クエリと統計と実行計画
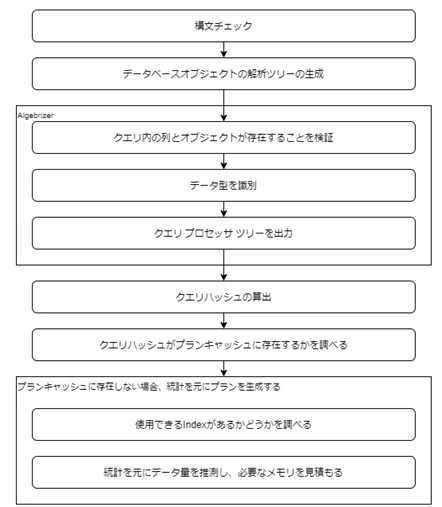
SQL Serverに限らず、コストベースで実行計画を作るRDBMSはクエリをもとに候補となるアクセスパスを作成し、複数の候補を統計を元に評価して、効率の良いものを実行計画として採用します。
また、クエリが過去に実行したもの同じものだった場合は実行計画はキャッシュから読みだされ、前回実行した時と同じものが利用されます。
同じクエリとみなされる条件は厳しくて、厳格に同じテキストである必要があります。コメントや空白文字、大文字、小文字の違い等も許容されません。
統計が更新されるタイミング
以下の場合に統計は自動更新されます。
- 手動で統計が更新された場合(INDEXの再構築も含む)
- テーブルに対する変更が閾値を超えた場合
下記のサイトを信じると、自動更新の発動の閾値はテーブルのレコード数に1000を掛けた値の平方根ということになっているようです。
統計の自動更新を止める
以下で統計の自動更新を止めることができます(デフォルトはON)。
ALTER DATABASE sample SET AUTO_UPDATE_STATISTICS OFF;
特定のINDEXの統計の自動更新を名指しで止める場合は以下のオプションを指定します。
ALTER INDEX IDX_M_ZIPCODE_ADDRESS_ADDRESS1
ON M_ZIPCODE_ADDRESS SET (STATISTICS_NORECOMPUTE = OFF);
SSMSからやる場合はこんな感じです。
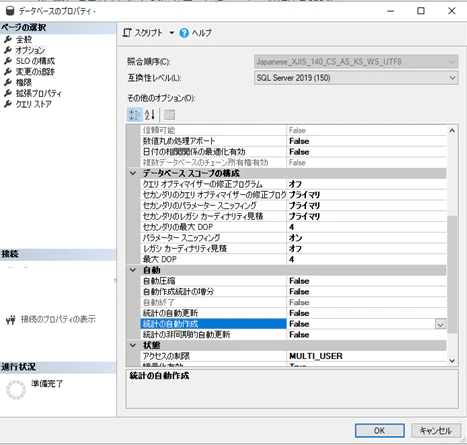
手動で統計を更新する
テーブルを名指しで指定して、統計を更新する場合は以下のように指定します。
UPDATE STATISTICS M_ZIPCODE_ADDRESS
テーブルとインデックスを名指しで指定して、統計を更新する場合は以下のように指定します。
WITH FULLSCANはオプションで、指定すると全件を確認して更新されます。
UPDATE STATISTICS M_ZIPCODE_ADDRESS IDX_M_ZIPCODE_ADDRESS_ADDRESS1 WITH FULLSCAN
以下のようにINDEXをREBUILDした場合もUPDATE STATISTICS ... WITH FULLSCANと同じ効果があります。WITHで指定しているONLINEオプションとRESUMABLEオプションは多くの場合に必須です。ONLINEオプションがないとテーブルがロックされ、RESUMABLEオプションがないと想定以上に時間がかかっても一時停止できません。
ALTER INDEX IDX_M_ZIPCODE_ADDRESS_ADDRESS1
ON M_ZIPCODE_ADDRESS REBUILD WITH(ONLINE = ON, RESUMABLE = ON)
統計を確認する
動きが分からなくなるので、まず統計の自動更新を止めます。
動作を確認するための準備をします。テーブルとインデックスは以下だけを使うことにします。
CREATE TABLE [dbo].[T_NMT_STATUS](
[NMT_ID] [nvarchar](14) NOT NULL,
[DRIVERID] [int] NOT NULL,
[STATUS] [int] NOT NULL,
CONSTRAINT [PK_T_NMT_STATUS] PRIMARY KEY CLUSTERED
(
[NMT_ID] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE INDEX IX_T_NMT_STATUS ON [T_NMT_STATUS] (STATUS)
ストアドプロシージャも作ります。
CREATE PROCEDURE [dbo].[P_T_NMT_STATUS]
(
@STATUS INT
)
AS
BEGIN
SELECT * FROM [T_NMT_STATUS] WHERE [STATUS] = @STATUS
END
GO
データを準備します。
| STATUS | 件数 |
|---|---|
| 99 | 1000000 |
| 0 | 100 |
| 1 | 100 |
| 2 | 100 |
INSERT INTO [T_NMT_STATUS] ([NMT_ID], [DRIVERID], [STATUS])
SELECT
TOP 1000000
'999999' + CONVERT(NVARCHAR(MAX), ROW_NUMBER() OVER (ORDER BY o1.object_id)) AS [NMT_ID], 10000 AS [DRIVERID], 99 AS [STATUS]
FROM sys.all_objects o1, sys.all_objects o2
GO
INSERT INTO [T_NMT_STATUS] ([NMT_ID], [DRIVERID], [STATUS])
SELECT TOP 100
'000000' + CONVERT(NVARCHAR(MAX), ROW_NUMBER() OVER (ORDER BY o1.object_id)) AS [NMT_ID], 20000 AS [DRIVERID], 0 AS [STATUS]
FROM sys.all_objects o1, sys.all_objects o2
GO
INSERT INTO [T_NMT_STATUS] ([NMT_ID], [DRIVERID], [STATUS])
SELECT
TOP 100
'111111' + CONVERT(NVARCHAR(MAX), ROW_NUMBER() OVER (ORDER BY o1.object_id)) AS [NMT_ID], 30000 AS [DRIVERID], 1 AS [STATUS]
FROM sys.all_objects o1, sys.all_objects o2
GO
INSERT INTO [T_NMT_STATUS] ([NMT_ID], [DRIVERID], [STATUS])
SELECT
TOP 100
'222222' + CONVERT(NVARCHAR(MAX), ROW_NUMBER() OVER (ORDER BY o1.object_id)) AS [NMT_ID], 40000 AS [DRIVERID], 2 AS [STATUS]
FROM sys.all_objects o1, sys.all_objects o2
GO
統計がまったくない状態の挙動確認
DBCC SHOW_STATISTICS ('T_NMT_STATUS','IX_T_NMT_STATUS') WITH HISTOGRAM
からっぽですね

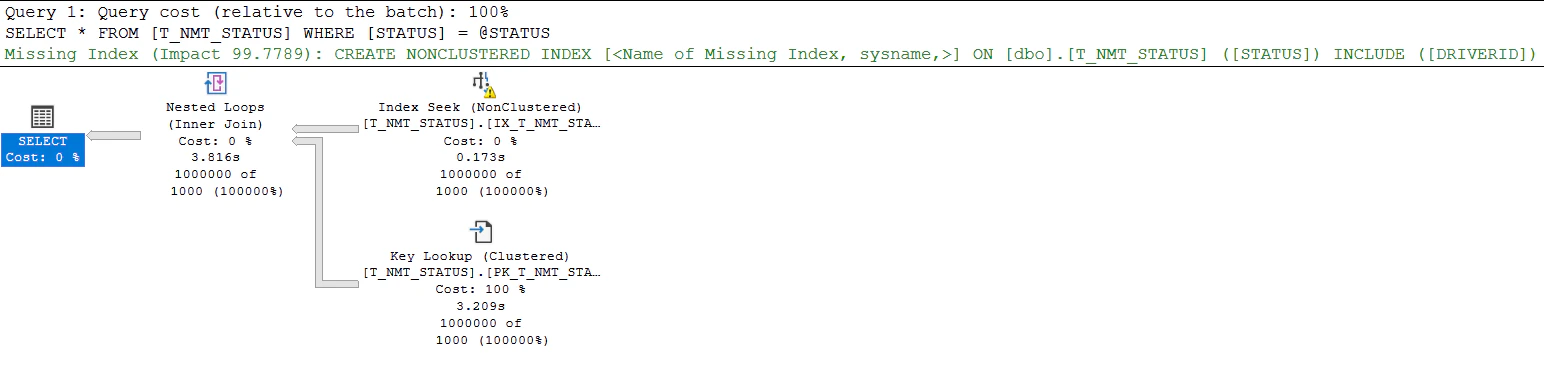
クエリを実行してどんな実行計画が作られるのか確認します。
EXEC P_T_NMT_STATUS 99
DBCC FREEPROCCACHE -- プランキャッシュを消す
0, 1, 2の場合も同じです。
EXEC P_T_NMT_STATUS 1
DBCC FREEPROCCACHE -- プランキャッシュを消す
統計が何も作られていない状態のときの動きを確認してみました。
すべてのパラメータでIX_T_NMT_STATUSをSEEKしてから、PK_T_NMT_STATUSにKey Lookupするという実行計画になりました。
FULLSCANで統計を作る
FULLSCANで統計を作ってみます。
UPDATE STATISTICS T_NMT_STATUS IX_T_NMT_STATUS WITH FULLSCAN
DBCC SHOW_STATISTICS ('T_NMT_STATUS','IX_T_NMT_STATUS') WITH HISTOGRAM
以下のように表示されました。

これはこういうことなのかなと理解しています。
| No | 一個前の境界値~XX | XXの件数 | 一個前の境界値~XXの値の種類数 | 一個前の境界値~XXの値の平均行数 |
|---|---|---|---|---|
| 1 | ~0 | 100 | 0 | 1 |
| 2 | ~2 | 100 | 1 | 100 |
| 3 | ~99 | 1000000 | 0 | 1 |
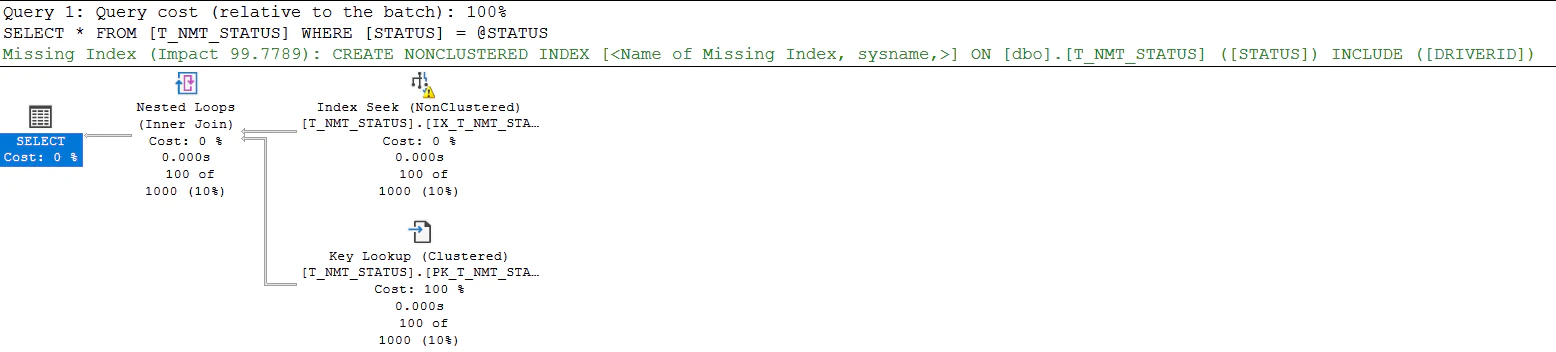
99の場合を確認すると、クラスタインデックスのSCANになりました。
EXEC P_T_NMT_STATUS 99
DBCC FREEPROCCACHE -- プランキャッシュを消す

一方、0, 1, 2の場合を確認すると、前回と同じIX_T_NMT_STATUSをSEEKしてから、PK_T_NMT_STATUSにKey Lookupするという実行計画になりました。
EXEC P_T_NMT_STATUS 1
DBCC FREEPROCCACHE -- プランキャッシュを消す
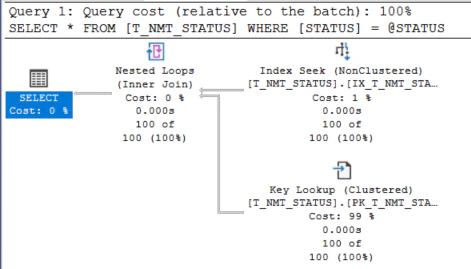
統計が作られたことで選択性がない99の場合と、選択性がある0, 1, 2の場合で異なる実行計画が作られるようになったのです。
統計の範囲外の値の挙動
さきほど確認した統計には99より大きい値の分布については何も情報がありませんでした。この時に仮にステータス100が指定されたらどうなるのか確認します。
100万件入れてみます。
INSERT INTO [T_NMT_STATUS] ([NMT_ID], [DRIVERID], [STATUS])
SELECT
TOP 1000000
'888888' + CONVERT(NVARCHAR(MAX), ROW_NUMBER() OVER (ORDER BY o1.object_id)) AS [NMT_ID], 10000 AS [DRIVERID], 100 AS [STATUS]
FROM sys.all_objects o1, sys.all_objects o2
GO
実行計画を確認すると、IX_T_NMT_STATUSをSEEKしてから、PK_T_NMT_STATUSにKey Lookupするという実行計画になりました。
EXEC P_T_NMT_STATUS 100
DBCC FREEPROCCACHE -- プランキャッシュを消す
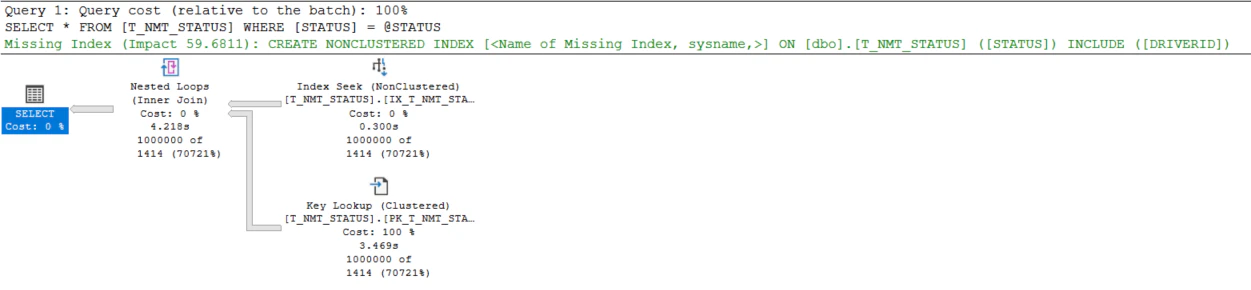
統計の自動更新の閾値を超えているので、自動更新が有効であれば99の場合と同じくSCANになったのだろうと思いますが、今回は自動更新が止まっていて、統計に何も情報がないためこうした動きになったようです。
今度は-1に1000000件、-2に100件入れてみます。統計では~0の値のバリエーションは0で平均の行数は1となっていました。
INSERT INTO [T_NMT_STATUS] ([NMT_ID], [DRIVERID], [STATUS])
SELECT
TOP 1000000
'777777' + CONVERT(NVARCHAR(MAX), ROW_NUMBER() OVER (ORDER BY o1.object_id)) AS [NMT_ID], 10000 AS [DRIVERID], -1 AS [STATUS]
FROM sys.all_objects o1, sys.all_objects o2
GO
INSERT INTO [T_NMT_STATUS] ([NMT_ID], [DRIVERID], [STATUS])
SELECT
TOP 100
'666666' + CONVERT(NVARCHAR(MAX), ROW_NUMBER() OVER (ORDER BY o1.object_id)) AS [NMT_ID], 10000 AS [DRIVERID], -2 AS [STATUS]
FROM sys.all_objects o1, sys.all_objects o2
GO
-1の場合の実行計画も、-2の場合も実行計画も以下になります。
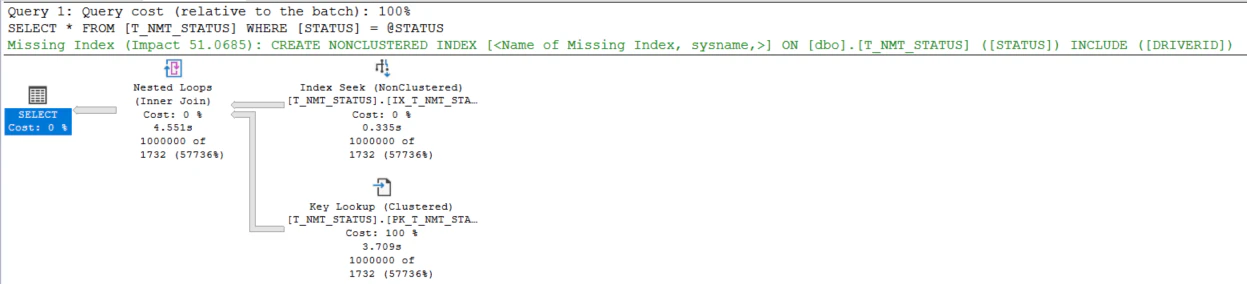
正確に言えば統計の範囲外の値は100のときで、-1と-2は統計の範囲外ではないんだと思います。
-1と-2でIX_T_NMT_STATUSをSEEKしてから、PK_T_NMT_STATUSにKey Lookupするのは区間の平均行数が1になっているからなんだろうと。
範囲外になる100の場合は統計がまったく作られていなかった場合と同じで、出現頻度の低い値だと見なされているのかなと思っていますが、この辺りの解説してくれている資料を見つけられませんでした。
統計を移植する
まず、統計の移植元になる環境と同じ照合順序を指定して、データベースを作り、統計の自動更新を無効にします。
統計の移植元になるデータベースを選択して、Tasksを選び、Generate Scriptsを選びます。
対象のテーブルを選択します。
Advancedを選びます。
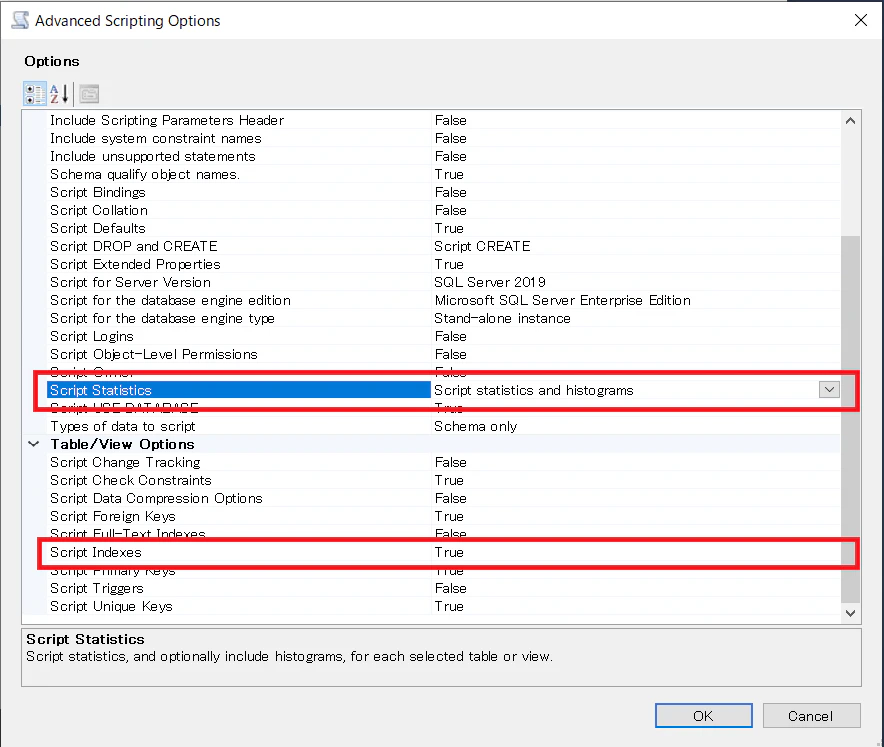
赤枠のオプションを変更して、統計とインデックスがスクリプト化されるようにします。
どこにスクリプトを書き出したいのかを選択します。ここではnew query windowsにします。
データベース名を変更してスクリプトを実行します。
これで統計を移植できました。
クエリを実行すると、中身は移植していないので空っぽですが、統計が移植されているので、期待どおりIndex Scanになっています。
SELECT
*
FROM T_NMT_STATUS
WHERE STATUS = 99

シリーズ SQL Server/SQL Database再入門
なんとなくならSQL Serverを使えている人のためのSQL Server/SQL DatabaseのTips集です。