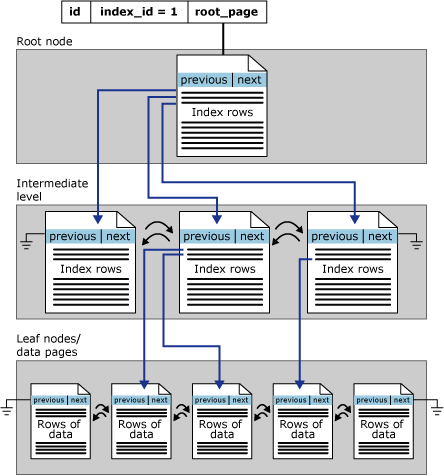
クラスター化インデックスと非クラスター化インデックスの構造
本題のIndex SeekとIndex Scanの話に入る前に、以下の公式サイトを元にSQL Serverで基本となるクラスター化インデックスと非クラスター化インデックスについて確認しておきましょう。
SQL Server のインデックスのアーキテクチャとデザイン ガイド - SQL Server | Microsoft Docs
B-Treeインデックス
図は次のクラスター化インデックスと非クラスター化インデックスの図をみてください。
- ツリー内の各ページをインデックス ノードと呼びます
- 最上位ノードはルート ノードと呼びます
- インデックス内の最下位ノードをリーフ ノードと呼びます
- ルート ノードとリーフ ノードの間にあるノードは中間レベルノードと呼びます
- ルート ノードと中間レベル ノードの各インデックス行には、キー値と、B ツリー内の中間レベル ページかインデックスのリーフ レベルのデータ行のいずれかへのポインターが含まれています
クラスター化インデックス
- クラスター化インデックスでは、リーフ ノードに基になるテーブルのデータ ページが含まれています。
- 特に指定しないと、主キーがクラスター化インデックスになります。
- クラスター化インデックスがない状態をヒープと呼びますが、この状態だとSQL Serverは断片化を解消できないのでSQL Serverでは事実上クラスター化インデックスは必須です。
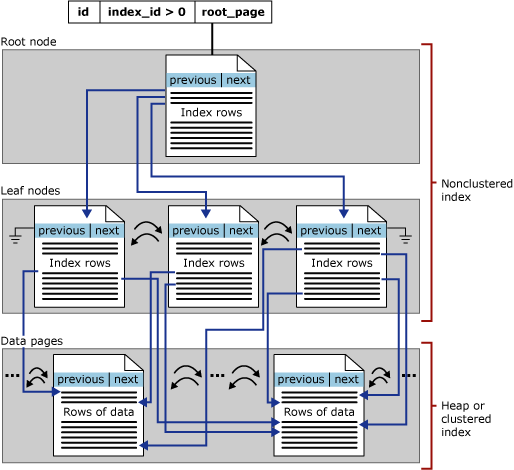
非クラスター化インデックス
- 非クラスター化インデックスでは、リーフ ノードにヒープもしくはクラスター化インデックスのポインターが含まれています。
インデックスの構造を確認する
確認するためのテーブルを作ってみます。
ちなみにGOで実行回数を指定できるのですが、私は先月まで知りませんでした。
CREATE TABLE [dbo].[test](
[id] [bigint] IDENTITY(1,1) NOT NULL PRIMARY KEY,
[name] [nvarchar](50) NOT NULL,
[address] [nvarchar](200) NOT NULL,
[rgdt] [datetime] NOT NULL
)
GO
INSERT INTO test (name, address, rgdt)
VALUES('a000', 'a000', GETDATE())
GO 300000
確認してみましょう。
SELECT
o.name,
d.index_id,
d.index_depth,
d.index_level,
d.index_type_desc,
d.page_count,
d.record_count,
d.avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats ( DB_ID(),
OBJECT_ID('[dbo].[test]'),
NULL,
NULL,
'DETAILED') d
JOIN sys.objects o on o.object_id =
d.object_id WHERE d.index_type_desc = 'CLUSTERED INDEX'
このインデックスの場合は、深さが3で、リーフのページ数は1745、レコード数は30000になっています。
中間ノードのページ数は7で、レコード数は1745ですね。

非クラスター化インデックスの場合も確認してみます。
CREATE NONCLUSTERED INDEX IDX_test_rgdt ON test (rgdt) INCLUDE (name);

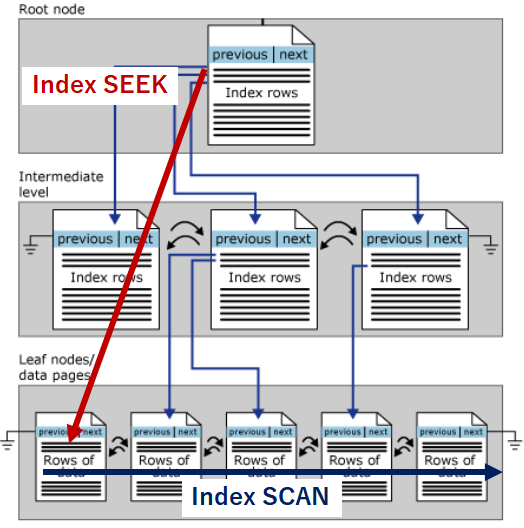
Index SeekとIndex Scan
Index SeekとIndex Scanの違いを図で表すと以下のような感じになります。Index Seekは探索している対象を一つ一つ、ルートからリーフに向かってアクセスし、SCANはリーフを横串でアクセスして対象を探します。
どちらのアクセスになるかはコスト計算をしてオプティマイザが決めてしまうので、今回はヒントで名指しして動きをみてみます。
SET statistics io on
SELECT
*
FROM test WITH(FORCESEEK)
WHERE id IN (906170, 906171)
論理読み取りの数が深さと探索している値の数を掛けた値になっていますね。
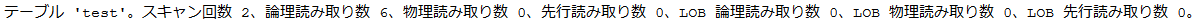
SET statistics io on
SELECT
*
FROM test WITH(FORCESCAN)
WHERE id IN (906170, 906171)
論理読み取りの数がクラスター化インデックスのリーフのページ数と同じ値になっています。
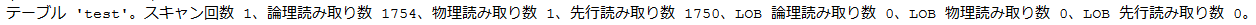
キーで範囲検索をしてみます。
SET STATISTICS IO, TIME ON
SELECT
*
FROM test
WHERE id BETWEEN 130 AND 140
SET STATISTICS IO, TIME OFF
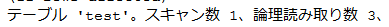
別の範囲でも検索してみます。
SET STATISTICS IO, TIME ON
SELECT
*
FROM test
WHERE id BETWEEN 20 AND 30
SET STATISTICS IO, TIME OFF

どちらの場合も今回はINDEX SEEKになりました。
論理読み取りの数が違うのは130と140の間にData Pageの境界があるからです。
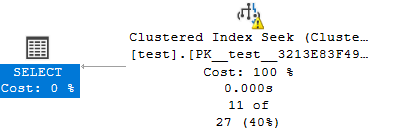
レコード数とINDEXの関係
5件だけ入れてみましょう。
INSERT INTO test (name, address, rgdt)
VALUES('a000', 'a000', GETDATE())
GO 5
この時のインデックスは1階層しかありません。

190行くらい入れると二階層になります。

もう少し細かく中身をみてみます。
SELECT
i.type_desc AS [index_type],
i.name AS [index],
page_level AS [page_level],
allocated_page_page_id AS [page_id],
page_type_desc,
previous_page_page_id,
next_page_page_id,
p.allocated_page_file_id AS [file_id]
FROM
sys.indexes i CROSS APPLY
sys.dm_db_database_page_allocations(DB_ID('sample'), i.object_id, i.index_id, NULL, 'DETAILED') p
WHERE i.name LIKE '%test%' AND page_type_desc IS NOT NULL
INDEX_PAGEの289が1つ、DATA_PAGEの288と290ができています。
これは、もともとはDATA_PAGEの288だけがあって、ここに収まりきらなくなったので、INDEX_PAGEの289とDATA_PAGEの290ができたのです。

このようにレコード数が増えてDATA_PAGEに収まらなくなると、ページが分割され、DATA_PAGEの親になるINDEXページが作られます。
さらにレコードを追加し続けると以下のように一つのINDEX_PAGEで収まらなくなり、3階層になります。

理屈ではさらに量が増えると4階層になる可能性もあるんだと思いますが見たことがありません。
4階層になる前にパーティションで分割することになって結果として3階層までで収まるのことなるだろうと思います。
Indexの中身
Data pageが2個、Index pageが1個しかない単純な状態で確認してみます。
SELECT
i.type_desc AS [index_type],
i.name AS [index],
page_level AS [page_level],
p.extent_page_id,
allocated_page_page_id AS [page_id],
page_type_desc,
previous_page_page_id,
next_page_page_id,
p.allocated_page_file_id AS [file_id]
FROM
sys.indexes i CROSS APPLY
sys.dm_db_database_page_allocations(DB_ID('sample'), i.object_id, i.index_id, NULL, 'DETAILED') p
WHERE i.name LIKE 'PK__test__3213E83F49FB8D49'
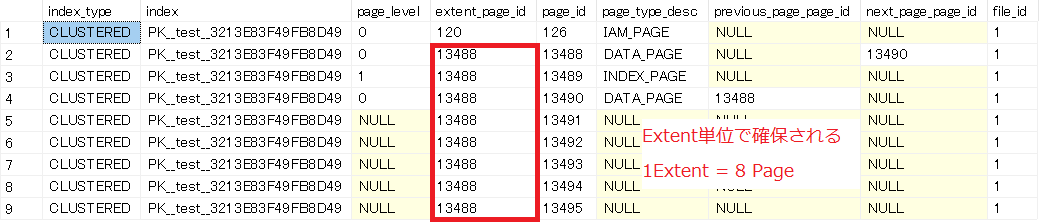
ページは一つずつ確保されるわけではなく、Extent単位で確保されます。
1Extent = 8 Pageです。
Index Pageの中身を確認します。
DBCC TRACEON(3604)
DBCC PAGE ('sample', 1, 13489, 3)
DBCC TRACEOFF(3604)
Index Pageの中にkeyの~133はData Pageの13488に、134~はData Pageの13490という指定があることが分かります。

今度はData Pageの中身を見てみます。
DBCC TRACEON(3604)
DBCC PAGE ('sample', 1, 13490, 3)
DBCC TRACEOFF(3604)
クラスタ化インデックスなので、テーブルの実体が入っています。
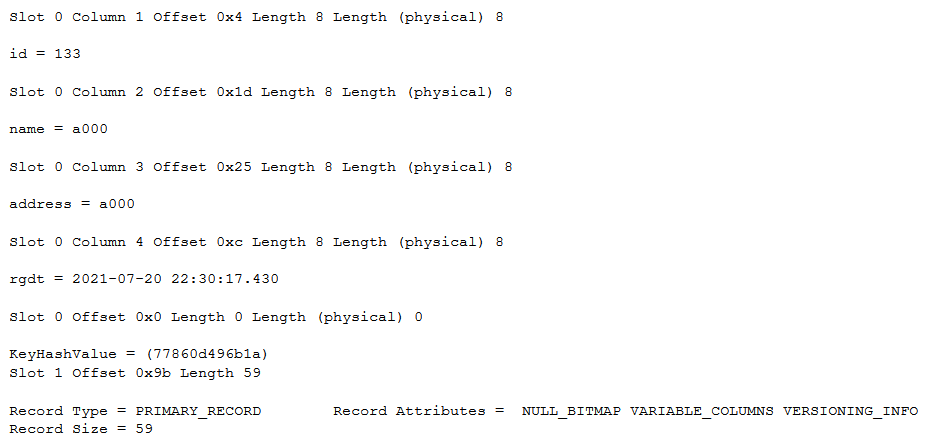
非クラスター化インデックスの中身をみてみます。
SELECT
i.type_desc AS [index_type],
i.name AS [index],
page_level AS [page_level],
p.extent_page_id,
allocated_page_page_id AS [page_id],
page_type_desc,
previous_page_page_id,
next_page_page_id,
p.allocated_page_file_id AS [file_id]
FROM
sys.indexes i CROSS APPLY
sys.dm_db_database_page_allocations(DB_ID('sample'), i.object_id, i.index_id, NULL, 'DETAILED') p
WHERE i.name LIKE 'idx_test_name'
Index Pageが一つだけあるのが分かります。
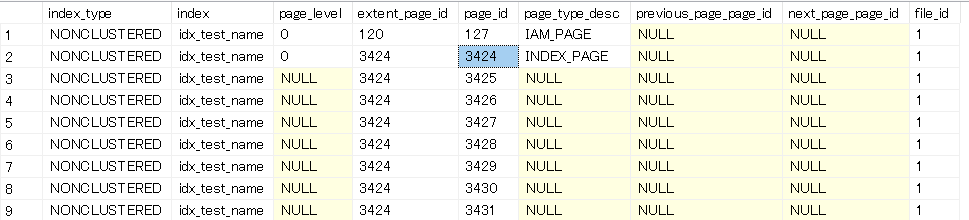
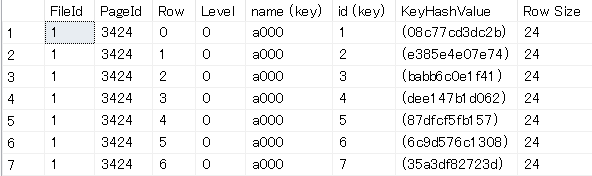
中をみてみましょう。
DBCC TRACEON(3604)
DBCC PAGE ('sample', 1, 3424, 3)
DBCC TRACEOFF(3604)
keyごとのPageIdとKeyHashValueというData Page内で対象行を特定する項目が入っています。
シリーズ SQL Server/SQL Database再入門
なんとなくならSQL Serverを使えている人のためのSQL Server/SQL DatabaseのTips集です。