(この記事は、「Elixir or Phoenix Advent Calendar 2017」の6日目です)
昨日は @twinbee さんのElixirのGenStageに入門する #1でした。
はじめに
ZACKY です。
今日は「ZEAM開発ログv0.1.0 Flow / GenStage による並列プログラミング入門」です。先日の「fukuoka.ex #8 ~2018年 春のElixir入学式~」で発表した「fukuoka.ex 入学式 / ZEAM開発ログ 第2回: 並列Elixirプログラミングことはじめ〜ZEAMで目指すことは何か」を発展させた内容を連載コラム化していきます。
@piacere さんから福岡Elixirコミュニティfukuoka.exに誘われて,2018年の2月にElixirプログラミングを始めました。そこでElixirに大いなる可能性に魅力を感じ,大学に務める研究者としての10年くらいかけて取り組む研究テーマとして選んだ次第です。

fukuoka.ex のデビュー作はこちらです。ZEAM(ZACKY's Elixir Abstract Machine)という処理系の構想について語りました。

ではさっそく本題に入っていきましょう。
並行と並列の違い
まず**並行(concurrent)と並列(parallel)**の違いについて,押さえておきましょう。
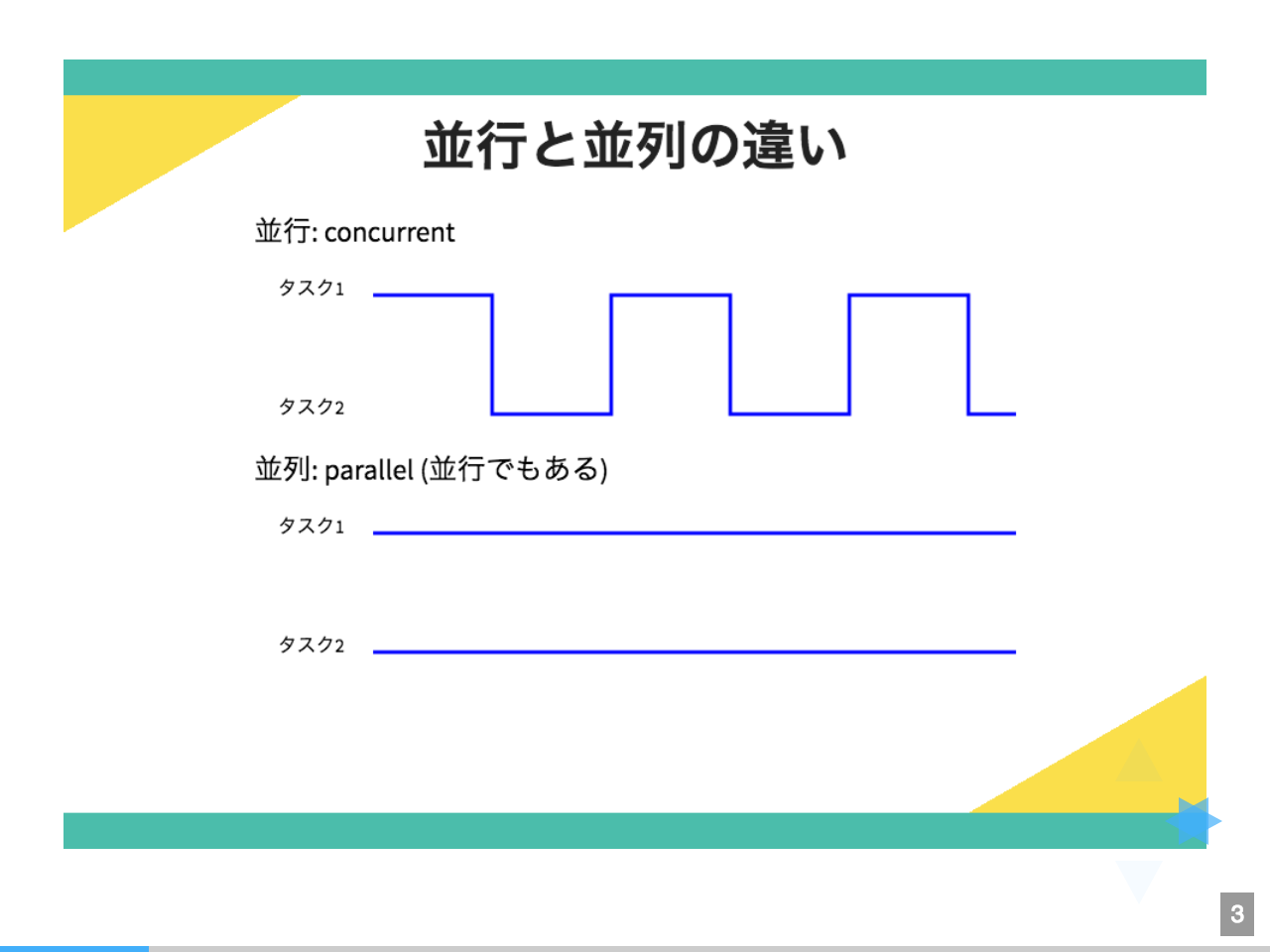
上図を見てください。
- 並列というのは,物理的にCPUやコアが複数あって,同時に複数のタスクが動いている状態を指します(上図の下)。この状態は並行でもあります。
- 一方,並列ではないが並行な状態というのは,物理的にはCPUやコアが1つだけで,ある瞬間はタスク1を,次の瞬間にはタスク2を実行するというように,高速でタスクを切り替えながら同時に複数のタスクをこなしているように見せている状態を指します(上図の上)。
- ちなみに並列でも並行でもない,タスクを1つずつ順番に動かす状態のことを逐次処理と言います。
今回 Elixir で行いたいのは,タスクを並列で動作させること,すなわち並列プログラミングです。
Flow / GenStage を使って並列プログラミングしてみよう
Elixir で並列プログラミングを行う方法はいくつかありますが,今回はそのうちの Flow / GenStage を使う方法を紹介します。
1..10
|> Flow.from_enumerable(max_demand: 1, stages: 10)
# stages で並列実行する最大数を指定する
# max_demand を指定しない,もしくは大きくしすぎると,並列実行してくれない
|> Flow.map(fn i -> Process.sleep(500); i end)
|> Enum.to_list
|> Enum.sort
- まず,
1..10というのは1〜10の範囲を表します。これは[1,2,3,4,5,6,7,8,9,10]というリストと等価です。 -
Flow.from_enumerableによって並列処理の単位に分割します。パラメータmax_demandとstagesが肝心です。-
stagesは並列実行する最大数を指定します。10を指定しているので,最大10並列で動作します。 -
max_demandは Flow がリストを分割する際の1つあたりの要素の最大数を指定します。1を指定しているので,リストを1つずつに分割して並列処理します。 - もし
max_demandを指定しない場合には,Flow は要素をある程度まとめて分割しようとするので,入力が1..10のように10個しか要素が含まれないと,並列ではなく逐次処理になってしまいます。 - 何でそんな動作をするかというと,やみくもに並列に実行するよりも,ある程度処理をまとめて逐次に処理した方が実行時間が短いことが多いからなんですね。
-
-
Flow.mapで処理を分配します。ここでは,Process.sleep(500)つまり0.5秒待つ処理を行います。- そのため,もし
max_demandを指定しないと逐次処理となって全体で5秒待つ処理になります。 - 一方,
max_demandを指定すると並列処理となって全体で0.5秒待つだけで済みます。
- そのため,もし
-
Enum.to_listでバラした処理をひとまとめのリストにします。- 並列処理すると実行順番がバラバラになるので,このときには順番がバラバラになります。
- そこで,
Enum.sortでソートして一意に揃えます。
実行してみると,max_demandを指定した状態だと一瞬で処理が終了しますが,max_demandを外すと5秒待って終了します。
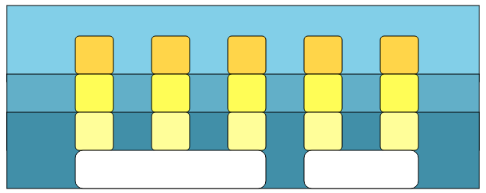
Flowが実際にどのように並列処理をしているかを模式的に表したのが上図です。
- まず
Flow.from_enumerableで処理を分配します(一番上の階層)。 -
Flow.mapを実行した時にGenStage に処理を引き渡します(上から2番目の階層)。 - GenStage は1つ1つのタスクを Erlang VM のプロセスに割り当てます(上から3番目の階層)。
- Erlang VM のプロセスは OS で CPU やコアに割り当てられます(一番下の階層)。
このように Flow はバックエンドで GenStage を使っているのですね。GenStage については昨日の @twinbee さんのElixirのGenStageに入門する #1に紹介されていますので,読んでみてください。
と,ここまでがfukuoka.ex#8で語った内容です。

Flow / GenStage を使ったベンチマーク〜整数によるロジスティック写像演算
ここからが新しい内容です。
スリープではなくロジスティック写像を使ってCPUで整数演算処理をぶん回すベンチマークを作ってみました。
ロジスティック写像についてはWikipediaの説明をご覧ください。
ここでは整数演算にするために次の漸化式を用いました。
X_{i+1} = \mu_{p}X_{i}(X_i+1) \mod p
$p$は任意の素数です。modはあまりを求める演算です。$\mu_p$は1〜$p-1$の任意の数です。$X_1$を1〜$p-1$の任意の数で始め,再帰的に$X_n$を計算します。
出典は次の通りです。ちなみに著者は大学の同僚です。
T. Miyazaki, S. Araki, S. Uehara, and Y. Nogami, “A Study of an Automorphism on the Logistic Maps over Prime Fields,” Proc. of The 2014 International Symposium on Information Theory and its Applications (ISITA2014), pp.727-731, 2014.
ちなみにこの方法で求めた値をグラフにプロットしても下図のようにはなりません。これは,この方法はロジスティック写像ではあるものの,オリジナルの方法と幾何学的性質が異なるからです。
ではElixirで実装してみましょう。
X_{i+1} = \mu_{p}X_{i}(X_i+1) \mod p
上の漸化式をElixirで実装すると次のようになります。
def calc(x, p, mu) do
rem(mu * x * (x + 1), p)
end
これを末尾再帰呼び出しで繰り返す関数を用意します。
def loopCalc(num, x, p, mu) do
if num <= 0 do
x
else
loopCalc(num - 1, calc(x, p, mu), p, mu)
end
end
【追記】 @piacere_ex さんの意見を受けて,次のコードも試しました。
def loopCalc(num, x, p, mu) when num <= 0 do x end
def loopCalc(num, x, p, mu) do
new_num = num - 1
new_calc = calc( x, p, mu )
loopCalc( new_num, new_calc, p, mu )
end
そしてこれをFlow.mapで並列に呼び出します。
def mapCalc(list, num, p, mu, stages) do
list
|> Flow.from_enumerable(stages: stages)
|> Flow.map(& loopCalc(num, &1, p, mu))
|> Enum.to_list
end
単体のベンチマークでは,漸化式を10回繰り返します。素数$p$として6,700,417を採用しました。1〜0x2000000の範囲でFlowで並列処理を行います。IO.putsで並列数と実行時間を表示します。
def benchmark(stages) do
IO.puts "stages: #{stages}"
IO.puts (
:timer.tc(fn -> mapCalc(1..0x2000000, 10, 6_700_417, 22, stages) end)
|> elem(0)
|> Kernel./(1000000)
)
end
ベンチマーク全体では,並列数は1,2,4,8,16,32,64,128の8通り設定しています。
def benchmarks() do
[1, 2, 4, 8, 16, 32, 64, 128]
|> Enum.map(& benchmark(&1))
|> Enum.to_list
end
ベンチマークの実行方法は次の通りです。
$ mix run -e "LogisticMap.benchmarks"
なお,ベンチマークのバリエーションとして他に2つ用意しました。
benchmarks2 は Flow.map(& calc(&1, p, mu)) をインライン展開して10回呼び出します。下記のmapCalc2を呼び出します。
def mapCalc2(list, p, mu, stages) do
list
|> Flow.from_enumerable(stages: stages)
|> Flow.map(& calc(&1, p, mu))
|> Flow.map(& calc(&1, p, mu))
|> Flow.map(& calc(&1, p, mu))
|> Flow.map(& calc(&1, p, mu))
|> Flow.map(& calc(&1, p, mu))
|> Flow.map(& calc(&1, p, mu))
|> Flow.map(& calc(&1, p, mu))
|> Flow.map(& calc(&1, p, mu))
|> Flow.map(& calc(&1, p, mu))
|> Flow.map(& calc(&1, p, mu))
|> Enum.to_list
end
benchmark3 は Flow.map の中で calc のパイプラインでインライン展開して10回呼び出します。下記のmapCalc3を呼び出します。
def mapCalc3(list, p, mu, stages) do
list
|> Flow.from_enumerable(stages: stages)
|> Flow.map(& (&1
|> calc(p, mu)
|> calc(p, mu)
|> calc(p, mu)
|> calc(p, mu)
|> calc(p, mu)
|> calc(p, mu)
|> calc(p, mu)
|> calc(p, mu)
|> calc(p, mu)
|> calc(p, mu)
))
|> Enum.to_list
end
また,Hexで公開しました。
ベンチマークによる検証
検証に用いたマシンの仕様は次の通りです。物理コア数4,ハイパースレッディングが有効なので8並列で動作します。
Mac Pro (Mid 2010)
Processor 2.8GHz Quad-Core Intel Xeon
Memory 16GB
ATI Radeon HD 5770 1024MB
実行結果は次の通りです。
$ mix run -e "LogisticMap.benchmarks"
Compiling 1 file (.ex)
stages: 1
52.79562
stages: 2
24.716176
stages: 4
15.016131
stages: 8
12.664873
stages: 16
12.807277
stages: 32
12.841774
stages: 64
13.158978
stages: 128
13.21785
- Mac Pro は最大8並列で動作することから,並列数が8のときが最も実行時間が短かったです。
- 並列数1から2,2から4の時の短縮度合いの方が並列数4から8のときより大きいのは,物理コアとハイパースレッディングの違いによるものでしょう。他のマシンで試しても同様の傾向が得られました。
- 並列数を8より大きく増やすと若干実行時間が延びます。これは並列数が多すぎることでタスク切り替えが発生し実行効率が悪くなるためでしょう。
それにしても Elixir では物理コア数に準じて速度がきれいに向上しますね! これは Elixir が関数型言語であるために,変数の書き換えが発生しないことにより,並列で動作させてもプロセス間通信がほとんど発生しないのでオーバーヘッドが生じないことによるものです。Elixir の可能性を感じますね!
異なるアプローチでインライン展開した benchmark2 と benchmark3 を比較してみましょう。
$ mix run -e "LogisticMap.benchmarks2"
stages: 1
54.697525
stages: 2
25.297751
stages: 4
15.763084
stages: 8
13.366235
stages: 16
13.611112
stages: 32
14.007026
stages: 64
14.013323
stages: 128
13.422258
$ mix run -e "LogisticMap.benchmarks3"
stages: 1
44.455119
stages: 2
20.67561
stages: 4
13.610704
stages: 8
11.308742
stages: 16
11.411827
stages: 32
11.714803
stages: 64
11.898896
stages: 128
11.914322
【追記】 @piacere_ex さんの意見を受けて試した結果です。
$ mix run -e "LogisticMap.benchmarks4"
stages: 1
53.469383
stages: 2
26.011707
stages: 4
15.299365
stages: 8
12.827463
stages: 16
12.947229
stages: 32
12.968043
stages: 64
13.230172
stages: 128
13.201316
Flow.map ごと展開した benchmark2 より Flow.map の中でパイプラインを形成して展開した benchmark3 の方が速いです! benchmark2 は benchmark より遅いですね。また,benchmark4はbenchmarkとあまり変わらないみたいです。
このことから,Flow.map をパイプラインで数珠繋ぎにしたい時には,Flow.map は1回に集約させて,Flow.map の中にパイプラインを作って数珠繋ぎにした方が高速であるということが言えます。要は下記みたいな感じにしましょうということです。
list
|> Flow.from_enumerable
|> Flow.map(& (&1
|> foo
|> bar
|> hoge
))
|> Enum.to_list
また,Elixirではbenchmarkのコードでも,末尾再帰の最適化はしてくれているみたいです。
実験結果を表にまとめておきましょう。
| stages(数) | benchmark(秒) | benchmark2(秒) | benchmark3(秒) | benchmark4(秒) | 備考 |
|---|---|---|---|---|---|
| 1 | 52.795620 | 54.697525 | 44.455119 | 53.469383 | |
| 2 | 24.716176 | 25.297751 | 20.675610 | 26.011707 | |
| 4 | 15.016131 | 15.763084 | 13.610704 | 15.299365 | 物理コア数 |
| 8 | 12.664873 | 13.366235 | 11.308742 | 12.827463 | 論理コア数(HT込みコア数),最速 |
| 16 | 12.807277 | 13.611112 | 11.411827 | 12.947229 | |
| 32 | 12.841774 | 14.007026 | 11.714803 | 12.968043 | |
| 64 | 13.158978 | 14.013323 | 11.898896 | 13.230172 | |
| 128 | 13.217850 | 13.422258 | 11.914322 | 13.201316 | |
| 備考 | mapの中で再帰ループ | mapを展開 | mapの中に展開 | 末尾再帰に配慮 |
いずれのベンチマークも stages がHT(ハイパースレッディング)込みのコア数の時に最速となっています。ちなみにFlowでは stages のデフォルト値は論理コア数(HT込みのコア数)になっています。そのおかげでFlowはいい感じで並列処理をしてくれるというわけです。
おわりに
- Elixir では Flow / GenStage を用いて並列プログラミングをすることが容易にできます。
- 思ったように並列性を稼げていないようならば,
Flow.from_enumerableのmax_demandを調整しましょう。 -
Flow.mapをパイプラインで数珠繋ぎにしたい時には,Flow.mapを1回に集約させて,Flow.mapの中にパイプラインを作って数珠繋ぎにした方が高速です。 - Flowでは
stagesのデフォルト値はHT込みのコア数となっているので,stagesは多くの場合最適に設定されています。
今回のベンチマークは GitHubとHexで公開しています。ぜひご利用ください。
しかし,2,3についていちいち意識するのは面倒ですね。そこで私たちが開発しているZEAM(ZACKY's Elixir Abstract Machine)という処理系では,この辺りを最適化する仕組みを導入したいなと思っています。
次回「ZEAM開発ログv0.1.1 AI/MLを爆速にしたい! Flow / GenStage でGPUを駆動できないの?」では Elixir の可能性をもっと高められないか,ZEAMでどのような最適化を取り入れると効果的か,考察してみましょう。お楽しみに!
明日は,@takasehidekiさんの「ElixirでIoT#1:IoTボードへのElixir環境の構築とEEloTツールキットの紹介」です!