり書きましょう。」
閑話休題。 C でデータ構造を作るならもちろん struct か union を使うはずだ。 そういう重要構造はヘッダファイルで定義されていることが多い。 もちろん内部構造は .c で定義されることもあるし動的に構築される データ構造もあるので、最終的には関数を読んでいかないとわからない。 それでもまずはヘッダファイルを読むべきだろう。ヘッダファイルを 読むときにもやはりファイル名は重要である。例えば言語処理系で frame.h というファイルがあったら、たぶんスタックフレームの定義だ。
データ構造を予測する時は構造体メンバに注目する。構造体の定義中に next というポインタがあればリンクリストだろうと想像できる。 同様に、parent・children・sibling と言った要素があれば十中八九 ツリーだ。
アルゴリズムとデータ構造を実務で使用した経験がないため、これらをどう使うかはよくわかっていない。どうやらビックデータ分析を行う際に多用されるらしい。文献等は以下を読むと理解が深まると考えられる。
STEP1
STEP2
AtCoder:競技プログラミングコンテストを開催する国内最大のサイト
これら以外に何かおすすめがあったら教えてください!
5 ライブラリ・フレームワーク
ソースコードに出現する単語はファイル・関数(メソッド)・型(クラス)・変数・メンバ変数・予約語のどれを指しているのか。どんな書き方をしているかを知る。
① ファイル
Railsなどのフレームワークなら命名規則が存在する。ファイル名でそれがソフトウェアにおいてどんな役割を担っているかをある程度類推できる。
② 関数(メソッド)の種類
標準ライブラリ産のメソッド(使用頻度が高いのでRuby,Railsなどに元々備わっているクラスやそれに付随するメソッド。殿堂入り)
外部ライブラリ産のメソッド(gem)
自作ライブラリ産のメソッド(helper,model,application)
メソッドのオプション
③ 型の種類
integer,string,arrayなど
オブジェクト志向プログラミングでは、型をクラスと呼び、クラスを自身で作成して使うことができる。
オブジェクト志向プログラミングの用語
クラス、オブジェクト、インスタンス、レシーバ、メソッド、メッセージ、状態(ステート)、属性(アトリビュート、プロパティ)
④変数(インスタンス)
変数、メンバ変数、インスタンス変数、クラスインスタンス変数
⑤名前空間を用いたクラスの差別化
クラス名の予期せぬ衝突を防ぐのが目的。
⑥予約語や識別子
「順次処理」「条件分岐」「繰り返し」のような構造を表した単語。
# rubyにおける予約語や識別子
BEGIN class ensure nil self when
END def false not super while
alias defined? for or then yield
and do if redo true __LINE__
begin else in rescue undef __FILE__
break elsif module retry unless __ENCODING__
case end next return until
⑦略語の調査
わかりにくい略語があればリストアップしておいて早めに調べる。 例えば「GC」と書いてあった場合、それが garbage collection なのか graphic context なのかでずいぶん話が違ってしまう。 英語だと単語の頭文字をとるとか、母音をなくすとかが多い。 特に対象プログラムの分野で有名な略語は問答無用で使われるので あらかじめチェックしておく。
筆者の記憶にある中から一つ例を挙げよう。 とある Lisp 処理系で、 プログラム全体で「blt」というプリフィクスが使われているのだが、 これが何を表しているのかわからなくて困ったことがある。 これは実は built-in function (組み込み関数) のことであった。 わかってみると単純なことだが、これがわかるのとわからないのでは ずいぶん難易度が違う。
らしい。確かにJavaの案件で略語を見た気がする。分からない場合は
- 詳しい人に聞く
- ドキュメントを調べる
- 検索する
のいずれかの戦略を取る必要があるだろう。
また、自分で変数などをコーディングする際はリーダブルコードを参照にするといい。
6 基本文法
5と同じ。
7 ソースコードとして書かれている各行
7.1 どのような目的で設計されたコードなのかを考える。
RASISとは、コンピュータシステムに関する評価指標の一つで、「信頼性」「可用性」「保守性」「保全性」「安全性」の5項目をアクロニム(頭文字語)によって表現したもののことである。
業務でWebサービス開発をする際に気をつけたいこと(新卒向け)を基に作成しました。RASISに関しては明るくないため、詳細を知りたい場合は参照元から。
①Reliability(信頼性)
システム障害への強さ「壊れにくさ」システムの故障しにくさを表します。
- 例外設計
- デプロイ/ロールバックの手順を完璧にする
- 死活監視/障害検知をする
- ログファイルを適切に扱う
- バックアップを取る
②Availability(可用性)
必要なタイミングで要求サービスが利用可「サービスが利用できる」度合い。システムが継続して稼働できる能力。
- 単一障害点をなくす
③Serviceability(保守性)(拡張性)
「シンプルなシステム」を志向する。シンプルだと内容の把握やアップデートが簡単。
- テストコード
- リーダブルコードの命名規則に沿った変数名
- バージョン管理
- ドキュメントを残す
- 障害情報をログに残す
- 開発環境を簡単に作る
④Integrity(保全性)
データの一貫性や整合性をさす。データベースのデータについて言及される事が多い。Railsであればモデル層やDBで制約をかけたりする。
- トランザクション制御
トランザクションとは?【13分でわかるDBトランザクション処理】データベース入門講座#4
- DBの制約
「SQLアンチパターン」を避けるためのチェックリスト①(DB論理設計編)
- モデル設計
データモデルの設計とベストプラクティス(第2部) - Talend
モデル設計を適当にやるとどうなるのか - SlideShare
ドメイン駆動設計をわかりやすく - ドメインのモデル設計を手を動かしながら学ぼう
⑤Security(機密性)(安全性)
情報が流出しないようにする。
- SSL化
- パスワードのハッシュ化
- フレームワークの機能を使う
- ストロングパラメーターの設定
- プレースホルダーの設定
7.2 歴史を読む
GitHubのコミットログを参照する。開発者の意図がわかるのと、完成モジュールに関わるソースコードがどれなのかが分かりやすい。
①git blame ファイル名
git blame ファイル名で「最終コミットのハッシュ値」「コミットした人」「コミット日時」「行番号」「行の内容」が取得できる。
「最終コミットのハッシュ値」をGitHubの検索欄に入れて検索かけると、issueが出現するので、issueの内容やコメントなどから前任者の実装の意図を把握する。
②GitHubのHistory欄を使う
GitHubのプロジェクト内のファイルページの右上にあるHistoryを押下すると、そのファイルの過去のコミットが見える。これによって、issueの内容やコメントなどから前任者の実装の意図を把握する。
7.3 ちょっと変更して動作させてみる
これは「この段階でやる」という類のものではなくて手法の一つである。 人間の頭というのは不思議なもので、できるだけ身体のいろんな場所を 使いながらやったことは記憶に残りやすい。パソコンのキーボードより 原稿用紙のほうがいい、という人が少なからずいるのは、単なる懐古趣味ではなく そういうことも関係しているのではないかと思う。
そういうわけで、単にモニタで読むというのは非常に身体に残りにくいので、 書き換えながら読む。そうするとわりと早く身体がコードに馴染んでくることが 多い。気にくわない名前やコードがあったら書き換える。わかりずらい略語は メモるだけでなく省略しない語に置換してしまってもよい。
ただし、当然のことだが書き換えるときはオリジナルのソースは別に残し、 途中で辻褄が合わないと思ったら元のソースを見て確認すること。でないと 自分の単純ミスで何時間も悩む羽目になる。
書き換えて動かす
前項と似ているが、こちらは実際にプログラムを動かしてみる。例えば 動作のわかりにくいところでパラメータやコードをちょっとだけ変えて 動かしてみる。そうすると当然動きが変わるから、コードがどういう意味 なのか類推できる。これまた言うまでもないが、オリジナルのバイナリは残しておいて 同じことを両方にやってみるべきである。
変更させて動作確認する行為は、私の経験上プログラミングスキルを高めることができるものだと考えており、特に初心者におすすめである。しかし、変更を元に戻せなくてエラーになって焦ってしまい、エラーが怖いから試さなくなってしまい成長機会を逃すというのを経験している。なので、命綱として変更を取り消すやり方について下記に記していく。
7.4 irbなどのインタラクティブな機能で試す
ライブラリやメソッドがどう動いているかを仮説検証できる
rails c --sandbox
7.5 ソースコードを楽しく読みたい(ゲーム感覚で取り組みたい)
- 記録を付ける
- 興味を持っている分野のソースコードを読む
- 良いソースコードを読む
- 仕事でも役立つソースコードを読む
- ちょっと変更して動作させてみる
- バグがないか探してみる
プログラマーが教える、ソースコードを読むための4つの方法!
【新人なるプログラマーへ】ソースコードを読みましょう (2/2)
8 エラー原因追及の際に切り分ける領域
サービスが止まってる
クラウドサーバーが止まってる、GitHubが止まってる
通信の問題
Wifiが繋がってない
環境の問題
機器: スマホ・PC
OS: Windows, Mac, Linux
ブラウザ: Safari・Chrome
サーバー: 開発環境・staging環境・本番環境
バージョン: それぞれの機器のバージョン
権限の問題
パーミッション・認証・認可・キーがない・設定ファイルが間違えてる
場所の問題
ファイルの作成場所が違う、現在いるディレクトリではない、設定ファイルが指し示すパス(場所)が違う
ロジックの問題
想定される見え方と違う系: 前提条件が違う、仕様を履き違えてる、言語ルールの把握不足、値が入っていない、見た目同じように見えるが型が違った、外部ライブラリをインストールしてない
データの問題
間違ったデータを使っていた、DBに入っているデータがおかしい、データが入っていない、データが不整合
リクエスト問題
リクエストヘッダ系: Cookie、HTTPメソッド、それ以外のヘッダ、HTTPのバージョン
デバッガーを外し忘れていた
サーバー側でアクセス制限をかけていたり権限が必要
見え方の問題
同期非同期、onloadなどレンダリングとタイミングが合っていない、キャッシュを消してない、cssの優先度、保存(ctrl+s)し忘れ
9 終わりに
さしあたってはこれくらいです。なお、外部からのコメントや、自身の成長度合いによってこの文章は随時更新していくつもりです。