##前回までのあらすじ
前回の記事ではタイタニック号の乗客で誰が生き残るか予測するために、データを見ていきました。データを解析していく中で、幾つかの仮説を立てました。今回は、その仮説に基づいてデータをもっと弄くり回していきます。
データを視覚化して解析する
それでは、仮説を確認するために、データ分析の視覚化を行っていきます。
数値特徴量の相関
数値特徴量とSurvived(統計学的に言うと応答変数)との相関を理解することから始めましょう。
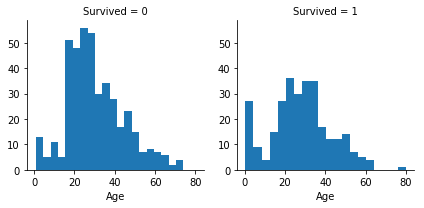
ヒストグラムはAgeのような連続的な数値変数を分析するのに便利で、一定値毎での区切りや範囲が有用であるパターンを特定するのに役立ちます。
ヒストグラムについて説明しておくと、横軸は階級(ある一定の数値で区切ったもの)、縦軸に度数(各階級に属する数値の数)、で表した縦棒グラフです。見ればなんとなく分かって頂けるかと思います。
ヒストグラムは、自動的に定義された階級の幅を使用した標本の分布を示すことができます。これは特定の階級に関する質問に答えるのに役立ちます(幼児の生存率はより良いか?)
ヒストグラムにおけるy軸は、標本または乗客の数を表すことに注意してください。
観察
- 幼児(年齢= 4歳)は高い生存率を示した。
- 最も年老いた乗客(年齢= 80)が生き残った。
- 15-25歳の多数が生き残れなかった。
- ほとんどの乗客は15-35歳の範囲にある。
結論
この単純な分析により仮説が正しいと確認され、後に続く分析で用いることができます。
- モデルトレーニングでageを考慮する必要があります。
- null値のageを補完する。
- age特徴量ではある程度の幅で表された新しい特徴量を作成する。
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20)
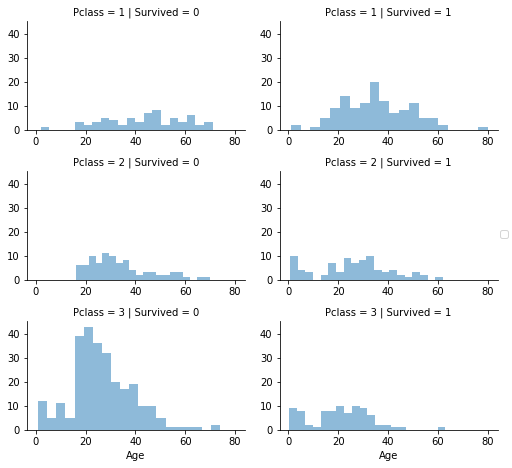
数値と順序尺度の特徴量の相関
1つのプロットを使用して相関を識別する複数の特徴量を組み合わせることができます。 これは数値とカテゴリカル特徴量を用いて行うことができます。
観察
- Pclass = 3 のほとんどの乗客は生き残れなかった。
- Pclass = 2 およびPclass = 3の幼児の乗客はほとんどが生き残った。 仮説【子供(年齢<?)は生存していた可能性が高い。】を実証しました。
- Pclass = 1 のほとんどの乗客は生き残った。 仮説【上位クラスの乗客(Pclass = 1)は生き残った可能性が高い。】を実証しました。
- Pclassは、乗客の年齢分布によって異なります。
結論
- モデルトレーニングのためにPclassを考慮する。
# grid = sns.FacetGrid(train_df, col='Pclass', hue='Survived')
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend();
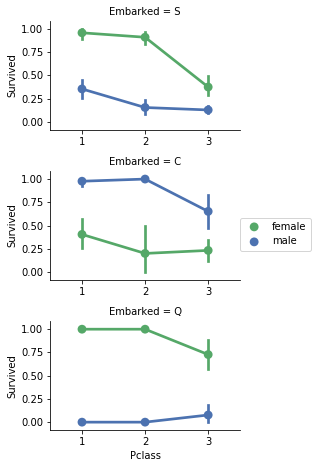
カテゴリカル特徴量の相関
カテゴリカル特徴量と応答変数(Survived)を関係を分析してみましょう。これは、数値の値を持つカテゴリカル特徴量と数値特徴量に対して行うことが出来ます。
観察
- 女性の乗客は男性よりもはるかに良好な生存率を示した。仮説【女性(性別=女性)は生存していた可能性が高い。】を実証しました。
- 例外的にEmbarked = C では男性の生存率が高い。 これは、PclassとEmbarkedとの間の相関性であり、Pclassの影響が高く、必ずしもEmbarkedとSurvivedの間の直接的な相関関係とは言えない。
- C、Q港でPclass = 2と比較した場合、男性はPclass = 3でより良い生存率を示した。 仮説【Survived または他の重要な特徴量と相関する可能性があるため、Embarked の欠損値も補完する必要があるかもしれません。】。
- 乗船港は、Pclass = 3および男性乗客の生存率が異なる。 仮説【各特徴量がどのように「Survived」に相関しているかを知りたい】。
結論
- モデルトレーニングにSex特徴量を追加する。
- モデルトレーニングにEmbarked特徴量を補完して追加する。
# grid = sns.FacetGrid(train_df, col='Embarked')
grid = sns.FacetGrid(train_df, row='Embarked', size=2.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()
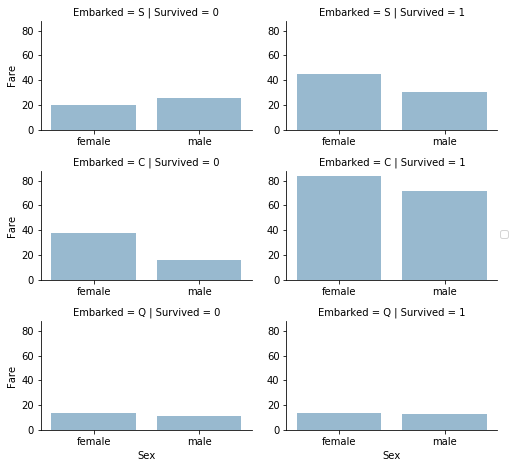
カテゴリカル特徴量と数値特徴量の相関
また、(数値以外の値を持つ)カテゴリカル特徴量と数値特徴量を関連付けることもできます。 今回は、Embarked(カテゴリカルで非数値)、性別(カテゴリカルで非数値)、運賃(数値で連続値)、生存(カテゴリカルで数値)の間での相関を分析することができます。
観察
- より高い運賃を支払う乗客はより良い生存率を示した。 仮説【Fareの範囲を特徴量として作成】。
- 乗船港は生存率と相関する。
結論
- Fare特徴量のバンディング(一定の区間で区切ってカテゴリカルにする)を検討する。
# grid = sns.FacetGrid(train_df, col='Embarked', hue='Survived', palette={0: 'k', 1: 'w'})
grid = sns.FacetGrid(train_df, row='Embarked', col='Survived', size=2.2, aspect=1.6)
grid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)
grid.add_legend()
データラングリング
これまで、データセットと問題要件に関するいくつかの仮説と結論を集めました。 これまでは、単一の特徴量や値を変更してこれらに到達する必要はありませんでしたが、これからは結論と仮説を実行して、特徴量を補完したり修正したり作成したしていきましょう。
特徴量を削除することで修正する
特徴量を削除することで、データポイントの数が減少し、分析をより楽にすることができます。
仮説と結論に基づいて、CabinとTicketの特徴量を削除しましょう。
該当する項目では、訓練データセットとテストデータセットの両方で操作を実行して、一貫性を保ちます。
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
"After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape
Before (891, 12) (418, 11) (891, 12) (418, 11)
('After', (891, 10), (418, 9), (891, 10), (418, 9))
既存のものから新しい特徴量を作成する
NameとPassengerIdを削除する前に、NameからTitle(肩書)を抽出し、TitleとSurvivedの相関関係を調べたいと思います。
次のコードでは、正規表現を使用してTitleを抽出します。 正規表現パターン (\w+\.)は、Name特徴量内のドット文字で終わる最初の単語と一致します。 expand = Falseフラグはパターンにマッチしたグループが1つの場合、Series(対象がSeriesのとき)かIndex(対象がIndexのとき)を返し、複数マッチした場合はDataframeを返します。デフォルトではTrueになっており、この場合は常にDataframeを返します。
観察
Title、年齢、生存率をプロットすると、次のような観察結果が得られます。
- ほとんどのTitleは、年齢層を正確に区別します。 例:Master の年齢平均は5歳です。
- Title年齢層の生存率はわずかに異なります。
- 一部のTitleはほとんどが生き残った(Mme、Lady、Sir)か、そうでなかった(Don、Rev、Jonkheer)。
結論
- モデルトレーニングのために新しいタイトル特徴量を留め置くことに決めました。
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train_df['Title'], train_df['Sex'])
| Sex | female | male |
|---|---|---|
| Title | ||
| Capt | 0 | 1 |
| Col | 0 | 2 |
| Countess | 1 | 0 |
| Don | 0 | 1 |
| Dr | 1 | 6 |
| Jonkheer | 0 | 1 |
| Lady | 1 | 0 |
| Major | 0 | 2 |
| Master | 0 | 40 |
| Miss | 182 | 0 |
| Mlle | 2 | 0 |
| Mme | 1 | 0 |
| Mr | 0 | 517 |
| Mrs | 125 | 0 |
| Ms | 1 | 0 |
| Rev | 0 | 6 |
| Sir | 0 | 1 |
多くのTitleをより一般的な名前に置き換えることも、「Rare」として分類することもできます。
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()
| Title | Survived | |
|---|---|---|
| 0 | Master | 0.575000 |
| 1 | Miss | 0.702703 |
| 2 | Mr | 0.156673 |
| 3 | Mrs | 0.793651 |
| 4 | Rare | 0.347826 |
カテゴリカルなタイトルを序数に変換することができます。
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | 7.2500 | S | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | 71.2833 | C | 3 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | 7.9250 | S | 2 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 53.1000 | S | 3 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 8.0500 | S | 1 |
これで、トレーニングとテストのデータセットからNameを安全に削除できます。 また、トレーニングデータセットにPassengerIdは必要ありません。生き残ったかどうかという問題とはどう考えても関係ないですよね。
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
train_df.shape, test_df.shape
((891, 9), (418, 9))
カテゴリカル特徴量の変換
文字列を含む特徴量を数値に変換できます。 この操作は、ほとんどのモデルアルゴリズムで必要で、特徴量の補完を成し遂げることに貢献してくれます。
Sex特徴量を、女性= 1、男性= 0の性別という新しい特徴量に変換してみましょう。
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
train_df.head()
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 22.0 | 1 | 0 | 7.2500 | S | 1 |
| 1 | 1 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 | C | 3 |
| 2 | 1 | 3 | 1 | 26.0 | 0 | 0 | 7.9250 | S | 2 |
| 3 | 1 | 1 | 1 | 35.0 | 1 | 0 | 53.1000 | S | 3 |
| 4 | 0 | 3 | 0 | 35.0 | 0 | 0 | 8.0500 | S | 1 |
連続的数値の特徴量を補完する
今度は、欠損値またはnull値を持つ特徴量を、その欠損値を推定して補完する必要があります。まず、age特徴量でこれを行います。
数値連続的特徴量を補完するのに、ここでは3つの方法が考えられます。
-
簡単な方法は、平均と標準偏差の間の乱数を生成することです。
-
欠損値を推測するより正確な方法は、他の相関する特徴量を使用することです。今回のケースでは、年齢、性別、およびPclassの間の相関を記録する。 PclassとGenderの特徴量の組み合わせのセット全体でageの中央値を使用してAgeの値を推測します。Pclass = 1、Gender = 0、Pclass = 1、Gender = 1などの中間の年齢などなど。
-
方法1と2を組み合わせる。中央値に基づいて年齢値を推測する代わりに、PclassとGenderの組み合わせのセットに基づいて、平均と標準偏差の間になる乱数を使用する。
方法1と3はランダムノイズをモデルに導入することになり、複数回の実行結果が異なる可能性があります。よって方法2を優先します。
# grid = sns.FacetGrid(train_df, col='Pclass', hue='Gender')
grid = sns.FacetGrid(train_df, row='Pclass', col='Sex', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()
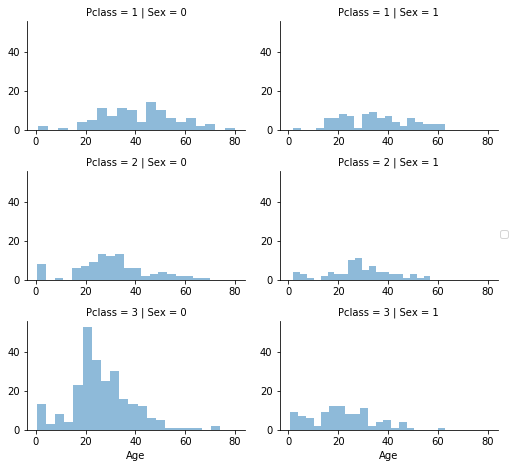
Pclass x Genderの組み合わせに基づいて推測されたAge値を格納する為の、空の配列を準備することから始めましょう。
guess_ages = np.zeros((2,3))
guess_ages
array([[ 0., 0., 0.],
[ 0., 0., 0.]])
今度は、Sex(0または1)とPclass(1,2,3)を繰り返し、6つの組み合わせのAgeの推測値を計算します。
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
guess_df = dataset[(dataset['Sex'] == i) & \
(dataset['Pclass'] == j+1)]['Age'].dropna()
# age_mean = guess_df.mean()
# age_std = guess_df.std()
# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)
age_guess = guess_df.median()
# Convert random age float to nearest .5 age
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\
'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int)
train_df.head()
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 22 | 1 | 0 | 7.2500 | S | 1 |
| 1 | 1 | 1 | 1 | 38 | 1 | 0 | 71.2833 | C | 3 |
| 2 | 1 | 3 | 1 | 26 | 0 | 0 | 7.9250 | S | 2 |
| 3 | 1 | 1 | 1 | 35 | 1 | 0 | 53.1000 | S | 3 |
| 4 | 0 | 3 | 0 | 35 | 0 | 0 | 8.0500 | S | 1 |
Ageの区間(Band)を作成し、Survivedとの相関を見てみましょう。
train_df['AgeBand'] = pd.cut(train_df['Age'], 5)
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)
| AgeBand | Survived | |
|---|---|---|
| 0 | (-0.08, 16.0] | 0.550000 |
| 1 | (16.0, 32.0] | 0.337374 |
| 2 | (32.0, 48.0] | 0.412037 |
| 3 | (48.0, 64.0] | 0.434783 |
| 4 | (64.0, 80.0] | 0.090909 |
これらの区間に基づいて年齢を序数に置き換えましょう。
for dataset in combine:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age'] = 4
train_df.head()
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | AgeBand | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 1 | 0 | 7.2500 | S | 1 | (16.0, 32.0] |
| 1 | 1 | 1 | 1 | 2 | 1 | 0 | 71.2833 | C | 3 | (32.0, 48.0] |
| 2 | 1 | 3 | 1 | 1 | 0 | 0 | 7.9250 | S | 2 | (16.0, 32.0] |
| 3 | 1 | 1 | 1 | 2 | 1 | 0 | 53.1000 | S | 3 | (32.0, 48.0] |
| 4 | 0 | 3 | 0 | 2 | 0 | 0 | 8.0500 | S | 1 | (32.0, 48.0] |
AgeBand特徴量を削除します。
train_df = train_df.drop(['AgeBand'], axis=1)
combine = [train_df, test_df]
train_df.head()
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | Title | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 1 | 0 | 7.2500 | S | 1 |
| 1 | 1 | 1 | 1 | 2 | 1 | 0 | 71.2833 | C | 3 |
| 2 | 1 | 3 | 1 | 1 | 0 | 0 | 7.9250 | S | 2 |
| 3 | 1 | 1 | 1 | 2 | 1 | 0 | 53.1000 | S | 3 |
| 4 | 0 | 3 | 0 | 2 | 0 | 0 | 8.0500 | S | 1 |
既存の特徴量を組み合わせて新しい特徴量を作成する
ParchとSibSpを組み合わせてFamilySizeとして新しい特徴量を作成できます。 これにより、データセットからParchとSibSpを削除できます。
for dataset in combine:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
train_df[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| FamilySize | Survived | |
|---|---|---|
| 3 | 4 | 0.724138 |
| 2 | 3 | 0.578431 |
| 1 | 2 | 0.552795 |
| 6 | 7 | 0.333333 |
| 0 | 1 | 0.303538 |
| 4 | 5 | 0.200000 |
| 5 | 6 | 0.136364 |
| 7 | 8 | 0.000000 |
| 8 | 11 | 0.000000 |
IsAloneという別の特徴量を作成することができます。
for dataset in combine:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
train_df[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()
| IsAlone | Survived | |
|---|---|---|
| 0 | 0 | 0.505650 |
| 1 | 1 | 0.303538 |
IsAloneが良さげなので、Parch、SibSp、およびFamilySize特徴量を削除します。
train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]
train_df.head()
| Survived | Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 7.2500 | S | 1 | 0 |
| 1 | 1 | 1 | 1 | 2 | 71.2833 | C | 3 | 0 |
| 2 | 1 | 3 | 1 | 1 | 7.9250 | S | 2 | 1 |
| 3 | 1 | 1 | 1 | 2 | 53.1000 | S | 3 | 0 |
| 4 | 0 | 3 | 0 | 2 | 8.0500 | S | 1 | 1 |
PclassとAgeを組み合わせた人工的な特徴を作成することもできます。
for dataset in combine:
dataset['Age*Class'] = dataset.Age * dataset.Pclass
train_df.loc[:, ['Age*Class', 'Age', 'Pclass']].head(10)
| Age*Class | Age | Pclass | |
|---|---|---|---|
| 0 | 3 | 1 | 3 |
| 1 | 2 | 2 | 1 |
| 2 | 3 | 1 | 3 |
| 3 | 2 | 2 | 1 |
| 4 | 6 | 2 | 3 |
| 5 | 3 | 1 | 3 |
| 6 | 3 | 3 | 1 |
| 7 | 0 | 0 | 3 |
| 8 | 3 | 1 | 3 |
| 9 | 0 | 0 | 2 |
カテゴリカル特徴量を補完する
Embarked特徴量は、乗船港に基づいてS、Q、Cの値を取ります。 トレーニングデータセットには2つの欠損値がありますが、今回は最も一般的な出現で埋めることにします。
freq_port = train_df.Embarked.dropna().mode()[0]
freq_port
'S'
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)
| Embarked | Survived | |
|---|---|---|
| 0 | C | 0.553571 |
| 1 | Q | 0.389610 |
| 2 | S | 0.339009 |
カテゴリカル特徴量を数値に変換する
欠損値を補完したので、Embarked特徴量を数値に変換出来るようになりました。
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
train_df.head()
| Survived | Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 7.2500 | 0 | 1 | 0 | 3 |
| 1 | 1 | 1 | 1 | 2 | 71.2833 | 1 | 3 | 0 | 2 |
| 2 | 1 | 3 | 1 | 1 | 7.9250 | 0 | 2 | 1 | 3 |
| 3 | 1 | 1 | 1 | 2 | 53.1000 | 0 | 3 | 0 | 2 |
| 4 | 0 | 3 | 0 | 2 | 8.0500 | 0 | 1 | 1 | 6 |
クイック補完と数値特徴量の変換
この特徴量の最頻値(最も頻繁に登場する値)を使用して、テストデータセットの値が不足している場合に、Fare特徴量を補完することができます。 これは1行のコードで行えます。
補完する目的は、欠損値を埋めて、モデルアルゴリズムがある程度望ましい状態で動作することです。必要以上に欠損値の推測に時間を掛ける必要はありません。
通貨を表しているので、運賃の小数点第二位以下を四捨五入する場合もあります。
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
test_df.head()
| PassengerId | Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | 0 | 2 | 7.8292 | 2 | 1 | 1 | 6 |
| 1 | 893 | 3 | 1 | 2 | 7.0000 | 0 | 3 | 0 | 6 |
| 2 | 894 | 2 | 0 | 3 | 9.6875 | 2 | 1 | 1 | 6 |
| 3 | 895 | 3 | 0 | 1 | 8.6625 | 0 | 1 | 1 | 3 |
| 4 | 896 | 3 | 1 | 1 | 12.2875 | 0 | 3 | 0 | 3 |
FareBand特徴量を作成することもできます。
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4)
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)
| FareBand | Survived | |
|---|---|---|
| 0 | (-0.001, 7.91] | 0.197309 |
| 1 | (7.91, 14.454] | 0.303571 |
| 2 | (14.454, 31.0] | 0.454955 |
| 3 | (31.0, 512.329] | 0.581081 |
FareBandに基づいてFare特徴量を序数に変換します。
for dataset in combine:
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]
train_df.head(10)
| Survived | Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 0 | 0 | 1 | 0 | 3 |
| 1 | 1 | 1 | 1 | 2 | 3 | 1 | 3 | 0 | 2 |
| 2 | 1 | 3 | 1 | 1 | 1 | 0 | 2 | 1 | 3 |
| 3 | 1 | 1 | 1 | 2 | 3 | 0 | 3 | 0 | 2 |
| 4 | 0 | 3 | 0 | 2 | 1 | 0 | 1 | 1 | 6 |
| 5 | 0 | 3 | 0 | 1 | 1 | 2 | 1 | 1 | 3 |
| 6 | 0 | 1 | 0 | 3 | 3 | 0 | 1 | 1 | 3 |
| 7 | 0 | 3 | 0 | 0 | 2 | 0 | 4 | 0 | 0 |
| 8 | 1 | 3 | 1 | 1 | 1 | 0 | 3 | 0 | 3 |
| 9 | 1 | 2 | 1 | 0 | 2 | 1 | 3 | 0 | 0 |
テストセットは以下の通り。
test_df.head(10)
| PassengerId | Pclass | Sex | Age | Fare | Embarked | Title | IsAlone | Age*Class | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | 0 | 2 | 0 | 2 | 1 | 1 | 6 |
| 1 | 893 | 3 | 1 | 2 | 0 | 0 | 3 | 0 | 6 |
| 2 | 894 | 2 | 0 | 3 | 1 | 2 | 1 | 1 | 6 |
| 3 | 895 | 3 | 0 | 1 | 1 | 0 | 1 | 1 | 3 |
| 4 | 896 | 3 | 1 | 1 | 1 | 0 | 3 | 0 | 3 |
| 5 | 897 | 3 | 0 | 0 | 1 | 0 | 1 | 1 | 0 |
| 6 | 898 | 3 | 1 | 1 | 0 | 2 | 2 | 1 | 3 |
| 7 | 899 | 2 | 0 | 1 | 2 | 0 | 1 | 0 | 2 |
| 8 | 900 | 3 | 1 | 1 | 0 | 1 | 3 | 1 | 3 |
| 9 | 901 | 3 | 0 | 1 | 2 | 0 | 1 | 0 | 3 |