パーティションテーブルを作る
SQL Serverの場合は物理的な配置先となるファイルグループをパーティションごとに割り当てることができますが、SQL Database では、PRIMARYファイル グループのみがサポートされています。
PARTITION FUNCTIONは値をパーティションに分割するための関数です。以下の場合は固定値でマッピングしています。
CREATE PARTITION FUNCTION partitionFunction (int)
AS RANGE LEFT FOR VALUES (0, 1, 2, 3, 4, 5, 6, 7, 8, 9) ;
GO
PARTITION SCHEMEはPARTITION FUNCTIONによって分割されたPARTITIONとファイル グループをマッピングするためのものなのですが、SQL Databaseの場合はPRIMARYしか使えないのでほぼ定型文になります。
CREATE PARTITION SCHEME partitionScheme1
AS PARTITION partitionFunction
ALL TO ('PRIMARY');
GO
以下のテーブルを試しに分割してみます。
CREATE TABLE PartitionTable (
col1 INT IDENTITY(1, 1),
col2 AS col1 % 10 PERSISTED,
col3 NVARCHAR(10),
CONSTRAINT PK_PartitionTable PRIMARY KEY CLUSTERED (col1, col2)
) ON partitionScheme1 (col2) ;
GO
検証用のデータを流し込んでみます。
INSERT INTO PartitionTable
(col3) VALUES ('AAA')
GO 10000
INSERT INTO PartitionTable
(col3) VALUES ('BBB')
GO 10000
INSERT INTO PartitionTable
(col3) VALUES ('CCC')
GO 10000
INSERT INTO PartitionTable
(col3) VALUES ('DDD')
GO 10000
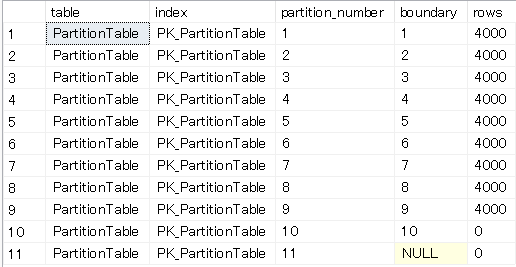
パーティション別の状態を確認してみましょう。
SELECT
t.name AS [table],
i.name AS [index],
p.partition_number,
r.value AS boundary,
p.rows
FROM sys.tables AS t
JOIN sys.indexes AS i
ON t.object_id = i.object_id
JOIN sys.partitions AS p
ON i.object_id = p.object_id AND i.index_id = p.index_id
JOIN sys.partition_schemes AS s
ON i.data_space_id = s.data_space_id
JOIN sys.partition_functions AS f
ON s.function_id = f.function_id
LEFT JOIN sys.partition_range_values AS r
ON f.function_id = r.function_id and r.boundary_id = p.partition_number
WHERE t.name = 'PartitionTable' AND i.type <= 1
ORDER BY p.partition_number;
11個のパーティションができていて、1から10までには4000件ずつ入っていますね。

パーティションテーブルにクエリを投げる
以下のクエリはパーティション分割されていなければ論理読み取りの回数はインデックスの深さと一致するはずですが、今回の結果は違います。
SET STATISTICS IO, TIME ON
SELECT
*
FROM PartitionTable
WHERE col1 = 100
SET STATISTICS IO, TIME OFF
論理読み取り数は20になっていますね。これは11あるパーティションのうち一つの中身は空で、それ以外の2階層あるインデックスをSEEKしたので、10 * 2 = 20になったのです。

パーティションの分割列を指定してみましょう。
SET STATISTICS IO, TIME ON
SELECT
*
FROM PartitionTable
WHERE col1 = 100 AND col2 = 0
SET STATISTICS IO, TIME OFF
今度はどのパーティションを読みに行ったらいいのかわかるので論理読み取りの数が2になりました。

パーティションを指定してTRUNCATEする
WITH(PARTITIONS(パーティション番号))で指定します。
TRUNCATE TABLE PartitionTable WITH(PARTITIONS(1))
パーティション番号 = 1の件数がゼロになっています。

パーティションを追加する
次に使うスキーマを指定したあと、境界になる値を指定します。
ALTER PARTITION SCHEME partitionScheme1 NEXT USED 'PRIMARY'
ALTER PARTITION FUNCTION partitionFunction() SPLIT RANGE (10)

パーティションをマージする
境界値として消したい値を指定します。
ALTER PARTITION FUNCTION partitionFunction() MERGE RANGE (0)
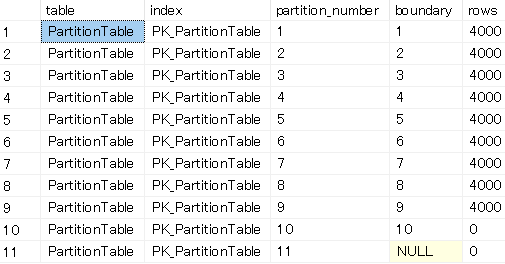
動きが分かるように値が入っているところをマージしてみます。
ALTER PARTITION FUNCTION partitionFunction() MERGE RANGE (4)

もう一度分割してみます。
ALTER PARTITION SCHEME partitionScheme1 NEXT USED 'PRIMARY'
ALTER PARTITION FUNCTION partitionFunction() SPLIT RANGE (4)
シリーズ SQL Server/SQL Database再入門
なんとなくならSQL Serverを使えている人のためのSQL Server/SQL DatabaseのTips集です。