(この記事は「言語実装 Advent Calendar 2018」の8日目です)
fukuoka.ex代表のpiacereです
ご覧いただいて、ありがとうございます![]()
「Esuna」というデータサイエンスプラットフォームを、Elixir/Phoenix+Vue.jsで開発・提供していますが、データ前処理のUI生成と、その後の前処理Elixirコード生成が、ちょっとした言語実装のようなものになっているので、その流れを解説したいと思います
(Advent Calendarへの投稿が1日遅れになってスミマセン…)
なお、「Phoenix」は、ElixirのWebフレームワークです
内容が、面白かったり、役に立ったら、「いいね」よろしくお願いします ![]()
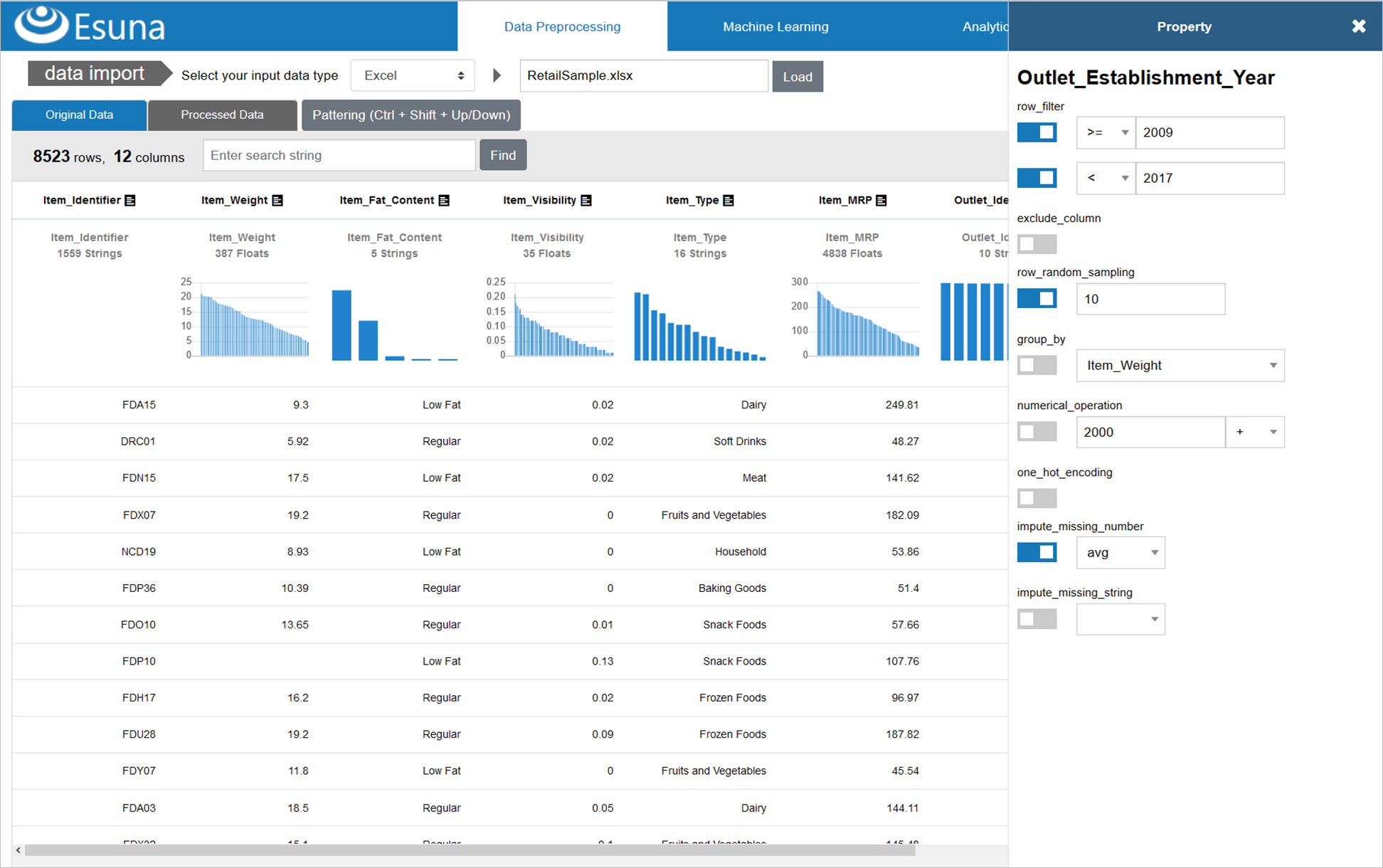
「Esuna」のデータ前処理は4つのステップで構成されている
データサイエンスプラットフォーム「Esuna」は、上記のようなUIを持っており、入力項目毎のデータ前処理を、画面右のような、プロパティウインドウで設定でき、設定した内容通りに、データ変換/集計を行うElixirコードを生成します
この処理の流れを、大まかに分けると、以下の4ステップで構成されています
① プロパティウインドウに表示する前処理UIを、Vue.jsのdata部から生成する ② 前処理UIに設定された内容がVue.jsのdata部に反映され、前処理規則としてPhoenix APIに引き渡される ③ 前処理規則を受け取ったAPIは、その内容に沿ったElixirコードを生成する ④ 生成されたElixirコードを実行し、前処理後の加工/集計データをEsunaの結果テーブルに反映するこれらの各ステップについて、説明していきます
①前処理UIは、Vue.jsのdata部から生成する
Vue.jsのdata部には、加工前のデータの列名群(original_columns)と、プロパティウインドウに出力するUIの元となる前処理規則(properties)があり、元データのインポートが行われた際に呼び出されるonImport()にて、original_columnsを元データ取得APIで更新し、その後、propertiesがoriginal_columnsに合わせて構築されます
var app = new Vue
( {
el: '#app',
data:
{
original_columns: [],
original_rows: [],
properties:
{
a5_row_filter:
{
_template:
[
{
on: false,
condition: '>=',
value: 2009,
},
{
on: false,
condition: '<',
value: 2017,
},
],
},
b5_exclude_column:
{
_template:
[
{
on: false,
},
],
},
c5_row_random_sampling:
{
_template:
[
{
on: false,
value: 20,
},
],
},
d5_group_by:
{
_template:
[
{
on: false,
column: 'Item_Weight',
group_by: 'sum',
},
],
},
…(他の前処理項目が続く)…
},
…(他のデータが続く)…
},
methods:
{
onImport: async function()
{
// Import original datas from import API
await axios.get
(
'/original_data'
)
.then( response =>
{
this.original_columns = response.data.columns
this.original_rows = response.data.rows
…(他の受信項目が続く)…
} )
// Build properties for imported columns from templates, after Delete templates
for ( var property in this.properties )
{
for ( var i = 0; i < this.original_columns.length; i++ )
{
this.properties[ property ][ this.original_columns[ i ].name ] = _.cloneDeep( this.properties[ property ]._template )
}
}
delete this.properties[ property ]._template
…(他のインポート時処理が続く)…
},
…(他のメソッドが続く)…
},
…(他の処理定義が続く)…
} )
具体例として、前処理カテゴリである「a5_row_filter」等は、配下に「_template」を持っており、「a5_row_filter」配下に、original_columnsの全列分、「_template」の複製を作り、全列用のプロパティを生成します(生成後、「_template」を削除します)
これを、全ての前処理カテゴリに対して行います
…
a5_row_filter:
{
Item_Identifier:
[
{
on: false,
condition: '>=',
value: 2009,
},
{
on: false,
condition: '<',
value: 2017,
},
],
Item_Weight:
[
{
on: false,
condition: '>=',
value: 2009,
},
{
on: false,
condition: '<',
value: 2017,
},
],
…(全列分のプロパティデータが複製される)…
},
…
UI側は、Vue.js側data部のoriginal_columns全列分に相当する前処理UIをpropertiesから生成します
たとえば、"on" アイテムは、 のスイッチを生成します
のスイッチを生成します
"value" アイテムはテキストフィールドを、"column" アイテムはインポートデータの列名コンボボックスを、"condition" アイテムは、以下のような条件判断コンボボックスを生成…といった感じで、設定項目に沿ったUIパーツを生成します

…
<div v-for="column in original_columns" v-bind:style="'display: ' + properties._display[ column.name ]">
<label class="caption">{{ column.name }}</label>
<span v-for="category_name in properties_keys" v-if="category_name != '_display'">
<label>{{ category_name.substr( 3 ) }}</label>
<div v-for="( item, item_no ) in properties[ category_name ][ column.name ]" class="grid-x grid-padding-x">
<div v-if="item.on != null" class="large-2 colummns">
<div class="switch tiny">
<input type="checkbox" v-model="item.on" v-bind:id="column.name + '_' + category_name + '_' + item_no" class="switch-input">
<label v-bind:for="column.name + '_' + category_name + '_' + item_no" class="switch-paddle"></label>
</div>
</div>
<div v-if="item.condition != null" class="large-2 colummns">
<select v-model="item.condition">
<option v-for="condition in conditions">{{ condition }}
</select>
</div>
<div v-if="item.value != null" class="large-5 colummns">
<input type="text" placeholder="Enter value" v-model="item.value" class="form-control">
</div>
<div v-if="item.column != null" class="large-7 colummns">
<select v-model="item.column">
<option v-for="column in original_columns">{{ column.name }}
</select>
</div>
…(他の前処理UI項目が続く)…
</div>
</span>
…
こうして生成されたプロパティウインドウ上の前処理UIは、Vue.js側のpropertiesと双方向データバインディングで連動しており、UIで設定した内容が、propertiesに反映されるようになります
②前処理規則をVue.jsからPhoenixの前処理コード生成APIに引き渡す
プロパティウインドウで設定した前処理規則(properties)は、Vue.js内のaxios経由で、Phoenixの前処理コード生成APIに渡されます
var app = new Vue
( {
…
methods:
{
…
onProcessedData: async function( evt )
{
// Send properties to build preprocess API
console.log( this.properties )
await axios.post
(
'/processed_data',
{
'processed_data':
{
'properties': this.properties,
…(他の送信項目が続く)…
}
}
)
…
},
…
Phoenixの前処理コード生成API側は、以下のコントローラで実装しており、PreprocessGenerator.generateにpropertiesを渡すことで、前処理Elixirコードを生成します
defmodule EsunaPreprocessWeb.ProcessedDataController do
…
def create(conn, %{"processed_data" => processed_data_params}) do
code = PreprocessGenerator.generate( processed_data_params[ "properties" ], processed_data_params[ "source" ] )
File.write!( "lib/generated/preprocessor.ex",
"""
defmodule Preprocessor do
def execute() do
#{ code }
|> Fl.write_map_list!( "datas/RetailSampleProcessed.csv" )
end
end
"""
)
json( conn, %{} )
end
…
end
③前処理コード生成APIは、前処理規則に沿ったElixirコードを生成する
APIから呼び出されるPreprocessGenerator.generateは、前処理規則(properties)のカテゴリ毎に、"on" アイテムがtrue(≒ONになっている)のものを対象に、Elixirコード生成を行っています
ポイントとなるのは、複数定義されているcategoryが、「カテゴリ名による関数パターンマッチ」をうまく活用し、カテゴリ毎のプロパティパースとElixirコード生成の分岐をスマートに処理していることです
defmodule PreprocessGenerator do
def generate( properties ) do
properties
|> Map.keys
|> Enum.map( &category( &1, properties[ &1 ] ) )
end
def category( "a5_row_filter", columns_property ) do
fomulas = columns_property
|> Map.keys
|> Enum.reduce( "", fn key, acc ->
acc <>
(
columns_property[ key ]
|> Enum.filter( fn %{ "on" => on } -> on == true end )
|> Enum.reduce( "", fn item, part -> part <> out_condition( key, item[ "condition" ], item[ "value" ] ) end )
)
end )
if fomulas != "", do: "\t\t|> Enum.filter( &( " <> cut_last_logical( fomulas ) <> ") )\n", else: ""
end
def category( "b5_exclude_column", columns_property ) do
fomulas = columns_property
|> Map.keys
|> Enum.reduce( "", fn key, acc ->
acc <>
(
columns_property[ key ]
|> Enum.filter( fn %{ "on" => on } -> on == true end )
|> Enum.reduce( "", fn _item, part -> part <> out_key( key ) end )
)
end )
if fomulas != "", do: "\t\t|> Enum.map( &( Map.drop( &1, [ " <> cut_last_comma( fomulas ) <> " ] ) ) )\n", else: ""
end
def category( "c5_row_random_sampling", columns_property ) do
fomulas = columns_property
|> Map.keys
|> Enum.reduce( "", fn key, acc ->
acc <>
(
columns_property[ key ]
|> Enum.filter( fn %{ "on" => on } -> on == true end )
|> Enum.reduce( "", fn item, part -> part <> out_number_value( item[ "value" ] ) end )
)
end )
if fomulas != "", do: "\t\t|> Enum.take_random( " <> cut_last_comma( fomulas ) <> " )\n", else: ""
end
…(他の前処理カテゴリを処理する関数が続く)…
def category( _key, _item ), do: ""
def out_key( key ), do: "\"#{ key }\", "
def out_number_value( value ), do: "#{ value }, "
def out_string_value( value ), do: "\"#{ value }\", "
def out_condition( key, condition, value ), do: "&1[ \"#{ key }\" ] #{ condition } \"#{ value }\" && "
def cut_last_comma( str ), do: str |> String.slice( 0..-3 )
def cut_last_logical( str ), do: str |> String.slice( 0..-4 )
まず、前処理規則(properties)は、PreprocessGenerator.generateに、以下の形で渡されてきます
%{
"a5_row_filter" =>
%{
…
"Outlet_Establishment_Year" =>
[
%{"condition" => ">=", "on" => true, "value" => "2006"},
%{"condition" => "<", "on" => true, "value" => 2017}
],
"Outlet_Identifier" =>
[
%{"condition" => ">=", "on" => false, "value" => 2009},
%{"condition" => "<", "on" => false, "value" => 2017}
],
…
},
"b5_exclude_column" =>
%{
…
"Outlet_Establishment_Year" => [%{"on" => false}],
"Outlet_Identifier" => [%{"on" => false}],
…
},
},
…
たとえば、「a5_row_filter」は、行の絞り込みをするための範囲設定として、以下のようなデータ構造でcolumns_propertyが渡されてくるので、全列に対し、「"condition" アイテムによる条件判断(コンボボックスで設定した、「<」「<=」「>」「>=」「==」「!=」のいずれか)」と「"value" アイテムに設定された値」の組み合わせを式として生成し、その後、Enum.filterの内部関数に埋め込むことで、前処理Elixirコードを生成します
%{
…
"Outlet_Establishment_Year" =>
[
%{"condition" => ">=", "on" => true, "value" => "2006"},
%{"condition" => "<", "on" => true, "value" => 2017}
],
"Outlet_Identifier" =>
[
%{"condition" => ">=", "on" => false, "value" => 2009},
%{"condition" => "<", "on" => false, "value" => 2017}
],
…
},
同じ要領で、「b5_exclude_column」であればEnum.mapとMap.dropの組み合わせを、「c5_row_random_sampling」であればEnum.take_randomを生成…といった感じで、各カテゴリに沿った式と、前処理Elixirコードを生成します
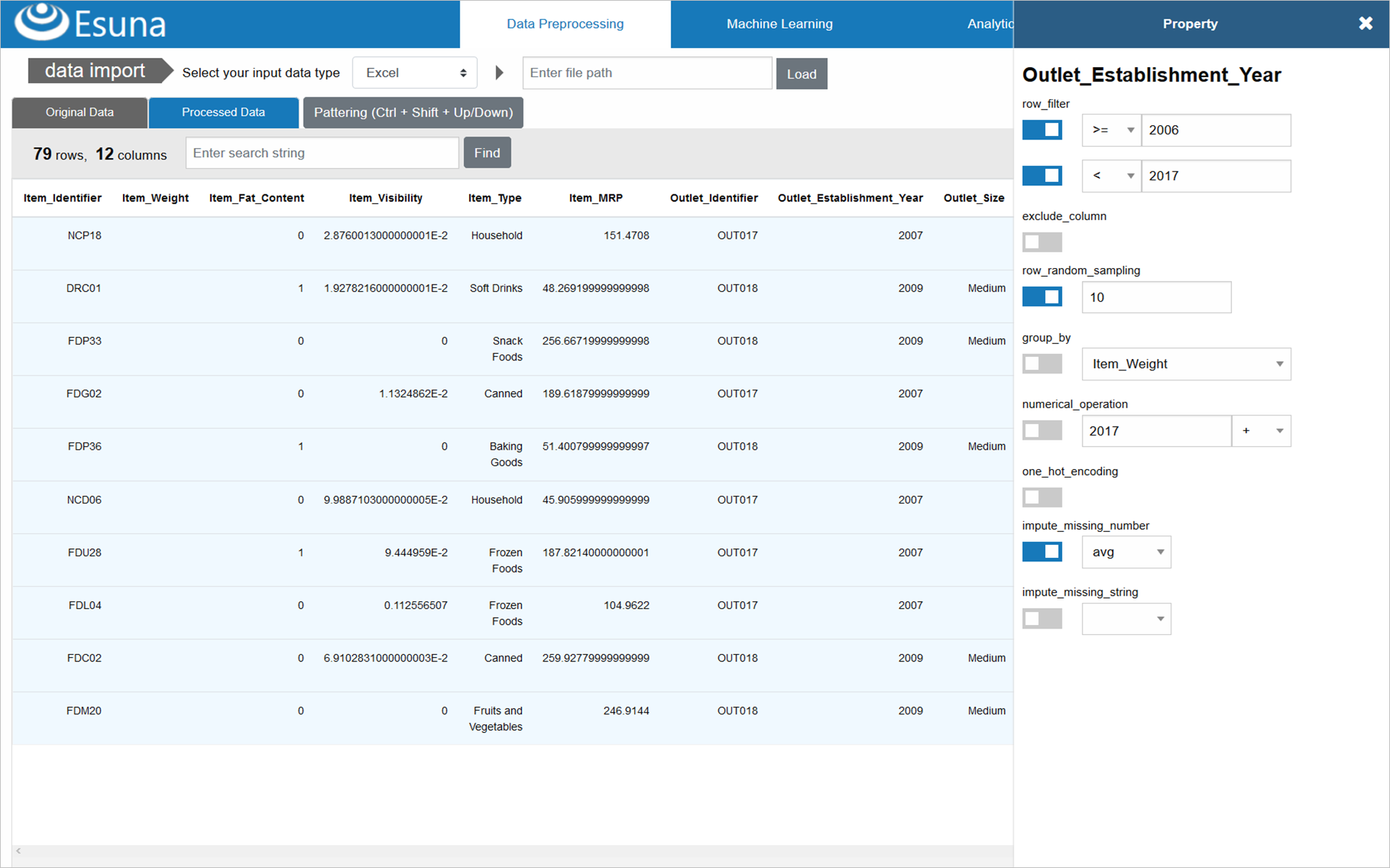
生成されたElixirコードは、以下のような感じで、前処理UIに設定した通りのデータ加工/集計を、ロード対象の元データに対して、Elixirのパイプで縦に並べた処理となります
defmodule Preprocessor do
def execute() do
Excel.load_map( "RetailSample.xlsx", Excel.sheet_names( "RetailSample.xlsx" ) |> List.first )
|> Enum.filter( &( &1[ "Outlet_Establishment_Year" ] >= "2006" && &1[ "Outlet_Establishment_Year" ] < "2017" ) )
|> Enum.map( &( Map.drop( &1, [ "Item_Weight" ] ) ) )
|> Enum.take_random( 10 )
|> MapUtil.get_dummies( [ "Item_Fat_Content" ] )
|> Fl.write_map_list!( "datas/RetailSampleProcessed.csv" )
end
end
Elixirは、データに対する加工/集計処理が、Enumで大抵、揃っているため、こうした前処理を作り込むのも、非常にカンタンです
④生成された前処理Elixirコードを実行し、結果データ反映
生成された前処理Elixirコードは、前処理Elixirコード実行APIの呼び出し時、PhoenixのAutoReloadによってビルドされ、その実行結果(processed_columns、processed_rows)をAPIの戻りとして受信します
var app = new Vue
( {
…
data:
{
processed_columns: [],
processed_rows: [],
…(他のデータが続く)…
},
methods:
{
…
onProcessedData: async function( evt )
{
…
// Load preprocessed datas
await axios.get
(
'/processed_data'
)
.then( response =>
{
this.processed_columns = response.data.columns
this.processed_rows = response.data.rows
…(他の受信項目が続く)…
} )
…
},
…
受信したprocessed_columns、processed_rowsは、Vue.jsの双方向データバインディングにより、「Processed data」タブ配下にあるデータ表示テーブルへと表示反映されます
終わり
データサイエンスプラットフォーム「Esuna」の前処理UI生成と、前処理Elixirコード生成について、実際のコードを交えて解説しましたが、いかがでしたでしょうか?
もしかしたら、今回のコラム内容は、私の他コラムと比べ、けっこう実践的で、少し複雑なデータ構造とその処理を扱っているため、Vue.jsとPhoenixの繋ぎ込み部分や、Elixirコード生成処理が難解に感じられたかも知れません
しかし、ElixirとVue.jsの記述能力の高さが相まって、他言語で同等の処理を書いたときと、比べ物にならない位シンプルに造られており、手入力したコードは、HTMLも含め、800行程度です
また、SPA(Single Page Application)+内部API数本で構成されており、アーキテクチャも単純です
この全容は、近々、OSSとして公開されるEsunaをお待ちください
p.s.「いいね」よろしくお願いします
ページ左上の  や
や  のクリックを、どうぞよろしくお願いします
のクリックを、どうぞよろしくお願いします![]()
ここの数字が増えると、書き手としては「ウケている」という感覚が得られ、連載を更に進化させていくモチベーションになりますので、もっとElixirネタを見たいというあなた、私達と一緒に盛り上げてください!![]()