(この記事は「機械学習工学 / MLSE Advent Calendar 2018」の9日目です)
「機械学習工学 / MLSE Advent Calendar 2018」8日目は @watanabe0621 さんの「初めてのMLシステム開発とデプロイ」でした。
「機械学習工学 / MLSE Advent Calendar 2018」9日目の今日は,並列プログラミング言語 Elixir(エリクサー)とそれによる機械学習ツールチェーンについてご紹介します。
@arutema47 さんの「2018年版 機械学習ハードウェアのState of the Artを考える ~CPU, GPU, TPUを添えて~」にも関連する話も言及したいと思います。
Elixir に注目する理由
私たち fukuoka.ex が Elixir に注目する理由を説明します。
今後,IoT の急速な普及などの理由でデータの流通量が爆発的に増大すると私たち fukuoka.ex は予想しています。また現在,ムーアの法則が終焉を迎えており,CPU の1コアあたりの性能向上は進んでおらず,もっぱら SIMD やマルチコアによって進んできています。
こうしたことから,並列プログラミングによって処理能力を高める必要性が高まっています。
Elixir は並列プログラミングに長けたプログラミング言語です。例えば次のようなコードをご覧ください。
1..1_000_000
|> Enum.map(foo)
|> Enum.map(bar)
- 1行目の
1..1_000_000は,1から1,000,000までの要素からなるリストを生成します。なお,数字の間の_(アンダースコア)によって,数字を分割するコンマを表します。 - 2,3行目の先頭にある
|>はパイプライン演算子で,パイプライン演算子の前に書かれている記述の値を,パイプライン演算子の後に書かれた関数の第1引数として渡します。すなわち,このような記述と等価です。Enum.map(Enum.map(1..1_000_000, foo), bar) - 2,3行目に書かれている
Enum.mapは,第1引数に渡されるリスト(など)の要素1つ1つに,第2引数で渡される関数を適用します。ここでは関数fooを各要素に適用した後,関数barを各要素に適用します。もし,fooが2倍する関数で,barが1加える関数だった時には,これらの記述により,2倍してから1加える処理を1から1,000,000までの要素に適用したリスト,[3, 5, 7, ...]を生成します。
このような**MapReduceによる記述は並列処理にとても向いています。**この例だと,リストの1つ1つの要素に対して,関数 foo と bar を順番に適用するわけですが,それぞれの要素に対する計算は互いに干渉しません。そのため,各要素の計算を異なるコアに配置して独立させて計算しても結果は変わらないですし,互いにコミュニケーションを取り合いながら同期させて計算する必要もありません。
このことを利用して,Elixir では Flow という並列処理ライブラリが開発されてきました。 Enum.map のときとコードはとても似ています。
1..1_000_000
|> Flow.from_enumerable() # リストの要素を各コアに分配する
|> Flow.map(foo)
|> Flow.map(bar)
|> Enum.to_list() # リストに戻す
このように書くだけで,並列処理をしてくれます。
こうした Elixir の特長を生かし,Phoenix というウェブフレームワークも開発されました。Phoenix はウェブフレームワークとしては最も高いレベルのレスポンス性能を有しています。
私たち fukuoka.ex は,Elixir と Phoenix こそが急速に量が増大するデータ流通の問題に対する切り札であると考えています。
また同時に,IoT センサーが収集するデータを処理する能力も質的にも量的にも高める必要があります。質的に高めるアプローチの1つが機械学習です。
そこで,私たち fukuoka.ex は,Elixir / Phoenix を中核とする機械学習ツールチェーンの研究開発に取り組んできました。その研究開発成果をご紹介します。
Keras と Elixir / Phoenix の接続
@piacere_ex さんが開発した,Elixir を Keras のデータクレンジングに活用し,かつウェブフレームワーク Phoenix で表示する方法をご紹介します。実用的には現段階ではこのような構成で機械学習ツールチェーンを構築します。これでも Elixir の並列処理能力と Phoenix の高速性の恩恵を受けることができます。
Elixir+Keras=手軽に高速な「データサイエンスプラットフォーム」 ~Flowでのマルチコア活用事例~
後述する Esuna と連携した事例もあります。
- Elixir+KerasでKaggleのタイタニック予測を解いてみた① ~UIでデータサイエンス、前処理/MLプラットフォーム「Esuna」~
- Elixir+KerasでKaggleタイタニック予測を解いてみた② ~データサイエンスプラットフォーム「Esuna」はUIでAI・MLを生成~
CPU / GPU 超並列処理系 Hastega
Hastega(ヘイスガ) @zacky1972 が研究開発している Elixir コードから CPU の SIMD 命令並列や GPGPU を行う処理系です。
Hastega の原理としては,前述の Elixir コード
1..1_000_000
|> Enum.map(foo)
|> Enum.map(bar)
は,単純で均質で大量にあるデータ 1..1_000_000 と 同じような命令列 foo |> bar で構成されます。したがって,これはGPUの基本アーキテクチャであるSIMDに適合します。次のようにOpenCLのネイティブコードで書いてみると,先ほどのコードから容易に変換できそうです。
__kernel void calc(
__global long* input,
__global long* output) {
size_t i = get_global_id(0);
long temp = input[i];
temp = foo(temp);
temp = bar(temp);
output[i] = temp;
}
このアイデアに基づいてプロトタイプを実装してみたところ,Python の NumPy ライクな GPU 実行系である CuPy での実行と比べて,3倍以上速度向上するという結果が得られました。
Hastega には SIMD 命令を用いた並列実行機能も備えようとしています。現時点では Rust によるループに対する SIMD 命令生成をそのまま利用しています。
整数演算ベンチマークについて,Elixir から,SIMD 命令を用いたマルチコアCPU駆動(rayon crate) のネイティブコードおよび OpenCL (ocl crate) による GPU 駆動のネイティブコードを呼び出す Hastega プロトタイプを開発しました。8月にプログラミング研究会とSWESTにて発表しました。当時得られた結果では Elixir からの速度向上は約4〜8倍,Pythonからの速度向上は3倍以上となりました。発表資料(論文,プレゼンテーション,ポスター)を下記に示します。


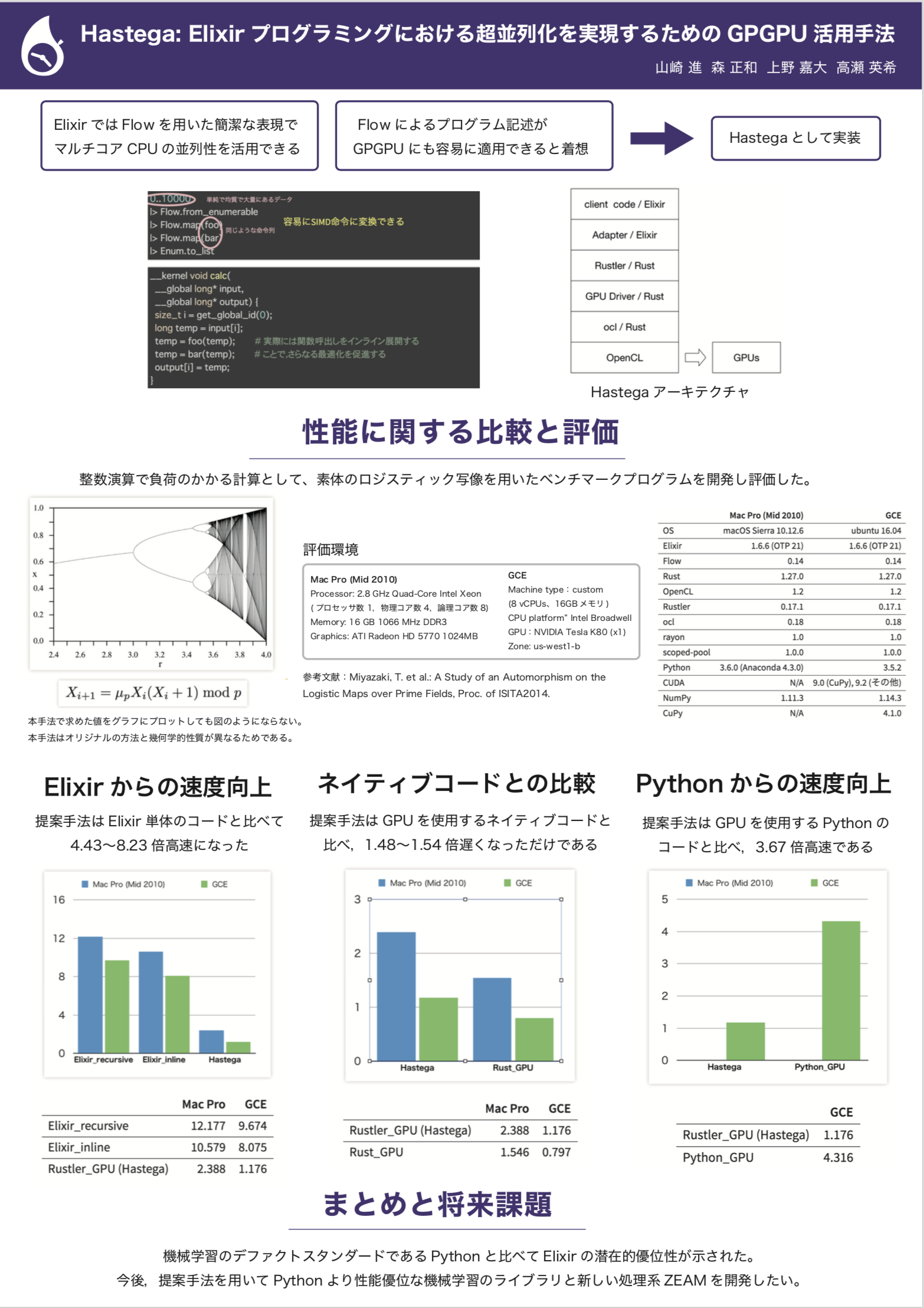
その後,複数の研究助成を受けて数々のマシンでテストする機会が得られたり,研究室学生が研究に合流してくれたりして,研究が進みました。
今度,Lonestar ElixirConf 2019 (2月28日〜3月2日 テキサス州 オースティン)でも発表してきます!
2018年のアドベントカレンダーに Hastega を特集しています。
Hastega
|> ZEAM開発ログ2018年総集編その1: Elixir 研究構想についてふりかえる(前編)
|> ZEAM開発ログ: Elixir マクロ + LLVM で超並列プログラミング処理系を研究開発中
|> ElixirとRustをつなぐRustlerを使った事例紹介
現時点ではまだ実用化に向けて実装を頑張っているという段階ですが,できるだけ早くみなさまに提供したいと考えています。
Elixir で記述する機械学習ライブラリ
「fukuoka.ex Elixir/Phoenix Advent Calendar 2018」10日目に @curry_on_a_rice さんが発表した「Elixirでニューラルネットワークを実装しようとした話」で紹介しています。
現段階では,論理演算のAND演算を学習させるというシンプルなもので,教師データを再現するような重み付けのみの実装となっており,何か未知の値を予測するためには追加実装が必要です。
データサイエンスプラットフォーム Esuna
- データサイエンスプラットフォームEsunaの前処理UI/Elixirコードは、入力データ解析の後、データ内容から自動生成されている
- Elixir+KerasでKaggleのタイタニック予測を解いてみた① ~UIでデータサイエンス、前処理/MLプラットフォーム「Esuna」~
- Elixir+KerasでKaggleタイタニック予測を解いてみた② ~データサイエンスプラットフォーム「Esuna」はUIでAI・MLを生成~
- 「Elixir Advent Calendar 2018」23日目に @piacere_ex さんが発表しますのでお楽しみに!
OpenCV と Elixir の接続
fukuoka.ex では,画像を対象に機械学習を行う場合に欠かせない OpenCV を Elixir から駆動できるようにするライブラリを近日中に開発しようとしています。お楽しみに!
まだまだ極秘の研究が...!!!
ほかにも研究を進めています! 順次公開していきます!
今後の展望〜機械学習ツールチェーンの全体像
現在, @hisaway さんとともに Elixir で記述する機械学習ライブラリを Hastega を用いて SIMD 命令や GPU を用いて高速化する研究開発を進めています。これを中核として,Esuna と OpenCV で前処理を行い,Phoenix でウェブ化するような, Elixir でほぼ完結するような機械学習ツールチェーンを構築しようとしています。
Python による機械学習ツールチェーンと比べた時の利点として,大幅なパフォーマンス向上が期待できるだろうと考えています。Python では困難なコードレベルの並列化と,現在研究開発中の Elixir 処理系である micro Elixir / ZEAM ではモジュールにまたがった大域的な最適化をサポートする予定であることによって,大幅なパフォーマンス向上を実現します。
今後の展望〜Hastega / micro Elixir / ZEAM の研究課題
@arutema47 さんの「2018年版 機械学習ハードウェアのState of the Artを考える ~CPU, GPU, TPUを添えて~」にもあるように,今後の高速化のためには,並列性の活用とメモリ律速の克服が求められます。
Hastega / micro Elixir / ZEAM では,今までに述べてきたように並列性の活用の追求をすることはもちろんですが,メモリ律速の克服についても研究を進めています。
たとえば関数にまたがってキャッシュメモリの利用を効率化してメモリアクセスを高速化するために,超インライン展開を前提にしたインストラクションスケジューリングによるキャッシュメモリの最適化を視野に入れています。
また,Elixir は,変数の値が一度決まったら不変であるというイミュータブル特性が備わっていることから,明示的に共有DBやI/Oから値を取得しない限り,再計算しても結果は変わりません。このことを利用して,メモリに記録するのではなく再計算したほうが速い場合には,積極的に再計算をするという最適化も検討しています。
行列計算のような多重の繰り返しにより計算を進める場合,どの部分を並列化するかについても最適化があります。セオリーとしては多重繰り返しの外側を並列化するようにして,内側はループで実現します。どの程度並列化するかについては裁量の余地があり,パラメータチューニングを行なって最適化していく必要があります。キャッシュメモリの最適化と合わせて,この辺りを自動化する処理系を研究開発できればと考えています。
GPGPUを高速化するにあたっては,CPUとGPUの間のデータ量やスケジューリングの最適化が重要となっています。この点についても研究をしています。
なお,「並列プログラミング言語 Elixir (エリクサー)におけるソフトウェアテスト〜基礎から最新展望まで」にもご紹介したように,実行時間を推定する技術について研究を進めているところです。
本記事で紹介したような技術により,並列性の活用とメモリ律速の克服を達成しようとしています。
Elixir を使ってみたくなったら
Elixir 入門記事
|> Excelから関数型言語マスター1回目:行の「並べ替え」と「絞り込み」
|> Excelから関数型言語マスター2回目:「列の抽出」と「Web表示」
|> Excelから関数型言語マスター3回目:WebにDBデータ表示【PostgreSQL or MySQL編】
|> Excelから関数型言語マスター4回目:Webに外部APIデータ表示
|> Excelから関数型言語マスター5回目:Webにグラフ表示
|> Excelから関数型言語マスター6回目: Vue.js+内部API(表示編)
|> Excelから関数型言語マスター7回目: Vue.js+内部API(更新編)
データサイエンスシリーズ
|> 関数型でデータサイエンス#1:様々なデータをインプットする
|> 関数型でデータサイエンス#2:インプットしたデータを変換する
|> 関数型でデータサイエンス番外編:様々な日時文字列を扱えるようにする
|> 関数型でデータサイエンス#3:インプットしたデータを集約する①
|> 関数型でデータサイエンス#4:インプットしたデータを集約する②
おわりに
「機械学習工学 / MLSE Advent Calendar 2018」9日目の今日は,並列プログラミング言語 Elixir(エリクサー)とそれによる機械学習ツールチェーンについてご紹介しましたが,いかがだったでしょうか。これを機会に今後 Elixir に注目していただければ幸いです。
次にアドベントカレンダー記事を書くのは12/10公開予定の「数値計算 Advent Calendar 2018」10日目「Elixir(エリクサー)で数値計算すると幸せになれる」です。お楽しみに!
また明日12/10の「機械学習工学 / MLSE Advent Calendar 2018」10日目は, @ohtaman さんです。こちらもお楽しみに!